开源 LLM 微调训练指南:如何打造属于自己的 LLM 模型
一、介绍
今天我们来聊一聊关于LLM的微调训练,LLM应该算是目前当之无愧的最有影响力的AI技术。尽管它只是一个语言模型,但它具备理解和生成人类语言的能力,非常厉害!它可以革新各个行业,包括自然语言处理、机器翻译、内容创作和客户服务等,成为未来商业环境的重要组成部分。
我相信很多人在领略了GPT等大语言模型的魅力之后,都希望迫不及待的考虑能将模型能力集成到自己的产品中去,提升产品竞争力,由于LLM天然具备强大的语义理解能力,使得我们原来在用尝试用NLP去解决一些比较困难的问题突然变得迎刃而解,非常简单,甚至超出你的想象。此刻,我脑海里已经想到了很多可以借助LLM来实现的场景。
但是,我们也要面对一个很现实的问题,那就是在生产中使用LLM的成本和收益。说白了,就是要讨论钱的问题,老板可能更关心你的ROI比。那目前这些炒的火热的LLM是否一定就适合我们呢,一起看看它存在什么样的缺点。
1.1、商用模型在企业应用的劣势
-
投入成本:像OpenAI的GPT-4和Google的PaLm 2模型这样的LLM提供商是LLM性能的顶尖者,但是他们的顶级模型相当昂贵。GPT-4以及Google PaLm 2每1000个令牌(约600个单词)的费用在3到6美分之间。想象一下,如果你有一家有1000名员工的公司——每个员工每天发送大约25个提示——你每天就要花费750到1500美元!这还不算有成千上万的客户与你的LLM增强的应用程序互动了。
-
数据隐私:Google和OpenAI都不是在数据隐私保护方面做的特别不错的公司。从去年GPT模型爆发开始,大家的关注点都被模型本身的能力吸引了,没有太关注数据本身的安全问题,实际上经过这么一段时间全球用户的使用正好在给OpenAI做免费模型训练,虽然官方说的是通过API接口调用不会存储和训练你传输的数据。但如果你的数据保密要求高,显然放在别人那里总归是不够踏实的。
-
模型训练数据。虽然现有的LLM在日常语言任务方面非常精通,但它们仍然是基于广泛、庞大的数据集进行训练,这些数据集可能与你的数据不重叠。一旦你想让模型根据你自己的数据或特定用例表现出特定的行为或回答特定问题,你就需要考虑拥有自己微调过的模型。
所以,为了避免这些问题,我们有一个选择,那就是运行我们自己完全可控制的LLM模型。我们可以决定什么被审查,我们可以根据我们自己公司非常特定的知识来决定如何回答特定问题。那怎么做呢?这就需要用到“迁移学习”的基础知识。它是一种使用已经预先训练、测试过的模型,并添加你特定需求到它们上面的技术。此外,我们还将演示如何使用迁移学习来微调我们的模型,使其表现出我们需要它表现出来的行为。别担心——我们不需要大量的数据——也可以使用较小的数据集。
总之,LLM虽然很厉害,但是成本和数据隐私问题确实需要我们思考。如果你想要更低成本地做LLM微调,并且保护好自己的数据隐私,那么自己训练LLM就是一个不错的选择!
二、什么是迁移学习?
迁移学习是一种利用预先训练好的机器学习模型来解决新问题的技术,通常涉及不同领域的原始模型训练。在迁移学习中,我们不从头开始训练新模型,而是使用预先训练好的模型作为起点,这样可以节省时间和资源。
大型语言模型(LLM)是最强大的预先训练好的模型之一,例如_GPT、BERT、MPT、XLNet_等。这些LLM在海量文本数据上进行训练,从中学习了很多关于语言的知识。然而,它们对于特定资源的了解相对较少。
微调一个预先训练好的LLM涉及将预先训练好的模型适应一个新的任务,通过在特定任务的数据集上进行训练。这包括使用反向传播来更新预先训练好的模型的参数。基本思想是,预先训练好的模型已经学习了很多关于语言结构和语义的知识,我们只需要对其进行微调,以适应我们感兴趣的特定领域或任务。
微调预先训练好的LLM通常包括三个主要步骤:
-
初始化预先训练好的模型 :首先,我们下载并初始化预先训练好的LLM。初始化模型涉及加载之前在大量文本语料上训练过的预先训练好的权重和架构。
-
微调预先训练好的LLM :接下来,我们使用较小的、特定任务的数据集来微调预先训练好的LLM,以适应特定任务。这涉及使用反向传播和梯度下降来更新预先训练好的LLM的权重,同时保持模型下层的权重固定。
-
评估微调后的LLM :最后,我们在测试集上评估微调后的LLM,以确定其在任务上的性能。
2.1、QLoRA:高效地微调LLM
通常,微调LLM是一个资源消耗较大的过程,需要进行许多参数调整。然而,开源社区已经开发出一种名为QLoRA的方法,它是一种高效的微调方法,可以减少内存使用量,并能够在单个48GB GPU上微调一个65B参数模型,同时保持完整的16位微调任务性能。
第一个使用QLoRA进行训练的模型家族是Guanaco模型,在Vicuna基准测试中超过了之前所有公开发布的模型,达到了与ChatGPT性能水平相当的99.3%,而只需要在单个GPU上进行24小时的微调。
与GPT模型训练所需的几个月和数百万美元的成本相比,QLoRA是一个胜利者。
因此,我们选择使用QLoRA微调技术。我们不会提供对QLoRA如何实现这些惊人结果的技术进行深入分析,而是更关注应用方面,找到如何利用它来实现我们自己的模型训练目标。
三、选择合适的基础模型
根据前面的讨论,我们不打算从头开始训练LLM模型,而是利用QLoRA微调方法来增强一个已有的泛化基础模型,使其具备我们自己的能力。
因此,我们需要选择一个可用的基础模型,有两个主要选择:
(1)、使用经过微调的GPT模型:由于GPT是目前表现最好的模型,并且OpenAI提供了强大的微调API,为什么不使用它作为基础呢?然而,正如前面提到的,由于隐私和成本的原因,我们目前不做考虑,如果大家有兴趣,可以点关注,后续会专门介绍针对OpenAI的模型做微调训练。
(2)、选择一个开源的LLM模型:除了商用模型的选择,其实开源社区一直在不断提供更优秀的模型。有数百个性能与GPT相当的开源模型。虽然目前还没有一个与GPT同样好的模型,但通过微调,我们可以轻松超越GPT的性能。
在这种情况下,我们需要选择一个性能良好的开源模型。Hugging Face是一个不错的选择。他们开发了流行的开源工具、库和模型,供NLP和AI爱好者使用。特别值得一提的是他们的Transformers库,它为目前所有可用的LLM提供了基础。此外,Hugging Face还建立了一个令人惊叹的、非常活跃的社区,多年来一直推动着机器学习和人工智能领域的创新。
Hugging Face方便地提供了当前最佳开源LLM模型的排行榜,您可以点击以下链接查看:
https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard
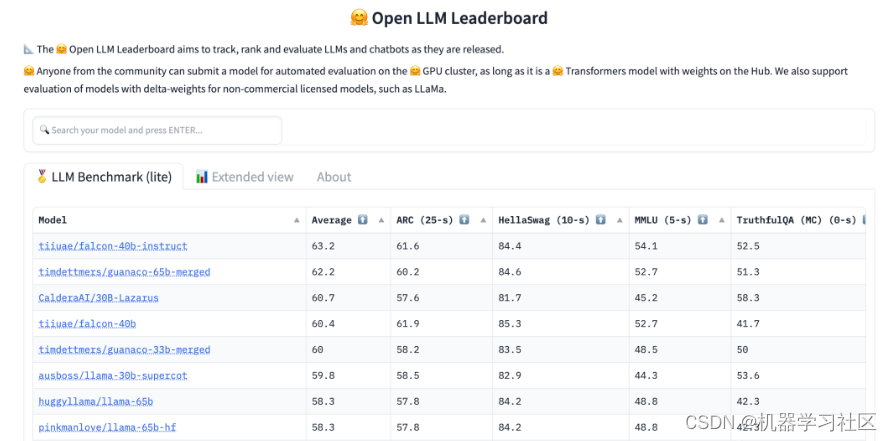
Hugging Face 的LLM排行榜提供了几个基准以及基准的平均值。以下是使用的不同基准:
-
ARC(AI推理挑战):包含7787个自然的、小学科学水平的问题,旨在评估模型的知识和推理能力。
-
HellaSwag:评估常识语言推断能力,模型得分越高,说明其更好地理解语言的含义和意图。
-
MMLU(大规模多任务语言理解能力):涵盖57个任务,包括初等数学、美国历史、计算机科学、法律等,要在这个测试中获得高准确率,模型必须具备广泛的世界知识和问题解决能力。
-
TruthfulQA:包含817个问题,涵盖38个类别,包括健康、法律、金融和政治等,用于判断模型输出的真实性。
根据您的具体任务,您可以按照任何一个基准对排行榜进行排序。例如,如果您需要处理许多推理类型的交互,那么ARC可能是一个不错的选择。
其实通常情况下,优秀的模型在所有基准上表现良好,并没有专门针对某个基准的模型。目前,通过简单地按照平均值排序,您几乎可以得到适用于任何用例的最佳模型。
除了以上的几个基准之外,还有三个因素需要考虑:
-
"指令"模型:例如 falcon-40b-instruct 模型,这些模型是专门为指令/聊天场景进行大量训练的,不适合进一步训练和微调。
-
模型大小:LLM模型由层和参数组成,参数越多,模型越复杂。较小的模型更容易进行微调,并且运行成本更低。根据经验法则,目前65亿参数的模型需要大约48GB或更多的GPU内存。出于经济原因,建议选择最小的能够满足您用例需求的模型。
-
许可证:与任何软件一样,我们需要注意可以做什么和不能做什么。要找到适用的许可证,请点击基准中的模型,并查找许可证部分。一般而言,Hugging Face上的模型可以用于研究目的。所有基于Llama的模型都禁止商业用途。而"falcon"模型家族是在宽松的Apache 2.0许可证下发布的,对于商业应用来说也是一个不错的起点。
3.1、模型选择的基本原则
-
使用hugging face排行榜并按平均基准结果排序。
-
排除任何"指导"模型。
-
检查模型的许可证以及它是否适合您的商业用例。
-
使用参数较少的模型,以便更容易地训练和降低成本。
虽然LLM模型排行榜每天都在变化,但截至目前,falcon模型依然还是开源模型中的最佳选择。它提供了两种大小(400亿和70亿),具备出色的基准结果,并且在Apache 2.0许可证下发布,这对于商业应用来说就非常友好了。更具体地说,由于它相对于其它同类的模型具有相当出色的性能,falcon-7b模型似乎是一个好的和经济合理的选择。
四、如何准备模型训练数据
现在我们已经选择好了基础模型,是时候选择训练数据进行训练了。这个步骤应该算是最复杂、最耗时、也是最重要的步骤了,因为我们提供给LLM的数据越好,我们得到的输出就越好。为了理解我们需要提供什么样的训练数据,首先需要了解模型训练的过程。
在非常高的层次上,模型训练涉及向现有的基础模型提供示例对话,包括问题和答案。然后,模型会学习并理解您希望参与的对话类型以及您期望它提供的答案类型和形式。
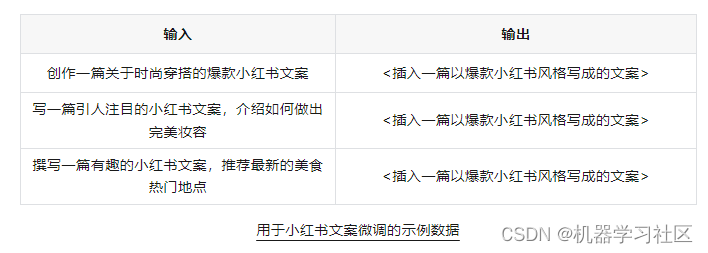
例如,如果您想让模型创建一种爆款小红书的文案风格,您需要提供用户问题和您认为正确输出的示例。
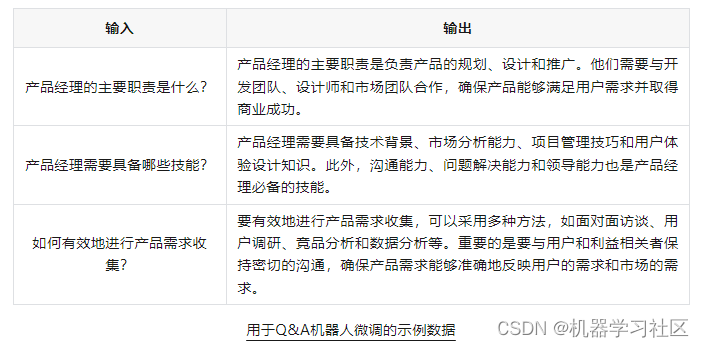
如果需要训练您的模型成为一个专家 Q&A 聊天机器人,提供用户问题和相应答案的示例。
4.1、应该准备多少组数据集示例?
数据集所需示例的数量没有一个非常通用的标准,但有一些经验可供参考。
-
对于较简单的任务,例如 FAQ 聊天机器人,通常 100 个示例已经足够好。
-
对于任务和输出更复杂的情况,就需要提供更多的示例。例如,如果你想改变模型的写作风格,比如总是鲁迅的风格写作,那么你可能需要提供数千个示例。
-
一般而言,示例越多越好,只要这些示例之间不重复。但也不要过度。对于许多任务来说,拥有数百个示例可能就足够了。
此外,你不需要提供所有可能的问题或交互,这几乎是不可能做到的,LLM 只需要能够“识别并理解”到你示例中的总体意图,并且为类似但不完全匹配的问题找到合适的答案即可。
4.2、如何创建数据集?
根据训练的任务,一般有几种方法可以考虑用于半自动地创建数据集。
1)、一种方法是创建一个 FAQ 聊天机器人的数据集。导出系统中最常见的问题以及客户支持团队提供的答案,并将其导出到 Excel 或 CSV 格式中。
2)、另一种方法是创建一个能够回答您知识库中大部分问题的模型。可以使用现有模型(如 GPT-4)来自动创建问题和答案。首先,将你的知识库分割成最多 3,000 个单词的块,然后将这些块发送给 GPT-3.5-16k,要求它根据这些文本块创建新用户可能提出的问题。最后,将所有输出合并以生成单个数据集。这个过程可以通过脚本高度自动化,只需几分钟即可生成数千个问题和答案。
3)、可能已经有一些预定义的数据集可用,它们可能对您的用例有用。Hugging Face Dataset Hub 是一个很好的起点,目前提供超过42000个数据集可供使用。你可以使用强大的过滤和搜索功能来查找适合您的数据集。
4.3、数据集需要遵循什么格式?
LLM的优势在于它们能够理解人类语言,而不受结构化数据的限制。因此,你的训练数据集不需要遵循特定的格式要求。但是,根据经验,最佳的做法是使用一个简单的两列数据集,其中一列是问题或提示,另一列是完美的答案,就像前一节中的例子一样。
选择这种格式的原因是它的简洁性,同时两列之间的分隔使我们能够将其格式化为后续训练步骤中可能需要的任何格式。这种灵活性使我们能够轻松地适应不同的数据处理和训练需求。
五、如何选择模型训练环境
在选择了基础模型和准备好训练数据集之后,我们需要选择一个执行模型训练过程的环境。
虽然我们可以在任何机器上进行模型训练,但高性能的 GPU 可以显著提高训练速度。一些现代的训练方法也需要 GPU 环境,因为在 CPU 上运行训练会非常耗时。因此,我们需要一个 GPU,具体来说,我们需要一款英伟达(NVIDIA)的 GPU。目前,英伟达的 CUDA 架构是最广泛使用的选项。尽管英特尔和 AMD 正在迎头赶上,但在未来几年内,我们仍然会受限于英伟达的选择。在选择 GPU 时,内存也是一个关键因素。
以下是几种不同规模的 GPU 选项:
-
小型 GPU,如 Nvidia’s RTX series 的 GPU,适合模型开发、测试和小规模项目部署,或者用于初期实验。它们通常具有小于 24GB 的内存。
