目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
Hi, I’m Shendi
1、目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
在最近有了个物体识别的需求,于是开始学习
在一番比较与询问后,最终选择 TensorFlow。
对于编程语言,我比较偏向Java或nodejs的,而TensorFlow这两者都是支持的,但是我看了下Java的API,标记了一个D…弃用的标识,而nodejs经过询问说不定有些功能可能没有,语言只是工具,所以最终还是选择了首选的Python
前置准备
因为使用python,在开始前,需要安装Python与pip
可以参考这篇文章 Python+pip下载与安装 https://sdpro.top/blog/html/article/1207.html
需要注意的是,对Python版本是有要求的,我因为版本过高无法安装TensorFlow,可以在下面链接查看版本要求
https://tensorflow.google.cn/install/pip?hl=zh-cn#system-install

否则会出现下面这样的问题:

这是 TensorFlow 官网:https://www.tensorflow.org/
官网的初学者快速入门教程:https://www.tensorflow.org/tutorials/quickstart/beginner
使用 pip 安装 TensorFlow
使用以下命令安装
pip3 install tensorflow
我使用了阿里云的镜像,需要增加额外参数信任此地址才能继续

等待下载完成就可以直接使用了
入门
这里通过官网的初学者 TensorFlow 2.0教程入门
初学者的 TensorFlow 2.0 教程
对于啥也不懂的我来说确实有点难以…
主要是其中的代码,讲述的大概不够清晰,不知道结果是什么样。通过查阅资料以及询问 GPT,总算是ok了
就分那么几步
第一步,导入 TensorFlow
import tensorflow as tf
第二步,加载数据集
关于这个数据集,我是懵逼的,官网就三行代码,也没有什么描述,但是有个链接,点进去,全英文
标题翻译过来是这样的:MNIST数据库的手写数字
根据询问gpt,的确是这样的
官方的描述与代码:
加载并准备 MNIST 数据集。将样本数据从整数转换为浮点数:
mnist = tf.keras.datasets.mnist(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
这样不知道数据集到底是什么,所以我通过询问GPT,得知了显示数据集的方法,直接显示报错,所以保存成图片的方式来显示
需要安装 matplotlib 库
pip install matplotlib
然后在代码导入
import matplotlib.pyplot as plt
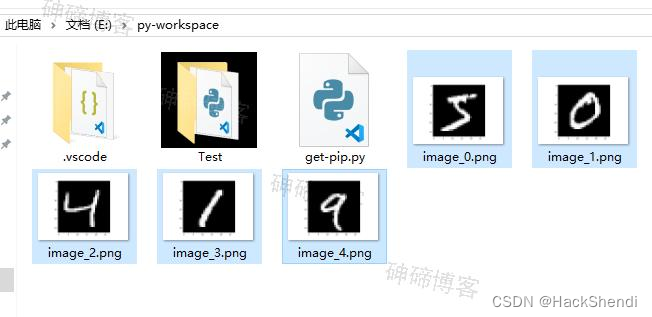
在加载完数据集后插入这样的代码,将数据集的几张图片保存
# 可视化前几个训练集样本的图像并保存为文件
for i in range(5): # 查看前五个样本print("标签:", y_train[i])plt.imshow(x_train[i], cmap='gray')plt.savefig(f'image_{i}.png') # 将图像保存为文件plt.close() # 关闭当前图像,准备绘制下一张图像
