Mysql索引事务(面试高频)
文章目录
目录
文章目录
前言
一 . 索引
1.1 概念
1.2 作用
1.3 使用场景
1.4 存储引擎
二 . 事务
2.1 事务的概念
2.2 事务四大特性
前言
大家好,今天给大家绍一下mysql索引和事务
一 . 索引
1.1 概念
索引是一种特殊的文件,包含着对数据表中的所有记录的引用指针。可以对表中的一列或者多列创建索引,并指定索引的类型,每一种索引都有各自的数据结构实现。
1.2 作用
- 数据库中的表、数据、索引之间的关系,类似于书架上的图书、书籍内容和书籍目录的关系。
- 索引所起的作用类似书籍目录,可用于快速定位、检索数据。
- 索引对于提高数据库的性能有很大的帮助。
1.3 使用场景
要考虑对数据库表的某列或某几列创建索引,需要考虑以下几点:
- 数据量较大,且经常对这些列进行条件查询。
- 该数据库表的插入操作,及对这些列的修改操作频率较低。
- 索引会占用额外的磁盘空间。
满足以上条件时,考虑对表中的这些字段创建索引,以提高查询效率。 反之,如果非条件查询列,或经常做插入、修改操作,或磁盘空间不足时,不考虑创建索引。
1.4 存储引擎
MySQL支持多种存储引擎,每种引擎都有其自己的特点和适用场景。以下是一些常见的MySQL存储引擎:
-
InnoDB:InnoDB是MySQL的默认存储引擎,它支持事务、行级锁定、外键约束等特性,适合于需要强大事务支持和并发控制的应用。
-
MyISAM:MyISAM是MySQL的另一种存储引擎,它不支持事务和行级锁定,但在读密集型应用中性能较好,适合用于数据仓库和日志等应用。
-
MEMORY:MEMORY存储引擎将数据存储在内存中,适合用于临时表和缓存等场景,具有快速访问速度。
-
NDB Cluster:NDB Cluster是MySQL的集群存储引擎,适合于高可用性和高性能的分布式数据库系统。
-
ARCHIVE:ARCHIVE存储引擎适合于需要高压缩比和低写入频率的存档数据。
存储引擎是mysql内部的一个模块,存储引擎模块提供了很多版本的实现,Innodb是当前最常用的存储引擎。
为什么Innodb是默认的存储引擎? 这取决于其内部的数据结构 ==> B+树
B+树 http://t.csdnimg.cn/ewuDZ
为什么B+树适合用作索引底层的数据结构来使用?
相比大家学过的数据结构也不少,在这么多的数据结构中适合进行查询并且性能相对较好的有
(哈希,红黑,B树) 其他的数据结构要么不适合进行查找或者就是效率上不是那么的好,像是平衡树
虽然查询的速度也是挺快的但是在插入数据的时候需要进行大量的旋转,效率自然而然的就下来了
1.为什么不使用红黑树?
内存占用: 红黑树每个节点包含的信息更多(包括颜色信息、指向父节点的指针等) 如果内存有限,需要存储的数据量又非常的大,这个是否只能将数据存入磁盘中,如果进行查询的话,需要进行大量的磁盘IO非常消耗时间
数据聚集性: 红黑树中数据直接没有关联性,不利于范围查询和顺序遍历
2.为什么不使用哈希表?
哈希表的效率不必多说O(1)的时间复杂度,基本上可以说吊打一切了,但是它有一个致命的缺陷,无法进行范围查询! 这限制了哈希表的应用场景
MEMORY存储引擎一般用于临时表和缓存等场景,这些场景下通常对于快速的数据访问更为重要,而不需要支持复杂的数据操作。因此,选择哈希数据结构可以更好地满足这些场景下的需求。
3.为什么不使用B树?
不稳定性: 对于B树来说,如果要查询的元素在根节点或者层次比较高的节点,可以做到很快的拿到元素, 但是如果要查询的节点在叶子节点,时间相对而言就会更多一些
稳定性对于数据库来说还是很重要的,在生活中也是很重要的,高考的摸底考试和正式高考,相差如果太大就直接g了
如果说没有B+树的话,B树也是算得上比较好的一种索引底层数据结构了,但是B+树是为索引而生的
4.为什么使用B+树?
1) 首先B+树起源于B树,是一颗N叉搜索树.树的高度是有限的,可以有效的降低磁盘IO的次数
2) 非常擅长范围查询,因为所有的值都存储在叶子结点
3) 稳定性好,所有的查询都是要落到叶子结点上的,查询和查询之间的时间开销是稳定的,不会出现B树的不稳定情况(三模600 高考500)
4) 由于叶子结点是全集,非叶子节点上只存储一个用来排序的key,数据库是按行组织数据的,创建索引的时候是针对一列进行创建,这就导致非叶子节点根本占不了多少空间,因为它存储的不过是一个用来排序的key(比如一个id) 这部分内容可以直接缓存到内存中
(硬盘上则是存储叶子结点和非叶子结点,在查询的时候可以把非叶子结点的内容加载到内存中,整个查询过程就是在内存中进行,进一步的减少了磁盘IO的次数)
二 . 事务
2.1 事务的概念
事务指逻辑上的一组操作,组成这组操作的各个单元,要么全部成功,要么全部失败。 在不同的环境中,都可以有事务。对应在数据库中,就是数据库事务。
start transaction rollback/commit 已经过时了,在现在的开发中事务被层层封装,这种最原始的在sql中穿插的命令已经用不到,不知道的也不必再了解.知道的也可以选择性遗忘
2.2 事务四大特性
