YOLOv5改进 | 卷积篇 | 通过RFAConv重塑空间注意力(深度学习的前沿突破)
一、本文介绍
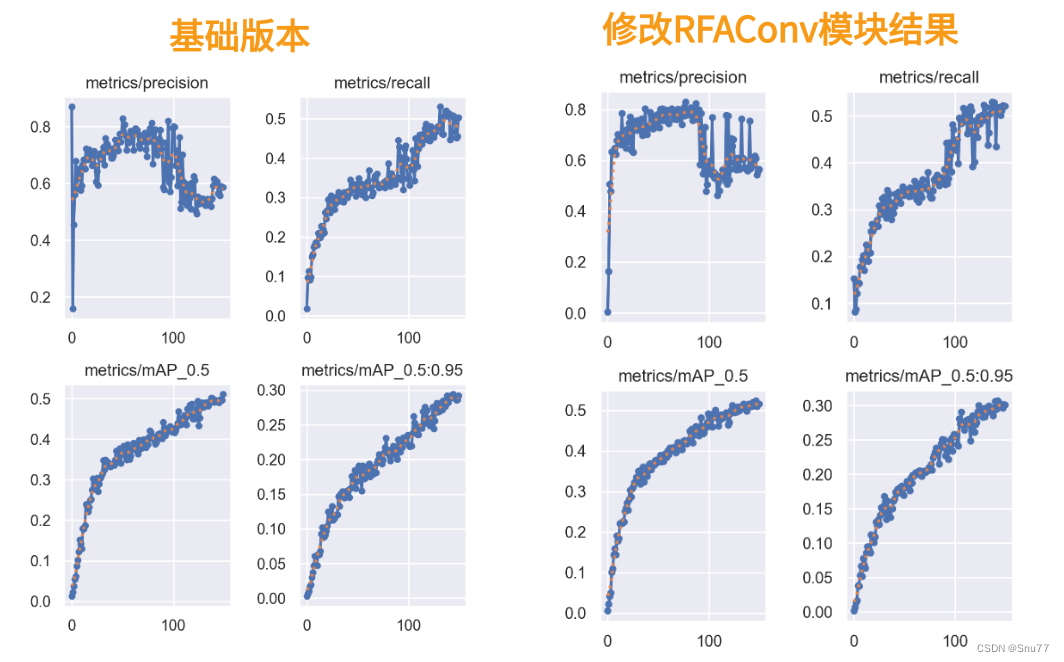
本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的提点)。这不仅让YOLOv5在识别和定位目标时更加精准,还大幅提升了处理速度和效率。本文章深入会探讨RFAConv如何在YOLOv5中发挥作用,以及它是如何改进在我们的YOLOv5中的。我将通过案例的角度来带大家分析其有效性(结果训练结果对比图)。
适用检测目标:亲测所有的目标检测均有一定的提点
推荐指数:⭐⭐⭐⭐⭐
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新
实验结果对比图->
目录
一、本文介绍
二、RFAConv结构讲解
2.1、RAFCAonv主要思想
2.2、感受野空间特征
2.3、解决参数共享问题
2.4、提高大尺寸卷积核的效率
三、RFAConv核心代码
四、手把手教你添加RFAConv和C3f_RFAConv模块
4.1 细节修改教程
4.1.1 修改一
4.1.2 修改二
4.1.3 修改三
4.1.4 修改四
4.2 RFAConv的yaml文件
4.2.1 RFAConv的yaml文件一
4.2.2 RFAConv的yaml文件二
4.2.3 RFAConv的yaml文件三
4.3 RFAConv运行成功截图
4.4 推荐RFAConv可添加的位置
五、本文总结
二、RFAConv结构讲解

