esp32-s3训练自己的数据进行目标检测、图像分类
esp32-s3训练自己的数据进行目标检测、图像分类
- 一、下载项目
- 二、环境
- 三、训练和导出模型
- 四、部署模型
- 五、存在的问题
esp-idf的安装参考我前面的文章: esp32cam和esp32-s3烧录human_face_detect实现人脸识别
一、下载项目
- 训练、转换模型:ModelAssistant(main)
- 部署模型:sscma-example-esp32(1.0.0)
- 说明文档:sscma-model-zoo
二、环境
python3.8 + CUDA11.7 + esp-idf5.0
# 主要按照ModelAssistant/requirements_cuda.txt,如果训练时有库不兼容的问题可参考下方
torch 2.0.0+cu117
torchaudio 2.0.1+cu117
torchvision 0.15.1+cu117
yapf 0.40.2
typing_extensions 4.5.0
tensorboard 2.13.0
tensorboard-data-server 0.7.2
tensorflow 2.13.0
keras 2.13.1
tensorflow-estimator 2.13.0
tensorflow-intel 2.13.0
tensorflow-io-gcs-filesystem 0.31.0
sscma 2.0.0rc3
setuptools 60.2.0
rich 13.4.2
Pillow 9.4.0
mmcls 1.0.0rc6
mmcv 2.0.0
mmdet 3.0.0
mmengine 0.10.1
mmpose 1.2.0
mmyolo 0.5.0
三、训练和导出模型
- step 1: 将voc格式的标注文件转换为edgelab的训练格式,并按8:2的比例划分为训练集和验证集
import os
import json
import pandas as pd
from xml.etree import ElementTree as ET
from PIL import Image
import shutil
import random
from tqdm import tqdm# Set paths
voc_path = 'F:/datasets/VOCdevkit/VOC2007'
train_path = 'F:/edgelab/ModelAssistant/datasets/myself/train'
valid_path = 'F:/edgelab/ModelAssistant/datasets/meself/valid'# 只读取有目标的,且属于需要训练的类别
classes = ["face"]# Create directories if not exist
if not os.path.exists(train_path):os.makedirs(train_path)
if not os.path.exists(valid_path):os.makedirs(valid_path)# Get list of image files
image_files = os.listdir(os.path.join(voc_path, 'JPEGImages'))
random.seed(0)
random.shuffle(image_files)# Split data into train and valid
train_files = image_files[:int(len(image_files)*0.8)]
valid_files = image_files[int(len(image_files)*0.8):]# Convert train data to COCO format
train_data = {'categories': [], 'images': [], 'annotations': []}
train_ann_id = 0
train_cat_id = 0
img_id = 0
train_categories = {}
for file in tqdm(train_files):# Add annotationsxml_file = os.path.join(voc_path, 'Annotations', file[:-4] + '.xml')tree = ET.parse(xml_file)root = tree.getroot()for obj in root.findall('object'):category = obj.find('name').textif category not in classes:continueif category not in train_categories:train_categories[category] = train_cat_idtrain_cat_id += 1category_id = train_categories[category]bbox = obj.find('bndbox')x1 = int(bbox.find('xmin').text)y1 = int(bbox.find('ymin').text)x2 = int(bbox.find('xmax').text)y2 = int(bbox.find('ymax').text)width = x2 - x1height = y2 - y1ann_info = {'id': train_ann_id, 'image_id': img_id, 'category_id': category_id, 'bbox': [x1, y1, width, height],'area': width*height, 'iscrowd': 0}train_data['annotations'].append(ann_info)train_ann_id += 1if len(root.findall('object')):# 只有有目标的图片才加进来image_id = img_idimg_id += 1image_file = os.path.join(voc_path, 'JPEGImages', file)shutil.copy(image_file, os.path.join(train_path, file))img = Image.open(image_file)image_info = {'id': image_id, 'file_name': file, 'width': img.size[0], 'height': img.size[1]}train_data['images'].append(image_info)# Add categories
for category, category_id in train_categories.items():train_data['categories'].append({'id': category_id, 'name': category})# Save train data to file
with open(os.path.join(train_path, '_annotations.coco.json'), 'w') as f:json.dump(train_data, f, indent=4)# Convert valid data to COCO format
valid_data = {'categories': [], 'images': [], 'annotations': []}
valid_ann_id = 0
img_id = 0
for file in tqdm(valid_files):# Add annotationsxml_file = os.path.join(voc_path, 'Annotations', file[:-4] + '.xml')tree = ET.parse(xml_file)root = tree.getroot()for obj in root.findall('object'):category = obj.find('name').textif category not in classes:continuecategory_id = train_categories[category]bbox = obj.find('bndbox')x1 = int(bbox.find('xmin').text)y1 = int(bbox.find('ymin').text)x2 = int(bbox.find('xmax').text)y2 = int(bbox.find('ymax').text)width = x2 - x1height = y2 - y1ann_info = {'id': valid_ann_id, 'image_id': img_id, 'category_id': category_id, 'bbox': [x1, y1, width, height],'area': width*height, 'iscrowd': 0}valid_data['annotations'].append(ann_info)valid_ann_id += 1if len(root.findall('object')):# Add imageimage_id = img_idimg_id += 1image_file = os.path.join(voc_path, 'JPEGImages', file)shutil.copy(image_file, os.path.join(valid_path, file))img = Image.open(image_file)image_info = {'id': image_id, 'file_name': file, 'width': img.size[0], 'height': img.size[1]}valid_data['images'].append(image_info)# Add categories
valid_data['categories'] = train_data['categories']# Save valid data to file
with open(os.path.join(valid_path, '_annotations.coco.json'), 'w') as f:json.dump(valid_data, f, indent=4)
- step 2: 参考Face Detection - Swift-YOLO下载模型权重文件和训练
python tools/train.py configs/yolov5/yolov5_tiny_1xb16_300e_coco.py \
--cfg-options \work_dir=work_dirs/face_96 \num_classes=3 \epochs=300 \height=96 \width=96 \batch=128 \data_root=datasets/face/ \load_from=datasets/face/pretrain.pth
- step 3: 训练过程可视化tensorboard
cd work_dirs/face_96/20231219_181418/vis_data
tensorboard --logdir=./
然后按照提示打开http://localhost:6006/

