爬虫 scrapy ——scrapy shell调试及下载当当网数据(十一)
目录
一、scrapy shell
1.什么是scrapy shell?
2.安装 ipython
3.使用scrapy shell
二、当当网案例
1.在items.py中定义数据结构
2.在dang.py中解析数据
3.使用pipeline保存
4.多条管道的使用
5.多页下载
参考
一、scrapy shell
1.什么是scrapy shell?
什么是scrapy shell?
scrapy终端,是一个交互终端,供您在未启动spider的情况下尝试及调试您的爬取代码。其本意是用来测试提取数据的代码,不过您可以将其作为正常的python终端,在上面测任何的python代码。该终端是用来测试Xpath或css表达式,查看他们的工作方式及从爬取的网页中提取的数据。在编写您的spider时,一旦熟悉了scrapy终端后,您会发现其在开发和调试spider时发挥的最大作用。
2.安装 ipython
安装ipython
pip install ipython
安装ipython后,scrapy终端将使用ipython代替python终端,ipython终端与其他相比更为强大,提供智能的自动补全,高亮输出及其他特性。
3.使用scrapy shell
在终端输入以下命令
scrapy shell 域名
eg:scrapy shell www.baidu.com
输出:进入到ipython
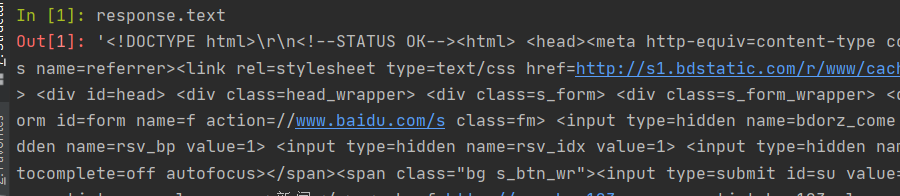
以上命令返回了一个response,可以直接使用
如下所示:可以调试返回的结果


二、当当网案例
目标:爬取当当网目标图书类目的所有图片、书名和价格,实现三者并行下载。
1.在items.py中定义数据结构
定义要获取的图片、书名和价格
class Scrapy095Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 通俗地讲就是你下载的数据都有什么# 爬取图片img = scrapy.Field()# 爬取书名name = scrapy.Field()# 爬取价格price = scrapy.Field()pass2.在dang.py中解析数据
同时下载书名、图片和价格,找到三者共在的标签 ‘ul’

定位Xpath路径,我们之前是这样写的,获取了每个内容的列表,但是我们想要的是书名、图片和价格相对应的结果。
# 找到三者共同所在的标签
img = response.xpath('//ul[@id="component_59"]/li//img/@src')
name = response.xpath('//ul[@id="component_59"]/li//img/@alt')
response.xpath('//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()')所以我们现在这样写:
调用selector下的Xpath,可以同时获取一个 li 中的三个内容。
# 所有selector对象可以在此调用 Xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:img = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(img,name,price)这样就获取到了。

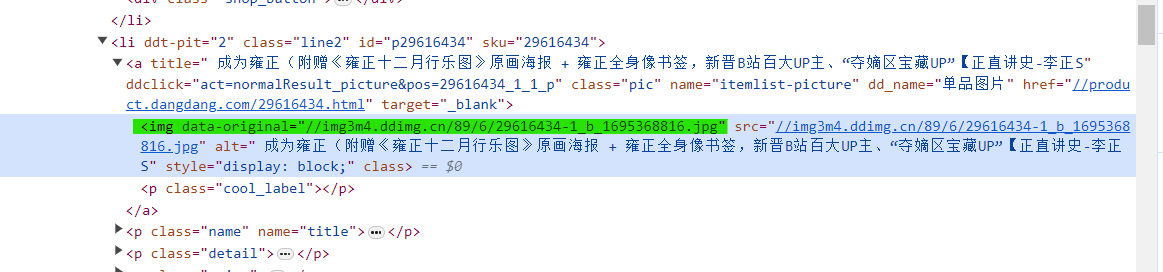
但是发现,图片全都为 “none”,这是因为网页的懒加载造成的,避免网页一下子加载太多数据。
所以我们要找到真正的图片链接,即 ‘data-original’,而不是‘src’。
然后我们修改路径,得到下面结果。

