风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
目录
前言
1 风速数据EMD分解与可视化
1.1 导入数据
1.2 EMD分解
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集
2.2 设置滑动窗口大小为96,制作数据集
3 基于Pytorch的EMD-CNN-LSTM模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
3.2 定义EMD-CNN-LSTM预测模型
3.3 定义模型参数
3.4 模型训练
3.5 结果可视化

往期精彩内容:
风速预测(一)数据集介绍和预处理-CSDN博客
风速预测(二)基于Pytorch的EMD-LSTM模型-CSDN博客
风速预测(三)EMD-LSTM-Attention模型-CSDN博客
风速预测(四)基于Pytorch的EMD-Transformer模型-CSDN博客
前言
LSTF(Long Sequence Time-Series Forecasting)问题是指在时间序列预测中需要处理长序列的情况。在实际应用中,时间序列可能会包含非常大量的数据点,在这种情况下,传统的时间序列预测模型可能会遇到一些挑战,因为处理长序列时会出现一些问题,例如:
-
长期依赖性: 随着时间序列数据的增长,模型需要能够捕捉长期的依赖关系和趋势。
-
计算复杂性: 针对长序列进行训练和预测通常需要更多的计算资源和时间。
-
内存消耗: 长序列通常需要大量的内存来存储数据和模型参数,这可能会导致内存耗尽或者性能下降的问题。
在处理LSTF问题时,选择合适的窗口大小(window size)是非常关键的。选择合适的窗口大小可以帮助模型更好地捕捉时间序列中的模式和特征,为了提取序列中更长的依赖建模,本文把窗口大小提升到96,运用EMD-CNN-LSTM模型来充分提取序列中的特征信息。
本文基于前期介绍的风速数据(文末附数据集),先经过经验模态EMD分解,然后通过数据预处理,制作和加载数据集与标签,最后通过Pytorch实现EMD-CNN-LSTM模型对风速数据的预测。风速数据集的详细介绍可以参考下文:
风速预测(一)数据集介绍和预处理
1 风速数据EMD分解与可视化
1.1 导入数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rc("font", family='Microsoft YaHei')
# 读取已处理的 CSV 文件
df = pd.read_csv('wind_speed.csv' )
# 取风速数据
winddata = df['Wind Speed (km/h)'].tolist()
winddata = np.array(winddata) # 转换为numpy
# 可视化
plt.figure(figsize=(15,5), dpi=100)
plt.grid(True)
plt.plot(winddata, color='green')
plt.show()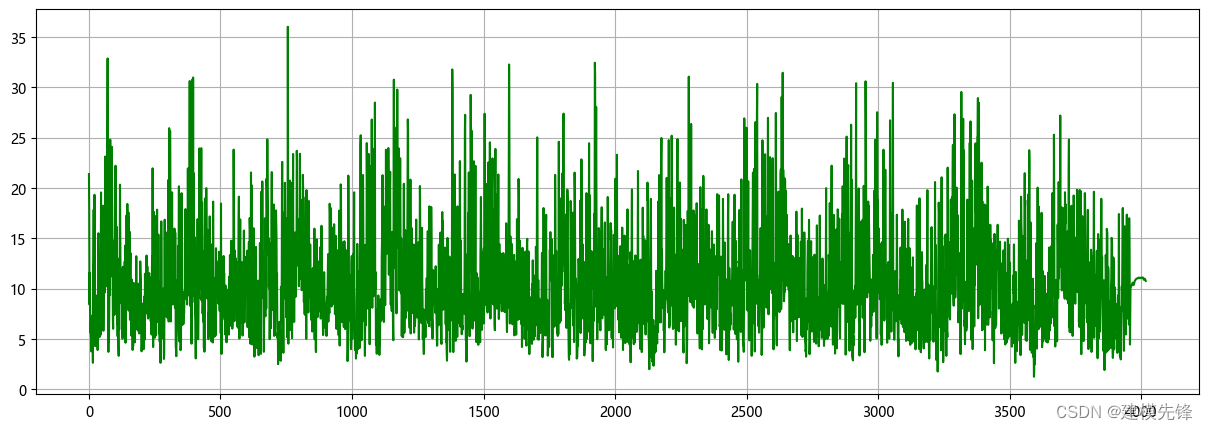
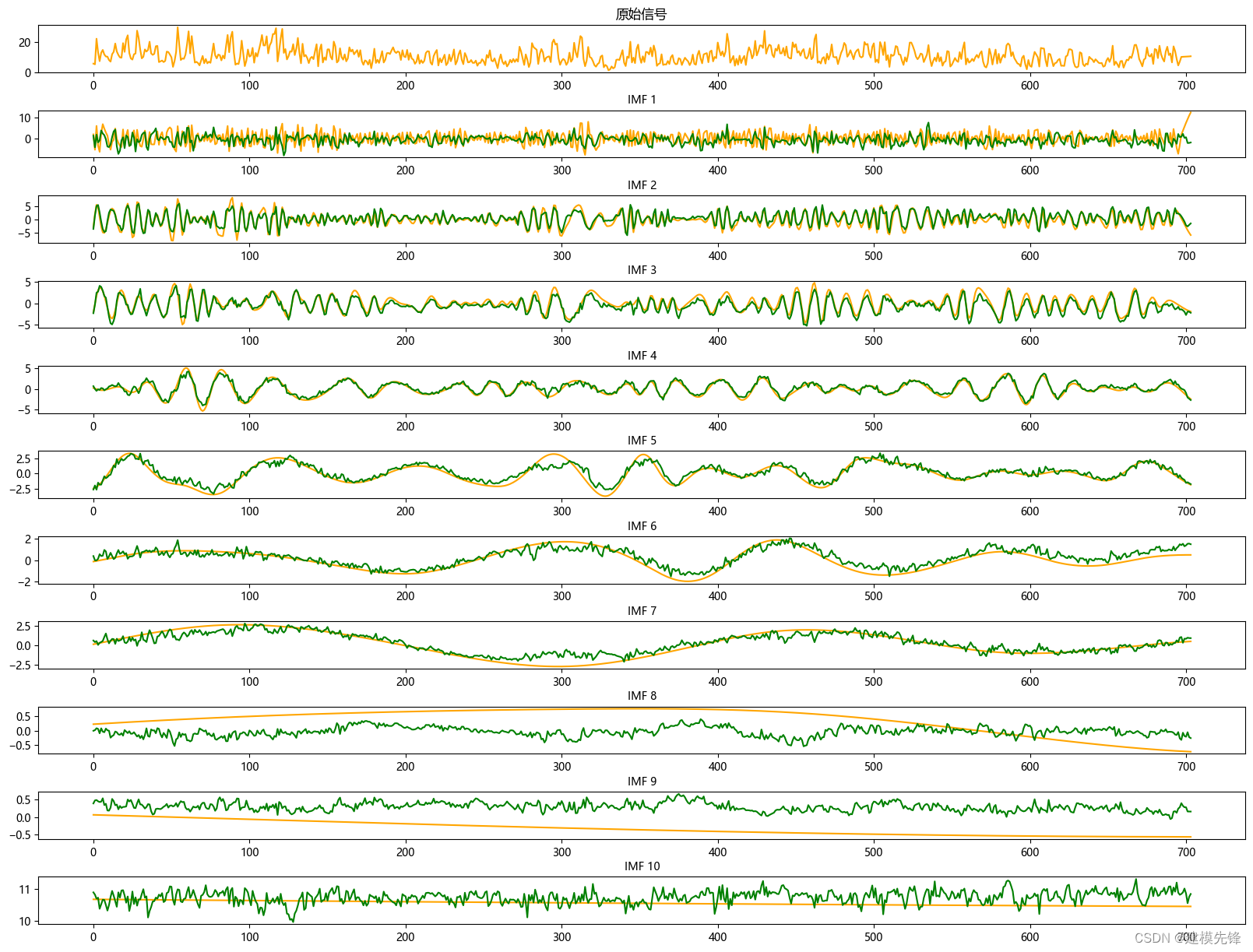
1.2 EMD分解
from PyEMD import EMD
# 创建 EMD 对象
emd = EMD()
# 对信号进行经验模态分解
IMFs = emd(winddata)
# 可视化
plt.figure(figsize=(20,15))
plt.subplot(len(IMFs)+1, 1, 1)
plt.plot(winddata, 'r')
plt.title("原始信号")
for num, imf in enumerate(IMFs):plt.subplot(len(IMFs)+1, 1, num+2)plt.plot(imf)plt.title("IMF "+str(num+1), fontsize
=
10
)
# 增加第一排图和第二排图之间的垂直间距
plt.subplots_adjust(hspace=0.8, wspace=0.2)
plt.show()
2 数据集制作与预处理
2.1 先划分数据集,按照8:2划分训练集和测试集

