[Kafka 常见面试题]如何保证消息的不重复不丢失
文章目录
- Kafka
- 1. Kafka如何保证不丢失消息?
- 生产者数据的不丢失
- 消费者数据的不丢失
- Kafka集群中的broker的数据不丢失
- 2. Kafka中的消息是否会丢失和重复消费?
- 1. 消息发送
- 2. 消息消费
- 3. Kafka 的设计是什么样的呢?
- 4. 数据传输的事务定义有哪三种
- 5. Kafka 怎么判断一个节点存活
- 6. 生产者是否直接将数据发送到 broker 的 leader (主节点)
- 7. Kafka 消费者是否可以消费指定分区消息?
- 8. Kafka 消息是采用 Pull 模式,还是 Push 模式?
- 9. Kafka 存储在硬盘上的消息格式是什么? (存疑)
- 10. 介绍一下kafka 的 ack 机制
- 11. Kafka 的消费者如何消费数据
Kafka
1. Kafka如何保证不丢失消息?
生产者数据的不丢失
- 如果是同步模式:
ack机制能够保证数据的不丢失,如果ack设置为0,风险很大,一般不建议设置为0。即使设置为1,也会随着leader宕机丢失数据。
producer.type=sync
request.required.acks=1
- 如果是异步模式:
也会考虑ack的状态,除此之外,异步模式下的有个buffer,通过buffer来进行控制数据的发送,有两个值来进行控制,时间阈值与消息的数量阈值,如果buffer满了数据还没有发送出去,有个选项是配置是否立即清空buffer。可以设置为-1,永久阻塞,也就数据不再生产。异步模式下,即使设置为-1。也可能因为程序员的不科学操作,操作数据丢失,比如kill -9,但这是特别的例外情况。
producer.type=async
request.required.acks=1
queue.buffering.max.ms=5000
queue.buffering.max.messages=10000
queue.enqueue.timeout.ms = -1
batch.num.messages=200
结论:producer有丢数据的可能,但是可以通过配置保证消息的不丢失。
消费者数据的不丢失
通过 offset commit 来保证数据的不丢失,Kafka自己记录了每次消费的offset数值,下次继续消费的时候,会接着上次的offset进行消费。
而offset的信息在Kafka0.8版本之前保存在Zookeeper中,在0.8版本之后保存到topic中,即使消费者在运行过程中挂掉了,再次启动的时候会找到offset的值,找到之前消费消息的位置,接着消费,由于 offset的信息写入的时候并不是每条消息消费完成后都写入的,所以这种情况有可能会造成重复消费,但是不会丢失消息。
唯一例外的情况是,我们在程序中给原本做不同功能的两个consumer组设置
Kafka SpoutConfig.bulider.setGroupid的时候设置成了一样的 groupid,这种情况会导致这两个组共享同一份数据,就会产生组A消费 partition1,partition2 中的消息,组B消费 partition3 的消息,这样每个组消费的消息都会丢失,都是不完整的。 为了保证每个组都独享一份消息数据,groupid一定不要重复才行。
Kafka集群中的broker的数据不丢失
每个broker中的partition我们一般都会设置有replication(副本)的个数,生产者写入的时候首先根据分发策略(有partition按partition,有key按key,都没有轮询)写入到leader中,follower(副本)再跟leader同步数据,这样有了备份,也可以保证消息数据的不丢失。
2. Kafka中的消息是否会丢失和重复消费?
要确定Kafka的消息是否丢失或重复,从两个方面分析入手:消息发送和消息消费。
1. 消息发送
Kafka消息发送有两种方式:同步(sync)和异步(async),默认是同步方式,可通过 producer.type属性进行配置。
Kafka通过配置 request.required.acks属性来确认消息的生产:
0---表示不进行消息接收是否成功的确认;
1---表示当Leader接收成功时确认;
-1---表示Leader和Follower都接收成功时确认;
综上所述,有6种消息生产的情况,下面分情况来分析消息丢失的场景:
(1) acks=0,不和 Kafka 集群进行消息接收确认,则当网络异常、缓冲区满了等情况时,消息可能丢失;
(2) acks=1、同步模式下,只有Leader确认接收成功后但挂掉了,副本没有同步,数据可能丢失;
2. 消息消费
Kafka 消息消费有两个 consumer 接口,Low-level API 和 High-level API:
Low-level API:消费者自己维护 offset 等值,可以实现对 Kafka 的完全控制;
