Flink系列之:SQL提示
Flink系列之:SQL提示
- 一、动态表选项
- 二、语法
- 三、例子
- 四、查询提示
- 五、句法
- 六、加入提示
- 七、播送
- 八、随机散列
- 九、随机合并
- 十、嵌套循环
- 十一、LOOKUP
- 十二、进一步说明
- 十三、故障排除
- 十四、连接提示中的冲突案例
- 十五、什么是查询块
SQL 提示可以与 SQL 语句一起使用来更改执行计划。本章解释如何使用提示来强制执行各种方法。
一般来说,提示可用于:
- 执行计划器:没有完美的计划器,因此实现提示以让用户更好地控制执行是有意义的;
- 附加元数据(或统计信息):一些统计信息,例如“扫描的表索引”和“某些洗牌键的倾斜信息”对于查询来说有些动态,使用提示配置它们会非常方便,因为我们来自规划器的规划元数据很多时候并不那么准确;
- 算子资源限制:在很多情况下,我们会给执行算子一个默认的资源配置,即最小并行度或托管内存(资源消耗UDF)或特殊资源要求(GPU或SSD磁盘)等等,这将非常灵活使用每个查询的提示(而不是作业)来分析资源。
一、动态表选项
动态表选项允许动态指定或覆盖表选项,与使用 SQL DDL 或连接 API 定义的静态表选项不同,这些选项可以在每个查询的每个表范围内灵活指定。
因此它非常适合用于交互式终端中的临时查询,例如,在 SQL-CLI 中,您可以通过添加动态选项 /*+ OPTIONS(’ 来指定忽略 CSV 源的解析错误csv.ignore-parse-errors’=‘true’) */。
二、语法
为了不破坏SQL兼容性,我们使用Oracle风格的SQL提示语法:
table_path /*+ OPTIONS(key=val [, key=val]*) */key:stringLiteral
val:stringLiteral
三、例子
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);-- 覆盖查询源中的表选项
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;-- 覆盖连接中的表选项
select * fromkafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1joinkafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2on t1.id = t2.id;-- 覆盖 INSERT 目标表的表选项
insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2;
四、查询提示
查询提示可用于建议优化器影响指定查询范围内的查询执行计划。它们的有效范围是指定查询提示的当前查询块(什么是查询块?)。现在,Flink Query Hints 仅支持 Join Hints。
五、句法
Flink 中的查询提示语法遵循 Apache Calcite 中的查询提示语法:
# Query Hints:
SELECT /*+ hint [, hint ] */ ...hint:hintName| hintName '(' optionKey '=' optionVal [, optionKey '=' optionVal ]* ')'| hintName '(' hintOption [, hintOption ]* ')'optionKey:simpleIdentifier| stringLiteraloptionVal:stringLiteralhintOption:simpleIdentifier| numericLiteral| stringLiteral
六、加入提示
连接提示允许用户向优化器建议连接策略,以获得更高性能的执行计划。现在 Flink Join Hints 支持 BROADCAST、SHUFFLE_HASH、SHUFFLE_MERGE 和 NEST_LOOP。
笔记:
- 连接提示中指定的表必须存在。否则,将抛出表不存在错误。
- Flink Join Hints 只支持一个查询块中包含一个提示块,如果指定多个提示块,如 /*+ BROADCAST(t1) / /+ SHUFFLE_HASH(t1) */,则解析该查询语句时会抛出异常。
- 在一个提示块中,在单个连接提示中指定多个表,例如 /*+ BROADCAST(t1, t2, …, tn) / 或指定多个连接提示,例如 /+ BROADCAST(t1), BROADCAST(t2), …、BROADCAST(tn) */ 均受支持。
- 对于单个 Join Hints 中的多个表或一个hint 块中的多个 Join Hints,Flink Join Hints 可能会发生冲突。如果发生冲突,Flink 将选择最匹配的表或连接策略。 (参见:连接提示中的冲突案例)
七、播送
批
BROADCAST 建议 Flink 使用 BroadCast join。无论table.optimizer.join.broadcast-threshold如何,带有hint的join端都会被广播,因此当表的hint端数据量很小时,它表现良好。
注意:BROADCAST 仅支持等价连接条件的连接,不支持 Full Outer Join。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用广播连接,t1 将是广播表。
SELECT /*+ BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用广播连接来进行连接,并且 t1、t3 将是广播表。
SELECT /*+ BROADCAST(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- BROADCAST 不支持非等价连接条件。
-- Join Hint 将不起作用,并且只能应用嵌套循环连接。
SELECT /*+ BROADCAST(t1) */ * FROM t1 join t2 ON t1.id > t2.id;-- BROADCAST 不支持完全外连接。
-- 这种情况下Join Hint不起作用,规划器会根据成本选择合适的Join策略。
SELECT /*+ BROADCAST(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
八、随机散列
批
SHUFFLE_HASH建议Flink使用Shuffle Hash join。带hint的join端将是join构建端,当表的hint端数据量不太大时,它表现良好。
注意:SHUFFLE_HASH 仅支持等价连接条件的连接。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用哈希连接,t1 将作为构建端。
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用 hash join 进行连接,t1、t3 将作为连接构建端。
SELECT /*+ SHUFFLE_HASH(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_HASH 不支持非等价连接条件。
-- 对于这种情况,Join Hint 将不起作用,只能应用嵌套循环连接。
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
九、随机合并
批
SHUFFLE_MERGE 建议 Flink 使用 Sort Merge join。这种类型的Join Hint推荐用于两个大表之间的Join场景或者Join两边的数据都已经有序的场景。
注意:SHUFFLE_MERGE 仅支持具有等价连接条件的连接。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- 采用排序合并连接策略。