论文地址:官方论文地址
代码地址:官方代码地址

2.1、RAFCAonv主要思想
RFAConv(Receptive-Field Attention Convolution)的主要思想是将空间注意力机制与卷积操作相结合,从而提高卷积神经网络(CNN)的性能。这种方法的核心在于优化卷积核的工作方式,特别是在处理感受野内的空间特征时。以下是RFAConv的几个关键思想:
1. 感受野空间特征的重点关注:RFAConv特别关注于感受野内的空间特征,不仅仅局限于传统的空间维度。这种方法允许网络更有效地理解和处理图像中的局部区域,从而提高特征提取的精确性。
2. 解决参数共享问题:在传统的CNN中,卷积核在处理不同区域的图像时共享同样的参数,这可能限制了模型对于复杂模式的学习能力。RFAConv通过引入注意力机制,能够更灵活地调整卷积核的参数,针对不同区域提供定制化的处理。
3. 提高大尺寸卷积核的效率:对于大尺寸卷积核,仅使用标准的空间注意力可能不足以捕获所有重要的信息。RFAConv通过提供有效的注意力权重,使得大尺寸卷积核能够更有效地处理图像信息。
总结:RFAConv通过结合空间注意力和感受野特征的处理,为卷积神经网络提供了一种新的、更高效的方式来提取和处理图像特征,尤其是在处理复杂或大尺寸的输入时。
下面我来分别介绍这几点->
2.2、感受野空间特征
感受野空间特征是指卷积神经网络(CNN)中,卷积层能“看到”的输入数据的局部区域。在CNN中,每个卷积操作的输出是基于输入数据的一个小窗口,或者说是一个局部感受野。这个感受野定义了卷积核可以接触到的输入数据的大小和范围。
感受野的概念对于理解CNN如何从输入数据中提取特征是至关重要的。在网络的初级层,感受野通常很小,允许模型捕捉到细微的局部特征,如边缘和角点。随着数据通过更多的卷积层,通过层层叠加,感受野逐渐扩大,允许网络感知到更大的区域,捕捉到更复杂的特征,如纹理和对象的部分。
在CNN的上下文中,感受野空间特征指的是每个卷积操作能够感知的输入图像区域中的特征。这些特征可以包括颜色、形状、纹理等基本视觉元素。在传统的卷积网络中,感受野通常是固定的,并且每个位置的处理方式都是相同的。但是,如果网络能够根据每个区域的不同特点来调整感受野的处理方式,那么网络对特征的理解就会更加精细和适应性更强。
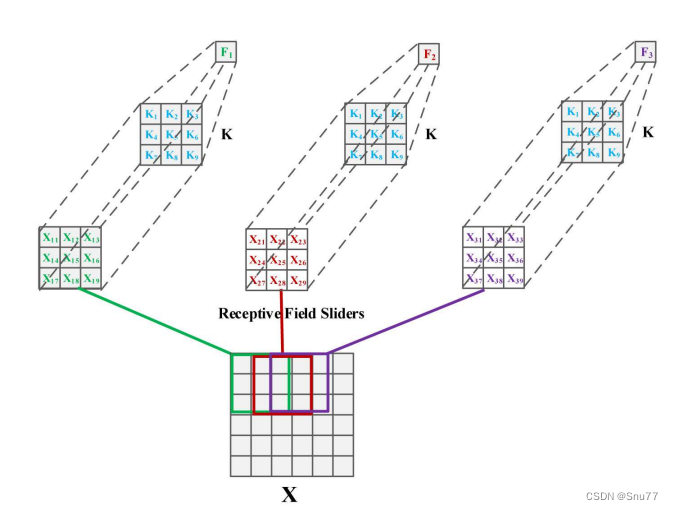
上图展示了一个3x3的卷积操作。在这个操作中,特征是通过将卷积核与同样大小的感受野滑块相乘然后求和得到的。具体来说,输入图像X上的每一个3x3的区域(即感受野)都被一个3x3的卷积核K处理。每个感受野内的元素,(其中i和j表示在感受野内的位置)都与卷积核K内对应位置的权重,
相乘,然后这些乘积会被求和得到一个新的特征值F。这个过程在整个输入图像上滑动进行,以生成新的特征图。这种标准的卷积操作强调了局部连接和权重共享的概念,即卷积核的权重对整个输入图。
总结:在RFAConv中,感受野空间特征被用来指导注意力机制,这样模型就不仅仅关注于当前层的特定区域,而是根据输入数据的复杂性和重要性动态调整感受野。通过这种方式,RFAConv能够为不同区域和不同尺寸的感受野提供不同的处理,使得网络能够更加有效地捕捉和利用图像中的信息。
2.3、解决参数共享问题
RFAConv卷积以解决参数共享问题,RFAConv通过引入注意力机制,允许网络为每个感受野生成特定的权重。这样,卷积核可以根据每个感受野内的不同特征动态调整其参数,而不是对所有区域一视同仁。
具体来说,RFAConv利用空间注意力来确定感受野中每个位置的重要性,并据此调整卷积核的权重。这样,每个感受野都有自己独特的卷积核,而不是所有感受野共享同一个核。这种方法使得网络能够更细致地学习图像中的局部特征,从而有助于提高整体网络性能。
通过这种方法,RFAConv提升了模型的表达能力,允许它更精确地适应和表达输入数据的特征,尤其是在处理复杂或多变的图像内容时。
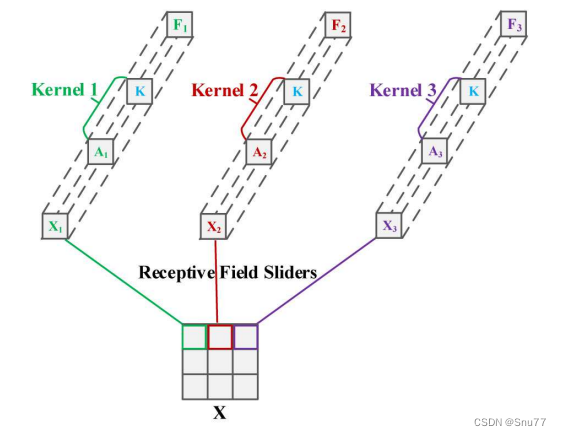
上图展示了一个卷积操作的过程,其中卷积核参数 通过将注意力权重
与卷积核参数 K 相乘得到。这意味着每个感受野滑块的卷积操作都有一个独特的卷积核参数,这些参数是通过将通用的卷积核参数与特定于该位置的注意力权重相结合来获得的。
具体地说,这个过程将注意力机制与卷积核相结合,为每个感受野位置产生一个定制化的卷积核。例如,图中的 Kernel 1、Kernel 2 和 Kernel 3 分别是通过将通用卷积核参数 K 与对应的注意力权重 、
和
相乘得到的。这种方法允许网络在特征提取过程中对不同空间位置的特征赋予不同的重要性,从而增强了模型对关键特征的捕获能力。
总结:这样的机制增加了卷积神经网络的表达能力,使得网络能够更加灵活地适应不同的输入特征,并有助于提高最终任务的性能。这是一种有效的方式来处理传统卷积操作中的参数共享问题,因为它允许每个位置的卷积核适应其处理的特定区域。
2.4、提高大尺寸卷积核的效率
RFAConv通过利用感受野注意力机制来动态调整卷积核的权重,从而为每个区域的特征提取提供了定制化的关注度。这样,即便是大尺寸卷积核,也能够更加有效地捕捉和处理重要的空间特征,而不会对不那么重要的信息分配过多的计算资源。
具体来说,RFAConv方法允许网络识别和强调输入特征图中更重要的区域,并且根据这些区域调整卷积核的权重。这意味着网络可以对关键特征进行重加权,使得大尺寸卷积核不仅能够捕捉到广泛的信息,同时也能够集中计算资源在更有信息量的特征上,从而提升了整体的处理效率和网络性能。
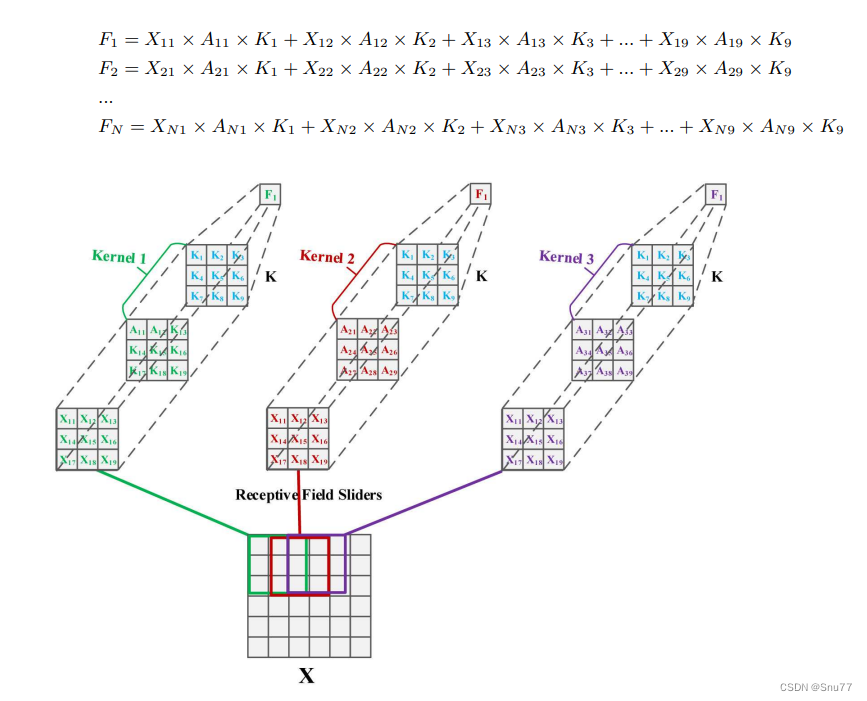
上图描述了感受野滑块中特征的重叠,这是在标准卷积操作中常见的现象。特征的重叠导致了注意力权重的共享问题,意味着不同的感受野可能会对相同的输入特征使用相同的注意力权重。
在图中,,
,...
代表不同感受野滑块内的特征输出,它们是通过将输入特征 X 与对应的注意力权重 A 以及卷积核 K 的权重进行逐元素乘法运算后得到的。例如,
是通过将
乘以对应的注意力权重
和卷积核权重
计算得到的,以此类推。
该图强调了每个感受野滑块内的卷积操作的参数不应该完全共享,而是应该根据每个特定区域内的特征和相应的注意力权重进行调整。这种调整允许网络对每个局部区域进行更加精细的处理,能够更好地捕捉和响应输入数据的特定特征,而不是简单地对整个图像应用相同的权重。这样的方法能够提升网络对特征的理解和表示,从而改善最终的学习和预测性。
总结:通过这种方法,RFAConv提升了模型的表达能力,允许它更精确地适应和表达输入数据的特征,尤其是在处理复杂或多变的图像内容时。这种灵活的参数调整机制为提高卷积神经网络的性能和泛化能力提供了新的途径。