High-level API:封装了对 parition 和 offset 的管理,使用简单;
如果使用高级接口High-level API,可能存在一个问题就是当消息消费者从集群中把消息取出来、并提交了新的消息offset值后,还没来得及消费就挂掉了,那么下次再消费时之前没消费成功的消息就“ 诡异”的消失了;
解决办法:
针对消息丢失:
同步模式下,确认机制设置为-1,即让消息写入Leader和Follower之后再确认消息发送成功;
异步模式下,为防止缓冲区满,可以在配置文件设置不限制阻塞超时时间,当缓冲区满时让生产者一直处于阻塞状态;
针对消息重复:将消息的唯一标识保存到外部介质中,每次消费时判断是否处理过即可。
消息重复消费及解决参考: 如何保证消息不被重复消费?(如何保证消息消费时的幂等性)-Java知音
消息的重复消费问题,需要考虑幂等性,如果消费类型天生幂等,那么就没有必要去考虑重复消费的问题。
但是一般上 MQ 的任务都是一些比较耗时的任务,比如说调用第三方服务,此时可以采用第三方记录(redis),保存消息的唯一 id,定义消息的唯一id 以及时间戳的消费类型(待处理,过程中,失败/完成),如果是消费过程丢失,会导致消息长时间处于待处理的状态,我们可以另起一个定时任务,轮询一定时间间隔的任务,将它生产到兜底服务,由兜底服务去判断是否需要再次消费(比如说,一个 sms 服务,可以去查询当前消息 id 的短信是否已经成功发出,如果成功发出,则标记当前任务成功消费。)
3. Kafka 的设计是什么样的呢?
Kafka 将消息以主题为单位进行归纳。
- 将向 Kafka 主题发布消息的程序称为生产者。
- 将预订主题并消费消息的程序成为消费者。
- Kafka 以集群的方式运行,可以由一个或多个服务组成,每个服务叫做一个 broker(中间人)。
- 生产者通过网络将消息发送到 Kafka 集群,集群向消费者提供消息
4. 数据传输的事务定义有哪三种
- 最多一次: 消息不会被重复发送,最多被传输一次,但也有可能一次不传输;
- 最少一次: 消息不会被漏发送,最少被传输一次,但也有可能被重复传输;
- 精确的一次(Exactly once): 不会漏传输也不会重复传输,每个消息都传输被一次而且仅仅被传输一次,这是大家所期望的。
5. Kafka 怎么判断一个节点存活
主要有两个条件
- 必须可以维护和 ZooKeeper 的连接,ZooKeeper 通过心跳机制检查每个节点的连接;
- 如果节点是个 follower,他必须能及时的同步 leader 的写操作,延时不能太久。
6. 生产者是否直接将数据发送到 broker 的 leader (主节点)
生产者直接将数据发送到 broker 的 leader(主节点),不需要在多个节点进行分发,为了 帮助 producer 做到这点,所有的 Kafka 节点都可以及时的告知,哪些节点是活动的,目标 topic 目标分区的 leader 在哪。这样 producer 就可以直接将消息发送到目的地了。
7. Kafka 消费者是否可以消费指定分区消息?
Kafka 消费消息时,向 broker 发出 “fetch” 请求去消费特定分区的消息,同时,consumer 还指定消息在日志中的偏移量(offset),这样就可以消费从这个位置开始的消息。
消费者拥有 了 offset 的控制权,可以向后回滚去重新消费之前的消息,这是很有意义的。
8. Kafka 消息是采用 Pull 模式,还是 Push 模式?
Kafka 遵循了一种大部分消息系统共同的传统 的设计:producer 将消息推送到 broker,consumer 从 broker 拉取消息 。
9. Kafka 存储在硬盘上的消息格式是什么? (存疑)
消息由一个固定长度的头部和可变长度的字节数组组成。头部包含了一个版本号和 CRC32 校验码。
- 版本号: 1 byte
- CRC 校验码: 4 bytes
- 具体的消息: n bytes
10. 介绍一下kafka 的 ack 机制
在Kafka发送数据的时候,每次发送消息都会有一个确认反馈机制,确保消息正常被收到。
可以通过设置request.required.acks 决定 ack 策略。
0: 生产者不会等待 broker 的 ack,这个延迟最低但是存储的保证最弱。当 server 挂掉的时候就会丢数据;1:服务端会等待 ack 值。leader 副本确认接收到消息后发送 ack 。如果 leader 挂掉后,不确保是否复制完成,也就是说新 leader 可能会丢失数据;-1:同样在 1 的基础上,服务端会等所有的 follower 的副本收到数据后, leader 才会发出 的 ack,这样数据就不会丢失。
11. Kafka 的消费者如何消费数据
消费者每次消费数据的时候,都会记录消费的物理偏移量(offset), 等到下次消费时,他会接着上次位置继续消费 。
相关文章:

[Kafka 常见面试题]如何保证消息的不重复不丢失
文章目录 Kafka1. Kafka如何保证不丢失消息?生产者数据的不丢失消费者数据的不丢失Kafka集群中的broker的数据不丢失 2. Kafka中的消息是否会丢失和重复消费?1. 消息发送2. 消息消费 3. Kafka 的设计是什么样的呢?4. 数据传输的事务定义有哪三…...
用法)
Java中System.setProperty()用法
Java中System.setProperty()用法 大家好,我是免费搭建查券返利机器人赚佣金就用微赚淘客系统3.0的小编,也是冬天不穿秋裤,天冷也要风度的程序猿!今天,让我们一起深入了解Java中的System.setProperty()方法,…...
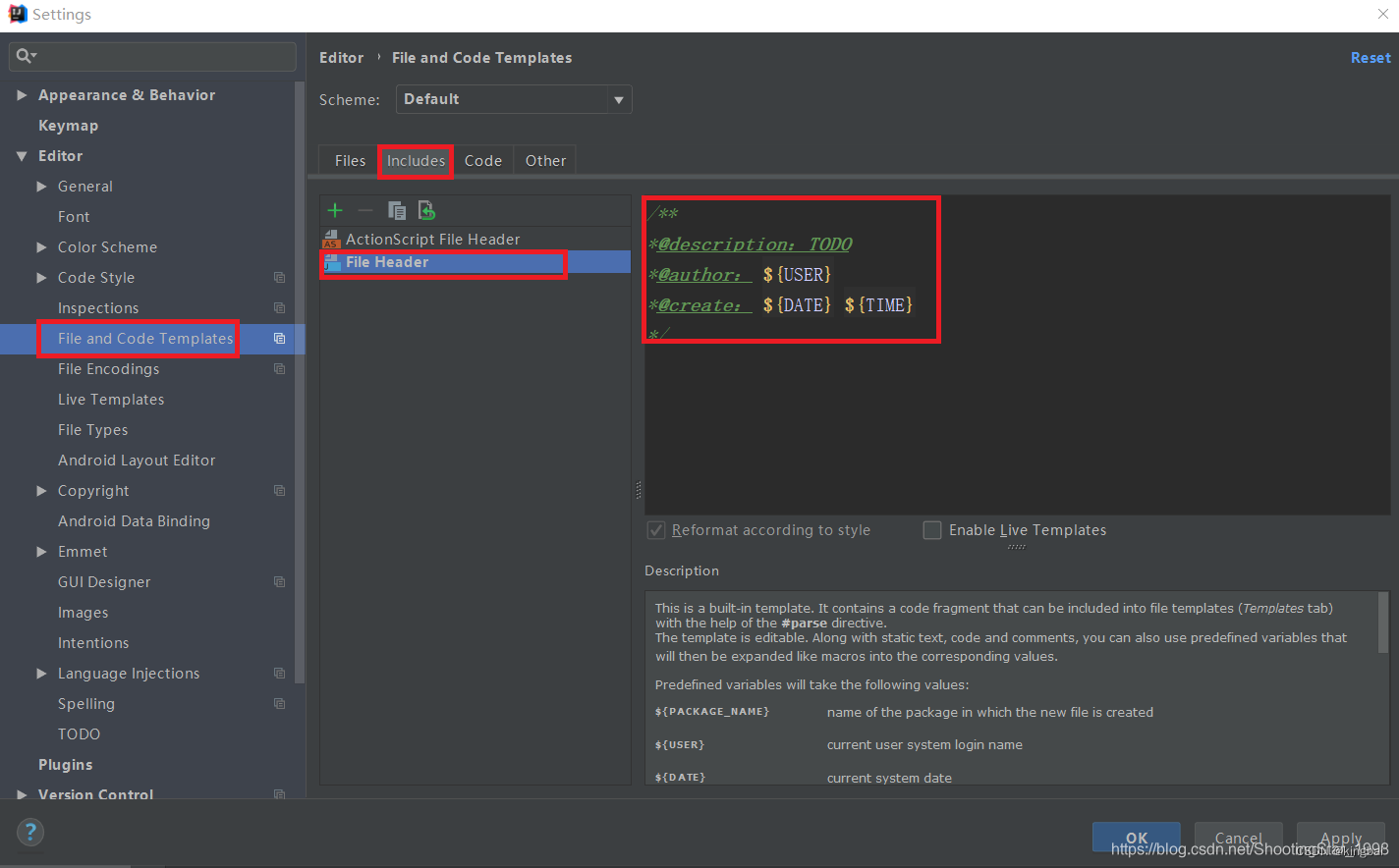
Eclipse 自动生成注解,如果是IDEA可以参考编译器自带模版进行修改
IDEA添加自动注解 左上角选择 File -> Settings -> Editor -> File and Code Templates; 1、添加class文件自动注解: /*** <b>Function: </b> todo* program: ${NAME}* Package: ${PACKAGE_NAME}* author: Jerry* date: ${YEA…...