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- 这两种连接均采用排序合并连接策略。
SELECT /*+ SHUFFLE_MERGE(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_MERGE don't support non-equivalent join conditions.
-- Join Hint will not work, and only nested loop join can be applied.
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
– SHUFFLE_MERGE 不支持非等价连接条件。
– Join Hint 将不起作用,并且只能应用嵌套循环连接。
十、嵌套循环
批
NEST_LOOP 建议 Flink 使用 Nested Loop join。如果没有特殊场景需求,不建议使用此类连接提示。
注意:NEST_LOOP 支持等效和非等效连接条件。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用嵌套循环连接,t1 将作为构建端。
SELECT /*+ NEST_LOOP(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用嵌套循环连接来进行连接,t1、t3 将是连接构建端。
SELECT /*+ NEST_LOOP(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
十一、LOOKUP
流
LOOKUP 提示允许用户建议 Flink 优化器:
- 使用同步(sync)或异步(async)查找功能
- 配置异步参数
- 启用查找的延迟重试策略
查找提示选项:
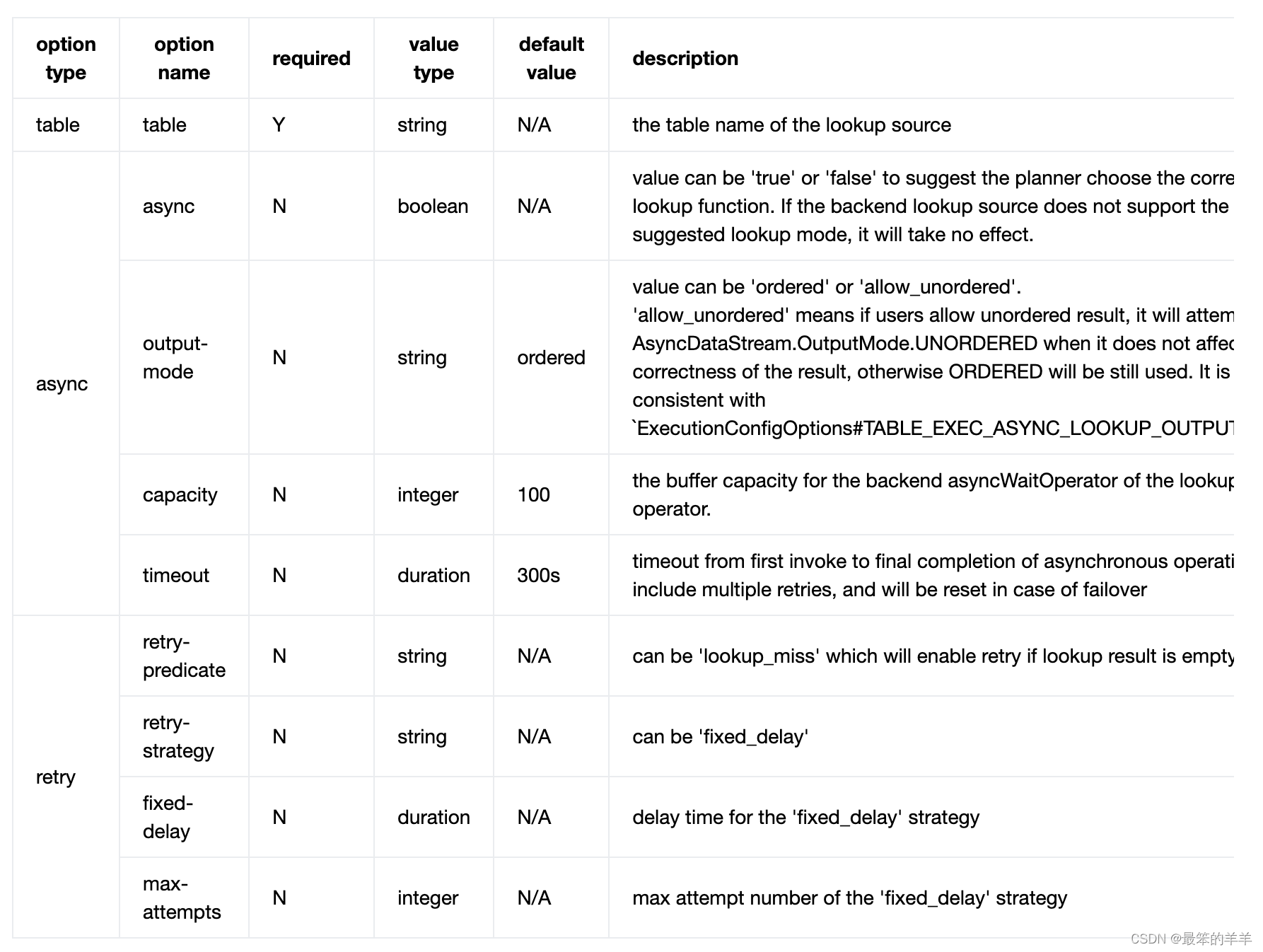
笔记:
- 'table’选项为必填项,仅支持表名(与FROM子句中的保持一致),注意如果表有别名,则只能使用别名。
- async选项都是可选的,如果没有配置将使用默认值。
重试选项没有默认值,需要启用重试时,所有重试选项都应设置为有效值。
1.使用同步和异步查找功能#
如果连接器同时具有异步和同步查找功能,则用户可以指定选项值“async”=“false”以建议规划器使用同步查找或“async”=“true”以使用异步查找:
例子:
-- suggest the optimizer to use sync lookup
LOOKUP('table'='Customers', 'async'='false')-- suggest the optimizer to use async lookup
LOOKUP('table'='Customers', 'async'='true')
注意:如果未指定“async”选项,优化器更喜欢异步查找,在以下情况下它将始终使用同步查找:
- 连接器仅实现同步查找
- 用户启用“table.optimizer.non-definistic-update.strategy”的“TRY_RESOLVE”模式,并且优化器已检查是否存在由非确定性更新引起的正确性问题。
- 配置异步参数 #
用户可以通过异步查找模式下的异步选项配置异步参数。
例子:
-- configure the async parameters: 'output-mode', 'capacity', 'timeout', can set single one or multi params
LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
注意:异步选项与作业级别执行选项中的异步选项一致,如果不设置将使用作业级别配置。另一个区别是LOOKUP提示的范围更小,仅限于当前查找操作中设置的提示选项对应的表名(其他查找操作不会受到LOOKUP提示的影响)。
例如,如果作业级别配置是:
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
然后出现以下提示:
1. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered')
2. LOOKUP('table'='Customers', 'async'='true', 'timeout'='300s')
相当于:
3. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
4. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='ordered', 'capacity'='100', 'timeout'='300s')
- 启用查找延迟重试策略 #
查找连接的延迟重试旨在解决外部系统延迟更新导致流数据意外丰富的问题。提示选项’retry-predicate’='lookup_miss’可以启用同步和异步查找重试,目前仅支持固定延迟重试策略。
固定延迟重试策略选项:
'retry-strategy'='fixed_delay'
-- fixed delay duration
'fixed-delay'='10s'
-- max number of retry(counting from the retry operation, if set to '1', then a single lookup process
-- for a specific lookup key will actually execute up to 2 lookup requests)
'max-attempts'='3'
例子:
1.启用异步查找重试
LOOKUP('table'='Customers', 'async'='true', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
2.启用同步查找重试
LOOKUP('table'='Customers', 'async'='false', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
如果查找源只有一种功能,则可以省略“异步”模式选项:
LOOKUP('table'='Customers', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
十二、进一步说明
启用缓存对重试的影响
FLIP-221 增加了对查找源的缓存支持,有 PARTIAL 和 FULL 缓存模式(NONE 模式表示禁用缓存)。当启用完整缓存时,根本不会重试(因为通过查找源的完整缓存镜像重试查找是没有意义的)。当启用 PARTIAL 缓存时,它将首先从本地缓存查找即将到来的记录,如果缓存未命中,将通过后端连接器进行外部查找(如果缓存命中,则立即返回记录),这将在查找结果时触发重试为空(与禁用缓存相同),重试完成时确定最终查找结果(在PARTIAL缓存模式下,也会更新本地缓存)。
关于查找键和‘retry-predicate’=‘lookup_miss’重试条件的注意事项
对于不同的连接器,索引查找能力可能会有所不同,例如内置的HBase连接器只能在rowkey上查找(没有二级索引),而内置的JDBC连接器可以提供更强大的任意列的索引查找能力,这是由不同的连接器决定的。物理存储。这里提到的查找键是索引查找的字段或字段组合,以查找连接为例,其中c.id是连接条件“ON o.customer_id = c.id”的查找键:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id
如果我们将连接条件更改为“ON o.customer_id = c.id and c.country = ‘US’”:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id and c.country = 'US'