2.2 设置滑动窗口大小为96,制作数据集

3 基于Pytorch的EMD-CNN-LSTM模型预测
3.1 数据加载,训练数据、测试数据分组,数据分batch
# 加载数据
import torch
from joblib import dump, load
import torch.utils.data as Data
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
# 参数与配置
torch.manual_seed(100) # 设置随机种子,以使实验结果具有可重复性
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 加载数据集
def dataloader(batch_size, workers=2):# 训练集train_set = load('train_set')train_label = load('train_label')# 测试集test_set = load('test_set')test_label = load('test_label')
# 加载数据train_loader = Data.DataLoader(dataset=Data.TensorDataset(train_set, train_label),batch_size=batch_size, num_workers=workers, drop_last=True)test_loader = Data.DataLoader(dataset=Data.TensorDataset(test_set, test_label),batch_size=batch_size, num_workers=workers, drop_last=True)return train_loader, test_loader
batch_size = 64
# 加载数据
train_loader, test_loader = dataloader(batch_size)3.2 定义EMD-CNN-LSTM预测模型
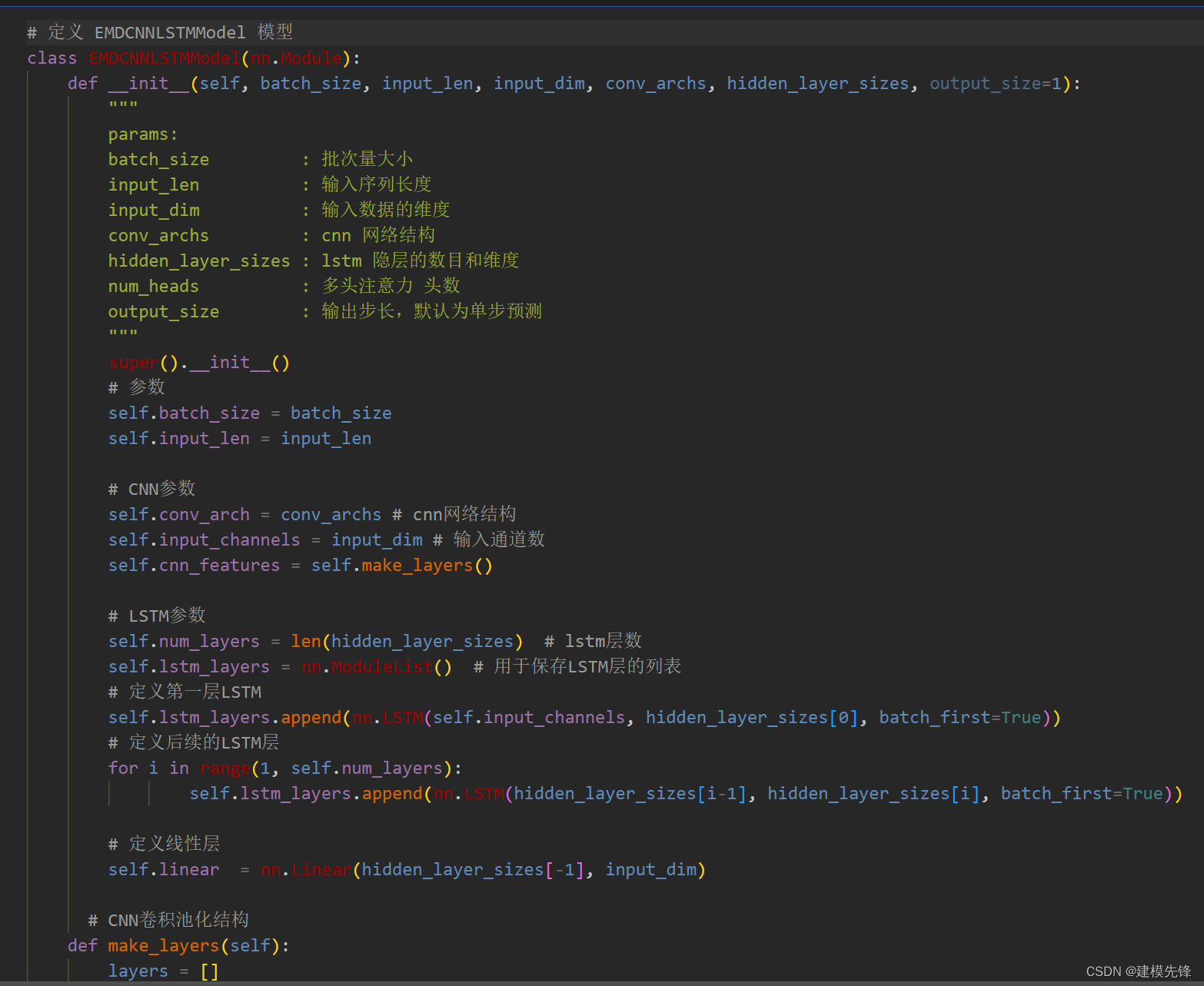
注意:输入风速数据形状为 [64, 10, 96], batch_size=64, 维度10维代表10个分量,96代表序列长度(滑动窗口取值)。
3.3 定义模型参数
# 定义模型参数
batch_size = 64
input_len = 96 # 输入序列长度为96 (窗口值)
input_dim = 10 # 输入维度为10个分量
conv_archs = ((1, 32), (1, 64)) # CNN 层卷积池化结构 类似VGG
hidden_layer_sizes = [64, 128] # LSTM 层 结构
output_size = 1 # 单步输出
model = EMDCNNLSTMModel(batch_size, input_len, input_dim, conv_archs, hidden_layer_sizes, output_size=1)
# 定义损失函数和优化函数
model = model.to(device)
loss_function = nn.MSELoss() # loss
learn_rate = 0.003
optimizer = torch.optim.Adam(model.parameters(), learn_rate) # 优化器3.4 模型训练