微信小程序vant安装使用过程中遇到无法构建npm的问题
官网地址,然而如果完全按照这个教程来,实际上是缺少步骤的,需要补充一些步骤(参考https://www.bilibili.com/video/BV1vL41127Er) # 这步init就是补充的 npm init npm i vant/weapp -S --production# 剩下的按照vant的…...

[python]用python获取EXCEL文件内容并保存到DBC
目录 关键词平台说明背景所需库实现过程方法1.1.安装相关库2.代码实现 关键词 python、excel、DBC、openpyxl 平台说明 项目Valuepython版本3.6 背景 在搭建自动化测试平台的时候经常会提取DBC文件中的信息并保存为excel或者其他文件格式,用于自动化测试。本文…...

Spring Boot 如何配置 log4j2
Log4j2 介绍 Spring Boot 中默认使用 Logback 作为日志框架,接下来我们将学习如何在 Spring Boot 中集成与配置 Log4j2。在配置之前,我们需要知道的是 Log4j2 是 Log4j 的升级版,它在 Log4j 的基础上做了诸多改进: 异步日志&…...

如何安装docker
安装Docker的步骤取决于您使用的操作系统。以下是常见操作系统上安装Docker的基本步骤: 对于Linux: 更新软件包索引: sudo apt-get update安装允许apt通过HTTPS使用仓库的包: sudo apt-get install apt-transport-https ca-certificates cur…...