- step 4: 导出模型
python tools/export.py configs/yolov5/yolov5_tiny_1xb16_300e_coco.py ./work_dirs/face_96/best_coco_bbox_mAP_epoch_300.pth --target tflite onnx
--cfg-options \work_dir=work_dirs/face_96 \num_classes=3 \epochs=300 \height=96 \width=96 \batch=128 \data_root=datasets/face/ \load_from=datasets/face/pretrain.pth
这样就会在./work_dirs/face_96路径下生成best_coco_bbox_mAP_epoch_300_int8.tflite文件了。
四、部署模型
- step 1: 将
best_coco_bbox_mAP_epoch_300_int8.tflite复制到F:\edgelab\sscma-example-esp32-1.0.0\model_zoo路径下 - step 2: 参照edgelab-example-esp32-训练和部署一个FOMO模型将模型转换为C语言文件,并将其放入到
F:\edgelab\sscma-example-esp32-1.0.0\components\modules\model路径下
python tools/tflite2c.py --input ./model_zoo/best_coco_bbox_mAP_epoch_300_int8.tflite --name yolo --output_dir ./components/modules/model --classes face
这样会生成./components/modules/model/yolo_model_data.cpp和yolo_model_data.h两个文件。
- step 3: 利用idf烧录程序

fb_gfx_printf(frame, yolo.x - yolo.w / 2, yolo.y - yolo.h/2 - 5, 0x1FE0, "%s:%d", g_yolo_model_classes[yolo.target], yolo.confidence);
打开esp-idf cmd
cd F:\edgelab\sscma-example-esp32-1.0.0\examples\yolo
idf.py set-target esp32s3
idf.py menuconfig
 勾选上方的这个选项不然报错
勾选上方的这个选项不然报错
E:/Softwares/Espressif/frameworks/esp-idf-v5.0.4/components/driver/deprecated/driver/i2s.h:27:2: warning: #warning "This set of I2S APIs has been deprecated, please include 'driver/i2s_std.h', 'driver/i2s_pdm.h' or 'driver/i2s_tdm.h' instead. if you want to keep using the old APIs and ignore this warning, you can enable 'Suppress leagcy driver deprecated warning' option under 'I2S Configuration' menu in Kconfig" [-Wcpp]27 | #warning "This set of I2S APIs has been deprecated, \| ^~~~~~~
ninja: build stopped: subcommand failed.
ninja failed with exit code 1, output of the command is in the F:\edgelab\sscma-example-esp32-1.0.0\examples\yolo\build\log\idf_py_stderr_output_27512 and F:\edgelab\sscma-example-esp32-1.0.0\examples\yolo\build\log\idf_py_stdout_output_27512
idf.py flash monitor -p COM3

