Elasticsearch 性能调优基础知识

Elastic Stack 已成为监控任何环境或应用程序的实际解决方案。 从日志、指标和正常运行时间到性能监控甚至安全,Elastic Stack 已成为满足几乎所有监控需求的一体化解决方案。 Elasticsearch 通过提供强大的分析引擎来处理任何类型的数据,成为这方面的基石。
Elasticsearch 旨在处理 TB 级的数据。 然而,这并不意味着 Elasticsearch 或 ELK 可以开箱即用地完美处理任何工作负载。 在大多数情况下,这是由于缺乏性能调整来满足确切的监控需求。 性能调优是令许多 DevOps 和系统管理员专业人员感到沮丧的一方面。 为了在 Elasticsearch 方面缓解这个问题,我们来看看如何开始调整 Elasticsearch 集群的性能。
评估你的要求
我们当然可以将环境中的所有数据推送到 Elasticsearch,但更好的问题是这样做是否能带来任何切实的好处。 是的,将所有数据放在一个易于访问的平台中可以简化事情。 然而,推送所有数据意味着更大且快速增长的数据集。 这很快就会变得笨重、成本高昂,甚至导致性能调整几乎不可能的情况。
避免这种情况的最简单方法是了解你需要从监控平台完成什么任务,并确定需要捕获并推送到 Elasticsearch 的优先级。 对最重要的数据进行分类,并将优化重点放在集群上,以满足这些高优先级数据集的需求。 假设你通过 S3 捕获 AWS VPC 流日志,但没有主动监控它们,那么将这些数据推送到 Elasticsearch 只是为了在需要时能够分析它们,这会浪费资源。 更好的解决方案是将这些数据保存在 S3 中,并在需要时使用 AWS Athena 等工具查询数据,或者在需要高级分析功能时推送数据子集。 你节省的容量可以在其他地方更好地利用,例如 APM 或其他日志,例如将更定期使用的应用程序错误日志。
例如,如果部署的主要需求是监控指标,那么更快的摄取和处理是关键。 如果我们专注于推送日志,存储也会在优化中发挥重要作用。 这是一个平衡游戏,需要选择需要推送的内容并优化摄取管道、存储和处理。 由于业务优先级不断变化,用户必须定期评估以确定需要优化的领域并定期更新优化。
硬件
无论进行怎样的优化,如果底层硬件没有足够的资源来处理摄取、处理和存储时的数据负载,用户仍然会遇到性能问题。 由于 Elasticsearch 旨在处理更大的数据集,因此需要适当的硬件资源才能实现最佳功能。 硬件资源的主要考虑因素是CPU、RAM 和存储。 你不仅需要资源来处理数据,还需要运行所需的应用程序本身。 你可能已经为摄取节点分配了足够的资源,但如果你的 Kibana 实例没有必要的资源,则部署将无法使用。
首先确定数据的确切需求,并考虑以下因素
- 摄入频率
- 数据加载
- 针对此数据运行的分析和查询的类型
- 存储要求、数据复制、保留期限
然后根据确定的需求为部署提供资源,并提供额外的空间以适应突然的使用高峰。
磁盘大小调整的注意事项
弄清楚集群的存储需求对于确保可靠的功能至关重要。 除了简单的磁盘容量要求外,用户还应该注意其他因素,例如 watermark 设置,当节点达到 85% 容量时将停止向节点发送分片,当节点达到容量的 90% 时完全停止写入现有分片 默认情况下。
如果配置了多个副本,则应该有足够的容量来容纳所有副本。 磁盘需要有足够的容量来处理所有这些需求,以及足够的空间,以便在发生故障或需要重新平衡时从其他节点重新定位分片。
索引和分片的容量规划
用户可以在 Elasticsearch 中创建任意数量的分片和索引,但不必要的大量分片和索引将会对集群管理级别以及日常使用带来显着的性能影响。
确定正确的分片和索引数量取决于多种因素,包括
- 可用硬件资源
- 数据的大小和复杂性
- 索引和分析需求、数据模型、查询需求
随着数据负载的增加,它直接影响负载,直接影响性能。 Elasticsearch 中的索引是一个或多个物理分片的逻辑分组。 更多分片意味着管理这些分片的开销更大,但查询大量较小的分片可以使每个分片的处理速度更快。 另一方面,处理相对较少的较大分片将导致更少的开销,有时在查询数据时可能会更快,但是在集群重新平衡等场景中,由于大小较大,可能需要更长的时间在不同节点之间移动分片,从而影响整个集群 表现。 Elastic 建议将以下内容作为起点。
- 目标是将平均分片大小保持在几 GB 到几十 GB 之间。 对于基于时间的数据的用例,通常会看到 20GB 到 40GB 范围内的分片。
- 避免大量分片问题。 节点可以容纳的分片数量与可用堆空间成正比。 作为一般规则,每 GB 堆空间的分片数量应小于 20。
最好的方法是使用我们将推送的数据进行测试以确定确切的要求。 最好在具有相对相似的数据集的临时集群中运行一些示例查询,然后在生产环境中镜像配置。
更多阅读:
-