Linux 之 性能优化
uptime $ uptime -p up 1 week, 1 day, 21 hours, 27 minutes$ uptime12:04:11 up 8 days, 21:27, 1 user, load average: 0.54, 0.32, 0.23“12:04:11” 表示当前时间“up 8 days, 21:27,” 表示运行了多长时间“load average: 0.54, 0.32, 0.23”“1 user” 表示 正在登录…...
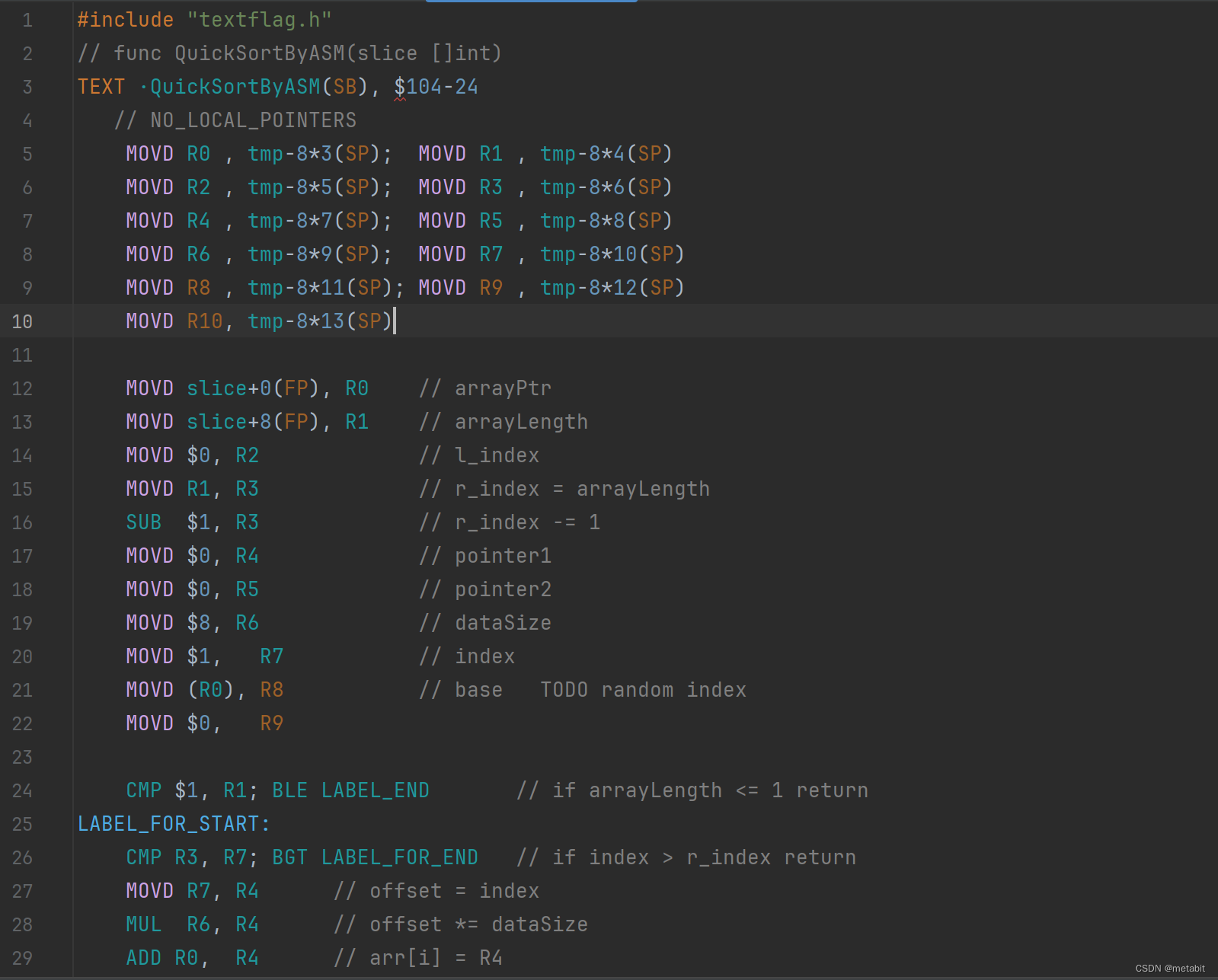
用Go汇编实现一个快速排序算法
本代码全网首发,使用Go plan9 windows arm64汇编,实现基础版快速排序算法。 未引入随机因子的快速排序的普通Go代码长这样。 func QuickSort(arr []int) {if len(arr) < 1 {return}base, l, r : arr[0], 0, len(arr)-1for i : 1; i < r; {if arr…...

