Spark Machine Learning进行数据挖掘的简单应用(兴趣预测问题)
数据挖掘的过程
数据挖掘任务主要分为以下六个步骤:
- 1.数据预处理
- 2.特征转换
- 3.特征选择
- 4.训练模型
- 5.模型预测
- 6.评估预测结果
数据准备
这里准备了20条关于不同地区、不同性别、不同身高、体重…的人的兴趣数据集(命名为hobby.csv):
id,hobby,sex,address,age,height,weight
1,football,male,dalian,12,168,55
2,pingpang,female,yangzhou,21,163,60
3,football,male,dalian,,172,70
4,football,female,,13,167,58
5,pingpang,female,shanghai,63,170,64
6,football,male,dalian,30,177,76
7,basketball,male,shanghai,25,181,90
8,football,male,dalian,15,172,71
9,basketball,male,shanghai,25,179,80
10,pingpang,male,shanghai,55,175,72
11,football,male,dalian,13,169,55
12,pingpang,female,yangzhou,22,164,61
13,football,male,dalian,23,170,71
14,football,female,,12,164,55
15,pingpang,female,shanghai,64,169,63
16,football,male,dalian,30,177,76
17,basketball,male,shanghai,22,180,80
18,football,male,dalian,16,173,72
19,basketball,male,shanghai,23,176,73
20,pingpang,male,shanghai,56,171,71
- 任务分析
通过sex,address,age,height,weight这五个特征预测一个人的兴趣爱好
数据预处理
想要连接数据,必须先创建一个spark对象
定义Spark对象
使用SparkSession中的builder()构建 后续设定appName 和master ,最后使用getOrCreate()完成构建
// 定义spark对象val spark = SparkSession.builder().appName("兴趣预测").master("local[*]").getOrCreate()
连接数据
使用spark.read连接数据,需要指定数据的格式为“CSV”,将首行设置为header,最后指定文件路径:
val df=spark.read.format("CSV").option("header",true).load("C:/Users/35369/Desktop/hobby.csv")
使用df.show() df.printSchema()查看数据:
df.show()df.printSchema()spark.stop() // 关闭spark
输出信息:
+---+----------+------+--------+----+------+------+
| id| hobby| sex| address| age|height|weight|
+---+----------+------+--------+----+------+------+
| 1| football| male| dalian| 12| 168| 55|
| 2| pingpang|female|yangzhou| 21| 163| 60|
| 3| football| male| dalian|null| 172| 70|
| 4| football|female| null| 13| 167| 58|
| 5| pingpang|female|shanghai| 63| 170| 64|
| 6| football| male| dalian| 30| 177| 76|
| 7|basketball| male|shanghai| 25| 181| 90|
| 8| football| male| dalian| 15| 172| 71|
| 9|basketball| male|shanghai| 25| 179| 80|
| 10| pingpang| male|shanghai| 55| 175| 72|
| 11| football| male| dalian| 13| 169| 55|
| 12| pingpang|female|yangzhou| 22| 164| 61|
| 13| football| male| dalian| 23| 170| 71|
| 14| football|female| null| 12| 164| 55|
| 15| pingpang|female|shanghai| 64| 169| 63|
| 16| football| male| dalian| 30| 177| 76|
| 17|basketball| male|shanghai| 22| 180| 80|
| 18| football| male| dalian| 16| 173| 72|
| 19|basketball| male|shanghai| 23| 176| 73|
| 20| pingpang| male|shanghai| 56| 171| 71|
+---+----------+------+--------+----+------+------+root|-- id: string (nullable = true)|-- hobby: string (nullable = true)|-- sex: string (nullable = true)|-- address: string (nullable = true)|-- age: string (nullable = true)|-- height: string (nullable = true)|-- weight: string (nullable = true)
补全年龄空缺的行
补全数值型数据可以分三步:
(1)取出去除空行数据之后的这一列数据
(2)计算(1)中那一列数据的平均值
(3)将平均值填充至原先的表中
- (1)取出空行之后的数据
val ageNaDF = df.select("age").na.drop()ageNaDF.show()
+---+
|age|
+---+
| 12|
| 21|
| 13|
| 63|
| 30|
| 25|
| 15|
| 25|
| 55|
| 13|
| 22|
| 23|
| 12|
| 64|
| 30|
| 22|
| 16|
| 23|
| 56|
+---+
- (2)计算(1)中那一列数据的平均值
查看ageNaDF的基本特征
ageNaDF.describe("age").show()
输出:
+-------+-----------------+
|summary| age|
+-------+-----------------+
| count| 19|
| mean|28.42105263157895|
| stddev|17.48432882286206|
| min| 12|
| max| 64|
+-------+-----------------+
可以看到其中的均值mean为28.42105263157895,我们需要取出这个mean
val mean = ageNaDF.describe("age").select("age").collect()(1)(0).toStringprint(mean) //28.42105263157895
- (3)将平均值填充至原先的表中
使用df.na.fill()方法可以填充空值,需要指定列为“age”,所以第二个参数为List(“age”)
val ageFilledDF = df.na.fill(mean,List("age"))ageFilledDF.show()
输出:
+---+----------+------+--------+-----------------+------+------+
| id| hobby| sex| address| age|height|weight|
+---+----------+------+--------+-----------------+------+------+
| 1| football| male| dalian| 12| 168| 55|
| 2| pingpang|female|yangzhou| 21| 163| 60|
| 3| football| male| dalian|28.42105263157895| 172| 70|
| 4| football|female| null| 13| 167| 58|
| 5| pingpang|female|shanghai| 63| 170| 64|
| 6| football| male| dalian| 30| 177| 76|
| 7|basketball| male|shanghai| 25| 181| 90|
| 8| football| male| dalian| 15| 172| 71|
| 9|basketball| male|shanghai| 25| 179| 80|
| 10| pingpang| male|shanghai| 55| 175| 72|
| 11| football| male| dalian| 13| 169| 55|
| 12| pingpang|female|yangzhou| 22| 164| 61|
| 13| football| male| dalian| 23| 170| 71|
| 14| football|female| null| 12| 164| 55|
| 15| pingpang|female|shanghai| 64| 169| 63|
| 16| football| male| dalian| 30| 177| 76|
| 17|basketball| male|shanghai| 22| 180| 80|
| 18| football| male| dalian| 16| 173| 72|
| 19|basketball| male|shanghai| 23| 176| 73|
| 20| pingpang| male|shanghai| 56| 171| 71|
+---+----------+------+--------+-----------------+------+------+
可以发现年龄中的空值被填充了平均值
删除城市有空值所在的行
由于城市的列没有合理的数据可以填充,所以如果城市出现空数据则选择把改行删除
使用.na.drop()方法
val addressDf = ageFilledDF.na.drop()addressDf.show()
输出:
+---+----------+------+--------+-----------------+------+------+
| id| hobby| sex| address| age|height|weight|
+---+----------+------+--------+-----------------+------+------+
| 1| football| male| dalian| 12| 168| 55|
| 2| pingpang|female|yangzhou| 21| 163| 60|
| 3| football| male| dalian|28.42105263157895| 172| 70|
| 5| pingpang|female|shanghai| 63| 170| 64|
| 6| football| male| dalian| 30| 177| 76|
| 7|basketball| male|shanghai| 25| 181| 90|
| 8| football| male| dalian| 15| 172| 71|
| 9|basketball| male|shanghai| 25| 179| 80|
| 10| pingpang| male|shanghai| 55| 175| 72|
| 11| football| male| dalian| 13| 169| 55|
| 12| pingpang|female|yangzhou| 22| 164| 61|
| 13| football| male| dalian| 23| 170| 71|
| 15| pingpang|female|shanghai| 64| 169| 63|
| 16| football| male| dalian| 30| 177| 76|
| 17|basketball| male|shanghai| 22| 180| 80|
| 18| football| male| dalian| 16| 173| 72|
| 19|basketball| male|shanghai| 23| 176| 73|
| 20| pingpang| male|shanghai| 56| 171| 71|
+---+----------+------+--------+-----------------+------+------+
4和14行被删除
将每列字段的格式转换成合理的格式
//对df的schema进行调整val formatDF = addressDf.select(col("id").cast("int"),col("hobby").cast("String"),col("sex").cast("String"),col("address").cast("String"),col("age").cast("Double"),col("height").cast("Double"),col("weight").cast("Double"))formatDF.printSchema()
输出:
root|-- id: integer (nullable = true)|-- hobby: string (nullable = true)|-- sex: string (nullable = true)|-- address: string (nullable = true)|-- age: double (nullable = true)|-- height: double (nullable = true)|-- weight: double (nullable = true)
