代码随想录刷题题Day15
刷题的第十五天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀
刷题语言:C++
Day15 任务
● 513.找树左下角的值
● 112. 路径总和 113.路径总和ii
● 106.从中序与后序遍历序列构造二叉树 105.从前序与中序遍历序列构造二叉树
1 找树左下角的值
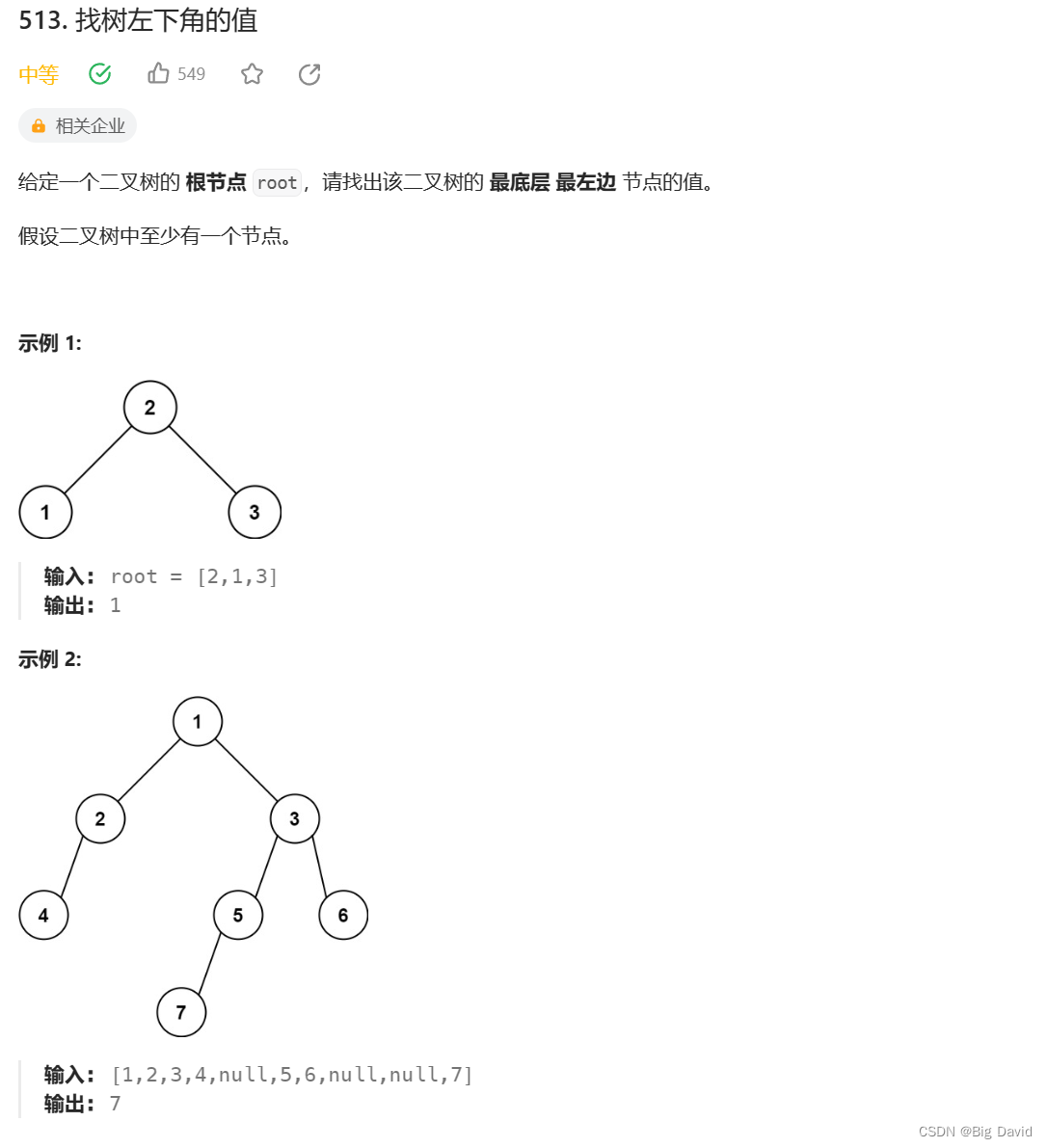
本题要找出树的最后一行最左边的值
思路1:层序遍历
思路2:递归
迭代法
层序遍历模板参考代码随想录刷题题Day12
class Solution {
public:int findBottomLeftValue(TreeNode* root) {queue<TreeNode*> que;int result;if (root != NULL) que.push(root);while (!que.empty()){int size = que.size();for (int i = 0; i < size; i++){TreeNode* node = que.front();que.pop();if (i == 0) result = node->val;// 记录最后一行第一个元素if (node->left) que.push(node->left);if (node->right) que.push(node->right);}}return result;}
};
递归法
误区:不是一直向左遍历,最后一个就是答案
一直向左遍历到最后一个,未必是最后一行
关键:在树的最后一行找到最左边的值
(1) 判断最后一行:深度最大的叶子节点
(2) 最左边的值:可以使用前序遍历(当然中序,后序都可以,因为本题没有 中间节点的处理逻辑,只要左优先就行),保证优先左边搜索,然后记录深度最大的叶子节点,此时就是树的最后一行最左边的值。
(1)确定递归函数的参数和返回值
参数:要遍历的树的根节点,最长深度
返回值:void
int maxDepth = INT_MIN;// 全局变量 记录最大深度
int result; // 全局变量 最大深度最左节点的数值
void traversal(TreeNode* node, int depth)
(2)确定终止条件
当遇到叶子节点的时候,就需要统计一下最大的深度了,所以需要遇到叶子节点来更新最大深度。
if (node->left == NULL && node->right == NULL)
{if (depth > maxDepth){maxDepth = depth; // 更新最大深度result = node->val; // 最大深度最左面的数值}return;
}
(3)确定单层递归的逻辑
找最大深度的时候,递归的过程中依然要使用回溯
// 中
if (node->left) {// 左depth++;// 深度加一traversal(node->left, depth);depth--;// 回溯,深度减一
}
if (node->right) {// 右depth++;// 深度加一traversal(node->right, depth);depth--;// 回溯,深度减一
}
C++:
class Solution {