三、RFAConv核心代码
# 大家在使用的时候注意这个卷积设计的时候有点问题,只能当输入输出相等的来使用,否则会报错,后面我给大家准备了三种yaml文件均可运行。
import torch
from torch import nn
from einops import rearrangedef autopad(k, p=None, d=1): # kernel, padding, dilation# Pad to 'same' shape outputsif d > 1:k = d * (k - 1) + 1 if isinstance(k, int) else [d * (x - 1) + 1 for x in k] # actual kernel-sizeif p is None:p = k // 2 if isinstance(k, int) else [x // 2 for x in k] # auto-padreturn pclass Conv(nn.Module):# Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):return self.act(self.bn(self.conv(x)))def forward_fuse(self, x):return self.act(self.conv(x))class RFAConv(nn.Module): # 基于Unfold实现的RFAConvdef __init__(self, in_channel, out_channel, kernel_size=3):super().__init__()self.kernel_size = kernel_sizeself.unfold = nn.Unfold(kernel_size=(kernel_size, kernel_size), padding=kernel_size // 2)self.get_weights = nn.Sequential(nn.Conv2d(in_channel * (kernel_size ** 2), in_channel * (kernel_size ** 2), kernel_size=1,groups=in_channel),nn.BatchNorm2d(in_channel * (kernel_size ** 2)))self.conv = nn.Conv2d(in_channel, out_channel, kernel_size=kernel_size, padding=0, stride=kernel_size)self.bn = nn.BatchNorm2d(out_channel)self.act = nn.ReLU()def forward(self, x):b, c, h, w = x.shapeunfold_feature = self.unfold(x) # 获得感受野空间特征 b c*kernel**2,h*wx = unfold_featuredata = unfold_feature.unsqueeze(-1)weight = self.get_weights(data).view(b, c, self.kernel_size ** 2, h, w).permute(0, 1, 3, 4, 2).softmax(-1)weight_out = rearrange(weight, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size,n2=self.kernel_size) # b c h w k**2 -> b c h*k w*kreceptive_field_data = rearrange(x, 'b (c n1) l -> b c n1 l', n1=self.kernel_size ** 2).permute(0, 1, 3,2).reshape(b, c,h, w,self.kernel_size ** 2) # b c*kernel**2,h*w -> b c h w k**2data_out = rearrange(receptive_field_data, 'b c h w (n1 n2) -> b c (h n1) (w n2)', n1=self.kernel_size,n2=self.kernel_size) # b c h w k**2 -> b c h*k w*kconv_data = data_out * weight_outconv_out = self.conv(conv_data)return self.act(self.bn(conv_out))class Bottleneck(nn.Module):# Standard bottleneckdef __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = RFAConv(c_, c2, 3)self.add = shortcut and c1 == c2def forward(self, x):return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))class C3_RFAConv(nn.Module):# CSP Bottleneck with 3 convolutionsdef __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansionsuper().__init__()c_ = int(c2 * e) # hidden channelsself.cv1 = Conv(c1, c_, 1, 1)self.cv2 = Conv(c1, c_, 1, 1)self.cv3 = Conv(2 * c_, c2, 1) # optional act=FReLU(c2)self.m = nn.Sequential(*(Bottleneck(c_, c_, shortcut, g, e=1.0) for _ in range(n)))def forward(self, x):return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))
四、手把手教你添加RFAConv和C3f_RFAConv模块
4.1 细节修改教程
4.1.1 修改一
我们找到如下的目录'yolov5-master/models'在这个目录下创建一个文件目录(注意是目录,因为我这个专栏会出很多的更新,这里用一种一劳永逸的方法)文件目录起名modules,然后在下面新建一个文件,将我们的代码复制粘贴进去。

