scrapy快加构造并发送请求
scrapy数据建模与请求
学习目标:
- 应用 在scrapy项目中进行建模
- 应用 构造Request对象,并发送请求
- 应用 利用meta参数在不同的解析函数中传递数据
1. 数据建模
通常在做项目的过程中,在items.py中进行数据建模
1.1 为什么建模
- 定义item即提前规划好哪些字段需要抓,防止手误,因为定义好之后,在运行过程中,系统会自动检查
- 配合注释一起可以清晰的知道要抓取哪些字段,没有定义的字段不能抓取,在目标字段少的时候可以使用字典代替
- 使用scrapy的一些特定组件需要Item做支持,如scrapy的ImagesPipeline管道类,百度搜索了解更多
1.2 如何建模
在items.py文件中定义要提取的字段:
# Define here the models for your scraped items
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.htmlimport scrapy
class DoubanItem(scrapy.Item):# define the fields for your item here like:name = scrapy.Field() # 名字content = scrapy.Field() # 内容link = scrapy.Field() # 链接txt = scrapy.Field() #详情介绍
1.3 如何使用模板类
模板类定义以后需要在爬虫中导入并且实例化,之后的使用方法和使用字典相同
job.py:
from myspider.items import MyspiderItem # 导入Item,注意路径
...def parse(self, response)item = MyspiderItem() # 实例化后可直接使用item['name'] = node.xpath('./h3/text()').extract_first()item['title'] = node.xpath('./h4/text()').extract_first()item['desc'] = node.xpath('./p/text()').extract_first()print(item)
注意:
- from myspider.items import MyspiderItem这一行代码中 注意item的正确导入路径,忽略pycharm标记的错误
- python中的导入路径要诀:从哪里开始运行,就从哪里开始导入
1.4 开发流程总结
- 创建项目
scrapy startproject 项目名 - 明确目标
在items.py文件中进行建模 - 创建爬虫
3.1 创建爬虫
scrapy genspider 爬虫名 允许的域
3.2 完成爬虫
修改start_urls
检查修改allowed_domains
编写解析方法 - 保存数据
在pipelines.py文件中定义对数据处理的管道
在settings.py文件中注册启用管道
2. 翻页请求的思路
对于要提取如下图中所有页面上的数据该怎么办?

