UNet-肝脏肿瘤图像语义分割
目录
一. 语义分割
二. 数据集
三. 数据增强
图像数据处理步骤
CT图像增强方法 :windowing方法
直方图均衡化
获取掩膜图像深度
在肿瘤CT图中提取肿瘤
保存肿瘤数据
四. 数据加载
数据批处理
编辑编辑
数据集加载
五. UNet神经网络模型搭建
单张图片预测图
一. 语义分割
第三代图像分割:语义分割
图像分割(Image Segmentation)是计算机视觉领域中的一项重要基础技术。图像分割是将数字图像细分为多个图像子区域的过程,通过简化或改变图像的表示形式,让图像能够更加容易被理解。更简单地说,图像分割就是为数字图像中的每一个像素附加标签,使得具有相同标签的像素具有某种共同的视觉特性。
医学图像的模态(格式)更加多样化,如X-ray、CT、MRI以及超声等等,当然也包括一些常见的RGB图像(如眼底视网膜图像)。不同模态图像反应的信息侧重点是不一样的。比如X-ray观察骨骼更清晰,CT可以反应组织和器官出血,MRI适合观察软组织。而且不同型号的成像设备得到的成像结果有一定差异。
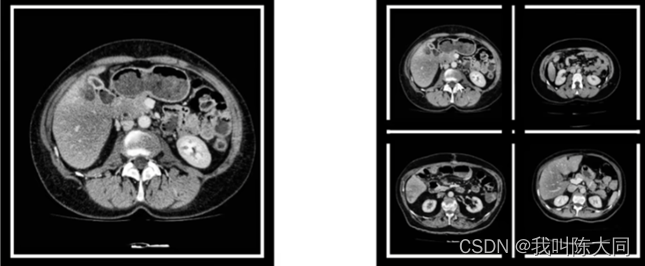
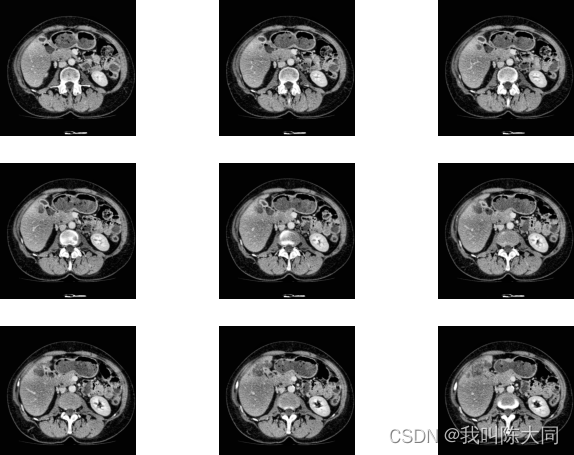
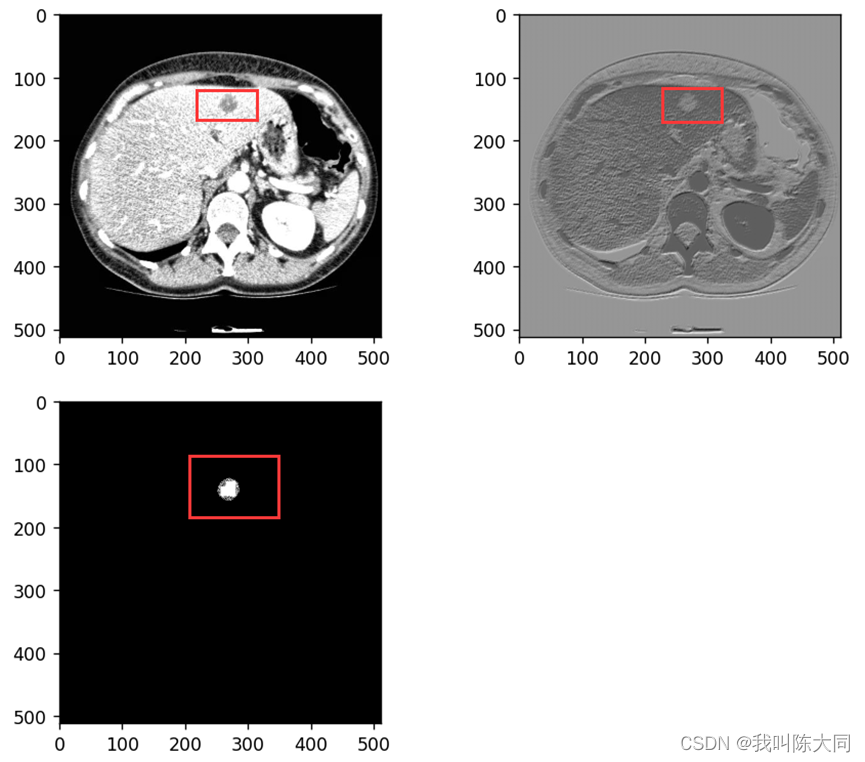
一图为一肝脏CT图像切片可视化结果,已经过预处理转化为灰度图像,组织与器官之间的分界线比较模糊。
二图为不同个体的肝脏CT图像,差异巨大,这给肝脏组织提取带来了很大的困难。
二. 数据集
3D-IRCADb (3D Image Reconstruction for Comparison of Algorithm Database,用于算法数据库比较的三维图像重建),数据库由75%病例中10名女性和10名男性肝脏肿瘤患者的CT扫描组成,每个文件夹对应不同的病人,提供了有关图像的信息,如肝脏大小(宽度、深度、高度)或根据Couninurd分割的肿瘤位置。它还表明,由于与邻近器官的接触、肝脏的非典型形状或密度,甚至图像中的伪影,肝脏分割可能会遇到重大困难。
链接:https://pan.baidu.com/s/1P76AF-wvrFjElc6tR82tRA
提取码:5el7
三. 数据增强
图像数据处理步骤
1.数据加载
2.CT图像增强
3.直方图均衡化增强
4.获取肿瘤对应CT图、肝脏肿瘤掩模图
5.保存图像
DICOM数据读取
使用pydicom库读取文件,pydicom.dcmread函数读取文件,对文件排序,pixel_array属性提取图像像素信息,展示图片:
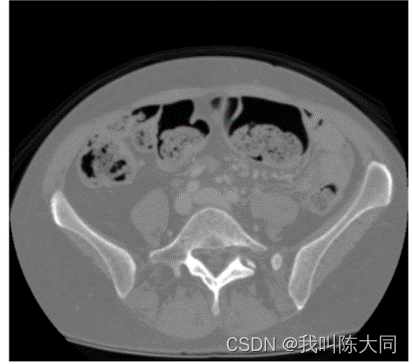
批量数据读取
# 批量读取数据
img_slices = [pydicom.dcmread(os.path.join(data_path, file_name)) for file_name in os.listdir(data_path)]
os.listdir(data_path)
# 排序,避免CT图乱序
img_slices.sort(key=lambda x:x.InstanceNumber) # 顺序属性
img_array = np.array([i.pixel_array for i in img_slices]) # 提取像素值
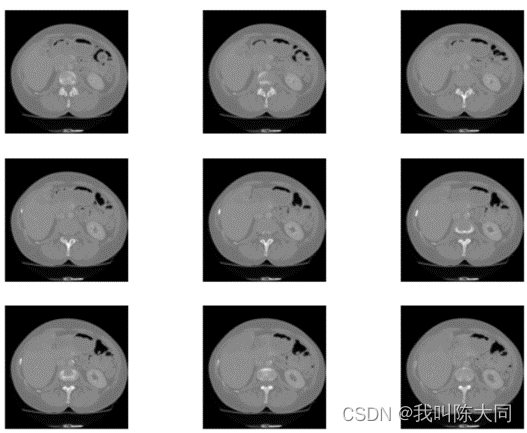
CT图像增强方法 :windowing方法
CT图像的范围很大导致了对比度很差,需要针对具体的器官进行处理。