4.1.2 修改二
然后新建一个__init__.py文件,然后我们在里面添加一行代码。注意标记一个'.'其作用是标记当前目录。
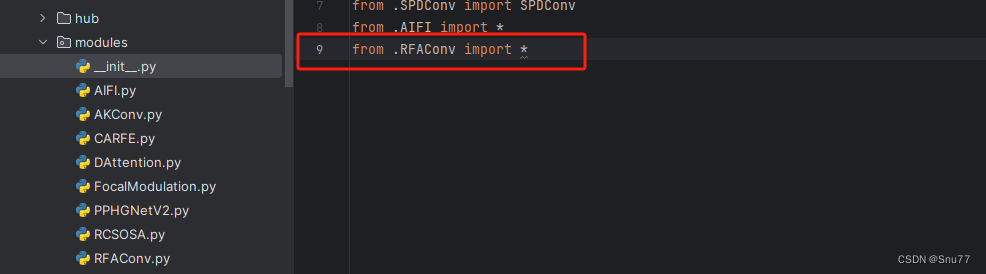
4.1.3 修改三
然后我们找到如下文件''models/yolo.py''在开头的地方导入我们的模块按照如下修改->
(如果你看了我多个改进机制此处只需要添加一个即可,无需重复添加)

4.1.4 修改四
然后我们找到parse_model方法,按照如下修改->
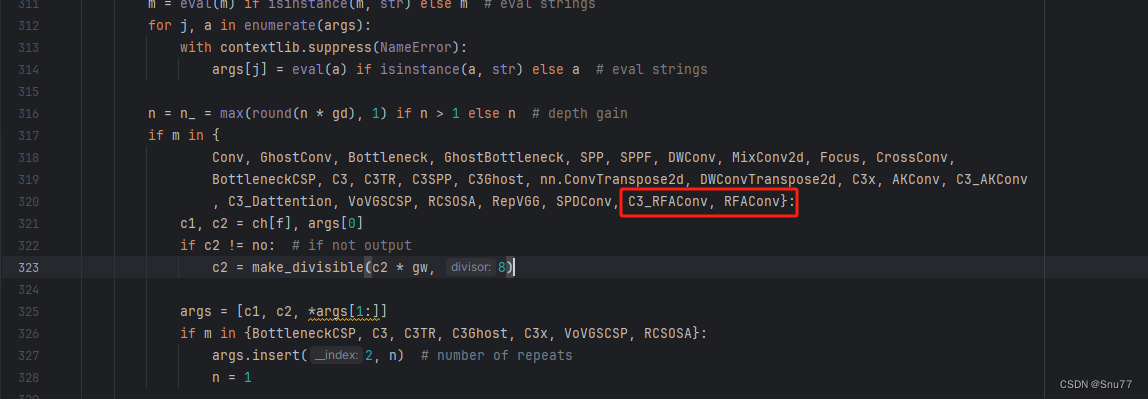
到此就修改完成了,复制下面的ymal文件即可运行。
4.2 RFAConv的yaml文件
4.2.1 RFAConv的yaml文件一
下面的配置文件为我修改的RFAConv的位置,参数的位置里面什么都不用添加空着就行,大家复制粘贴我的就可以运行,同时我提供多个版本给大家,根据我的经验可能涨点的位置。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3_RFAConv, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3_RFAConv, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3_RFAConv, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]4.2.2 RFAConv的yaml文件二
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, RFAConv, [512]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, RFAConv, [256]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 20 (P4/16-medium)[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 23 (P5/32-large)[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]4.2.3 RFAConv的yaml文件三
注意此版本的我再大目标,小目标,中目标三个曾的后面添加了一个注意力机制,此版本需要显存较大,可以根据自己的需求增删,如果修改大家要注意修改Detect里面的检测层数。
# YOLOv5 🚀 by Ultralytics, AGPL-3.0 license# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.25 # layer channel multiple
anchors:- [10,13, 16,30, 33,23] # P3/8- [30,61, 62,45, 59,119] # P4/16- [116,90, 156,198, 373,326] # P5/32# YOLOv5 v6.0 backbone
backbone:# [from, number, module, args][[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2[-1, 1, Conv, [128, 3, 2]], # 1-P2/4[-1, 3, C3, [128]],[-1, 1, Conv, [256, 3, 2]], # 3-P3/8[-1, 6, C3, [256]],[-1, 1, Conv, [512, 3, 2]], # 5-P4/16[-1, 9, C3, [512]],[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32[-1, 3, C3, [1024]],[-1, 1, SPPF, [1024, 5]], # 9]# YOLOv5 v6.0 head
head:[[-1, 1, Conv, [512, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 6], 1, Concat, [1]], # cat backbone P4[-1, 3, C3, [512, False]], # 13[-1, 1, Conv, [256, 1, 1]],[-1, 1, nn.Upsample, [None, 2, 'nearest']],[[-1, 4], 1, Concat, [1]], # cat backbone P3[-1, 3, C3, [256, False]], # 17 (P3/8-small)[-1, 1, RFAConv, [256]], #18[-1, 1, Conv, [256, 3, 2]],[[-1, 14], 1, Concat, [1]], # cat head P4[-1, 3, C3, [512, False]], # 21 (P4/16-medium)[-1, 1, RFAConv, [512]], # 22[-1, 1, Conv, [512, 3, 2]],[[-1, 10], 1, Concat, [1]], # cat head P5[-1, 3, C3, [1024, False]], # 25 (P5/32-large)[-1, 1, RFAConv, [1024]], #26[[18, 22, 26], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)]4.3 RFAConv运行成功截图
附上我的运行记录确保我的教程是可用的。