Elasticsearch:我的 Elasticsearch 集群中应该有多少个分片?
-
Elasticsearch:如何部署 Elasticsearch 来满足自己的要求
-
Elasticsearch:Elasticsearch 容量规划
在实际的使用中,我们还需要注意到索引的生命周期管理。对于不常用的数据,我们可以把它放入到冻层或冷层。有管索引生命周期管理的知识,可以阅读文章:
-
Elasticsearch 索引生命周期和翻滚 (rollover) 策略
-
Elasticsearch:Index 生命周期管理入门
-
Elastic: 使用索引生命周期管理实现热温冷架构
负载均衡
处理大量请求的最佳方式是平衡多个节点之间的负载。 大多数生产集群将使用负载平衡在节点之间分配工作负载,并减少单个节点不堪重负的机会。 通过在多个节点之间分配工作负载,负载平衡将毫不费力地提高集群的整体性能。
Elasticsearch 默认提供负载均衡功能,唯一的要求是用户必须手动启用它。 用户可以将节点配置为协调节点以启用智能负载平衡,从而在节点之间分配负载。 根据需求,用户可以配置多个负载均衡器来针对不同数据处理需求的特定节点。 负载均衡不仅适用于数据摄取或处理,它影响集群的各个方面。 确保您有足够数量的节点来处理从摄取节点、数据节点到 Kibana 以及 APM 和 Fleet 节点的负载(具体取决于使用情况)。
在实践中,我们可以通过配置 coordination-only 节点来实现 Elasticsearch 节点的负载均衡。你可以参考文章 “Elasticsearch 中的一些重要概念: cluster, node, index, document, shards 及 replica” 以了解更多。
刷新间隔
数据被索引后不会立即可用,这是由于配置的刷新间隔控制内存缓冲区中存在的数据的写入时间。 这相当于刷新一个数据流以获得最新的结果。 如果刷新间隔设置为10秒,它将每10秒更新一次并为你提供最新的数据。
由于每次刷新都会消耗资源,跨多个流的多次连续或并行刷新会给集群带来压力,从而导致性能下降。 因此,用户必须微调刷新间隔。 指标和正常运行时间需要更快的刷新间隔,因为这些取决于最新数据。 同时,根据日志类型,日志可以有更大的间隔,例如,如果你正在监视 Nginx 访问/错误日志,则需要更快的间隔,但对于后台任务执行日志,我们可以有更大的间隔。
作为基本经验法则,需要不断更新的数据可以以较小的间隔保留,而不太重要的数据可以设置为较大的间隔,例如每小时甚至每天刷新。
监控性能指标
我们使用 Elasticsearch 进行监控,但我们不要忘记监控 Elasticsearch 和 ELK。 应持续监控集群的健康状况和节点可用性。 由于 Elasticsearch 性能与可用硬件资源相关,用户应监控集群内所有节点的性能指标,例如 CPU、内存使用情况和磁盘 I/O。 内存使用情况监控还包括 JVM 内存以及垃圾收集统计信息。
除了索引和分片的数量之外,还必须不断监控性能和查询延迟,以识别资源密集型查询和索引,并在必要时执行任何优化。 索引和分片可以完全删除或合并以减少资源开销。 可以优化查询,或者重新配置索引以提高性能,我们甚至可以添加额外的资源以保持集群性能最佳。 这主要适用于自托管集群,应监控网络延迟和性能,以确保集群内所有资源之间的可靠且快速的连接。
主动关注集群性能是消除性能问题的最佳预防措施。更多关于健康 Elastic Stack 的文章:
- Beats:通过 Metricbeat 实现外部对 Elastic Stack 的监视
- Elastic:通过 Logstash 或 Kafka 使用 Metricbeat 监控 Elastic Stack
- Elastic:监控 Elasticsearch 及 Kibana
- Elastic:监控 Beats 及 APM Server
- Logstash:使用 Metricbeat 监控 Logstash
-
Observability:集群监控 (一) - Elastic Stack 8.x
-
Observability:集群监控 (二) - Elastic Stack 8.x
结论
确定数据处理需求的优先级、提供足够的硬件资源、根据用户的具体需求优化集群以及持续监控是正确调整 Elasticsearch 集群以发挥最佳性能的基础。 初始优化可能非常耗时且艰巨,但可以获得显着的性能提升,并且对于任何集群来说都是必须做的。
相关文章:
Elasticsearch 性能调优基础知识
Elastic Stack 已成为监控任何环境或应用程序的实际解决方案。 从日志、指标和正常运行时间到性能监控甚至安全,Elastic Stack 已成为满足几乎所有监控需求的一体化解决方案。 Elasticsearch 通过提供强大的分析引擎来处理任何类型的数据,成为这方面的基…...