public:int maxDepth = INT_MIN;int result;void traversal(TreeNode* node, int depth) {if (node->left == NULL && node->right == NULL) {if (maxDepth < depth) {maxDepth = depth;result = node->val;}}if (node->left) {depth++;traversal(node->left, depth);depth--;}if (node->right) {depth++;traversal(node->right, depth);depth--;}return;}int findBottomLeftValue(TreeNode* root) {traversal(root, 0);return result;}
};
精简版本C++:
class Solution {
public:int maxDepth = INT_MIN;int result;void traversal(TreeNode* node, int depth) {if (node->left == NULL && node->right == NULL) {if (maxDepth < depth) {maxDepth = depth;result = node->val;}}if (node->left) {traversal(node->left, depth + 1);// 隐藏着回溯}if (node->right) {traversal(node->right, depth + 1);// 隐藏着回溯}return;}int findBottomLeftValue(TreeNode* root) {traversal(root, 0);return result;}
};
2 路径总和
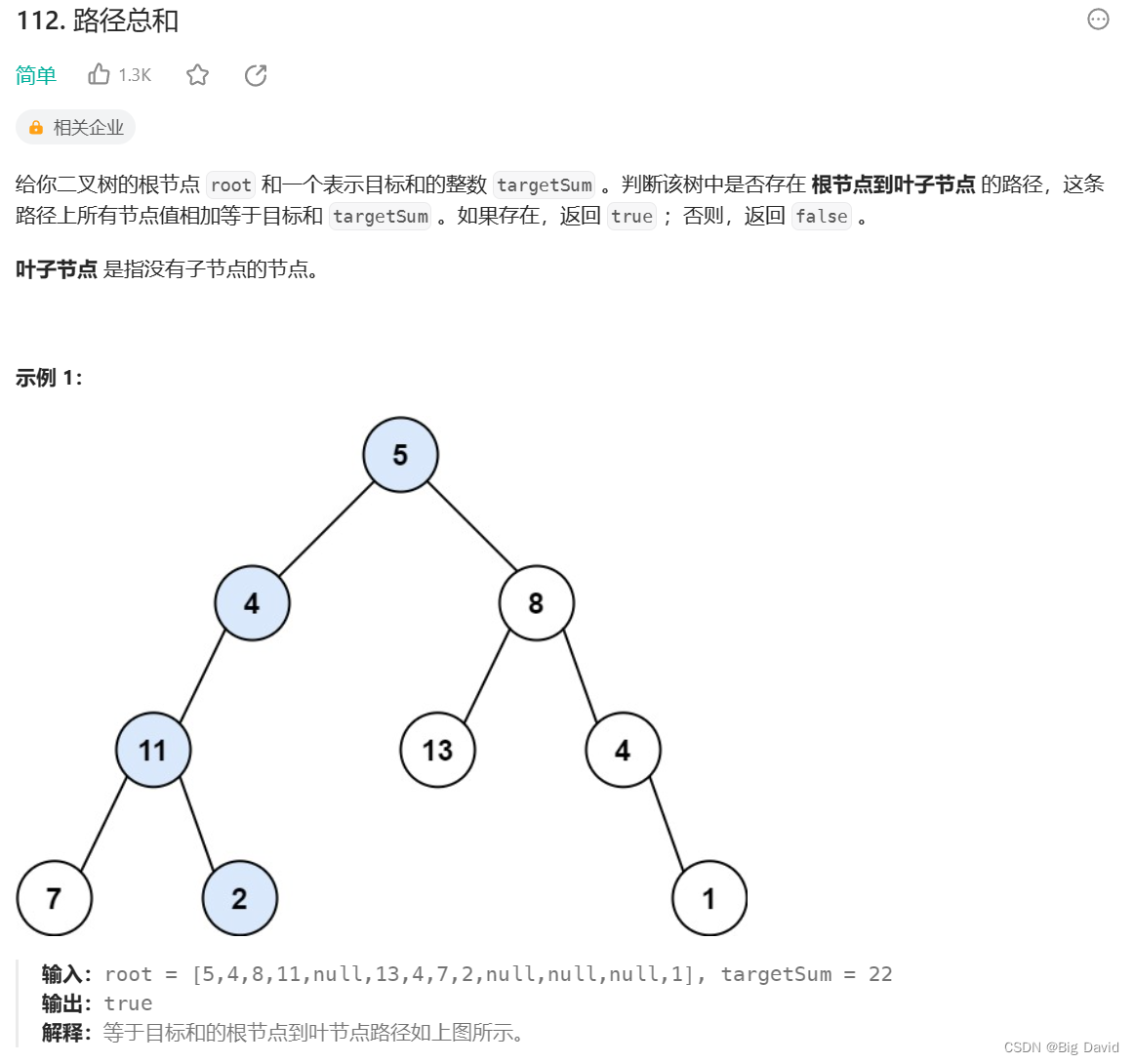
思路:
使用深度优先遍历的方式,本题前中后序都可以,因为中间节点没有处理逻辑
递归法
(1)确定递归函数的参数和返回类型
参数:二叉树的根节点、计算器(用来计算二叉树的一条边之和是否正好是目标和)
返回值:要找一条符合条件的路径,所以递归函数需要返回值,遍历的路线,并不要遍历整棵树,及时返回,返回类型是bool
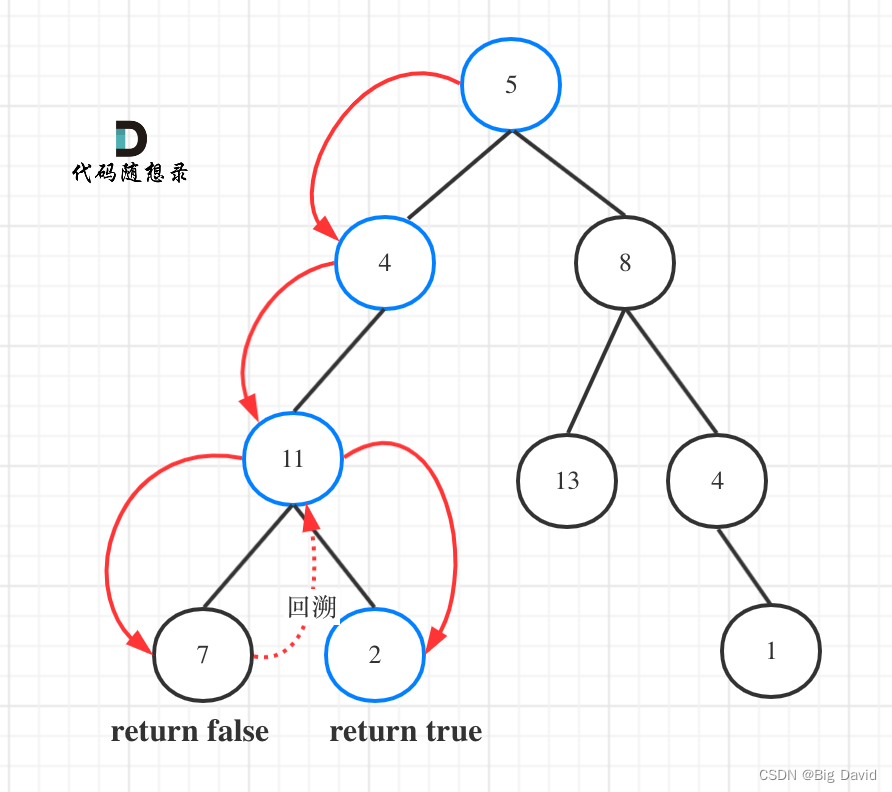
递归函数返回值:
(1)如果需要搜索整棵二叉树且不用处理递归返回值,递归函数就不要返回值
(2)如果需要搜索整棵二叉树且需要处理递归返回值,递归函数就需要返回值。
(3)如果要搜索其中一条符合条件的路径,那么递归一定需要返回值,因为遇到符合条件的路径了就要及时返回
bool traversal(TreeNode* node, int count)
(2)确定终止条件
计数器count初始为目标和,然后每次减去遍历路径节点上的数值
- 如果最后count == 0,同时到了叶子节点的话,说明找到了目标和
- 如果遍历到了叶子节点,count不为0,就是没找到
if (node->left == NULL && node->right == NULL && count == 0) return true;
if (node->left == NULL && node->right == NULL && count != 0) return false;
(3)确定单层递归的逻辑
递归函数是有返回值的,如果递归函数返回true,说明找到了合适的路径,应该立刻返回
if (node->left) {// 左 (空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif (traversal(node->left, count - node->left->val)) return true;
}
if (node->right) {// 右 (空节点不遍历)// 遇到叶子节点返回true,则直接返回trueif (traversal(node->right, count - node->right->val)) return true;