当 Customers 表存储在 MySql 中时,c.id 和 c.country 都将用作查找键:
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
)
当Customers表存储在HBase中时,只有c.id可以作为查找键,其余连接条件c.country = 'US’将在查找结果返回后进行评估
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'hbase-2.2',...
)
因此,当启用“lookup_miss”重试谓词和固定延迟重试策略时,上述查询将对不同存储产生不同的重试效果。
例如,如果 Customers 表中有一行:
id=100, country='CN'
在处理订单流中id=100的记录时,在jdbc连接器中,对应的查找结果为空(country='CN’不满足条件c.country = ‘US’),因为c.country=‘US’。 id 和 c.country 用作查找键,因此这将触发重试。
当在’hbase’连接器中时,仅使用c.id作为查找键,相应的查找结果不会为空(会返回记录id=100,country=‘CN’),因此不会触发重试(对于返回的记录,剩余的连接条件 c.country = ‘US’ 将被评估为不正确)。
目前基于SQL语义考虑,只提供了lookup_miss重试谓词,当需要等待维度表的延迟更新时(表中已经存在而不是不存在历史版本记录),用户可以使用可以尝试两种解决方案:
- 使用 DataStream Async I/O 中新的重试支持实现自定义重试谓词(允许对返回的记录进行更复杂的判断)。
- 通过添加另一个连接条件(包括比较由时间戳生成的某种数据版本)来启用延迟重试,对于上面的示例,假设 Customers 表每小时更新一次,我们可以添加一个新的与时间相关的版本字段 update_version,该字段保留为每小时精度,例如,记录的更新时间“2022-08-15 12:01:02”会将 update_version 存储为“2022-08-15 12:00”
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING,-- the newly added time-dependent version fieldupdate_version STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
)
将 Order 流的时间字段和 Customers.update_version 上的相等条件附加到连接条件:
ON o.customer_id = c.id AND DATE_FORMAT(o.order_timestamp, 'yyyy-MM-dd HH:mm') = c.update_version
那么当Order的记录无法在Customers表中查找到‘12:00’版本的新记录时,我们可以启用延迟重试。
十三、故障排除
当开启延迟重试查找时,查找节点更有可能遇到背压问题,这可以通过Web ui“任务管理器”页面上的“线程转储”快速确认。分别从异步和同步查找中,线程睡眠的调用堆栈将出现在:
- 异步查找:RetryableAsyncLookupFunctionDelegator
- 同步查找:RetryableLookupFunctionDelegator
笔记:
- 带重试的异步查找无法对所有输入数据进行固定延迟处理(应使用其他较轻的方法来解决,例如挂起的源消耗或使用带重试的同步查找)
- 同步查找中延迟等待重试执行是完全同步的,即,直到当前记录完成后才开始处理下一条记录。
- 在异步查找中,如果“output-mode”为“ORDERED”模式,则延迟重试导致背压的概率可能高于“UNORDERED”模式,在这种情况下,增加异步“容量”可能无法有效减少背压,并且可能有必要考虑缩短延迟时间。
十四、连接提示中的冲突案例
如果 Join Hints 发生冲突,Flink 会选择最匹配的一个。
- 如果同一个Join Hint策略发生冲突,Flink会选择第一个匹配的表进行Join。
- 当不同的Join Hints策略发生冲突时,Flink会选择第一个匹配的hint进行Join。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Conflict in One Same Join Hints Strategy Case-- The first hint will be chosen, t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2), BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- BROADCAST(t2, t1) will be chosen, and t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2, t1), BROADCAST(t1, t2) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- This case equals to BROADCAST(t1, t2) + BROADCAST(t3),
-- when join between t1 and t2, t1 will be the broadcast table,
-- when join between the result after t1 join t2 and t3, t3 will be the broadcast table.
SELECT /*+ BROADCAST(t1, t2, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- Conflict in Different Join Hints Strategies Case-- The first Join Hint (BROADCAST(t1)) will be chosen, and t1 will be the broadcast table.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Although BROADCAST is first one hint, but it doesn't support full outer join,
-- so the following SHUFFLE_HASH(t1) will be chosen, and t1 will be the join build side.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;-- Although there are two Join Hints were defined, but all of them are neither support non-equivalent join,
-- so only nested loop join can be applied.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id > t2.id;
十五、什么是查询块
查询块是SQL的基本单元。例如,任何内联视图或 SQL 语句的子查询都被视为与外部查询不同的查询块。
例子:
一条 SQL 语句可以由多个子查询组成。子查询可以是 SELECT、INSERT 或 DELETE。子查询可以在 FROM 子句、WHERE 子句或 UNION 或 UNION ALL 的子查询中包含其他子查询。
对于这些不同的子查询或视图类型,它们可以由多个查询块组成,例如:
下面的简单查询只有一个子查询,但它有两个查询块 - 一个用于外部 SELECT,另一个用于子查询 SELECT。