速盾网络:网络安全守护者
速盾网络作为一家专业的网络安全服务提供商,致力于为企业和个人提供全面、高效、可靠的网络安全解决方案。以下是速盾网络的主要业务介绍: 一、CDN加速 速盾网络拥有全球化的CDN加速网络,通过分布在全球各地的节点,为客户提供快速…...

jmeter如何参数化?Jmeter参数化设置的5种方法
jmeter如何参数化?我们使用jmeter在进行测试的时候,测试数据是一项重要的准备工作,每次迭代的数据当不一样的时候,需要进行参数化,从参数化的文件中来读取测试数据。那么,你知道jmeter如何进行参数化吗&…...
01AVue入门(持续学习中)
1.使用AVue开发简单的前端页面直接简单到起飞,他是Element PlusVueVite开发的,不需要向元素的前端代码一样一个组件要传很多参数,他可以使用Json文本来控制我们要传入的数据结构来决定显示什么 //我使用的比较新,我们也可以使用cdn直接使用script标签直接引入 2.开发中遇到的坑…...

js 深浅拷贝的区别和实现方法
一:什么浅拷贝: 浅拷贝创建一个新对象,然后将原始对象的所有属性值复制到新对象中。这意味着,如果原始对象的属性值是基本类型(例如数字、字符串),那么这些值会被直接复制到新对象中。但如果属…...
【jvm从入门到实战】(九) 垃圾回收(2)-垃圾回收器
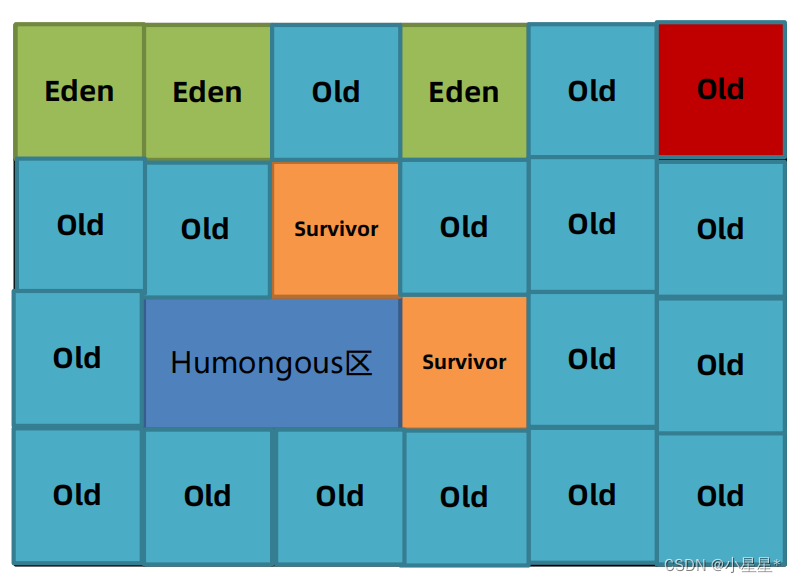
垃圾回收器是垃圾回收算法的具体实现。 由于垃圾回收器分为年轻代和老年代,除了G1之外其他垃圾回收器必须成对组合进行使用 垃圾回收器的组合使用关系图如下。 常用的组合如下: Serial(新生代) Serial Old(老年代) Pa…...