运行后,可以在当前文件的上级文件夹看到对应的图片了,是手写数字图
第三步,构建机器学习模型
这里直接复制官网的代码据可以了,毕竟刚学,重要的是体验
通过堆叠层来构建 tf.keras.Sequential 模型。
model = tf.keras.models.Sequential([tf.keras.layers.Flatten(input_shape=(28, 28)),tf.keras.layers.Dense(128, activation='relu'),tf.keras.layers.Dropout(0.2),tf.keras.layers.Dense(10)
])对于每个样本,模型都会返回一个包含 logits 或 log-odds 分数的向量,每个类一个。
在深度学习的分类问题中,模型通常最后一层输出的是一个包含每个类别得分的向量,这些得分被称为 logits 或 log-odds 分数。Logits 不是直接的概率值,它们表示模型对每个类别的置信程度或分数。
举例来说,如果你的模型对手写数字进行分类,输出层可能会生成一个包含 10 个元素的向量,对应着数字 0 到 9。这个向量中的每个元素都代表了模型认为图像属于对应数字的得分,比如对于数字 3 的 logits 可能是 6.2,对于数字 7 可能是 3.1,而对于数字 1 可能是 1.5 等等。
predictions = model(x_train[:1]).numpy()
predictions
上面可以使用 print 将 predictions 打印查看,是一个数组
这行代码是在使用训练好的模型对输入数据进行预测,其中
x_train[:1]表示取训练集中的第一个样本(在 TensorFlow 中,通常使用的索引是从 0 开始的)。
model(x_train[:1])这部分代码是将训练好的模型应用在第一个训练样本上,得到模型的预测结果。预测结果是一个包含每个类别的 logits(或 log-odds 分数)的向量。通过
.numpy()方法,将 TensorFlow 的张量对象转换为 NumPy 数组,以便查看预测结果。这个操作对于初步了解模型在单个样本上的预测结果非常有用。这样可以看到模型对于这个特定样本的预测结果,了解模型的输出结构以及 logits 的分布情况。
tf.nn.softmax 函数将这些 logits 转换为每个类的概率:
tf.nn.softmax(predictions).numpy()
这行代码使用了 TensorFlow 中的
tf.nn.softmax()函数对模型的预测结果predictions进行 softmax 处理,将其转换为概率分布。具体来说,
tf.nn.softmax(predictions)将 logits(或 log-odds 分数)转换为对应的概率分布,这些概率表示模型对每个类别的预测概率。通过
.numpy()方法将 TensorFlow 的张量对象转换为 NumPy 数组,以便查看预测结果。这样处理后,你将得到每个类别的概率分布,可以看到模型对于这个特定样本,每个类别的预测概率值。