-
中型 GPU,如 Nvidia A40 GPU,适用于中到大型项目。这些 GPU 在成本和计算能力之间提供了平衡,通常是大多数 LLM 训练任务的理想选择。它们具有约 48GB 的内存。
-
大型 GPU,如 Nvidia A100 GPU,非常适合大规模和内存密集型的训练任务,如 LLM 所需的训练。这些 GPU 价格昂贵,但在关键项目中加速训练速度往往是值得的。A100 旗舰型号提供了 80GB 的内存。
-
GPU 集群:如果以上选项仍然不够,现代训练框架允许并行地利用多个 GPU,从而可以加载和训练庞大的 LLM。
根据上述 GPU 选项列表,我们需要选择一个适应我们模型并且价格合理的 GPU。大多数模型并没有提供所需的训练内存大小,因此这是一个试错的过程。根据以往的经验,在使用 QLoRA 进行训练时:
-
70亿参数的模型可以在具有 12GB 内存的 GPU 上进行训练
-
300亿参数的模型适合在具有 24GB 内存的 GPU 上进行训练
-
650亿参数的模型可以在具有 48GB 内存的 GPU 上进行训练
具体如何选择,请根据你的训练需求和预算选择适合的 GPU。
5.1、具体在哪里获取这些 GPU?
要获取所需的 GPU,有几个选项,从免费到昂贵都有:
-
Google Colab:由 Google 提供,Colab 是一个运行 Jupyter Notebook 的平台。由于我们的模型训练将在 Python 中完成,因此这是一个不错的选择。Colab 提供了强大的硬件资源,免费用户可以获得带有 12GB RAM 的 NVIDIA T4 GPU,足以训练 7 亿参数的模型。如果需要更好的硬件和更多内存,可以选择付费计划,每月费用为 12 美元。请参考 Google 的 Colab GPU 指南,了解如何启用 GPU。
-
RunPod:RunPod 是一个按需提供多种 NVIDIA GPU 的服务商,以非常具有吸引力的每小时价格提供服务。启动一个支持 GPU 的虚拟机非常简单,并提供 SSH 访问权限、功能强大的 Web 控制台和预安装的 Jupyter 服务器。尽管无法与 Google Colab 的免费定价相比,但 RunPod 提供了相当低廉的 GPU 价格和易用性,是训练模型的理想选择。
-
云服务提供商:大型云服务提供商如 Azure、GCP 和 AWS 都提供 GPU 机器。请参考它们的虚拟机页面以获取更多详细信息。对于模型训练而言,它们相对于 Colab 和 RunPod 这样的解决方案稍显复杂,而且您可能不需要长时间运行机器。
-
自建服务器:最后一个选项是购买 GPU 并在家里或公司运行。虽然这可能需要一开始的大量投资(例如,NVIDIA RTX 3080 被认为是进行真正的 LLM 训练的最低要求,价格约为 1000 美元,而 A100 的价格约为 4000 美元),但如果您计划进行大量的训练操作,这可能是值得的。请注意,考虑到您是否真的需要全天候进行模型训练,RunPod 的价格可能会高达每月 1300 欧元。
对于大多数任务来说,训练过程通常只需要一两天的高性能 GPU。因此,在经济上,前面提到的解决方案通常更具优势。
本文我们将使用 Google Colab,因为我们要训练一个具有 70 亿参数的模型。然而,我们将使用 Colab Pro,因为我们需要超过 13GB 的系统内存(免费 Colab 的内存限制为 13GB)。
请记住,更大、更快的 GPU 可以加速训练和推理性能,所以如果预算允许,考虑使用其他方法。
六、开始训练你的LLM模型
前面的训练环境准备好之后,现在开始进行模型训练了。请确保您拥有一台至少具有 13GB GPU 内存的专用 GPU,并通过使用前面提到的任何一种方法来实现。
您还需要具备 16GB 系统内存,并且需要一个 Python 3.9+ 环境来运行训练代码步骤。
1)、首先,安装所需的依赖项。
pip install -qqq bitsandbytes
pip install -qqq datasets !pip install-qqq git+https://github.com/huggingface/transformers@de9255de27abfcae4a 1f816b904915f0b1e2
!pip install-qqq git+https://github.com/huggingface/peft.git !pip install -qqq git+https://github.com/huggingface/accelerate.git !pip install -qqq einops
!pip install -qqq scipy # 我们需要这个特定版本的transformers,因为当前的主分支存在一个bug,导致无法成功训练:
!pip install git+https://github.com/huggingface/transformers@de9255de27abfcae4a 1f816b904915f0b1e2
2)、导入所需的模块:
import bitsandbytes as bab
import torch
import torch.nn as nn
import transformers
from datasets import load_datasetfrom peft import LoraConfig, PeftConfig, postmedial, \
prepare_model_for_kbit_training, get_peft_model from transformers import AutoTokenizer, BitsAndBytesConfig, \ AutoModelForCausalLM
3)、初始化模型:
model_name = "tiiuae/falcon-7b"
bnb_config = BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) model = AutoModelForCausalLM.from_pretrained( model_name,trust_remote_code=True, quantization_config=bnb_config, device_map="auto"
)
-
model_name:要使用的模型名称。请参考 Hugging Face 获取确切的模型名称。
-
load_in_4bit:以 4 位量化模式加载模型,以便在有限的 GPU 内存下进行训练。使用 QLoRA 技术,我们不会损失模型性能。
-
