Ignite内存配置
配置内存
#1.内存架构
#1.1.概述
Ignite内存架构通过可以同时在内存和磁盘上存储和处理数据及索引,得到了支持磁盘持久化的内存级性能。

多层存储的运行方式类似于操作系统(例如Linux)的虚拟内存。但是这两种类型架构之间的主要区别是,多层存储始终将磁盘视为数据的超集(如果启用了持久化),在故障或者重启后仍然可以保留数据,而传统的虚拟内存仅将磁盘作为交换扩展,一旦进程停止,数据就会被清除。
#1.2.内存架构
多层架构是一种基于固定大小页面的内存架构,这些页面存储在内存(Java堆外)的托管非堆区中,并按磁盘上的特定层次结构进行组织。
Ignite在内存和磁盘上都维护相同的二进制数据表示形式,这样在内存和磁盘之间移动数据时就不需要进行昂贵的序列化。
下图说明了多层存储架构:
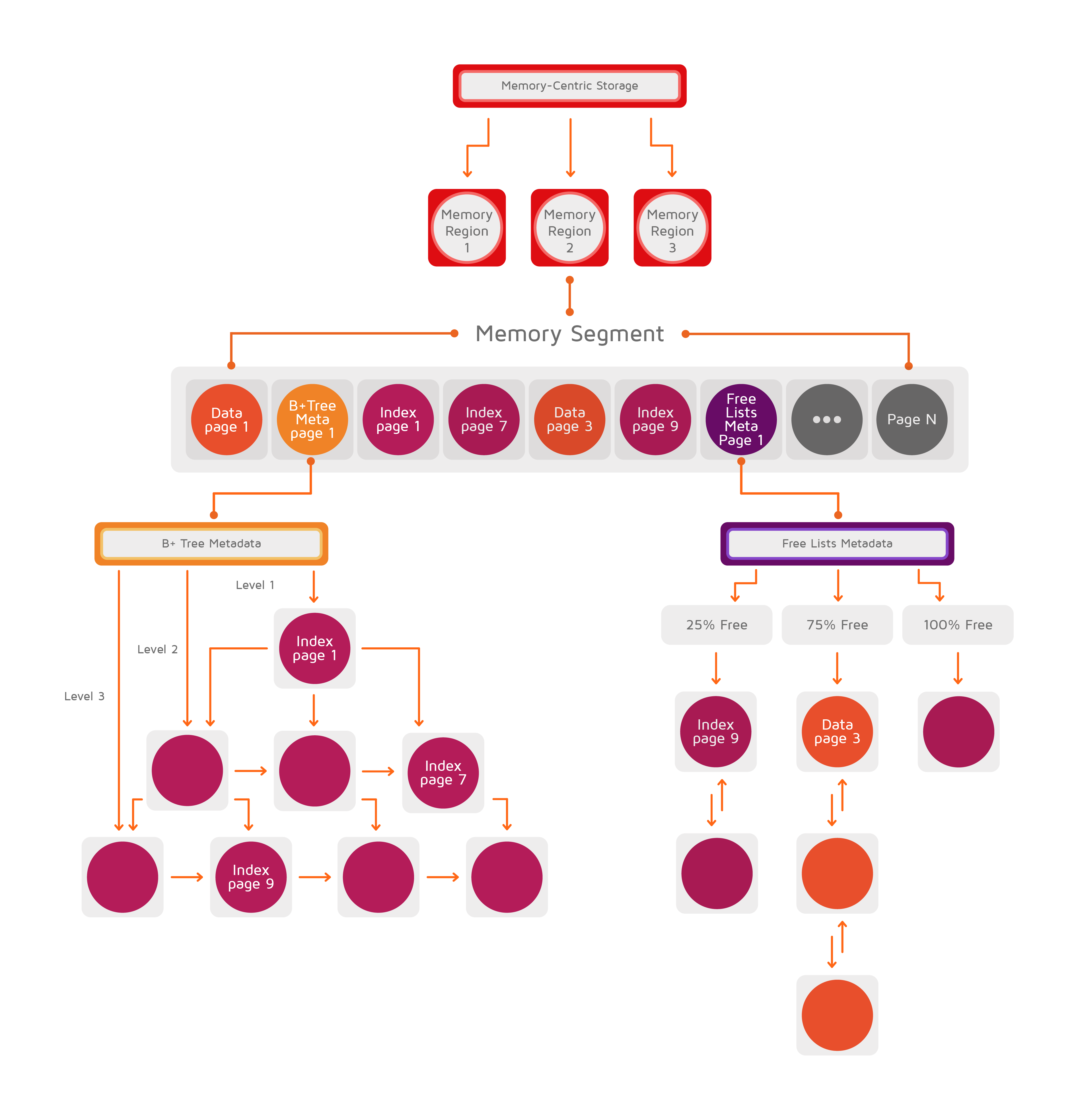
#1.2.1.内存段
每个数据区均以初始大小开始,并具有可以增长到的最大大小。该区域通过分配连续的内存段扩展到其最大大小。
内存段是从操作系统分配的物理内存的连续字节数组,该数组被拆分为固定大小的页面。该段中可以存在几种类型的页面,如下图所示。

#1.2.2.数据页面
数据页面存储从应用端写入缓存的条目。
通常每个数据页面持有多个键值条目,以便尽可能高效地使用内存并避免内存碎片。将新条目添加到缓存后,Ignite会寻找一个适合整个键-值条目的最佳页面。
但是如果一个条目的总大小超过了DataStorageConfiguration.setPageSize(..)属性配置的页面大小,则该条目将占用多个数据页面。
提示
如果有许多缓存条目无法容纳在单个页面中,那么增加页面大小配置参数是有必要的。
如果在更新期间条目大小扩大并超过了其数据页面的剩余可用空间,则Ignite会搜索新的空间足够的数据页面,并将其移到那里。
#1.2.3.内存碎片整理
Ignite自动执行内存碎片整理,不需要用户干预。
随着时间的推移,每个数据页面可能会通过不同的CRUD操作多次更新,这会导致页面和整体内存碎片化。为了最大程度地减少内存碎片,只要页面碎片过多,Ignite都会使用页面压缩。
压缩的数据页面如下图所示:

页面具有一个头部,其存储内部使用所需的元信息。所有键-值条目总是从右到左添加。在上图中,页面中存储了三个条目(分别为1、2和3)。这些条目可能具有不同的大小。
页面内条目位置的偏移量(或引用)从左到右存储,并且始终为固定大小。偏移量用于在页面中查找键-值条目的指针。
中间的空间是可用空间,每当将更多数据推入集群时,该空间就会被填充。
接下来,假设随着时间的推移,条目2被删除,这导致页面中的非连续可用空间:

这就是碎片化页面的样子。
但是,当需要页面的整个可用空间或达到某个碎片阈值时,压缩过程会对页面进行碎片整理,使其变为上面第一张图片中所示的状态,其中该连续空间是连续的。此过程是自动的,不需要用户干预。
#1.3.持久化
Ignite提供了许多功能,可以将数据持久化磁盘上,同时还保持一致性。可以在不丢失数据的前提下重启集群,可以应对故障,并在内存不足时为数据提供存储。启用原生持久化后,Ignite会将所有数据保存在磁盘上,并将尽可能多的数据加载到内存中进行处理。更多信息请参考Ignite持久化章节的内容。
#2.配置数据区
#2.1.概述
Ignite使用数据区的概念来控制可用于缓存的内存数量,数据区是缓存数据存储在内存中的逻辑可扩展区域。可以控制数据区的初始值及其可以占用的最大值,除了大小之外,数据区还控制缓存的持久化配置。
Ignite有一个默认的数据区最多可占用该节点20%的内存,并且创建的所有缓存均位于该数据区中,但是也可以添加任意多个数据区,创建多个数据区的原因有:
- 可以通过不同数据区分别配置缓存对应的可用内存量;
- 持久化参数是按数据区配置的。如果要同时具有纯内存缓存和持久化缓存,则需要配置两个(或多个)具有不同持久化参数的数据区:一个用于纯内存缓存,一个用于持久化缓存;
- 部分内存参数,比如退出策略,是按照数据区进行配置的。
下面的章节会演示如何更改默认数据区的参数或配置多个数据区。
#2.2.配置默认数据区
新的缓存默认会添加到默认的数据区中,可以在数据区配置中更改默认数据区的属性:
- XML
- Java
- C#/.NET
DataStorageConfiguration storageCfg = new DataStorageConfiguration();DataRegionConfiguration defaultRegion = new DataRegionConfiguration();
defaultRegion.setName("Default_Region");
defaultRegion.setInitialSize(100 * 1024 * 1024);storageCfg.setDefaultDataRegionConfiguration(defaultRegion);IgniteConfiguration cfg = new IgniteConfiguration();cfg.setDataStorageConfiguration(storageCfg);// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.3.添加自定义数据区
除了默认的数据区,还可以使用自定义配置定义更多个数据区,在下面的示例中,配置了一个数据区占用40MB空间然后使用了Random-2-LRU退出策略,注意在进一步的缓存配置中,在该数据区中创建了一个缓存。
- XML
- Java
- C#/.NET
DataStorageConfiguration storageCfg = new DataStorageConfiguration();DataRegionConfiguration defaultRegion = new DataRegionConfiguration();
defaultRegion.setName("Default_Region");
defaultRegion.setInitialSize(100 * 1024 * 1024);storageCfg.setDefaultDataRegionConfiguration(defaultRegion);
// 40MB memory region with eviction enabled.
DataRegionConfiguration regionWithEviction = new DataRegionConfiguration();
regionWithEviction.setName("40MB_Region_Eviction");
regionWithEviction.setInitialSize(20 * 1024 * 1024);
regionWithEviction.setMaxSize(40 * 1024 * 1024);
regionWithEviction.setPageEvictionMode(DataPageEvictionMode.RANDOM_2_LRU);storageCfg.setDataRegionConfigurations(regionWithEviction);IgniteConfiguration cfg = new IgniteConfiguration();cfg.setDataStorageConfiguration(storageCfg);CacheConfiguration cache1 = new CacheConfiguration("SampleCache");
//this cache will be hosted in the "40MB_Region_Eviction" data region
cache1.setDataRegionName("40MB_Region_Eviction");cfg.setCacheConfiguration(cache1);// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.4.缓存预热策略
集群启动组网成功之后,Ignite本身并不需要对内存进行预热,应用就可以在其上执行计算和查询。但是对于需要低延迟的系统,还是希望在查询数据之前先将数据加载到内存中的。
当前,Ignite的预热策略是从索引开始,将数据加载到所有或者指定的数据区,直到用完可用空间为止。可以为所有的数据区进行配置(默认),也可以单独为某个数据区进行配置。
要预热所有数据区,需将配置参数LoadAllWarmUpStrategy传递给DataStorageConfiguration#setDefaultWarmUpConfiguration,如下所示:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();DataStorageConfiguration storageCfg = new DataStorageConfiguration();//Changing the default warm-up strategy for all data regions
storageCfg.setDefaultWarmUpConfiguration(new LoadAllWarmUpConfiguration());cfg.setDataStorageConfiguration(storageCfg);
要预热某个数据区,需将配置参数LoadAllWarmUpStrategy传递给DataStorageConfiguration#setWarmUpConfiguration,如下所示:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();DataStorageConfiguration storageCfg = new DataStorageConfiguration();//Setting another warm-up strategy for a custom data region
DataRegionConfiguration myNewDataRegion = new DataRegionConfiguration();myNewDataRegion.setName("NewDataRegion");//You can tweak the initial size as well as other settings
myNewDataRegion.setInitialSize(100 * 1024 * 1024);//Performing data loading from disk in DRAM on restarts.
myNewDataRegion.setWarmUpConfiguration(new LoadAllWarmUpConfiguration());//Enabling Ignite persistence. Ignite reads data from disk when queried for tables/caches from this region.
myNewDataRegion.setPersistenceEnabled(true);//Applying the configuration.
storageCfg.setDataRegionConfigurations(myNewDataRegion);cfg.setDataStorageConfiguration(storageCfg);
要停止预热所有数据区,请将配置参数NoOpWarmUpStrategy传递给DataStorageConfiguration#setDefaultWarmUpConfiguration,如下所示:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();DataStorageConfiguration storageCfg = new DataStorageConfiguration();storageCfg.setDefaultWarmUpConfiguration(new NoOpWarmUpConfiguration());cfg.setDataStorageConfiguration(storageCfg);
要停止预热某个数据区,请将配置参数NoOpWarmUpStrategy传递给DataStorageConfiguration#setWarmUpConfiguration,如下所示:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();DataStorageConfiguration storageCfg = new DataStorageConfiguration();//Setting another warm-up strategy for a custom data region
DataRegionConfiguration myNewDataRegion = new DataRegionConfiguration();myNewDataRegion.setName("NewDataRegion");//You can tweak the initial size as well as other settings
myNewDataRegion.setInitialSize(100 * 1024 * 1024);//Skip data loading from disk in DRAM on restarts.
myNewDataRegion.setWarmUpConfiguration(new NoOpWarmUpConfiguration());//Enabling Ignite persistence. Ignite reads data from disk when queried for tables/caches from this region.
myNewDataRegion.setPersistenceEnabled(true);//Applying the configuration.
storageCfg.setDataRegionConfigurations(myNewDataRegion);cfg.setDataStorageConfiguration(storageCfg);
还可以使用control.sh和JMX停止缓存预热过程。
要使用control.sh停止预热:
- Linux
- Windows
control.sh --warm-up --stop --yes
要使用JMX停止预热,可使用下面的方法:
org.apache.ignite.mxbean.WarmUpMXBean#stopWarmUp
#3.退出策略
如果关闭了Ignite原生持久化,Ignite会在堆外内存中存储所有的缓存条目,当有新的数据注入,会进行页面的分配。如果达到了内存的限制,Ignite无法分配页面时,部分数据就必须从内存中删除以避免内存溢出,这个过程叫做退出,退出保证系统不会内存溢出,但是代价是内存数据丢失以及如果需要数据还需要重新加载。
退出策略用于下面的场景:
- 关闭原生持久化之后的堆外内存;
- 整合外部存储后的堆外内存;
- 堆内缓存;
- 近缓存(如果启用)。
如果开启了原生持久化,当Ignite无法分配新的页面时,会有一个叫做页面替换的简单过程来进行堆外内存的释放,不同点在于数据并没有丢失(因为其存储于持久化存储),因此不用担心数据丢失,而要关注效率。页面替换由Ignite自动处理,用户无法进行配置。
#3.1.堆外内存退出
堆外内存退出的实现方式如下:
当内存使用超过预设限制时,Ignite使用预配置的算法之一来选择最适合退出的内存页面。然后将页面中的每个缓存条目从页面中删除,但是会保留被事务锁定的条目。因此,整个页面或大块页面都是空的,可以再次使用。
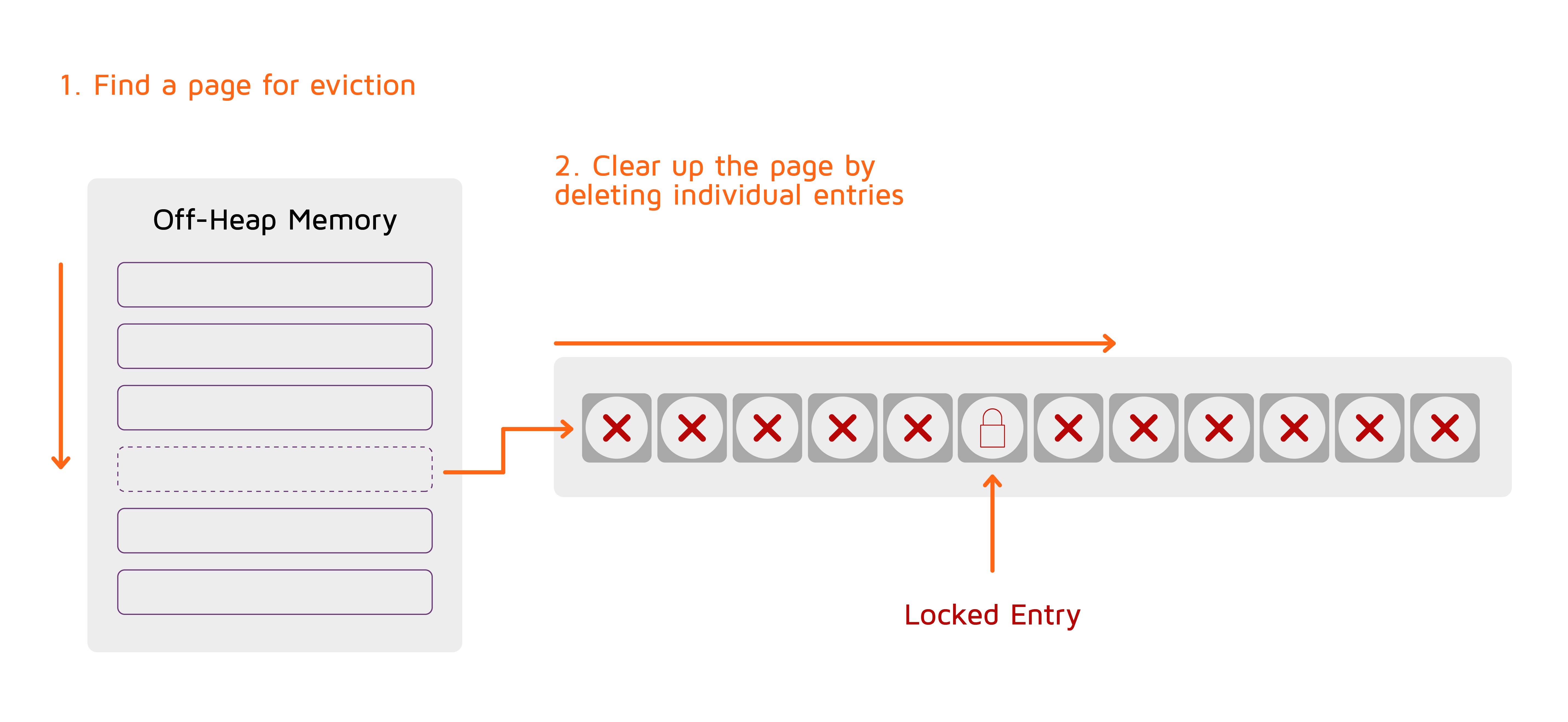
堆外内存的退出默认是关闭的,这意味着内存使用量会一直增长直到达到限值。如果要开启退出,需要在数据区配置中指定页面退出模式。注意堆外内存退出是数据区级的,如果没使用数据区,那么需要给默认的数据区显式地增加参数来配置退出。
默认情况下,当某个数据区的内存消耗量达到90%时,退出就开始了,如果希望更早或者更晚地发起退出,可以配置DataRegionConfiguration.setEvictionThreshold(...)参数。
Ignite支持两种页面选择算法:
- Random-LRU
- Random-2-LRU
两者的不同下面会说明。
#3.1.1.Random-LRU
要启用Random-LRU退出算法,配置方式如下所示;
- XML
- Java
- C#/.NET
// Node configuration.
IgniteConfiguration cfg = new IgniteConfiguration();// Memory configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();// Creating a new data region.
DataRegionConfiguration regionCfg = new DataRegionConfiguration();// Region name.
regionCfg.setName("20GB_Region");// 500 MB initial size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);// 20 GB max size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);// Enabling RANDOM_LRU eviction for this region.
regionCfg.setPageEvictionMode(DataPageEvictionMode.RANDOM_LRU);// Setting the data region configuration.
storageCfg.setDataRegionConfigurations(regionCfg);// Applying the new configuration.
cfg.setDataStorageConfiguration(storageCfg);
Random-LRU算法工作方式如下:
- 当一个数据区配置了内存策略时,就会分配一个堆外数组,它会跟踪每个数据页面的
最后使用时间戳; - 当数据页面被访问时,跟踪数组的时间戳就会被更新;
- 当到了退出页面时间时,算法会从跟踪数组中随机地选择5个索引,然后退出最近的时间戳对应的页面,如果部分索引指向非数据页面(索引或者系统页面),算法会选择其它的页面。
#3.1.2.Random-2-LRU
Random-2-LRU退出算法是Random-LRU算法的抗扫描版,配置方式如下所示:
- XML
- Java
- C#/.NET
// Ignite configuration.
IgniteConfiguration cfg = new IgniteConfiguration();// Memory configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();// Creating a new data region.
DataRegionConfiguration regionCfg = new DataRegionConfiguration();// Region name.
regionCfg.setName("20GB_Region");// 500 MB initial size (RAM).
regionCfg.setInitialSize(500L * 1024 * 1024);// 20 GB max size (RAM).
regionCfg.setMaxSize(20L * 1024 * 1024 * 1024);// Enabling RANDOM_2_LRU eviction for this region.
regionCfg.setPageEvictionMode(DataPageEvictionMode.RANDOM_2_LRU);// Setting the data region configuration.
storageCfg.setDataRegionConfigurations(regionCfg);// Applying the new configuration.
cfg.setDataStorageConfiguration(storageCfg);
在Random-2-LRU算法中,每个数据页面会存储两个最近访问时间戳,退出时,算法会随机地从跟踪数组中选择5个索引值,然后两个最近时间戳中的最小值会被用来和另外4个候选页面中的最小值进行比较。
Random-2-LRU比Random-LRU要好,因为它解决了昙花一现的问题,即一个页面很少被访问,但是偶然地被访问了一次,然后就会被退出策略保护很长时间。
#3.2.堆内缓存退出
关于如何为堆内缓存配置退出策略的介绍,请参见堆内缓存配置退出策略章节的内容。
配置持久化
#1.Ignite持久化
#1.1.概述
Ignite持久化,或者说原生持久化,是旨在提供持久化存储的一组功能。启用后,Ignite会将所有数据存储在磁盘上,并将尽可能多的数据加载到内存中进行处理。例如,如果有100个条目,而内存仅能存储20个,则所有100个都存储在磁盘上,而内存中仅缓存20个,以获得更好的性能。
如果关闭原生持久化并且不使用任何外部存储时,Ignite就是一个纯内存存储。
启用持久化后,每个服务端节点只会存储整个数据的一个子集,即只包含分配给该节点的分区(如果启用了备份,也包括备份分区)。
原生持久化基于以下特性:
- 在磁盘上存储数据分区;
- 预写日志;
- 检查点;
- 操作系统交换的使用。
启用持久化后,Ignite会将每个分区存储在磁盘上的单独文件中,分区文件的数据格式与保存在内存中的数据格式相同。如果启用了分区备份,则也会保存在磁盘上,除了数据分区,Ignite还存储索引和元数据。