开发中经常会遇到一些需要一气呵成的操作,即必须是同时成功或者是同时失败,这种操作业内称之为原子操作 ,为什么叫原子操作? 这是早期的一个错误观点被沿用至今(也没有修改的必要), 在人类的发展认知中曾经存在过 "原子是不可分割的最小单位" 这一说法,这一个错误观点就诞生了事务的四大特征之一 - 原子性中原子两字
举个例子: 张三给李四转账500元 首先张三的账户减去500 然后李四的账户加上500
这个时候如果张三的账户减少500,但是李四的账户并没有加上500,这个时候问题可就大了
所以事务的原子性是不可或缺的!
原子性: 事务要么同事成功,要么同时失败
再来思考一个问题,有没有一种可能,张三账户上减500元 李四账户上加50000000元,这个时候如果处理不好,那可就是"刑"了,有没有可能出现这么一个情况呢? 早期我不知道,但是有事务的一致性为我保驾护航,我想问题应该不大
一致性: 数据库操作前后,数据要能对得上
持久性(Durability):一旦事务提交,其所做的修改将会永久保存在数据库中,即使系统发生故障,这些修改也不会丢失。
隔离性: 多个事务并发执行时,各个事务的操作互不干扰。
并发执行时非常的常见的,mysql是一个客户端服务器结构的程序,一个服务器可以给多个客户端提供服务,如果多个客户端同时访问数据库,在客户端1提交的事务执行到一半时,客户端2提交的事务也过来了,这个时候数据库服务器需要同时并发处理这两个事务,这个时候我们应该怎么去处理呢?
如果我们希望数据库服务器的执行效率提高,这个时候就需要提高并发率,但是提高并发率可能会出现数据错误的情况,具体情况如下
脏读: 一个事务A正在写数据的的过程中,另一个事务B读取了同一个数据,接下来A又修改了数据,导致B之前读到的数据,是一个无效的数据/中间的数据(脏数据)
如何解决?
注意上面的措词, 写数据的过程中,另一个事务读取了同一个数据
如果在一个事务写的过程中,另一个或者多个事务无法去读取该数据,那么问题不就完美解决了吗?
这个操作称之为 "写加锁"
并发性降低了,隔离性提高了,效率降低了,数据准确性提高了
不可重复读: 并发执行事务的过程中如果事务A在多次读取同一个数据的时候,出现不同的情况,这就是不可重复读,意味着在A两次读取数据之间,有一个数据B修改并提交了数据
如何解决?
注意措词 A两次读取数据之间,有一个数据B修改并提交了数据 如果在A读取数据的过程中,其他的事务无法读取该数据不就完美解决了吗?
这个操作我们称之为 - "读"加锁
并发程度进一步降低,隔离性提高,效率降低,数据的准确性提高
幻读: 一个事务A在执行过程中,两次的读取操作,数据内容虽然没有改变,但是结果集变了,这种称之为 "幻读"
比如我在读A文件,你不能写A文件,但是你可以写其他的文件,这样我在读取的时候,读取的内容虽然没有变,但是结果集发生了改变
如何解决?
引入串行化方式解决幻读,什么是串行化? 完全没有并发 我在读A文件的时候,其他人什么也不能干
数据绝对安全,效率绝对低的离谱!
总结一波
事务的四大特性通常指的是ACID特性,即:
-
原子性(Atomicity):事务是一个不可分割的工作单位,要么全部执行,要么全部不执行。在事务执行过程中,如果发生错误或者中断,系统会将所有操作回滚到事务开始前的状态,保证数据的一致性。
-
一致性(Consistency):事务执行前后,数据库的完整性约束没有被破坏。即使在事务执行过程中发生了错误,系统也会保证数据库从一个一致的状态转移到另一个一致的状态。
-
隔离性(Isolation):多个事务并发执行时,各个事务的操作互不干扰。每个事务的操作对其他事务是隔离的,因此不会出现数据争用、幻读等问题。
-
持久性(Durability):一旦事务提交,其所做的修改将会永久保存在数据库中,即使系统发生故障,这些修改也不会丢失。
这些特性确保了事务在数据库系统中的可靠性和一致性,是数据库设计和管理中非常重要的概念。
常见的事务隔离级别包括:
-
读未提交(Read Uncommitted):允许一个事务读取另一个事务未提交的数据。这是最低的隔离级别,可能会导致脏读、不可重复读和幻读的问题。
-
读提交(Read Committed):保证一个事务不会读取另一个事务未提交的数据。这个级别可以避免脏读,但仍然可能出现不可重复读和幻读的问题。
-
可重复读(Repeatable Read):保证一个事务不会读取到另一个事务已提交的修改,从而避免了不可重复读的问题。但仍然可能出现幻读的问题。(Innodb默认隔离级别)
-
串行化(Serializable):最高的隔离级别,通过强制事务串行执行来避免脏读、不可重复读和幻读。这个级别能够确保事务之间的完全隔离,但会导致性能下降。
总结
这篇博客主要介绍了mysql数据库索引和事务的相关内容,下一篇博客见!
相关文章:
)
Mysql索引事务(面试高频)
文章目录 目录 文章目录 前言 一 . 索引 1.1 概念 1.2 作用 1.3 使用场景 1.4 存储引擎 二 . 事务 2.1 事务的概念 2.2 事务四大特性 前言 大家好,今天给大家绍一下mysql索引和事务 一 . 索引 1.1 概念 索引是一种特殊的文件,包含着对数据表中的所有记录的引用指针…...

