Java 并发编程 —— Fork/Join 框架的原理详解
目录
一. 前言
二. 并发和并行
2.1. 并发
2.2. 并行
2.3. 分治法
三. ForkJoin 并行处理框架的理论
3.1. ForkJoin 框架概述
3.2. ForkJoin 框架原理
3.3. 工作窃取算法
四. ForkJoin 并行处理框架的实现
4.1. ForkJoinPool 类
4.2. ForkJoinWorkerThread 类
4.3. ForkJoinTask 类
4.4. ForkJoin 示例
五. 总结
一. 前言
在 JDK 中,提供了这样一种功能:它能够将复杂的逻辑拆分成一个个简单的逻辑来并行执行,待每个并行执行的逻辑执行完成后,再将各个结果进行汇总,得出最终的结果数据。有点像Hadoop 中的 MapReduce。
ForkJoin 是由 JDK1.7 之后提供的多线程并发处理框架。ForkJoin 框架的基本思想是分而治之。什么是分而治之?分而治之就是将一个复杂的计算,按照设定的阈值分解成多个计算,然后将各个计算结果进行汇总。相应的,ForkJoin 将复杂的计算当做一个任务,而分解的多个计算则是当做一个个子任务来并行执行。
二. 并发和并行
并发和并行在本质上还是有所区别的。
2.1. 并发
并发指的是在同一时刻,只有一个线程能够获取到 CPU 执行任务,而多个线程被快速的轮换执行,这就使得在宏观上具有多个线程同时执行的效果,并发不是真正的同时执行,并发可以使用下图表示:

2.2. 并行
并行指的是无论何时,多个线程都是在多个 CPU 核心上同时执行的,是真正的同时执行。
2.3. 分治法
把一个规模大的问题划分为规模较小的子问题,然后分而治之,最后合并子问题的解得到原问题的解。在分治法中,子问题一般是相互独立的,因此,经常通过递归调用算法来求解子问题。
步骤可分为:1. 分割原问题;2. 求解子问题;3. 合并子问题的解为原问题的解。我们可以使用如下伪代码来表示这个步骤:
if (任务很小){直接计算得到结果
} else {分拆成N个子任务调用子任务的fork()进行计算调用子任务的join()合并计算结果
}典型应用有:二分搜索、大整数乘法、Strassen矩阵乘法、棋盘覆盖、合并排序、快速排序、线性时间选择、汉诺塔。
三. ForkJoin 并行处理框架的理论
3.1. ForkJoin 框架概述
Java 1.7 引入了一种新的并发框架 —— Fork/Join Framework,主要用于实现“分而治之”的算法,特别是分治之后递归调用的函数。
ForkJoin 框架的本质是一个用于并行执行任务的框架,能够把一个大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务的计算结果。在 Java 中,ForkJoin 框架与 ThreadPool 共存,并不是要替换 ThreadPool。
其实,在 Java 8 中引入的并行流计算,内部就是采用的 ForkJoinPool 来实现的。例如,下面使用并行流实现打印数组元组的程序:
public class SumArray {public static void main(String[] args) {List<Integer> numberList = Arrays.asList(1,2,3,4,5,6,7,8,9);numberList.parallelStream().forEach(System.out::println);}
}说到这里,可能有读者会问:可以使用线程池的 ThreadPoolExecutor 来实现啊?为什么要使用ForkJoinPool? 接下来,我们就来回答这个问题。
3.2. ForkJoin 框架原理
ForkJoin 框架是从 JDK1.7 中引入的新特性,它同 ThreadPoolExecutor 一样,也实现了Executor 和 ExecutorService 接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入指定的线程数量,那么当前计算机可用的 CPU 数量会被设置为线程数量作为默认值。
ForkJoinPool 主要使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool 能够使用相对较少的线程来处理大量的任务。
比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。
比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概200万+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用 ThreadPoolExecutor 时,使用分治法会存在问题,因为 ThreadPoolExecutor 中的线程无法向任务队列中再添加一个任务并在等待该任务完成之后再继续执行。而使用 ForkJoinPool就能够解决这个问题,它就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
那么使用 ThreadPoolExecutor 或者 ForkJoinPool,性能上会有什么差异呢?
首先,使用 ForkJoinPool 能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用 ThreadPoolExecutor 时,是不可能完成的,因为 ThreadPoolExecutor 中的 Thread 无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,很显然这是不可行的,也是很不合理的!
3.3. 工作窃取算法
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如 A 线程负责处理 A 队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点:
充分利用线程进行并行计算,并减少了线程间的竞争。
工作窃取算法的缺点:
在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗更多的系统资源,比如创建多个线程和多个双端队列。
四. ForkJoin 并行处理框架的实现
ForkJoin 框架中一些重要的类如下所示:

4.1. ForkJoinPool 类
既然任务是被逐渐的细化的,那就需要把这些任务存在一个池子里面,这个池子就是ForkJoinPool,它与其它的 ExecutorService 区别主要在于它使用“工作窃取”。由类图可以看出,ForkJoinPool 类实现了线程池的 Executor接口。我们还可以使用 Executors.newWorkStealPool() 方法来创建 ForkJoinPool。
ForkJoinPool 中提供了如下提交任务的方法:
public void execute(ForkJoinTask<?> task)
public void execute(Runnable task)
public <T> T invoke(ForkJoinTask<T> task)
public <T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks)
public <T> ForkJoinTask<T> submit(ForkJoinTask<T> task)
public <T> ForkJoinTask<T> submit(Callable<T> task)
public <T> ForkJoinTask<T> submit(Runnable task, T result)
public ForkJoinTask<?> submit(Runnable task)4.2. ForkJoinWorkerThread 类
实现 ForkJoin 框架中的线程。
4.3. ForkJoinTask<V> 类
ForkJoinTask 封装了数据及其相应的计算,并且支持细粒度的数据并行。ForkJoinTask 比线程要轻量,ForkJoinPool 中少量工作线程能够运行大量的 ForkJoinTask。ForkJoinTask 类中主要包括两个方法 fork() 和 join(),分别实现任务的分拆与合并。
fork() 方法类似于 Thread.start(),但是它并不立即执行任务,而是将任务放入工作队列中。跟Thread.join() 方法不同,ForkJoinTask 的 join() 方法并不简单的阻塞线程,而是利用工作线程运行其他任务,当一个工作线程中调用 join(),它将处理其他任务,直到注意到目标子任务已经完成。
我们可以使用下图来表示这个过程:

ForkJoinTask有3个子类:
- RecursiveAction:无返回值的ForkJoinTask,并实现 Runnable。
- RecursiveTask:有返回值的ForkJoinTask,并实现 Callable。
- CountedCompleter:完成任务后将触发其他任务。
4.4. ForkJoin 示例
package com.lm.concurrency.example;import java.util.concurrent.ForkJoinPool;
import java.util.concurrent.Future;
import java.util.concurrent.RecursiveTask;public class ForkJoinTaskExample extends RecursiveTask<Integer> {public static final int threshold = 2;private int start;private int end;public ForkJoinTaskExample(int start, int end) {this.start = start;this.end = end;}@Overrideprotected Integer compute() {int sum = 0;// 如果任务足够小就计算任务boolean canCompute = (end - start) <= threshold;if (canCompute) {for (int i = start; i <= end; i++) {sum += i;}} else {// 如果任务大于阈值,就分裂成两个子任务计算int middle = (start + end) / 2;ForkJoinTaskExample leftTask = new ForkJoinTaskExample(start, middle);ForkJoinTaskExample rightTask = new ForkJoinTaskExample(middle + 1, end);// 执行子任务leftTask.fork();rightTask.fork();// 等待任务执行结束合并其结果int leftResult = leftTask.join();int rightResult = rightTask.join();// 合并子任务sum = leftResult + rightResult;}return sum;}public static void main(String[] args) {ForkJoinPool forkjoinPool = new ForkJoinPool();// 生成一个计算任务,计算1+2+3+4ForkJoinTaskExample task = new ForkJoinTaskExample(1, 100);// 执行一个任务Future<Integer> result = forkjoinPool.submit(task);try {System.out.println("result: " + result.get());} catch (Exception e) {System.out.println(e);}}
}五. 总结
Fork/Join 框架局限性:
对于 Fork/Join 框架而言,当一个任务正在等待它使用 Join 操作创建的子任务结束时,执行这个任务的工作线程查找其他未被执行的任务,并开始执行这些未被执行的任务,通过这种方式,线程充分利用它们的运行时间来提高应用程序的性能。为了实现这个目标,Fork/Join 框架执行的任务有一些局限性。
- 任务只能使用 Fork 和 Join 操作来进行同步机制,如果使用了其他同步机制,则在同步操作时,工作线程就不能执行其他任务了。比如,在 Fork/Join 框架中,使任务进行了睡眠,那么,在睡眠期间内,正在执行这个任务的工作线程将不会执行其他任务了。
- 在 Fork/Join 框架中,所拆分的任务不应该去执行 IO 操作,比如:读写数据文件。
- 任务不能抛出检查异常,必须通过必要的代码来处理这些异常。
相关文章:
Java 并发编程 —— Fork/Join 框架的原理详解
目录 一. 前言 二. 并发和并行 2.1. 并发 2.2. 并行 2.3. 分治法 三. ForkJoin 并行处理框架的理论 3.1. ForkJoin 框架概述 3.2. ForkJoin 框架原理 3.3. 工作窃取算法 四. ForkJoin 并行处理框架的实现 4.1. ForkJoinPool 类 4.2. ForkJoinWorkerThread 类 4.3.…...