训练结果

采用两个评价指标:MSE 与 MAE 对模型训练进行评价,100个epoch,MSE 为0.00412,MAE 为 0.000241,EMD-CNN-LSTM预测效果良好,性能提升明显,适当调整模型参数,还可以进一步提高模型预测表现。通过CNN模型来处理输入的长窗口时间序列数据,能够有效地捕获局部模式和特征,将CNN模型的输出作为LSTM模型的输入,LSTM模型能够更好地捕捉时间序列数据中的长期依赖关系。EMD-CNN-LSTM模型效果明显,可见其性能的优越性。
注意调整参数:
-
可以适当调整CNN中卷积池化的层数和维度,微调学习率;
-
调整LSTM层数和维度,增加更多的 epoch (注意防止过拟合)
-
可以改变滑动窗口长度(设置合适的窗口长度)
3.5 结果可视化

相关文章:
风速预测(五)基于Pytorch的EMD-CNN-LSTM模型
目录 前言 1 风速数据EMD分解与可视化 1.1 导入数据 1.2 EMD分解 2 数据集制作与预处理 2.1 先划分数据集,按照8:2划分训练集和测试集 2.2 设置滑动窗口大小为96,制作数据集 3 基于Pytorch的EMD-CNN-LSTM模型预测 3.1 数据加载&…...
-云计算2023.12-云南农业大学)
单元测试二(理论)-云计算2023.12-云南农业大学
文章目录 一、单选题1、三次握手、四次挥手发生在网络模型的哪一层上?2、互联网Internet的拓扑结构是什么?3、以下哪一种网络设备是工作在网络层的?4、以下哪种关于分组交换网络的说法是错误的?5、以下哪种协议是在TCP/IP模型中的…...