bnb_4bit_quant_type:fp4 或 nf4 之一。这设置了量化数据类型。nf4 是 QLoRA 特定的浮点类型,称为 NormalFloat。
-
bnb_4bit_compute_dtype:这设置了计算类型,它可能与输入类型不同。例如,输入可能是 fp32,但计算可以设置为 bf16 来加速。对于 QLoRA 调优,请使用 bfloat16。
-
trust_remote_code:为了加载 falcon 模型,需要执行一些 falcon 模型特定的代码(使其适合 transformer 接口)。涉及到的代码是configuration_RW.py和modelling_RW.py。
-
device_map:定义将工作负载映射到哪个 GPU 设备上。设置为 auto 以最佳方式分配资源。
4)、初始化分词器(负责从提示和响应中创建令牌的对象):
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.pad_token = tokenizer.eos_token
AutoTokenizer:是一个Hugging Face Transformer Auto Class,它会根据模型架构自动创建正确的分词器实例
pad_token:一个特殊令牌,用于将令牌数组调整为相同大小以便进行批处理。设置为句子结束(eos)令牌。
5)、启用梯度检查点并调用准备方法:
model.gradient_checkpointing_enable()
model = prepare_model_for_kbit_training(model)
Gradient Checkpointing : 是一种用于在训练深度神经网络时减少内存占用的方法,代价是计算时间略有增加。更多细节可以在这里找到:
https://github.com/cybertronai/gradient-checkpointing
prepare_model_for_kbit_training:这个方法包装了在运行参数高效微调训练(QLoRA是这种训练范式的一种方法)之前准备模型的整个协议。
6)、初始化我们的LoRA训练配置:
config = LoraConfig( r=8, lora_alpha=32, target_modules=["query_key_value"], lora_dropout=0.05,bias="none",task_type="CAUSAL_LM"
)model = get_peft_model(model, config)
r, lora_alpha和lora_dropout是LoRA超参数。可以根据需要进行更改。对于 falcon 家族来说,上述参数通常是一个很好的起点。阅读Hugging Face QLoRA博客文章以了解更多细节。
task_type:描述语言建模类型,是因果的还是掩码的。对于像 GPT、LLama 或 Falcon 这样的 Transformer,它是因果的。更多细节请参考这里。
target_modules:变压器模型中应该用QLoRA进行训练的目标模块。根据这篇文章,实际上总是查询/键值模块。
6.1、加载数据集
接下来要做的是加载数据集。Hugging Face 的 datasets 模块提供了一个方便的方法 load_dataset,可以从本地路径或 Hugging Face 数据集中心加载数据集。该方法还将数据集拆分为特征,以供模型训练使用。
为了训练我们的模型,我将使用一个著名的电子商务 FAQ 数据集,其中包含关于一个假设的电子商务产品的信息。原始文件可以在这里找到:
https://www.kaggle.com/datasets/saadmakhdoom/ecommerce-faq-chatbot-dataset
我已经对文件进行了修改,以符合之前描述的问题/答案对数组的格式。该文件以 JSON 格式包含以下信息:
[{"question": "我应该怎么创建账号?","answer": "创建账号,在网站右上角点击[注册]按钮完成注册流程"
},...]
如果您想按照本示例进行操作,请从
https://datascienceengineer.com/datasets/ecommerce_faq.json 下载准备好的数据集。但您也可以使用自己的数据集,只要保持原始格式即可。
# 加载JSON文件并将其转换为训练特征
data = load_dataset("json", data_files="ecommerce_faq.json")
接下来,我们希望为我们的数据集添加一些提示格式。模型训练应该向模型展示在生产环境中可能看到的提示样式。因此,我们可能会得到以下内容:
:一些问题?
:LLM 的答案
为了实现这一点,我们用 “” 前缀标记我们的问题,用 “” 前缀标记我们的答案。
def generate_prompt(question_answer): return f"""
<human>: {question_answer["question"]}
<assistant>: {question_answer["answer"]} """.strip() def tokenize_prompt(question_answer):prompt = generate_prompt(question_answer)tokenized_prompt = tokenizer(prompt, padding=True, truncation=True) return tokenized_prompt # 使用 shuffle 来重新排序列表,以消除潜在的排序偏差
data_prompt = data["train"].shuffle().map(tokenize_prompt)
6.2、训练配置和执行
我们到了最后一步 - 配置训练器并运行模型训练。
下面的训练器对象参数是超参数,可以(也应该)根据需要进行更改以获得更好的结果。对于 falcon-7b 模型训练,下面的参数非常有用,我在各种数据集上都获得了良好的结果。但是,对于其他类型的模型,您可能需要调整这些参数以获得更好的结果。
请参考 Hugging Face Trainer API 文档了解更多细节:
https://huggingface.co/transformers/v3.0.2/main_classes/trainer.html