又发现了问题,我们并没有拿到第一个数据的链接,因为第一个数据没有‘data-original’属性。
修改为以下代码
# 所有selector对象可以在此调用 Xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:# 第一章图片的链接在 src 里# 其余图片的链接在 data-original 里img = li.xpath('.//img/@data-original').extract_first()if img:img = imgelse:img = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(img,name,price)这样我们就获取到了所有数据

3.使用pipeline保存
将数据交给 pipeline,添加最后两行代码。
调用 items.py 中的 Scrapy095Item 类。其中img=,name=和price=为 items.py中定义的变量。
# 所有selector对象可以在此调用 Xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li')
for li in li_list:# 第一章图片的链接在 src 里# 其余图片的链接在 data-original 里img = li.xpath('.//img/@data-original').extract_first()if img:img = imgelse:img = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(img,name,price)book = Scrapy095Item(img=img,name=name,price=price)# 将 book 交给 pipeline 下载yield book什么是yield?
带有yield的函数可以视作一个生成器generator,可用于迭代。yield是一个类似于return的关键字,迭代一个遇到yield时就返回yield后面的值。重点是:下一次迭代时,从上一次迭代遇到的yield后面的代码开始执行。
也就是说,yield会不断把book传递给pipeline。
如果要使用管道的话,就要在 settings.py 中开启管道,解开注释。