CT值的物理意义就是CT射线照了你的身体,辐射经过你的身体时的辐射强度的衰减程度。
CT 的特点是能够分辨人体组织密度的轻微差别,所采用的标准是根据各种组织对x线的线性吸收系数(μ值)来决定的。
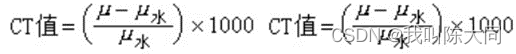
根据Hu(CT)值来筛选我们想要的部位的图片,其他部位全部抹黑或者抹白,目的是为了增加图像对比度。使用windowing方法。观察的CT值范围:窗宽。观察的中心CT值即为窗位,然后对肿瘤部分进行二值化处理。
def windowing(img, window_width, window_center):# params:需要增强的图片, 窗口宽度, 窗中心 通过窗口最小值来线性移动窗口增强min_windows = float(window_center)-0.5*float(window_width)new_img = (img-min_windows)/float(window_width)new_img[new_img<0] = 0 # 二值化处理 抹白new_img[new_img>1] = 1 # 抹黑return (new_img * 255).astype('uint8') # 把数据整理成标准图像格式
img_ct = windowing(img_array, 500, 150)
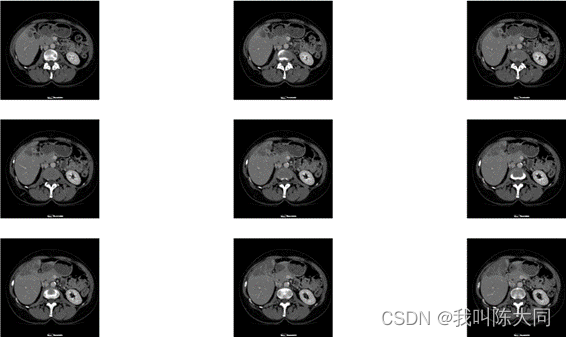
直方图均衡化
直方图均衡化函数:把整个图像分成许多小块(比如按10*10作为一个小块),对每个小块进行均衡化。主要对于图像直方图不是那么单一的(比如存在多峰情况)图像比较实用。0pencv中将这种方法为:cv2.createCLAHE()
def clahe_equalized(imgs):# 输入imgs的形状必须是3维assert (len(imgs.shape) == 3)# 定义均衡化函数clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8))# 新数组存放均衡化后的数据img_res = np.zeros_like(imgs)for i in range(len(imgs)):img_res[i,:,:] = clahe.apply(np.array(imgs[i,:,:], dtype=np.uint8))return img_res/255
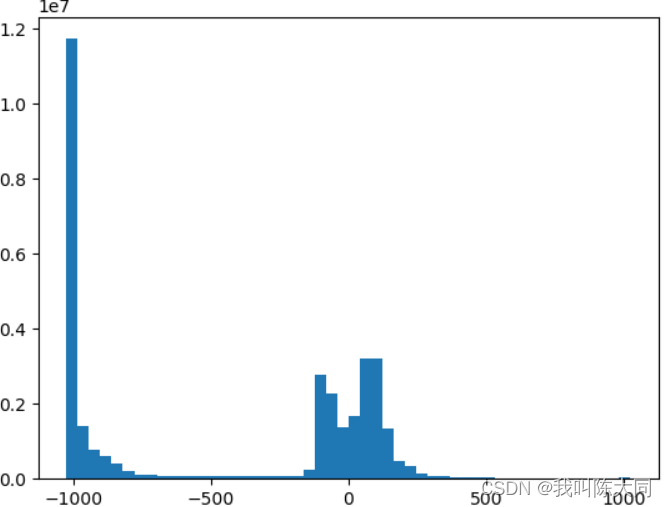
plt.hist(img_array.reshape(-1,),bins=50) # 降成一维,分成50分
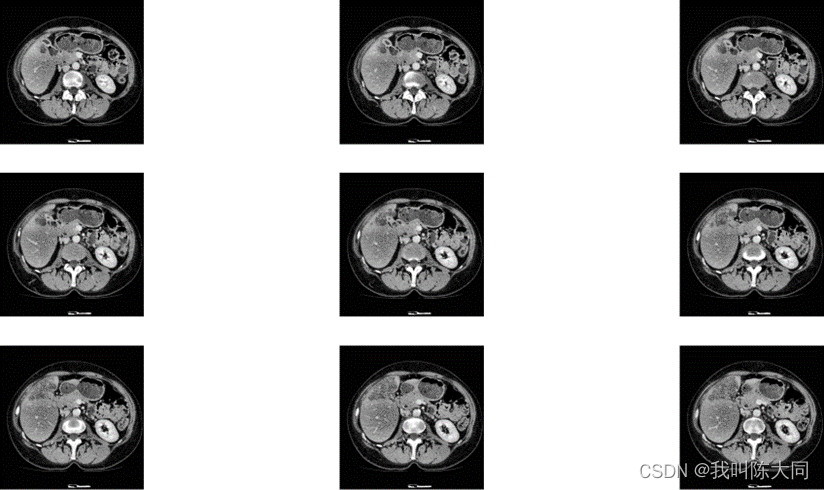
获取掩膜图像深度
为加快训练速度,自定义函数实现提取肝脏肿瘤对应的CT图像(处理后)和对应的掩模图,并分别保存到不同的文件夹中,分别作为模型的输入与输出。读取肿瘤CT图:
tumor_slice = [pydicom.dcmread(os.path.join(data_path_mask, file_name)) for file_name in os.listdir(data_path_mask)]
#避免CT图乱序,顺序属性
tumor_slice.sort(key=lambda x: x.InstanceNumber)
#提取像素值
tumor_array = np.array([i.pixel_array for i in tumor_slice])