SpringCloudGateway 3.1.4版本 Netty内存泄漏问题解决
一、 产生的异常 当时是服务器访问不到服务了,上去一看,无法申请资源OutOfDirectMemoryError了,内存级别的东西让人一阵头大,赶紧在线下模拟, 1. 减少分配的堆外内存,打开Netty的监测工具等有助于复现的…...
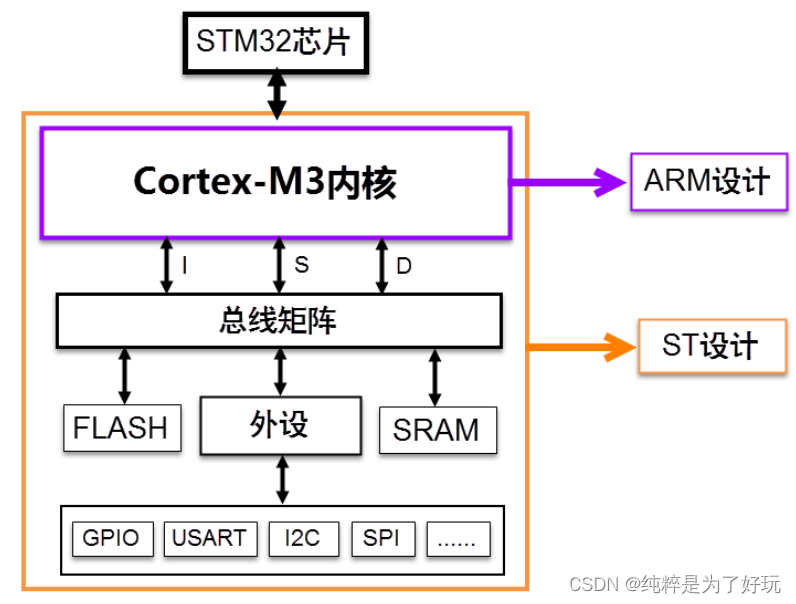
STM32内部是怎么工作的
STM32是怎么工作的 1 从孩子他妈说起2 早期计算机的组成2.1 五大元件(1)第一个出场的是电容元件(2)第二个出场的是二极管(3)第三个出场的是电阻元件(4)第四个出场的是电感࿰…...
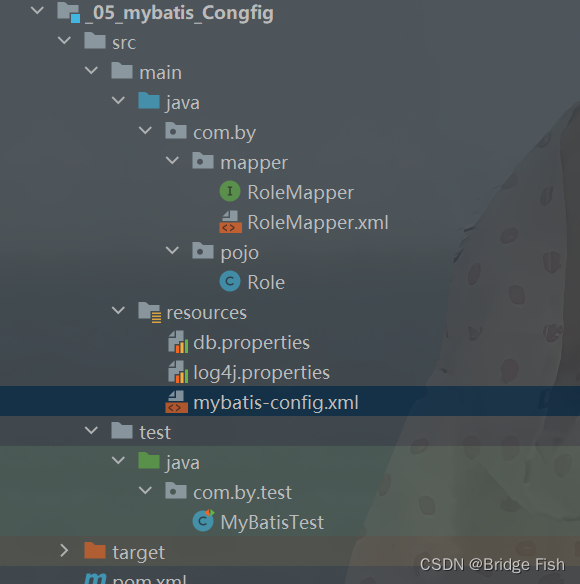
MyBatis的配置文件
目录 MyBatis配置 1.properties标签 2.typeAliases标签 3.Mappers标签 一个最全面的MyBatis配置文件可能会包含各种不同的设置和选项,根据实际情况,可以根据需要添加或删除配置。以下是一个包含各种可能设置的示例。 这个配置文件包含了环境设置、数…...

