【Python百宝箱】云上翱翔:Python编程者的AWS奇妙之旅
雲端箴言:用Python主持AWS管理交響樂
前言
随着云计算的普及,AWS(Amazon Web Services)成为了许多组织和开发者首选的云服务提供商。作为Python工程师,深入了解AWS管理工具和库对于高效利用云资源至关重要。本文将引导读者探索云计算的精髓,通过AWS的关键工具和Python库,构建强大、灵活且可维护的云基础设施。
【Python百宝箱】从传感器到云端:深度解析Python在物联网中的多面应用
【Python百宝箱】Python云计算奇兵:库库皆英雄
【Python百宝箱】数据巨轮启航:Python大数据处理库全攻略,引领数据科学新浪潮
【Python百宝箱】DevOps利器汇总:从单元测试到容器化,打造完美开发运维生态
欢迎订阅专栏:Python库百宝箱:解锁编程的神奇世界
文章目录
- 雲端箴言:用Python主持AWS管理交響樂
- 前言
- 1. Boto3
- 1.1 概述
- 1.2 安装
- 1.3 基本用法
- 1.4 高级特性
- 1.5 AWS Lambda 与 Boto3 的协同
- 1.6 Boto3 的 S3 文件上传与下载
- 1.7 Boto3 与 AWS DynamoDB 集成
- 1.8 Boto3 与 Amazon SNS 发送通知
- 2. AWS CLI
- 2.1 简介
- 2.2 安装
- 2.3 配置
- 2.4 基本命令
- 2.5 使用AWS CLI进行脚本编写
- 2.6 AWS CLI 的命令组合与管道操作
- 2.7 AWS CLI 的 S3 文件传输与同步
- 2.8 AWS CLI 与 CloudWatch 结合进行监控
- 2.9 AWS CLI 的 CloudFormation 集成
- 2.10 AWS CLI 的 ECS 操作
- 3. Terraform
- 3.1 简介
- 3.2 安装
- 3.3 配置文件
- 3.4 资源部署
- 3.5 Terraform模块
- 3.6 Terraform 的变量和数据源
- 3.7 Terraform 的迁移和重用
- 3.8 Terraform 的状态管理
- 3.9 Terraform 的输出与引用
- 3.10 Terraform 的函数和表达式
- 4. CloudFormation
- 4.1 概述
- 4.2 模板
- 4.3 栈管理
- 4.4 参数化
- 4.5 跨栈引用
- 4.6 CloudFormation 的资源依赖与更新
- 4.7 CloudFormation 的变更集与回滚
- 4.8 CloudFormation 的输出与导出
- 4.9 CloudFormation 的条件与循环
- 4.10 CloudFormation 的 AWS Lambda 自定义资源
- 5. Pulumi
- 5.1 简介
- 5.2 安装
- 5.3 作为声明性基础设施的代码 (IaC)
- 5.4 多云支持
- 5.5 Pulumi与AWS集成
- 5.6 Pulumi 的栈和配置
- 5.7 Pulumi 的资源依赖与更新
- 5.8 Pulumi 的条件与循环
- 5.9 Pulumi 的输出与导出
- 5.10 Pulumi 的 AWS Lambda 自定义资源
- 6. AWS SDK for Python (BotoCore)
- 6.1 概述
- 6.2 安装
- 6.3 BotoCore基础
- 6.4 使用BotoCore进行低级别AWS服务交互
- 6.5 BotoCore 的配置文件
- 6.6 BotoCore 的异常处理
- 6.7 BotoCore 的自定义配置和插件
- 6.8 BotoCore 的异步操作
- 6.9 BotoCore 的签名版本
- 6.10 BotoCore 的服务模型和文档
- 6.11 BotoCore 的版本管理
- 6.12 BotoCore 的事件和钩子
- 总结
1. Boto3
1.1 概述
Boto3是AWS软件开发工具包(SDK)的一部分,专为Python开发者设计,用于与AWS服务进行交互。它提供了简单而强大的API,用于管理云资源,执行操作和访问AWS服务。
1.2 安装
使用pip安装Boto3:
pip install boto3
1.3 基本用法
import boto3# 创建S3客户端
s3_client = boto3.client('s3')# 列出所有S3存储桶
response = s3_client.list_buckets()
buckets = [bucket['Name'] for bucket in response['Buckets']]
print('S3 Buckets:', buckets)
1.4 高级特性
Boto3支持众多AWS服务的高级特性,例如Amazon EC2实例的管理、DynamoDB表的创建和查询等。以下是使用Boto3管理EC2实例的示例:
import boto3# 创建EC2客户端
ec2_client = boto3.client('ec2')# 启动EC2实例
response = ec2_client.run_instances(ImageId='ami-xxxxxxxx',MinCount=1,MaxCount=1,InstanceType='t2.micro'
)instance_id = response['Instances'][0]['InstanceId']
print('Launched EC2 Instance with ID:' , instance_id)
1.5 AWS Lambda 与 Boto3 的协同
AWS Lambda是一项强大的服务,允许您在无需管理服务器的情况下运行代码。Boto3与AWS Lambda的结合使用提供了在云端自动执行任务的灵活性。以下是一个使用Boto3在AWS Lambda中启动EC2实例的例子:
import boto3def lambda_handler(event, context):# 创建EC2客户端ec2_client = boto3.client('ec2')# 启动EC2实例response = ec2_client.run_instances(ImageId='ami-xxxxxxxx',MinCount=1,MaxCount=1,InstanceType='t2.micro')instance_id = response['Instances'][0]['InstanceId']print('Launched EC2 Instance with ID:', instance_id)return {'statusCode': 200,'body': f'Launched EC2 Instance with ID: {instance_id}'}
通过结合Boto3和AWS Lambda,您可以轻松创建自动化任务,并根据需要触发它们,实现云端计算的灵活应用。
1.6 Boto3 的 S3 文件上传与下载
Boto3为与Amazon S3交互提供了方便的方法。以下是使用Boto3上传和下载文件到S3的示例:
import boto3# 创建S3客户端
s3_client = boto3.client('s3')# 上传文件到S3
s3_client.upload_file('local_file.txt', 'my-s3-bucket', 'remote_file.txt')# 下载文件从S3
s3_client.download_file('my-s3-bucket', 'remote_file.txt', 'local_file_downloaded.txt')
通过这些代码示例,您可以方便地使用Boto3在Python中进行S3文件的上传和下载。
1.7 Boto3 与 AWS DynamoDB 集成
Boto3为与AWS DynamoDB交互提供了直观的接口。以下是使用Boto3创建DynamoDB表并进行查询的示例:
import boto3# 创建DynamoDB客户端
dynamodb_client = boto3.client('dynamodb')# 创建DynamoDB表
table_name = 'my-dynamodb-table'
dynamodb_client.create_table(TableName=table_name,KeySchema=[{'AttributeName': 'id', 'KeyType': 'HASH'}],AttributeDefinitions=[{'AttributeName': 'id', 'AttributeType': 'N'}],ProvisionedThroughput={'ReadCapacityUnits': 5, 'WriteCapacityUnits': 5}
)# 插入数据到DynamoDB表
dynamodb_client.put_item(TableName=table_name,Item={'id': {'N': '1'}, 'name': {'S': 'John Doe'}}
)# 查询数据
response = dynamodb_client.scan(TableName=table_name)
items = response['Items']
print('DynamoDB Items:', items)
通过这个示例,您可以学习如何使用Boto3与AWS DynamoDB集成,进行数据的增删改查操作。
1.8 Boto3 与 Amazon SNS 发送通知
Amazon Simple Notification Service(SNS)是一项用于构建分布式、高度可伸缩的应用程序的完全托管的通信服务。以下是使用Boto3发送SNS通知的示例:
import boto3# 创建SNS客户端
sns_client = boto3.client('sns')# 创建SNS主题
topic_arn = sns_client.create_topic(Name='my-sns-topic')['TopicArn']# 发送通知
sns_client.publish(TopicArn=topic_arn,Message='Hello from Boto3!',Subject='Test Notification'
)print('Notification sent to SNS topic:', topic_arn)
通过以上代码,您可以了解如何使用Boto3与Amazon SNS协同工作,实现通知服务的集成。
2. AWS CLI
2.1 简介
AWS CLI是AWS命令行界面,提供了一组命令,用于与AWS服务进行交互。它是通过命令行或脚本自动化AWS资源管理的有力工具。
2.2 安装
AWS CLI可以通过多种方式安装,包括pip、操作系统软件包管理器等。使用pip安装的方法如下:
pip install awscli
2.3 配置
在使用AWS CLI之前,需要配置AWS访问密钥和区域信息:
aws configure
2.4 基本命令
AWS CLI提供了众多命令,以下是一个简单的例子,列出所有S3存储桶:
aws s3 ls
2.5 使用AWS CLI进行脚本编写
AWS CLI支持脚本编写,例如使用JMESPath进行结果筛选,通过以下示例列出S3存储桶的名称:
aws s3 ls --query 'Buckets[].Name'
2.6 AWS CLI 的命令组合与管道操作
AWS CLI的强大之处在于您可以将多个命令组合起来,形成复杂的操作序列,并使用管道(pipe)来传递输出。以下是一个示例,通过AWS CLI获取EC2实例的ID列表,然后根据ID获取实例的详细信息:
# 获取EC2实例ID列表
instance_ids=$(aws ec2 describe-instances --query 'Reservations[].Instances[].InstanceId' --output text)# 根据ID获取实例详细信息
aws ec2 describe-instances --instance-ids $instance_ids
在这个示例中,首先使用 describe-instances 命令获取EC2实例的ID列表,然后将这些ID传递给另一个 describe-instances 命令,获取实例的详细信息。
2.7 AWS CLI 的 S3 文件传输与同步
AWS CLI不仅可以列出S3存储桶,还提供了强大的文件传输和同步功能。以下是使用AWS CLI将本地文件上传到S3的示例:
# 将本地文件上传到S3
aws s3 cp local_file.txt s3://my-s3-bucket/remote_file.txt
AWS CLI还支持文件夹同步,可用于将本地文件夹同步到S3存储桶:
# 同步本地文件夹到S3
aws s3 sync local_folder/ s3://my-s3-bucket/remote_folder/
2.8 AWS CLI 与 CloudWatch 结合进行监控
AWS CLI可以与CloudWatch服务协同工作,通过命令行监控AWS资源的指标。以下是一个使用AWS CLI获取EC2实例CPU利用率的示例:
# 获取EC2实例的CPU利用率
aws cloudwatch get-metric-statistics \--namespace AWS/EC2 \--metric-name CPUUtilization \--dimensions Name=InstanceId,Value=i-xxxxxxxxxxxxxxxxx \--start-time $(date -u -d '1 hour ago' '+%Y-%m-%dT%H:%M:%SZ') \--end-time $(date -u '+%Y-%m-%dT%H:%M:%SZ') \--period 300 \--statistics Maximum
在这个示例中,使用 get-metric-statistics 命令获取EC2实例的CPU利用率统计信息。
2.9 AWS CLI 的 CloudFormation 集成
AWS CLI可以用于创建、更新和删除CloudFormation堆栈。以下是使用AWS CLI创建CloudFormation堆栈的示例:
# 创建CloudFormation堆栈
aws cloudformation create-stack \--stack-name my-cf-stack \--template-body file://cloudformation-template.yaml \--parameters ParameterKey=KeyName,ParameterValue=my-key
在这个示例中,使用 create-stack 命令创建了一个CloudFormation堆栈,并指定了堆栈的名称、模板文件以及参数。