4.4 推荐RFAConv可添加的位置
RFAConv是一种即插即用的可替换注意力机制的模块,其可以添加的位置有很多,添加的位置不同效果也不同,所以我下面推荐几个添加的位,置大家可以进行参考,当然不一定要按照我推荐的地方添加。
残差连接中:在残差网络的残差连接中加入RFAConv(yaml文件一)。
Neck部分:YOLOv8的Neck部分负责特征融合,这里添加修改后的C3_RFAConv可以帮助模型更有效地融合不同层次的特征(yaml文件二)。
检测头:可以再检测头前面添加(yaml文件三)
检测头中:可以再检测头的内部添加该机制(未提供因为需要修改检测头比较麻烦,后期专栏收费后大家购买专栏之后大家会得到一个包含上百个机制的v5文件里面包含所有的改进机制)
五、本文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的YOLOv5改进有效涨点专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的改进机制进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾:YOLOv5改进专栏——持续复现各种顶会内容——内含100+创新

相关文章:
YOLOv5改进 | 卷积篇 | 通过RFAConv重塑空间注意力(深度学习的前沿突破)
一、本文介绍 本文给大家带来的改进机制是RFAConv,全称为Receptive-Field Attention Convolution,是一种全新的空间注意力机制。与传统的空间注意力方法相比,RFAConv能够更有效地处理图像中的细节和复杂模式(适用于所有的检测对象都有一定的…...

056:vue工具 --- CSS在线格式化
第056个 查看专栏目录: VUE ------ element UI 专栏目标 在vue和element UI联合技术栈的操控下,本专栏提供行之有效的源代码示例和信息点介绍,做到灵活运用。 (1)提供vue2的一些基本操作:安装、引用,模板使…...