MCU平台下确定栈空间大小的方法
本文介绍MCU平台下确定栈空间大小的方法。 通常使用IDE开发MCU程序在生成Image文件时,Image文件被划分为代码区,数据区,BSS区,堆区,栈区。其中,代码区,数据区,BSS区空间大小由编译器…...
Flink系列之:SQL提示
Flink系列之:SQL提示 一、动态表选项二、语法三、例子四、查询提示五、句法六、加入提示七、播送八、随机散列九、随机合并十、嵌套循环十一、LOOKUP十二、进一步说明十三、故障排除十四、连接提示中的冲突案例十五、什么是查询块 SQL 提示可以与 SQL 语句一起使用来…...
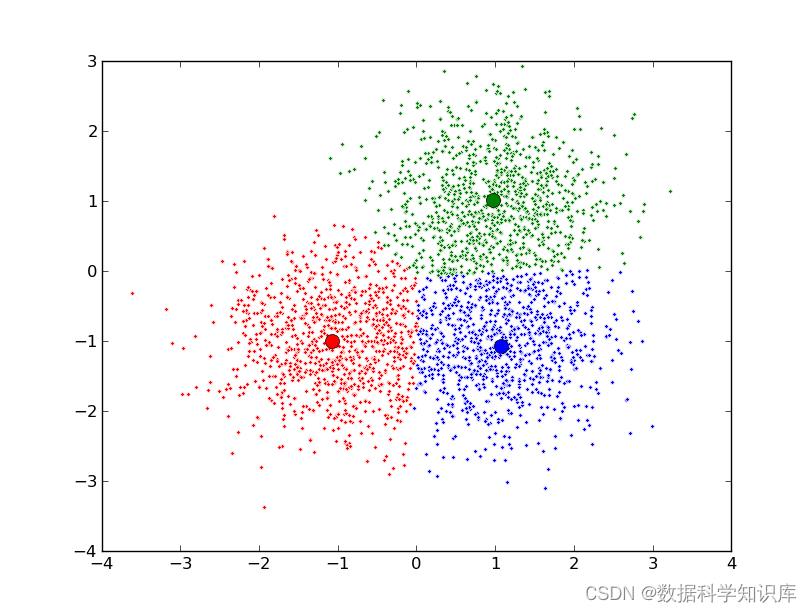
机器学习算法---聚类
类别内容导航机器学习机器学习算法应用场景与评价指标机器学习算法—分类机器学习算法—回归机器学习算法—聚类机器学习算法—异常检测机器学习算法—时间序列数据可视化数据可视化—折线图数据可视化—箱线图数据可视化—柱状图数据可视化—饼图、环形图、雷达图统计学检验箱…...