C#基础——匿名函数和参数不固定的函数
匿名函数、参数不固定的函数 匿名函数:没有名字,又叫做lambda表达式,具有简洁,灵活,可读的特性。 具名函数:有名字的函数。 1、简洁性:使用更少的代码实现相同的功能 MyDelegate myDelegate…...
lM-ICP)
PCL 点云匹配 4 之 (非线性迭代点云匹配)lM-ICP
一、IM迭代法 PCL IterativeClosestPointNonLinear 非线性L-M迭代法-CSDN博客 Matlab 非线性迭代法(3)阻尼牛顿法 L-M-CSDN博客 MATLAB实现最小二乘法_matlab最小二乘法-CSDN博客...

MySQL_14.数据库高速缓冲区空间管理
数据库高速缓冲区空间管理 Oracle 用 LRU(Least Recently Used)算法来管理数据高速缓冲区。该算法将最近使用的 数据块按照使用时间的早晚排成队列,当缓冲区占满后,调入新的数据块时,必须清除已有的数据 块,…...
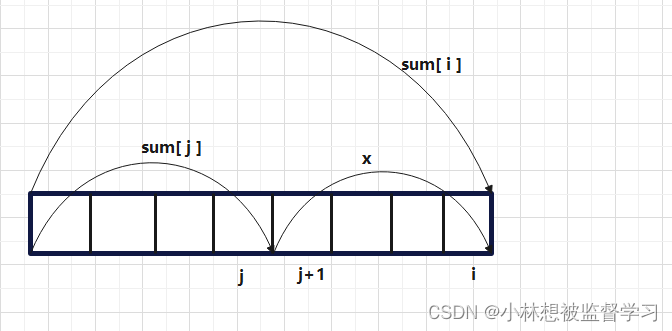
leetcode 974. 和可被 K 整除的子数组(优质解法)
代码: class Solution {public int subarraysDivByK(int[] nums, int k) {HashMap<Integer,Integer> hashMapnew HashMap();hashMap.put(0,1);int count0; //记录子数组的个数int last0; //前一个下标的前缀和int now0; //当前下标的前缀和for(int i0;…...

【技术】MySQL 日期时间操作
MySQL 日期时间操作 MySQL 系统时间MySQL 时间格式化MySQL 年月日时分秒周MySQL 日期计算时分秒时差日期差日期加减 MySQL 系统时间 now():系统时间,年月日时分秒current_date:系统时间,年月日current_time:系统时间&…...

测试理论知识三:测试用例、测试策略
1.测试用例 完全的测试是不可能的,对任何程序的测试必定是不完全的,那么,最显然的测试策略就是努力使测试尽可能完全。 进行测试前,推荐先使用黑盒测试的方法设计测试用例,然后使用白盒测试方法来补充的测试用例。 2…...
【clickhouse】在CentOS中离线安装clickhouse
https://packages.clickhouse.com/rpm/stable/ 通过如下命令检查是否安装过clickhouse [root172 ~]# rpm -qa | grep clickhouse 把rpm安装包放到opt/lzh目录 按照如下命令顺序安装 [root172 /]# rpm -ivh /opt/lzh/clickhouse-common-static-22.1.2.2-2.x86_64.rpm [root…...

微信商户号申请0.2费率
我们都知道,目前市场上的支付宝或者微信商户收款,无论是线上收款还是实体店收款,一般都采用0.6%的收款费率,1万元就是60元。 其实这不低的。 大多数线下实体店商家可能使用的聚合支付码可能是0.38%,1万元是38。 虽然不…...

基于单片机设计的电子指南针(LSM303DLH模块(三轴磁场 + 三轴加速度)
一、前言 本项目是基于单片机设计的电子指南针,主要利用STC89C52作为主控芯片和LSM303DLH模块作为指南针模块。通过LCD1602液晶显示屏来展示检测到的指南针信息。 在日常生活中,指南针是一种非常实用的工具,可以帮助我们确定方向࿰…...