print(tumor_array.shape) # (129, 512, 512)
 白色部分为肿瘤掩模图,黑色部分对应的像素数组全为0。
白色部分为肿瘤掩模图,黑色部分对应的像素数组全为0。
在肿瘤CT图中提取肿瘤
index = [i.sum() > 0 for i in tumor_array] # 提取含肿瘤部分
# print(len(index)) # = tumor_array.shape[0] 129
# 提取掩模图的肿瘤部分
img_tumor = tumor_array[index]
# 对增强后的CT图提取肿瘤部分
img_patient = img_clahe[index]

保存肿瘤数据
# 设置保存文件路径
patient_save_path = r'E:/datasets/liver/tmp/patient/'
tumor_save_path = r'E:/datasets/liver/tmp/tumor/'
for path in [patient_save_path, tumor_save_path]:if os.path.exists(path): # 判断文件夹是否存在shutil.rmtree(path) # 清空os.mkdir(path)
# 保留一个肿瘤的数据
# plt.imsave(os.path.join(patient_save_path, '0.jpg'), img_patient[0],cmap='gray')
for i in range(len(img_patient)):plt.imsave(os.path.join(patient_save_path, f'{i}.jpg'), img_patient[i], cmap='gray')plt.imsave(os.path.join(tumor_save_path, f'{i}.jpg'), img_tumor[i], cmap='gray')四. 数据加载
数据批处理
取3dircadb1文件夹中数据作为实验对象,取前1-10个病人的数据作为训练样本,10-20个病人的数据作为测试样本。
- 1.读取CT图图像片段
- 2.提取像素值
- 3.CT图增强、均衡化
- 4.处理肿瘤掩模图
- 5.对每个病人的肿瘤图进行排序,提取肿瘤片段像素值
- 6.提取肿瘤肿瘤部分像素编号
- 7.找到CT图中对应位置
- 8.保存所有肿瘤数据
def processImage(start, end):for num in range(start, end):print('正在处理第%d号病人' % num)data_path = fr'G:/dataPack/基于深度学习的肝脏肿瘤图像分割/3dircadb1/3dircadb1.{num}/PATIENT_DICOM'# 读取CT图图像片段image_slices = [pydicom.dcmread(os.path.join(data_path, file_name)) for file_name in os.listdir(data_path)]os.listdir(data_path)image_slices.sort(key=lambda x: x.InstanceNumber) # 排序# 提取像素值image_array = np.array([i.pixel_array for i in image_slices])# CT图增强-windowingimg_ct = windowing(image_array, 250, 0)# 直方图均衡化img_clahe = clahe_equalized(img_ct)# 肿瘤掩模图处理livertumor_path = fr'G:/dataPack/基于深度学习的肝脏肿瘤图像分割/3dircadb1/3dircadb1.