QModelIndex 是 Qt 框架中的一个类,用于表示数据模型中的索引位置
QModelIndex 是 Qt 框架中的一个类,用于表示数据模型中的索引位置。 在 Qt 中,数据模型是一种组织和管理数据的方式,常见的数据模型包括 QAbstractItemModel、QStandardItemModel 和 QSqlQueryModel 等。QModelIndex 类提供了一种标识数据模…...
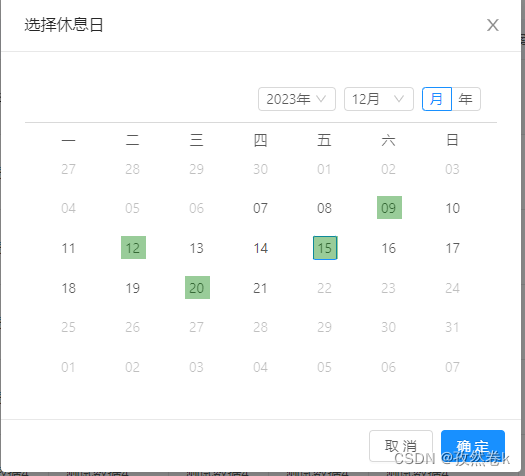
前端实现一个时间区间内,再次单选功能,使用Antd组件库内日历组件Calendar
需求:需要先让用户选择一个时间区间,然后再这个时间区间中,让用户再次去单选其种特殊日期。 思路: 1.先用Antd组件库中日期选择DatePicker.RangePicker实现让用户选择时间区间 2.在选择完时间区间后,用这个时间区间…...