深度学习 该用什么标准判断差异最小
决定差异最小的标准通常依赖于您的具体问题和任务。以下是一些常见的用于评估预测性能的标准和思路: 1. **均方根误差 (RMSE):** RMSE 是预测值和真实值之间差异的平方的平均值的平方根。它对较大的误差更加敏感。 from sklearn.metrics import mean_squared_error…...
汽车制造厂设备故障预测与健康管理PHM
在现代汽车制造工业中,设备的可靠性和稳定性对于保证生产线的高效运行至关重要。为了提高生产效率、降低维修成本以及确保产品质量,汽车制造厂逐渐采用设备故障预测与健康管理(PHM)系统,以实现对设备状态的实时监测和预…...
如何通过宝塔面板搭建一个MySQL数据库服务并实现无公网ip远程访问?
文章目录 前言1.Mysql服务安装2.创建数据库3.安装cpolar3.2 创建HTTP隧道 4.远程连接5.固定TCP地址5.1 保留一个固定的公网TCP端口地址5.2 配置固定公网TCP端口地址 前言 宝塔面板的简易操作性,使得运维难度降低,简化了Linux命令行进行繁琐的配置,下面简单几步,通过宝塔面板cp…...
C++ Qt开发:TabWidget实现多窗体功能
Qt 是一个跨平台C图形界面开发库,利用Qt可以快速开发跨平台窗体应用程序,在Qt中我们可以通过拖拽的方式将不同组件放到指定的位置,实现图形化开发极大的方便了开发效率,本章将重点介绍TabWidget标签组件的常用方法及灵活运用。 Q…...

【轻量化篇】YOLOv8改进实战 | 更换主干网络 Backbone 之 RepGhostnet,重参数化实现硬件高效的Ghost模块
YOLOv8专栏导航:点击此处跳转 前言 轻量化网络设计是一种针对移动设备等资源受限环境的深度学习模型设计方法。下面是一些常见的轻量化网络设计方法: 网络剪枝:移除神经网络中冗余的连接和参数,以达到模型压缩和加速的目的。分组卷积:将卷积操作分解为若干个较小的卷积操…...

超短脉冲激光自聚焦效应
前言与目录 强激光引起自聚焦效应机理 超短脉冲激光在脆性材料内部加工时引起的自聚焦效应,这是一种非线性光学现象,主要涉及光学克尔效应和材料的非线性光学特性。 自聚焦效应可以产生局部的强光场,对材料产生非线性响应,可能…...

鸿蒙中用HarmonyOS SDK应用服务 HarmonyOS5开发一个医院挂号小程序
一、开发准备 环境搭建: 安装DevEco Studio 3.0或更高版本配置HarmonyOS SDK申请开发者账号 项目创建: File > New > Create Project > Application (选择"Empty Ability") 二、核心功能实现 1. 医院科室展示 /…...

基于Uniapp开发HarmonyOS 5.0旅游应用技术实践
一、技术选型背景 1.跨平台优势 Uniapp采用Vue.js框架,支持"一次开发,多端部署",可同步生成HarmonyOS、iOS、Android等多平台应用。 2.鸿蒙特性融合 HarmonyOS 5.0的分布式能力与原子化服务,为旅游应用带来…...

九天毕昇深度学习平台 | 如何安装库?
pip install 库名 -i https://pypi.tuna.tsinghua.edu.cn/simple --user 举个例子: 报错 ModuleNotFoundError: No module named torch 那么我需要安装 torch pip install torch -i https://pypi.tuna.tsinghua.edu.cn/simple --user pip install 库名&#x…...

【生成模型】视频生成论文调研
工作清单 上游应用方向:控制、速度、时长、高动态、多主体驱动 类型工作基础模型WAN / WAN-VACE / HunyuanVideo控制条件轨迹控制ATI~镜头控制ReCamMaster~多主体驱动Phantom~音频驱动Let Them Talk: Audio-Driven Multi-Person Conversational Video Generation速…...
: 一刀斩断视频片头广告)
快刀集(1): 一刀斩断视频片头广告
一刀流:用一个简单脚本,秒杀视频片头广告,还你清爽观影体验。 1. 引子 作为一个爱生活、爱学习、爱收藏高清资源的老码农,平时写代码之余看看电影、补补片,是再正常不过的事。 电影嘛,要沉浸,…...

yaml读取写入常见错误 (‘cannot represent an object‘, 117)
错误一:yaml.representer.RepresenterError: (‘cannot represent an object’, 117) 出现这个问题一直没找到原因,后面把yaml.safe_dump直接替换成yaml.dump,确实能保存,但出现乱码: 放弃yaml.dump,又切…...