return false;
把回溯的过程表现出来:
if (node->left) {// 左count -= node->left->val;// 递归,处理节点;if (traversal(node->left, count)) return true;count += node->left->val;// 回溯,撤销处理结果
}
if (node->right) { // 右count -= node->right->val;if (traversal(node->right, count)) return true;count += node->right->val;// 回溯,撤销处理结果
}
C++:
class Solution {
public:bool traversal(TreeNode* node, int count) {if (node->left == NULL && node->right == NULL && count == 0) return true;// 遇到叶子节点,并且计数为0if (node->left == NULL && node->right == NULL && count != 0) return false;// 遇到叶子节点直接返回if (node->left) {// 左count -= node->left->val;// 递归,处理节点;if (traversal(node->left, count)) return true;count += node->left->val;// 回溯,撤销处理结果}if (node->right) {// 右count -= node->right->val;// 递归,处理节点if (traversal(node->right, count)) return true;count += node->right->val;// 回溯,撤销处理结果}return false;}bool hasPathSum(TreeNode* root, int targetSum) {if (root == NULL) return false;return traversal(root, targetSum - root->val);}
};
精简版本C++:
class Solution {
public:bool hasPathSum(TreeNode* root, int targetSum) {if (!root) return false;if (!root->left && !root->right && targetSum == root->val) {return true;}return hasPathSum(root->left, targetSum - root->val) || hasPathSum(root->right, targetSum - root->val);}
};
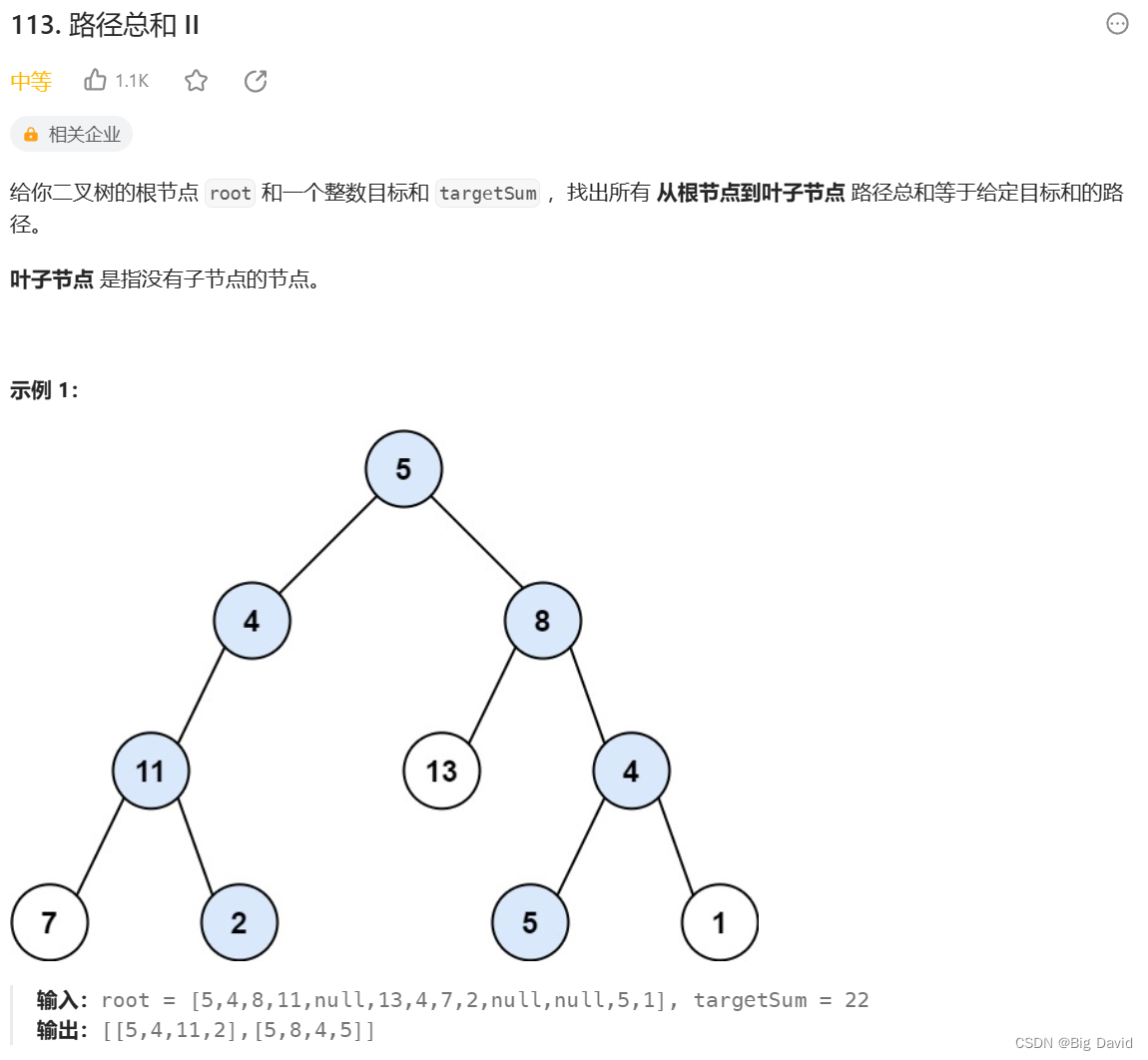
思路:
路径总和ii要遍历整个树,找到所有路径,所以递归函数不要返回值!
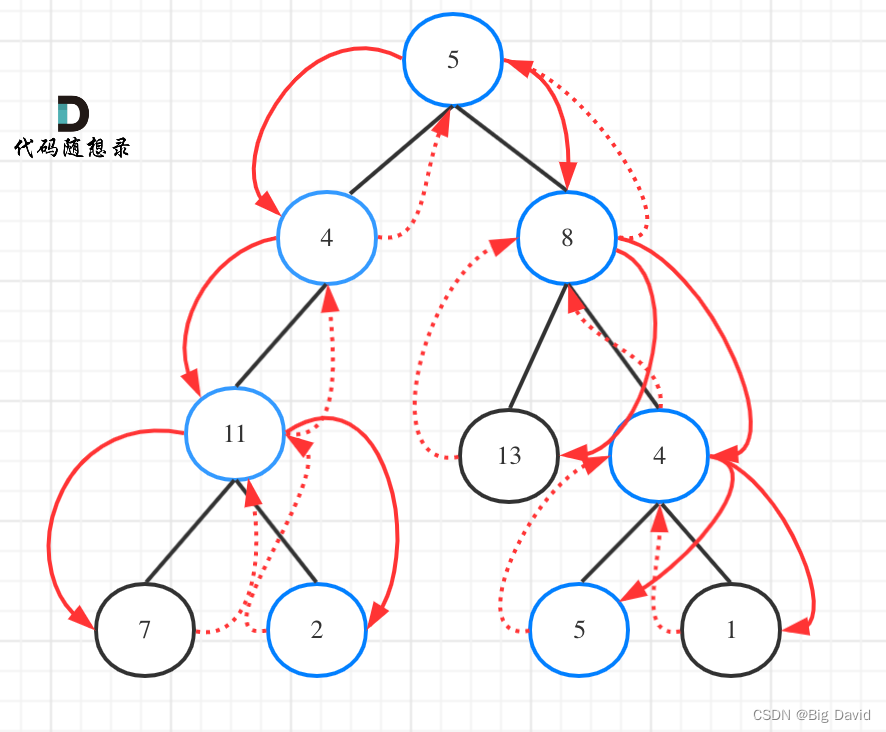
class Solution {