lcd端也能实时显示识别结果,输入大小为96x96时推理时间大概200ms,192x192时时间大概660ms

五、存在的问题
该链路中量化是比较简单的,在我的数据集上量化后精度大打折扣,应该需要修改量化算法,后续再说吧。
- 量化前

- 量化后

相关文章:
esp32-s3训练自己的数据进行目标检测、图像分类
esp32-s3训练自己的数据进行目标检测、图像分类 一、下载项目二、环境三、训练和导出模型四、部署模型五、存在的问题 esp-idf的安装参考我前面的文章: esp32cam和esp32-s3烧录human_face_detect实现人脸识别 一、下载项目 训练、转换模型:ModelAssist…...
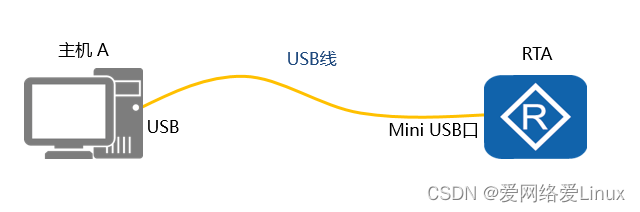
华为设备VRP基础
交换机可以隔离冲突域,路由器可以隔离广播域,这两种设备在企业网络中应用越来越广泛。随着越来越多的终端接入到网络中,网络设备的负担也越来越重,这时网络设备可以通过华为专有的VRP系统来提升运行效率。通用路由平台VRP…...

论文笔记 | ICLR 2023 WikiWhy:回答和解释因果问题
文章目录 一、前言二、主要内容三、总结🍉 CSDN 叶庭云:https://yetingyun.blog.csdn.net/ 一、前言 ICLR 2023 | Accept: notable-top-5%:《WikiWhy: Answering and Explaining Cause-and-Effect Questions》 一段话总结:WikiWhy 是一个新的 QA 数据集,围绕一个新的任务…...

LC24. 两两交换链表中的节点
代码随想录 class Solution {// 举例子:假设两个节点 1 -> 2// 那么 head 1; next 2; next.next null// 那么swapPairs(next.next),传入的是null,再下一次递归中直接返回null// 因此 newNode null// 所以 next.next head; > 2.next 1; 2 -> 1// head.next…...