Spring-整合MyBatis
依赖 <dependencies><!--提供数据源--><dependency><groupId>org.springframework</groupId><artifactId>spring-jdbc</artifactId><version>5.1.9.RELEASE</version></dependency><!--提供sqlSessionFactory…...
sql宽字节注入
magic_quotes_gpc(魔术引号开关) https://www.cnblogs.com/timelesszhuang/p/3726736.html magic_quotes_gpc函数在php中的作用是判断解析用户提交的数据,如包括有:post、get、cookie过来的数据增加转义字符“\”,以…...
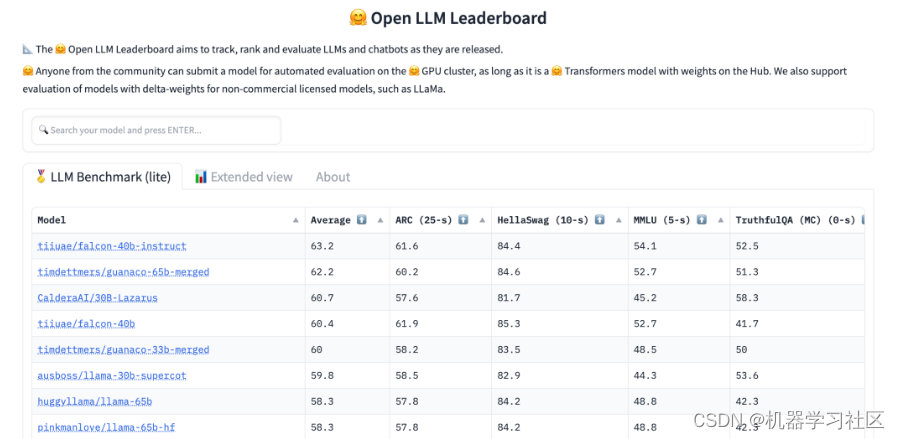
开源 LLM 微调训练指南:如何打造属于自己的 LLM 模型
一、介绍 今天我们来聊一聊关于LLM的微调训练,LLM应该算是目前当之无愧的最有影响力的AI技术。尽管它只是一个语言模型,但它具备理解和生成人类语言的能力,非常厉害!它可以革新各个行业,包括自然语言处理、机器翻译、…...

Android hilt使用
一,添加依赖库 添加依赖库app build.gradle.kts implementation("com.google.dagger:hilt-android:2.49")annotationProcessor("com.google.dagger:hilt-android:2.49")annotationProcessor("com.google.dagger:hilt-compiler:2.49"…...
2023/12/17 初始化
普通变量(int,float,double变量)初始化: int a0; float b(0); double c0; 数组初始化: int arr[10]{0}; 指针初始化: 空指针 int *pnullptr; 被一个同类型的变量的地址初始化(赋值) int…...

【算法Hot100系列】三数之和
💝💝💝欢迎来到我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。 推荐:kwan 的首页,持续学…...

CSS 简介
什么是 CSS? CSS 是层叠样式表(Cascading Style Sheets)的缩写,是一种用来为结构化文档(如 HTML 文档或 XML 应用)添加样式(字体、间距和颜色等)的计算机语言。 CSS 的主要作用是: 控制网页的样式,如字体、颜色、背景、布局等提高网页的开发效率CSS 的语法 CSS 的…...

myBatis-plus自动填充插件
在 MyBatis-Plus 3.x 中,自动填充的插件方式发生了变化。现在推荐使用 MetaObjectHandler 接口的实现类来定义字段的填充逻辑。以下是使用 MyBatis-Plus 3.x 自动填充的基本步骤: 1.基本配置 1.1添加 Maven 依赖: 确保你的 Maven 依赖中使…...

746. 使用最小花费爬楼梯 --力扣 --JAVA
题目 给你一个整数数组 cost ,其中 cost[i] 是从楼梯第 i 个台阶向上爬需要支付的费用。一旦你支付此费用,即可选择向上爬一个或者两个台阶。 你可以选择从下标为 0 或下标为 1 的台阶开始爬楼梯。 请你计算并返回达到楼梯顶部的最低花费。 解题思路 到…...

使用Verdaccio搭建私有npm仓库
搭建团队的私有仓库,保证团队组件的安全维护和私密性,是进阶前端开发主管路上,必不可少的一项技能。 一、原理 我们平时使用npm publish进行发布时,上传的仓库默认地址是npm,通过Verdaccio工具在本地新建一个仓库地址…...