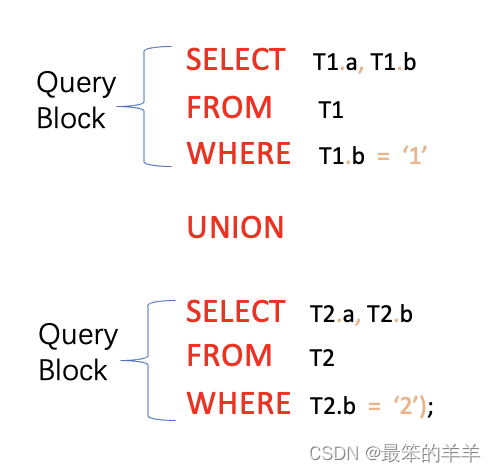
下面的查询是一个联合查询,它包含两个查询块 - 一个用于第一个 SELECT,另一个用于第二个 SELECT。
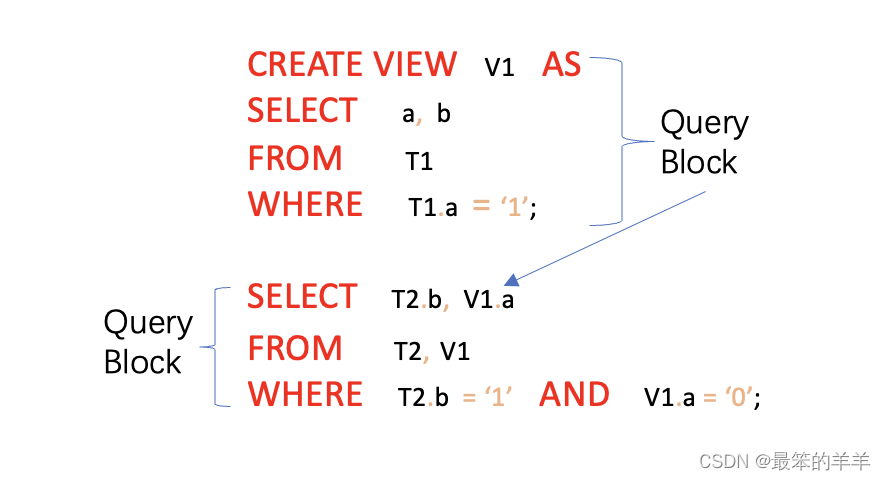
下面的查询包含一个视图,它有两个查询块 - 一个用于外部 SELECT,另一个用于视图。
相关文章:
Flink系列之:SQL提示
Flink系列之:SQL提示 一、动态表选项二、语法三、例子四、查询提示五、句法六、加入提示七、播送八、随机散列九、随机合并十、嵌套循环十一、LOOKUP十二、进一步说明十三、故障排除十四、连接提示中的冲突案例十五、什么是查询块 SQL 提示可以与 SQL 语句一起使用来…...
机器学习算法---聚类
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统计学检验箱…...
gitlab ci pages
参考文章 gitlab pages是什么 一个可以利用gitlab的域名和项目部署自己静态网站的机制 开启 到gitlab的如下页面 通过gitlab.ci部署项目的静态网站 # build ruby 1/3: # stage: build # script: # - echo "ruby1"# build ruby 2/3: # stage: build …...
Web ML 库的Transformers.js 提供文本转语音功能
JavaScript 库 Transformers.js 提供了类似 Python Transformers 库的功能,设计用于在 Web 浏览器中直接运行 Transformer 模型,而不再需要外部服务器参与处理。在最新的 2.7 版本中,Transformers.js 引入了增强功能,其中包括文本…...