回顾requests模块是如何实现翻页请求的:
- 找到下一页的URL地址
- 调用requests.get(url)
scrapy实现翻页的思路:
- 找到下一页的url地址
- 构造url地址的请求对象,传递给引擎
3. 构造Request对象,并发送请求
3.1 实现方法
- 确定url地址
- 构造请求,scrapy.Request(url,callback)
- callback:指定解析函数名称,表示该请求返回的响应使用哪一个函数进行解析
- 把请求交给引擎:yield scrapy.Request(url,callback)
3.2 网易招聘爬虫
通过爬取豆瓣新书速递的页面信息,学习如何实现翻页请求
地址: https://book.douban.com/latest?icn=index-latestbook-all
思路分析:
- 获取首页的数据
- 寻找下一页的地址,进行翻页,获取数据
注意:
- 可以在settings中设置ROBOTS协议
# False表示忽略网站的robots.txt协议,默认为True
ROBOTSTXT_OBEY = False
- 可以在settings中设置User-Agent:
# scrapy发送的每一个请求的默认UA都是设置的这个User-Agent
USER_AGENT = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.115 Safari/537.36'
scrapy.Request的更多参数
scrapy.Request(url[,callback,method="GET",headers,body,cookies,meta,dont_filter=False])
参数解释
- 中括号里的参数为可选参数
- callback:表示当前的url的响应交给哪个函数去处理
- meta:实现数据在不同的解析函数中传递,meta默认带有部分数据,比如下载延迟,请求深度等
- dont_filter:默认为False,会过滤请求的url地址,即请求过的url地址不会继续被请求,对需要重复请求的url地址可以把它设置为Ture,比如贴吧的翻页请求,页面的数据总是在变化;start_urls中的地址会被反复请求,否则程序不会启动
- method:指定POST或GET请求
- headers:接收一个字典,其中不包括cookies
- cookies:接收一个字典,专门放置cookies
- body:接收json字符串,为POST的数据,发送payload_post请求时使用(在下一章节中会介绍post请求)
4. meta参数的使用
meta的作用:meta可以实现数据在不同的解析函数中的传递
在爬虫文件的parse方法中,提取详情页增加之前callback指定的parse_detail函数:
def parse(self,response):...yield scrapy.Request(detail_url, callback=self.parse_detail,meta={"item":item})
...def parse_detail(self,response):#获取之前传入的itemitem = resposne.meta["item"]
特别注意
- meta参数是一个字典
- meta字典中有一个固定的键
proxy,表示代理ip,关于代理ip的使用我们将在scrapy的下载中间件的学习中进行介绍
小结
- 完善并使用Item数据类:
- 在items.py中完善要爬取的字段
- 在爬虫文件中先导入Item
- 实力化Item对象后,像字典一样直接使用
- 构造Request对象,并发送请求:
- 导入scrapy.Request类
- 在解析函数中提取url
- yield scrapy.Request(url, callback=self.parse_detail, meta={})
- 利用meta参数在不同的解析函数中传递数据:
- 通过前一个解析函数 yield scrapy.Request(url, callback=self.xxx, meta={}) 来传递meta
- 在self.xxx函数中 response.meta.get(‘key’, ‘’) 或 response.meta[‘key’] 的方式取出传递的数据
相关文章:
scrapy快加构造并发送请求
scrapy数据建模与请求 学习目标: 应用 在scrapy项目中进行建模应用 构造Request对象,并发送请求应用 利用meta参数在不同的解析函数中传递数据 1. 数据建模 通常在做项目的过程中,在items.py中进行数据建模 1.1 为什么建模 定义item即提前…...

【C++】谈谈深拷贝与浅拷贝
目录 一、浅拷贝 1.定义 2.示例 3.问题 二、深拷贝 1.定义 2.示例 3.优点 三、考虑场景 浅拷贝的考虑 1.性能要求 2.简单地数据结构 3.资源管理 深拷贝的考虑 1.动态内存分配 2.复杂数据结构 3.资源管理 总结 一、浅拷贝 1.定义 浅拷贝是指对对象进行复制时…...

电商API接口如何驱动业务:代码演示与解析
随着电子商务的飞速发展,电商平台的业务逻辑日益复杂,涉及的模块和功能也越来越多。在这个过程中,电商API接口扮演着至关重要的角色。通过API接口,不同的业务模块可以相互通信,实现数据和服务的共享,提高业…...

秋招总结_就业
2020秋招总结 【前言】 以下内容是写给研二学弟学妹们的秋招总结,研一的师弟师妹们如有需要,也可看看。先说一下我为什么要写这个总结: 1、时代在变化,社会在发展,一届有必要给下一届讲一些经验。 2、我平时和你们…...

基于查表法的水流量算法设计与实现
写在前面 本文分享的是一种基于查表法的水流量的算法方案设计与实现,算法简单易懂,主要面向初学者,有两个目的:一是给初学者一些算法设计的思路引导;二是引导初学者学习怎样用C语言编程实现。 一、设计需求 基于“19…...