使用redis-rds-tools 工具分析redis rds文件
redis-rdb-tools安装部署及使用 发布时间:2020-07-28 12:33:12 阅读:29442 作者:苏黎世1995 栏目:关系型数据库 活动:开发者测试专用服务器限时活动,0元免费领,库存有限,领完即止&…...
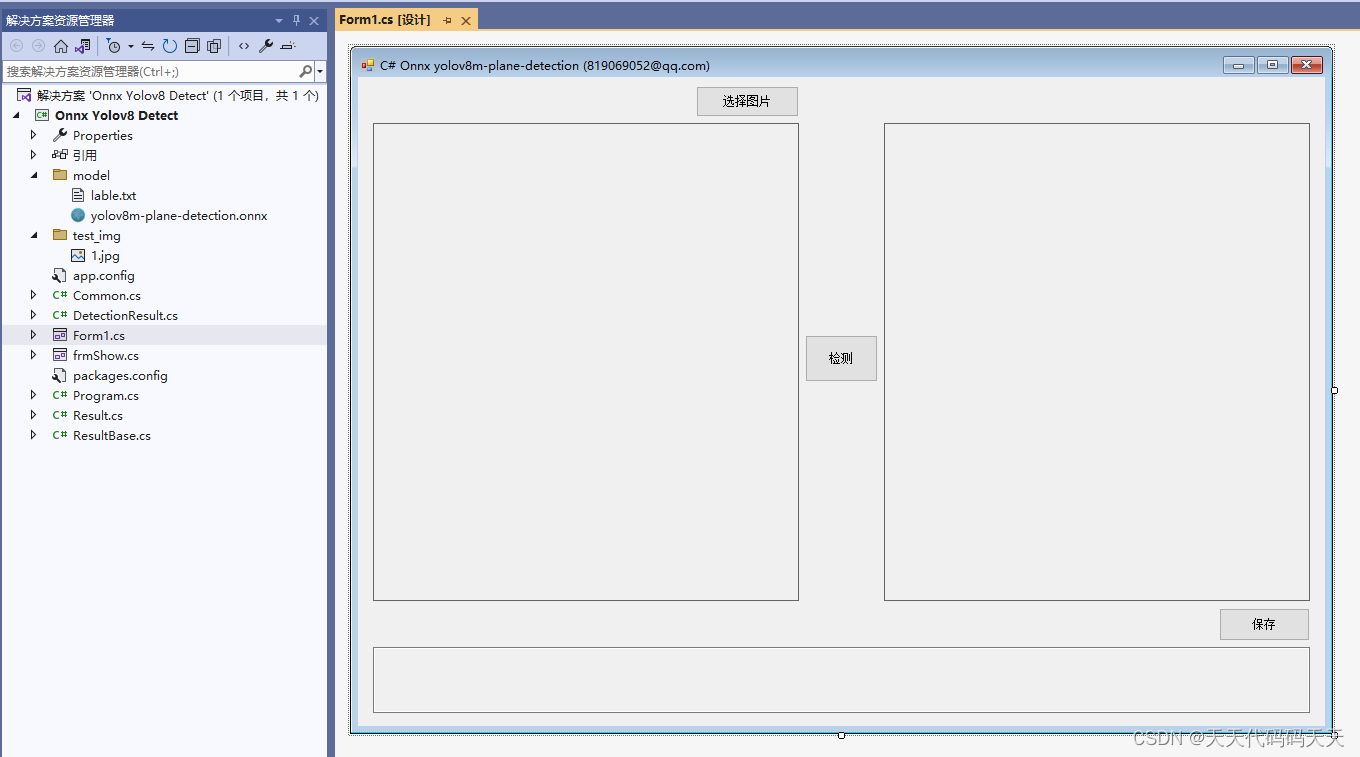
C# Onnx yolov8 plane detection
C# Onnx yolov8 plane detection 效果 模型信息 Model Properties ------------------------- date:2023-12-22T10:57:49.823820 author:Ultralytics task:detect license:AGPL-3.0 https://ultralytics.com/license version&am…...