前端调试HTTP状态码
1xx(信息类状态码) 这类状态码表示临时响应,需要客户端继续处理请求。 100 Continue 服务器已收到请求的初始部分,客户端应继续发送剩余部分。 2xx(成功类状态码) 表示请求已成功被服务器接收、理解并处…...

【实施指南】Android客户端HTTPS双向认证实施指南
🔐 一、所需准备材料 证书文件(6类核心文件) 类型 格式 作用 Android端要求 CA根证书 .crt/.pem 验证服务器/客户端证书合法性 需预置到Android信任库 服务器证书 .crt 服务器身份证明 客户端需持有以验证服务器 客户端证书 .crt 客户端身份…...
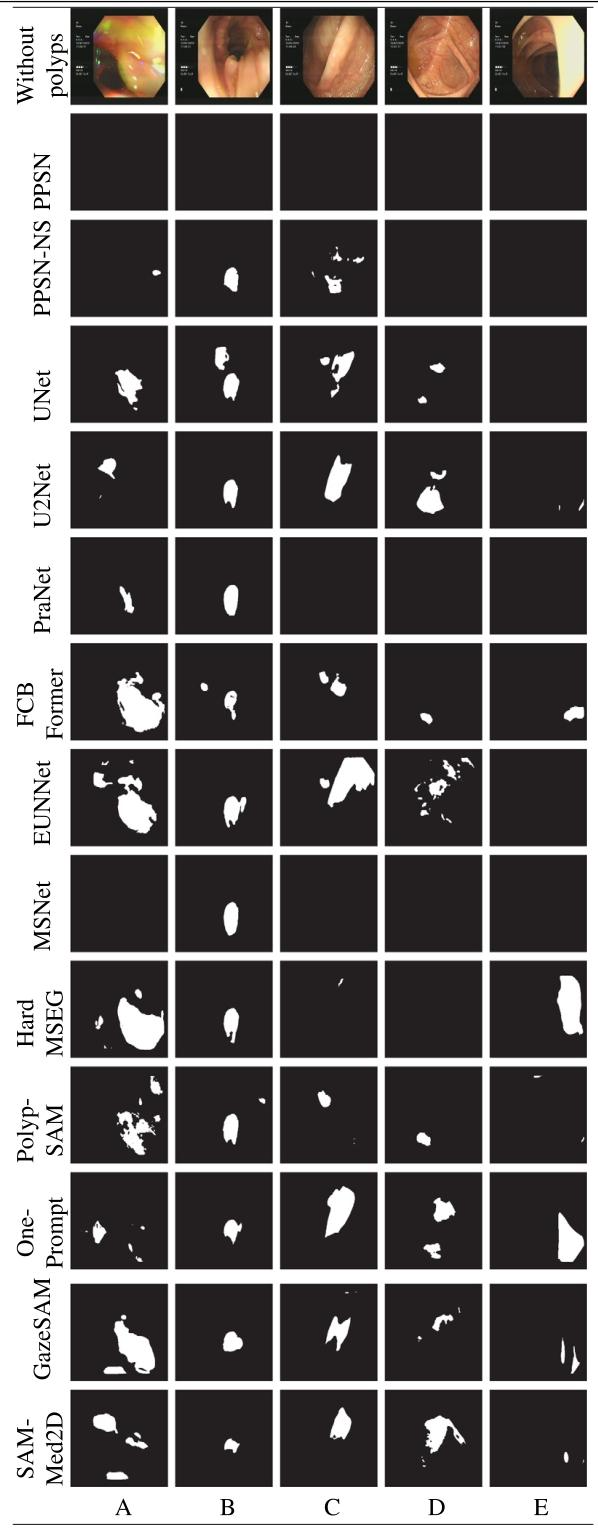
内窥镜检查中基于提示的息肉分割|文献速递-深度学习医疗AI最新文献
Title 题目 Prompt-based polyp segmentation during endoscopy 内窥镜检查中基于提示的息肉分割 01 文献速递介绍 以下是对这段英文内容的中文翻译: ### 胃肠道癌症的发病率呈上升趋势,且有年轻化倾向(Bray等人,2018&#x…...