可以在配置中修改数据文件的默认位置。
#1.2.启用持久化存储
原生持久化是配置在数据区上的。要启用持久化存储,需要在数据区配置中将persistenceEnabled属性设置为true,可以同时有纯内存数据区和持久化数据区。
以下是如何为默认数据区启用持久化存储的示例:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();//data storage configuration
DataStorageConfiguration storageCfg = new DataStorageConfiguration();storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);cfg.setDataStorageConfiguration(storageCfg);Ignite ignite = Ignition.start(cfg);
#1.3.配置持久化存储目录
启用持久化之后,节点就会在{IGNITE_WORK_DIR}/db目录中存储用户的数据、索引和WAL文件,该目录称为存储目录。通过配置DataStorageConfiguration的storagePath属性可以修改存储目录。
每个节点都会在存储目录下维护一个子目录树,来存储缓存数据、WAL文件和WAL存档文件。
| 子目录名 | 描述 |
|---|---|
{WORK_DIR}/db/{nodeId} | 该目录中包括了缓存的数据和索引 |
{WORK_DIR}/db/wal/{nodeId} | 该目录中包括了WAL文件 |
{WORK_DIR}/db/wal/archive/{nodeId} | 该目录中包括了WAL存档文件 |
这里的nodeId要么是节点的一致性ID(如果在节点配置中定义)要么是自动生成的节点ID,它用于确保节点目录的唯一性。如果多个节点共享同一工作目录,则它们将使用不同的子目录。
如果工作目录包含多个节点的持久化文件(存在多个具有不同nodeId的{nodeId}子目录),则该节点将选择第一个未使用的子目录。为了确保节点即使重启也始终使用固定的子目录,即指定数据分区,需要在节点配置中将IgniteConfiguration.setConsistentId设置为集群范围内的唯一值。
修改存储目录的代码如下所示:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();//data storage configuration
DataStorageConfiguration storageCfg = new DataStorageConfiguration();storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);storageCfg.setStoragePath("/opt/storage");cfg.setDataStorageConfiguration(storageCfg);Ignite ignite = Ignition.start(cfg);
还可以将WAL和WAL存档路径指向存储目录之外的目录。详细信息后面章节会介绍。
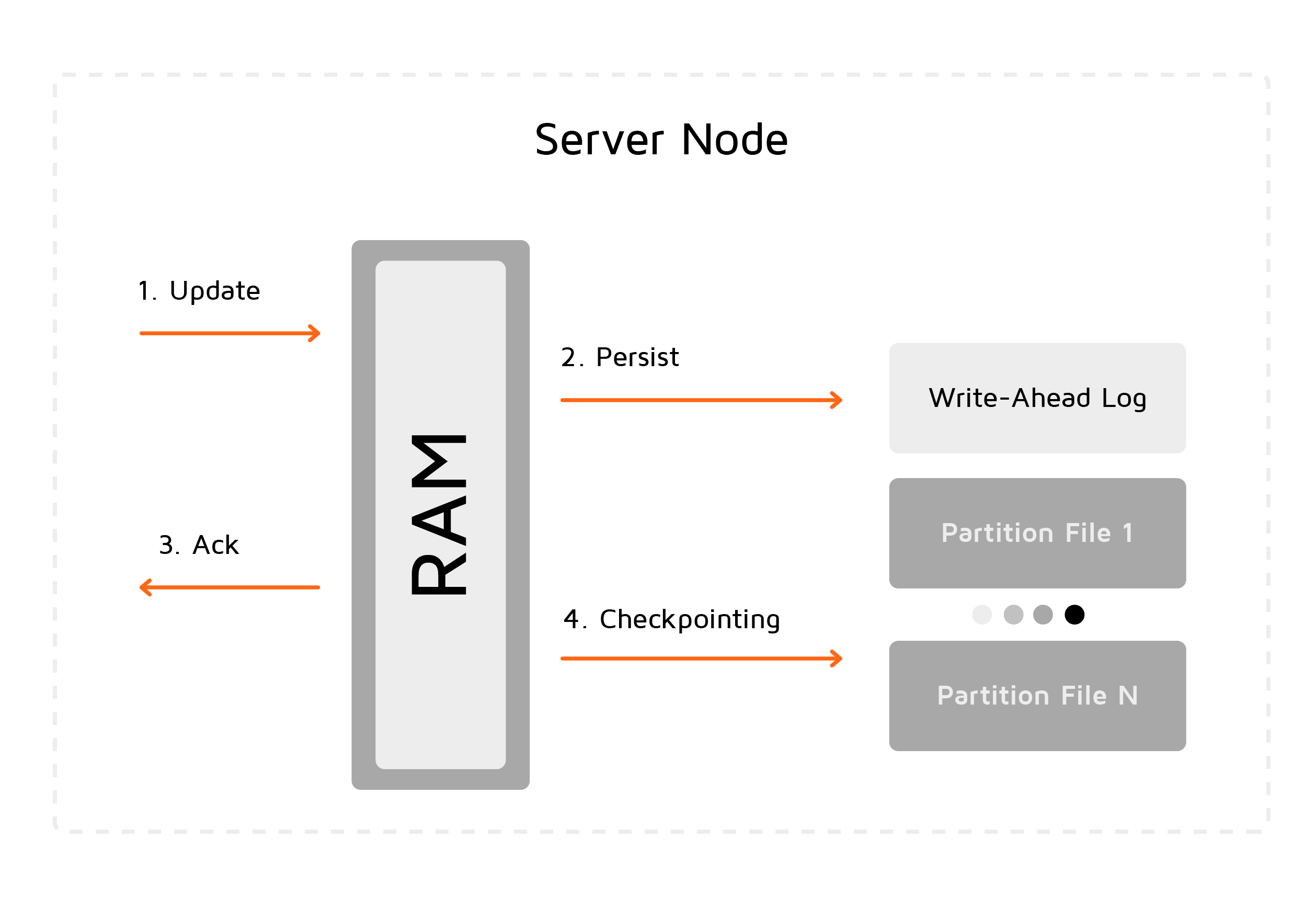
#1.4.预写日志
预写日志是节点上发生的所有数据修改操作(包括删除)的日志。在内存中更新页面时,更新不会直接写入分区文件,而是会附加到WAL的末尾。
预写日志的目的是为单个节点或整个集群的故障提供一个恢复机制。如果发生故障或重启,则可以依靠WAL的内容将集群恢复到最近成功提交的事务。
WAL由几个文件(称为活动段)和一个存档组成。活动段按顺序填充,然后循环覆盖。第一个段写满后,其内容将复制到WAL存档中(请参见下面的WAL存档章节)。在复制第一段时,第二段会被视为激活的WAL文件,并接受来自应用端的所有更新,活动段默认有10个。
#1.4.1.WAL模式
WAL模式有几种,每种模式对性能的影响方式不同,并提供不同的一致性保证:
| WAL模式 | 描述 | 一致性保证 |
|---|---|---|
FSYNC | 保证每个原子写或者事务性提交都会持久化到磁盘。 | 数据更新不会丢失,不管是任何的操作系统或者进程故障,甚至是电源故障。 |
LOG_ONLY | 默认模式,对于每个原子写或者事务性提交,保证会刷新到操作系统的缓冲区缓存或者内存映射文件。默认会使用内存映射文件方式,并且可以通过将IGNITE_WAL_MMAP系统属性配置为false将其关闭。 | 如果仅仅是进程崩溃数据更新会保留。 |
BACKGROUND | 如果打开了IGNITE_WAL_MMAP属性(默认),该模式的行为类似于LOG_ONLY模式,如果关闭了内存映射文件方式,变更会保持在节点的内部缓冲区,缓冲区刷新到磁盘的频率由walFlushFrequency参数定义。 | 如果打开了IGNITE_WAL_MMAP属性(默认),该模式提供了与LOG_ONLY模式一样的保证,否则如果进程故障或者其它的故障发生时,最近的数据更新可能丢失。 |
NONE | WAL被禁用,只有在节点优雅地关闭时,变更才会正常持久化,使用Ignite#active(false)可以冻结集群然后停止节点。 | 可能出现数据丢失,如果节点在更新操作期间突然终止,则磁盘上存储的数据很可能出现不同步或损坏。 |
#1.4.2.WAL存档
WAL存档用于保存故障后恢复节点所需的WAL段。存档中保存的段的数量应确保所有段的总大小不超过WAL存档的既定大小。
WAL存档的最大大小(在磁盘上占用的总空间)定义为检查点缓冲区大小的4倍,可以在配置中更改该值。
警告
将WAL存档大小配置为小于默认值可能影响性能,用于生产之前需要进行测试。
#1.4.3.修改WAL段大小
在高负载情况下,默认的WAL段大小(64MB)可能效率不高,因为它会导致WAL过于频繁地在段之间切换,并且切换/轮转是一项昂贵的操作。更大的WAL段大小有助于提高高负载下的性能,但代价是增加WAL文件和WAL存档文件的总大小。
可以在数据存储配置中更改WAL段文件的大小,该值必须介于512KB和2GB之间。
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);storageCfg.setWalSegmentSize(128 * 1024 * 1024);cfg.setDataStorageConfiguration(storageCfg);Ignite ignite = Ignition.start(cfg);
#1.4.4.禁用WAL
警告
禁用或启用WAL只能在稳定的拓扑上进行:即所有基线节点都应该在线,在此操作期间不应该有节点加入或离开集群。否则,缓存可能会陷入不一致状态。如果发生这种情况,建议销毁受影响的缓存。
在某些情况下,禁用WAL以获得更好的性能是合理的做法。例如,在初始数据加载期间禁用WAL并在预加载完成后启用WAL就是个好的做法。
- Java
- C#/.NET
- SQL
IgniteConfiguration cfg = new IgniteConfiguration();
DataStorageConfiguration storageCfg = new DataStorageConfiguration();
storageCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);cfg.setDataStorageConfiguration(storageCfg);Ignite ignite = Ignition.start(cfg);ignite.cluster().state(ClusterState.ACTIVE);String cacheName = "myCache";ignite.getOrCreateCache(cacheName);ignite.cluster().disableWal(cacheName);//load data
ignite.cluster().enableWal(cacheName);
警告
如果禁用WAL并重启节点,则将从该节点上的持久化存储中删除所有数据。之所以这样实现,是因为如果没有WAL,则无法保证节点故障或重启时的数据一致性。
#1.4.5.WAL存档压缩
可以启用WAL存档压缩以减少WAL存档占用的空间。WAL存档默认包含最后20个检查点的段(此数字是可配置的)。启用压缩后,则将所有1个检查点之前的已存档段压缩为ZIP格式,如果需要这些段(例如在节点之间再平衡数据),则会将其解压缩为原始格式。
关于如何启用WAL存档压缩,请参见下面的配置属性章节。
#1.4.6.WAL记录压缩
如设计文档中所述,在确认用户操作之前,代表数据更新的物理和逻辑记录已写入WAL文件,Ignite可以先将WAL记录压缩到内存中,然后再写入磁盘以节省空间。
WAL记录压缩要求引入ignite-compress模块,具体请参见启用模块。
WAL记录压缩默认是禁用的,如果要启用,需要在数据存储配置中设置压缩算法和压缩级别:
IgniteConfiguration cfg = new IgniteConfiguration();DataStorageConfiguration dsCfg = new DataStorageConfiguration();
dsCfg.getDefaultDataRegionConfiguration().setPersistenceEnabled(true);//WAL page compression parameters
dsCfg.setWalPageCompression(DiskPageCompression.LZ4);
dsCfg.setWalPageCompressionLevel(8);cfg.setDataStorageConfiguration(dsCfg);
Ignite ignite = Ignition.start(cfg);
DiskPageCompression中列出了支持的压缩算法。
#1.4.7.禁用WAL存档
有时可能想要禁用WAL存档,比如减少与将WAL段复制到存档文件有关的开销,当Ignite将数据写入WAL段的速度快于将段复制到存档文件的速度时,这样做就有用,因为这样会导致I/O瓶颈,从而冻结节点的操作,如果遇到了这样的问题,就可以尝试关闭WAL存档。
通过将WAL路径和WAL存档路径配置为同一个值,可以关闭存档。这时Ignite就不会将段复制到存档文件,而是只是在WAL文件夹中创建新的段。根据WAL存档大小设置,旧段将随着WAL的增长而删除。
#1.5.检查点
检查点是一个将脏页面从内存复制到磁盘上的分区文件的过程,脏页面是指页面已经在内存中进行了更新但是还没有写入对应的分区文件(只是添加到了WAL中)。
创建检查点后,所有更改都将保存到磁盘,并且在节点故障并重启后将生效。
检查点和预写日志旨在确保数据的持久化和节点故障时的恢复能力。
这个过程通过在磁盘上保持页面的最新状态而节省更多的磁盘空间,检查点完成后,就可以在WAL存档中删除检查点执行前创建的WAL段。
具体请参见相关的文档:
- 检查点操作监控;
- 调整检查点缓冲区大小。
#1.6.配置属性
下表列出了DataStorageConfiguration的主要参数:
| 属性名 | 描述 | 默认值 |
|---|---|---|
persistenceEnabled | 将该属性配置为true可以开启原生持久化。 | false |
storagePath | 数据存储路径。 | ${IGNITE_HOME}/work/db/node{IDX}-{UUID} |
walPath | WAL活动段存储路径。 | ${IGNITE_HOME}/work/db/wal/ |
walArchivePath | WAL存档路径。 | ${IGNITE_HOME}/work/db/wal/archive/ |
walCompactionEnabled | 将该属性配置为true可以开启WAL存档压缩。 | false |
walSegmentSize | WAL段文件大小(字节)。 | 64MB |
walMode | 预写日志模式。 | LOG_ONLY |
walCompactionLevel | WAL压缩级别,1表示速度最快,9表示最高的压缩率。 | 1 |
maxWalArchiveSize | WAL存档占用空间最大值(字节)。 | 检查点缓冲区大小的4倍 |
#2.外部存储
#2.1.概述
Ignite可以做为已有数据库之上的一个缓存层,包括RDBMS或者NoSQL数据库,比如Apache Cassandra或者MongoDB等,该场景通过内存计算来对底层数据库进行加速。
Ignite可以与Apache Cassandra直接集成,但是暂时还不支持其他NoSQL数据库,但是开发自己的CacheStore接口实现。
使用外部存储的两个主要场景是:
- 作为已有数据库的缓存层,这时可以通过将数据加载到内存来优化处理速度,还可以为不支持SQL的数据库带来SQL支持能力(数据全部加载到内存);
- 希望将数据持久化到外部数据库(而不是单一的原生持久化)。
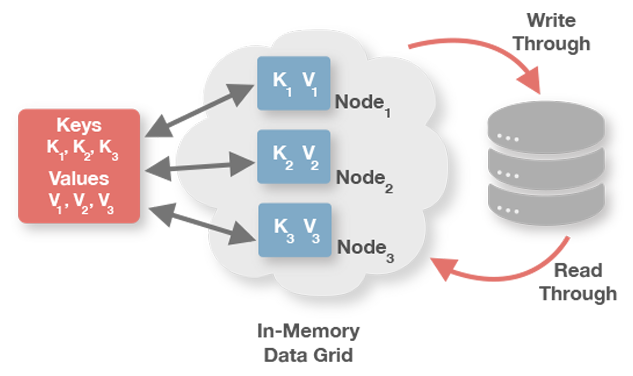
CacheStore接口同时扩展了javax.cache.integration.CacheLoader和javax.cache.integration.CacheWriter,相对应的分别用于通读和通写。也可以单独实现每个接口,然后在缓存配置中单独配置。
提示
除了键-值操作,Ignite的通写也支持SQL的INSERT、UPDATE和MERGE,但是SELECT查询语句不会从外部数据库通读数据。
#2.1.1.通读和通写
通读是指如果缓存中不存在,则从底层持久化存储中读取数据。注意这仅适用于通过键-值API进行的get操作,SELECT查询不会从外部数据库查询数据。要执行SELECT查询,必须通过调用loadCache()方法将数据从数据库预加载到缓存中。
通写是指数据在缓存中更新后会自动持久化。所有的通读和通写操作都参与缓存事务,然后作为整体提交或回滚。
#2.1.2.后写缓存
在一个简单的通写模式中每个缓存的put和remove操作都会涉及一个持久化存储的请求,因此整个缓存更新的持续时间可能是相对比较长的。另外,密集的缓存更新频率也会导致非常高的存储负载。
对于这种情况,可以启用后写模式,它会以异步的方式执行更新操作。这个方式的主要概念是累积更新操作然后作为一个批量异步刷入持久化存储。数据的刷新可以基于时间的事件(数据条目驻留在队列中的时间是有限的)来触发,也可以基于队列大小的事件(如果队列大小达到限值,会被刷新)触发,或者两者(先发生者优先)。
性能和一致性
启用后写缓存可以通过异步更新来提高性能,但这可能会导致一致性下降,因为某些更新可能由于节点故障或崩溃而丢失。
对于后写的方式只有数据的最后一次更新会被写入底层存储。如果键为key1的缓存数据分别被依次更新为值value1、value2和value3,那么只有(key1,value3)对这一个存储请求会被传播到持久化存储。
更新性能
批量的存储操作通常比按顺序的单一操作更有效率,因此可以通过开启后写模式的批量操作来利用这个特性。简单类型(put和remove)的简单顺序更新操作可以被组合成一个批量操作。比如,连续地往缓存中写入(key1,value1)、(key2,value2)、(key3,value3)可以通过一个单一的CacheStore.putAll(...)操作批量处理。
#2.2.RDBMS集成
要将RDBMS作为底层存储,可以使用下面的CacheStore实现之一:
CacheJdbcPojoStore:使用反射将对象存储为一组字段,如果在现有数据库之上添加Ignite并希望使用底层表中的部分字段或所有字段,请使用此实现;CacheJdbcBlobStore:将对象以Blob格式存储在底层数据库中,当将外部数据库作为持久化存储并希望以简单格式存储数据时,可以用此实现。
下面是CacheStore两种实现的配置示例:
#2.2.1.CacheJdbcPojoStore
使用CacheJdbcPojoStore,可以将对象存储为一组字段,并可以配置表列和对象字段之间的映射。
-
将
CacheConfiguration.cacheStoreFactory属性设置为org.apache.ignite.cache.store.jdbc.CacheJdbcPojoStoreFactory并提供以下属性:dataSourceBean:数据库连接凭据:URL、用户、密码;dialect:实现与数据库兼容的SQL方言的类。Ignite为MySQL、Oracle、H2、SQLServer和DB2数据库提供了现成的实现。这些方言位于org.apache.ignite.cache.store.jdbc.dialect包中;types:此属性用于定义数据库表和相应的POJO之间的映射(请参见下面的POJO配置示例)。
-
(可选)如果要在缓存上执行SQL查询,请配置查询实体。
以下示例演示了如何在MySQL表之上配置Ignite缓存。该映射到Person类对象的表有2列:id(INTEGER)和name(VARCHAR)。
可以通过XML或Java代码配置CacheJdbcPojoStore。
- XML
- Java
IgniteConfiguration igniteCfg = new IgniteConfiguration();CacheConfiguration<Integer, Person> personCacheCfg = new CacheConfiguration<>();personCacheCfg.setName("PersonCache");
personCacheCfg.setCacheMode(CacheMode.PARTITIONED);
personCacheCfg.setAtomicityMode(CacheAtomicityMode.ATOMIC);personCacheCfg.setReadThrough(true);
personCacheCfg.setWriteThrough(true);CacheJdbcPojoStoreFactory<Integer, Person> factory = new CacheJdbcPojoStoreFactory<>();
factory.setDialect(new MySQLDialect());
factory.setDataSourceFactory((Factory<DataSource>)() -> {MysqlDataSource mysqlDataSrc = new MysqlDataSource();mysqlDataSrc.setURL("jdbc:mysql://[host]:[port]/[database]");mysqlDataSrc.setUser("YOUR_USER_NAME");mysqlDataSrc.setPassword("YOUR_PASSWORD");return mysqlDataSrc;
});JdbcType personType = new JdbcType();
personType.setCacheName("PersonCache");
personType.setKeyType(Integer.class);
personType.setValueType(Person.class);
// Specify the schema if applicable
// personType.setDatabaseSchema("MY_DB_SCHEMA");
personType.setDatabaseTable("PERSON");personType.setKeyFields(new JdbcTypeField(java.sql.Types.INTEGER, "id", Integer.class, "id"));personType.setValueFields(new JdbcTypeField(java.sql.Types.INTEGER, "id", Integer.class, "id")),new JdbcTypeField(java.sql.Types.VARCHAR, "name", String.class, "name"));factory.setTypes(personType);personCacheCfg.setCacheStoreFactory(factory);QueryEntity qryEntity = new QueryEntity();qryEntity.setKeyType(Integer.class.getName());
qryEntity.setValueType(Person.class.getName());
qryEntity.setKeyFieldName("id");Set<String> keyFields = new HashSet<>();
keyFields.add("id");
qryEntity.setKeyFields(keyFields);LinkedHashMap<String, String> fields = new LinkedHashMap<>();
fields.put("id", "java.lang.Integer");
fields.put("name", "java.lang.String");qryEntity.setFields(fields);personCacheCfg.setQueryEntities(Collections.singletonList(qryEntity));igniteCfg.setCacheConfiguration(personCacheCfg);
Person类:
class Person implements Serializable {private static final long serialVersionUID = 0L;private int id;private String name;public Person() {}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getId() {return id;}public void setId(int id) {this.id = id;}
}
#2.2.2.CacheJdbcBlobStore
CacheJdbcBlobStore将对象以Blob格式存储于底层数据库中,它会创建一张表名为ENTRIES,有名为key和val的列(类型都为binary)。
可以通过提供自定义的建表语句和DML语句,分别用于加载、更新、删除数据来修改默认的定义,具体请参见CacheJdbcBlobStore的javadoc。
在下面的示例中,Person类的对象存储于单一列的字节数组中。
- XML
- Java
IgniteConfiguration igniteCfg = new IgniteConfiguration();CacheConfiguration<Integer, Person> personCacheCfg = new CacheConfiguration<>();
personCacheCfg.setName("PersonCache");CacheJdbcBlobStoreFactory<Integer, Person> cacheStoreFactory = new CacheJdbcBlobStoreFactory<>();cacheStoreFactory.setUser("USER_NAME");MysqlDataSource mysqlDataSrc = new MysqlDataSource();
mysqlDataSrc.setURL("jdbc:mysql://[host]:[port]/[database]");
mysqlDataSrc.setUser("USER_NAME");