在 pipelines.py 中保存数据
# 如果要使用管道的话,就要在 settings.py 中开启管道
class Scrapy095Pipeline:# item 就是 yield 的返回值def process_item(self, item, spider):# 保存数据with open('book.json','a', encoding='utf-8') as file:# 存在的问题# item 是一个对象,需要将其转换为 str# 写文件的方式要改为 ‘a’ 追加模式,而不是 ‘w’覆盖模式。file.write(str(item))return item需要注意的是:
item 是一个对象,需要将其转换为 str
写文件的方式要改为 ‘a’ 追加模式,而不是 ‘w’覆盖模式。
这样就把内容保存下载来了
但是这样写文件的缺点是,写数据时需要频繁的打开关闭文件,对文件的操作过于频繁。
所以我们只要打开并关闭一次文件
定义两个函数 open_spider 和 close_spider ,这两个函数是 scrapy的内置函数,可以操作文件只打开或者关闭一次。
# 如果要使用管道的话,就要在 settings.py 中开启管道
class Scrapy095Pipeline:# 在爬虫文件开始之前就执行的一个文件def open_spider(self, spider):print('++++++++++++++++++++++++++')self.fp = open('book.json','w',encoding='utf-8')# item 就是 yield 的返回值def process_item(self, item, spider):# 我们不这样保存# # 保存数据# with open('book.json','a', encoding='utf-8') as file:# # 存在的问题# # item 是一个对象,需要将其转换为 str# # 写文件的方式要改为 ‘a’ 追加模式,而不是 ‘w’覆盖模式。# file.write(str(item))self.fp.write(str(item))return item# 在爬虫文件执行完之后再执行的方法def close_spider(self, spider):print('----------------------')self.fp.close()4.多条管道的使用
在 pipelines.py 中添加一个类,模仿上一个类写,用来下载图片,注意,这个类中定义的方法要与上一个类相同,然后我们在这个类中写下载图片的代码,最后返回 item
import urllib.request
# 多条管道开启
# (1)定义管道类
# (2)在settings中开启管道
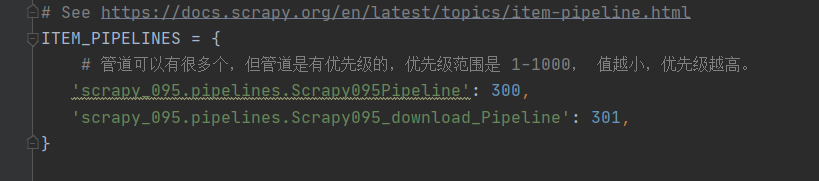
class Scrapy095_download_Pipeline:def process_item(self, item, spider):url = 'http:' + item.get('img')filename = './books/' + item.get('name') + '.jpg'urllib.request.urlretrieve(url=url, filename=filename)return item重要的是,我们要为下图片创建一个新管道,才能实现JSON数据保存和图片下载的同时进行。
在 settings.py 中新添加一个管道,修改的名字就是我们定义的类名。
这样再运行爬虫文件,就可以得到JSON文件和所有的图片了。
5.多页下载
找一下每一页的url之间的规律
# http://category.dangdang.com/pg2-cp01.36.04.00.00.00.html
# http://category.dangdang.com/pg3-cp01.36.04.00.00.00.html
# http://category.dangdang.com/pg4-cp01.36.04.00.00.00.html
可以看到,只有page不一样
所以我们可以在 dang.py 的类中定义一个url_base。
url_base = 'http://category.dangdang.com/pg'
page = 1然后在 parse方法中添加以下代码
使用 yield 将新的url再传递给 parse() 方法。
# 多个页面的请求
# 每一页爬取的业务逻辑都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法
# http://category.dangdang.com/pg2-cp01.36.04.00.00.00.html
# http://category.dangdang.com/pg3-cp01.36.04.00.00.00.html
# http://category.dangdang.com/pg4-cp01.36.04.00.00.00.htmlif self.page < 10:self.page = self.page + 1url = self.url_base + str(self.page) + '-cp01.36.04.00.00.00.html'# 怎么调用 parse 方法# scrapy.Request 就是scrapy的get请求# url 就是请求地址,callback就是你要执行的那个函数,不需要加‘ () ’yield scrapy.Request(url=url, callback=self.parse)完整代码:
dang.py
import scrapy
from ..items import Scrapy095Itemclass DangSpider(scrapy.Spider):name = 'dang'# 如果是多页下载,allowed_domains只保留域名,去掉协议和地址,为的是扩大允许范围allowed_domains = ['category.dangdang.com']start_urls = ['http://category.dangdang.com/cp01.36.04.00.00.00.html']url_base = 'http://category.dangdang.com/pg'page = 1def parse(self, response):print('=============================')# pipeline 下载数据# items 定义数据结构# 找到三者共同所在的标签# img = response.xpath('//ul[@id="component_59"]/li//img/@data-original')# name = response.xpath('//ul[@id="component_59"]/li//img/@alt')# price = response.xpath('//ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()')# 所有selector对象可以在此调用 Xpath方法li_list = response.xpath('//ul[@id="component_59"]/li')for li in li_list:# 第一章图片的链接在 src 里# 其余图片的链接在 data-original 里img = li.xpath('.//img/@data-original').extract_first()if img:img = imgelse:img = li.xpath('.//img/@src').extract_first()name = li.xpath('.//img/@alt').extract_first()price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first()print(img,name,price)book = Scrapy095Item(img=img,name=name,price=price)# 将 book 交给 pipeline 下载yield book# 多个页面的请求# 每一页爬取的业务逻辑都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法# http://category.dangdang.com/pg2-cp01.36.04.00.00.00.html# http://category.dangdang.com/pg3-cp01.36.04.00.00.00.html# http://category.dangdang.com/pg4-cp01.36.04.00.00.00.htmlif self.page < 10:self.page = self.page + 1url = self.url_base + str(self.page) + '-cp01.36.04.00.00.00.html'# 怎么调用 parse 方法# scrapy.Request 就是scrapy的get请求# url 就是请求地址,callback就是你要执行的那个函数,不需要加‘ () ’yield scrapy.Request(url=url, callback=self.parse)print('=============================')items.py
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapyclass Scrapy095Item(scrapy.Item):# define the fields for your item here like:# name = scrapy.Field()# 通俗地讲就是你下载的数据都有什么# 爬取图片img = scrapy.Field()# 爬取书名name = scrapy.Field()# 爬取价格price = scrapy.Field()pass
pipelines.py
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interface
from itemadapter import ItemAdapter# 如果要使用管道的话,就要在 settings.py 中开启管道
class Scrapy095Pipeline:# 在爬虫文件开始之前就执行的一个文件def open_spider(self, spider):print('++++++++++++++++++++++++++')self.fp = open('book.json', 'w', encoding='utf-8')# item 就是 yield 的返回值def process_item(self, item, spider):# 我们不这样保存# # 保存数据# with open('book.json','a', encoding='utf-8') as file:# # 存在的问题# # item 是一个对象,需要将其转换为 str# # 写文件的方式要改为 ‘a’ 追加模式,而不是 ‘w’覆盖模式。# file.write(str(item))self.fp.write(str(item))return item# 在爬虫文件执行完之后再执行的方法def close_spider(self, spider):print('----------------------')self.fp.close()import urllib.request
# 多条管道开启
# (1)定义管道类
# (2)在settings中开启管道
class Scrapy095_download_Pipeline:def process_item(self, item, spider):url = 'http:' + item.get('img')filename = './books/' + item.get('name') + '.jpg'urllib.request.urlretrieve(url=url, filename=filename)return item
settings.py 中只 取消ROBOTSTXT_OBEY的注释,并添加下面的管道。
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {# 管道可以有很多个,但管道是有优先级的,优先级范围是 1-1000, 值越小,优先级越高。'scrapy_095.pipelines.Scrapy095Pipeline': 300,'scrapy_095.pipelines.Scrapy095_download_Pipeline': 301,
}参考
尚硅谷Python爬虫教程小白零基础速通(含python基础+爬虫案例)
相关文章:
爬虫 scrapy ——scrapy shell调试及下载当当网数据(十一)
目录 一、scrapy shell 1.什么是scrapy shell? 2.安装 ipython 3.使用scrapy shell 二、当当网案例 1.在items.py中定义数据结构 2.在dang.py中解析数据 3.使用pipeline保存 4.多条管道的使用 5.多页下载 参考 一、scrapy shell 1.什么是scrapy shell&am…...
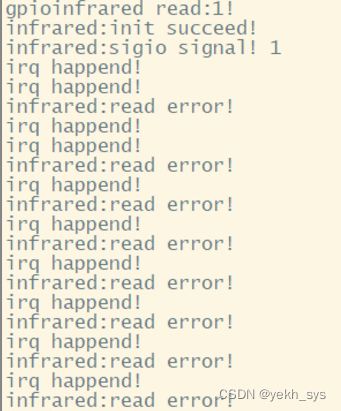
Linux驱动(中断、异步通知):红外对射,并在Qt StatusBus使用指示灯进行显示
本文工作: 1、Linux驱动与应用程序编写:使用了设备树、中断、异步通知知识点,实现了红外对射状态的异步信息提醒。 2、QT程序编写:自定义了一个“文本指示灯”类,并放置在QMainWidget的StatusBus中。 3、C与C混合编程与…...
echarts地图的常见用法:基本使用、区域颜色分级、水波动画、区域轮播、给地图添加背景图片和图标、3d地图、飞线图
前言 最近几天用echarts做中国地图,就把以前写的demo:在vue中实现中国地图 拿来用,结果到项目里直接报错了,后来发现是因为版本的问题,没办法只能从头进行踩坑了。以下内容基于vue3 和 echarts 5.32 基本使用 获取地…...