【运维笔记】Hyperf正常情况下Xdebug报错死循环解决办法
问题描述 在使用hyperf进行数据库迁移时,迁移报错: 查看报错信息,错误描述是Xdebug检测到死循环,可是打印的堆栈确实正常堆栈,没看到死循环。 寻求解决 gpt 说的跟没说一样。。 google一下 直接把报错信息粘贴上去…...
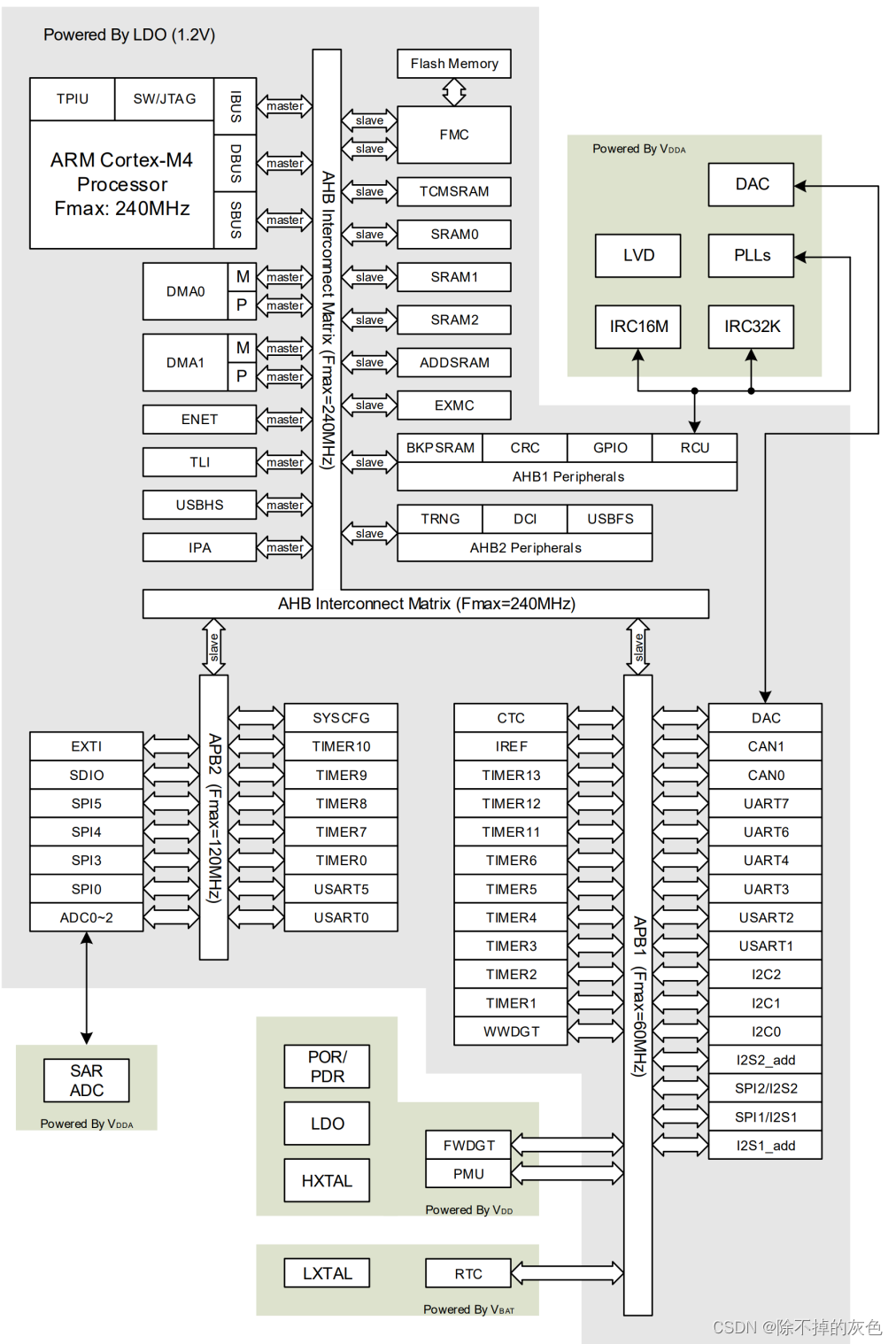
嵌入式开发中的总线与时钟
总线 AHB总线 AHB的全称是"Advanced High-performance Bus",中文翻译就是"高级高性能总线"。这是一种在计算机系统中用于连接不同硬件组件的总线架构,它可以帮助这些组件之间高效地传输数据和信息。这个总线架构通常用于处理速度较快且对性能要求较高的…...
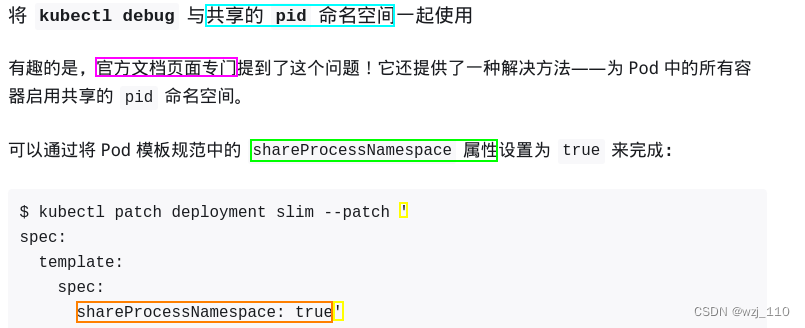
k8s debug 浅谈
一 k8s debug 浅谈 说明: 本文只是基于对kubectl debug浅显认识总结的知识点,后续实际使用再补充案例 Kubernetes 官方出品调试工具上手指南(无需安装,开箱即用) debug-application 简化 Pod 故障诊断: kubectl-debug 介绍 1.18 版本之前需要自己…...
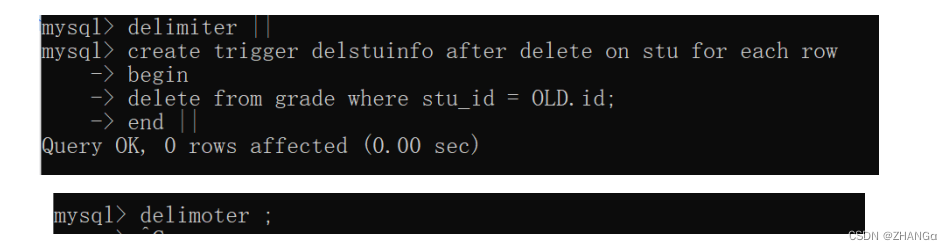
Day10 Liunx高级系统设计11-数据库2
DQL:数据查询语言 查询全表 select * from 表名; 查询指定列 select 列名 1, 列名 2,… from 表名 ; 条件查询 select * from 表名 where 条件 ; 注意: 条件查询就是在查询时给出 WHERE 子句,在 WHERE 子句中可以使用如下运算符及关键 字&#…...
车载导航系统UI界面,可视化大屏设计(PS源文件)
大屏组件可以让UI设计师的工作更加便捷,使其更高效快速的完成设计任务。现分享车载导航系统科技风蓝黑简约UI界面、车载系统UI主界面、车载系统科技风UI界面、首页车载系统科技感界面界面的大屏Photoshop源文件,开箱即用! 若需 更多行业 相关…...