mysqlDataSrc.setPassword("PASSWORD");cacheStoreFactory.setDataSource(mysqlDataSrc);personCacheCfg.setCacheStoreFactory(cacheStoreFactory);personCacheCfg.setWriteThrough(true);
personCacheCfg.setReadThrough(true);igniteCfg.setCacheConfiguration(personCacheCfg);
#2.3.加载数据
缓存存储配置完成并启动集群后,就可以使用下面的代码从数据库加载数据了:
// Load data from person table into PersonCache.
IgniteCache<Integer, Person> personCache = ignite.cache("PersonCache");personCache.loadCache(null);
#2.4.NoSQL数据库集成
通过实现CacheStore接口,可以将Ignite与任何NoSQL数据库集成。
警告
虽然Ignite支持分布式事务,但是并不会使NoSQL数据库具有事务性,除非数据库本身直接支持事务。
#2.4.1.Cassandra集成
Ignite通过CacheStore实现,直接支持将Apache Cassandra用作持久化存储。其利用Cassandra的异步查询来提供loadAll()、writeAll()和deleteAll()等高性能批处理操作,并自动在Cassandra中创建所有必要的表和命名空间。
具体请参见Cassandra集成章节的介绍。
#3.交换空间
#3.1.概述
如果使用纯内存存储,随着数据量的大小逐步达到物理内存大小,可能导致内存溢出。如果不想使用原生持久化或者外部存储,还可以开启交换,这时Ignite会将内存中的数据移动到磁盘上的交换空间,注意Ignite不会提供自己的交换空间实现,而是利用了操作系统(OS)提供的交换功能。
打开交换空间之后,Ignite会将数据存储在内存映射文件(MMF)中,操作系统会根据内存使用情况,将其内容交换到磁盘,但是这时数据访问的性能会下降。另外,还没有数据持久性保证,这意味着交换空间中的数据只在节点在线期间才可用。一旦存在交换空间的节点停止,所有数据都会丢失。因此,应该将交换空间作为内存的扩展,以留出足够的时间向集群中添加更多的节点让数据重新分布,并避免集群未及时扩容导致内存溢出的错误(OOM)发生。
注意
虽然交换空间位于磁盘上,但是其不能替代原生持久化。交换空间中的数据只有在节点在线时才有效,一旦节点关闭,数据将丢失。为了确保数据一直可用,应该启用原生持久化或使用外部存储。
#3.2.启用交换
数据区的maxSize定义了区域的整体最大值,如果数据量达到了maxSize,然后既没有使用原生持久化,也没有使用外部存储,那么就会抛出内存溢出异常。使用交换可以避免这种情况的发生,做法是:
- 配置
maxSize的值大于内存大小,这时操作系统就会使用交换; - 启用数据区的交换,如下所示。
- XML
- Java
- C#/.NET
// Node configuration.
IgniteConfiguration cfg = new IgniteConfiguration();// Durable Memory configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();// Creating a new data region.
DataRegionConfiguration regionCfg = new DataRegionConfiguration();// Region name.
regionCfg.setName("500MB_Region");// Setting initial RAM size.
regionCfg.setInitialSize(100L * 1024 * 1024);// Setting region max size equal to physical RAM size(5 GB)
regionCfg.setMaxSize(5L * 1024 * 1024 * 1024);// Enable swap space.
regionCfg.setSwapPath("/path/to/some/directory");// Setting the data region configuration.
storageCfg.setDataRegionConfigurations(regionCfg);// Applying the new configuration.
cfg.setDataStorageConfiguration(storageCfg);
#4.实现自定义CacheStore
可以实现自己的自定义CacheStore并将其作为缓存的底层数据存储,IgniteCache中读写数据的方法将会调用CacheStore实现中相应的方法。
下表描述了CacheStore接口中的方法:
| 方法 | 描述 |
|---|---|
loadCache() | 调用IgniteCache.loadCache(…)时,就会调用该方法,通常用于从数据库预加载数据。此方法在驻有缓存的所有节点上执行,要加载单个节点的数据,需要在该节点上调用IgniteCache.localLoadCache()方法。 |
load()、write()、delete() | 当调用IgniteCache接口的get()、put()、remove()方法时,会分别调用这3个方法,这些方法用于单条数据的通读和通写。 |
loadAll()、writeAll()、deleteAll() | 当调用IgniteCache接口的getAll()、putAll()、removeAll()方法时,会分别调用这3个方法,这些方法用于处理多条数据的通读和通写,通常以批量的形式实现以提高性能。 |
#4.1.CacheStoreAdapter
CacheStoreAdapter是CacheStore的扩展,提供了批量操作的默认实现,如loadAll(Iterable)、writeAll(Collection)和deleteAll(Collection),其会迭代所有条目并在每个条目上调用对应的load()、write()和delete()方法。
#4.2.CacheStoreSession
CacheStoreSession用于持有多个操作之间的上下文,主要用于提供事务支持。一个事务中的多个操作是在同一个数据库连接中执行的,并在事务提交时提交该连接。通过@GridCacheStoreSessionResource注解可以将其注入CacheStore实现中。
关于如何实现事务化的CacheStore,可以参见GitHub上的示例。
#4.3.示例
下面是一个CacheStore的非事务化实现的示例:
public class CacheJdbcPersonStore extends CacheStoreAdapter<Long, Person> {// This method is called whenever the "get(...)" methods are called on IgniteCache.@Overridepublic Person load(Long key) {try (Connection conn = connection()) {try (PreparedStatement st = conn.prepareStatement("select * from PERSON where id=?")) {st.setLong(1, key);ResultSet rs = st.executeQuery();return rs.next() ? new Person(rs.getInt(1), rs.getString(2)) : null;}} catch (SQLException e) {throw new CacheLoaderException("Failed to load: " + key, e);}}@Overridepublic void write(Entry<? extends Long, ? extends Person> entry) throws CacheWriterException {try (Connection conn = connection()) {// Syntax of MERGE statement is database specific and should be adopted for your database.// If your database does not support MERGE statement then use sequentially// update, insert statements.try (PreparedStatement st = conn.prepareStatement("merge into PERSON (id, name) key (id) VALUES (?, ?)")) {Person val = entry.getValue();st.setLong(1, entry.getKey());st.setString(2, val.getName());st.executeUpdate();}} catch (SQLException e) {throw new CacheWriterException("Failed to write entry (" + entry + ")", e);}}// This method is called whenever the "remove(...)" method are called on IgniteCache.@Overridepublic void delete(Object key) {try (Connection conn = connection()) {try (PreparedStatement st = conn.prepareStatement("delete from PERSON where id=?")) {st.setLong(1, (Long) key);st.executeUpdate();}} catch (SQLException e) {throw new CacheWriterException("Failed to delete: " + key, e);}}// This method is called whenever the "loadCache()" and "localLoadCache()"// methods are called on IgniteCache. It is used for bulk-loading the cache.// If you don't need to bulk-load the cache, skip this method.@Overridepublic void loadCache(IgniteBiInClosure<Long, Person> clo, Object... args) {if (args == null || args.length == 0 || args[0] == null)throw new CacheLoaderException("Expected entry count parameter is not provided.");final int entryCnt = (Integer) args[0];try (Connection conn = connection()) {try (PreparedStatement st = conn.prepareStatement("select * from PERSON")) {try (ResultSet rs = st.executeQuery()) {int cnt = 0;while (cnt < entryCnt && rs.next()) {Person person = new Person(rs.getInt(1), rs.getString(2));clo.apply(person.getId(), person);cnt++;}}}} catch (SQLException e) {throw new CacheLoaderException("Failed to load values from cache store.", e);}}// Open JDBC connection.private Connection connection() throws SQLException {// Open connection to your RDBMS systems (Oracle, MySQL, Postgres, DB2, Microsoft SQL, etc.)Connection conn = DriverManager.getConnection("jdbc:mysql://[host]:[port]/[database]", "YOUR_USER_NAME", "YOUR_PASSWORD");conn.setAutoCommit(true);return conn;}
}
#5.集群快照
#5.1.概述
对于开启了原生持久化的集群,Ignite提供了创建集群完整快照的功能。一个Ignite快照包括了整个集群中所有存盘数据的完整一致副本,以及用于恢复过程必需的其他一些文件。
快照的结构除了一些例外,类似于Ignite原生持久化存储目录的布局,以下面的快照为例,看一下结构:
work
└── snapshots└── backup23012020└── db├── binary_meta│ ├── node1│ ├── node2│ └── node3├── marshaller│ ├── node1│ ├── node2│ └── node3├── node1│ └── my-sample-cache│ ├── cache_data.dat│ ├── part-3.bin│ ├── part-4.bin│ └── part-6.bin├── node2│ └── my-sample-cache│ ├── cache_data.dat│ ├── part-1.bin│ ├── part-5.bin│ └── part-7.bin└── node3└── my-sample-cache├── cache_data.dat├── part-0.bin└── part-2.bin
- 快照位于
work\snapshots目录下,名为backup23012020,这里work是Ignite的工作目录; - 创建快照的集群有3个节点,所有节点都在同一台主机上运行。在此示例中,节点分别名为
node1、node2和node3,而实际上,它们的名字是节点的一致性ID; - 快照保留了
my-sample-cache缓存的副本; db文件夹在part-N.bin和cache_data.dat文件中保留数据记录的副本。预写日志和检查点不在快照中,因为这些在当前的恢复过程中并不需要;binary_meta和marshaller目录存储了和元数据和编组器有关的信息。
通常快照分布于整个集群
上面的示例显示为同一个集群创建的快照运行于同一台物理机,因此整个快照位于一个位置上。实际上,集群中不同主机的所有节点上都会有快照数据。每个节点都持有快照的一段,即归属于该节点的数据快照,恢复过程会说明恢复时如何将所有段合并在一起。
#5.2.配置快照目录
快照默认存储在相应Ignite节点的工作目录中,并和Ignite持久化保存数据、索引、WAL和其他文件使用相同的存储介质。因为快照消耗了和持久化相当的空间,然后和Ignite持久化进程共享磁盘IO,从而会影响应用的性能,因此建议将快照和持久化文件存储在不同的存储介质上。
可以通过更改持久化文件的存储目录或覆盖快照的默认位置来避免Ignite原生持久化和快照之间的这种干扰,如下所示:
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();File exSnpDir = U.resolveWorkDirectory(U.defaultWorkDirectory(), "ex_snapshots", true);cfg.setSnapshotPath(exSnpDir.getAbsolutePath());
#5.3.创建快照
Ignite提供了几个API来进行快照的创建,下面看下所有的选项:
#5.3.1.使用控制脚本
Ignite自带的控制脚本支持和快照有关的操作,如下所示:
#Create a cluster snapshot:
control.(sh|bat) --snapshot create snapshot_name#Cancel a running snapshot:
control.(sh|bat) --snapshot cancel snapshot_name#Kill a running snapshot:
control.(sh|bat) --kill SNAPSHOT snapshot_name
#5.3.2.使用JMX
使用SnapshotMXBean接口,可以通过JMX执行和快照有关的过程:
| 方法 | 描述 |
|---|---|
createSnapshot(String snpName) | 创建快照 |
createSnapshot(String snpName) | 在创建快照的发起节点取消快照 |
#5.3.3.使用Java API
也可以通过Java API通过编程式创建快照:
CacheConfiguration<Long, String> ccfg = new CacheConfiguration<Long, String>("snapshot-cache");try (IgniteCache<Long, String> cache = ignite.getOrCreateCache(ccfg)) {cache.put(1, "Maxim");// Start snapshot operation.ignite.snapshot().createSnapshot("snapshot_02092020").get();
}
finally {ignite.destroyCache(ccfg);
}
#5.4.从快照恢复
当前,数据恢复过程必须手动执行。简而言之,需要停止集群,用快照中的数据替换持久化数据和其他文件,然后重启节点。
详细过程如下:
- 停止要恢复的集群;
- 从检查点目录
$IGNITE_HOME/work/cp中删除所有文件; - 在每个节点上执行以下操作,单独清理
db/{node_id}目录,如果他不在Ignite的work目录下:- 从
$IGNITE_HOME/work/db/binary_meta目录中删除和{nodeId}有关的文件; - 从
$IGNITE_HOME/work/db/marshaller目录中删除和{nodeId}有关的文件; - 从
$IGNITE_HOME/work/db目录中删除和{nodeId}有关的文件和子目录; - 将快照中属于
{node_id}节点的文件复制到$IGNITE_HOME/work/目录中。如果db/{node_id}目录不在Ignite的工作目录下,则应在对应目录复制数据文件。
- 从
- 重启集群。
在不同拓扑的集群上恢复
有时可能在N个节点的集群上创建快照,但是需要在有M个节点的集群上进行恢复,下表说明了支持的选项:
| 条件 | 描述 |
|---|---|
N==M | 建议方案,在拓扑一致的集群上创建和使用快照。 |
N<M | 在M个节点的集群上首先启动N个节点,应用快照,然后将剩余的M-N个集群节点加入拓扑,然后等待数据再平衡和索引重建。 |
N>M | 不支持。 |
#5.5.一致性保证
在Ignite的持久化文件、索引、模式、二进制元数据、编组器以及节点的其他文件上的并发操作以及正在进行的修改,所有的快照都是完全一致的。
集群范围的快照一致性是通过触发分区映射交换过程实现的,通过这样做,集群最终达到的状态是所有之前发起的事务全部完成,新的事务全部暂停,这个过程结束之后,集群就会发起快照创建过程,PME过程会确保快照以一致的状态包括了主快照和备份快照。
Ignite持久化文件与其快照副本之间的一致性是通过将原始文件复制到目标快照目录并跟踪所有正在进行的更改来实现的,跟踪更改可能需要额外的空间。
#5.6.当前的限制
快照过程有若干限制,如果要用于生产环境需要事先了解:
- 不支持某个表/缓存的快照,只能创建整个集群的快照;
- 未开启原生持久化的表/缓存,不支持快照;
- 加密的缓存不包括在快照中;
- 同时只能执行一个快照操作;
- 如果一个服务端节点离开集群,快照过程会被中断;
- 快照只能在具有相同节点ID的同一集群拓扑中恢复;
- 目前还不支持自动化的恢复过程,只能手工执行。
#6.磁盘压缩
磁盘压缩是指将数据页面写入磁盘时对其进行压缩的过程,以减小磁盘空间占用。这些页面在内存中是不压缩的,但是当将数据刷新到磁盘时,将使用配置的算法对其进行压缩。这仅适用于开启原生持久化的数据页面并且不会压缩索引或WAL记录的数据页,WAL记录压缩是可以单独启用的。
磁盘页面压缩是在每个缓存的配置中设定的,缓存必须在持久化的数据区中。目前没有选项可全局启用磁盘页面压缩,此外,还必须必须满足以下的条件:
- 将持久化配置中的
pageSize属性设置为文件系统页面大小的至少2倍,这意味着页面大小必须为8K或16K; - 启用
ignite-compress模块。
要为某个缓存启用磁盘页面压缩,需要在缓存配置中提供一种可用的压缩算法,如下所示:
- XML
- Java
DataStorageConfiguration dsCfg = new DataStorageConfiguration();//set the page size to 2 types of the disk page size
dsCfg.setPageSize(4096 * 2);//enable persistence for the default data region
dsCfg.setDefaultDataRegionConfiguration(new DataRegionConfiguration().setPersistenceEnabled(true));IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setDataStorageConfiguration(dsCfg);CacheConfiguration cacheCfg = new CacheConfiguration("myCache");
//enable disk page compression for this cache
cacheCfg.setDiskPageCompression(DiskPageCompression.LZ4);
//optionally set the compression level
cacheCfg.setDiskPageCompressionLevel(10);cfg.setCacheConfiguration(cacheCfg);Ignite ignite = Ignition.start(cfg);
#6.1.支持的算法
支持的压缩算法包括:
ZSTD:支持从-131072到22的压缩级别(默认值:3);LZ4:支持从0到17的压缩级别(默认值:0);SNAPPYSKIP_GARBAGE:该算法仅从半填充页面中提取有用的数据,而不压缩数据。
#7.持久化调优
本章节总结了Ignite原生持久化调优的最佳实践。
#7.1.调整页面大小
Ignite的页面大小(DataStorageConfiguration.pageSize)不要小于存储设备(SSD、闪存、HDD等)的页面大小以及操作系统缓存页面的大小,默认值为4KB。