到此,数据预处理部分完成。
特征转换
为了便于模型训练,在数据的特征转换中,我们需要对age、weight、height、address、sex这些特征做分桶处理。
对年龄做分桶处理
- 18以下
- 18-35
- 35-60
- 60以上
使用Bucketizer类用来分桶处理,需要设置输入的列名和输出的列名,把定义的分桶区间作为这个类分桶的依据,最后给定需要做分桶处理的DataFrame
//2.1 对年龄进行分桶处理//定义一个数组作为分桶的区间val ageSplits = Array(Double.NegativeInfinity,18,35,60,Double.PositiveInfinity)val bucketizerDF = new Bucketizer().setInputCol("age").setOutputCol("ageFeature").setSplits(ageSplits).transform(formatDF)bucketizerDF.show()
查看分桶结果:
+---+----------+------+--------+-----------------+------+------+----------+
| id| hobby| sex| address| age|height|weight|ageFeature|
+---+----------+------+--------+-----------------+------+------+----------+
| 1| football| male| dalian| 12.0| 168.0| 55.0| 0.0|
| 2| pingpang|female|yangzhou| 21.0| 163.0| 60.0| 1.0|
| 3| football| male| dalian|28.42105263157895| 172.0| 70.0| 1.0|
| 5| pingpang|female|shanghai| 63.0| 170.0| 64.0| 3.0|
| 6| football| male| dalian| 30.0| 177.0| 76.0| 1.0|
| 7|basketball| male|shanghai| 25.0| 181.0| 90.0| 1.0|
| 8| football| male| dalian| 15.0| 172.0| 71.0| 0.0|
| 9|basketball| male|shanghai| 25.0| 179.0| 80.0| 1.0|
| 10| pingpang| male|shanghai| 55.0| 175.0| 72.0| 2.0|
| 11| football| male| dalian| 13.0| 169.0| 55.0| 0.0|
| 12| pingpang|female|yangzhou| 22.0| 164.0| 61.0| 1.0|
| 13| football| male| dalian| 23.0| 170.0| 71.0| 1.0|
| 15| pingpang|female|shanghai| 64.0| 169.0| 63.0| 3.0|
| 16| football| male| dalian| 30.0| 177.0| 76.0| 1.0|
| 17|basketball| male|shanghai| 22.0| 180.0| 80.0| 1.0|
| 18| football| male| dalian| 16.0| 173.0| 72.0| 0.0|
| 19|basketball| male|shanghai| 23.0| 176.0| 73.0| 1.0|
| 20| pingpang| male|shanghai| 56.0| 171.0| 71.0| 2.0|
+---+----------+------+--------+-----------------+------+------+----------+
对身高做二值化处理
基准为170 使用Binarizer类
//2.2 对身高做二值化处理val heightDF = new Binarizer().setInputCol("height").setOutputCol("heightFeature").setThreshold(170) // 阈值.transform(bucketizerDF)heightDF.show()
查看处理后结果:
+---+----------+------+--------+-----------------+------+------+----------+-------------+
| id| hobby| sex| address| age|height|weight|ageFeature|heightFeature|
+---+----------+------+--------+-----------------+------+------+----------+-------------+
| 1| football| male| dalian| 12.0| 168.0| 55.0| 0.0| 0.0|
| 2| pingpang|female|yangzhou| 21.0| 163.0| 60.0| 1.0| 0.0|
| 3| football| male| dalian|28.42105263157895| 172.0| 70.0| 1.0| 1.0|
| 5| pingpang|female|shanghai| 63.0| 170.0| 64.0| 3.0| 0.0|
| 6| football| male| dalian| 30.0| 177.0| 76.0| 1.0| 1.0|
| 7|basketball| male|shanghai| 25.0| 181.0| 90.0| 1.0| 1.0|
| 8| football| male| dalian| 15.0| 172.0| 71.0| 0.0| 1.0|
| 9|basketball| male|shanghai| 25.0| 179.0| 80.0| 1.0| 1.0|
| 10| pingpang| male|shanghai| 55.0| 175.0| 72.0| 2.0| 1.0|
| 11| football| male| dalian| 13.0| 169.0| 55.0| 0.0| 0.0|
| 12| pingpang|female|yangzhou| 22.0| 164.0| 61.0| 1.0| 0.0|
| 13| football| male| dalian| 23.0| 170.0| 71.0| 1.0| 0.0|
| 15| pingpang|female|shanghai| 64.0| 169.0| 63.0| 3.0| 0.0|
| 16| football| male| dalian| 30.0| 177.0| 76.0| 1.0| 1.0|
| 17|basketball| male|shanghai| 22.0| 180.0| 80.0| 1.0| 1.0|
| 18| football| male| dalian| 16.0| 173.0| 72.0| 0.0| 1.0|
| 19|basketball| male|shanghai| 23.0| 176.0| 73.0| 1.0| 1.0|
| 20| pingpang| male|shanghai| 56.0| 171.0| 71.0| 2.0| 1.0|
+---+----------+------+--------+-----------------+------+------+----------+-------------+
对体重做二值化处理
阈值设为 65
//2.3 对体重做二值化处理val weightDF = new Binarizer().setInputCol("weight").setOutputCol("weightFeature").setThreshold(65).transform(heightDF)weightDF.show()
性别、城市、爱好字段的处理
这三个字段都是字符串,而字符串的形式在机器学习中是不适合做分析处理的,所以也需要对他们做特征转换(编码处理)。
//2.4 对性别进行labelEncode转换val sexIndex = new StringIndexer().setInputCol("sex").setOutputCol("sexIndex").fit(weightDF).transform(weightDF)//2.5对家庭地址进行labelEncode转换val addIndex = new StringIndexer().setInputCol("address").setOutputCol("addIndex").fit(sexIndex).transform(sexIndex)//2.6对地址进行one-hot编码val addOneHot = new OneHotEncoder().setInputCol("addIndex").setOutputCol("addOneHot").fit(addIndex).transform(addIndex)//2.7对兴趣字段进行LabelEncode处理val hobbyIndexDF = new StringIndexer().setInputCol("hobby").setOutputCol("hobbyIndex").fit(addOneHot).transform(addOneHot)hobbyIndexDF.show()
这里额外对地址做了一个one-hot处理。
将hobbyIndex列名称改成label,因为hobby在模型训练阶段用作标签。
//2.8修改列名val resultDF = hobbyIndexDF.withColumnRenamed("hobbyIndex","label")resultDF.show()
最终特征转换后的结果:
+---+----------+------+--------+-----------------+------+------+----------+-------------+-------------+--------+--------+-------------+-----+
| id| hobby| sex| address| age|height|weight|ageFeature|heightFeature|weightFeature|sexIndex|addIndex| addOneHot|label|
+---+----------+------+--------+-----------------+------+------+----------+-------------+-------------+--------+--------+-------------+-----+
| 1| football| male| dalian| 12.0| 168.0| 55.0| 0.0| 0.0| 0.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 2| pingpang|female|yangzhou| 21.0| 163.0| 60.0| 1.0| 0.0| 0.0| 1.0| 2.0| (2,[],[])| 1.0|
| 3| football| male| dalian|28.42105263157895| 172.0| 70.0| 1.0| 1.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 5| pingpang|female|shanghai| 63.0| 170.0| 64.0| 3.0| 0.0| 0.0| 1.0| 1.0|(2,[1],[1.0])| 1.0|
| 6| football| male| dalian| 30.0| 177.0| 76.0| 1.0| 1.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 7|basketball| male|shanghai| 25.0| 181.0| 90.0| 1.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 2.0|
| 8| football| male| dalian| 15.0| 172.0| 71.0| 0.0| 1.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 9|basketball| male|shanghai| 25.0| 179.0| 80.0| 1.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 2.0|
| 10| pingpang| male|shanghai| 55.0| 175.0| 72.0| 2.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 1.0|
| 11| football| male| dalian| 13.0| 169.0| 55.0| 0.0| 0.0| 0.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 12| pingpang|female|yangzhou| 22.0| 164.0| 61.0| 1.0| 0.0| 0.0| 1.0| 2.0| (2,[],[])| 1.0|
| 13| football| male| dalian| 23.0| 170.0| 71.0| 1.0| 0.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 15| pingpang|female|shanghai| 64.0| 169.0| 63.0| 3.0| 0.0| 0.0| 1.0| 1.0|(2,[1],[1.0])| 1.0|
| 16| football| male| dalian| 30.0| 177.0| 76.0| 1.0| 1.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 17|basketball| male|shanghai| 22.0| 180.0| 80.0| 1.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 2.0|