Python:复制、移动文件到指定文件夹
需要考虑的问题: 指定文件夹是否存在,不存在则创建在指定文件夹中是否存在同名文件,是覆盖还是另存为 import os import shutil import tracebackdef copyfile(srcfile, dstpath, replaceFalse):"""复制文件到指定文件夹par…...
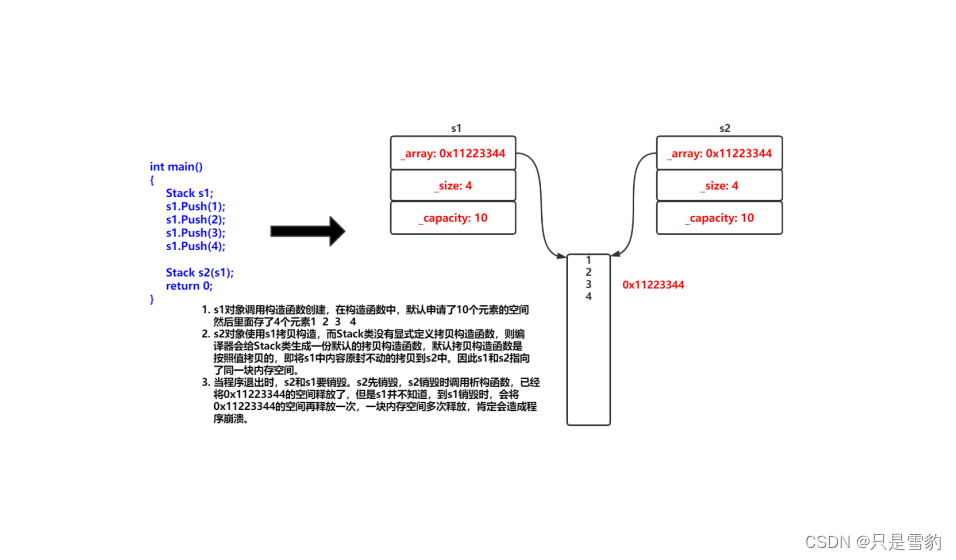
类和对象(中篇)
类的六个默认成员函数 如果一个类中什么成员都没有,简称为空类。 空类中真的什么都没有吗?并不是,任何类在什么都不写时,编译器会自动生成以下6个默认成员函数。 默认成员函数: 用户没有显式实现,编译器会…...
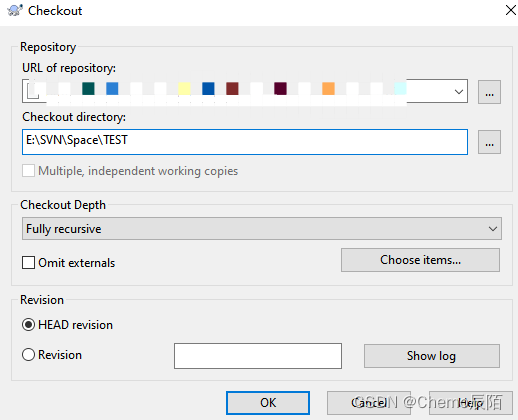
简单几步完成SVN的安装