2.10 AWS CLI 的 ECS 操作
AWS CLI支持ECS(Elastic Container Service),可以用于管理Docker容器。以下是使用AWS CLI在ECS中运行任务的示例:
# 在ECS中运行任务
aws ecs run-task \--cluster my-ecs-cluster \--task-definition my-task-definition \--launch-type EC2
在这个示例中,使用 run-task 命令在ECS集群中启动了一个任务,指定了集群名称、任务定义和启动类型。
3. Terraform
3.1 简介
Terraform是一种基础设施即代码(IaC)工具,用于自动化和管理云基础设施。它支持多云平台,包括AWS。
3.2 安装
Terraform可以从官方网站下载,并按照相应平台的安装说明进行安装。
3.3 配置文件
Terraform使用HCL(HashiCorp Configuration Language)编写配置文件。以下是一个简单的例子,创建AWS S3存储桶:
provider "aws" {region = "us-east-1"
}resource "aws_s3_bucket" "example" {bucket = "my-terraform-bucket"acl = "private"
}
3.4 资源部署
使用以下命令初始化Terraform配置并应用:
terraform init
terraform apply
3.5 Terraform模块
Terraform模块是可重用的基础设施代码单元。以下是一个简单的例子,创建可配置的EC2实例模块:
variable "instance_type" {description = "EC2 instance type"default = "t2.micro"
}resource "aws_instance" "example" {ami = "ami-xxxxxxxx"instance_type = var.instance_type
}
3.6 Terraform 的变量和数据源
Terraform支持使用变量和数据源进行配置和信息的灵活管理。以下是一个示例,定义了变量用于指定AWS区域和实例类型,并使用数据源获取AMI ID:
variable "aws_region" {description = "AWS region"default = "us-east-1"
}variable "instance_type" {description = "EC2 instance type"default = "t2.micro"
}data "aws_ami" "latest_amazon_linux" {most_recent = trueowners = ["amazon"]filter {name = "name"values = ["amzn2-ami-hvm-*-x86_64-gp2"]}
}provider "aws" {region = var.aws_region
}resource "aws_instance" "example" {ami = data.aws_ami.latest_amazon_linux.idinstance_type = var.instance_type
}
在这个示例中,使用了 variable 定义了两个变量,分别表示AWS区域和EC2实例类型。使用 data 定义了一个数据源,通过该数据源获取了最新的Amazon Linux AMI ID。在 aws_instance 资源中使用了这些变量和数据源。
3.7 Terraform 的迁移和重用
Terraform支持迁移和重用现有的基础设施代码。以下是一个示例,通过 terraform import 命令导入现有S3存储桶的定义:
terraform import aws_s3_bucket.example my-existing-bucket
这个命令将现有S3存储桶与Terraform配置关联,使得可以通过Terraform进行进一步的管理。
3.8 Terraform 的状态管理
Terraform使用状态文件来跟踪已创建的资源并确保与配置文件的一致性。可以通过配置不同的后端(backend)来管理状态文件的存储。以下是一个配置S3存储状态文件的示例:
terraform {backend "s3" {bucket = "my-terraform-state-bucket"key = "terraform.tfstate"region = "us-east-1"}
}
在这个示例中,通过配置S3后端,Terraform将状态文件存储在指定的S3存储桶中。
3.9 Terraform 的输出与引用
Terraform允许定义输出(output),以便在其他配置文件中引用。以下是一个示例,定义了一个输出以输出EC2实例的公有IP地址:
output "instance_public_ip" {value = aws_instance.example.public_ip
}
在其他配置文件中,可以通过引用 module.example.instance_public_ip 来获取该输出值,实现模块间的数据传递。
3.10 Terraform 的函数和表达式
Terraform支持多种函数和表达式,用于在配置文件中进行计算和操作。以下是一个示例,使用 count 和 element 函数创建多个S3存储桶:
variable "bucket_names" {type = list(string)default = ["bucket-1", "bucket-2", "bucket-3"]
}resource "aws_s3_bucket" "example" {count = length(var.bucket_names)bucket = var.bucket_names[count.index]acl = "private"
}
在这个示例中,使用了 count 和 element 函数,根据变量中的列表创建了多个S3存储桶。
通过深入学习Terraform的这些特性,您将更加熟练地使用这一强大的基础设施即代码工具,实现更复杂的云基础设施管理。
4. CloudFormation
4.1 概述
AWS CloudFormation是一种基础设施即代码服务,允许您以声明性的方式定义和部署AWS基础设施。
4.2 模板
CloudFormation使用JSON或YAML模板描述基础设施。以下是一个简单的S3存储桶模板:
Resources:MyS3Bucket:Type: AWS::S3::BucketProperties:BucketName: my-cloudformation-bucket
4.3 栈管理
使用CloudFormation模板创建栈并进行管理。以下是创建S3存储桶的命令:
aws cloudformation create-stack --stack-name my-s3-stack --template-body file://s3-template.yaml
4.4 参数化
通过在模板中定义参数,可以使CloudFormation模板更加灵活。以下是一个带有参数的S3存储桶模板:
Parameters:BucketName:Type: StringResources :MyS3Bucket:Type: AWS::S3::BucketProperties:BucketName: !Ref BucketName
4.5 跨栈引用
CloudFormation允许在不同栈之间进行引用。以下是一个引用其他栈输出的例子:
Resources:MyEC2Instance:Type: AWS::EC2::InstanceProperties:ImageId: "ami-xxxxxxxx"InstanceType: "t2.micro"SubnetId: !ImportValue OtherStackSubnetId
4.6 CloudFormation 的资源依赖与更新
CloudFormation允许定义资源之间的依赖关系,以确保它们按正确的顺序创建。以下是一个具有资源依赖关系的示例,确保EC2实例在VPC和子网创建后再创建:
Resources:MyVPC:Type: AWS::EC2::VPCProperties:CidrBlock: "10.0.0.0/16"MySubnet:Type: AWS::EC2::SubnetDependsOn: MyVPCProperties:VpcId: !Ref MyVPCCidrBlock: "10.0.0.0/24"MyEC2Instance:Type: AWS::EC2::InstanceDependsOn: MySubnetProperties:ImageId: "ami-xxxxxxxx"InstanceType: "t2.micro"SubnetId: !Ref MySubnet
在这个示例中,MyVPC 和 MySubnet 的创建被设置为 MyEC2Instance 的依赖项,确保VPC和子网在EC2实例创建之前已经存在。
4.7 CloudFormation 的变更集与回滚
CloudFormation支持变更集(Change Sets)功能,用于在应用更改之前预览这些更改。以下是一个创建变更集并执行变更的示例:
aws cloudformation create-change-set \--stack-name my-s3-stack \--change-set-name my-change-set \--template-body file://updated-s3-template.yamlaws cloudformation execute-change-set --change-set-name my-change-set --stack-name my-s3-stack
通过创建变更集,您可以在实际应用更改之前查看将对栈进行的修改,以确保安全性和一致性。
4.8 CloudFormation 的输出与导出
CloudFormation允许定义输出,使得可以在其他栈中引用这些输出。以下是一个输出EC2实例公有IP地址的例子:
Outputs:InstancePublicIP:Description: "Public IP address of the EC2 instance"Value: !GetAtt MyEC2Instance.PublicIp
在其他栈中,可以通过引用 Outputs 来获取这个输出值。
4.9 CloudFormation 的条件与循环
CloudFormation支持条件语句和循环,以便更灵活地定义和创建基础设施。以下是一个使用条件语句的示例,根据条件创建不同的资源:
Resources:MyS3Bucket:Type: AWS::S3::BucketCondition: CreateBucketConditionProperties:BucketName: my-bucketConditions:CreateBucketCondition: !Equals [ !Ref EnvironmentType, "production" ]
在这个示例中,根据条件 CreateBucketCondition 的值,决定是否创建S3存储桶。
4.10 CloudFormation 的 AWS Lambda 自定义资源
CloudFormation允许定义AWS Lambda自定义资源,以便执行在模板中无法完成的任务。以下是一个使用AWS Lambda自定义资源的例子:
Resources:MyLambdaFunction:Type: AWS::Lambda::FunctionProperties:Handler: index.handlerRole: arn:aws:iam::xxxxxx:role/lambda-execution-roleFunctionName: my-custom-resource-lambdaRuntime: nodejs14.xTimeout: 60Code:S3Bucket: my-lambda-code-bucketS3Key: my-lambda-code.zipMyCustomResource:Type: Custom::MyCustomResourceDependsOn: MyLambdaFunctionProperties:ServiceToken: !GetAtt MyLambdaFunction.Arn
在这个示例中,MyLambdaFunction 定义了一个AWS Lambda函数,而 MyCustomResource 使用了这个Lambda函数作为自定义资源的服务令牌。
通过深入学习CloudFormation的这些特性,您将能够更灵活地定义和管理AWS基础设施,并以声明性的方式实现更复杂的云架构。
5. Pulumi
5.1 简介
Pulumi是一个通用的基础设施即代码(IaC)工具,支持多云平台,包括AWS。
5.2 安装
Pulumi可以通过pip进行安装:
pip install pulumi
5.3 作为声明性基础设施的代码 (IaC)
Pulumi使用Python编写基础设施代码。以下是一个简单的例子,创建AWS S3存储桶:
import pulumi_aws as aws# 创建S3存储桶
bucket = aws.s3.Bucket('my-pulumi-bucket')# 输出存储桶名称
pulumi.export('bucket_name', bucket.bucket)
5.4 多云支持
Pulumi支持多云提供商,可以在同一项目中混合使用。以下是一个使用Azure和AWS的例子:
import pulumi
import pulumi_azure as azure
import pulumi_aws as aws# 创建Azure资源
resource_group = azure.core.ResourceGroup('my-rg')# 创建AWS S3存储桶
bucket = aws.s3.Bucket('my-pulumi-bucket')# 输出资源名称
pulumi.export('azure_resource_group', resource_group.name)
pulumi.export('aws_bucket_name', bucket.bucket)
5.5 Pulumi与AWS集成
Pulumi与AWS集成密切,可以使用AWS资源提供程序直接访问AWS服务。以下是一个创建EC2实例的例子:
import pulumi
import pulumi_aws as aws# 创建EC2实例
instance = aws.ec2.Instance('my-instance',instance_type='t2.micro',ami='ami-xxxxxxxx',tags={'Name': 'my-instance'}