{num}/MASKS_DICOM'tumor_paths = [os.path.join(livertumor_path, i) for i in os.listdir(livertumor_path) if 'livertumor' in i]# 重新排序tumor_paths.sort()# 提取所有肿瘤数据j = 0for tumor_path in tumor_paths:print("正在处理第%d个肿瘤" % j)tumor_slices = [pydicom.dcmread(os.path.join(tumor_path, file_name)) for file_name inos.listdir(tumor_path)]# 重新对肿瘤片段图排序tumor_slices.sort(key=lambda x: x.InstanceNumber)# 提取像素值tumor_array = np.array([i.pixel_array for i in tumor_slices])# 没有肿瘤的掩模图全为黑色,对应像素全为0index = [i.sum() > 0 for i in tumor_array] # 提取肿瘤部分编号img_tumor = tumor_array[index]# 对增强后的CT图提取肿瘤img_patient = img_clahe[index]# 保存所有肿瘤数据for i in range(len(img_patient)):plt.imsave(os.path.join(patient_save_path, f'{num}_{j}_{i}.jpg'), img_patient[i], cmap='gray') # 保存CT图plt.imsave(os.path.join(tumor_save_path, f'{num}_{j}_{i}.jpg'), img_tumor[i], cmap='gray') # 保存肿瘤掩模图j += 1return img_patient, img_tumor处理后保存的CT增强图像与肿瘤掩模图

数据集加载
定义Dataset数据加载器,对样本中每个图片进行进一步处理,转成np数组并转换维度方便UNet网络训练,通过Dataloader中定义batch_size设置每批数据大小为2(从计算角度来提高训练效率)
transform = transforms.Compose([transforms.Resize((512, 512)),transforms.ToTensor()
])首先读取本地文件,设置训练集与测试集文件路径,通过torch.squeeze(anno_tensor).type(torch.long)将肿瘤图转化为单通道数组
并对肿瘤图进行二值化处理
# 读取之前保存的处理后的病人CT图片与肿瘤图片
train_img_patient, train_img_tumor = processImage(1, 5)
test_img_patient, test_img_tumor = processImage(5, 7)
patient_images = glob.glob(r'E:\\datasets\liver\tmp\patient\*.jpg')
tumor_images = glob.glob(r'E:\\datasets\liver\tmp\tumor\*.jpg')