介绍以及特点 SVN:Subversion,即版本控制系统。 1.代码版本管理工具 2.查看所有的修改记录 3.恢复到任何历史版本和已经删除的文件 4.使用简单上手快,企业安全必备 下载安装 SVN的安装分为两部分,第一部分是服务端安装&…...
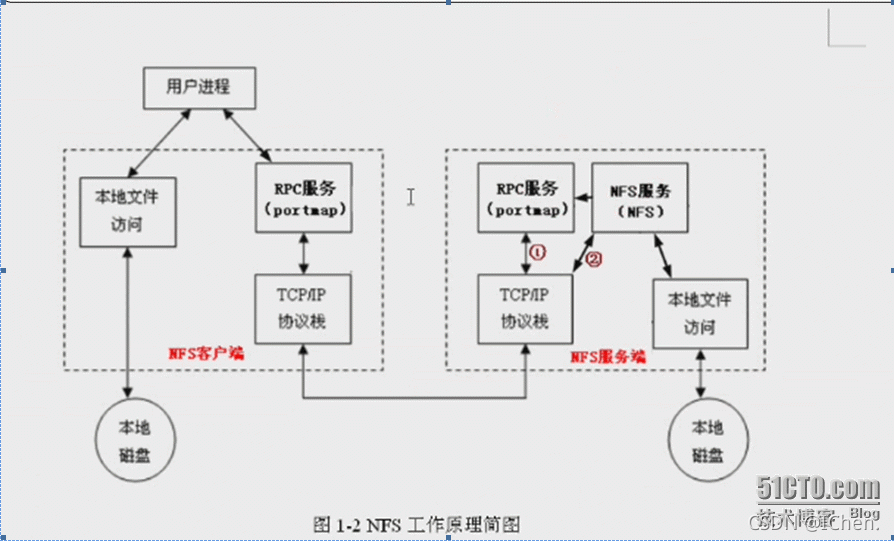
NFS原理详解
一、NFS介绍 1)什么是NFS 它的主要功能是通过网络让不同的机器系统之间可以彼此共享文件和目录。 NFS服务器可以允许NFS客户端将远端NFS服务器端的共享目录挂载到本地的NFS客户端中。 在本地的NFS客户端的机器看来,NFS服务器端共享的目录就好像自己的磁…...
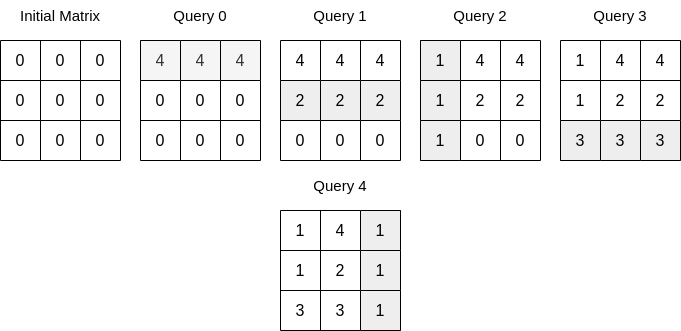
查询后矩阵的和
说在前面 🎈不知道大家对于算法的学习是一个怎样的心态呢?为了面试还是因为兴趣?不管是出于什么原因,算法学习需要持续保持。 问题描述 给你一个整数 n 和一个下标从 0 开始的 二维数组 queries ,其中 queries[i] [t…...