操作系统的缓存页面大小很容易就可以通过系统工具和参数获取到。
存储设备比如SSD的页面大小可以在设备的说明上找到,如果厂商未提供这些信息,可以运行SSD的基准测试来算出这个数值,如果还是难以拿到这个数值,可以使用4KB作为Ignite的页面大小。很多厂商为了适应4KB的随机写工作负载不得不调整驱动,因为很多标准基准测试都是默认使用4KB,来自英特尔的白皮书也确认4KB足够了。
选定最优值之后,可以将其用于集群的配置:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();// Durable memory configuration.
DataStorageConfiguration storageCfg = new DataStorageConfiguration();// Changing the page size to 8 KB.
storageCfg.setPageSize(8192);cfg.setDataStorageConfiguration(storageCfg);
#7.2.单独保存WAL
考虑为数据文件以及预写日志(WAL)使用单独的磁盘设备。Ignite会主动地写入数据文件以及WAL文件,下面的示例会显示如何为数据存储、WAL以及WAL存档配置单独的路径:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Native Persistence.
DataStorageConfiguration storeCfg = new DataStorageConfiguration();// Sets a path to the root directory where data and indexes are to be persisted.
// It's assumed the directory is on a separated SSD.
storeCfg.setStoragePath("/ssd/storage");// Sets a path to the directory where WAL is stored.
// It's assumed the directory is on a separated HDD.
storeCfg.setWalPath("/wal");// Sets a path to the directory where WAL archive is stored.
// The directory is on the same HDD as the WAL.
storeCfg.setWalArchivePath("/wal/archive");cfg.setDataStorageConfiguration(storeCfg);// Starting the node.
Ignite ignite = Ignition.start(cfg);
#7.3.增加WAL段大小
WAL段的默认大小(64MB)在高负载情况下可能是低效的,因为它导致WAL在段之间频繁切换,并且切换/轮转是昂贵的操作。将段大小设置为较大的值(最多2GB)可能有助于减少切换操作的次数,不过这将增加预写日志的占用空间。
具体请参见修改WAL段大小。
#7.4.调整WAL模式
考虑其它WAL模式替代默认模式。每种模式在节点故障时提供不同程度的可靠性,并且可靠性与速度成反比,即,WAL模式越可靠,则速度越慢。因此,如果具体业务不需要高可靠性,那么可以切换到可靠性较低的模式。
具体可以看WAL模式的相关内容。
#7.5.禁用WAL
有时禁用WAL也会改进性能。
#7.6.页面写入限流
Ignite会定期地启动检查点进程,以在内存和磁盘间同步脏页面。脏页面是已在内存中更新但是还未写入对应的分区文件的页面(更新只是添加到了WAL)。这个进程在后台进行,对应用没有影响。
但是,如果计划进行检查点的脏页面在写入磁盘前被更新,它之前的状态会被复制进某个区域,叫做检查点缓冲区。如果这个缓冲区溢出,那么在检查点处理过程中,Ignite会停止所有的更新。因此,写入性能可能降为0,直至检查点过程完成,如下图所示:
当检查点处理正在进行中时,如果脏页面数达到阈值,同样的情况也会发生,这会使Ignite强制安排一个新的检查点执行,并停止所有的更新操作直到第一个检查点执行完成。
当磁盘较慢或者更新过于频繁时,这两种情况都会发生,要减少或者防止这样的性能下降,可以考虑启用页面写入限流算法。这个算法会在检查点缓冲区填充过快或者脏页面占比过高时,将更新操作的性能降低到磁盘的速度。
页面写入限流剖析
要了解更多的信息,可以看相关的Wiki页面。
下面的示例显示了如何开启页面写入限流:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Native Persistence.
DataStorageConfiguration storeCfg = new DataStorageConfiguration();// Enabling the writes throttling.
storeCfg.setWriteThrottlingEnabled(true);cfg.setDataStorageConfiguration(storeCfg);
// Starting the node.
Ignite ignite = Ignition.start(cfg);
#7.7.调整检查点缓冲区大小
前述章节中描述的检查点缓冲区大小,是检查点处理的触发器之一。
缓冲区的默认大小是根据数据区大小计算的。
| 数据区大小 | 默认检查点缓冲区大小 |
|---|---|
< 1GB | MIN (256 MB, 数据区大小) |
1GB ~ 8GB | 数据区大小/4 |
> 8GB | 2GB |
默认的缓冲区大小并没有为写密集型应用进行优化,因为在大小接近标称值时,页面写入限流算法会降低写入的性能,因此在正在进行检查点处理时还希望保持写入性能,可以考虑增加DataRegionConfiguration.checkpointPageBufferSize,并且开启写入限流来阻止性能的下降:
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();// Configuring Native Persistence.
DataStorageConfiguration storeCfg = new DataStorageConfiguration();// Enabling the writes throttling.
storeCfg.setWriteThrottlingEnabled(true);// Increasing the buffer size to 1 GB.
storeCfg.getDefaultDataRegionConfiguration().setCheckpointPageBufferSize(1024L * 1024 * 1024);cfg.setDataStorageConfiguration(storeCfg);// Starting the node.
Ignite ignite = Ignition.start(cfg);
在上例中,默认数据区的检查点缓冲区大小配置为1GB。
#7.8.启用直接I/O
通常当应用访问磁盘上的数据时,操作系统拿到数据后会将其写入一个文件缓冲区缓存,写操作也是同样,操作系统首先将数据写入缓存,然后才会传输到磁盘,要消除这个过程,可以打开直接IO,这时数据会忽略文件缓冲区缓存,直接从磁盘进行读写。
Ignite中的直接I/O插件用于加速检查点进程,它的作用是将内存中的脏页面写入磁盘,建议将直接IO插件用于写密集型负载环境中。
注意
注意,无法专门为WAL文件开启直接I/O,但是开启直接I/O可以为WAL文件带来一点好处,就是WAL数据不会在操作系统的缓冲区缓存中存储过长时间,它会在下一次页面缓存扫描中被刷新(依赖于WAL模式),然后从页面缓存中删除。
要启用直接I/O插件,需要在二进制包中将{IGNITE_HOME}/libs/optional/ignite-direct-io文件夹上移一层至libs/optional/ignite-direct-io文件夹,或者也可以作为一个Maven构件引入,具体请参见这里的介绍。
通过IGNITE_DIRECT_IO_ENABLED系统属性,也可以在运行时启用/禁用该插件。
相关的Wiki页面有更多的细节。
#7.9.购买产品级SSD
限于SSD的操作特性,在经历几个小时的高强度写入负载之后,Ignite原生持久化的性能可能会下降,因此需要考虑购买快速的产品级SSD来保证高性能,或者切换到非易失性内存设备比如Intel Optane持久化内存。
#7.10.SSD预留空间
由于SSD预留空间的原因,50%使用率的磁盘的随机写性能要好于90%使用率的磁盘,因此需要考虑购买高预留空间比率的SSD,然后还要确保厂商能提供工具来进行相关的调整。
Intel 3D XPoint
考虑使用3D XPoint驱动器代替常规SSD,以避免由SSD级别上的低预留空间设置和恒定垃圾收集造成的瓶颈。具体可以看这里。
配置缓存
#1.缓存配置
本章节介绍如何设定缓存的配置参数,缓存创建之后,这些参数将无法修改。
Ignite中的缓存和表
缓存驱动的配置方式是配置选项之一,还可以使用CREATE TABLE这样的标准SQL命令来配置缓存/表,具体请参见键-值缓存与SQL表章节的内容以了解Ignite中缓存和表的关系。
#1.1.配置示例
下面是缓存配置的示例:
- XML
- Java
- C#/.NET
- SQL
CacheConfiguration cacheCfg = new CacheConfiguration("myCache");cacheCfg.setCacheMode(CacheMode.PARTITIONED);
cacheCfg.setBackups(2);
cacheCfg.setRebalanceMode(CacheRebalanceMode.SYNC);
cacheCfg.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC);
cacheCfg.setPartitionLossPolicy(PartitionLossPolicy.READ_ONLY_SAFE);IgniteConfiguration cfg = new IgniteConfiguration();
cfg.setCacheConfiguration(cacheCfg);// Start a node.
Ignition.start(cfg);
完整的参数列表,请参见CacheConfiguration的javadoc。
| 参数 | 描述 | 默认值 |
|---|---|---|
name | 缓存名 | |
cacheMode | 该参数定义了数据在集群中的分布方式。在默认的PARTITIONED模式中,整体数据集被拆分为分区,然后所有的分区再以平衡的方式分布于相关的节点上。而在REPLICATED模式中,所有的数据在所有的节点上都复制一份,具体请参见分区/复制模式章节的介绍。 | PARTITIONED |
writeSynchronizationMode | 写同步模式,具体请参见配置分区备份章节的内容。 | PRIMARY_SYNC |
rebalanceMode | 该参数控制再平衡过程的执行方式。可选值包括:SYNC:所有缓存操作都会被阻塞直到再平衡结束;ASYNC:再平衡在后台执行;NONE:再平衡不会被触发。 | ASYNC |
backups | 缓存的备份分区数量。 | 0 |
partitionLossPolicy | 分区丢失策略 | IGNORE |
readFromBackup | 如果本地的备份分区可用,则从备份分区读取数据,而不是向主分区请求数据(可能位于远程节点)。 | true |
queryPrallelism | 单节点在缓存上执行SQL查询的线程数,具体请参见性能优化的查询并行度相关章节的内容。 | 1 |
#1.2.缓存模板
缓存模板是在集群中注册的CacheConfiguration实例,然后用作后续创建新缓存或SQL表的基础,一个从模板创建的缓存或表会继承该模板的所有属性。
当使用CREATE TABLE命令建表时,模板非常有用,因为该命令并不支持所有的缓存参数。
提示
当前,CREATE TABLE和REST命令支持模板。
创建模板时,需要定义一个缓存配置然后将其加入Ignite实例中,如下所示。如果希望在XML配置文件中定义缓存模板,需要在模板名后面加一个*号,这个是用于标示该配置是一个模板而不是实际的缓存。
- XML
- Java
- C#/.NET
IgniteConfiguration igniteCfg = new IgniteConfiguration();try (Ignite ignite = Ignition.start(igniteCfg)) {CacheConfiguration cacheCfg = new CacheConfiguration("myCacheTemplate");cacheCfg.setBackups(2);cacheCfg.setCacheMode(CacheMode.PARTITIONED);// Register the cache templateignite.addCacheConfiguration(cacheCfg);
}
缓存模板在集群中注册之后,就可以用相同的配置创建其他缓存了。
#2.配置分区备份
Ignite默认为每个分区持有一个副本(整个数据集的一个副本),这时如果一个或者多个节点故障,存储于这些节点上的分区就会丢失,为了避免这种情况,可以配置Ignite维护分区的备份副本。
提示
备份默认是禁用的。
备份副本是缓存(表)级的配置,如果配置了2个备份副本,集群会为每个分区维护3个副本。其中一个分区称为主分区,其他2个称为备份分区。扩展来说,具有主分区的节点称为该分区中存储的数据的主节点,备份分区对应的节点称为备份节点。
当某些数据对应的主分区所在的节点离开集群,Ignite会触发分区映射交换(PME)过程,PME会标记这些数据对应的某个已配置的备份分区为主分区。
备份分区增加了数据的可用性和某些场景的数据读取速度,因为如果本地节点的备份分区可用,Ignite会从备份分区读取数据(这是默认的行为,但是可以禁用)。但是增加了内存的消耗或者持久化存储的大小(如果开启)。
#2.1.配置备份
在缓存配置中配置backups属性,可以配置备份副本的数量。
- XML
- Java
- C#/.NET
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");
cacheCfg.setCacheMode(CacheMode.PARTITIONED);
cacheCfg.setBackups(1);IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);// Start the node.
Ignite ignite = Ignition.start(cfg);
#2.2.同步和异步备份
通过指定写同步模式,可以配置更新在主备副本之间是同步模式还是异步模式,如下所示:
- XML
- Java
- C#/.NET
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");
cacheCfg.setBackups(1);
cacheCfg.setWriteSynchronizationMode(CacheWriteSynchronizationMode.FULL_SYNC);
IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);// Start the node.
Ignition.start(cfg);
写同步模式有如下的可选值:
| 值 | 描述 |
|---|---|
FULL_SYNC | 客户端节点会等待所有相关的远程节点(主和备)写入或者提交完成。 |
FULL_ASYNC | 客户端节点不会等待来自相关节点的响应,这时远程节点会在缓存写入或者事务提交方法完成之后稍晚些收到状态更新。 |
PRIMARY_SYNC | 默认模式,客户端节点会等待主节点的写入或者提交完成,但是不会等待备份的更新。 |
#3.分区丢失策略
在整个集群的生命周期中,由于分区的主节点和备份节点的故障可能出现分区丢失的情况,这会导致部分数据丢失,需要根据场景进行处理。
当一个分区的主副本和所有备份副本均不在线,即该分区的主节点和备份节点全部故障时,该分区将丢失。这意味着对于给定的缓存,能承受的节点故障数不能超过缓存备份数。
当集群拓扑发生变更时,Ignite会检查变更是否导致分区丢失,并根据配置的分区丢失策略和基线自动调整设置,允许或禁止对缓存进行操作,具体请参见下一章节的介绍。
对于纯内存缓存,当分区丢失时,除非数据重新加载,否则分区中的数据将无法恢复。对于持久化缓存,数据不会物理丢失,因为它已被持久化到磁盘上。当发生故障或断开连接的节点回到集群时(重启后),将从磁盘上加载数据。这时需要重置丢失的分区的状态才能继续使用数据,具体请参见处理分区丢失章节的介绍。
#3.1.配置分区丢失策略
Ignite支持以下的分区丢失策略:
| 策略 | 描述 |
|---|---|
IGNORE | 分区丢失将被忽略。集群将丢失的分区视为空分区。当请求该分区的数据时,将返回空值,就好像数据从不存在一样。此策略只能在纯内存集群中使用且是默认值,这个模式中启用了基线自动调整且超时为0。在所有其他配置(集群中只要有一个数据区开启了持久化)中,IGNORE策略都会被READ_WRITE_SAFE替代,即使在缓存配置中显式指定也不行。 |
READ_WRITE_SAFE | 缓存丢失分区的读写尝试都会抛出异常,但是在线分区的读写是正常的。 |
READ_ONLY_SAFE | 缓存处于只读状态,缓存的写操作会抛出异常,丢失分区的读操作也会抛出异常,具体请参见处理分区丢失章节的介绍。 |
分区丢失策略是缓存级的配置。
- XML
- Java
CacheConfiguration cacheCfg = new CacheConfiguration("myCache");cacheCfg.setPartitionLossPolicy(PartitionLossPolicy.READ_ONLY_SAFE);
#3.2.监听分区丢失事件
当发生分区丢失时,可以监听EVT_CACHE_REBALANCE_PART_DATA_LOST事件的通知。每个丢失的分区都会触发该事件,其包含了丢失的分区号以及持有该分区的节点ID。只有使用READ_WRITE_SAFE或READ_ONLY_SAFE策略时,才会触发分区丢失事件。
首先需要在集群的配置中启用事件,具体参见启用事件的介绍。
Ignite ignite = Ignition.start();IgnitePredicate<Event> locLsnr = evt -> {CacheRebalancingEvent cacheEvt = (CacheRebalancingEvent) evt;int lostPart = cacheEvt.partition();ClusterNode node = cacheEvt.discoveryNode();System.out.println(lostPart);return true; // Continue listening.
};ignite.events().localListen(locLsnr, EventType.EVT_CACHE_REBALANCE_PART_DATA_LOST);
关于其他和分区再平衡有关的事件,可以参见分区再平衡事件章节的介绍。
#3.3.处理分区丢失
如果数据没有物理丢失,可以将该节点恢复然后重置丢失分区的状态,这样就可以继续处理该数据,通过控制脚本,或者在特定的缓存上调用Ignite.resetLostPartitions(cacheNames),可以重置分区的状态。
ignite.resetLostPartitions(Arrays.asList("myCache"));
控制脚本命令为:
control.sh --cache reset_lost_partitions myCache
如果不重置丢失的分区,根据缓存策略的配置,从丢失分区的读写操作可能会抛出CacheException,通过分析上层的触发原因,可以检查该异常是否由分区状态导致:
IgniteCache<Integer, Integer> cache = ignite.cache("myCache");try {Integer value = cache.get(3);System.out.println(value);
} catch (CacheException e) {if (e.getCause() instanceof CacheInvalidStateException) {System.out.println(e.getCause().getMessage());} else {e.printStackTrace();}
}
通过IgniteCache.lostPartitions(),可以拿到缓存丢失分区的列表:
IgniteCache<Integer, String> cache = ignite.cache("myCache");cache.lostPartitions();
#3.4.从丢失分区中恢复
下面的章节会介绍根据集群的不同配置,如何从分区丢失中恢复。
#3.4.1.IGNORE策略的纯内存集群
在此配置中,该IGNORE策略仅适用于启用基线自动调整且超时为0的场景,这也是纯内存集群的默认设置。这时将忽略分区丢失,缓存仍然可以操作,丢失的分区会被视为空分区。
当禁用基线自动调整或超时时间大于0时,IGNORE策略会被替换为READ_WRITE_SAFE。
#3.4.2.READ_WRITE_SAFE或READ_ONLY_SAFE策略的纯内存集群
重置丢失的分区之前,对缓存的操作将被阻止。重置后,缓存可以继续使用,但是数据将丢失。
禁用基线自动调整或超时大于0时,必须在重置丢失的分区之前将节点(每个分区至少一个分区所有者)恢复到基线拓扑。否则,Ignite.resetLostPartitions(cacheNames)会抛出一个消息为Cannot reset lost partitions because no baseline nodes are online [cache=someCahe, partition=someLostPart]的ClusterTopologyCheckedException,表明无法安全恢复。如果由于某种原因(例如硬件故障)而无法恢复节点,需要在重置丢失的分区之前将它们从基线拓扑中手动删除。
#3.4.3.开启持久化的集群
如果所有的数据区都开启了持久化(没有纯内存数据区),那么有两种从丢失分区中恢复的方式(只要数据没有物理损坏):
- 让所有的节点返回到基线;
- 重置丢失的分区(所有的缓存调用
Ignite.resetLostPartitions(…))。
或者:
- 停止所有的节点;
- 启动包括故障节点在内的所有节点,然后激活集群。
如果某些节点无法返回,在尝试重置丢失分区状态前,需要将他们从基线拓扑中删除。
#3.4.4.同时有纯内存和持久化缓存的集群
如果集群同时有纯内存的数据区和持久化的数据区,那么纯内存的缓存会和配置为READ_WRITE_SAFE的纯内存集群的处理方式一致,而持久化的缓存会和持久化的集群的处理方式一致。
#4.原子化模式
缓存默认仅支持原子操作,而批量操作(例如putAll()或removeAll())则按顺序单独执行写入和删除。但是也可以启用事务支持并将一个或多个缓存操作,可能对应一个或者多个键,分组为单个原子事务。这些操作在没有任何其他交叉操作的情况下执行,或全部成功或全部失败,没有部分成功的状态。
要启用缓存的事务支持,需要将缓存配置中的atomicityMode参数设置为TRANSACTIONAL。