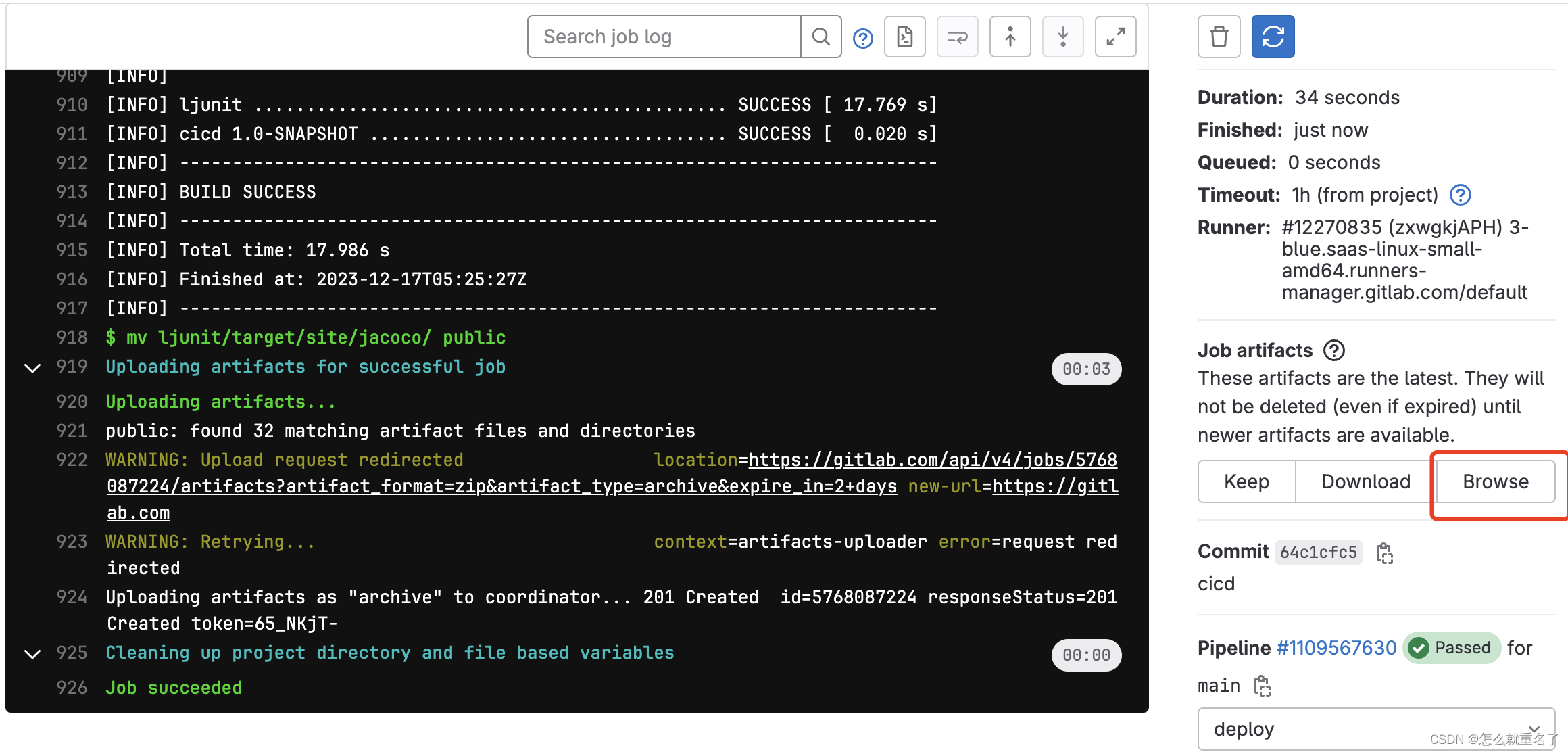
gitlab ci pages
参考文章 gitlab pages是什么 一个可以利用gitlab的域名和项目部署自己静态网站的机制 开启 到gitlab的如下页面 通过gitlab.ci部署项目的静态网站 # build ruby 1/3: # stage: build # script: # - echo "ruby1"# build ruby 2/3: # stage: build …...
Web ML 库的Transformers.js 提供文本转语音功能
JavaScript 库 Transformers.js 提供了类似 Python Transformers 库的功能,设计用于在 Web 浏览器中直接运行 Transformer 模型,而不再需要外部服务器参与处理。在最新的 2.7 版本中,Transformers.js 引入了增强功能,其中包括文本…...