使用 losses.SparseCategoricalCrossentropy 为训练定义损失函数,它会接受 logits 向量和 True 索引,并为每个样本返回一个标量损失。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True)
此损失等于 true 类的负对数概率:如果模型确定类正确,则损失为零。
这个未经训练的模型给出的概率接近随机(每个类为 1/10),因此初始损失应该接近 -tf.math.log(1/10) ~= 2.3。
loss_fn(y_train[:1], predictions).numpy()
可以通过 print 打印上面的执行结果
在开始训练之前,使用 Keras Model.compile 配置和编译模型。将 optimizer 类设置为 adam,将 loss 设置为您之前定义的 loss_fn 函数,并通过将 metrics 参数设置为 accuracy 来指定要为模型评估的指标。
model.compile(optimizer='adam',loss=loss_fn,metrics=['accuracy'])
第四步,训练并评估模型
使用 Model.fit 方法调整您的模型参数并最小化损失
model.fit(x_train, y_train, epochs=5)
Model.evaluate 方法通常在 “Validation-set” 或 “Test-set” 上检查模型性能。
model.evaluate(x_test, y_test, verbose=2)
可以将上面的结果通过 print 打印,是一个数组,有两个值
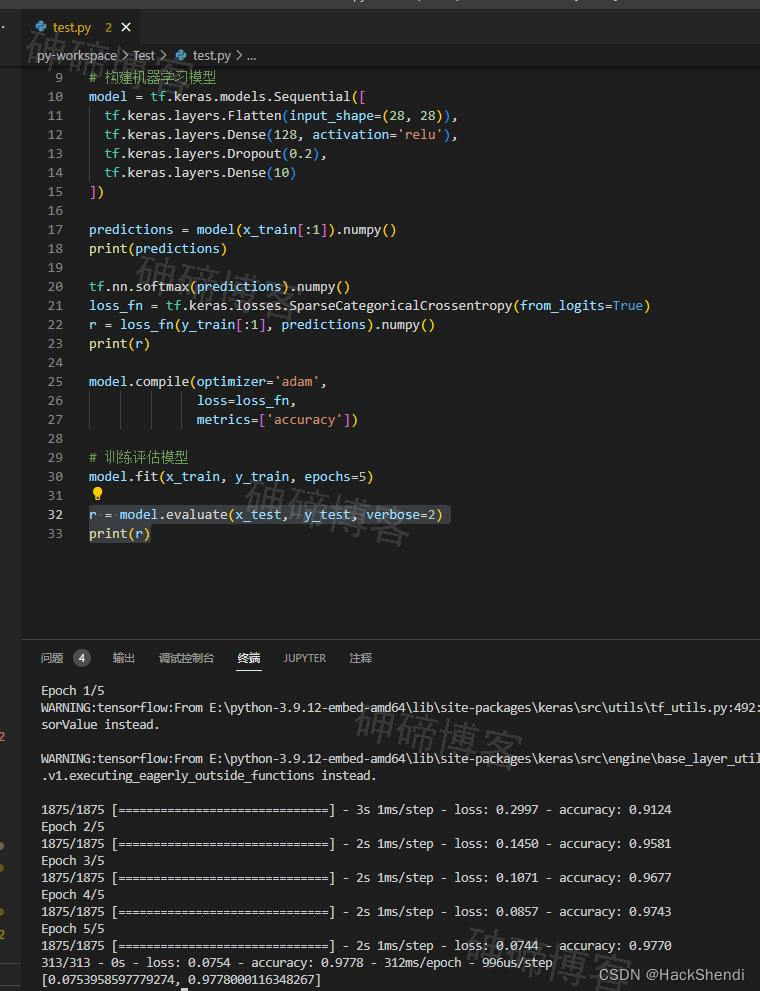
- 第一个值
0.0753958597779274是模型在测试集上的损失值。这个值表示模型在测试数据集上的平均损失程度,即模型在预测过程中与真实标签的差异程度。 - 第二个值
0.9778000116348267是模型在测试集上的准确率(或其他指定的评估指标)。在分类问题中,通常使用准确率来衡量模型的性能,它表示模型在测试集上正确预测的样本比例。
这两个值分别展示了模型在测试数据集上的损失程度和整体性能。较低的损失值和较高的准确率通常意味着模型在这个测试数据集上表现良好。
如果您想让模型返回概率,可以封装经过训练的模型,并将 softmax 附加到该模型:
probability_model = tf.keras.Sequential([model,tf.keras.layers.Softmax()
])probability_model(x_test[:5])
到这里就算是体验了下吧,下节将这个模型尝试使用,看看能不能识别出数字
结论
恭喜!您已经利用 Keras API 借助预构建数据集训练了一个机器学习模型。
有关使用 Keras 的更多示例,请查阅教程。要详细了解如何使用 Keras 构建模型,请阅读指南。如果您想详细了解如何加载和准备数据,请参阅有关图像数据加载或 CSV 数据加载的教程。
END
相关文章:
目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估
Hi, I’m Shendi 1、目标检测入门体验,技术选型,加载数据集、构建机器学习模型、训练并评估 在最近有了个物体识别的需求,于是开始学习 在一番比较与询问后,最终选择 TensorFlow。 对于编程语言,我比较偏向Java或nod…...