管理类联考——数学——真题篇——按题型分类——充分性判断题——蒙猜E
老老规矩,看目录,平均每年2E,跟2D一样,D是全对,E是全错,侧面也看出10道题,大概是3A/B,3C,2D,2E,其实还是蛮平均的。但E为1道的情况居多。 第20题…...
】)
【Linux基本指令(2)】
文章目录 一. 基本指令第二回 一. 基本指令第二回 cp指令语法 cp src dst 将目标文件或者目录拷贝到指定目录下或文件下。注意同级目录下,不允许存在同名文件或同名目录。如果将一个file.txt文件拷贝到当前目录下,就重名了,报错cp不了&#…...

Debian系统设置SSH密钥登陆
如果没有安装ssh,root权限运行apt install openssh-server进行安装。 ssh-keygen -t rsa # 生成配对密钥,后续一路enter即可会在用户目录(即~这个)下生成.ssh文件夹,里面的id_rsa是私钥,id_rsa.pub是公钥…...

uniapp cli开发和HBuilderX开发
uniapp cli开发和HBuilderX开发 前言 uniapp是一个跨平台的开发框架,可以开发出微信小程序、支付宝小程序、百度小程序、头条小程序、H5、App等,开发者只需要写一套代码,就可以发布到各个平台,大大提高了开发效率。 uniapp的开…...
【Java异常】idea 报错:无效的目标发行版:17 的解决办法
【Java异常】idea 报错:无效的目标发行版:17 的解决办法 一,问题来源 springcloud的第一个demo项目就给我干趴了 二、原因分析 java: 无效的目标发行版: 17 原因就是 JDK 版本不对。从 IDEA 编辑器中可以找到问题的原因所在,…...