trainer = transformers.Trainer( model=model, train_dataset=data_prompt, args=transformers.TrainingArguments( per_device_train_batch_size=1,gradient_accumulation_steps=4, num_train_epochs=1, warmup_ratio=0.05, max_steps=80, learning_rate=2e-4, fp16=True,logging_steps=1, output_dir="outputs", optim="paged_adamw_8bit", lr_scheduler_type="cosine"
), data_collator=transformers.DataCollatorForLanguageModeling(tokenizer,
mlm=False),) model.config.use_cache = False trainer.train()
在调整模型参数的时候,注意不要修改这个参数 optim=“paged_adamw_8bit”,这是一种优化技术,可以避免内存峰值,从而防止 GPU 内存超载。
max_steps 参数不应该比你的训练数据集中的行数高太多。监控你的训练损失,以检查是否需要减少或增加这个值。
等待几分钟后,你的模型就成功训练好了!将你的模型保存在磁盘上,你就完成了!
model.save_pretrained("my-falcon")
参数(本例中为“my-falcon”)决定了你的模型文件将存储到哪个文件夹路径。
七、模型推理
现在我们已经创建并保存了我们的模型,接下来展示如何加载模型并对我们新训练的 LLM 模型进行查询。
首先,让我们加载配置并加载我们的模型:
# 从我们微调的模型中加载LoRA配置
lora_config = PeftConfig.from_pretrained('my-falcon') # 实例化一个Transformer模型类,根据我们的模型自动推断
my_model = AutoModelForCausalLM.from_pretrained( lora_config.base_model_name_or_path, return_dict=True,quantization_config=bnb_config, device_map="auto", trust_remote_code=True,load_in_8bit=True #这个设置可能会将量化减少到8位speed up inference and reduces memory footprint.
) tokenizer=AutoTokenizer.from_pretrained( lora_config.base_model_name_or_path)
tokenizer.pad_token=tokenizer.eos_token # 根据LoRA配置和权重实例化一个LoRA模型
my_model = PeftModel.from_pretrained(my_model, "my-falcon")
然后,让我们创建提示。请记住,我们专门训练了我们的 LLM 来使用 “/” 提示语法。因此,我们也可以将其添加到提示中。(这不是一个硬性要求,因为 LLM 大多能够自己找到 human/assistant 的角色。然而,由于我们在训练中包含了它,如果我们在提示中也包含它,性能可能会更好)。
prompt = f"""<human>: 我应该怎么创建账号?<assistant>:""".strip()
配置模型推理参数:
gen_conf=my_model.generation_config
gen_conf.temperature=0
gen_conf.top_p=0.7
gen_conf.max_new_tokens=200
gen_conf.num_return_sequences=1
gen_conf.pad_token_id=tokenizer.eos_token_id gen_conf.eos_token_id=tokenizer.eos_token_id
-
temperature: 介于 0 和 1 之间,用于决定模型输出的 “创造力”。值越高,对相似问题的回答越多样化。值越低,输出越确定性。
-
top_p: 介于 0 和 1 之间,用于决定考虑下一个输出 token 的数量。例如,如果设置为 0.5,则只考虑概率质量最高的 50% 的 token。
-
max_new_tokens: 输出应该生成多少个 token
-
num_return_sequences: 每个输入返回的序列候选数
接下来,使用我们的提示准备模型的输入,并将张量发送到推理设备。在此示例中,使用 “cuda:0” 进行 GPU 推理。
inputs = tokenizer(prompt, return_tensors="pt").to("cuda:0")
最后,让我们进行实际的推理:
with torch.inference_mode():
outputs = my_model.generate( input_ids=inputs.input_ids, attention_mask=inputs.attention_mask, generation_config=gen_conf, do_sample=False, use_cache=True
) print(tokenizer.decode(outputs[0], skip_special_tokens=True))
到此,您的模型将需要几秒钟来生成 token,它会利用您训练它时使用的微调数据。
八、总结
迁移学习和 QLoRA 框架为我们提供了强大的工具,可以高效地利用预训练的语言模型(LLM)来解决特定任务。通过根据基准评估选择合适的基础 LLM 模型,我们可以确保我们微调工作的最佳性能。
生成高质量的训练数据非常重要,因为它有助于捕捉目标任务特定的细微差别。我们已经了解到了应该遵循哪种格式,并且我们看到并不需要大量的数据 - 数百个左右就足够了。
使用 Hugging Face Transformer 和 PEFT 库,我们对基础 LLM 进行了微调,使其专门适应期望的任务。
最后,通过使用经过微调的 LLM 进行模型推理,我们能够部署一个强大的语言模型,在实际应用中进行准确的预测并生成有价值的洞察力。
相关文章:
开源 LLM 微调训练指南:如何打造属于自己的 LLM 模型
一、介绍 今天我们来聊一聊关于LLM的微调训练,LLM应该算是目前当之无愧的最有影响力的AI技术。尽管它只是一个语言模型,但它具备理解和生成人类语言的能力,非常厉害!它可以革新各个行业,包括自然语言处理、机器翻译、…...