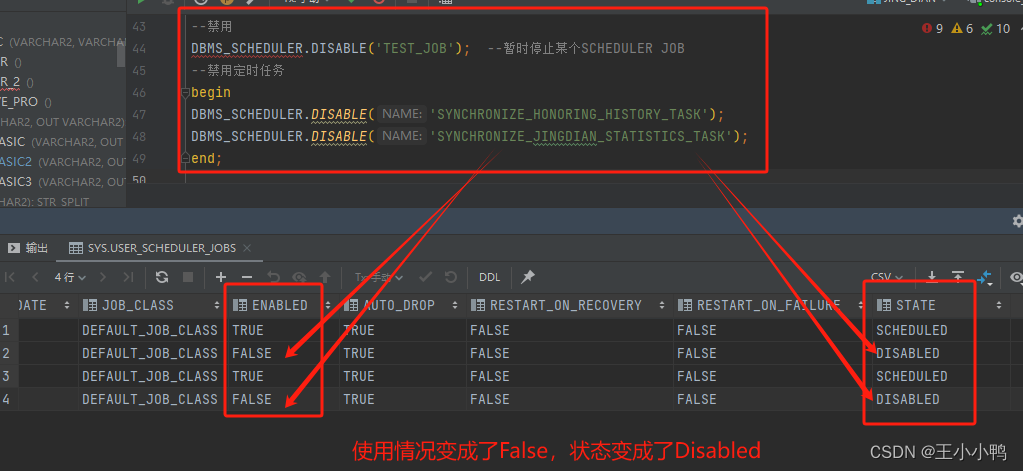
Oracle定时任务的创建与禁用/删除
在开始操作之前,先从三W开始,即我常说的what 是什么;why 为什么使用;how 如何使用。 一、Oracle定时器是什么 Oracle定时器是一种用于在特定时间执行任务或存储过程的工具,可以根据需求设置不同的时间段和频率来执行…...
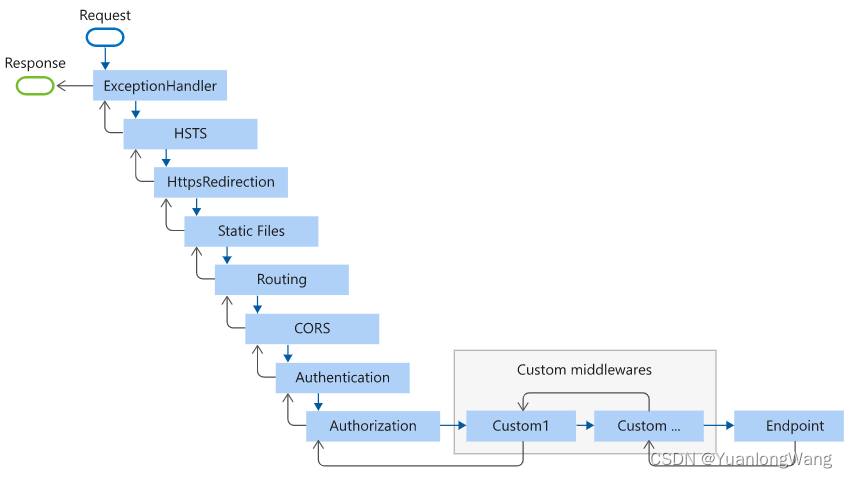
Asp.Net Core 项目中常见中间件调用顺序
常用的 AspNetCore 项目中间件有这些,调用顺序如下图所示: 最后的 Endpoint 就是最终生成响应的中间件。 Configure调用如下: public void Configure(IApplicationBuilder app, IWebHostEnvironment env){if (env.IsDevelopment()){app.UseD…...