| 18| football| male| dalian| 16.0| 173.0| 72.0| 0.0| 1.0| 1.0| 0.0| 0.0|(2,[0],[1.0])| 0.0|
| 19|basketball| male|shanghai| 23.0| 176.0| 73.0| 1.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 2.0|
| 20| pingpang| male|shanghai| 56.0| 171.0| 71.0| 2.0| 1.0| 1.0| 0.0| 1.0|(2,[1],[1.0])| 1.0|
+---+----------+------+--------+-----------------+------+------+----------+-------------+-------------+--------+--------+-------------+-----+
特征选择
特征转换后的结果是一个多列数据,但不是所有的列都可以拿来用作机器学习的模型训练,特征选择就是要选择可以用来机器学习的数据。
选择特征
使用VectorAssembler()可以将需要的列取出
//3.1选择特征val vectorAssembler = new VectorAssembler().setInputCols(Array("ageFeature","heightFeature","weightFeature","sexIndex","addIndex","label")).setOutputCol("features")
特征进行规范化处理
val scaler = new StandardScaler().setInputCol("features").setOutputCol("featureScaler").setWithStd(true) // 是否使用标准差.setWithMean(false) // 是否使用中位数
特征筛选
// 特征筛选,使用卡方检验方法来做筛选val selector = new ChiSqSelector().setLabelCol("label").setOutputCol("featuresSelector")
构建逻辑回归模型和pipline
// 逻辑回归模型val lr = new LogisticRegression().setLabelCol("label").setFeaturesCol("featuresSelector")// 构造pipelineval pipeline = new Pipeline().setStages(Array(vectorAssembler,scaler,selector,lr))
设置网络搜索最佳参数
// 设置网络搜索最佳参数val params = new ParamGridBuilder().addGrid(lr.regParam,Array(0.1,0.01)) //正则化参数.addGrid(selector.numTopFeatures,Array(5,10,5)) //设置卡方检验最佳特征数.build()
设置交叉检验
// 设置交叉检验val cv = new CrossValidator().setEstimator(pipeline).setEvaluator(new BinaryClassificationEvaluator()).setEstimatorParamMaps(params).setNumFolds(5)
模型训练与预测
模型训练前需要拆分一下训练集和测试集
val Array(trainDF,testDF) = resultDF.randomSplit(Array(0.8,0.2))
使用randomSplit方法可以完成拆分
- 开始训练和预测
val model = cv.fit(trainDF)// 模型预测val preddiction = model.bestModel.transform(testDF)preddiction.show()
报错求解决
运行cv.fit(trainDF)的地方报错了 这个信息网上也没找到
Exception in thread "main" java.lang.NoClassDefFoundError: org/apache/spark/sql/catalyst/trees/BinaryLikeat java.lang.ClassLoader.defineClass1(Native Method)at java.lang.ClassLoader.defineClass(ClassLoader.java:756)at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142)at java.net.URLClassLoader.defineClass(URLClassLoader.java:473)at java.net.URLClassLoader.access$100(URLClassLoader.java:74)at java.net.URLClassLoader$1.run(URLClassLoader.java:369)at java.net.URLClassLoader$1.run(URLClassLoader.java:363)at java.security.AccessController.doPrivileged(Native Method)at java.net.URLClassLoader.findClass(URLClassLoader.java:362)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)at org.apache.spark.ml.stat.SummaryBuilderImpl.summary(Summarizer.scala:251)at org.apache.spark.ml.stat.SummaryBuilder.summary(Summarizer.scala:54)at org.apache.spark.ml.feature.StandardScaler.fit(StandardScaler.scala:112)at org.apache.spark.ml.feature.StandardScaler.fit(StandardScaler.scala:84)at org.apache.spark.ml.Pipeline.$anonfun$fit$5(Pipeline.scala:151)at org.apache.spark.ml.MLEvents.withFitEvent(events.scala:130)at org.apache.spark.ml.MLEvents.withFitEvent$(events.scala:123)at org.apache.spark.ml.util.Instrumentation.withFitEvent(Instrumentation.scala:42)at org.apache.spark.ml.Pipeline.$anonfun$fit$4(Pipeline.scala:151)at scala.collection.Iterator.foreach(Iterator.scala:943)at scala.collection.Iterator.foreach$(Iterator.scala:943)at scala.collection.AbstractIterator.foreach(Iterator.scala:1431)at org.apache.spark.ml.Pipeline.$anonfun$fit$2(Pipeline.scala:147)at org.apache.spark.ml.MLEvents.withFitEvent(events.scala:130)at org.apache.spark.ml.MLEvents.withFitEvent$(events.scala:123)at org.apache.spark.ml.util.Instrumentation.withFitEvent(Instrumentation.scala:42)at org.apache.spark.ml.Pipeline.$anonfun$fit$1(Pipeline.scala:133)at org.apache.spark.ml.util.Instrumentation$.$anonfun$instrumented$1(Instrumentation.scala:191)at scala.util.Try$.apply(Try.scala:213)at org.apache.spark.ml.util.Instrumentation$.instrumented(Instrumentation.scala:191)at org.apache.spark.ml.Pipeline.fit(Pipeline.scala:133)at org.apache.spark.ml.Pipeline.fit(Pipeline.scala:93)at org.apache.spark.ml.Estimator.fit(Estimator.scala:59)at org.apache.spark.ml.tuning.CrossValidator.$anonfun$fit$7(CrossValidator.scala:174)at scala.runtime.java8.JFunction0$mcD$sp.apply(JFunction0$mcD$sp.java:23)at scala.concurrent.Future$.$anonfun$apply$1(Future.scala:659)at scala.util.Success.$anonfun$map$1(Try.scala:255)at scala.util.Success.map(Try.scala:213)at scala.concurrent.Future.$anonfun$map$1(Future.scala:292)at scala.concurrent.impl.Promise.liftedTree1$1(Promise.scala:33)at scala.concurrent.impl.Promise.$anonfun$transform$1(Promise.scala:33)at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)at org.sparkproject.guava.util.concurrent.MoreExecutors$SameThreadExecutorService.execute(MoreExecutors.java:293)at scala.concurrent.impl.ExecutionContextImpl$$anon$4.execute(ExecutionContextImpl.scala:138)at scala.concurrent.impl.CallbackRunnable.executeWithValue(Promise.scala:72)at scala.concurrent.impl.Promise$KeptPromise$Kept.onComplete(Promise.scala:372)at scala.concurrent.impl.Promise$KeptPromise$Kept.onComplete$(Promise.scala:371)at scala.concurrent.impl.Promise$KeptPromise$Successful.onComplete(Promise.scala:379)at scala.concurrent.impl.Promise.transform(Promise.scala:33)at scala.concurrent.impl.Promise.transform$(Promise.scala:31)at scala.concurrent.impl.Promise$KeptPromise$Successful.transform(Promise.scala:379)at scala.concurrent.Future.map(Future.scala:292)at scala.concurrent.Future.map$(Future.scala:292)at scala.concurrent.impl.Promise$KeptPromise$Successful.map(Promise.scala:379)at scala.concurrent.Future$.apply(Future.scala:659)at org.apache.spark.ml.tuning.CrossValidator.$anonfun$fit$6(CrossValidator.scala:182)at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)at scala.collection.TraversableLike.map(TraversableLike.scala:286)at scala.collection.TraversableLike.map$(TraversableLike.scala:279)at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:198)at org.apache.spark.ml.tuning.CrossValidator.$anonfun$fit$4(CrossValidator.scala:172)at scala.collection.TraversableLike.$anonfun$map$1(TraversableLike.scala:286)at scala.collection.IndexedSeqOptimized.foreach(IndexedSeqOptimized.scala:36)at scala.collection.IndexedSeqOptimized.foreach$(IndexedSeqOptimized.scala:33)at scala.collection.mutable.ArrayOps$ofRef.foreach(ArrayOps.scala:198)at scala.collection.TraversableLike.map(TraversableLike.scala:286)at scala.collection.TraversableLike.map$(TraversableLike.scala:279)at scala.collection.mutable.ArrayOps$ofRef.map(ArrayOps.scala:198)at org.apache.spark.ml.tuning.CrossValidator.$anonfun$fit$1(CrossValidator.scala:166)at org.apache.spark.ml.util.Instrumentation$.$anonfun$instrumented$1(Instrumentation.scala:191)at scala.util.Try$.apply(Try.scala:213)at org.apache.spark.ml.util.Instrumentation$.instrumented(Instrumentation.scala:191)at org.apache.spark.ml.tuning.CrossValidator.fit(CrossValidator.scala:137)at org.example.SparkML.SparkMl01$.main(SparkMl01.scala:147)at org.example.SparkML.SparkMl01.main(SparkMl01.scala)