Android hilt使用
一,添加依赖库 添加依赖库app build.gradle.kts implementation("com.google.dagger:hilt-android:2.49")annotationProcessor("com.google.dagger:hilt-android:2.49")annotationProcessor("com.google.dagger:hilt-compiler:2.49"…...
2023/12/17 初始化
普通变量(int,float,double变量)初始化: int a0; float b(0); double c0; 数组初始化: int arr[10]{0}; 指针初始化: 空指针 int *pnullptr; 被一个同类型的变量的地址初始化(赋值) int…...

【算法Hot100系列】三数之和
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

CSS 简介
什么是 CSS? CSS 是层叠样式表(Cascading Style Sheets)的缩写,是一种用来为结构化文档(如 HTML 文档或 XML 应用)添加样式(字体、间距和颜色等)的计算机语言。 CSS 的主要作用是: 控制网页的样式,如字体、颜色、背景、布局等提高网页的开发效率CSS 的语法 CSS 的…...

myBatis-plus自动填充插件
在 MyBatis-Plus 3.x 中,自动填充的插件方式发生了变化。现在推荐使用 MetaObjectHandler 接口的实现类来定义字段的填充逻辑。以下是使用 MyBatis-Plus 3.x 自动填充的基本步骤: 1.基本配置 1.1添加 Maven 依赖: 确保你的 Maven 依赖中使…...

746. 使用最小花费爬楼梯 --力扣 --JAVA
题目 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。 请你计算并返回达到楼梯顶部的最低花费。 解题思路 到…...