进程间通讯-管道
介绍 管道(Pipe)是操作系统提供的一种进程间通信(IPC,Inter-Process Communication)机制,它允许一个进程的输出直接作为另一个进程的输入。管道主要分为以下两种类型: 无名管道(Unn…...
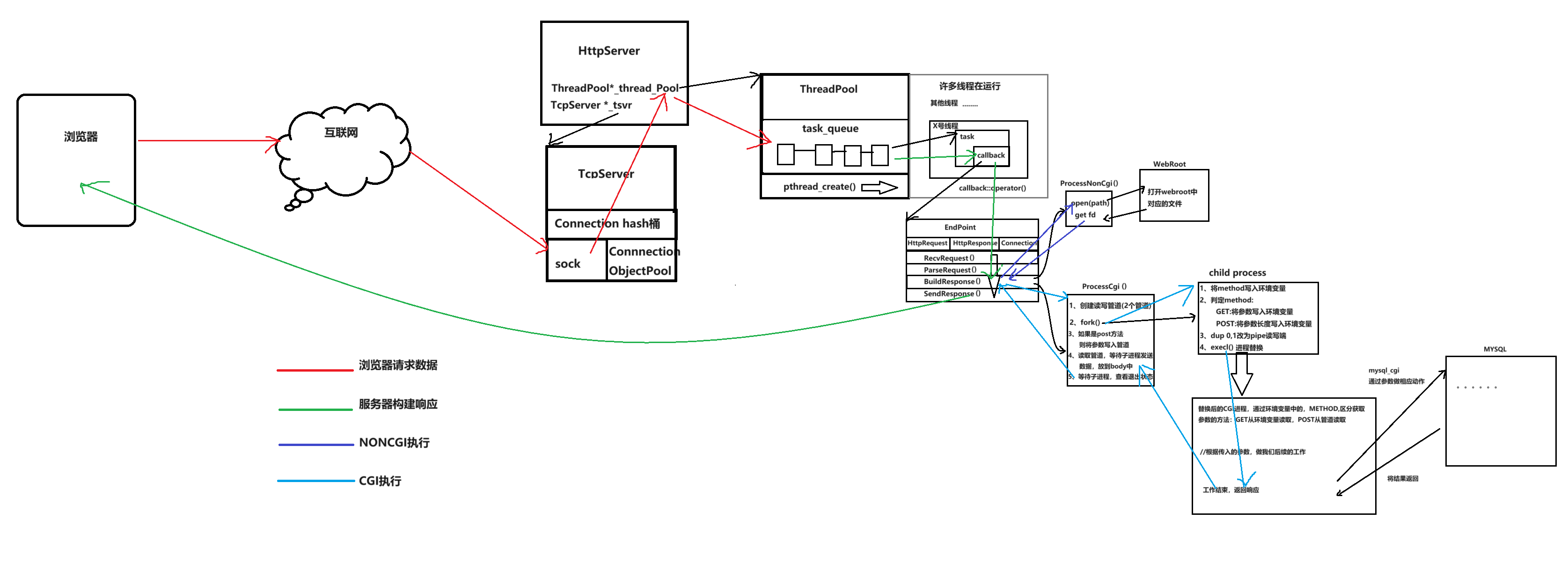
项目总结-自主HTTP实现
终于是写完了,花费了2周时间,一点一点看,还没有扩展,但是基本功能是已经实现了。利用的是Tcp为网络链接,在其上面又写了http的壳。没有使用epoll,多路转接难度比较高,以后有机会再写,…...