Caused by: java.lang.ClassNotFoundException: org.apache.spark.sql.catalyst.trees.BinaryLikeat java.net.URLClassLoader.findClass(URLClassLoader.java:387)at java.lang.ClassLoader.loadClass(ClassLoader.java:418)at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:355)at java.lang.ClassLoader.loadClass(ClassLoader.java:351)
全部源码以及pom文件
package org.example.SparkMLimport org.apache.spark.ml.Pipeline
import org.apache.spark.ml.classification.LogisticRegression
import org.apache.spark.ml.evaluation.BinaryClassificationEvaluator
import org.apache.spark.ml.feature.{Binarizer, Bucketizer, ChiSqSelector, OneHotEncoder, StandardScaler, StringIndexer, VectorAssembler}
import org.apache.spark.ml.tuning.{CrossValidator, ParamGridBuilder}
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.col/*** 数据挖掘的过程* 1.数据预处理* 2.特征转换(编码。。。)* 3.特征选择* 4.训练模型* 5.模型预测* 6.评估预测结果*/
object SparkMl01 {def main(args: Array[String]): Unit = {// 定义spark对象val spark = SparkSession.builder().appName("兴趣预测").master("local").getOrCreate()import spark.implicits._val df=spark.read.format("CSV").option("header",true).load("C:/Users/35369/Desktop/hobby.csv")//1.数据预处理,补全空缺的年龄val ageNaDF = df.select("age").na.drop()val mean = ageNaDF.describe("age").select("age").collect()(1)(0).toStringval ageFilledDF = df.na.fill(mean,List("age"))//address为空的行直接删除val addressDf = ageFilledDF.na.drop()//对df的schema进行调整val formatDF = addressDf.select(col("id").cast("int"),col("hobby").cast("String"),col("sex").cast("String"),col("address").cast("String"),col("age").cast("Double"),col("height").cast("Double"),col("weight").cast("Double"))//2.特征转换//2.1 对年龄进行分桶处理//定义一个数组作为分桶的区间val ageSplits = Array(Double.NegativeInfinity,18,35,60,Double.PositiveInfinity)val bucketizerDF = new Bucketizer().setInputCol("age").setOutputCol("ageFeature").setSplits(ageSplits).transform(formatDF)//2.2 对身高做二值化处理val heightDF = new Binarizer().setInputCol("height").setOutputCol("heightFeature").setThreshold(170) // 阈值.transform(bucketizerDF)//2.3 对体重做二值化处理val weightDF = new Binarizer().setInputCol("weight").setOutputCol("weightFeature").setThreshold(65).transform(heightDF)//2.4 对性别进行labelEncode转换val sexIndex = new StringIndexer().setInputCol("sex").setOutputCol("sexIndex").fit(weightDF).transform(weightDF)//2.5对家庭地址进行labelEncode转换val addIndex = new StringIndexer().setInputCol("address").setOutputCol("addIndex").fit(sexIndex).transform(sexIndex)//2.6对地址进行one-hot编码val addOneHot = new OneHotEncoder().setInputCol("addIndex").setOutputCol("addOneHot").fit(addIndex).transform(addIndex)//2.7对兴趣字段进行LabelEncode处理val hobbyIndexDF = new StringIndexer().setInputCol("hobby").setOutputCol("hobbyIndex").fit(addOneHot).transform(addOneHot)//2.8修改列名val resultDF = hobbyIndexDF.withColumnRenamed("hobbyIndex","label")//3 特征选择//3.1选择特征val vectorAssembler = new VectorAssembler().setInputCols(Array("ageFeature","heightFeature","weightFeature","sexIndex","addOneHot")).setOutputCol("features")//3.2特征进行规范化处理val scaler = new StandardScaler().setInputCol("features").setOutputCol("featureScaler").setWithStd(true) // 是否使用标准差.setWithMean(false) // 是否使用中位数// 特征筛选,使用卡方检验方法来做筛选val selector = new ChiSqSelector().setFeaturesCol("featureScaler").setLabelCol("label").setOutputCol("featuresSelector")// 逻辑回归模型val lr = new LogisticRegression().setLabelCol("label").setFeaturesCol("featuresSelector")// 构造pipelineval pipeline = new Pipeline().setStages(Array(vectorAssembler,scaler,selector,lr))// 设置网络搜索最佳参数val params = new ParamGridBuilder().addGrid(lr.regParam,Array(0.1,0.01)) //正则化参数.addGrid(selector.numTopFeatures,Array(5,10,5)) //设置卡方检验最佳特征数.build()// 设置交叉检验val cv = new CrossValidator().setEstimator(pipeline).setEvaluator(new BinaryClassificationEvaluator()).setEstimatorParamMaps(params).setNumFolds(5)// 模型训练val Array(trainDF,testDF) = resultDF.randomSplit(Array(0.8,0.2))trainDF.show()testDF.show()val model = cv.fit(trainDF)//生成模型
// val model = pipeline.fit(trainDF)
// val prediction = model.transform(testDF)
// prediction.show()// 模型预测
// val preddiction = model.bestModel.transform(testDF)
// preddiction.show()spark.stop()}
}<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.example</groupId><artifactId>untitled</artifactId><version>1.0-SNAPSHOT</version><properties><maven.compiler.source>8</maven.compiler.source><maven.compiler.target>8</maven.compiler.target><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding></properties><dependencies><dependency><groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>2.12.18</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-core_2.12</artifactId><version>3.0.0-preview2</version></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-hive_2.12</artifactId><version>3.1.2</version>
<!-- <scope>provided</scope>--></dependency><dependency><groupId>org.apache.spark</groupId><artifactId>spark-sql_2.12</artifactId><version>3.0.0-preview2</version>
<!-- <scope>compile</scope>--></dependency><!-- <dependency>-->
<!-- <groupId>mysql</groupId>-->
<!-- <artifactId>mysql-connector-java</artifactId>-->
<!-- <version>8.0.16</version>-->
<!-- </dependency>--><dependency><groupId>org.apache.spark</groupId><artifactId>spark-mllib_2.12</artifactId><version>3.5.0</version>
<!-- <scope>compile</scope>--></dependency></dependencies><build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-shade-plugin</artifactId><version>2.4.1</version><executions><execution><phase>package</phase><goals><goal>shade</goal></goals><configuration><transformers><transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"><mainClass>com.xxg.Main</mainClass></transformer></transformers></configuration></execution></executions></plugin></plugins></build></project>
相关文章:
)
Spark Machine Learning进行数据挖掘的简单应用(兴趣预测问题)
数据挖掘的过程 数据挖掘任务主要分为以下六个步骤: 1.数据预处理2.特征转换3.特征选择4.训练模型5.模型预测6.评估预测结果 数据准备 这里准备了20条关于不同地区、不同性别、不同身高、体重…的人的兴趣数据集(命名为hobby.csv): id,h…...