管理类联考——数学——真题篇——按题型分类——充分性判断题——蒙猜E
老老规矩,看目录,平均每年2E,跟2D一样,D是全对,E是全错,侧面也看出10道题,大概是3A/B,3C,2D,2E,其实还是蛮平均的。但E为1道的情况居多。 第20题…...
】)
【Linux基本指令(2)】
文章目录 一. 基本指令第二回 一. 基本指令第二回 cp指令语法 cp src dst 将目标文件或者目录拷贝到指定目录下或文件下。注意同级目录下,不允许存在同名文件或同名目录。如果将一个file.txt文件拷贝到当前目录下,就重名了,报错cp不了&#…...

Debian系统设置SSH密钥登陆
如果没有安装ssh,root权限运行apt install openssh-server进行安装。 ssh-keygen -t rsa # 生成配对密钥,后续一路enter即可会在用户目录(即~这个)下生成.ssh文件夹,里面的id_rsa是私钥,id_rsa.pub是公钥…...

uniapp cli开发和HBuilderX开发
uniapp cli开发和HBuilderX开发 前言 uniapp是一个跨平台的开发框架,可以开发出微信小程序、支付宝小程序、百度小程序、头条小程序、H5、App等,开发者只需要写一套代码,就可以发布到各个平台,大大提高了开发效率。 uniapp的开…...
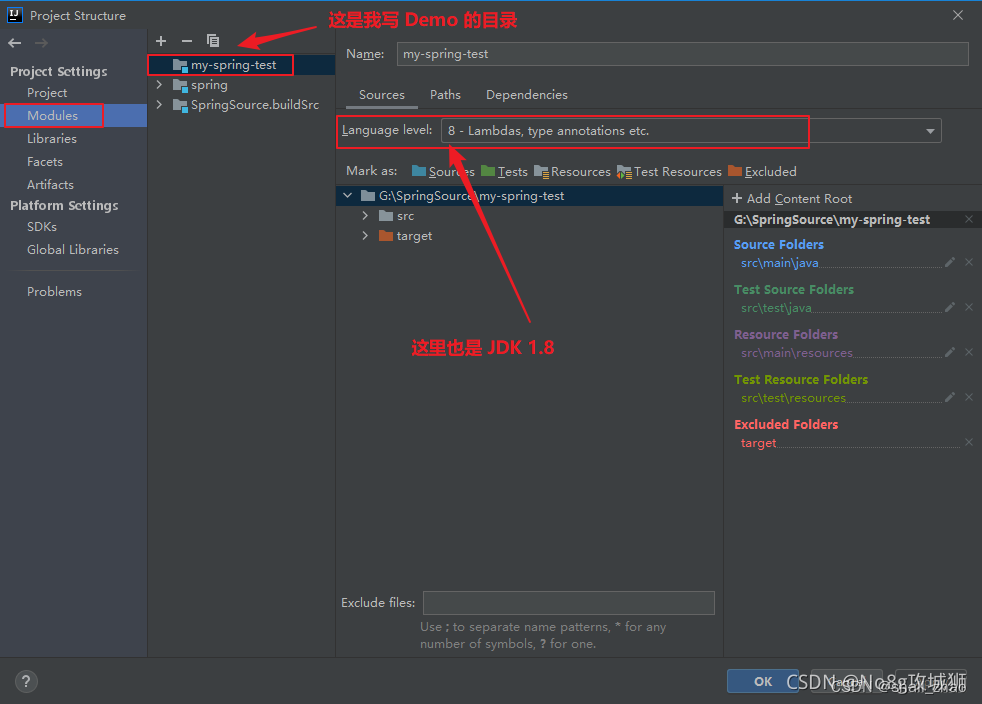
【Java异常】idea 报错:无效的目标发行版:17 的解决办法
【Java异常】idea 报错:无效的目标发行版:17 的解决办法 一,问题来源 springcloud的第一个demo项目就给我干趴了 二、原因分析 java: 无效的目标发行版: 17 原因就是 JDK 版本不对。从 IDEA 编辑器中可以找到问题的原因所在,…...