public:vector<vector<int>> result;vector<int> path;// 递归函数不需要返回值,因为我们要遍历整个树void traversal(TreeNode* node, int count) {if (node->left == NULL && node->right == NULL && count == 0) {result.push_back(path);return;}if (node->left == NULL && node->right == NULL) return;// 遇到叶子节点而没有找到合适的边,直接返回if (node->left) {// 左 (空节点不遍历)path.push_back(node->left->val);count -= node->left->val;traversal(node->left, count);// 递归count += node->left->val;// 回溯path.pop_back();// 回溯}if (node->right) {// 右 (空节点不遍历)path.push_back(node->right->val);count -= node->right->val;traversal(node->right, count);// 递归count += node->right->val;// 回溯path.pop_back();// 回溯}return;}vector<vector<int>> pathSum(TreeNode* root, int targetSum) {result.clear();path.clear();if (root == NULL) return result;path.push_back(root->val);// 把根节点放进路径traversal(root, targetSum - root->val);return result;}
};
3 从中序与后序遍历序列构造二叉树
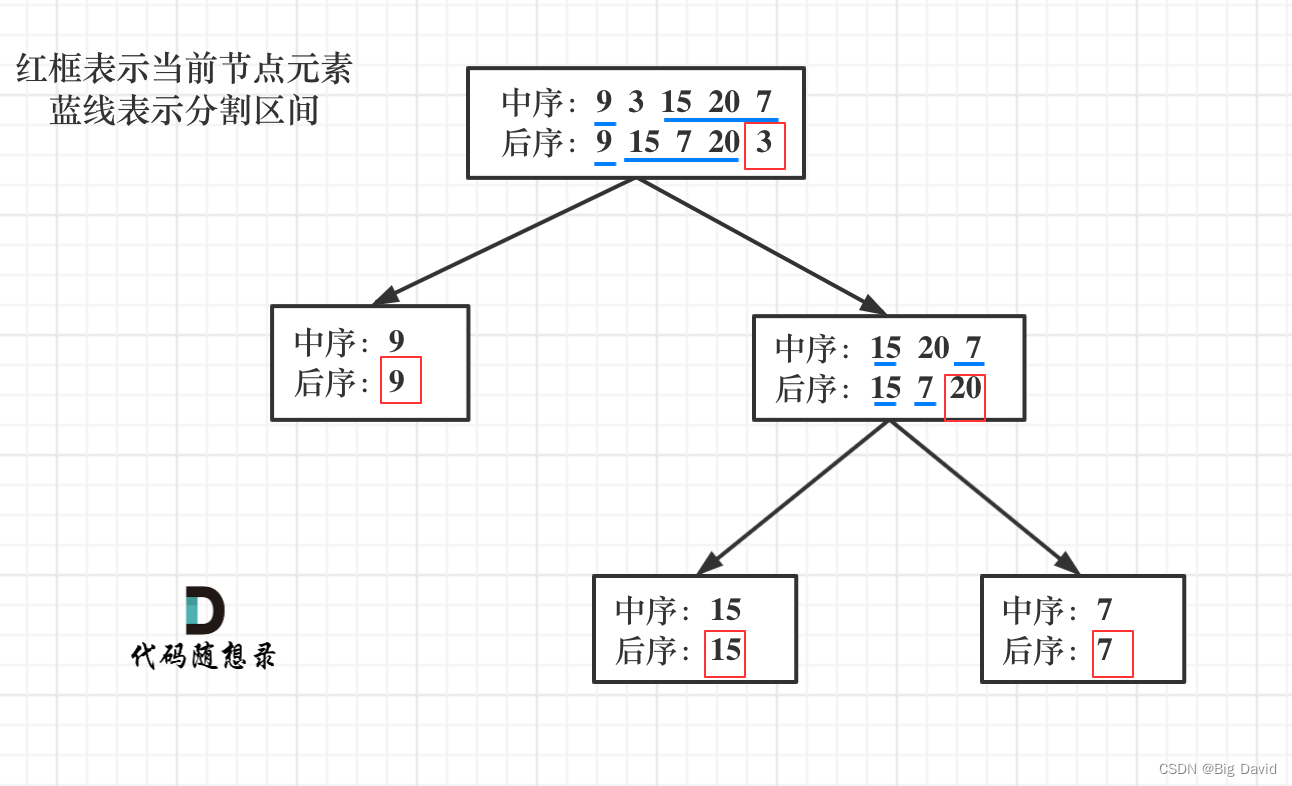
思路:
- 后序数组为0,空节点
- 后序数组最后一个元素为节点元素
- 寻找中序数组位置作为切割点
- 切中序数组
- 切后序数组
- 递归处理左右区间
C++:
class Solution {
public:TreeNode* traversal(vector<int>& inorder, vector<int>& postorder) {if (postorder.size() == 0) return NULL;// 后序遍历数组最后一个元素,就是当前的中间节点int rootValue = postorder[postorder.size() - 1];TreeNode* root = new TreeNode(rootValue);// 叶子节点if (postorder.size() == 1) return root;// 找到中序遍历的切割点int index;for (index = 0; index < inorder.size(); index++){if (inorder[index] == rootValue) break;}// 切割中序数组vector<int> leftInorder(inorder.begin(), inorder.begin() + index);vector<int> rightInorder(inorder.begin() + index + 1, inorder.end());postorder.resize(postorder.size() - 1);// 切割后序数组vector<int> leftPostorder(postorder.begin(), postorder.begin() + leftInorder.size());vector<int> rightPostorder(postorder.begin() + leftInorder.size(), postorder.end());root->left = traversal(leftInorder, leftPostorder);root->right = traversal(rightInorder, rightPostorder);return root;}TreeNode* buildTree(vector<int>& inorder, vector<int>& postorder) {if (inorder.size() == 0 || postorder.size() == 0) return NULL;return traversal(inorder, postorder);}