DRF从入门到精通二(Request源码分析、DRF之序列化、反序列化、反序列化校验、序列化器常用字段及参数、source、定制字段、保存数据)
文章目录 一、Request对象源码分析区分原生request和新生request新的request还能像原来的reqeust一样使用吗源码片段分析总结: 二、DRF之序列化组件序列化介绍序列化步骤序列化组件的基本使用反序列化基本使用反序列化的新增反序列化的新增删除单条 反序列化的校验序…...

Flink系列之:Upsert Kafka SQL 连接器
Flink系列之:Upsert Kafka SQL 连接器 一、Upsert Kafka SQL 连接器二、依赖三、完整示例四、可用元数据五、键和值格式六、主键约束七、一致性保证八、为每个分区生成相应的watermark九、数据类型映射 一、Upsert Kafka SQL 连接器 Scan Source: Unbounded 、Sink…...
)
前端与后端的异步编排(promise、async、await 、CompletableFuture)
前端与后端的异步编排 文章目录 前端与后端的异步编排1、为什么需要异步编排2、前端中的异步2.1 、Promise的使用2.1.1、Promise的基础概念2.1.2、Promise中的两个回调函数2.1.3、工具方法1、Promise.all()2、Promise.race()3、Promise.resolve() 2.2 、async 与 aw…...
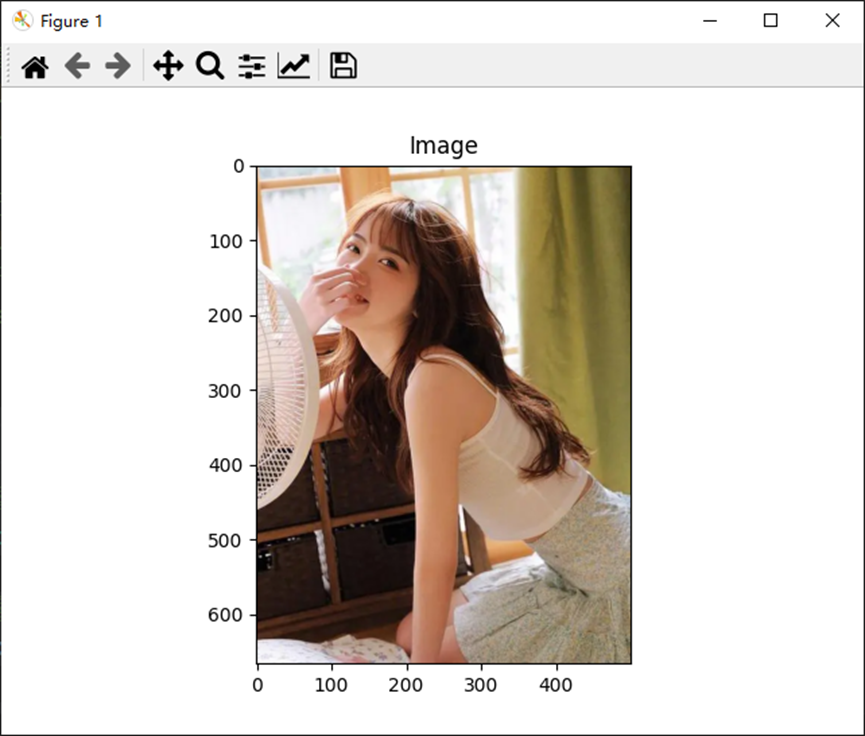
python打开opencv图像与QImage图像及其转化
目录 1、Qimage图像 2、opencv图像 3、python打开QImage图像通过Qlabel控件显示 4、python打开QImage图像通过opencv显示 5、python打开opencv图像并显示 6、python打开opencv图像通过Qlabel控件显示 1、Qimage图像 QImage是Qt库中用于存储和处理图像的类。它可以存储多种…...