代码提交规范-ESLint+Prettier+husky+Commitlint
代码提交规范-ESLintPrettierhuskyCommitlint 配置eslint (3步)配置prettier(4步)1.安装配置prettier2.设置忽略文件 .prettierignore3.处理eslint冲突4. 配置vscode 的settings.json husky安装并配置lint-staged(3步)安装配置com…...
)
手动实现 Vue 3的简易双向数据绑定(模仿源码)
Vue 3 带来了许多令人兴奋的新特性和改进,其中之一就是其双向数据绑定的实现方式。与 Vue 2 使用 Object.defineProperty 不同,Vue 3 利用了 JavaScript 的 Proxy 特性来创建响应式数据。在这篇博客中,我们将探讨 Vue 3 中双向数据绑定的基础…...
LVS最终奥义之DR直接路由模式
1 LVS-DR(直接路由模式) 1.1 LVS-DR模式工作过程 1.客户端通过VIP将访问请求报文(源IP为客户端IP,目标IP为VIP)发送到调度器 2.调度器通过调度算法选择最适合的节点服务器并重新封装数据报文(将源mac地址改为调度器的mac地址&am…...
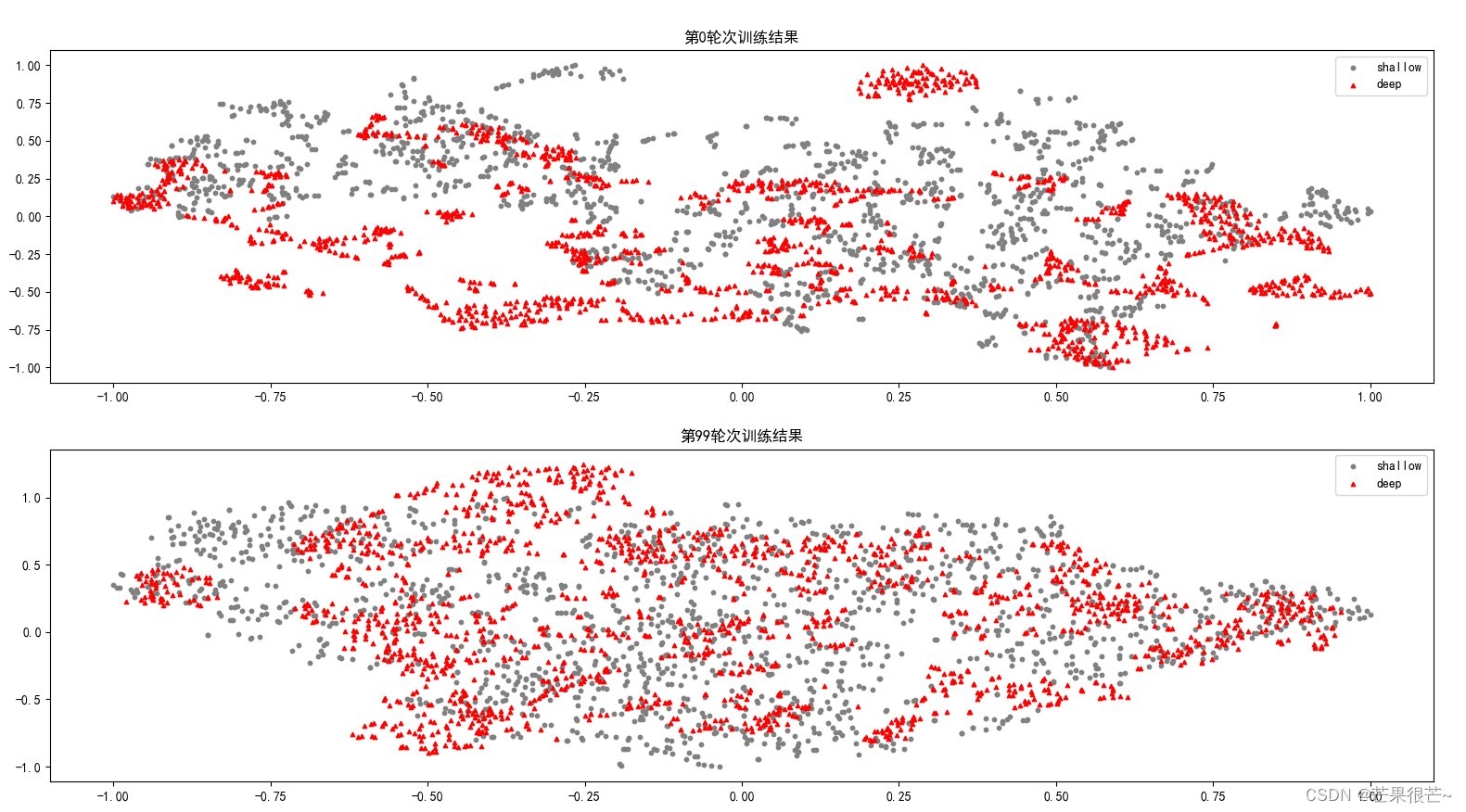
t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as plt from sklearn import manifold, datasets """对S型曲线数据的降维和可视化"&q…...

配置应用到k8s
配置应用到k8s,前置条件是安装了Docker,Minikube,kubectl 应用已经通过Docker生成本地镜像文件 1,创建godemo-deployment.yaml apiVersion: apps/v1kind: Deploymentmetadata:name: godemo-deploymentspec:replicas: 3 #启动三个…...