【UE5插件推荐】运行时,通过HTTP / HTTPS下载文件(Runtime Files Downloader)
UE5 github Home gtreshchev/RuntimeFilesDownloader Wiki (github.com)...
信息论安全与概率论
目录 一. Markov不等式 二. 选择引理 三. Chebyshev不等式 四. Chernov上限 4.1 变量大于 4.2 变量小于 信息论安全中会用到很多概率论相关的上界,本文章将梳理几个论文中常用的定理,重点关注如何理解这些定理以及怎么用。 一. Markov不等式 假定…...
各种不同语言分别整理的拿来开箱即用的8个开源免费单点登录(SSO)系统
各种不同语言分别整理的拿来开箱即用的8个开源免费单点登录(SSO)系统。 单点登录(SSO)是一个登录服务层,通过一次登录访问多个应用。使用SSO服务可以提高多系统使用的用户体验和安全性,用户不必记忆多个密…...

Netty Review - 优化Netty通信:如何应对粘包和拆包挑战
文章目录 概述Pre概述场景复现解决办法概览方式一: 特殊分隔符分包 (演示Netty提供的众多方案中的一种)流程分析 方式二: 发送长度(推荐) DelimiterBasedFrameDecoder 源码分析 概述 Pre Netty Review - 借助SimpleTalkRoom初体验…...

vue介绍以及基本指令
目录 一、vue是什么 二、使用vue的准备工作 三、创建vue项目 四、vue插值表达式 五、vue基本指令 六、key的作用 七、v-model 九、指令修饰符 一、vue是什么 Vue是一种用于构建用户界面的JavaScript框架。它可以帮助开发人员构建单页应用程序和复杂的前端应用程序。Vue…...

重塑数字生产力体系,生成式AI将开启云计算未来新十年?
科技云报道原创。 今天我们正身处一个历史的洪流,一个巨变的十字路口。生成式AI让人工智能技术完全破圈,带来了机器学习被大规模采用的历史转折点。 它掀起的新一轮科技革命,远超出我们今天的想象,这意味着一个巨大的历史机遇正…...

JFreeChart 生成图表,并为图表标注特殊点、添加文本标识框
一、项目场景: Java使用JFreeChart库生成图片,主要场景为将具体的数据 可视化 生成曲线图等的图表。 本篇文章主要针对为数据集生成的图表添加特殊点及其标识框。具体包括两种场景:x轴为 时间戳 类型和普通 数值 类型。(y轴都为…...

vue整合axios 未完
一、简介 1、介绍 axios前端异步请求库类似jouery ajax技术,axios用来在前端页面发起一个异步请求,请求之后页面不动,响应回来刷新页面局部;Axios 是一个基于 promise 的 HTTP 库,可以用在浏览器和 node.js 中 2、特…...

java代码编写twitter授权登录
在上一篇内容已经介绍了怎么申请twitter开放的API接口。 下面介绍怎么通过twitter提供的API,进行授权登录功能。 开发者页面设置 首先在开发者页面开启“用户认证设置”,点击edit进行信息编辑。 我的授权登录是个网页,并且只需要进行简单的…...
SK Ecoplant借助亚马逊云科技,海外服务器为环保事业注入新活力
在当今全球面临着资源紧缺和环境挑战的大背景下,数字技术所依赖的海外服务器正成为加速循环经济转型的关键利器。然而,很多企业在整合数字技术到运营中仍然面临着一系列挑战,依然存在低效流程导致的不必要浪费。针对这一问题,SK E…...
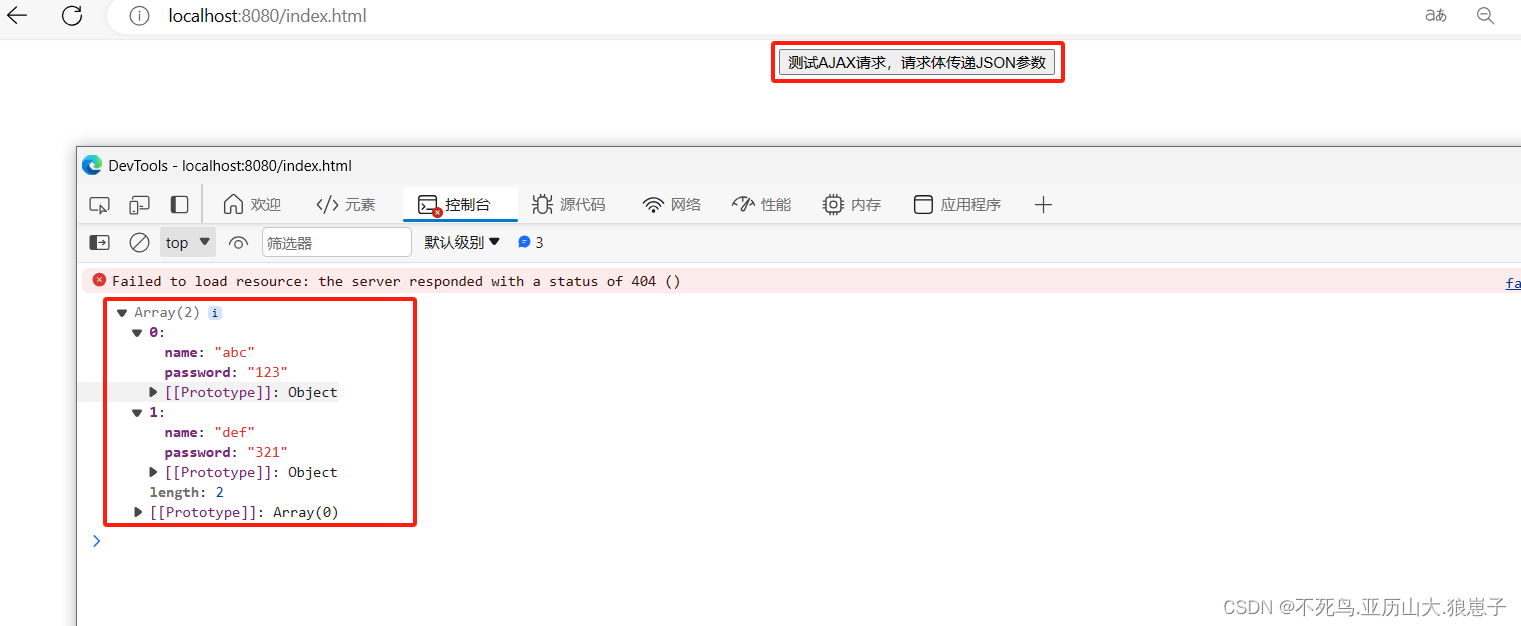
RPC(5):AJAX跨域请求处理
接上一篇RPC(4):HttpClient实现RPC之POST请求进行修改。 1 修改客户端项目 1.1 修改maven文件 修改后配置文件如下: <dependencyManagement><dependencies><dependency><groupId>org.springframework.b…...