train_images = [p for p in patient_images if '1_' in p]
train_labels = [p for p in tumor_images if '1_' in p]
test_images = [p for p in patient_images if '2_' in p]
test_labels = [p for p in tumor_images if '2_' in p]
train_images = np.array(train_images)
train_labels = np.array(train_labels)
test_images = np.array(test_images)
test_labels = np.array(test_labels)
# img = Image.open(train_images[1])
# plt.imshow(img)
# plt.show()class Portrait_dataset(data.Dataset):def __init__(self, img_paths, anno_paths):self.imgs = img_pathsself.annos = anno_pathsdef __getitem__(self, index):img = self.imgs[index]anno = self.annos[index]pil_img = Image.open(img)img_tensor = transform(pil_img)pil_anno = Image.open(anno)anno_tensor = transform(pil_anno)# 由于蒙版图都是黑白图,会产生channel为1的维度。经过转换后,256x256x1,这个1并不是我们需要的。anno_tensor = torch.squeeze(anno_tensor).type(torch.long)anno_tensor[anno_tensor > 0] = 1 # 语义分割。二分类。return img_tensor, anno_tensordef __len__(self):return len(self.imgs)BATCH_SIZE = 2
train_set = Portrait_dataset(train_images, train_labels)
test_set = Portrait_dataset(test_images, test_labels)
train_dataloader = data.DataLoader(train_set, batch_size=BATCH_SIZE, shuffle=True)
test_dataloader = data.DataLoader(test_set, batch_size=BATCH_SIZE)
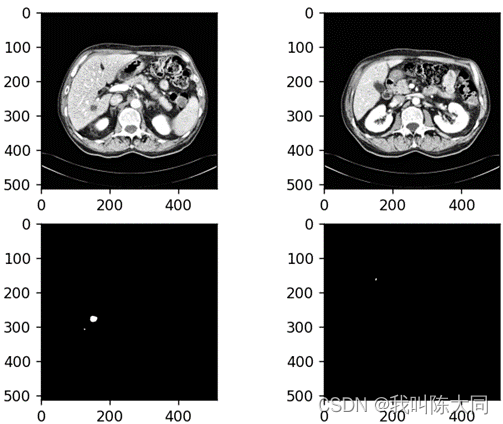
img_batch, anno_batch = next(iter(train_dataloader))通过DataSet读取数据集,在通过DataLoader设置批处理图片数量=2(提高计算效率)
随机选取病人CT图和肿瘤图展示:
五. UNet神经网络模型搭建
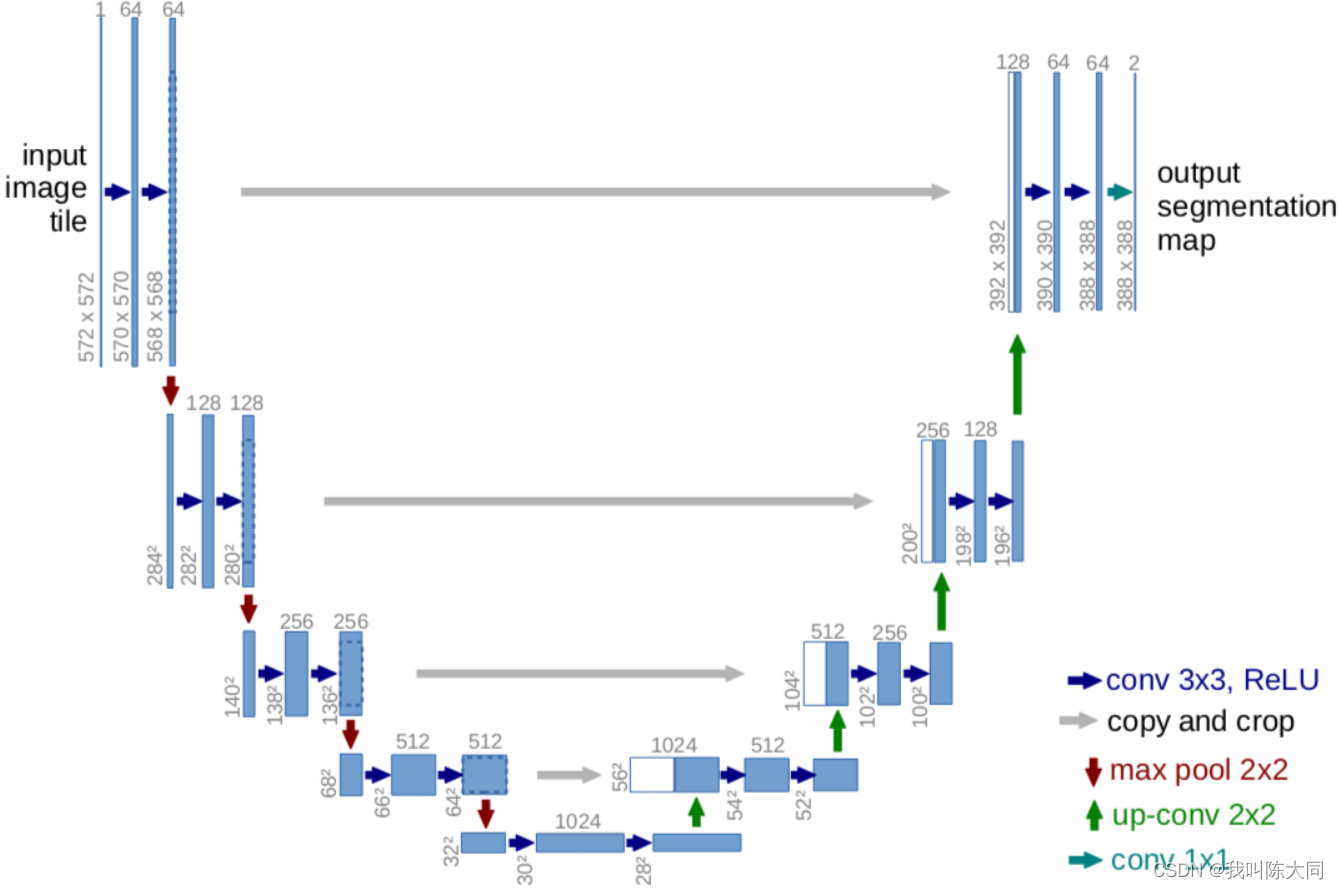
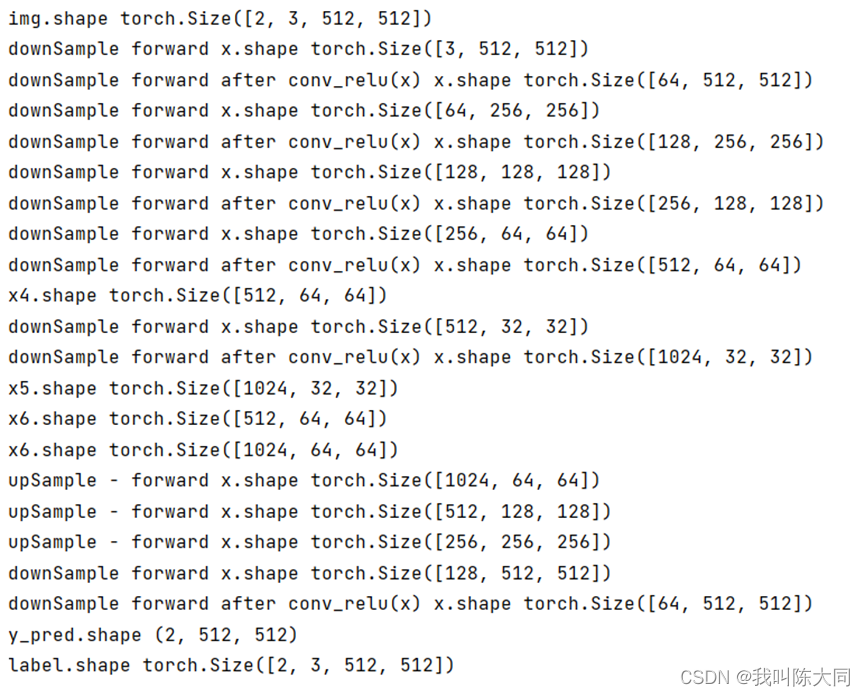