)# 输出实例ID
pulumi.export('instance_id', instance.id)
5.6 Pulumi 的栈和配置
Pulumi使用栈(Stack)来管理不同的环境和配置。以下是一个使用栈的示例:
pulumi stack init dev
pulumi config set aws:region us-east-1
pulumi up
在这个示例中,创建了一个名为"dev"的栈,并设置了AWS区域为"us-east-1"。
5.7 Pulumi 的资源依赖与更新
Pulumi允许定义资源之间的依赖关系,确保它们按正确的顺序创建。以下是一个具有资源依赖关系的Python示例,确保EC2实例在VPC和子网创建后再创建:
import pulumi_aws as aws# 创建VPC
vpc = aws.ec2.Vpc('my-vpc', cidr_block='10.0.0.0/16')# 创建子网
subnet = aws.ec2.Subnet('my-subnet', vpc_id=vpc.id, cidr_block='10.0.0.0/24')# 创建EC2实例
instance = aws.ec2.Instance('my-instance',ami='ami-xxxxxxxx',instance_type='t2.micro',subnet_id=subnet.id,depends_on=[subnet]
)# 输出实例ID
pulumi.export('instance_id', instance.id)
在这个示例中,vpc 和 subnet 的创建被设置为 instance 的依赖项,确保VPC和子网在EC2实例创建之前已经存在。
5.8 Pulumi 的条件与循环
Pulumi支持条件语句和循环,以便更灵活地定义和创建基础设施。以下是一个使用条件语句的Python示例,根据条件创建不同的资源:
import pulumi_aws as aws# 根据条件创建S3存储桶
is_production = True
acl = 'private' if is_production else 'public-read'
bucket = aws.s3.Bucket('my-pulumi-bucket', acl=acl)
在这个示例中,根据条件 is_production 的值,决定S3存储桶的ACL是"private"还是"public-read"。
5.9 Pulumi 的输出与导出
Pulumi允许定义输出,使得可以在其他Stack中引用这些输出。以下是一个输出EC2实例公有IP地址的Python示例:
import pulumi_aws as aws# 创建EC2实例
instance = aws.ec2.Instance('my-instance',ami='ami-xxxxxxxx',instance_type='t2.micro'
)# 输出EC2实例的公有IP地址
pulumi.export('instance_public_ip', instance.public_ip)
在其他Stack中,可以通过引用 pulumi.export 来获取这个输出值。
5.10 Pulumi 的 AWS Lambda 自定义资源
Pulumi允许定义AWS Lambda自定义资源,以便执行在模板中无法完成的任务。以下是一个使用AWS Lambda自定义资源的Python示例:
import pulumi_aws as aws# 创建AWS Lambda函数
lambda_function = aws.lambda_.Function('my-lambda',handler='index.handler',role='arn:aws:iam::xxxxxx:role/lambda-execution-role',runtime=aws.lambda_.Runtime.NODEJS14D_X,timeout=60,code={'s3Bucket': 'my-lambda-code-bucket','s3Key': 'my-lambda-code.zip'}
)# 创建自定义资源
custom_resource = pulumi.CustomResource('my-pulumi-custom-resource',lambda_function_arn=lambda_function.arn
)
在这个示例中,lambda_function 定义了一个AWS Lambda函数,而 custom_resource 使用了这个Lambda函数的ARN作为自定义资源的属性。
通过深入学习Pulumi的这些特性,您将能够以更直观和编程语言风格的方式定义和管理云基础设施。
6. AWS SDK for Python (BotoCore)
6.1 概述
BotoCore是Boto3的基础库,提供了低级别的AWS服务接口。它通常由开发人员用于创建自定义的AWS服务客户端。
6.2 安装
BotoCore通常随Boto3一起安装,无需额外安装。
6.3 BotoCore基础
BotoCore提供了与AWS服务进行低级别交互的基础功能。以下是一个使用BotoCore创建S3存储桶的例子:
import botocore.session# 创建BotoCore会话
session = botocore.session.get_session()# 创建S3客户端
s3_client = session.create_client('s3')# 创建S3存储桶
s3_client.create_bucket(Bucket='my-boto-core-bucket')
6.4 使用BotoCore进行低级别AWS服务交互
BotoCore允许开发人员直接与AWS服务API进行交互,实现更高级别的自定义操作。以下是一个使用BotoCore列出EC2实例的例子:
import botocore.session# 创建BotoCore会话
session = botocore.session.get_session()# 创建EC2客户端
ec2_client = session.create_client('ec2')# 列出所有EC2实例
response = ec2_client.describe_instances()
instances = [instance['InstanceId'] for reservation in response['Reservations'] for instance in reservation['Instances']]
print('EC2 Instances:', instances)
通过深入学习这些库,读者将能够全面了解云计算和AWS管理的工具和技术。这些工具提供了灵活性和自动化,使得在云中部署和管理基础设施变得更加高效和可维护。
6.5 BotoCore 的配置文件
BotoCore使用配置文件来存储AWS访问密钥、区域信息等配置。默认情况下,BotoCore将查找位于用户主目录下的.aws文件夹中的config文件。以下是一个简单的配置文件示例:
[default]
aws_access_key_id = YOUR_ACCESS_KEY_ID
aws_secret_access_key = YOUR_SECRET_ACCESS_KEY
region = us-east-1
通过配置文件,可以更灵活地管理多个AWS配置,避免硬编码访问密钥和区域信息。
6.6 BotoCore 的异常处理
在与AWS服务进行交互时,异常处理是一个重要的方面。BotoCore提供了丰富的异常类,可以捕获并处理各种错误情况。以下是一个处理S3存储桶创建冲突异常的例子:
import botocore.exceptionstry:# 尝试创建S3存储桶s3_client.create_bucket(Bucket='existing-bucket')
except botocore.exceptions.ClientError as e:if e.response['Error']['Code'] == 'BucketAlreadyOwnedByYou':print('Bucket already exists and is owned by you.')else:print('Error:', e)
通过捕获特定的异常类型,开发人员可以更精细地处理不同类型的错误情况。
6.7 BotoCore 的自定义配置和插件
BotoCore允许用户通过自定义配置和插件来扩展和调整其行为。通过创建自定义插件,可以添加新的功能或修改现有功能。以下是一个简单的自定义插件示例,用于打印请求信息:
from botocore import hooksdef print_request_info(request, **kwargs):print(f"Request URL: {request.url}")print(f"Request Headers: {request.headers}")print(f"Request Body: {request.body}")# 注册插件
session.register('before-sign.s3', print_request_info)# 创建S3客户端
s3_client = session.create_client('s3')# 创建S3存储桶
s3_client.create_bucket(Bucket='custom-plugin-bucket')
通过使用自定义插件,可以在请求发送之前或之后执行特定的操作,实现更高级的定制需求。
6.8 BotoCore 的异步操作
BotoCore支持异步操作,可以在异步应用程序中使用。以下是一个使用异步操作列出S3存储桶的例子:
import asyncio
import botocore.sessionasync def list_buckets():session = botocore.session.get_session()async with session.create_client('s3') as s3_client:response = await s3_client.list_buckets()buckets = [bucket['Name'] for bucket in response['Buckets']]print('S3 Buckets:', buckets)# 运行异步操作
asyncio.run(list_buckets())
通过使用async with语法,可以在异步环境中方便地使用BotoCore进行AWS服务交互。
6.9 BotoCore 的签名版本
BotoCore允许选择AWS服务请求的签名版本。某些服务可能需要使用特定的签名版本,开发人员可以通过配置选择合适的版本。以下是一个配置BotoCore使用AWS S3 V4签名版本的例子:
import botocore.session# 创建BotoCore会话
session = botocore.session.get_session()# 配置S3客户端使用V4签名
session.set_config_variable('s3', 'signature_version', 's3v4')# 创建S3客户端
s3_client = session.create_client('s3')
通过设置signature_version配置变量,可以选择不同的签名版本。
6.10 BotoCore 的服务模型和文档
BotoCore的服务模型和文档是开发人员理解和使用AWS服务的重要资源。服务模型描述了服务的API操作、参数、响应等信息,文档提供了详细的使用说明。以下是一个查看S3服务模型和文档的例子:
import botocore.session# 创建BotoCore会话
session = botocore.session.get_session()# 获取S3服务模型
s3_model = session.get_service_model('s3')# 获取S3服务文档
s3_docs = session.get_available_services()# 打印S3服务模型信息
print("S3 Service Model:")
print(s3_model)# 打印S3服务文档信息
print("\nAvailable Services:" )
print(s3_docs)
通过查看服务模型和文档,开发人员可以深入了解AWS服务的细节和用法,为更高效地使用BotoCore提供支持。
6.11 BotoCore 的版本管理
BotoCore的版本管理对于确保与AWS服务保持同步非常重要。开发人员应该定期更新BotoCore以获取最新的功能和修复。以下是一个使用pip进行BotoCore更新的例子:
pip install --upgrade botocore
通过定期更新BotoCore,可以确保使用最新的AWS服务 API 版本,以及获得性能改进和安全修复。
6.12 BotoCore 的事件和钩子
BotoCore支持事件和钩子机制,允许开发人员在请求的不同生命周期中注册自定义的处理函数。以下是一个使用事件和钩子打印请求信息的例子:
import botocore.sessiondef print_request_info(request, **kwargs):print(f"Request URL: {request.url}")print(f"Request Headers: {request.headers}")print(f"Request Body: {request.body}")# 创建BotoCore会话
session = botocore.session.get_session()# 注册钩子
session.register('before-sign.s3', print_request_info)# 创建S3客户端
s3_client = session.create_client('s3')# 创建S3存储桶
s3_client.create_bucket(Bucket='event-hook-bucket')
通过注册事件和钩子,可以在请求的不同阶段执行自定义的操作,实现更高级的自定义需求。
通过深入学习BotoCore的这些高级功能,开发人员可以更好地理解和利用其强大的低级别接口,实现更定制化和复杂的AWS服务交互。
总结
本文旨在帮助Python工程师更好地利用AWS云服务,从而提高工作效率。通过深入研究各种工具和库,读者将能够在云端环境中轻松创建、管理和维护复杂的基础设施。AWS管理不再是一项繁琐的任务,而是变得更加直观和可控。希望本文能够成为Python工程师们在云计算领域的实用指南,助力他们更好地驾驭云端未来。
相关文章:

【Python百宝箱】云上翱翔:Python编程者的AWS奇妙之旅
雲端箴言:用Python主持AWS管理交響樂 前言 随着云计算的普及,AWS(Amazon Web Services)成为了许多组织和开发者首选的云服务提供商。作为Python工程师,深入了解AWS管理工具和库对于高效利用云资源至关重要。本文将引…...
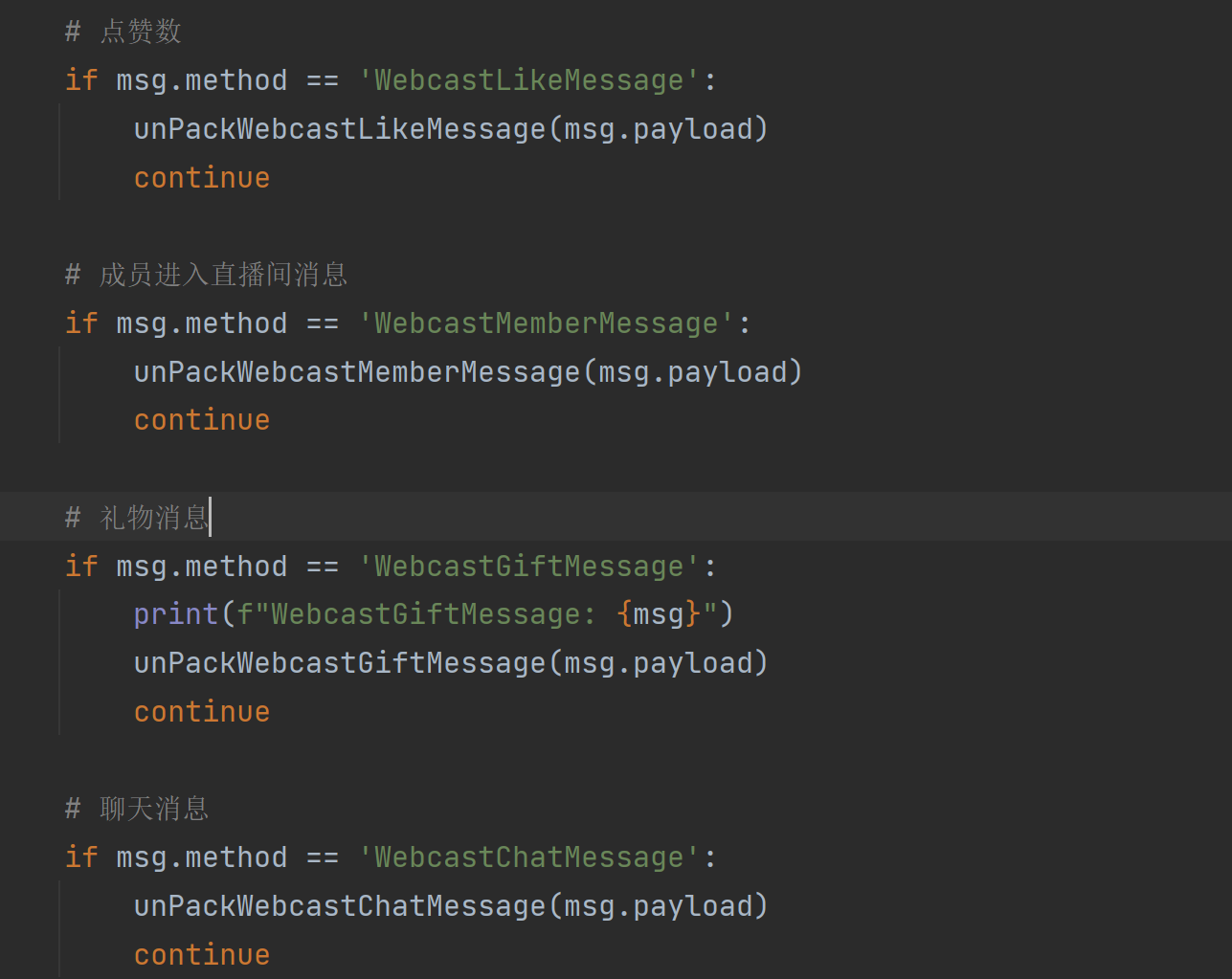
抖音直播间websocket礼物和弹幕消息推送可能出现重复的情况,解决办法
在抖音直播间里,通过websocket收到的礼物消息数据格式如下: {common: {method: WebcastGiftMessage,msgId: 7283420150152942632,roomId: 7283413007005207308,createTime: 1695803662805,isShowMsg: True,describe: 莎***:送给主播 1个入团卡,priority…...