自定义IDEA代码补全插件
目标: 对于项目中的静态方法(主要是各种工具类里的静态方法),可以在输入方法名时直接提示相关的静态方法,选中后自动补全代码,并导入静态类。 设计: 初步构想,用户选择要导入的文…...
uniapp uview1.0 页面多个upload上传、回显之后处理数据
<view class"img-title w-s-color-3 f-28 row">商品图片</view><u-upload ref"images" :header"header" :file-list"fileListImages" :action"action" name"iFile" icon-name"camera"u…...
生活中的物理2——人类迷惑行为(用笔扎手)
1实验 材料 笔、手 实验 1、先用手轻轻碰一下笔尖(未成年人须家长监护) 2、再用另一只手碰碰笔尾 你发现了什么?? 2发现 你会发现碰笔尖的手明显比碰笔尾的手更痛 你想想为什么 3原理 压强f/s 笔尖的面积明显比笔尾的小 …...
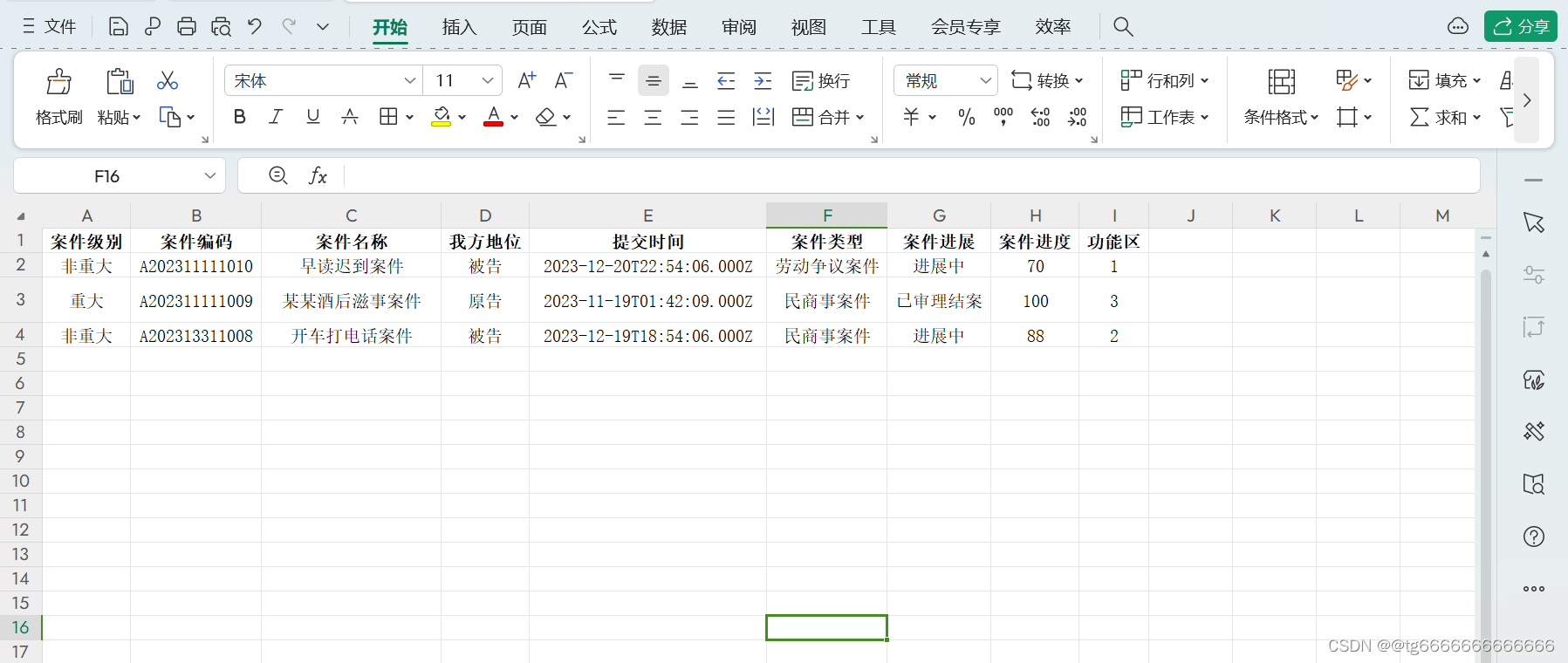
vue3表格导入导出.xlsx
在这次使用时恰好整出来了,希望大家也能学习到,特此分享出来 使用前确保安装以下模块,最好全局配置element-plus ### 展示一下 ### ###导出选项 ### ###导入de数据 ### 安装的模块 npm install js-table2excel // 安装js-table2excel n…...
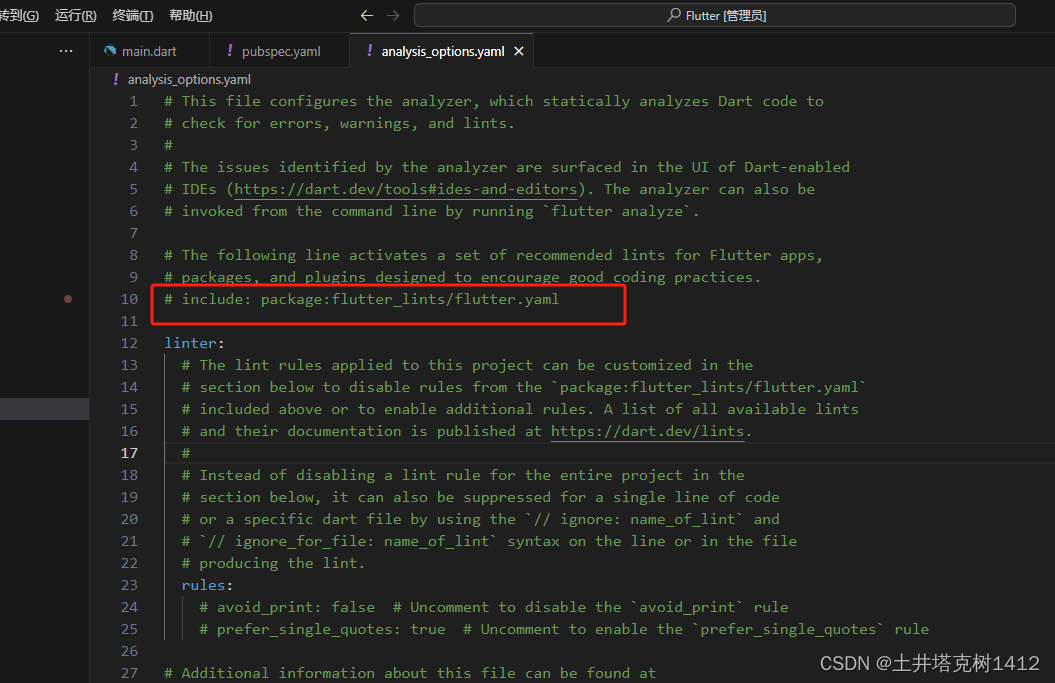
vscode dart语言出现蓝色波浪线
pubspec.yaml 注释掉:flutter_lints: ^2.0.0 analysis_options.yaml 注释掉:include: package:flutter_lints/flutter.yaml...