警告
如果在一个缓存组中配置了多个缓存,这些缓存的原子化模式应全部相同,不能有的是TRANSACTIONAL,有的是ATOMIC。
Ignite支持3种原子化模式,如下表所示:
| 原子化模式 | 描述 |
|---|---|
ATOMIC | 默认模式,所有操作都会原子化地执行,一次一个,不支持事务。ATOMIC模式通过避免事务锁,提供了最好的性能,同时为每个单个操作提供了数据原子性和一致性。比如putAll(…)以及removeAll(…)方法这样的批量操作,并不以事务方式执行,可能部分失败,如果发生了这种情况,会抛出CachePartialUpdateException异常,其中包含了更新失败的键列表。 |
TRANSACTIONAL | 在键-值API层面开启了符合ACID的事务支持,但是SQL不支持事务。该模式的事务支持不同的并发模型和隔离级别。如果确实需要符合ACID操作才建议开启这个模式,因为事务会导致性能下降。具体请参见执行事务。 |
TRANSACTIONAL_SNAPSHOT | 多版本并发控制(MVCC)的试验性实现。其同时支持键-值事务和SQL事务,更多的信息以及限制,请参见多版本并发控制。**注意:**MVCC实现目前还处于测试阶段,不建议用于生产。 |
可以在缓存配置中为缓存开启事务支持:
- XML
- Java
- C#/.NET
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");cacheCfg.setAtomicityMode(CacheAtomicityMode.TRANSACTIONAL);IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);// Optional transaction configuration. Configure TM lookup here.
TransactionConfiguration txCfg = new TransactionConfiguration();cfg.setTransactionConfiguration(txCfg);// Start a node
Ignition.start(cfg);
#5.过期策略
#5.1.概述
过期策略指定了在缓存条目过期之前必须经过的时间量,时间可以从创建、最后访问或者修改时间开始计算。
根据内存配置,过期策略将从内存或磁盘上删除条目:
- 内存模式:数据仅保存在内存中,过期的条目会完全从内存中清除;
- 内存+Ignite持久化:过期的条目会完全从内存和磁盘上删除,注意过期策略会从磁盘上的分区文件中删除数据,但是不会释放空间,该空间会在后续的数据写入中重用;
- 内存+外部存储:过期的条目仅仅从内存(Ignite)中删除,外部存储(RDBMS、NoSQL以及其它数据库)中的数据会保持不变;
- 内存+交换空间:过期的条目会同时从内存和交换空间中删除。
过期策略可以通过任何标准的javax.cache.expiry.ExpiryPolicy实现或自定义实现进行设置:
#5.2.配置
下面是过期策略的配置示例:
- XML
- Java
- C#/.NET
CacheConfiguration<Integer, String> cfg = new CacheConfiguration<Integer, String>();
cfg.setName("myCache");
cfg.setExpiryPolicyFactory(CreatedExpiryPolicy.factoryOf(Duration.FIVE_MINUTES));
也可以为单独的缓存操作配置或者修改过期策略,该策略会影响返回的缓存实例上调用的每个操作:
CacheConfiguration<Integer, String> cacheCfg = new CacheConfiguration<Integer, String>("myCache");ignite.createCache(cacheCfg);IgniteCache cache = ignite.cache("myCache").withExpiryPolicy(new CreatedExpiryPolicy(new Duration(TimeUnit.MINUTES, 5)));// if the cache does not contain key 1, the entry will expire after 5 minutes
cache.put(1, "first value");
#5.3.Eager TTL(热生存时间)
过期的条目从缓存中删除,既可以马上删除,也可以在缓存操作对其访问时再删除。只要有一个缓存启用了热生存时间,Ignite就会创建一个线程在后台清理过期的数据。
如果该属性配置为false,过期的条目不会被马上删除,而是在执行缓存操作时由执行该操作的线程将其删除。
热生存时间可以通过CacheConfiguration.eagerTtl属性启用或者禁用(默认值是true)。
- XML
- Java
- C#/.NET
CacheConfiguration<Integer, String> cfg = new CacheConfiguration<Integer, String>();
cfg.setName("myCache");cfg.setEagerTtl(true);
#6.堆内缓存
Ignite在Java堆外部使用堆外内存来分配数据区,但是可以通过配置CacheConfiguration.setOnheapCacheEnabled(true)来开启堆内缓存。
对于在使用二进制形式的缓存条目或调用缓存条目的反序列化的服务器节点上进行大量缓存读取的场景,堆内缓存很有用。例如,当分布式计算或部署的服务从缓存中获取数据进行进一步处理时,可能会发生这种情况。
- XML
- Java
- C#/.NET
CacheConfiguration cfg = new CacheConfiguration();
cfg.setName("myCache");
cfg.setOnheapCacheEnabled(true);
#6.1.配置退出策略
启用堆内缓存后,可以使用堆内缓存退出策略来管理不断增长的堆内缓存。
退出策略控制缓存的堆内存中可以存储的最大数据量,当到达最大值后,条目会从Java堆中退出。
提示
堆内退出策略只会从Java堆中删除缓存条目,堆外数据区中存储的数据不受影响。
退出策略支持基于批次的退出和基于内存大小限制的退出。如果开启了基于批次的退出,那么当缓存的数量比缓存最大值多出batchSize个条目时,退出就开始了,这时batchSize个条目就会被退出。如果开启了基于内存大小限制的退出,那么当缓存条目的大小(字节数)大于最大值时,退出就会被触发。
注意
只有未配置最大内存限制时,才会支持基于批次的退出。
Ignite中退出策略是可插拔的,可以通过EvictionPolicy接口进行控制,退出策略的实现定义了从堆内缓存选择待退出条目的算法,然后当缓存发生改变时就会收到通知。
#6.1.1.最近最少使用(LRU)
LRU退出策略基于最近最少使用算法,它会确保最近最少使用的数据(即最久没有被访问的数据)会被首先退出。
注意
LRU退出策略适用于堆内缓存的大多数使用场景,不确定时可以优先使用。
这个退出策略通过CacheConfiguration进行配置,支持基于批次的退出以及基于内存大小限制的退出,如下所示:
- XML
- Java
- C#/.NET
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");// Enabling on-heap caching for this distributed cache.
cacheCfg.setOnheapCacheEnabled(true);// Set the maximum cache size to 1 million (default is 100,000).
cacheCfg.setEvictionPolicyFactory(() -> new LruEvictionPolicy(1000000));IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);
#6.1.2.先进先出(FIFO)
FIFO退出策略基于先进先出(FIFO)算法,它确保缓存中保存时间最久的数据会被首先退出,它与LruEvictionPolicy不同,因为它忽略了数据的访问顺序。
这个策略通过CacheConfiguration进行配置,支持基于批次的退出以及基于内存大小限制的退出。
- XML
- Java
- C#/.NET
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");// Enabling on-heap caching for this distributed cache.
cacheCfg.setOnheapCacheEnabled(true);// Set the maximum cache size to 1 million (default is 100,000).
cacheCfg.setEvictionPolicyFactory(() -> new FifoEvictionPolicy(1000000));IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);
#6.1.3.有序
有序退出策略和FIFO退出策略很像,不同点在于通过默认或者用户定义的比较器定义了数据的顺序,然后确保最小的数据(即排序数值最小的数据)会被退出。
默认的比较器用缓存条目的键作为比较器,它要求键必须实现Comparable接口。也可以提供自定义的比较器实现,可以通过键,值或者两者都用来进行条目的比较。
这个策略通过CacheConfiguration进行配置,支持基于批次的退出以及基于内存大小限制的退出。
- XML
- Java
CacheConfiguration cacheCfg = new CacheConfiguration();cacheCfg.setName("cacheName");// Enabling on-heap caching for this distributed cache.
cacheCfg.setOnheapCacheEnabled(true);// Set the maximum cache size to 1 million (default is 100,000).
cacheCfg.setEvictionPolicyFactory(() -> new SortedEvictionPolicy(1000000));IgniteConfiguration cfg = new IgniteConfiguration();cfg.setCacheConfiguration(cacheCfg);
#7.缓存组
对于集群中的缓存来说,总有一个开销,即缓存被拆分为分区后其状态必须在每个集群节点上进行跟踪以满足系统的需要。
如果开启了Ignite的原生持久化,那么对于每个分区来说,都会在磁盘上打开一个文件进行读写,因此,如果有更多的缓存和分区:
- 分区映射就会占用更多的Java堆,每个缓存都有自己的分区映射;
- 新节点加入集群就会花费更多的时间;
- 节点离开集群也会因为再平衡花费更多的时间;
- 打开中的分区文件就会更多从而影响检查点的性能。
通常,如果只有几十甚至几百个缓存时,不用担心这些问题,但是如果增长到上千时,这类问题就会凸显。
要避免这个影响,可以考虑使用缓存组,一个组内的缓存会共享各种内部数据结构比如上面提到的分区映射,这样,会提高拓扑事件处理的效率以及降低整体的内存使用量。注意,从API上来看,缓存是不是组的一部分并没有什么区别。
通过配置CacheConfiguration的groupName属性可以创建一个缓存组,示例如下:
- XML
- Java
- C#/.NET
// Defining cluster configuration.
IgniteConfiguration cfg = new IgniteConfiguration();// Defining Person cache configuration.
CacheConfiguration<Integer, Person> personCfg = new CacheConfiguration<Integer, Person>("Person");personCfg.setBackups(1);// Group the cache belongs to.
personCfg.setGroupName("group1");// Defining Organization cache configuration.
CacheConfiguration orgCfg = new CacheConfiguration("Organization");orgCfg.setBackups(1);// Group the cache belongs to.
orgCfg.setGroupName("group1");cfg.setCacheConfiguration(personCfg, orgCfg);// Starting the node.
Ignition.start(cfg);
在上面的示例中,Person和Organization缓存都属于group1。
如何区分键-值对
如果将缓存分配给一个缓存组,则其数据存储在共享分区的内部结构中。写入缓存的每个键都会附加其所属的缓存的唯一ID。该ID是从缓存名派生的。这些都是透明的,并允许将不同缓存的数据存储在相同的分区和B+树结构中。
对缓存进行分组的原因很简单,如果决定对1000个缓存进行分组,则存储分区数据、分区映射和打开分区文件的结构将减少为原来的千分之一。
缓存组是否应一直使用?
虽然有这么多的好处,但是它可能影响读操作和索引的性能,这是由于所有的数据和索引都混合在一个共享的数据结构(分区映射、B+树)中,查询的时间变长导致的。 因此,如果集群有数十个和数百个节点和缓存,并且由于内部结构、检查点性能下降和/或节点到集群的连接速度较慢而遇到Java堆使用增加的情况,可以考虑使用缓存组。
#8.近缓存
近缓存是一种本地缓存,用于在本地节点上存储最近或最常访问的数据。假设应用启动了一个客户端节点并定期查询数据,例如国家/地区代码。因为客户端节点不存储数据,所以这些查询总是从远程节点获取数据。这时可以配置近缓存,以在应用运行时将国家/地区代码保留在本地节点上,这样可以提高性能。
近缓存为特定的常规缓存配置,并且仅保留该缓存的数据。
近缓存将数据存储在堆内存中,可以为近缓存条目配置缓存的最大值和退出策略。
提示
近缓存是完全事务性的,并且每当服务端节点上的数据更改时,它们都会自动更新或失效。
#8.1.配置近缓存
可以在缓存配置中为某个缓存配置近缓存:
- XML
- Java
- C#/.NET
// Create a near-cache configuration for "myCache".
NearCacheConfiguration<Integer, Integer> nearCfg = new NearCacheConfiguration<>();// Use LRU eviction policy to automatically evict entries
// from near-cache whenever it reaches 100_000 entries
nearCfg.setNearEvictionPolicyFactory(new LruEvictionPolicyFactory<>(100_000));CacheConfiguration<Integer, Integer> cacheCfg = new CacheConfiguration<Integer, Integer>("myCache");cacheCfg.setNearConfiguration(nearCfg);// Create a distributed cache on server nodes
IgniteCache<Integer, Integer> cache = ignite.getOrCreateCache(cacheCfg);
以这种方式配置后,就在从底层缓存请求数据的任何节点(包括服务端节点和客户端节点)上创建近缓存。如以下示例所示,当拿到缓存的实例时,数据将通过近缓存获得:
IgniteCache<Integer, Integer> cache = ignite.cache("myCache");int value = cache.get(1);
CacheConfiguration中与近缓存有关的大部分参数都会继承于底层缓存的配置,比如,如果底层缓存有一个ExpiryPolicy配置,近缓存中的条目也会基于同样的策略。
下表中列出的参数是不会从底层配置中继承的:
| 参数 | 描述 | 默认值 |
|---|---|---|
nearEvictionPolicy | 近缓存退出策略 | 无 |
nearStartSize | 近缓存初始大小(可持有的条目数) | 375,000 |
#8.2.客户端节点动态创建近缓存
从客户端节点向尚未配置近缓存的缓存发出请求时,可以为该缓存动态创建近缓存,通过在客户端本地存储“热”数据来提高性能。此缓存仅在创建它的节点上生效。
为此,创建一个近缓存配置并将其作为参数传递给获取缓存实例的方法:
- Java
- C#/.NET
// Create a near-cache configuration
NearCacheConfiguration<Integer, String> nearCfg = new NearCacheConfiguration<>();// Use LRU eviction policy to automatically evict entries
// from near-cache, whenever it reaches 100_000 in size.
nearCfg.setNearEvictionPolicyFactory(new LruEvictionPolicyFactory<>(100_000));// get the cache named "myCache" and create a near cache for it
IgniteCache<Integer, String> cache = ignite.getOrCreateNearCache("myCache", nearCfg);String value = cache.get(1);
数据再平衡
#1.数据再平衡
#1.1.概述
当一个新节点加入集群时,部分分区会被分配至新的节点,以使整个集群的数据保持平均分布,这个过程称为数据再平衡。
如果现有节点永久离开集群,并且未配置备份,则会丢失此节点上存储的分区。配置备份后,丢失分区的备份副本之一将成为主分区,并开始再平衡过程。
警告
数据再平衡由基线拓扑的变化触发。在纯内存集群中,默认行为是在节点离开或加入集群时(基线拓扑自动更改)立即开始再平衡。在开启持久化的集群中,默认必须手动更改基线拓扑,或者在启用基线自动调整后可以自动更基线拓扑。
再平衡是缓存级的配置。
#1.2.配置再平衡模式
Ignite支持同步和异步的再平衡,在同步模式中,再平衡结束前缓存的任何操作都会被阻塞。在异步模式中,再平衡过程以异步的模式执行,也可以为某个缓存禁用再平衡。
如果要修改再平衡模式,可以在缓存配置中配置如下的值:
SYNC:同步再平衡模式,再平衡结束前缓存的任何操作都会被阻塞;ASYNC:异步再平衡模式,缓存直接可用,然后在后台会从其它节点加载所有必要的数据;NONE:该模式下不会发生再平衡,这意味着要么在访问数据时从持久化存储载入,要么数据被显式地填充。
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();CacheConfiguration cacheCfg = new CacheConfiguration("mycache");cacheCfg.setRebalanceMode(CacheRebalanceMode.SYNC);cfg.setCacheConfiguration(cacheCfg);// Start a node.
Ignite ignite = Ignition.start(cfg);
#1.3.配置再平衡线程池
默认一个节点只会有一个线程用于再平衡,这意味着在一个特定的时间点只有一个线程用于从一个节点到另一节点传输批量数据,或者处理来自远端的批量数据。
可以从系统线程池中拿到更多的线程数用于再平衡。每当节点需要将一批数据发送到远端节点或需要处理来自远端节点的一批数据时,都会从池中获取系统线程,批次处理完成后,该线程会被释放。
- XML
- Java
IgniteConfiguration cfg = new IgniteConfiguration();cfg.setRebalanceThreadPoolSize(4);CacheConfiguration cacheCfg = new CacheConfiguration("mycache");
cfg.setCacheConfiguration(cacheCfg);// Start a node.
Ignite ignite = Ignition.start(cfg);
警告
在内部,系统线程池广泛用于和缓存有关的所有操作(put,get等),SQL引擎和其它模块,因此将再平衡线程池设置为一个很大的值会显著提高再平衡的性能,但是会影响应用的吞吐量。
#1.4.再平衡消息限流
当数据从一个节点传输到另一个节点时,整个数据集会被拆分为多个批次然后将每一个批次作为一个单独的消息进行发送,批次的大小和节点在消息之间的等待时间,都是可以配置的。
- XML
- Java
- C#/.NET
IgniteConfiguration cfg = new IgniteConfiguration();CacheConfiguration cacheCfg = new CacheConfiguration("mycache");cfg.setRebalanceBatchSize(2 * 1024 * 1024);
cfg.setRebalanceThrottle(100);cfg.setCacheConfiguration(cacheCfg);// Start a node.
Ignite ignite = Ignition.start(cfg);
#1.5.其他配置
下表列出了CacheConfiguration中和再平衡有关的属性:
| 属性 | 描述 | 默认值 |
|---|---|---|
rebalanceBatchSize | 单个再平衡消息的大小(字节),在每个节点再平衡算法会将数据拆分为多个批次,然后再将其发送给其他节点。 | 512KB |
rebalanceDelay | 当节点加入或者离开集群时,再平衡过程启动的延迟时间(毫秒),如果打算在节点离开拓扑后重启节点,或者打算在同时/一个个启动多个节点的过程中,所有节点都启动完成之前不进行重新分区或者再平衡,也可以推迟。 | 0,无延迟 |
rebalanceOrder | 完成再平衡的顺序,只有SYNC和ASYNC再平衡模式的缓存才可以将再平衡顺序设置为非0值,具有更小值的缓存再平衡会被首先完成,再平衡默认是无序的。 | 0 |
rebalanceThrottle | 请参见再平衡消息限流 | 0(限流禁用) |
rebalanceTimeout | 节点间交换再平衡消息的挂起超时。 | 10秒 |
#1.6.再平衡过程监控
通过JMX可以监控缓存的再平衡过程。
相关文章:
Ignite内存配置
配置内存 #1.内存架构 #1.1.概述 Ignite内存架构通过可以同时在内存和磁盘上存储和处理数据及索引,得到了支持磁盘持久化的内存级性能。 多层存储的运行方式类似于操作系统(例如Linux)的虚拟内存。但是这两种类型架构之间的主要区别是&…...