代码提交规范-ESLint+Prettier+husky+Commitlint
代码提交规范-ESLintPrettierhuskyCommitlint 配置eslint (3步)配置prettier(4步)1.安装配置prettier2.设置忽略文件 .prettierignore3.处理eslint冲突4. 配置vscode 的settings.json husky安装并配置lint-staged(3步)安装配置com…...
)
手动实现 Vue 3的简易双向数据绑定(模仿源码)
Vue 3 带来了许多令人兴奋的新特性和改进,其中之一就是其双向数据绑定的实现方式。与 Vue 2 使用 Object.defineProperty 不同,Vue 3 利用了 JavaScript 的 Proxy 特性来创建响应式数据。在这篇博客中,我们将探讨 Vue 3 中双向数据绑定的基础…...
LVS最终奥义之DR直接路由模式
1 LVS-DR(直接路由模式) 1.1 LVS-DR模式工作过程 1.客户端通过VIP将访问请求报文(源IP为客户端IP,目标IP为VIP)发送到调度器 2.调度器通过调度算法选择最适合的节点服务器并重新封装数据报文(将源mac地址改为调度器的mac地址&am…...
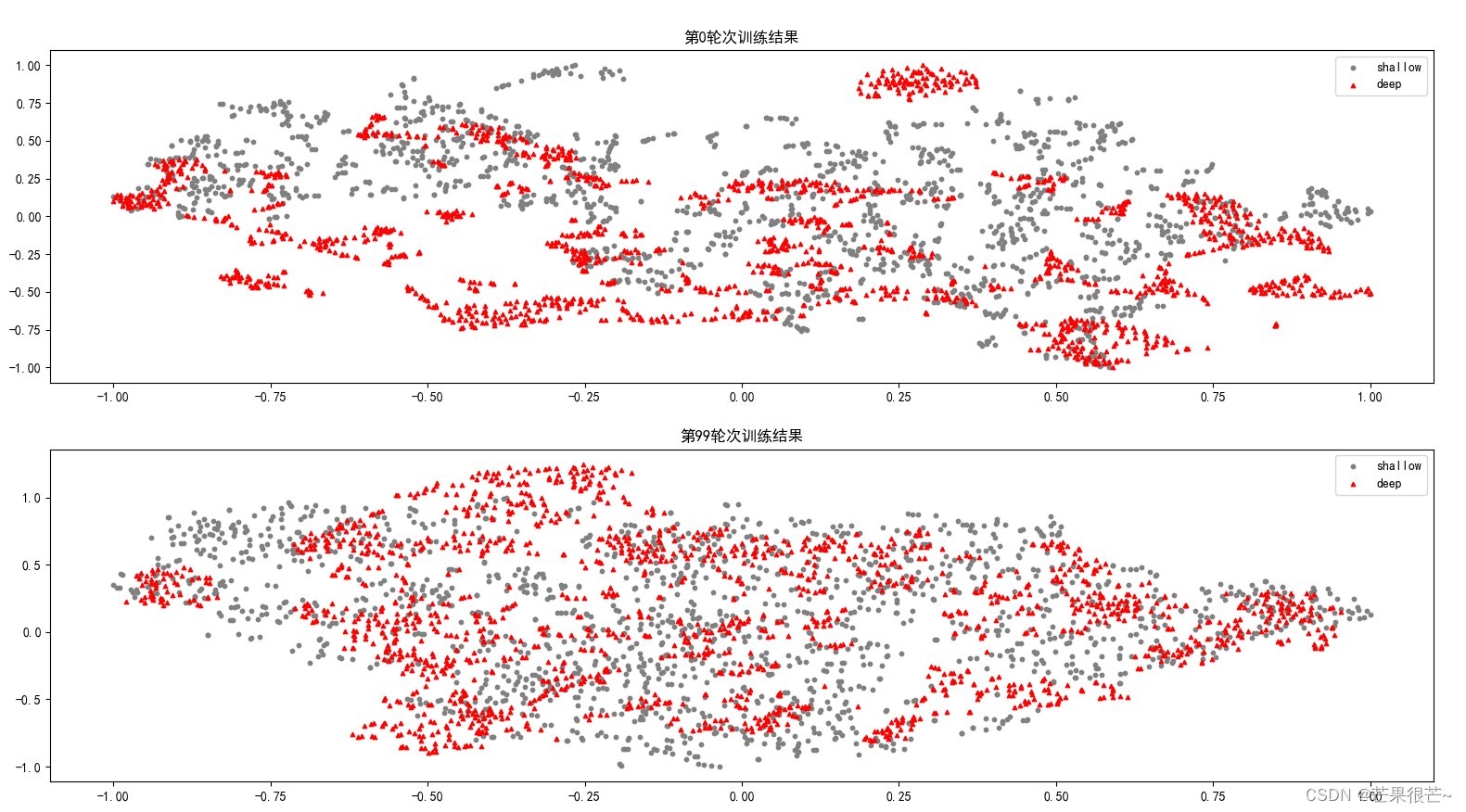
t-SNE高维数据可视化实例
t-SNE:高维数据分布可视化 实例1:自动生成一个S形状的三维曲线 实例1结果: 实例1完整代码: import matplotlib.pyplot as plt from sklearn import manifold, datasets """对S型曲线数据的降维和可视化"&q…...