一种磁盘上循环覆盖文件策略
目录标题 1. 前言2. 软件设计流程思路3. 模拟测试3.1 分区准备工作3.2 模拟写数据3.3 测试 1. 前言 实际开发中经常需要存储数据, 无论是存储日志,还是二进制数据(图片,雷达数据或视频文件等), 不能一直存,是否存在一种策略: 当磁盘空间不足时…...
elementui消息弹出框MessageBox英文内容不换行问题
问题:当MessageBox内容为中文时,会自动换行,但当内容为英文时不会触发自动换行 如图,内容名称为英文时,名称太长会戳出提示框,不会自动换行 为数字英文会在英文数字处换行但是我们往往不需要它换行 解决方…...

WPF——样式和控件模板、数据绑定与校验转换
样式和控件模板 合并资源字典 Style简单样式的定义和使用 ControlTemplate控件模板的定义和使用 定义 使用 Trigger触发器 数据绑定与校验转换 数据绑定的设置 代码层实现绑定 数据模板DataTemplate xml文件的读取与显示 方法的返回值作为源绑定到控件中ObjectDataProvider L…...
服务器数据恢复-raid5故障导致上层分区无法访问的数据恢复案例
服务器数据恢复环境&故障: 一台服务器上3块硬盘组建了一组raid5磁盘阵列。服务器运行过程中有一块硬盘的指示灯变为红色,raid5磁盘阵列出现故障,服务器上层操作系统的分区无法识别。 服务器数据恢复过程: 1、将故障服务器上磁…...
石器时代H5小游戏架设教程
本文讲解石器时代 H5 之恐龙宝贝架设教程,想研究 H5 游戏如何实现,那请跟着此次教程学习在拥有小游戏源码的情况下该如何搭建起来 开始架设 1. 架设条件 石器时代架设需要准备: 一台linux 服务器,建议 CentOs 7.6 版本…...

计算机网络-网络协议
一、TCP/IP协议 作为一个小萌新,当然我无法将tcp/ip协议的大部分江山和盘托出,但是其中很多面试可能问到的知识,我觉得有必要总结一下! 首先,在学习tcp/ip协议之前,我们必须搞明白什么是tcp/ip协议。 1、…...

多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现KOA-CNN-BiGRU-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 MATLAB实现KOA-CNN-B…...
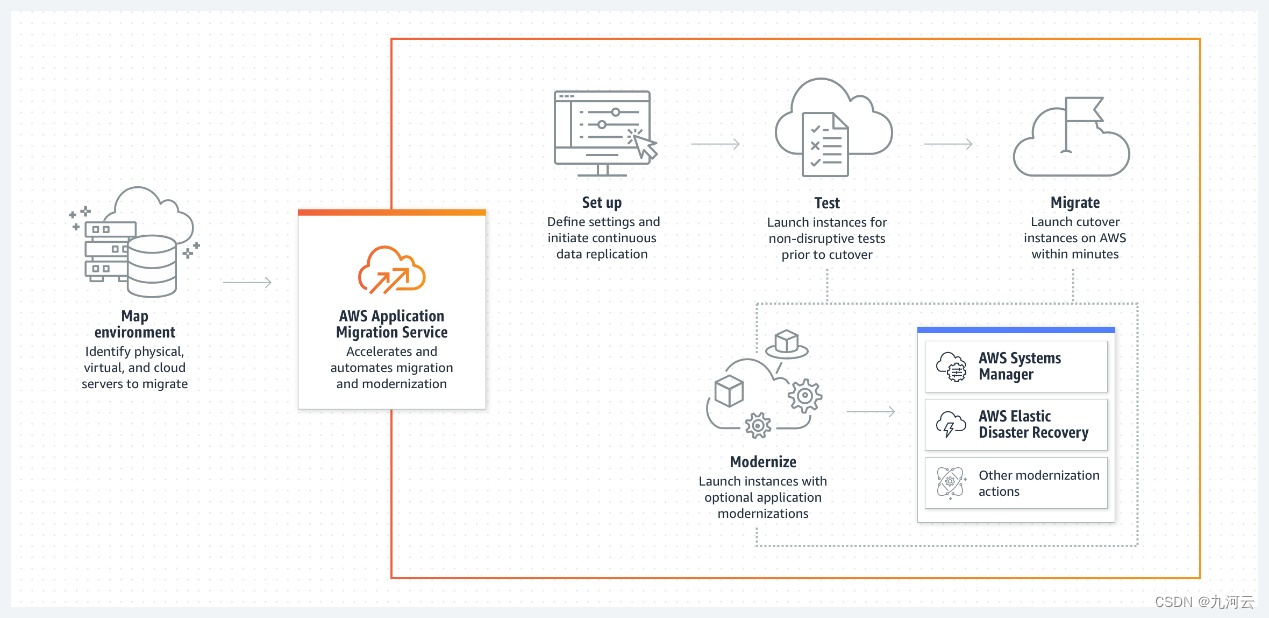
业务出海如何快速将站点搬迁到AWS云中?
随着国内市场趋于饱和,竞争压力越来越大,越来越多的企业选择出海,把业务放在海外做,从而追求更广阔的市场,获取更多客户。那都在讲出海,那怎么将站点完完整整的搬到海外呢?大家都会想࿰…...

ansible剧本playbook
Palybook组层部分 tasks 任务包含要在目标主机上执行的操作,使用模块定义这些操作,每个任务都是一个模块的调用variables变量:存储和传递数据,变量可以自定义,可以在palybook当中定义为全局变量,也可以在外部传参temp…...