linux 其他版本RCU
1、不可抢占RCU 如果我们的需求是“不管内核是否编译了可抢占RCU,都要使用不可抢占RCU”,那么应该使用不可抢占RCU的专用编程接口。 读者使用函数rcu_read_lock_sched()标记进入读端临界区,使用函数rcu_read_unlock_ sched()标记退出读端临界…...

【单调栈】LeetCode:2818操作使得分最大
作者推荐 map|动态规划|单调栈|LeetCode975:奇偶跳 涉及知识点 单调栈 题目 给你一个长度为 n 的正整数数组 nums 和一个整数 k 。 一开始,你的分数为 1 。你可以进行以下操作至多 k 次,目标是使你的分数最大: 选择一个之前没有选过的 非…...
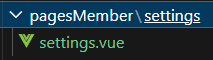
uniapp 添加分包页面,配置分包预下载
为什么要分包 ? 分包即将小程序代码分成多个部分打包,可以减少小程序的加载时间,提升用户体验 添加分包页面 比较便捷的方法是使用vscode插件 uni-create-view 新建分包文件夹 以在我的页面,添加分包的设置页面为例,新建文件夹 s…...
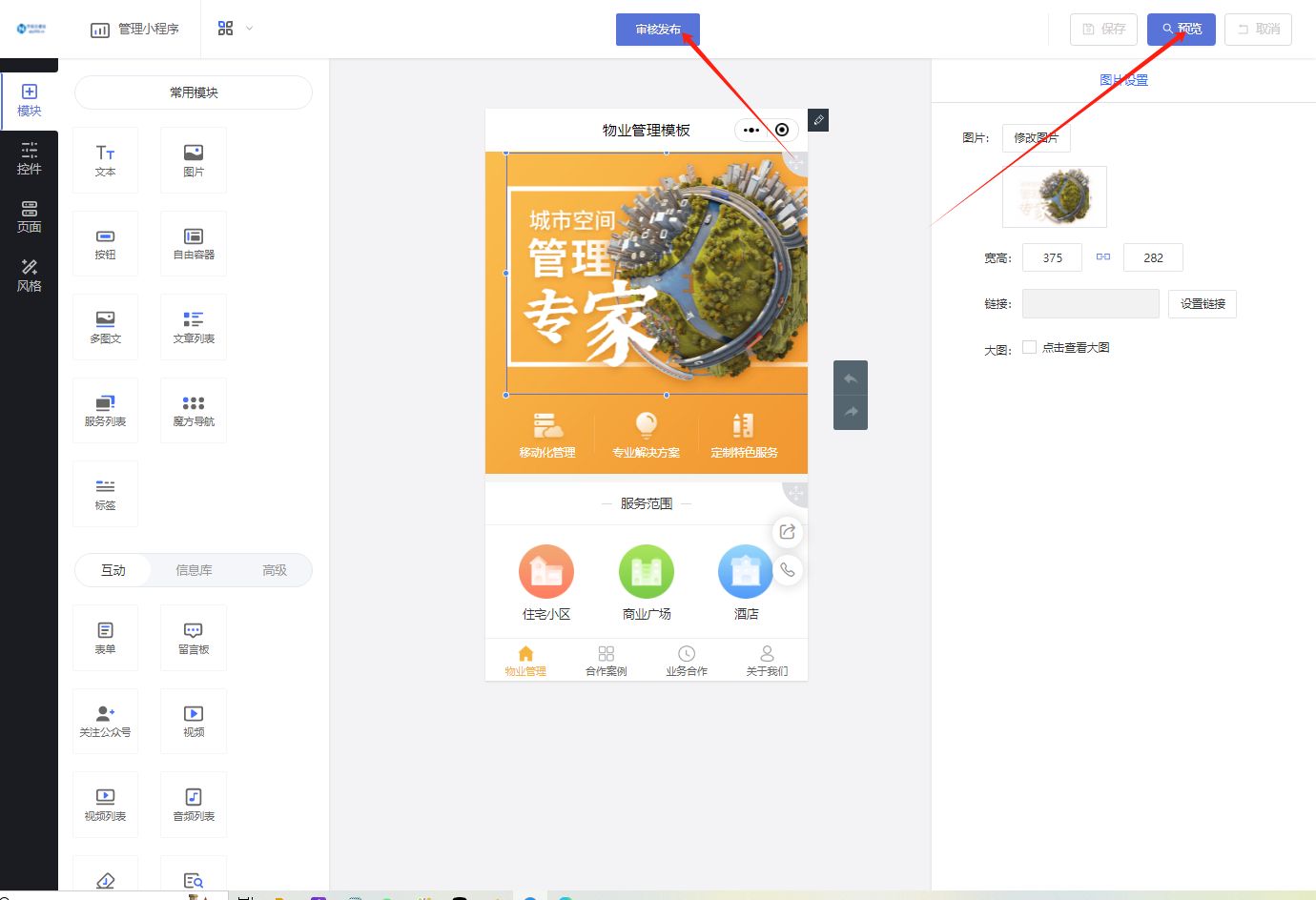
成功案例分享:物业管理小程序如何助力打造智慧社区
随着科技的进步和互联网的普及,数字化转型已经渗透到各个行业,包括物业管理。借助小程序这一轻量级应用,物业管理可以实现线上线下服务的无缝对接,提升服务质量,优化用户体验。本文将详细介绍如何通过乔拓云网设计小程…...