用大白话举例子讲明白区块链
什么是区块链?网上这么说: 区块链是一种分布式数据库技术,它以块的形式记录和存储交易数据,并使用密码学算法保证数据的安全性和不可篡改性。每个块都包含了前一个块的哈希值和自身的交易数据,形成了一个不断增长的链条…...

Java URL
URL:统一资源定位符,说白了,就是一个网络 通过URLConnection类可以连接到URL,然后通过URLConnection可以获取读数据的通道。非文本数据用字节流来读取。 读完之后写入本地即可。 public class test {public static void main(S…...
:ETL涉及到的名词解释)
ETL-从1学到100(1/100):ETL涉及到的名词解释
本文章主要介绍ETL和大数据中涉及到名词,同时解释这些名词的含义。由于不是一次性收集这些名词,所以这篇文章将会持续更新,更新日志会存放在本段话下面: 12-19更新:OLTP、OLAP、BI、ETL。 12-20更新:ELT、…...

Jenkins + gitlab 持续集成和持续部署的学习笔记
1. Jenkins 介绍 软件开发生命周期(SLDC, Software Development Life Cycle):它集合了计划、开发、测试、部署的集合。 软件开发瀑布模型 软件的敏捷开发 1.1 持续集成 持续集成 (Continuous integration 简称 CI): 指的是频繁的将代码集成到主干。 持续集成的流…...

R语言【cli】——通过cli_abort用 cli 格式的内容显示错误、警告或信息,内部调用cli_bullets和inline-makeup
cli_abort(message,...,call .envir,.envir parent.frame(),.frame .envir ) 先从那些不需要下大力气理解的参数入手: 参数【.envir】:进行万能表达式编译的环境。 参数【.frame】:抛出上下文。默认用于参数【.trace_bottom】ÿ…...

cka从入门到放弃
无数次想放弃,最后选择了坚持 监控pod日志 监控名为 foobar 的 Pod 的日志,并过滤出具有 unable-access-website 信息的行,然后将 写入到 /opt/KUTR00101/foobar # 解析 监控pod的日志,使用kubectl logs pod-name kubectl logs…...

通过 jekyll 构建 github pages 博客实战笔记
jekyll 搭建教程 jekyll 搭建教程 Gem 安装 Ruby,请访问 下载地址。 Jekyll Jekyll 是一个简单且具备博客特性的静态网站生成器。 Jekyll 中文文档 极客学院中文文档 使用以下命令安装 Jekyll。 $ gem install jekyll在中国可能需要使用代理软件。然后ÿ…...