Unet网络结构是对称的,蓝/白色框表示 feature map;蓝色箭头表示 3x3 卷积,用于特征提取;灰色箭头表示 skip-connection,用于特征融合;红色箭头表示池化 pooling,用于降低维度;绿色箭头表示上采样 upsample,用于恢复维度;青色箭头表示 1x1 卷积,用于输出结果。
class downSample(nn.Module):def __init__(self, in_channels, out_channels):super(downSample, self).__init__()# 两层*(卷积+激活)self.conv_relu = nn.Sequential(# padding=1,希望图像经过卷积之后大小不变nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1),nn.ReLU(inplace=True))# 下采样(池化)self.pool = nn.MaxPool2d(kernel_size=2)def forward(self, x, is_pool=True):if is_pool:x = self.pool(x)print("downSample forward x.shape",x.shape)x = self.conv_relu(x)print("downSample forward after conv_relu(x) x.shape",x.shape)return x# 上采样模型。卷积、卷积、上采样(反卷积实现上采样)
class upSample(nn.Module):def __init__(self, channels):# 两层*(卷积层+激活层)super(upSample, self).__init__()self.conv_relu = nn.Sequential(nn.Conv2d(2 * channels, channels, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(channels, channels, kernel_size=3, padding=1),nn.ReLU(inplace=True))# 上采样激活层(ConvTransposed)将输出层的channel变成原来的一半self.upConv_relu = nn.Sequential(nn.ConvTranspose2d(channels, channels // 2,kernel_size=3, stride=2,padding=1, output_padding=1),nn.ReLU(inplace=True))def forward(self, x):print("upSample - forward x.shape",x.shape)x = self.conv_relu(x)x = self.upConv_relu(x)return x# 创建Unet。要初始化上、下采样层,还有其他的一些层
class Unet(nn.Module):def __init__(self):super(Unet, self).