使用Verdaccio搭建私有npm仓库
搭建团队的私有仓库,保证团队组件的安全维护和私密性,是进阶前端开发主管路上,必不可少的一项技能。 一、原理 我们平时使用npm publish进行发布时,上传的仓库默认地址是npm,通过Verdaccio工具在本地新建一个仓库地址…...

87 GB 模型种子,GPT-4 缩小版,超越ChatGPT3.5,多平台在线体验
瞬间爆火的Mixtral 8x7B 大家好,我是老章 最近风头最盛的大模型当属Mistral AI 发布的Mixtral 8x7B了,火爆程度压过Google的Gemini。 缘起是MistralAI二话不说,直接在其推特账号上甩出了一个87GB的种子 随后Mixtral公布了模型的一些细节&am…...

Golang 数组 移除元素 双指针法 leetcode27 小记
文章目录 移除元素 leetcode27暴力解法双指针法1. 快慢指针2. 双向指针 移除元素 leetcode27 go中数据类型的分类: 1.值类型:int、float、bool、string、数组、结构体 2.引用类型:指针、切片、map、管道、接口 由于切片为引用类型,…...
)
c# OpenCV 图像裁剪、调整大小、旋转、透视(三)
图像裁剪、调整大小、旋转、透视图像处理基本操作。 croppedImage 图像裁剪Cv2.Resize() 调整图像大小图像旋转 Cv2.Rotate()旋转Cv2.Flip()翻转Cv2.WarpAffine()任意角度旋转Cv2.GetAffineTransform()透视 一、图像裁剪 // 读取原始图像 Mat image new Mat("1.png&q…...

Kafka相关知识
一、kafka架构 Kafka基础知识 Kafka是最初由Linkedin公司开发,是一个分布式、分区的、多副本的、多生产者、多订阅者,基于zookeeper协 调的分布式日志系统(也可以当做MQ系统),常见可以用于webynginx日志、访问日志,消息服务等等&…...
gitlab 通过svn hook 触发
jenkins 起一个item 配置: 我选的自由风格的 源码管理配置 先选subversion 就是svn类型 url 设置project 的路径, 注意是工程,不是svn 顶层 添加一个账户来进行pull 等操作 选择添加的账号 构建触发器: ,重要的是要自…...

设计模式详解---单例模式
1. 设计模式详解 单例模式是一种创建对象的设计模式,它确保一个类只有一个实例,并提供全局访问点以获取该实例。 在单例模式中,类负责创建自己的唯一实例,并确保任何其他对象只能访问该实例。这对于需要共享状态或资源的情况非常有…...
毕设之-Hlang后端架构-双系统交互
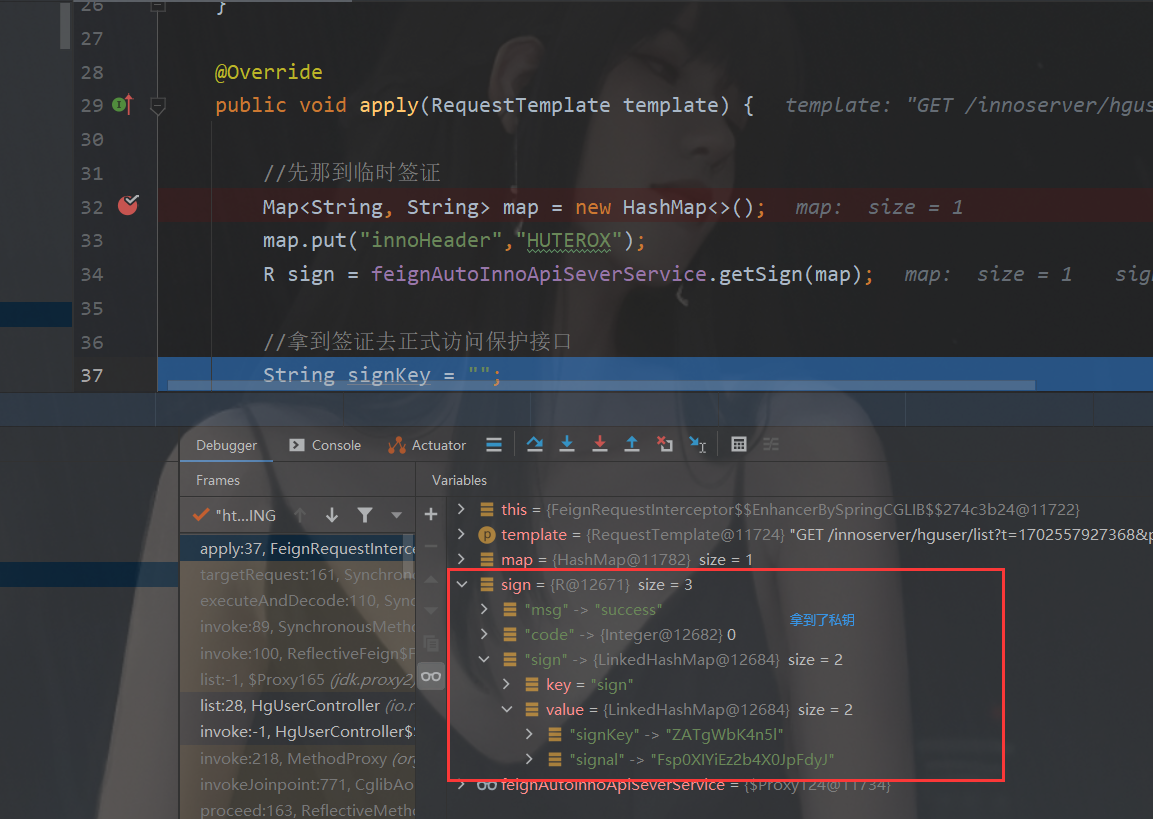
文章目录 前言交互流程基本流程约定公钥人人中台携带公钥获取私钥私钥生成人人中台携带私钥访问私钥验证(博客系统) 调试演示总结 前言 前天我们完成了基本的整合,但是还没有整合到我们的业务系统,也就是博客系统。本来昨天要搞一…...
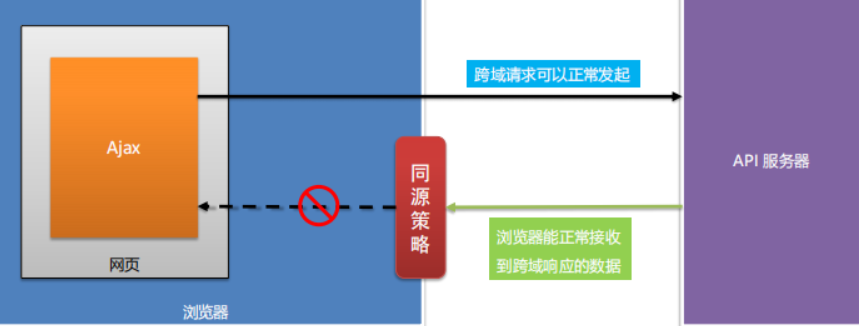
什么同源策略?
同源 同源指的是URL有相同的协议、主机名和端口号。 同源策略 同源策略指的是浏览器提供的安全功能,非同源的RUL之间不能进行资源交互 跨域 两个非同源之间要进行资源交互就是跨域。 浏览器对跨域请求的拦截 浏览器是允许跨域请求的,但是请求返回…...