Flutter实现丝滑的滑动删除、移动排序等-Dismissible控件详解
文章目录 Dismissible 简介使用场景常用属性基本用法举例注意事项 Dismissible 简介 Dismissible 是 Flutter 中用于实现可滑动删除或拖拽操作的一个有用的小部件。主要用于在用户对列表项或任何其他可滑动的元素执行删除或拖动操作时,提供一种简便的实现方式。 使…...
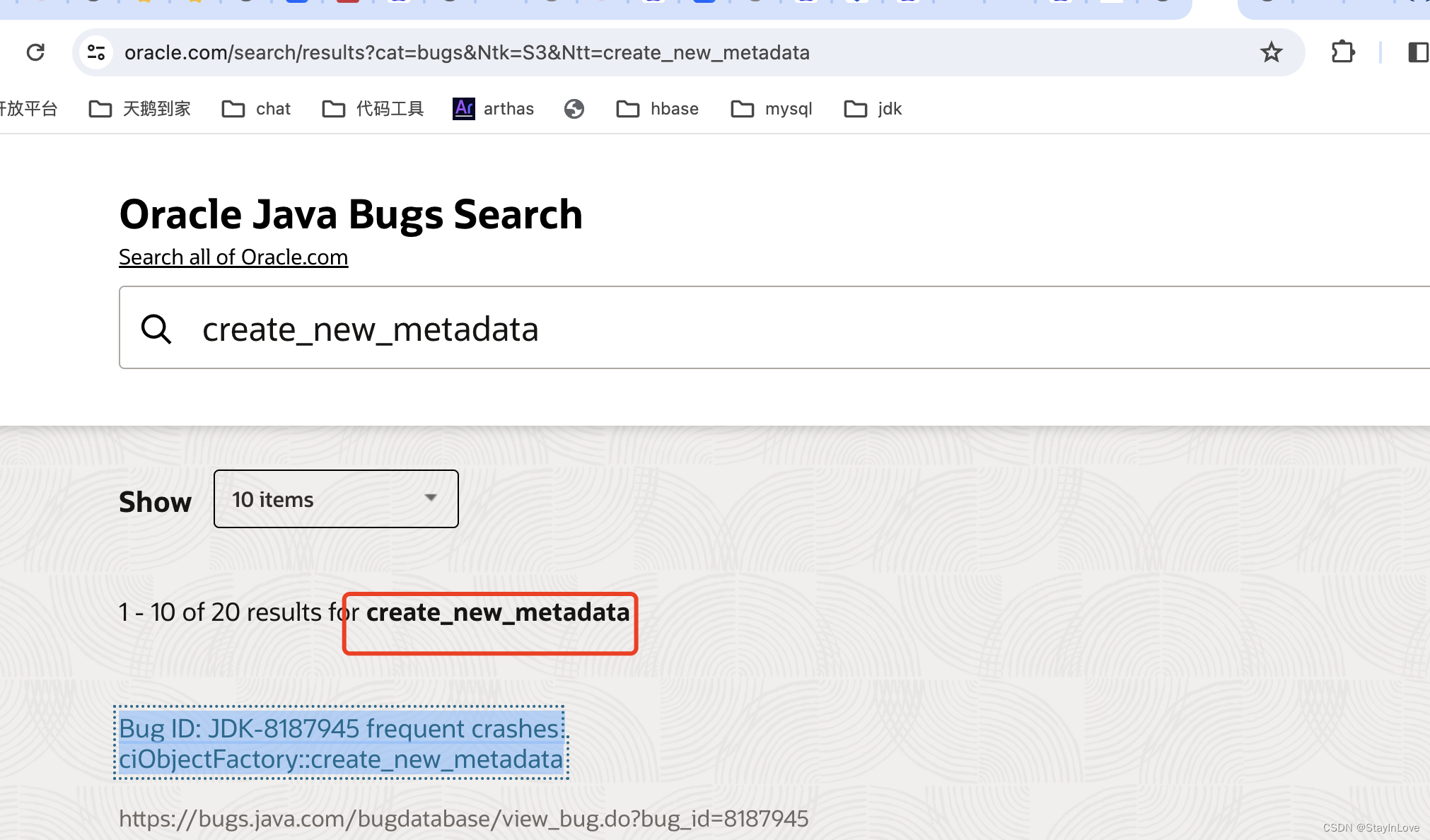
JDK bug:ciObjectFactory::create_new_metadata:原因完全解析
文章目录 1、问题2.详细日志2.关键日志3.结论4.JDK:bug最终bug链接: 京东遇到过类似bug各位大佬如果有更详细的解答可以留言。 