Java语言+二维数组+非递归实现五子棋游戏
以前做过一个C语言版五子棋:C语言+二维数组+非递归实现五子棋游戏 现在做一个Java语言版五子棋,规则如下: 1、白子为O; 2、黑子为; 3、白子先手;…...

WordCloud—— 词云
【说明】文章内容来自《机器学习入门——基于sklearn》,用于学习记录。若有争议联系删除。 wordcloud 是python的第三方库,称为词云,也成文字云,可以根据文本中的词频以直观和艺术化的形式展示文本中词语的重要性。 依赖于pillow …...

linux网络----UDP编程
一、函数接口: 1.socket:创建一个用来网络通信的终端节点; 参数: type:套接字类型 SOCK_STREAM 流式套接字 TCP SOCK_DGRAM 数据报套接字 UDP SOCK_RAM 原始套接字 domain: 协议族 AF_INET protocal: 默认为0 2.s…...

[AI工具推荐]AiRestful智能API代码生成
智能API代码示例生成工具AiRestful 一、产品介绍二、如何使用1、第一步(必须):2、第二步(可选):3、第三步(智能生成): 三、如何集成到您的网站(应用)1、开始接入2、接入案例 四、注意点 一、产品介绍 AiRestful是一款基于智能AI的,帮助小白快速生成任意编程语言的API接口调用示…...

Elasticsearch 8.10.0同义词API用法详解,支持同义词热更新
Elasticsearch 的同义词功能非常强大,如果使用得当,可以显着提高搜索引擎的效果。使用同义词功能时的一个常见问题是更新同义词集。 同义词在搜索引擎领域用途 同义词在搜索引擎领域的用途可概括如下: 增强搜索的准确性——当用户输入一个关键词时,可能与他们实际意图相关…...

深度学习之模型权重
在深度学习中,模型的权重(weights)是指神经网络中的参数,这些参数用于调整和学习模型的行为,以便能够对输入数据进行有效的映射和提取有用的特征。深度学习模型通常由许多神经元和连接组成,而权重就是连接这…...
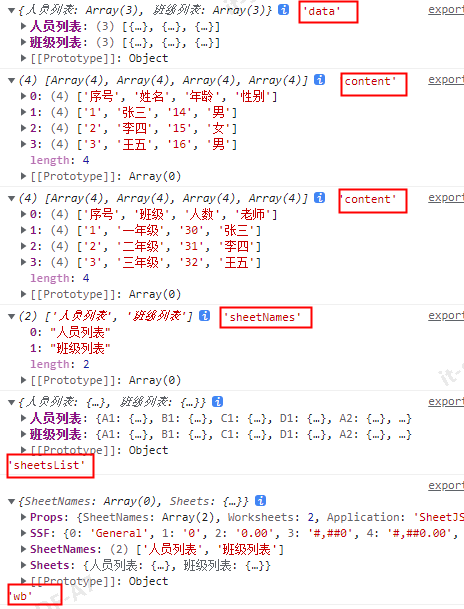
纯前端使用XLSX导出excel表格
1 单个sheet page.js(页面中的导出方法) import { exportExcel } from ../../../utils/exportExcel.js; leadOut() {const arr [{ id: 1, name: 张三, age: 14, sex: 男 },{ id: 2, name: 李四, age: 15, sex: 女 },{ id: 3, name: 王五, age: 16, sex: 男 },];const allR…...
将mjpg格式数转化成opencv Mat格式
该博客可以解决如下两个问题: 1、将mjpg格式数据转化成opencv Mat格式 2、v4l2_buffer 格式获取的mjpg格式数据转换成Mat格式。 要将 MJPEG 格式的数据转换为 OpenCV 的 Mat 格式,您可以使用 imdecode 函数。imdecode 函数可以将图像数据解码为 Mat 对象…...