3-10岁孩子语文能力培养里程碑
文章目录 基础能力3岁4岁5岁6-7岁(1-2年级)8-9岁(3-4年级)10岁(5年级) 阅读推荐&父母执行3岁4-5岁6-7岁(1-2年级)8-9岁(3-4年级)10岁(5年级&a…...

Vue+ElementUi 基于Tree实现动态节点添加,节点自定义为输入框列
VueElementUi 基于Tree实现动态节点手动添加,节点自定义为输入框列 代码 <el-steps :active"active" finish-status"success" align-center><el-step title"test1"/><el-step title"test2"/><el-st…...
)
Web前端-JavaScript(js数组和函数)
文章目录 1.数组1.1 数组的概念1.2 创建数组1.3 获取数组中的元素1.4 数组中新增元素1.5 遍历数组 2.函数2.1 函数的概念2.2 函数的使用函数声明调用函数函数的封装 2.3 函数的参数函数参数语法函数形参和实参数量不匹配时 2.4 函数的返回值2.4.1 案例练习 2.5 arguments的使用…...
判断数据是否为整数--函数设计与实现
#定义函数:is_num(s),判断输入的数据是否整数。 #(1)判断是否是数字 def is_num(s):if s.isdigit(): #isdigit()是一个字符串方法,用于检查字符串是否只包含数字字符。如果字符串只包含数字字符,则返回True;否则返回Falsereturn T…...

netty源码:(29)ChannelInboundHandlerAdapter
它实现的方法都有一个ChannelHandlerContext参数,它的方法都是直接调用ChannelHandlerContext参数对应的方法,该方法会调用下一个handler对应的方法。 可以继承这个类,重写感兴趣的方法,比如channelRead. 这个类有个子类:SimpleC…...
)
Shell脚本应用(二)
一、条件测试操作 Shell环境根据命令执行后的返回状态值〈$?)来判断是否执行成功,当返回值为О时表示成功.否则〈非О值)表示失败或异常。使用专门的测试工具---test命令,可以对特定条件进行测试.并根据返回值来判断条件是否成立…...
Kafka基本原理及使用
目录 基本概念 单机版 环境准备 基本命令使用 集群版 消息模型 成员组成 1. Topic(主题): 2. Partition(分区): 3. Producer(生产者): 4. Consumer(…...

使用Python爬取GooglePlay并从复杂的自定义数据结构中实现解析
文章目录 【作者主页】:吴秋霖 【作者介绍】:Python领域优质创作者、阿里云博客专家、华为云享专家。长期致力于Python与爬虫领域研究与开发工作! 【作者推荐】:对JS逆向感兴趣的朋友可以关注《爬虫JS逆向实战》,对分布…...
前后端分离下的鸿鹄电子招投标系统:使用Spring Boot、Mybatis、Redis和Layui实现源码与立项流程
在数字化时代,采购管理也正经历着前所未有的变革。全过程数字化采购管理成为了企业追求高效、透明和规范的关键。该系统通过Spring Cloud、Spring Boot2、Mybatis等先进技术,打造了从供应商管理到采购招投标、采购合同、采购执行的全过程数字化管理。通过…...

ChatGPT 有什么新奇的使用方式?
来看看 OpenAI 内部是如何使用 ChatGPT 的。 目前(4月29日)距离ChatGPT发布了已经半年,这期间大家基本上把能想到的ChatGPT的使用方法都研究遍了——从写作、写代码,到翻译、英语润色,再到角色扮演等等。 所以&#x…...