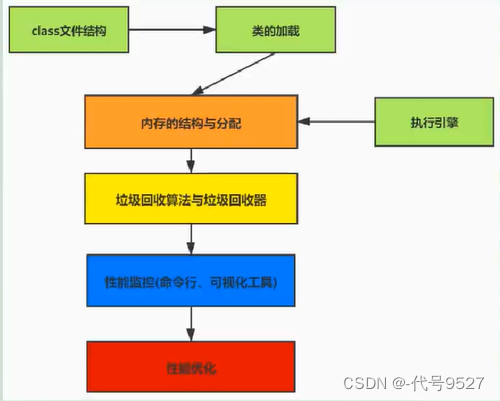
【JVM】一、认识JVM
文章目录 1、虚拟机2、Java虚拟机3、JVM的整体结构4、Java代码的执行流程5、JVM的分类6、JVM的生命周期 1、虚拟机 虚拟机,Virtual Machine,一台虚拟的计算机,用来执行虚拟计算机指令。分为: 系统虚拟机:如VMware&am…...
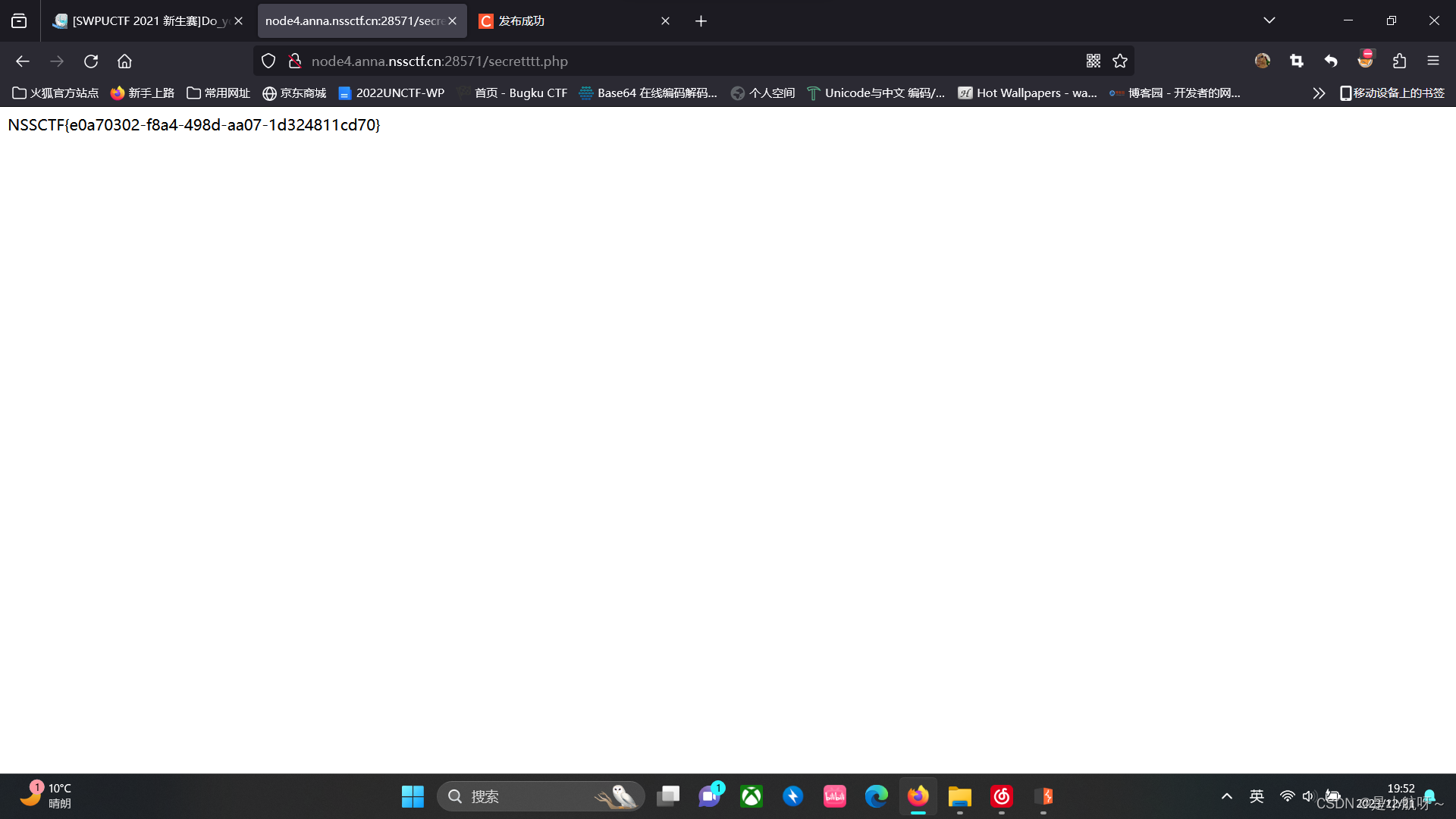
[SWPUCTF 2021 新生赛]Do_you_know_http已
打开环境 它说用WLLM浏览器打开,使用BP抓包,发送到重发器 修改User-Agent 下一步,访问a.php 这儿他说添加一个本地地址,它给了一个183.224.40.160,我用了发现没用,然后重新添加一个地址:X-Forwa…...