【golang/g3n】3D游戏引擎G3N的windows安装与测试
目录 说在前面安装测试 说在前面 操作系统:win 11go version:go1.21.5 windows/amd64g3n版本:github.com/g3n/engine v0.2.0其他:找了下golang 3d相关的库,目前好像就这个比较活跃 安装 按照官方教程所说,…...
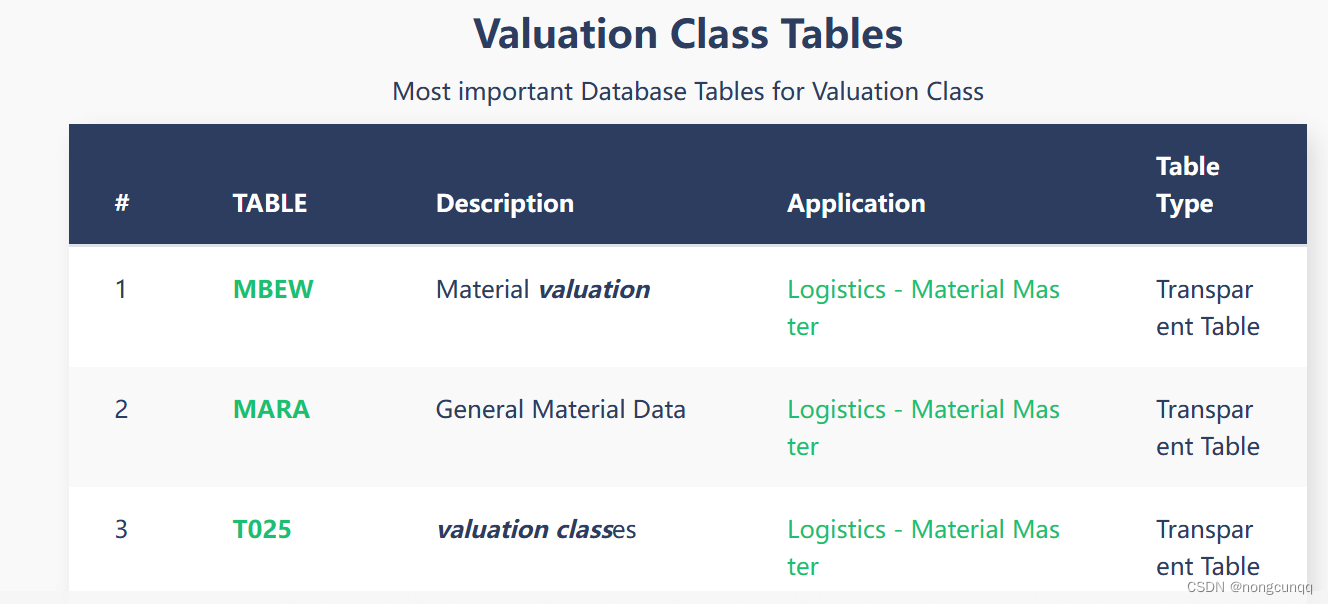
sap table 获取 valuation class MBEW 查表获取
参考 https://www.tcodesearch.com/sap-tables/search?qvaluationclass...

介绍一些操作系统—— Ubuntu 系统
介绍一些操作系统—— Ubuntu 系统 Ubuntu 系统 Ubuntu 是一个以桌面应用为主的 Linux 发行版操作系统,其名称来自非洲南部祖鲁语或豪萨语的“ubuntu"一词,意思是“人性”“我的存在是因为大家的存在",是非洲传统的一种价值观。U…...