【计算机四级(网络工程师)笔记】操作系统概论
目录 一、OS的概念 1.1OS的定义 1.2OS的特征 1.2.1并发性 1.2.2共享性 1.2.3随机性 1.3研究OS的观点 1.3.1软件的观点 1.3.2资源管理器的观点 1.3.3进程的观点 1.3.4虚拟机的观点 1.3.5服务提供者的观点 二、OS的分类 2.1批处理操作系统 2.2分时操作系统 2.3实时操作系统 2.4嵌…...
贪心算法)
LeetCode算法练习top100:(10)贪心算法
package top100.贪心算法;import java.util.ArrayList; import java.util.List;public class TOP {//121. 买卖股票的最佳时机public int maxProfit(int[] prices) {int res 0, min prices[0];for (int i 1; i < prices.length; i) {if (prices[i] < min) {min price…...

随记-探究 OpenApi 的加密方式
open api 主要参数如下 appKey 接口Key(app id)appSecret 接口密钥timeStamp 时间戳 毫秒nonceStr 随机字符串signature 加密字符串 客户端 使用 appSecret 按照一定规则将 appKey timeStamp nonceStr 进行加密,得到密文 signature将 appK…...
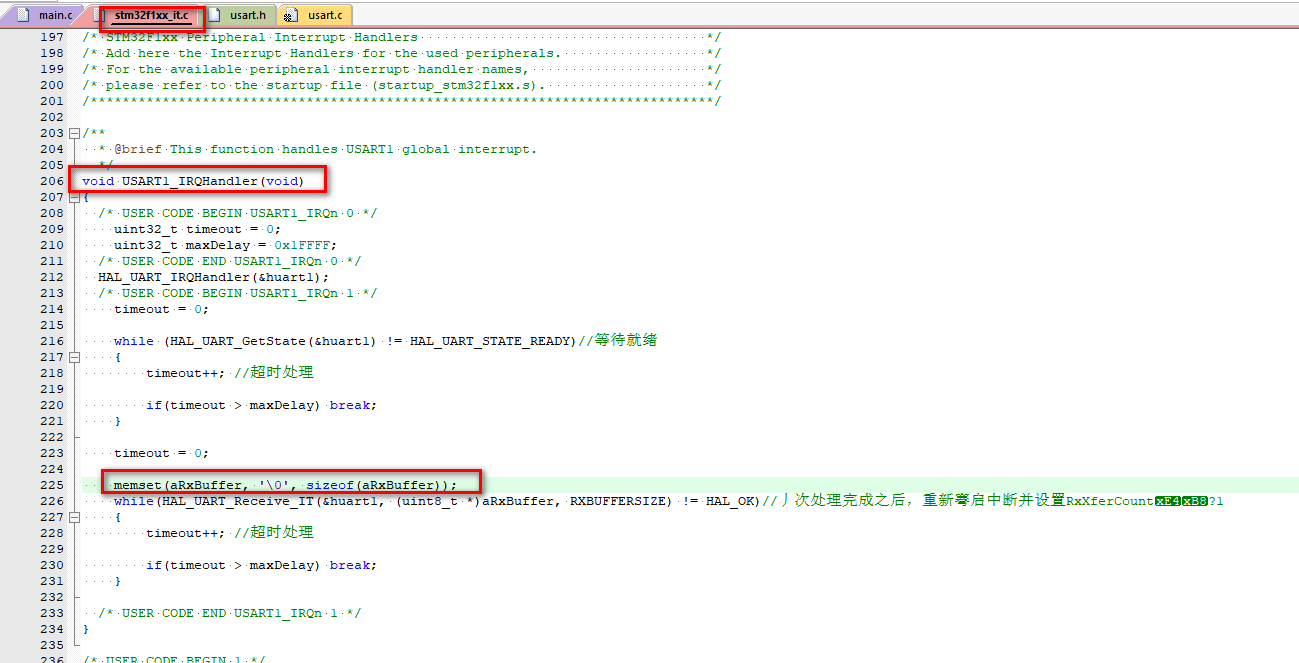
stm32学习总结:4、Proteus8+STM32CubeMX+MDK仿真串口收发
stm32学习总结:4、Proteus8STM32CubeMXMDK仿真串口收发 文章目录 stm32学习总结:4、Proteus8STM32CubeMXMDK仿真串口收发一、前言二、资料收集三、STM32CubeMX配置串口1、配置开启USART12、设置usart中断优先级3、配置外设独立生成.c和.h 四、MDK串口收发…...