【AI美图】第09期效果图,AI人工智能汽车+摩托车系列图集
期待中的未来AI汽车 欢迎来到未来的世界,一个充满创新和无限可能的世界,这里有你从未见过的科技奇迹——AI汽车。 想象一下,你站在十字路口,繁忙的交通信号灯在你的视线中闪烁,汽车如潮水般涌来,但是&…...

终极指南:如何利用Awesome DevSecOps构建企业安全文化全流程
终极指南:如何利用Awesome DevSecOps构建企业安全文化全流程 【免费下载链接】awesome-devsecops An authoritative list of awesome devsecops tools with the help from community experiments and contributions. 项目地址: https://gitcode.com/gh_mirrors/aw…...

vLLM-v0.17.1环境快速部署:Windows系统下Python与CUDA配置详解
vLLM-v0.17.1环境快速部署:Windows系统下Python与CUDA配置详解 1. 前言:为什么选择vLLM? 如果你正在Windows系统上探索大语言模型的高效推理方案,vLLM绝对值得关注。这个由加州大学伯克利分校团队开发的开源项目,以其…...

利用 AI 提升开发效率:一款简洁实用的对话工具分享
在日常开发与技术学习过程中,合理使用 AI 工具已经成为提升效率的常见方式。无论是快速生成代码片段、梳理业务逻辑、解释技术概念,还是辅助撰写技术文档,一个稳定易用的 AI 工具都能有效减少重复工作,让我们更专注于核心技术实现…...

突破百度网盘下载限制的开源工具:免费提速技巧全解析
突破百度网盘下载限制的开源工具:免费提速技巧全解析 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘的龟速下载而烦恼吗&am…...

Bugku CTF: Exploiting LFI Vulnerabilities in Multi-Language Web Apps
1. 理解LFI漏洞的本质 本地文件包含(Local File Inclusion,简称LFI)是Web安全中常见的漏洞类型,它允许攻击者通过精心构造的输入参数读取服务器上的敏感文件。这种漏洞通常出现在动态包含文件的功能中,比如PHP的includ…...

零基础玩转OpenClaw:Qwen3.5-9B镜像云端体验指南
零基础玩转OpenClaw:Qwen3.5-9B镜像云端体验指南 1. 为什么选择云端体验OpenClaw 作为一个长期在本地折腾AI工具的开发者,我完全理解新手面对环境配置时的恐惧。记得第一次尝试部署本地AI助手时,光是解决Python版本冲突就花了两天时间。直到…...

孤能子视角:Kimi自我分析诊断[2],静态同构分析
(这也是Kimi的自分析诊断,上一分析为动态涌现法,这是静态同构法。里面所述技术及数值是否真实?)场域切换:静态同构模式已激活X光切片:当前互动场的截面解剖时间已冻结。以下是对"此刻的我"这一关系势能凝结体…...

HowTo-易连EDI-EasyLink如何实现Email收发
在数字化通信时代,Email作为最基础的互联网服务之一,其背后依赖着一套复杂的协议体系来实现邮件的发送、接收和管理。这些协议构成了电子邮件系统的技术基础,确保了不同邮件服务提供商之间的互操作性。在易连EDI-Easylink系统中,E…...

别再只传明文了!SpringBoot若依框架接口Base64加解密避坑指南
若依框架接口安全升级:Base64编码传输的实战陷阱与解决方案 在前后端分离架构中,数据安全传输一直是开发者关注的焦点。最近接手一个金融类项目改造,客户明确要求所有接口数据必须经过编码处理。当我信心满满地准备用Base64方案快速实现时&am…...

LangChain4j的ChatMemoryProvider实战:如何为不同用户/线程创建独立的AI对话记忆?
LangChain4j多用户对话隔离实战:ChatMemoryProvider架构设计与生产级优化 想象一下这样的场景:你的电商客服机器人正在同时处理数百个用户的咨询,每个用户都在进行独立的对话。突然,用户A询问订单状态,机器人却回复了用…...