React中props 和 state异同初探
在 React 中,props 和 state 是两个非常重要的概念,它们决定了组件的行为和渲染方式。 Props props(属性)是父组件传递给子组件的数据。它们类似于函数的参数,可以在组件内部被访问和使用,但不能被修改。…...
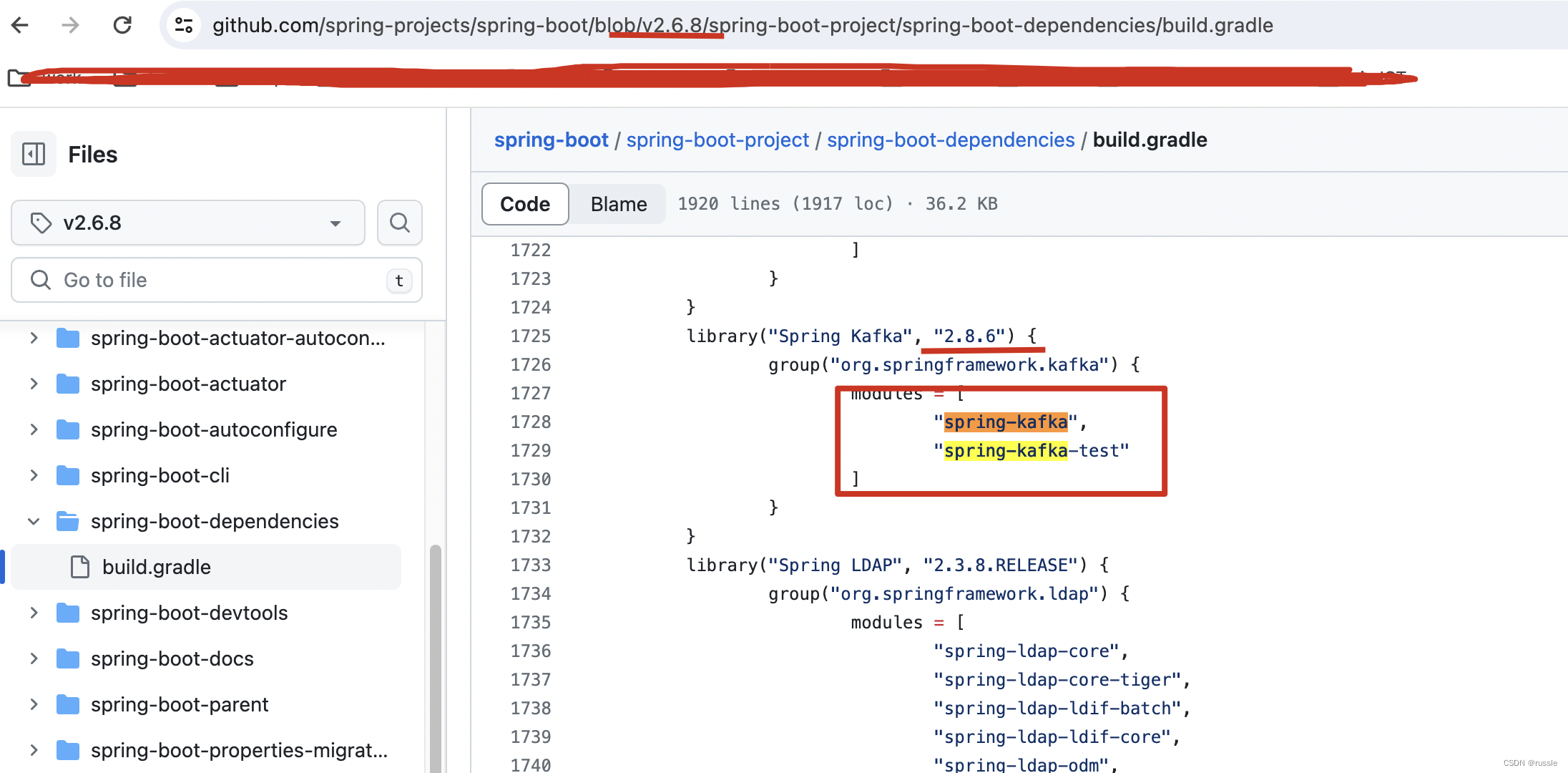
spring-kakfa依赖管理之org/springframework/kafka/listener/CommonErrorHandler错误
问题: 整个项目使用spring-boot2.6.8版本,使用gradle构建,在common模块指定了implementation org.springframework.kafka:spring-kafka:2.6.8’这个工程也都能运行(这正常发送kafka消息和接收消息),但是执行…...