87 GB 模型种子,GPT-4 缩小版,超越ChatGPT3.5,多平台在线体验
瞬间爆火的Mixtral 8x7B 大家好,我是老章 最近风头最盛的大模型当属Mistral AI 发布的Mixtral 8x7B了,火爆程度压过Google的Gemini。 缘起是MistralAI二话不说,直接在其推特账号上甩出了一个87GB的种子 随后Mixtral公布了模型的一些细节&am…...

GLM-OCR入门教程:3步完成Ubuntu20.04环境部署与首次调用
GLM-OCR入门教程:3步完成Ubuntu20.04环境部署与首次调用 你是不是也遇到过这种情况:手头有一堆图片,里面全是文字信息,比如扫描的文档、截图的聊天记录,或者拍下来的白板内容。一个个手动敲键盘录入?太费时…...

避开这3个坑!用nRF Connect调试BLE信标时90%人会犯的错误
避开这3个坑!用nRF Connect调试BLE信标时90%人会犯的错误 在物联网和智能硬件的开发中,BLE信标技术已经成为室内定位、近场交互的核心组件。作为开发者,我们经常使用nRF Connect这样的专业工具来分析和调试信标设备,但在这个过程中…...

Qwen-Image-Edit超分辨率实战:快速修复模糊人像,效果实测
Qwen-Image-Edit超分辨率实战:快速修复模糊人像,效果实测 1. 引言:模糊照片的救星 你是否遇到过这样的困扰?手机里珍藏的老照片变得模糊不清,或是抓拍的精彩瞬间因为对焦不准而失去了细节。传统修图软件往往难以真正…...

丹青幻境部署教程:从Docker镜像拉取到本地模型路径映射的完整操作链
丹青幻境部署教程:从Docker镜像拉取到本地模型路径映射的完整操作链 1. 环境准备与快速部署 在开始部署丹青幻境之前,请确保您的系统满足以下基本要求: 操作系统:Ubuntu 20.04 或 CentOS 8(推荐Ubuntu)D…...

小白也能懂的GME多模态向量使用指南:图文联合搜索,理解更精准
小白也能懂的GME多模态向量使用指南:图文联合搜索,理解更精准 1. 什么是GME多模态向量? 想象一下,你正在整理手机里的照片。有些照片你记得很清楚内容,但就是找不到关键词来描述;有些截图里的文字很重要&…...
AudioSeal Pixel Studio代码实例:Python调用PyTorch实现水印生成与识别
AudioSeal Pixel Studio代码实例:Python调用PyTorch实现水印生成与识别 1. 音频水印技术概述 音频数字水印技术是一种将特定信息嵌入到音频信号中的技术,这些信息对人类听觉系统几乎不可感知,但可以通过专用算法检测提取。AudioSeal是Meta(…...
的工作原理与最佳实践)
深入解析Java中ForkJoinPool.commonPool()的工作原理与最佳实践
1. 从两个常见问题说起:你的并行任务到底在哪个池子里跑? 很多朋友刚开始用Java 8的并行流(parallelStream)或者CompletableFuture做异步编程时,心里都会犯嘀咕:我写的这些并行任务,背后到底是谁…...

CAN总线安全新思路:为什么说VoltageIDS的电气特性检测比传统方案更靠谱?
CAN总线安全新思路:VoltageIDS如何通过电气特性检测重塑车载安全 在汽车电子系统日益复杂的今天,CAN总线作为连接各个电子控制单元(ECU)的神经系统,其安全性直接关系到整车功能的可靠性。传统基于协议分析和行为模式的入侵检测系统(IDS)正面临…...

数字孪生如何助力智慧工厂建设?
随着制造业不断迈向数字化与智能化,传统工厂的生产管理模式正在经历深刻变化。生产设备数量不断增加、生产流程愈发复杂,产品质量、效率与成本之间的平衡也变得更加关键。仅依赖人工经验或分散的信息系统,已经难以全面掌握生产运行情况。在这…...

第一篇:从零搭建 Spring Boot 3 + Dubbo 3 + ZooKeeper 微服务实战
技术栈速览组件版本说明Spring Boot3.2.6基础框架Apache Dubbo3.3.4RPC 框架ZooKeeper3.9.2注册中心(Docker 部署)Curator5.xZK 客户端(由 Starter 管理)JDK17Spring Boot 3 最低要求项目目录结构先把整体结构了然于胸,…...