.NET 中string类型的字符串内部化机制
当创建一个字符串时,如果具有相同字符序列的字符串已经存在于内存中,那么新创建的字符串会指向已经存在的那个字符串的内存地址,而不是创建一个全新的副本。这有助于节省内存,并提高字符串操作的效率。 因此相同内容的字符串变量…...

公共字段自动填充——后端
场景:当处理一些请求时,会重复的对数据库的某些字段进行赋值(如:在插入和更新某个物品时,需要更新该物品的更新时间和更新者的信息),这样会导致代码冗余。 如: 思路: 自…...

nginx upstream 6种负载均衡策略介绍
upstream参数 参数描述service反向服务地址加端口weight权重max_fails失败多少次,认为主机已经挂掉,踢出fail_timeout踢出后重新探测时间backup备用服务max_conns允许最大连接数slow_start当节点恢复,不立即加入 负载均衡策略 轮询&#x…...
基于Antd4 和React-hooks的项目开发
基于Antd4 和React-hooks的项目开发 https://github.com/dL-hx/react-cnode 项目依赖使用 react 16.13react-redux 7.xreact-router-dom 5.xredux 4.xantd 4axiosmoment 2.24 (日期格式化)qs 项目视图说明 首页主题详情用户列表用户详情关于 配置按需加载 https://3x.an…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

Linux链表操作全解析
Linux C语言链表深度解析与实战技巧 一、链表基础概念与内核链表优势1.1 为什么使用链表?1.2 Linux 内核链表与用户态链表的区别 二、内核链表结构与宏解析常用宏/函数 三、内核链表的优点四、用户态链表示例五、双向循环链表在内核中的实现优势5.1 插入效率5.2 安全…...

macOS多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用
文章目录 问题现象问题原因解决办法 问题现象 macOS启动台(Launchpad)多出来了:Google云端硬盘、YouTube、表格、幻灯片、Gmail、Google文档等应用。 问题原因 很明显,都是Google家的办公全家桶。这些应用并不是通过独立安装的…...

大模型多显卡多服务器并行计算方法与实践指南
一、分布式训练概述 大规模语言模型的训练通常需要分布式计算技术,以解决单机资源不足的问题。分布式训练主要分为两种模式: 数据并行:将数据分片到不同设备,每个设备拥有完整的模型副本 模型并行:将模型分割到不同设备,每个设备处理部分模型计算 现代大模型训练通常结合…...

自然语言处理——Transformer
自然语言处理——Transformer 自注意力机制多头注意力机制Transformer 虽然循环神经网络可以对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,但是它有一个很大的缺陷——很难并行化。 我们可以考虑用CNN来替代RNN,但是…...

mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包
文章目录 现象:mysql已经安装,但是通过rpm -q 没有找mysql相关的已安装包遇到 rpm 命令找不到已经安装的 MySQL 包时,可能是因为以下几个原因:1.MySQL 不是通过 RPM 包安装的2.RPM 数据库损坏3.使用了不同的包名或路径4.使用其他包…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

Web 架构之 CDN 加速原理与落地实践
文章目录 一、思维导图二、正文内容(一)CDN 基础概念1. 定义2. 组成部分 (二)CDN 加速原理1. 请求路由2. 内容缓存3. 内容更新 (三)CDN 落地实践1. 选择 CDN 服务商2. 配置 CDN3. 集成到 Web 架构 …...
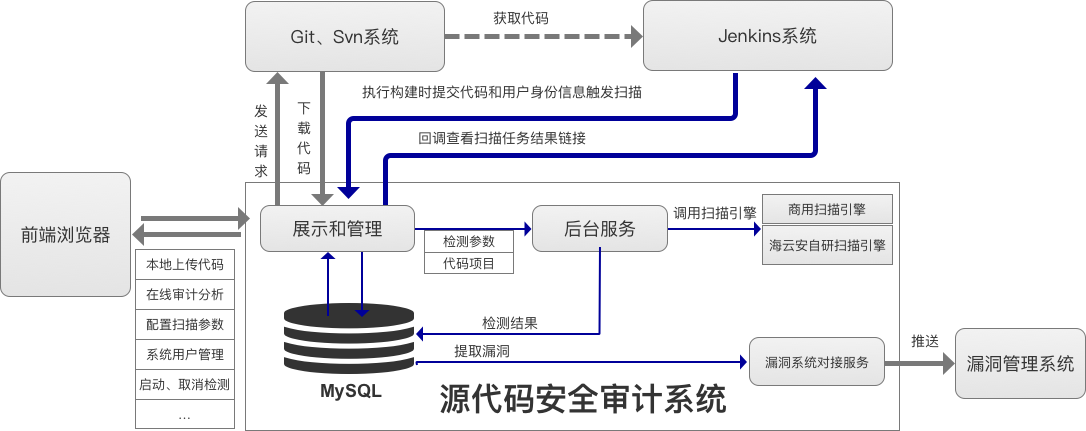
海云安高敏捷信创白盒SCAP入选《中国网络安全细分领域产品名录》
近日,嘶吼安全产业研究院发布《中国网络安全细分领域产品名录》,海云安高敏捷信创白盒(SCAP)成功入选软件供应链安全领域产品名录。 在数字化转型加速的今天,网络安全已成为企业生存与发展的核心基石,为了解…...
解析“道作为序位生成器”的核心原理
解析“道作为序位生成器”的核心原理 以下完整展开道函数的零点调控机制,重点解析"道作为序位生成器"的核心原理与实现框架: 一、道函数的零点调控机制 1. 道作为序位生成器 道在认知坐标系$(x_{\text{物}}, y_{\text{意}}, z_{\text{文}}…...