hadoop01_完全分布式搭建
hadoop完全分布式搭建 1 完全分布式介绍 Hadoop运行模式包括:本地模式(计算的数据存在Linux本地,在一台服务器上 自己测试)、伪分布式模式(和集群接轨 HDFS yarn,在一台服务器上执行)、完全分…...

【每日一题】得到山形数组的最少删除次数
文章目录 Tag题目来源解题思路方法一:最长递增子序列 写在最后 Tag 【最长递增子序列】【数组】【2023-12-22】 题目来源 1671. 得到山形数组的最少删除次数 解题思路 方法一:最长递增子序列 前后缀分解 根据前后缀思想,以 nums[i] 为山…...

2023年,为什么汽车依然有很多小毛病?
汽车出现小毛病是一个复杂的问题,其原因涉及到汽车本身的设计、制造质量、维护保养以及使用环境等多个方面。只有汽车制造商、车主和社会各界共同努力,才能够减少汽车的小毛病,提高汽车的可靠性和安全性。 比如,汽车的维护和保养…...

yocto系列讲解[实战篇]93 - 添加Qtwebengine和Browser实例
By: fulinux E-mail: fulinux@sina.com Blog: https://blog.csdn.net/fulinus 喜欢的盆友欢迎点赞和订阅! 你的喜欢就是我写作的动力! 目录 概述集成meta-qt5移植过程中的问题问题1:virtual/libgl set to mesa, not mesa-gl问题2:dmabuf-server-buffer tries to use undecl…...
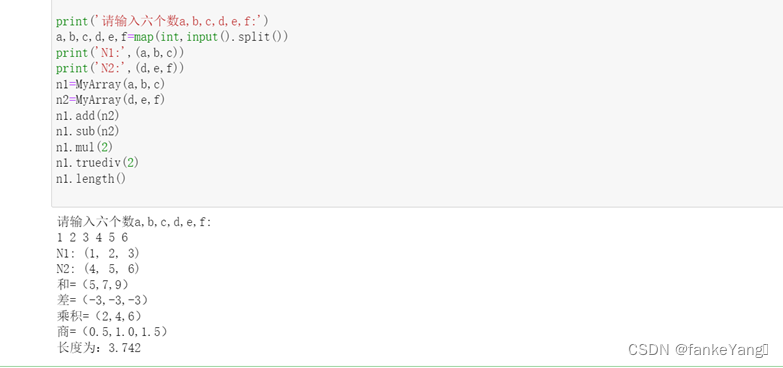
Python实验报告十一、自定义类模拟三维向量及其运算
一、实验目的: 1、了解如何定义一个类。 2、了解如何定义类的私有数据成员和成员方法。 3、了解如何使用自定义类实例化对象。 二、实验内容: 定义一个三维向量类,并定义相应的特殊方法实现两个该类对象之间的加、减运算(要…...
机器学习 | 聚类Clustering 算法
物以类聚人以群分。 什么是聚类呢? 1、核心思想和原理 聚类的目的 同簇高相似度 不同簇高相异度 同类尽量相聚 不同类尽量分离 聚类和分类的区别 分类 classification 监督学习 训练获得分类器 预测未知数据 聚类 clustering 无监督学习,不关心类别标签 …...
IntelliJ IDEA 2023.3 新功能介绍
IntelliJ IDEA 2023.3 在众多领域进行了全面的改进,引入了许多令人期待的功能和增强体验。以下是该版本的一些关键亮点: IntelliJ IDEA mac版下载 macappbox.com/a/intellij-idea-for-mac.html 1. AI Assistant 的全面推出 IntelliJ IDEA 2023.3 中&am…...
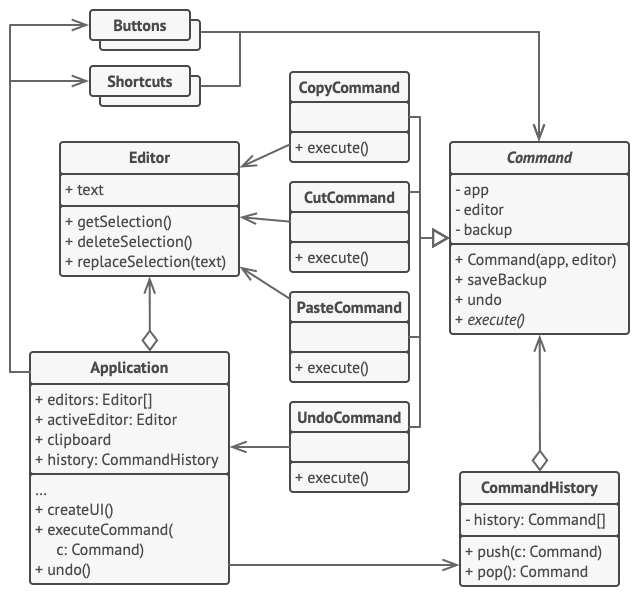
2. 行为模式 - 命令模式
亦称: 动作、事务、Action、Transaction、Command 意图 命令模式是一种行为设计模式, 它可将请求转换为一个包含与请求相关的所有信息的独立对象。 该转换让你能根据不同的请求将方法参数化、 延迟请求执行或将其放入队列中, 且能实现可撤销…...
Java智慧工地源码 SAAS智慧工地源码 智慧工地管理可视化平台源码 带移动APP
一、系统主要功能介绍 系统功能介绍: 【项目人员管理】 1. 项目管理:项目名称、施工单位名称、项目地址、项目地址、总造价、总面积、施工准可证、开工日期、计划竣工日期、项目状态等。 2. 人员信息管理:支持身份证及人脸信息采集&#…...