(四)STM32 操作 GPIO 点亮 LED灯 / GPIO工作模式
目录 1. STM32 工程模板中的工程目录介绍 2. GPIO 简介 3. GPIO 框图剖析 1)保护二极管及上、下拉电阻 2) P-MOS 管和 N-MOS 管 3)输出数据寄存器 3.1)ODR 端口输出数据寄存器 3.2)BSRR 端口位设置/清除寄存器 4&a…...
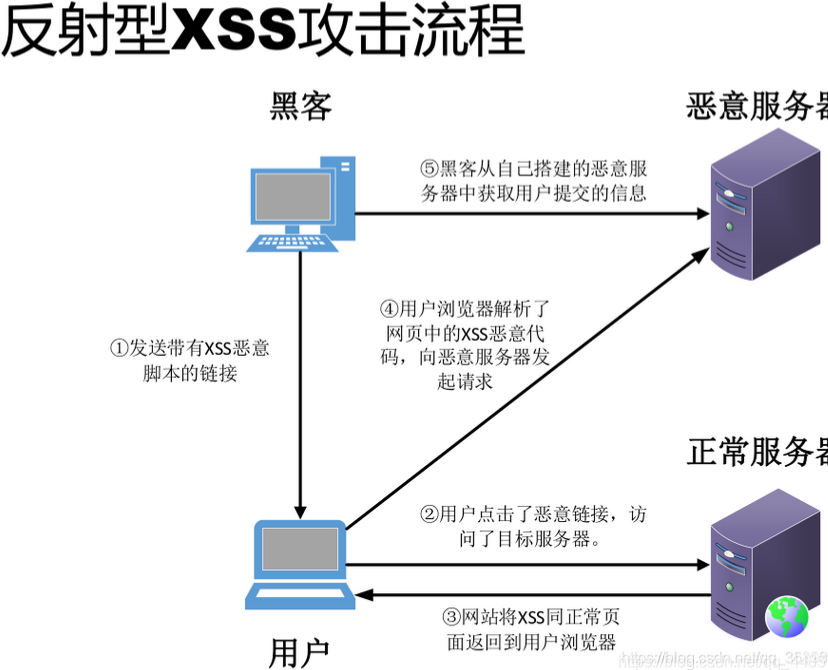
你知道跨站脚本攻击吗?一篇带你了解什么叫做XSS
1.XSS简介 (1)XSS简介 XSS作为OWASP TOP 10之一。 XSS中文叫做跨站脚本攻击(Cross-site scripting),本名应该缩写为CSS,但是由于CSS(Cascading Style Sheets,层叠样式脚本&#x…...
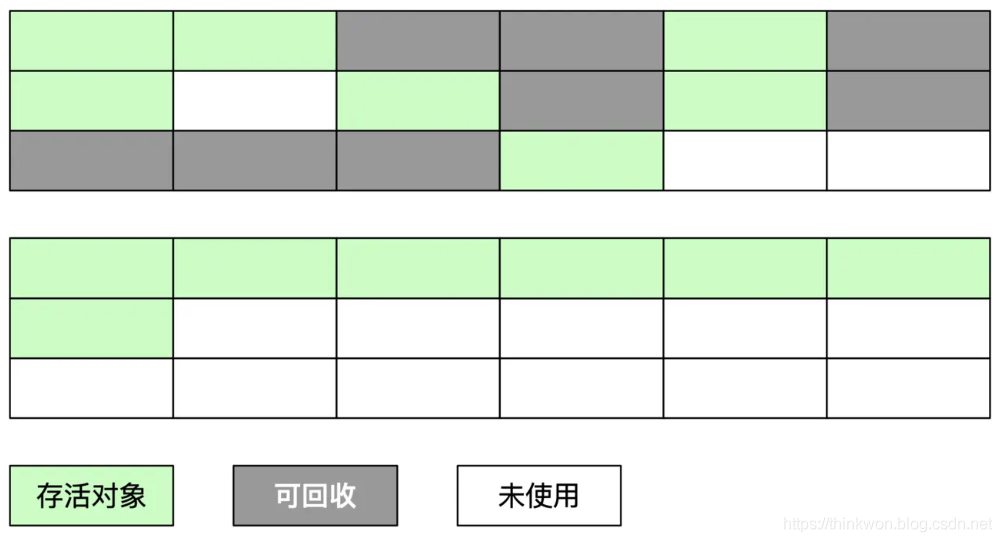
JVM入门
JVM概述 JVM位置 JVM体系结构 注意:栈中一定不存在垃圾,栈中数据用完一个弹出一个,总结来说,栈区、本地方法栈、程序计数器这三块必定不存在垃圾。JVM调优主要是针对方法区、堆(99%)进行调优。 常用的第三…...
)
Cmake基础(5)
这篇文章主要描述如何使用cmake构建一个库工程 文章目录 add_libraryinstall 库工程的代码:头文件和源文件 #ifndef ADD_H #define ADD_H#ifdef _WIN32 #ifdef MYMATH_EXPORTS #define MYMATH_API __declspec(dllexport) #else #define MYMATH_API __declspec(dll…...

Rabbitmq 死信取消超时订单
本文使用的版本 otp_win64_25.0rabbitmq-server-3.11.26rabbitmq插件 rabbitmq_delayed_message_exchange-3.11.1 pom.xml文件 <dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-amqp</artifactId> …...

C语言—每日选择题—Day55
指针相关博客 打响指针的第一枪:指针家族-CSDN博客 深入理解:指针变量的解引用 与 加法运算-CSDN博客 第一题 1. 若有如下定义,则 p1&m;p2p1; 是正确赋值语句.说法是否正确? int *p1; int *p2; int m …...

定时器任务——若依源码分析
分析util包下面的工具类schedule utils: ScheduleUtils 是若依中用于与 Quartz 框架交互的工具类,封装了定时任务的 创建、更新、暂停、删除等核心逻辑。 createScheduleJob createScheduleJob 用于将任务注册到 Quartz,先构建任务的 JobD…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

三体问题详解
从物理学角度,三体问题之所以不稳定,是因为三个天体在万有引力作用下相互作用,形成一个非线性耦合系统。我们可以从牛顿经典力学出发,列出具体的运动方程,并说明为何这个系统本质上是混沌的,无法得到一般解…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

HDFS分布式存储 zookeeper
hadoop介绍 狭义上hadoop是指apache的一款开源软件 用java语言实现开源框架,允许使用简单的变成模型跨计算机对大型集群进行分布式处理(1.海量的数据存储 2.海量数据的计算)Hadoop核心组件 hdfs(分布式文件存储系统)&a…...

回溯算法学习
一、电话号码的字母组合 import java.util.ArrayList; import java.util.List;import javax.management.loading.PrivateClassLoader;public class letterCombinations {private static final String[] KEYPAD {"", //0"", //1"abc", //2"…...