前端基础vue路由懒加载
为什么用路由懒加载 首屏组件加载速度更快一些,解决白屏问题,常言道需要就加载,不需要就先放一边 懒加载定义 懒加载简单来说就是延迟加载或按需加载,即在需要的时候的时候进行加载。 使用 常用的懒加载方式有两种:即…...
C++系列第九篇 数据类型下篇 - 复合类型(指针高级应用)
系列文章 C 系列 前篇 为什么学习C 及学习计划-CSDN博客 C 系列 第一篇 开发环境搭建(WSL 方向)-CSDN博客 C 系列 第二篇 你真的了解C吗?本篇带你走进C的世界-CSDN博客 C 系列 第三篇 C程序的基本结构-CSDN博客 C 系列 第四篇 C 数据类型…...

python三大开发框架django、 flask 和 fastapi 对比
本文讲述了什么启发了 FastAPI 的诞生,它与其他替代框架的对比,以及从中汲取的经验。 如果不是基于前人的成果,FastAPI 将不会存在。在 FastAPI 之前,前人已经创建了许多工具 。 几年来,我一直在避免创建新框架。首先&…...

html基础2
视频video <video src"视频的路径"controls"控制播放、暂停、音量等"autoplay"自动播放"loop"循环播放"width"视频播放器的宽度"height"视频播放器的高度"> </video>还有做浏览器兼容的方式…...