【设计模式--行为型--访问者模式】
设计模式--行为型--访问者模式 访问者模式定义结构案例优缺点使用场景扩展分派动态分派静态分派双分派 访问者模式 定义 封装一些作用于某种数据结构中的各元素的操作,它可以在不改变这个数据结构的前提下定义作用于这些元素的新操作。 结构 抽象访问者角色&…...
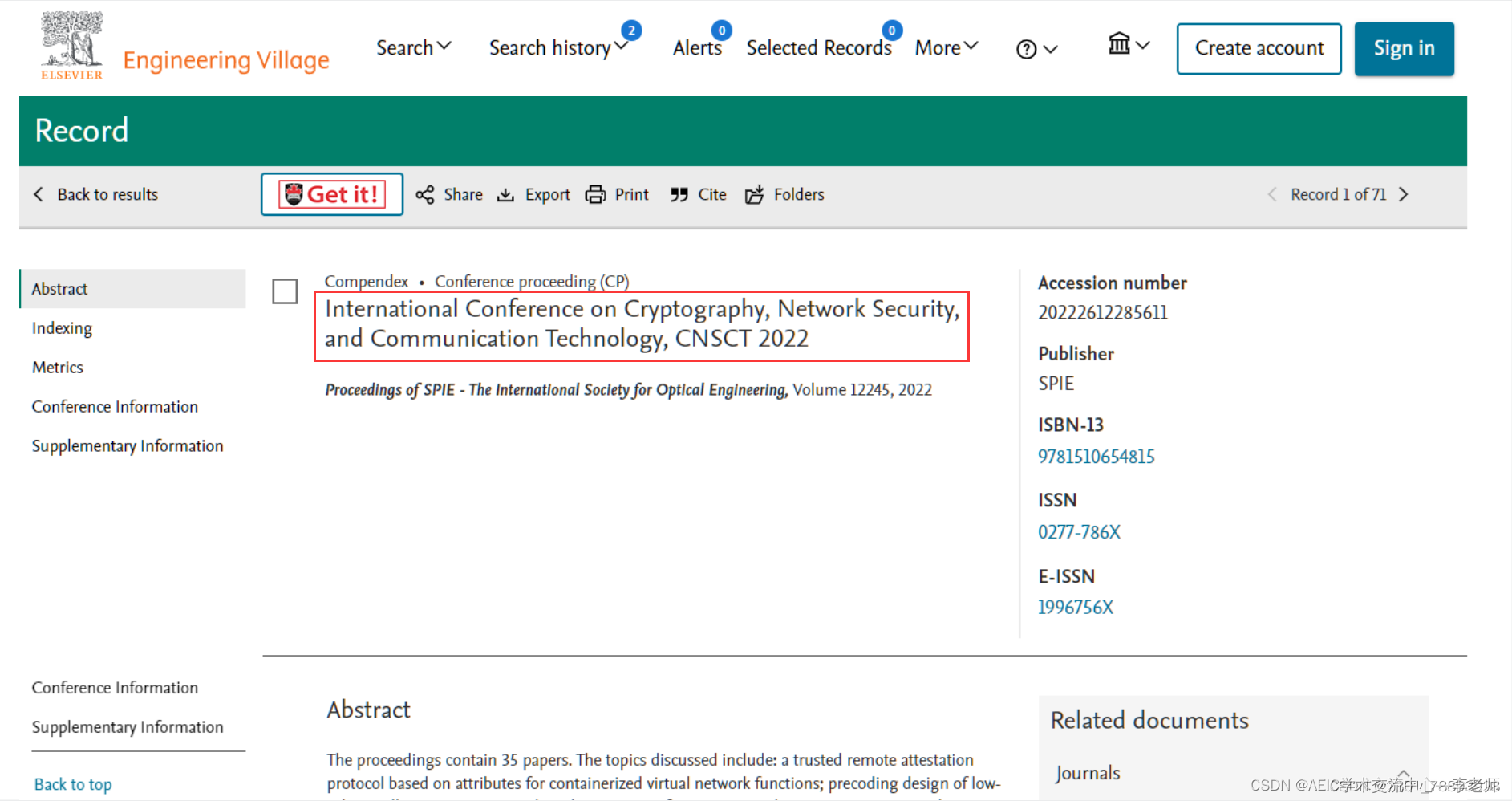
[最后一个月征稿、ACM独立出版】第三届密码学、网络安全和通信技术国际会议(CNSCT 2024)
第三届密码学、网络安全和通信技术国际会议(CNSCT 2024) 2024 3rd International Conference on Cryptography, Network Security and Communication Technology 一、大会简介 随着互联网和网络应用的不断发展,网络安全在计算机科学中的地…...