配置paddleocr及paddlepaddle解决报错 GLIBCXX_3.4.30 FreeTypeFont
配置 https://github.com/PaddlePaddle/PaddleOCR/blob/release/2.7/StyleText/README_ch.md#style-text 环境配置 https://www.paddlepaddle.org.cn/ 根据自己的cuda版本选择paddlepaddle-gpu # 新建conda环境 # python version conda create -n paddle python3.8 # 安装p…...

【实战】如何在Docker Image中轻松运行MySQL
定义 使用Docker运行MySQL有许多优势。它允许数据库程序和数据分离,增强了数据的安全性和可靠性。Docker Image的轻便性简化了MySQL的部署和迁移,而Docker的资源隔离功能确保了应用程序之间无冲突。结合中间件和容器化系统,Docker为MySQL提供…...

PLC物联网,实现工厂设备数据采集
随着工业4.0时代的到来,物联网技术在工厂设备管理领域的应用日益普及。作为物联网技术的重要一环,PLC物联网为工厂设备数据采集带来了前所未有的便捷和高效。本文将围绕“PLC物联网,实现工厂设备数据采集”这一主题,探讨PLC物联网…...
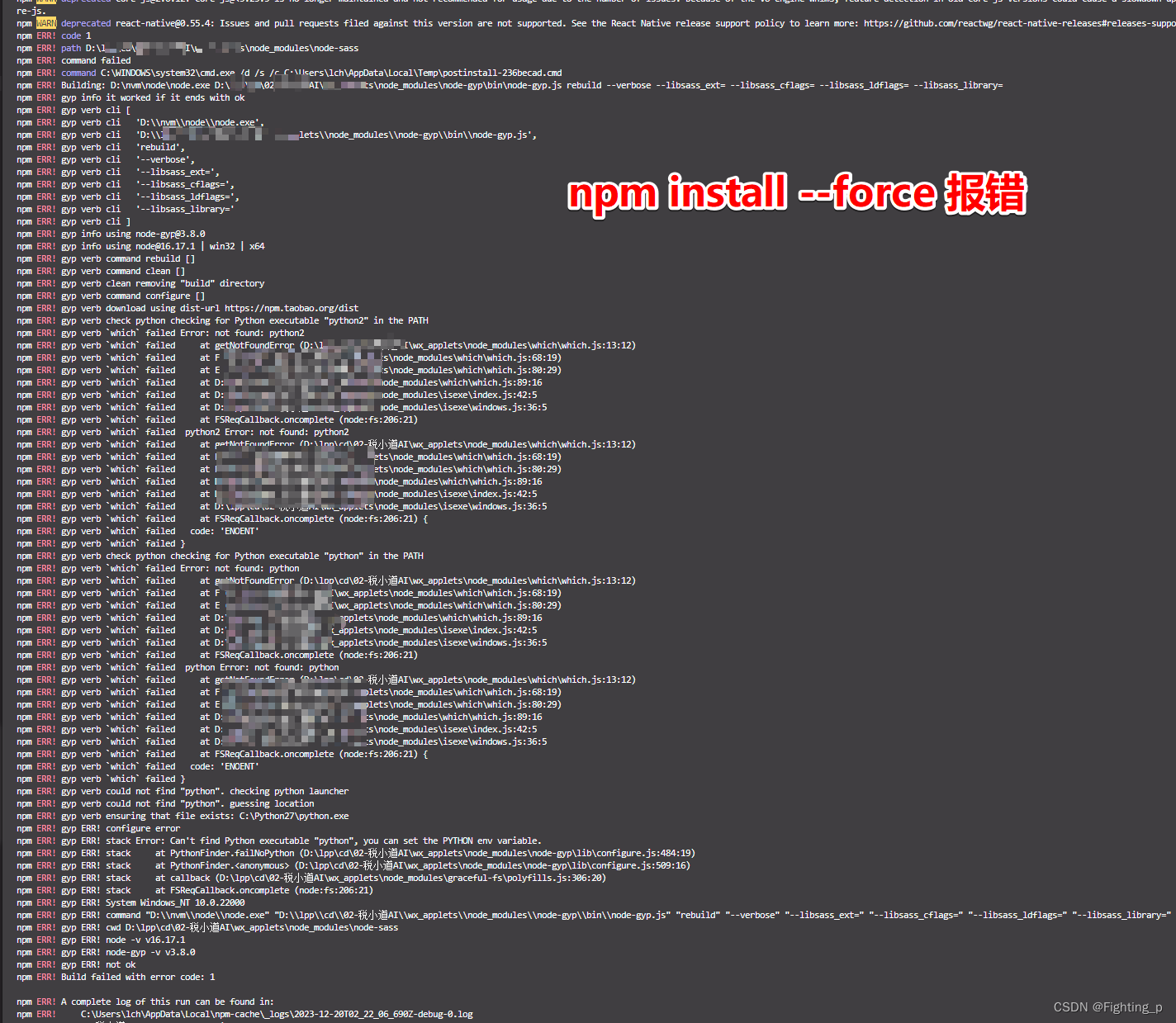
npm安装依赖报错ERESOLVE unable to resolve dependency tree(我是在taro项目中)(node、npm 版本问题)
换了电脑之后新电脑安装包出错 👇👇👇 npm install 安装包报错 ERESOLVE unable to resolve dependency tree 百度后尝试使用 npm install --force 还是报错 参考 有人说是 node 版本和 npm 版本的问题 参考 新电脑 node版本:16.1…...
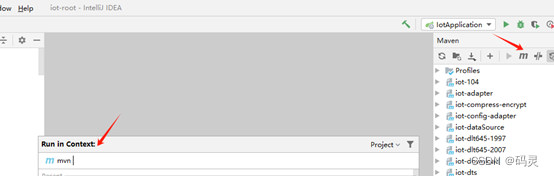
Maven仓库上传jar和mvn命令汇总
目录 导入远程仓库 命令结构 命令解释 项目pom 输入执行 本地仓库导入 命令格式 命令解释 Maven命令汇总 mvn 参数 mvn常用命令 web项目相关命令 导入远程仓库 命令结构 mvn deploy:deploy-file -Dfilejar包完整名称 -DgroupIdpom文件中引用的groupId名 -Dartifa…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