Electron执行本地cmd命令
javascript执行本地cmd命令,javascript代码怎么执行_js调用本机cmd-CSDN博客 使用 Node.js 打开本地应用_nodejs启动应用-CSDN博客 笔记:nodejs脚本唤醒本地应用程序或者调用命令-CSDN博客 electron调起本地应用_electron 调用本地程序-CSDN博客 命令行打开vscode 你可以使用…...

YOLOv8改进 | 主干篇 | 利用MobileNetV3替换Backbone(轻量化网络结构)
一、本文介绍 本文给大家带来的改进机制是MobileNetV3,其主要改进思想集中在结合硬件感知的网络架构搜索(NAS)和NetAdapt算法,以优化移动设备CPU上的性能。它采用了新颖的架构设计,包括反转残差结构和线性瓶颈层&…...

MATLAB Mobile - 使用预训练网络对手机拍摄的图像进行分类
系列文章目录 前言 此示例说明如何使用深度学习对移动设备摄像头采集的图像进行分类。 在您的移动设备上安装和设置 MATLAB Mobile™。然后,从 MATLAB Mobile 的“设置”登录 MathWorks Cloud。 在您的设备上启动 MATLAB Mobile。 一、在您的设备上安装 MATLAB M…...

LangChain入门指南:定义、功能和工作原理
LangChain入门指南:定义、功能和工作原理 引言LangChain是什么?LangChain的核心功能LangChain的工作原理LangChain实际应用案例如何开始使用LangChain 引言 在人工智能的浪潮中,语言模型已成为推动技术革新的重要力量。从简单的文本生成到复…...
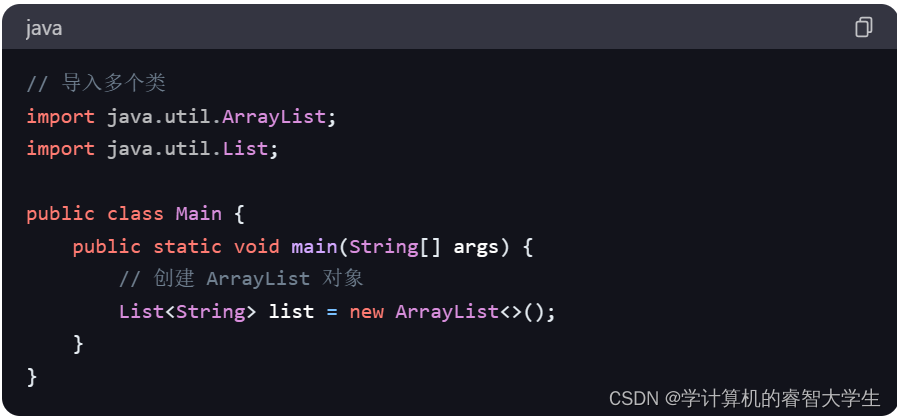
关键字:import关键字
在 Java 中,import关键字用于导入类或接口,使你可以在代码中使用它们而无需完全限定其名称。以下是使用import关键字的示例代码: 在上述示例中,通过使用import关键字导入了java.util.ArrayList类,这样就可以在代码中直…...