【分享】推荐一些办公小工具
1、PDF 在线转换 https://smallpdf.com/cn/pdf-tools 推荐理由:大部分的转换软件需要收费,要么功能不齐全,而开会员又用不了几次浪费钱,借用别人的又不安全。 这个网站它不需要登录或下载安装。而且提供的免费功能就能满足日常…...

多模态图像修复系统:基于深度学习的图片修复实现
多模态图像修复系统:基于深度学习的图片修复实现 1. 系统概述 本系统使用多模态大模型(Stable Diffusion Inpainting)实现图像修复功能,结合文本描述和图片输入,对指定区域进行内容修复。系统包含完整的数据处理、模型训练、推理部署流程。 import torch import numpy …...
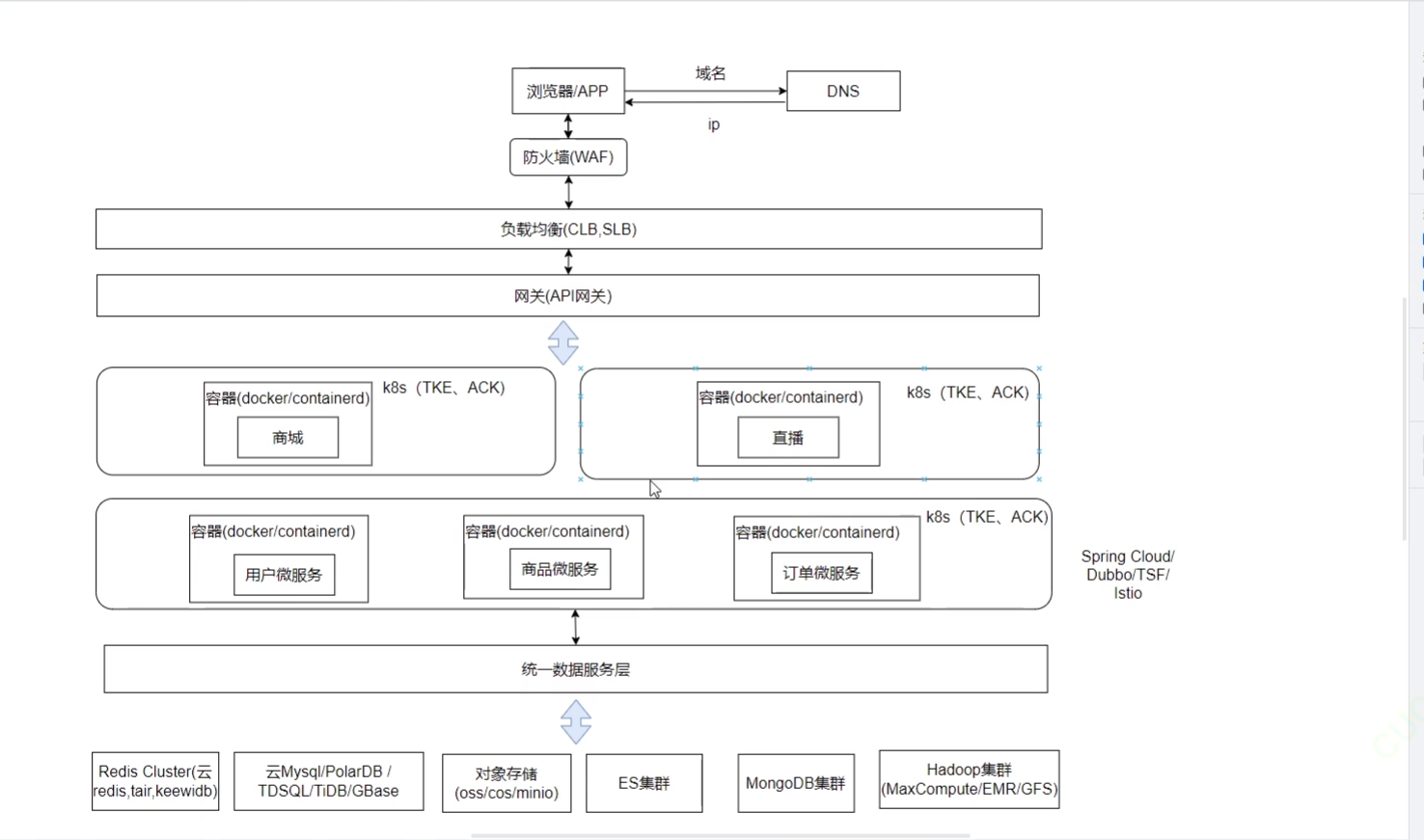
《Docker》架构
文章目录 架构模式单机架构应用数据分离架构应用服务器集群架构读写分离/主从分离架构冷热分离架构垂直分库架构微服务架构容器编排架构什么是容器,docker,镜像,k8s 架构模式 单机架构 单机架构其实就是应用服务器和单机服务器都部署在同一…...
之(六) ——通用对象池总结(核心))
怎么开发一个网络协议模块(C语言框架)之(六) ——通用对象池总结(核心)
+---------------------------+ | operEntryTbl[] | ← 操作对象池 (对象数组) +---------------------------+ | 0 | 1 | 2 | ... | N-1 | +---------------------------+↓ 初始化时全部加入 +------------------------+ +-------------------------+ | …...