};
4 从前序与中序遍历序列构造二叉树
思路:
- 前序数组为0,空节点
- 前序数组第一个元素为节点元素
- 寻找中序数组位置作为切割点
- 切中序数组
- 切前序数组
- 递归处理左右区间
C++:
class Solution {
public:TreeNode* traversal(vector<int>& preorder, vector<int>& inorder) {// 前序数组为0,空节点if (preorder.size() == 0) return NULL;// 前序数组第一个元素为节点元素int rootValue = preorder[0];TreeNode* root = new TreeNode(rootValue);if (preorder.size() == 1) return root;// 寻找中序数组位置作为切割点int index;for (index = 0; index < inorder.size(); index++) {if (inorder[index] == rootValue) break;}// 切中序数组vector<int> leftInorder(inorder.begin(), inorder.begin() + index);vector<int> rightInorder(inorder.begin() + index + 1, inorder.end());// 切前序数组preorder.erase(preorder.begin());vector<int> leftPreorder(preorder.begin(), preorder.begin() + leftInorder.size());vector<int> rightPreorder(preorder.begin() + leftPreorder.size(), preorder.end());// 递归处理左右区间root->left = traversal(leftPreorder, leftInorder);root->right = traversal(rightPreorder, rightInorder);return root;}TreeNode* buildTree(vector<int>& preorder, vector<int>& inorder) {if (preorder.size() == 0 || inorder.size() == 0) return NULL;return traversal(preorder, inorder);}
};
鼓励坚持十六天的自己😀😀😀
相关文章:
代码随想录刷题题Day15
刷题的第十五天,希望自己能够不断坚持下去,迎来蜕变。😀😀😀 刷题语言:C Day15 任务 ● 513.找树左下角的值 ● 112. 路径总和 113.路径总和ii ● 106.从中序与后序遍历序列构造二叉树 105.从前序与中序遍历…...
软件设计师——信息安全(一)
📑前言 本文主要是【信息安全】——软件设计师——信息安全的文章,如果有什么需要改进的地方还请大佬指出⛺️ 🎬作者简介:大家好,我是听风与他🥇 ☁️博客首页:CSDN主页听风与他 🌄…...