【C#】.net core 6.0 通过依赖注入注册和使用上下文服务
给自己一个目标,然后坚持一段时间,总会有收获和感悟! 请求上下文是指在 Web 应用程序中处理请求时,包含有关当前请求的各种信息的对象。这些信息包括请求的头部、身体、查询字符串、路由数据、用户身份验证信息以及其他与请求相关…...
关于redis单线程和IO多路复用的理解
首先,Redis是一个高性能的分布式缓存中间件。其复杂性不言而喻,对于Redis整体而言肯定不是只有一个线程。 我们常说的Redis 是单线程,主要是指 Redis 在网络 IO和键值对读写是采用一个线程来完成的,这也是 Redis 对外提供键值存储…...

第四十一章 XML 映射参数摘要
文章目录 第四十一章 XML 映射参数摘要 第四十一章 XML 映射参数摘要 TopicParameters启用 XML 映射。XMLENABLED 类参数将属性映射到元素或属性。XMLPROJECTION property parameter ("NONE", "ATTRIBUTE", "XMLATTRIBUTE", "CONTENT"…...

redis之五种基本数据类型
一) 字符串(String) 1 使用场景 2 编码 3 编码转换 二) List(列表) 1 使用场景 2 编码 三) Set(无序集合) 1 使用场景 2 编码 3 编码转换 四) ZSet(有序集合) 1 使用场景 2 编码 3 编码转换 五) Hash 1 使用场景 2 编码 3 编码转换 五种基本数据类型 redis…...
RocketMQ系统性学习-RocketMQ高级特性之消息大量堆积处理、部署架构和高可用机制
🌈🌈🌈🌈🌈🌈🌈🌈 【11来了】文章导读地址:点击查看文章导读! 🍁🍁🍁🍁🍁🍁dz…...
Angular 进阶之五: Signals到底用不用?
Angular 在V16的时候推出了Signals,在17正式作为主打功能之一强烈推荐,看过了各种博主的各种科普文章也没说明白,到底这东西值不值得用?毕竟项目大了,重构代码也不是闹着玩儿的。各种科普文章主要在说两点:…...

茉莉花插件架构解析:智能中文文献元数据抓取与PDF结构化处理方案
茉莉花插件架构解析:智能中文文献元数据抓取与PDF结构化处理方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 茉莉…...

CANoe测试报告配置避坑指南:Test Module与vTESTstudio两种模式下的关键差异与最佳实践
CANoe测试报告配置避坑指南:Test Module与vTESTstudio两种模式下的关键差异与最佳实践 在汽车电子测试领域,CANoe作为Vector公司的旗舰产品,其测试报告配置的灵活性和准确性直接影响着测试效率与结果分析。面对Test Module(传统CA…...

从零到一:基于STM32硬件SPI驱动M95系列EEPROM的实战指南
1. 硬件SPI与EEPROM基础概念 第一次接触STM32的硬件SPI驱动EEPROM时,我也被各种专业术语搞得头晕眼花。简单来说,SPI就像两个人在用摩斯密码交流——主设备(STM32)通过四根线(MOSI、MISO、SCK、NSS)与从设备…...

深度学习权重约束技术:原理与实践指南
1. 深度学习中的权重约束:从理论到实践在训练深度神经网络时,我们常常面临一个关键挑战:如何在保持模型强大表达能力的同时,防止它过度记忆训练数据中的噪声和无关细节。传统方法如权重衰减(weight decay)通…...

如何在AMD显卡上轻松训练AI绘画模型:kohya_ss完整配置指南
如何在AMD显卡上轻松训练AI绘画模型:kohya_ss完整配置指南 【免费下载链接】kohya_ss 项目地址: https://gitcode.com/GitHub_Trending/ko/kohya_ss 想要用AMD显卡训练自己的AI绘画模型却不知从何入手?kohya_ss为你提供了完美的解决方案…...

3分钟掌握人类微生物组数据分析:curatedMetagenomicData终极指南
3分钟掌握人类微生物组数据分析:curatedMetagenomicData终极指南 【免费下载链接】curatedMetagenomicData Curated Metagenomic Data of the Human Microbiome 项目地址: https://gitcode.com/gh_mirrors/cu/curatedMetagenomicData 还在为宏基因组数据分析…...

MacBook电池终极保养指南:如何用AlDente延长电池寿命3倍
MacBook电池终极保养指南:如何用AlDente延长电池寿命3倍 【免费下载链接】AlDente-Battery_Care_and_Monitoring Menubar Tool to set Charge Limits and Prolong Battery Lifespan 项目地址: https://gitcode.com/gh_mirrors/al/AlDente-Battery_Care_and_Monito…...

基于Harness Engineering的零代码AI智能体开发平台Nexent深度解析
1. 项目概述:当“零代码”遇上“工程化”,AI智能体开发的新范式 最近在AI应用开发圈子里,一个词被反复提及: Agentic AI ,或者说智能体。大家可能都体验过ChatGPT这类对话模型,它们能回答问题、写写代码&…...

从JDK8到21:SpringBoot核心组件适配实战与性能优化
1. 从JDK8到21的升级背景与挑战 最近几年Java生态发生了翻天覆地的变化,特别是JDK21作为最新的LTS版本,带来了虚拟线程、模式匹配等革命性特性。我们团队负责的一个电商系统原本运行在JDK8SpringBoot 2.0.3的环境上,为了利用这些新特性提升系…...

不止于APK:用bsdiff玩转Android文件差分,从游戏资源到配置文件的增量更新思路
超越APK:用bsdiff构建Android全文件增量更新体系 当游戏资源包从200MB增长到300MB时,用户每次更新都要重新下载整个文件?配置文件微调几个参数却要推送完整文件?这些场景正是二进制差分技术大显身手的舞台。bsdiff作为高效的二进制…...