android —— PopupWindow
一、常用方法: 1、设置显示的位置 // 一个参数 popupWindow.showAsDropDown(v); //参数1: popupWindow关联的view // 参数2和3:相对于关联控件的偏移量popupWindow.showAsDropDown(View anchor, int xoff, int yoff)2、是否会获取焦点 popupWindow.se…...
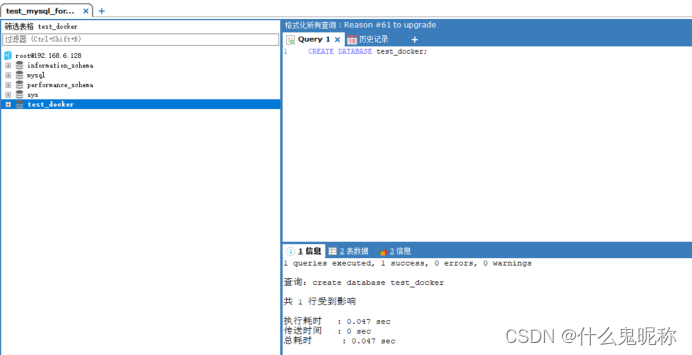
mysql部署 --(docker)
先查找MySQL 镜像 Docker search mysql ; 拉取mysql镜像,默认拉取最新的; 创建mysql容器,-p 代表端口映射,格式为 宿主机端口:容器运行端口 -e 代表添加环境变量,MYSQL_ROOT_PASSWORD是root用户…...