git必须掌握:git远程变动怎么解决
如何已经指定了选择分支 那下面的分支名称可以省略 如果远程分支存在变动,通常 git 推送的流程如下: 首先,使用 git fetch 命令从远程仓库获取最新的分支信息和变动。 git fetch然后,可以使用 git merge 或者 git rebase 命令进…...

Python里的时间模块
time 模块 时间表示方式 时间戳 timestamp:表示的是从 1970 年1月1日 00:00:00 开始按秒计算的偏移量UTC(Coordinated Universal Time, 世界协调时)亦即格林威治天文时间,世界标准时间。在中国为 UTC+8 DST(Daylight Saving Time) 即夏令时;结构化时间(struct_time): …...
SCI一区级 | Matlab实现GWO-CNN-GRU-selfAttention多变量多步时间序列预测
SCI一区级 | Matlab实现GWO-CNN-GRU-selfAttention多变量多步时间序列预测 目录 SCI一区级 | Matlab实现GWO-CNN-GRU-selfAttention多变量多步时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.Matlab实现GWO-CNN-GRU-selfAttention灰狼算法优化卷积门控循环…...

C#学习相关系列之自定义遍历器
在C#中,自定义遍历器需要实现IEnumerable接口和IEnumerator接口。其中,IEnumerable接口包含一个GetEnumerator方法,该方法返回一个IEnumerator接口的实例,而IEnumerator接口包含Current、MoveNext和Reset方法。 IEnumerable&#…...
WPS没保存关闭了怎么恢复数据?3个方法,完成数据恢复!
“我今天在使用WPS时,突然有点急事出去了一趟,但是我忘记保存文档了,回来之后发现电脑自动关机了,我的文档也没了!这可怎么办呢?有什么办法可以找回这些数据吗?” 在快节奏的工作中,…...
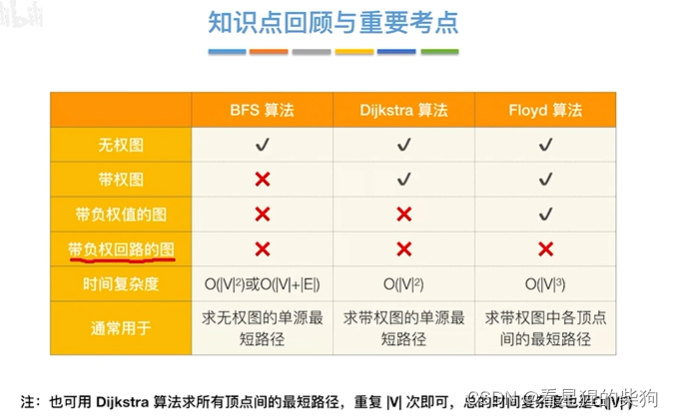
数据结构和算法-最小生成树(prim和krusakal)和最短路径问题(BFS和dijkastra和floyd)
文章目录 最小生成树总览生成树广度优先生成树深度优先生成树最小生成树Prim算法Kruskal算法Prim vs KrusakalPrim的实现Kruskal的实现 小结 最短路径问题单源最短路径问题BFS求无权图的单源最短路径小结Dijkastra算法算法时间复杂度不适用情况 每一对顶点的最短路径问题Floyd算…...
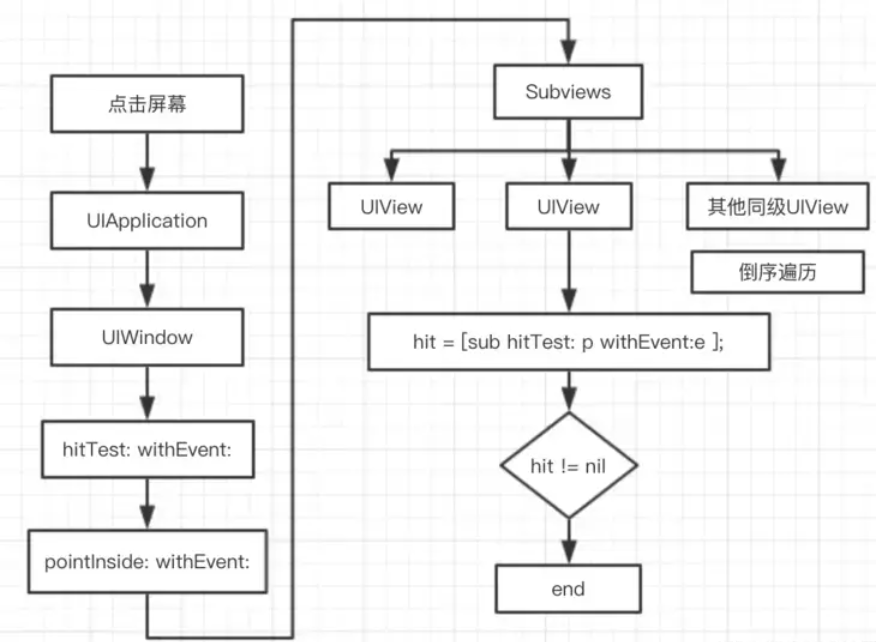
响应者链概述
响应者链 iOS事件的3大类型 Touch Events(触摸事件)Motion Events(运动事件,比如重力感应和摇一摇等)Remote Events(远程事件,比如用耳机上得按键来控制手机) 触摸事件 处理触摸事件的两个步骤 寻找事件的最佳响应者事件的响应在响应链中的传递 寻…...
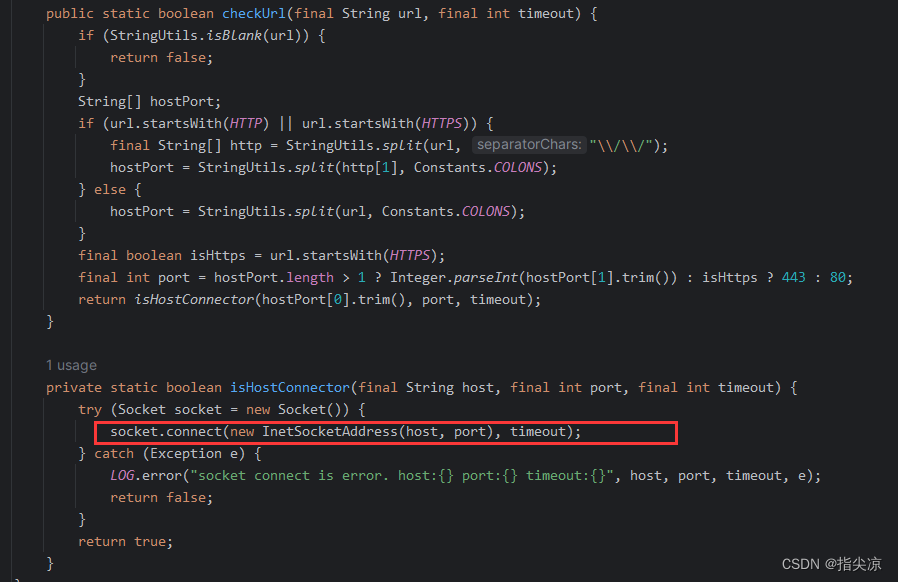
ShenYu网关Http服务探活解析
文章目录 网关端服务探活admin端服务探活 Shenyu HTTP服务探活是一种用于检测HTTP服务是否正常运行的机制。它通过建立Socket连接来判断服务是否可用。当服务不可用时,将服务从可用列表中移除。 网关端服务探活 以divide插件为例,看下divide插件是如何获…...
基于dockerfile搭建LNMP
组件自定义IP所需组件nginx172.111.0.10nginxwordpressmysql172.111.0.20mysql-5.7.20php172.111.0.30php LNMP介绍 L:Linux平台,操作系统,另外桑组件的运行平台 N:nginx 提供前端页面 M:MySQL,开源关系的…...
基于VGG-16+Android+Python的智能车辆驾驶行为分析—深度学习算法应用(含全部工程源码)+数据集+模型(三)
目录 前言总体设计系统整体结构图系统流程图 运行环境模块实现1. 数据预处理2. 模型构建3. 模型训练及保存1)模型训练2)模型保存 4. 模型生成1)模型导入及调用2)相关代码(1)布局文件(2ÿ…...
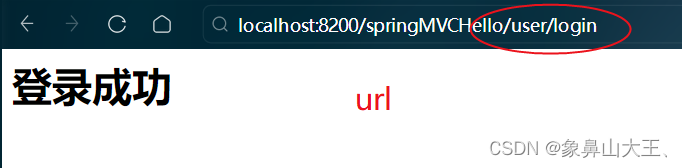
springMVC-@RequestMapping
基本介绍 RequestMapping注解可以指定控制器/处理器的某个方法的请求的url, 示例 (结合springMVC基本原理理解) Controller public class UserHandler {RequestMapping(value "/login")public String login() {System.out.println("登…...