工作之踩坑记录
1.i386架构之atol函数使用导致的业务程序错误: 情景:将框架传递的链接地址采用整形保存传输,在i386架构上导致地址比较大,采用atol转型可能导致数据被截断出现异常。 方案:采用atoll更大的数据类型进行处理即可避免该问题。 2.Json库使用注意long int问…...

【深度学习目标检测】四、基于深度学习的抽烟识别(python,yolov8)
YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。 YOLO(You Only Look Once)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。…...

YML学习
讲解YML使用场景、语法和解析 1.基础知识1.1 什么是YML1.2 YML优点1.3 YML使用场景 2.YML语法2.1 基础语法2.2 字面量数据类型2.2.1 字符串2.2.2 NULL2.4.5 时间戳(timestamp) 2.3 对象\MAP类型2.4 数组/List/Set2.4.1 值为基础类型2.4.2 值为对象2.4.3 …...

华为HCIP认证H12-821题库下
26、6.交换技术核心知识 (单选题)某交换机运行RSTP协议,其相关配置信息如图所示,请根据命令配置情况指出对于Instance 1,该交换机的角色是: A、根交换机 B、非根交换机 C、交换机 D、无法判断 正确答案是&…...

01--二分查找
一. 初识算法 1.1 什么是算法? 在数学和计算机科学领域,算法是一系列有限的严谨指令,通常用于解决一类特定问题或执行计算 不正式的说,算法就是任何定义优良的计算过程:接收一些值作为输入,在有限的时间…...

初识大数据应用,一文掌握大数据知识文集(1)
文章目录 🏆初识大数据应用知识🔎一、初识大数据应用知识(1)🍁 01、请用Java实现非递归二分查询?🍁 02、是客户端还是Namenode决定输入的分片?🍁 03、mapred.job.tracker命令的作用?…...
Kafka生产问题总结及性能优化实践
1、消息丢失情况 消息发送端: (1)acks0: 表示producer不需要等待任何broker确认收到消息的回复,就可以继续发送下一条消息。性能最高,但是最容易丢消息。大数据统计报表场景,对性能要求很高&am…...

[MySQL]数据库原理2,Server,DataBase,Connection,latin1、UTF-8,gb2312,Encoding,Default Collation——喵喵期末不挂科
希望你开心,希望你健康,希望你幸福,希望你点赞! 最后的最后,关注喵,关注喵,关注喵,佬佬会看到更多有趣的博客哦!!! 喵喵喵,你对我真的…...