php学习02-php标记风格
<?php echo "这是xml格式风格" ?><script language"php">echo 脚本风格标记 </script><% echo "这是asp格式风格" %>推荐使用xml格式风格 如果要使用简短风格和ASP风格,需要在php.ini中对其进行配置&#…...
)
LangGraph落地神器!手把手教你用 langgraph-up-react 模板做 ReAct Agent,小白也能5分钟上手(建议收藏)
本文是解析了ReAct框架与LangGraph机制。重点推荐了 langgraph-up-react 模板,该模板专为国内开发者设计,支持通义千问、DeepSeek等模型,内置MCP工具,提供开箱即用的配置和测试。文章手把手指导从环境安装、配置到启动项目的全流程…...

金仓数据库 SQL 防火墙:内核级防护,筑牢 SQL 注入安全防线
在数字化转型的浪潮中,数据已成为企业的核心资产。然而,SQL注入攻击如同潜伏在阴影中的“不速之客”,时刻威胁着数据库的安全。即使开发团队严守预编译、输入过滤等防线,遗留代码、第三方组件的漏洞或人为疏忽仍可能给攻击者可乘之…...

Harness 工程 vs 上下文工程
你是否还在为 AI 智能体 20% 的失败率而挣扎?是时候重新思考你的方法了!发现上下文工程与 Harness 工程之间的关键区别,学习如何构建真正可靠的系统。不要只创建演示 —— 构建生产就绪的智能体!继续阅读,转变你的 AI …...

TypeScript学习笔记 - P1
TypeScript学习笔记——简介1. TypeScript的简介2. TS增加了什么?1. 类型2. 支持ES6新特性3. 添加ES不具备的新特性4. 丰富的配置选项5. 强大的开发工具3.TS开发环境搭建1. 下载Node.js2. 安装Node.js3. 使用npm全局安装typescript4.第一个TS文件1. 创建ts文件1. 编…...

如何理解Martini框架的依赖注入:Go语言Web开发的终极指南
如何理解Martini框架的依赖注入:Go语言Web开发的终极指南 【免费下载链接】martini Classy web framework for Go 项目地址: https://gitcode.com/gh_mirrors/ma/martini Martini是一个优雅的Go语言Web框架,其核心优势在于通过反射机制实现的依赖…...

Vue v-bind 用法详解:单属性绑定 vs 批量绑定,前端必会
【Vue v-bind】前端中后台开发:从核心用法到落地实操,彻底搞懂动态属性绑定的最佳写法,避开面向搜索引擎写代码的高频坑! 📑 文章目录 一、本文你将学到什么(适合收藏) 二、先极简总结…...

卡尔曼滤波SOC算法模型
扩展卡尔曼滤波(EKF)与自适应卡尔曼滤波(AEKF) SOC估算实现文档 目录 1. [理论基础](#理论基础) 2. [电池等效电路模型](#电池等效电路模型) 3. [EKF算法实现](#ekf算法实现) 4. [AEKF算法实现](#aekf算法实现) 5. [系统集成方案](#系统集成方案) 6. [代码实现](#代码实现…...

从计算机组成原理角度看AI模型推理:春联生成的GPU算力消耗
从计算机组成原理角度看AI模型推理:春联生成的GPU算力消耗 春节临近,想用AI模型生成一副独一无二的春联,体验一下科技与传统文化的碰撞。你可能已经试过,输入几个关键词,几秒钟后一副对仗工整、寓意吉祥的春联就跃然屏…...

如何用n8n+Gemini+Pollinations.ai打造小红书爆款笔记全自动生产线
如何用n8nGeminiPollinations.ai打造小红书爆款笔记全自动生产线 在内容为王的时代,小红书运营者每天面临的最大挑战是如何持续产出高质量笔记。传统人工创作模式不仅耗时耗力,更难以保证内容风格的一致性。本文将揭示一套基于n8n工作流引擎的自动化解决…...
范式与LFPBench基准数据集(三))
原创丨弥补法律判决预测的现实鸿沟:基于证据的法律事实预测(LFP)范式与LFPBench基准数据集(三)
作者:张瀚元 本文约3000字,建议阅读5分钟 本文介绍了 LFP 基准构建、模型实证,揭示法律 AI 的系统性偏见。[ 摘要 ] 随着自然语言处理(NLP)技术的飞速发展,法律判决预测(LJP)已成为法…...