配置应用到k8s
配置应用到k8s,前置条件是安装了Docker,Minikube,kubectl 应用已经通过Docker生成本地镜像文件 1,创建godemo-deployment.yaml apiVersion: apps/v1kind: Deploymentmetadata:name: godemo-deploymentspec:replicas: 3 #启动三个…...

(四)STM32 操作 GPIO 点亮 LED灯 / GPIO工作模式
目录 1. STM32 工程模板中的工程目录介绍 2. GPIO 简介 3. GPIO 框图剖析 1)保护二极管及上、下拉电阻 2) P-MOS 管和 N-MOS 管 3)输出数据寄存器 3.1)ODR 端口输出数据寄存器 3.2)BSRR 端口位设置/清除寄存器 4&a…...

跨越Android存储权限适配的深水区:从Android 11到13的实战避坑指南
1. 当存储权限遇上Android版本分裂:真实踩坑现场 去年接手一个图片下载功能时,我遭遇了职业生涯最诡异的兼容性问题。在荣耀Android 10、红米Android 11和小米Android 13上运行完美的代码,到了三星Galaxy S23 Ultra(Android 13&am…...

TPS5430玩点不一样的:15V输入如何生成一个干净的-12V电源?电路设计与极性电容防炸指南
TPS5430负压生成实战:从15V到-12V的电路设计精要 在模拟电路设计中,双电源供电系统(如12V)是音频设备、运算放大器和高精度ADC的常见需求。然而,当系统仅提供单路正电压输入时,如何高效生成稳定的负电压轨成…...

解放Windows潜能:APK安装器让安卓应用在电脑上完美运行
解放Windows潜能:APK安装器让安卓应用在电脑上完美运行 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾梦想过在Windows电脑上直接运行手机应用&am…...

更换背景图用什么工具?8个月来我测试过50+款产品,这是真实体验分享
买了新手机,想给证件照换个背景;电商运营需要批量处理商品图;自媒体博主要给头像去个背景……这些场景下,"更换背景图用什么工具"可能是你Google搜索框里最常打的一句话。说实话,这个问题看似简单࿰…...
的信号)
视频均衡驱动器,最大支持1920x1080@60(1080P60)的信号
GMM613是一款无需配置、上电即用的视频均衡驱动器,功能对标德州仪器(TI)的LMH0344和Semtech的GS2994。该芯片作为均衡器使用,能够补偿信号在长距离同轴线缆传输过程中的损耗,恢复信号质量,从而延长SDI信号的…...

CircuitPython微控制器图形保存实战:从屏幕截图到BMP文件生成
1. 项目概述:为什么我们需要在微控制器上保存图形? 在嵌入式开发领域,尤其是当我们使用像Adafruit PyPortal、PyGamer这类带有彩色显示屏的开发板时,图形界面的调试和内容存档一直是个不大不小的痛点。想象一下,你花了…...
)
从Python到Shell:给AI/开发者的极简跨语言编程指南(附避坑对比)
从Python到Shell:给AI/开发者的极简跨语言编程指南(附避坑对比) 当Python开发者第一次接触Shell脚本时,往往会陷入两种极端:要么低估了Shell的能力,认为它只是简单的命令拼接;要么高估了它的复…...

终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题
终极指南:如何用ROFL-Player永久解决英雄联盟回放版本兼容性问题 【免费下载链接】ROFL-Player (No longer supported) One stop shop utility for viewing League of Legends replays! 项目地址: https://gitcode.com/gh_mirrors/ro/ROFL-Player 还在为英雄…...

APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案
APK Installer终极指南:在Windows电脑上快速安装Android应用的完整方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否厌倦了在电脑和手机之间来回传…...

为什么92%的戏剧研究生还没用上NotebookLM真正能力?——解锁其多源文本互文性推理的3个密钥
更多请点击: https://intelliparadigm.com 第一章:NotebookLM戏剧研究辅助的范式革命 传统戏剧研究长期依赖人工文本比对、手写批注与线性阅读,面对莎士比亚全集、元杂剧数百种版本、当代实验戏剧脚本等海量非结构化文本,知识提取…...