__init__()self.down1 = downSample(3, 64)self.down2 = downSample(64, 128)self.down3 = downSample(128, 256)self.down4 = downSample(256, 512)self.down5 = downSample(512, 1024)self.up = nn.Sequential(nn.ConvTranspose2d(1024, 512,kernel_size=3,stride=2,padding=1,output_padding=1),nn.ReLU(inplace=True))self.up1 = upSample(512)self.up2 = upSample(256)self.up3 = upSample(128)self.conv_2 = downSample(128, 64) # 最后两层卷积self.last = nn.Conv2d(64, 2, kernel_size=1) # 输出层为2分类def forward(self, x):x1 = self.down1(x, is_pool=False)x2 = self.down2(x1)x3 = self.down3(x2)x4 = self.down4(x3) # ([512, 64, 64])print("x4.shape",x4.shape) # x4.shape torch.Size([512, 64, 64])x5 = self.down5(x4)print("x5.shape",x5.shape) # x5.shape torch.Size([1024, 32, 32])x6 = self.up(x5)print("x6.shape",x6.shape) # x6.shape torch.Size([512, 64, 64])# 将下采用过程x4的输出与上采样过程x5的输出做一个合并x6 = torch.cat([x4, x6], dim=0) # dim=0print("x6.shape",x6.shape) # x6.shape torch.Size([512, 128, 64])x7 = self.up1(x6)x7 = torch.cat([x3, x7], dim=0)x8 = self.up2(x7)x8 = torch.cat([x2, x8], dim=0)x9 = self.up3(x8)x9 = torch.cat([x1, x9], dim=0)x10 = self.conv_2(x9, is_pool=False)result = self.last(x10)return result神经网络中图像shape变化图:
单张图片预测图
相关文章:
UNet-肝脏肿瘤图像语义分割
目录 一. 语义分割 二. 数据集 三. 数据增强 图像数据处理步骤 CT图像增强方法 :windowing方法 直方图均衡化 获取掩膜图像深度 在肿瘤CT图中提取肿瘤 保存肿瘤数据 四. 数据加载 数据批处理 编辑编辑 数据集加载 五. UNet神经网络模型搭建 单张图片…...

三周爆赚千万 电竞选手在无聊猿游戏赢麻了
如何用3个星期赚到1千万?普通人做梦都不敢想的事,电竞职业选手Mongraal却用几把游戏轻易完成,赚钱地点是蓝筹NFT项目Bored Ape Yacht Club(BAYC无聊猿)出品的新游戏Dookey Dash。 这款游戏类似《神庙逃亡》࿰…...

BERT学习
非精读BERT-b站有讲解视频(跟着李沐学AI) (大佬好厉害,讲的比直接看论文容易懂得多) 写在前面 在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真…...
大话数据结构-图的深度优先遍历和广度优先遍历
4 图的遍历 图的遍历分为深度优先遍历和广度优先遍历两种。 4.1 深度优先遍历 深度优先遍历(Depth First Search),也称为深度优先搜索,简称DFS,深度优先遍历,是指从某一个顶点开始,按照一定的规…...