智能优化算法应用:基于树种算法3D无线传感器网络(WSN)覆盖优化 - 附代码
智能优化算法应用:基于树种算法3D无线传感器网络(WSN)覆盖优化 - 附代码 文章目录 智能优化算法应用:基于树种算法3D无线传感器网络(WSN)覆盖优化 - 附代码1.无线传感网络节点模型2.覆盖数学模型及分析3.树种算法4.实验参数设定5.算法结果6.参考文献7.MA…...

web前端项目-影视网站开发
影视网站 本项目主要使用到了 HTML;CSS;JavaScript脚本技术;AJAX无刷新技术;jQuery等技术实现了动态影视网页 运行效果: 一:index.html <!DOCTYPE> <html lang"en"> <head>…...
QT:Unable to create a debugging engine.
debug跑不了: 报错:Unable to create a debugging engine. 参考: https://blog.csdn.net/u010906468/article/details/104716198 先检查是否安装了DEBUG插件 工具-》》选项 查看插件,如果没有的话,需要重新安装qt时…...

如何理解Rust语言中的“impl”关键字
在Rust编程语言中,impl是一个关键字,用于为类型实现方法和特性(traits)。impl关键字后面可以跟一个类型或者特性名称,然后在大括号中定义该类型或特性的具体实现。 当我们使用impl关键字为一个类型实现方法时…...