【算法集训】基础数据结构:十、矩阵
矩阵其实就是二维数组,这些题目在9日集训中已经做过,这里做的方法大致相同。 第一题 1351. 统计有序矩阵中的负数 int countNegatives(int** grid, int gridSize, int* gridColSize) {int r gridSize;int c gridColSize[0];int ret 0;for(int i 0;…...

python排序算法 直接插入排序法和折半插入排序法
最近需要使用到一些排序算法,今天主要使针对直接插入排序和折半插入排序进行讲解。 首先是直接插入排序,其排序过程主要是,针对A[a1,a2,a3,a4,a5....an],从排序的序列头部起始位置开始,将其也就是a1视为只有一个元素的…...

【flutter对抗】blutter使用+ACTF习题
最新的能很好反编译flutter程序的项目 1、安装 git clone https://github.com/worawit/blutter --depth1 然后我直接将对应的两个压缩包下载下来(通过浏览器手动下载) 不再通过python的代码来下载,之前一直卡在这个地方。 如果读者可以正…...

Unity-MCP协议:可嵌入、可协商的AI上下文通信标准
1. 这不是又一个“AI插件”,而是Unity开发工作流的底层重定义你有没有过这样的时刻:在Unity里反复调整Animator Controller的过渡条件,只为让角色转身动画不穿模;写完一段NavMesh寻路逻辑,却要花两小时调试Agent卡在斜…...

13456
12356...
)
Allegro PCB设计小技巧:如何让Route Keepout区域既能走线又能打过孔(附详细步骤图)
Allegro PCB设计实战:Route Keepout区域的灵活控制技巧 在高速PCB设计中,Route Keepout区域的管理常常让工程师陷入两难境地——元件封装自带的限制区域与实际布线需求产生冲突。特别是处理PCIE等高速信号时,这种矛盾尤为突出。传统做法要么完…...

ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南
ZTE光猫工厂模式解锁:5分钟开启隐藏功能的终极指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 核心关键词:ZTE光猫工厂模式解锁 长尾关键词: ZT…...

风控系统如何全维度识别爬虫:IP、账号与行为的协同决策机制
1. 这不是“反爬失败”,而是风控系统在对你做全维度画像你写完一段 requests BeautifulSoup 的代码,本地跑通了,开开心心部署到服务器,结果第二天早上发现:所有请求返回 403,日志里全是空响应;…...

从零构建FOC轮腿机器人:开源平衡机器人完整指南
从零构建FOC轮腿机器人:开源平衡机器人完整指南 【免费下载链接】foc-wheel-legged-robot Open source materials for a novel structured legged robot, including mechanical design, electronic design, algorithm simulation, and software development. | 一个…...

基于PGA2311的树莓派Hi-Fi模拟音量控制器设计与实现
1. 项目概述:为树莓派DAC打造的高品质模拟音量控制器玩过树莓派音频播放器的朋友都知道,用上像PCM1794A这类高性能DAC芯片后,音质确实能上一个台阶,但有个不大不小的麻烦:这类芯片本身不带音量控制。软件调音量&#x…...

render_async嵌套渲染:构建复杂异步界面的完整解决方案
render_async嵌套渲染:构建复杂异步界面的完整解决方案 【免费下载链接】render_async render_async lets you include pages asynchronously with AJAX 项目地址: https://gitcode.com/gh_mirrors/re/render_async 在现代Web开发中,页面加载速度…...

基于LSTM自编码器的家用电器功耗异常检测系统构建指南
1. 项目概述:从能耗洞察到智能干预我们每天都在和各种家用电器打交道,从清晨唤醒你的咖啡机,到深夜还在默默工作的路由器。你有没有想过,这些看似微不足道的设备,其背后隐藏的能耗模式,其实大有文章&#x…...

基于Meshtastic构建LoRa Mesh网络:从硬件自制到传感器集成实战
1. 项目概述:构建一个灵活且易用的LoRa Mesh网络 如果你对物联网、远程传感或者去中心化通信网络感兴趣,那么LoRa技术一定不会陌生。它以其超低功耗、超远距离和强大的抗干扰能力,成为了构建广域传感网络的理想选择。然而,传统的…...