1、问题 服务不通,接口404,查看日志有一下截图,还有一个更详细的日志 2.详细日志 # #…...
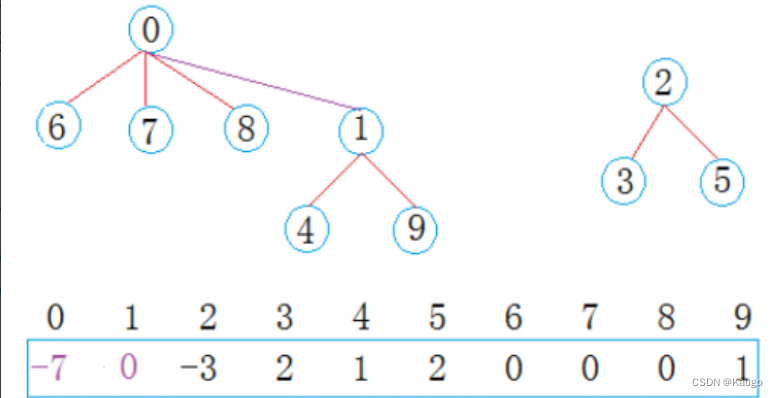
【数据结构】并查集的简单实现,合并,查找(C++)
文章目录 前言举例: 一、1.构造函数2.查找元素属于哪个集合FindRoot3.将两个集合归并成一个集合Union4.查找集合数量SetCount 二、源码 前言 需要将n个不同的元素划分成一些不相交的集合。开始时,每个元素自成一个单元素集合,然后按一定的规…...
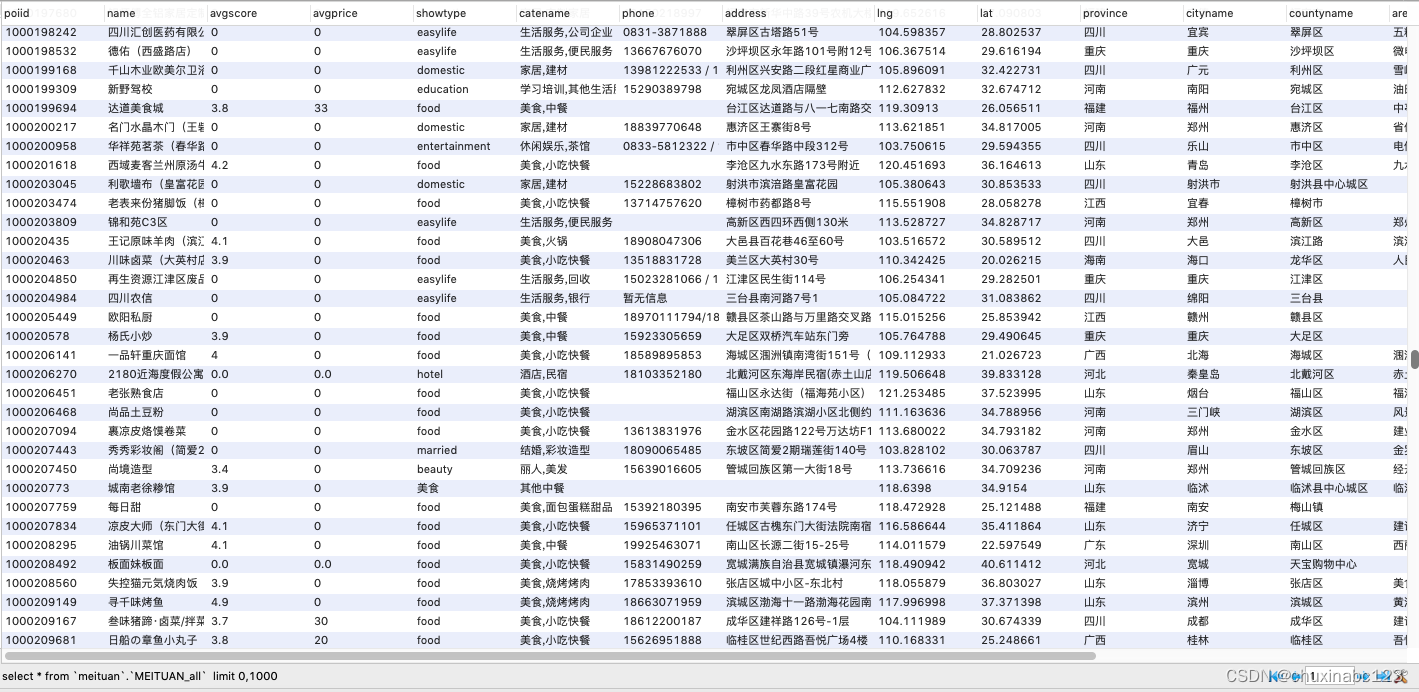
2023美团商家信息
2023美团商家电话、地址、经纬度、评分、均价、执照......