C++实现简单的猜数字小游戏
猜数字 小游戏介绍:猜数字游戏是令游戏机随机产生一个100以内的正整数,用户输入一个数对其进行猜测,需要你编写程序自动对其与随机产生的被猜数进行比较,并提示大了,还是小了,相等表示猜到了。如果猜到&…...

人工智能导论复习资料
题型 1、简答题(5题) 2、设计题 3、综合题 4、论述题(10分) 考点 第一章 1、人工智能的定义、发展; 2、人工智能的学派、认知观及其间的关系; 3、人工智能要素及系统分类; 4、人工智能的研究、…...

Sentinel使用详解
组件简介 Sentinel是阿里开源的一套用于服务容错的综合性解决方案。它以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度来保护服务的稳定性。Sentinel承接了阿里巴巴近10年的双十一大促流量的核心场景,例如秒杀、消息削峰填谷、集群流量控…...

【无人售货柜・RK+YOLO】篇 6:安卓端落地!RK3576 + 安卓系统,YOLO RKNN 模型实时推理保姆级教程
目录 一、前置说明 & 新手扫盲 新手必守的红线 二、第一步:环境 & 资源准备,新手零坑版 三、第二步:创建安卓项目,配置环境 四、第三步:核心功能实现,全流程代码带注释 模块 1:动…...

3步实现专业级直播抠像:OBS背景移除插件完全指南
3步实现专业级直播抠像:OBS背景移除插件完全指南 【免费下载链接】obs-backgroundremoval An OBS plugin for removing background in portrait images (video), making it easy to replace the background when recording or streaming. 项目地址: https://gitco…...

“网域小星球”启航:一个网络工程大三学生的自留地与学习计划
大家好,我是一名网络工程专业的大三学生。很高兴在CSDN这个技术社区安家,给我的技术自留地取名为“网域小星球”——希望在这里记录自己在网络世界里探索的点滴,也希望能成为一颗持续发光、不断成长的小星球。目前我正在系统学习C语言和C编程…...

隐私优先方案:OpenClaw+本地化Qwen3-32B处理敏感数据
隐私优先方案:OpenClaw本地化Qwen3-32B处理敏感数据 1. 为什么需要完全离线的数据处理方案 去年我在处理一批法律案件卷宗时,遇到了一个棘手的问题:客户要求所有材料必须在内网环境完成数字化处理,且禁止使用任何云端AI工具。当…...

网易云信Web语音通信实战:从零封装一个Vue3语音聊天组件
Vue3网易云信Web语音通信组件开发实战 语音交互正在成为现代Web应用的重要功能模块。本文将带您从零开始,基于Vue3组合式API和网易云信Web SDK,构建一个企业级可复用的语音聊天组件。不同于简单的SDK集成教程,我们将重点探讨工程化实践中的关…...

【ROS2】机械臂抓取——gazebo_grasp_plugin编译排障与模型集成实战
1. 环境准备与源码获取 最近在做一个机械臂抓取项目时,遇到了gazebo_grasp_plugin这个神奇的插件。说实话,从下载到成功运行的过程真是踩了不少坑,今天就把这些经验完整分享给大家。首先需要明确的是,我们使用的是ROS2 Humble版本…...

基于GTE的智能广告投放:用户兴趣与广告文案的语义匹配
基于GTE的智能广告投放:用户兴趣与广告文案的语义匹配 1. 引言 你有没有遇到过这样的情况?刷手机时看到的广告完全不对胃口,不是已经买过的产品,就是根本不感兴趣的内容。这种糟糕的广告体验背后,其实是传统广告投放…...

STM32电机控制库5.4版:开源无感驱动注释详解——从寄存器设置到弱磁控制策略实现
STM32电机库5.4开源无感注释 KEIL工程文件 辅助理解ST库 寄存器设置AD TIM1 龙贝格PLL 前馈控制 弱磁控制 foc的基本流 svpwm占空比计算方法 斜坡启动 死区补偿 有详细的注释, 当前是无传感器版本龙贝格观测,三电阻双AD采样!搞STM32电机控制就像在玩硬件…...

Nanbeige 4.1-3B效果展示:思考链日志折叠/展开动画+绿色脉冲高亮关键推理步骤
Nanbeige 4.1-3B效果展示:思考链日志折叠/展开动画绿色脉冲高亮关键推理步骤 1. 复古像素风AI对话体验 Nanbeige 4.1-3B模型搭载了一套独特的"像素冒险"风格对话界面,将AI交互转化为一场视觉化的JRPG游戏体验。这套界面设计突破了传统聊天机…...

思源宋体深度应用指南:从技术原理到实战优化
思源宋体深度应用指南:从技术原理到实战优化 【免费下载链接】source-han-serif-ttf Source Han Serif TTF 项目地址: https://gitcode.com/gh_mirrors/so/source-han-serif-ttf 在全球化数字内容创作浪潮中,中文字体的选择与应用直接关系到信息传…...