基于go语言开发的海量用户及时通讯系统
文章目录 二十三、海量用户即时通讯系统1、项目开发前技术准备2.实现功能-显示客户端登录菜单3.实现功能-完成用户登录-1.完成客户端可以该长度值发送消息长度,服务器端可以正常接收到-2.完成客户端可以发送消息,服务器端可以接收到消息并根据客户端发送…...
 、count(*) 和count(列名) 函数的区别)
19.Oracle 中count(1) 、count(*) 和count(列名) 函数的区别
count(1) and count(字段) 两者的主要区别是 count(1) 会统计表中的所有的记录数,包含字段为null 的记录。count(字段) 会统计该字段在表中出现的次数,忽略字段为null 的情况。 即不统计字段为null 的记录。 count(*) 和 count(1)和count(列名)区别 …...

应用升级/灾备测试时使用guarantee 闪回点迅速回退
1.场景 应用要升级,当升级失败时,数据库回退到升级前. 要测试系统,测试完成后,数据库要回退到测试前。 相对于RMAN恢复需要很长时间, 数据库闪回只需要几分钟。 2.技术实现 数据库设置 2个db_recovery参数 创建guarantee闪回点,不需要开启数据库闪回。…...

反向工程与模型迁移:打造未来商品详情API的可持续创新体系
在电商行业蓬勃发展的当下,商品详情API作为连接电商平台与开发者、商家及用户的关键纽带,其重要性日益凸显。传统商品详情API主要聚焦于商品基本信息(如名称、价格、库存等)的获取与展示,已难以满足市场对个性化、智能…...

【大模型RAG】Docker 一键部署 Milvus 完整攻略
本文概要 Milvus 2.5 Stand-alone 版可通过 Docker 在几分钟内完成安装;只需暴露 19530(gRPC)与 9091(HTTP/WebUI)两个端口,即可让本地电脑通过 PyMilvus 或浏览器访问远程 Linux 服务器上的 Milvus。下面…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

unix/linux,sudo,其发展历程详细时间线、由来、历史背景
sudo 的诞生和演化,本身就是一部 Unix/Linux 系统管理哲学变迁的微缩史。来,让我们拨开时间的迷雾,一同探寻 sudo 那波澜壮阔(也颇为实用主义)的发展历程。 历史背景:su的时代与困境 ( 20 世纪 70 年代 - 80 年代初) 在 sudo 出现之前,Unix 系统管理员和需要特权操作的…...

短视频矩阵系统文案创作功能开发实践,定制化开发
在短视频行业迅猛发展的当下,企业和个人创作者为了扩大影响力、提升传播效果,纷纷采用短视频矩阵运营策略,同时管理多个平台、多个账号的内容发布。然而,频繁的文案创作需求让运营者疲于应对,如何高效产出高质量文案成…...

CRMEB 中 PHP 短信扩展开发:涵盖一号通、阿里云、腾讯云、创蓝
目前已有一号通短信、阿里云短信、腾讯云短信扩展 扩展入口文件 文件目录 crmeb\services\sms\Sms.php 默认驱动类型为:一号通 namespace crmeb\services\sms;use crmeb\basic\BaseManager; use crmeb\services\AccessTokenServeService; use crmeb\services\sms\…...

【Linux系统】Linux环境变量:系统配置的隐形指挥官
。# Linux系列 文章目录 前言一、环境变量的概念二、常见的环境变量三、环境变量特点及其相关指令3.1 环境变量的全局性3.2、环境变量的生命周期 四、环境变量的组织方式五、C语言对环境变量的操作5.1 设置环境变量:setenv5.2 删除环境变量:unsetenv5.3 遍历所有环境…...

MySQL:分区的基本使用
目录 一、什么是分区二、有什么作用三、分类四、创建分区五、删除分区 一、什么是分区 MySQL 分区(Partitioning)是一种将单张表的数据逻辑上拆分成多个物理部分的技术。这些物理部分(分区)可以独立存储、管理和优化,…...