0155 - Java 数组
1 数组介绍 数组可以存放多个同一类型的数据。数组也是一种数据类型,是引用类型。 即:数(数据)组(一组)就是一组数据 2 数组的使用 2.1 使用方式一 2.2 使用方式二 3 数组使用注意事项和细节 数组是多个相同类型数据的组合,实现对这些数据…...

Java 语言有哪些特点
Java语言具有以下特点: 简单易学:Java语法相对简单,与C相比更容易上手。 面向对象:Java是一门纯粹的面向对象编程语言,支持封装、继承和多态等面向对象的特性。 平台无关性:Java程序可以在不同的操作系统…...

SAP 特殊采购类50简介----虚拟件
今天我们测试一下特殊类50,也就是我们常说的虚拟件。 虚拟物料是库存中实际不存在的物料清单(BOM)的子装配件,它用于简化物料清单。尽管虚拟物料出现在物料清单中,但生产订单显示制造虚拟物料所需的组件,而不是虚拟物料本身。 我们举个列子,生产的手机是有包装的,有盒子…...

C语言——内存函数的使用与模拟实现
大家好,我是残念,希望在你看完之后,能对你有所帮助,有什么不足请指正!共同学习交流 本文由:残念ing 原创CSDN首发,如需要转载请通知 个人主页:残念ing-CSDN博客,欢迎各位…...
)
Mysql索引事务(面试高频)
文章目录 目录 文章目录 前言 一 . 索引 1.1 概念 1.2 作用 1.3 使用场景 1.4 存储引擎 二 . 事务 2.1 事务的概念 2.2 事务四大特性 前言 大家好,今天给大家绍一下mysql索引和事务 一 . 索引 1.1 概念 索引是一种特殊的文件,包含着对数据表中的所有记录的引用指针…...

SpringCloudGateway 3.1.4版本 Netty内存泄漏问题解决
一、 产生的异常 当时是服务器访问不到服务了,上去一看,无法申请资源OutOfDirectMemoryError了,内存级别的东西让人一阵头大,赶紧在线下模拟, 1. 减少分配的堆外内存,打开Netty的监测工具等有助于复现的…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

深度学习水论文:mamba+图像增强
🧀当前视觉领域对高效长序列建模需求激增,对Mamba图像增强这方向的研究自然也逐渐火热。原因在于其高效长程建模,以及动态计算优势,在图像质量提升和细节恢复方面有难以替代的作用。 🧀因此短时间内,就有不…...

【JVM】Java虚拟机(二)——垃圾回收
目录 一、如何判断对象可以回收 (一)引用计数法 (二)可达性分析算法 二、垃圾回收算法 (一)标记清除 (二)标记整理 (三)复制 (四ÿ…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

【p2p、分布式,区块链笔记 MESH】Bluetooth蓝牙通信 BLE Mesh协议的拓扑结构 定向转发机制
目录 节点的功能承载层(GATT/Adv)局限性: 拓扑关系定向转发机制定向转发意义 CG 节点的功能 节点的功能由节点支持的特性和功能决定。所有节点都能够发送和接收网格消息。节点还可以选择支持一个或多个附加功能,如 Configuration …...
零知开源——STM32F103RBT6驱动 ICM20948 九轴传感器及 vofa + 上位机可视化教程
STM32F1 本教程使用零知标准板(STM32F103RBT6)通过I2C驱动ICM20948九轴传感器,实现姿态解算,并通过串口将数据实时发送至VOFA上位机进行3D可视化。代码基于开源库修改优化,适合嵌入式及物联网开发者。在基础驱动上新增…...

xmind转换为markdown
文章目录 解锁思维导图新姿势:将XMind转为结构化Markdown 一、认识Xmind结构二、核心转换流程详解1.解压XMind文件(ZIP处理)2.解析JSON数据结构3:递归转换树形结构4:Markdown层级生成逻辑 三、完整代码 解锁思维导图新…...

6️⃣Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙
Go 语言中的哈希、加密与序列化:通往区块链世界的钥匙 一、前言:离区块链还有多远? 区块链听起来可能遥不可及,似乎是只有密码学专家和资深工程师才能涉足的领域。但事实上,构建一个区块链的核心并不复杂,尤其当你已经掌握了一门系统编程语言,比如 Go。 要真正理解区…...

比较数据迁移后MySQL数据库和ClickHouse数据仓库中的表
设计一个MySQL数据库和Clickhouse数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...