基于博弈树的开源五子棋AI教程[5 启发式搜索]
文章目录 1 最大化攻击者/最小化防守者排序2 置换表启发3 杀手表启发4 历史表启发历史表以及杀手表的维护初始化追加杀手表项清空杀手表 启发式搜索的姿势千奇百怪,本文只讨论一下几种 //搜索空间 #define Search_Space_MVA 0 //最优价值攻击者[分数最大] #d…...

JavaScript原型,原型链 ? 有什么特点?
一、原型 JavaScript 常被描述为一种基于原型的语言——每个对象拥有一个原型对象 当试图访问一个对象的属性时,它不仅仅在该对象上搜寻,还会搜寻该对象的原型,以及该对象的原型的原型,依次层层向上搜索,直到找到一个…...

Unity 问题 之 ScrollView ,LayoutGroup,ContentSizeFitter 一起使用时,动态变化时无法及时刷新更新适配界面的问题
Unity 问题 之 ScrollView ,LayoutGroup,ContentSizeFitter 一起使用时,动态变化时无法及时刷新更新适配界面的问题 目录 Unity 问题 之 ScrollView ,LayoutGroup,ContentSizeFitter 一起使用时,动态变化时无法及时刷新更新适配界面的问题 一、简单介绍…...
linux 中 C++的环境搭建以及测试工具的简单介绍
文章目录 makefleCMakegdb调试 与 coredumpValgrind 内存检测gtest 单元测试 makefile 介绍 安装 : sudo apt install make makefile 的规则: 举例说明 包括:目标文件 、 依赖文件 、 生成规则 使用 : make make clean CMake : CMake是一个…...

448. 找到所有数组中消失的数字
找到所有数组中消失的数字 描述 : 给你一个含 n 个整数的数组 nums ,其中 nums[i] 在区间 [1, n] 内。请你找出所有在 [1, n] 范围内但没有出现在 nums 中的数字,并以数组的形式返回结果。 题目 : LeetCode 448. 找到所有数组中消失的数字: 448. 找…...

为何在下雪天它“失宠”了,传统雪地靴居然不适合下雪穿
随着冬至的到来,一年之中最寒冷的“三九天”正式拉开序幕。近期各地纷纷下起了大雪,在这场大雪中雪地靴似乎“失宠”了。在社交媒体上,有网友吐槽“雪地靴根本不能下雪穿”,后面有不少网友纷纷分享了自己在雪地靴上尴尬的经历&…...

第34节: Vue3 调用内联处理程序中的方法
在UniApp中使用Vue3框架时,你可以在模板中直接调用组件内联处理程序中的方法。以下是一个示例: <template> <view> <button click"handleClick">Click me</button> <p>{{ message }}</p> </view&…...
)
JavaScript--明明白白Promise (Park One)
明明白白Promise (Park One) Promise是一种用于处理异步操作的特殊对象。它代表了一个尚未完成但最终会完成的操作,并可以在操作完成后返回结果或错误。 Promise有三种状态:pending(进行中)、fulfilled(已完成&#…...

el-form与el-upload结合上传带附件的表单数据(后端篇)
1.写在之前 本文采用Spring Boot MinIO MySQLMybatis Plus技术栈,参考ruoyi-vue-pro项目。 前端实现请看本篇文章el-form与el-upload结合上传带附件的表单数据(前端篇)-CSDN博客。 2.需求描述 在OA办公系统中,流程表单申请人…...
postMessage——不同源的网页直接通过localStorage/sessionStorage/Cookies——技能提升
最近遇到一个问题,就是不同源的两个网页之间进行localstorage或者cookie的共享。 上周其实遇到过一次,觉得麻烦就让后端换了种方式处理了,昨天又遇到了同样的问题。 使用场景 比如从网页A通过iframe跳转到网页B,而且这两个网页…...
)
上市公司-绿色投资者数据集(2000-2022)
上市公司-绿色投资者数据(2000-2022年)是一份涵盖了过去二十多年中国上市公司绿色投资情况的详细数据集。该数据集包括了各上市公司的股票代码、年份、会计年度、股票简称,以及STPT(特殊处理股票的标识),行…...

3 pandas之dataframe
定义 DataFrame是一个二维数据结构,即数据以行和列的方式以表格形式对齐。 DataFrame特点: 存在不同类型的列大小可变带有标签的轴可对列和行进行算数运算 构造函数 pandas.DataFrame( data, index, columns, dtype, copy)参数解释: 序号…...
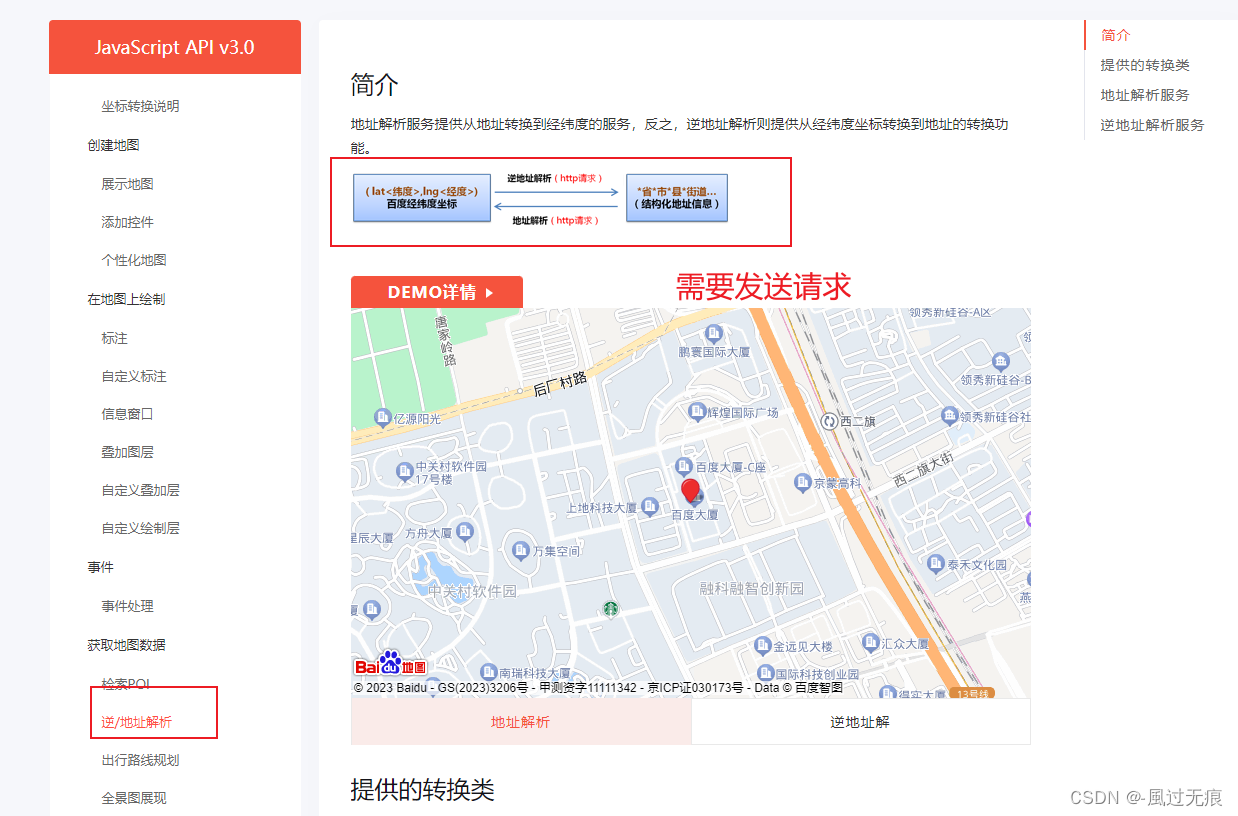
vue-内网,离线使用百度地图(地图瓦片图下载静态资源展示定位)
前言 最近发现很多小伙伴都在问内网怎么使用百度地图,或者是断网情况下能使用百度地图吗 后面经过一番研究,主要难点是,正常情况下我们是访问公网百度图片,数据,才能使用 内网时访问不了百度地图资源时就会使用不了&…...

OpenFeign 万字教程详解
OpenFeign 万字教程详解 目录 一、概述 1.1.OpenFeign是什么?1.2.OpenFeign能干什么1.3.OpenFeign和Feign的区别1.4.FeignClient 二、OpenFeign使用 2.1.OpenFeign 常规远程调用2.2.OpenFeign 微服务使用步骤2.3.OpenFeign 超时控制2.4.OpenFeign 日志打印2.5.O…...

全自动双轴晶圆划片机:半导体制造的关键利器
随着科技的飞速发展,半导体行业正以前所未有的速度向前迈进。在这个过程中,全自动双轴晶圆划片机作为一种重要的设备,在半导体晶圆、集成电路、QFN、发光二极管、miniLED、太阳能电池、电子基片等材料的划切过程中发挥着举足轻重的作用。 全自…...

日语AI面试高效通关秘籍:专业解读与青柚面试智能助攻
在如今就业市场竞争日益激烈的背景下,越来越多的求职者将目光投向了日本及中日双语岗位。但是,一场日语面试往往让许多人感到步履维艰。你是否也曾因为面试官抛出的“刁钻问题”而心生畏惧?面对生疏的日语交流环境,即便提前恶补了…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

visual studio 2022更改主题为深色
visual studio 2022更改主题为深色 点击visual studio 上方的 工具-> 选项 在选项窗口中,选择 环境 -> 常规 ,将其中的颜色主题改成深色 点击确定,更改完成...

基于Docker Compose部署Java微服务项目
一. 创建根项目 根项目(父项目)主要用于依赖管理 一些需要注意的点: 打包方式需要为 pom<modules>里需要注册子模块不要引入maven的打包插件,否则打包时会出问题 <?xml version"1.0" encoding"UTF-8…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

数据库分批入库
今天在工作中,遇到一个问题,就是分批查询的时候,由于批次过大导致出现了一些问题,一下是问题描述和解决方案: 示例: // 假设已有数据列表 dataList 和 PreparedStatement pstmt int batchSize 1000; // …...

【JavaWeb】Docker项目部署
引言 之前学习了Linux操作系统的常见命令,在Linux上安装软件,以及如何在Linux上部署一个单体项目,大多数同学都会有相同的感受,那就是麻烦。 核心体现在三点: 命令太多了,记不住 软件安装包名字复杂&…...

RNN避坑指南:从数学推导到LSTM/GRU工业级部署实战流程
本文较长,建议点赞收藏,以免遗失。更多AI大模型应用开发学习视频及资料,尽在聚客AI学院。 本文全面剖析RNN核心原理,深入讲解梯度消失/爆炸问题,并通过LSTM/GRU结构实现解决方案,提供时间序列预测和文本生成…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

IP如何挑?2025年海外专线IP如何购买?
你花了时间和预算买了IP,结果IP质量不佳,项目效率低下不说,还可能带来莫名的网络问题,是不是太闹心了?尤其是在面对海外专线IP时,到底怎么才能买到适合自己的呢?所以,挑IP绝对是个技…...