【配置 YOLOX 用于按目录分类的图片数据集】
现在的图标点选越来越多,如何一步解决,采用 YOLOX 目标检测模式则可以轻松解决 要在 YOLOX 中使用按目录分类的图片数据集(每个目录代表一个类别,目录下是该类别的所有图片),你需要进行以下配置步骤&#x…...

C++中string流知识详解和示例
一、概览与类体系 C 提供三种基于内存字符串的流,定义在 <sstream> 中: std::istringstream:输入流,从已有字符串中读取并解析。std::ostringstream:输出流,向内部缓冲区写入内容,最终取…...

LLM基础1_语言模型如何处理文本
基于GitHub项目:https://github.com/datawhalechina/llms-from-scratch-cn 工具介绍 tiktoken:OpenAI开发的专业"分词器" torch:Facebook开发的强力计算引擎,相当于超级计算器 理解词嵌入:给词语画"…...

MySQL中【正则表达式】用法
MySQL 中正则表达式通过 REGEXP 或 RLIKE 操作符实现(两者等价),用于在 WHERE 子句中进行复杂的字符串模式匹配。以下是核心用法和示例: 一、基础语法 SELECT column_name FROM table_name WHERE column_name REGEXP pattern; …...

SpringCloudGateway 自定义局部过滤器
场景: 将所有请求转化为同一路径请求(方便穿网配置)在请求头内标识原来路径,然后在将请求分发给不同服务 AllToOneGatewayFilterFactory import lombok.Getter; import lombok.Setter; import lombok.extern.slf4j.Slf4j; impor…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...

使用LangGraph和LangSmith构建多智能体人工智能系统
现在,通过组合几个较小的子智能体来创建一个强大的人工智能智能体正成为一种趋势。但这也带来了一些挑战,比如减少幻觉、管理对话流程、在测试期间留意智能体的工作方式、允许人工介入以及评估其性能。你需要进行大量的反复试验。 在这篇博客〔原作者&a…...

MySQL 知识小结(一)
一、my.cnf配置详解 我们知道安装MySQL有两种方式来安装咱们的MySQL数据库,分别是二进制安装编译数据库或者使用三方yum来进行安装,第三方yum的安装相对于二进制压缩包的安装更快捷,但是文件存放起来数据比较冗余,用二进制能够更好管理咱们M…...