破译模式:模式识别在计算机视觉中的作用
一、介绍 在当代数字领域,计算机视觉中的模式识别是关键的基石,推动着众多技术进步和应用。本文探讨了计算机视觉中模式识别的本质、方法、应用、挑战和未来趋势。通过使机器能够识别和解释视觉数据中的模式,模式识别不仅推动了计算机视觉领域…...

c语言-全局变量与局部变量
目录 1、(作用)域的概念 2、全局与局部的相对性 3、生命周期 3、静态变量static 结语: 前言: 在c语言中,全局变量的可见范围是整个工程,而局部变量的可见范围从该变量被定义到该作用域结束,…...

【Spring】00 入门指南
文章目录 1.简介2.概念1)控制反转(IoC)2)依赖注入(DI) 3.核心模块1)Spring Core2)Spring AOP3)Spring MVC4)Spring Data5)Spring Boot 4.编写 Hel…...

BIM 技术:CIM (City Information Modeling) 1-7 级
本心、输入输出、结果 文章目录 BIM 技术:CIM (City Information Modeling) 1-7 级前言城市信息模型(CIM)概述城市信息模型分级介绍CIM 1CIM 2CIM 3CIM 4CIM 5CIM 6CIM 7 花有重开日,人无再少年实践是检验真…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

云启出海,智联未来|阿里云网络「企业出海」系列客户沙龙上海站圆满落地
借阿里云中企出海大会的东风,以**「云启出海,智联未来|打造安全可靠的出海云网络引擎」为主题的阿里云企业出海客户沙龙云网络&安全专场于5.28日下午在上海顺利举办,现场吸引了来自携程、小红书、米哈游、哔哩哔哩、波克城市、…...

CMake基础:构建流程详解
目录 1.CMake构建过程的基本流程 2.CMake构建的具体步骤 2.1.创建构建目录 2.2.使用 CMake 生成构建文件 2.3.编译和构建 2.4.清理构建文件 2.5.重新配置和构建 3.跨平台构建示例 4.工具链与交叉编译 5.CMake构建后的项目结构解析 5.1.CMake构建后的目录结构 5.2.构…...

【JVM】- 内存结构
引言 JVM:Java Virtual Machine 定义:Java虚拟机,Java二进制字节码的运行环境好处: 一次编写,到处运行自动内存管理,垃圾回收的功能数组下标越界检查(会抛异常,不会覆盖到其他代码…...

对WWDC 2025 Keynote 内容的预测
借助我们以往对苹果公司发展路径的深入研究经验,以及大语言模型的分析能力,我们系统梳理了多年来苹果 WWDC 主题演讲的规律。在 WWDC 2025 即将揭幕之际,我们让 ChatGPT 对今年的 Keynote 内容进行了一个初步预测,聊作存档。等到明…...
)
GitHub 趋势日报 (2025年06月08日)
📊 由 TrendForge 系统生成 | 🌐 https://trendforge.devlive.org/ 🌐 本日报中的项目描述已自动翻译为中文 📈 今日获星趋势图 今日获星趋势图 884 cognee 566 dify 414 HumanSystemOptimization 414 omni-tools 321 note-gen …...

Swagger和OpenApi的前世今生
Swagger与OpenAPI的关系演进是API标准化进程中的重要篇章,二者共同塑造了现代RESTful API的开发范式。 本期就扒一扒其技术演进的关键节点与核心逻辑: 🔄 一、起源与初创期:Swagger的诞生(2010-2014) 核心…...
安装docker)
Linux离线(zip方式)安装docker
目录 基础信息操作系统信息docker信息 安装实例安装步骤示例 遇到的问题问题1:修改默认工作路径启动失败问题2 找不到对应组 基础信息 操作系统信息 OS版本:CentOS 7 64位 内核版本:3.10.0 相关命令: uname -rcat /etc/os-rele…...