基于多智能体系统一致性算法的电力系统分布式经济调度策略MATLAB程序
微❤关注“电气仔推送”获得资料(专享优惠) 参考文献: 主要内容: 应用多智能体系统中的一致性算法,以发电机组的增量成本和柔性负荷的增量效益作为一致性变量,设计一种用于电力系统经济调度的算法&#x…...
Android : SensorManager 传感器入门 简单应用
功能介绍:转动手机 图片跟着旋转 界面: activity_main.xml <?xml version"1.0" encoding"utf-8"?> <androidx.constraintlayout.widget.ConstraintLayout xmlns:android"http://schemas.android.com/apk/res/andr…...

《点云处理》 点云去噪
前言 通常从传感器(3D相机、雷达)中获取到的点云存在噪点(杂点、离群点、孤岛点等各种叫法)。噪点产生的原因有不同,可能是扫描到了不想要扫描的物体,可能是待测工件表面反光形成的,也可能是相…...
npm login报错:Public registration is not allowed
npm login报错:Public registration is not allowed 1.出现场景2.解决 1.出现场景 npm login登录时,出现 2.解决 将自己的npm镜像源改为npm的https://registry.npmjs.org/这个,解决!...

OpenHarmony 启动流程优化
目前rk3568的开机时间有21s,统计的是关机后从按下 power 按键到显示锁屏的时间,当对openharmony的系统进行了裁剪子系统,系统app,禁用部分服务后发现开机时间仅仅提高到了20.94s 优化微乎其微。在对init进程的log进行分析并解决其…...

解决腾讯云CentOS 6硬盘空间不足问题:从快照到数据迁移
引言: 随着数据的不断增加,服务器硬盘空间不足变成了许多运维人员必须面对的问题。此主机运行了httpd(apache服务),提供对外web访问服务,web资源挂载在**/data/wwwroot目录下,http日志存放在/data/wwwlogs目录下&…...

org.slf4j日志组件实现日志功能
slf4j 全称是Simple Logging Facade for Java。facade是一种设计模式。 slf4j 是一个抽象程度更高的日志组件,本身并不提供实际的日志功能。实际的日志功能是通过log4j等日志组件实现,而使用者只需要关心 slf4j 给出的API。 slf4j 仅仅是一个为Java程序提…...
3D小球跑酷
目录 一、前言 二、开发环境 三、场景搭建 1. 创建项目 2. 创建场景内物体 2.1 创建跑道 2.2 创建玩家 2.3 创建障碍物 2.4 改变跑道和障碍物的颜色 2.4.1 创建材质 2.4.2 给跑道和障碍物更换材质 四、功能脚本实现 1. 创建玩家脚本 2. 相机跟随 3. 胜负的判定 3.1 …...
PyQt6 QInputDialog输入对话框控件
锋哥原创的PyQt6视频教程: 2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~_哔哩哔哩_bilibili2024版 PyQt6 Python桌面开发 视频教程(无废话版) 玩命更新中~共计50条视频,包括:2024版 PyQt6 Python桌面开发 视频教程(无废话版…...

ASP.NET Core MVC依赖注入理解(极简个人版)
依赖注入 文献来源:《Pro ASP.NET Core MVC》 Adam Freeman 第18章 依赖注入 1 依赖注入原理 所有可能变化的地方都用接口在使用接口的地方用什么实体类通过在ConfigureService中注册解决注册的实体类需要指定在何种生命周期中有效 TransientScopedSingleton 2…...

美光将于 2025 年推出 1γ DRAM,并在日本生产HBM
美国内存巨头美光正准备从 2025 年开始在其位于日本广岛的晶圆厂生产最先进的“1γ”DRAM。同时,公司计划在同一晶圆厂生产高带宽存储器(HBM),以满足对生成式人工智能应用日益增长的需求。 据《日经亚洲》12月13日报道࿰…...

【Docker】以service形式离线安装卸载的docker、compose服务
CentOS7离线卸载Docker步骤 移除开机自启 [rootCenOS-1 system]# systemctl disable docker移除注册文件 rm -rf /etc/systemd/system/docker.service删除相关安装目录 rm -rf $(find / -name docker)CentOS7离线安装Docker、Compose步骤 资源地址:docker_20.10…...

Dubbo RPC-Redis协议
Redis协议 特性说明 Redis 是一个高效的 KV 存储服务器。基于 Redis 实现的 RPC 协议。 2.3.0 以上版本支持。 使用场景 缓存,限流,分布式锁等 使用方式 引入依赖 从 Dubbo 3 开始,Redis 协议已经不再内嵌在 Dubbo 中,需要单…...

Cursor实现用excel数据填充word模版的方法
cursor主页:https://www.cursor.com/ 任务目标:把excel格式的数据里的单元格,按照某一个固定模版填充到word中 文章目录 注意事项逐步生成程序1. 确定格式2. 调试程序 注意事项 直接给一个excel文件和最终呈现的word文件的示例,…...

【算法训练营Day07】字符串part1
文章目录 反转字符串反转字符串II替换数字 反转字符串 题目链接:344. 反转字符串 双指针法,两个指针的元素直接调转即可 class Solution {public void reverseString(char[] s) {int head 0;int end s.length - 1;while(head < end) {char temp …...

人工智能(大型语言模型 LLMs)对不同学科的影响以及由此产生的新学习方式
今天是关于AI如何在教学中增强学生的学习体验,我把重要信息标红了。人文学科的价值被低估了 ⬇️ 转型与必要性 人工智能正在深刻地改变教育,这并非炒作,而是已经发生的巨大变革。教育机构和教育者不能忽视它,试图简单地禁止学生使…...

JavaScript基础-API 和 Web API
在学习JavaScript的过程中,理解API(应用程序接口)和Web API的概念及其应用是非常重要的。这些工具极大地扩展了JavaScript的功能,使得开发者能够创建出功能丰富、交互性强的Web应用程序。本文将深入探讨JavaScript中的API与Web AP…...
提供了哪些便利?)
现有的 Redis 分布式锁库(如 Redisson)提供了哪些便利?
现有的 Redis 分布式锁库(如 Redisson)相比于开发者自己基于 Redis 命令(如 SETNX, EXPIRE, DEL)手动实现分布式锁,提供了巨大的便利性和健壮性。主要体现在以下几个方面: 原子性保证 (Atomicity)ÿ…...

iview框架主题色的应用
1.下载 less要使用3.0.0以下的版本 npm install less2.7.3 npm install less-loader4.0.52./src/config/theme.js文件 module.exports {yellow: {theme-color: #FDCE04},blue: {theme-color: #547CE7} }在sass中使用theme配置的颜色主题,无需引入,直接可…...

c# 局部函数 定义、功能与示例
C# 局部函数:定义、功能与示例 1. 定义与功能 局部函数(Local Function)是嵌套在另一个方法内部的私有方法,仅在包含它的方法内可见。 • 作用:封装仅用于当前方法的逻辑,避免污染类作用域,提升…...

Linux 下 DMA 内存映射浅析
序 系统 I/O 设备驱动程序通常调用其特定子系统的接口为 DMA 分配内存,但最终会调到 DMA 子系统的dma_alloc_coherent()/dma_alloc_attrs() 等接口。 关于 dma_alloc_coherent 接口详细的代码讲解、调用流程,可以参考这篇文章,我觉得写的非常…...

【免费数据】2005-2019年我国272个地级市的旅游竞争力多指标数据(33个指标)
旅游业是一个城市的重要产业构成。旅游竞争力是一个城市竞争力的重要构成部分。一个城市的旅游竞争力反映了其在旅游市场竞争中的比较优势。 今日我们分享的是2005-2019年我国272个地级市的旅游竞争力多指标数据!该数据集源自2025年4月发表于《地理学报》的论文成果…...

JS红宝书笔记 - 3.3 变量
要定义变量,可以使用var操作符,后跟变量名 ES实现变量初始化,因此可以同时定义变量并设置它的值 使用var操作符定义的变量会成为包含它的函数的局部变量。 在函数内定义变量时省略var操作符,可以创建一个全局变量 如果需要定义…...