c语言指针怎么理解 第一部分
不理解指针,是因为有人教错了你。 有人告诉你,指针是“指向”某某某的,那就是误导你,给你挖了个坑。初学者小心不要误读这“指向”二字。 第一,“指针”通常用于保存一个地址,这个地址的数据类型在定义指…...
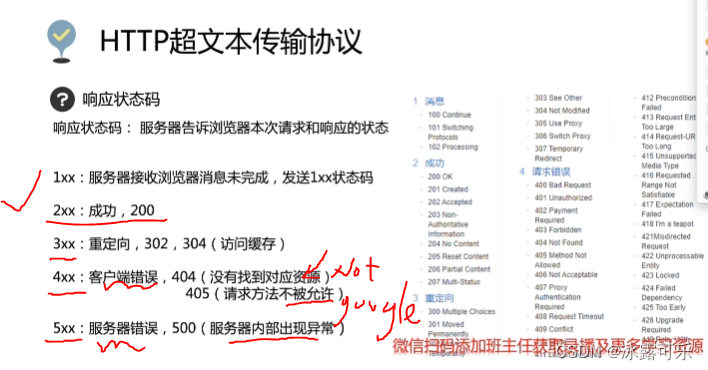
计算机网络安全基础知识2:http超文本传输协议,请求request消息的get和post,响应response消息的格式,响应状态码
计算机网络安全基础知识: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤…...

Pytest自动化框架~权威教程03-原有TestSuite的执行方法
前言TestSuite一直是unittest的灵活与精髓之处, 在繁多的测试用例中, 可以任意挑选和组合各种用例集, 比如smoke用例集, level1用例集, webtest用例集, bug回归用例集等等, 当然这些TestSuite需要我们提前定义好, 并把用例加载进去.Pytest采取的是完全不同的用例组织和运行方式…...

web自动化 基于python+Selenium+PHP+Ftp实现的轻量级web自动化测试框架
1、 开发环境 win7 64 PyCharm 4.0.5 setuptools-29.0.1.zip 下载地址:setuptools-29.0.1.zip_免费高速下载|百度网盘-分享无限制 官方下载地址:setuptools PyPI python 3.3.2 mysql-connector-python-2.1.4-py3.3-win64 下载地址:mysq…...

【MyBatis】源码学习 05 - 关于 xml 文件解析的分析
文章目录前言参考目录学习笔记1、章节目录概览2、14.3:SqlSourceBuilder 类与 StaticSqlSource 类3、14.4.2:ResultMapResolver 类3.1、测试代码说明3.2、结果集 userMap 解析流程3.3、结果集 getGirl 解析流程3.4、鉴别器 discriminator 解析流程4、14.…...
代码随想录算法训练营第二天| 977. 有序数组的平方、209. 长度最小子数组、59.螺旋矩阵II
977 有序数组的平方题目链接:977 有序数组的平方介绍给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。思路看到题目的第一反应,首先负数的平方跟正数的平方是相同的&…...
Ethercat系列(10)用QT实现SOEM主站
首先将SOEM编译成静态Lib库可以参考前面的博文(83条消息) VS2017下编译SOEM(Simle Open EtherCAT Master)_soem vs_CoderIsArt的博客-CSDN博客make_libsoem_lib.bat "C:\Program Files (x86)\Microsoft Visual Studio\2017\Community\VC\Auxiliary\Build" x86用QT创建…...

论文投稿指南——中文核心期刊推荐(科学、科学研究)
【前言】 🚀 想发论文怎么办?手把手教你论文如何投稿!那么,首先要搞懂投稿目标——论文期刊 🎄 在期刊论文的分布中,存在一种普遍现象:即对于某一特定的学科或专业来说,少数期刊所含…...
、attr()和data())
jQuery属性操作prop()、attr()和data()
jQuery 提供了一些属性操作的方法,主要包括 prop()、attr() 和 data() 等。通过这些方法,能够实现不同的需求。下面我们分别进行详细讲解。 1.prop() 方法 prop0 方法用来设置或获取元素固有属性值。元素固有属性是指元素本身自带的属性,如 …...
git的使用
1.git的四个区域: 2.常规git命令 git status 查看working directory哪些文件被更改了git add .把更改add到staging area,缓存的地方。改一个地方可以就先暂存一下,最后确认是哪些改动后再一起commit,以免不必要的版本。 在暂存区域ÿ…...
webpack生产环境配置
3 webpack生产环境配置 由于笔记文档没有按照之前的md格式书写,所以排版上代码上存在问题😢😢😢😢 09 提取css成单独文件 使用下载插件 npm i mini-css-extract-plugin0.9.0 -D webpack配置此时a,b提取成单独文件,并且…...
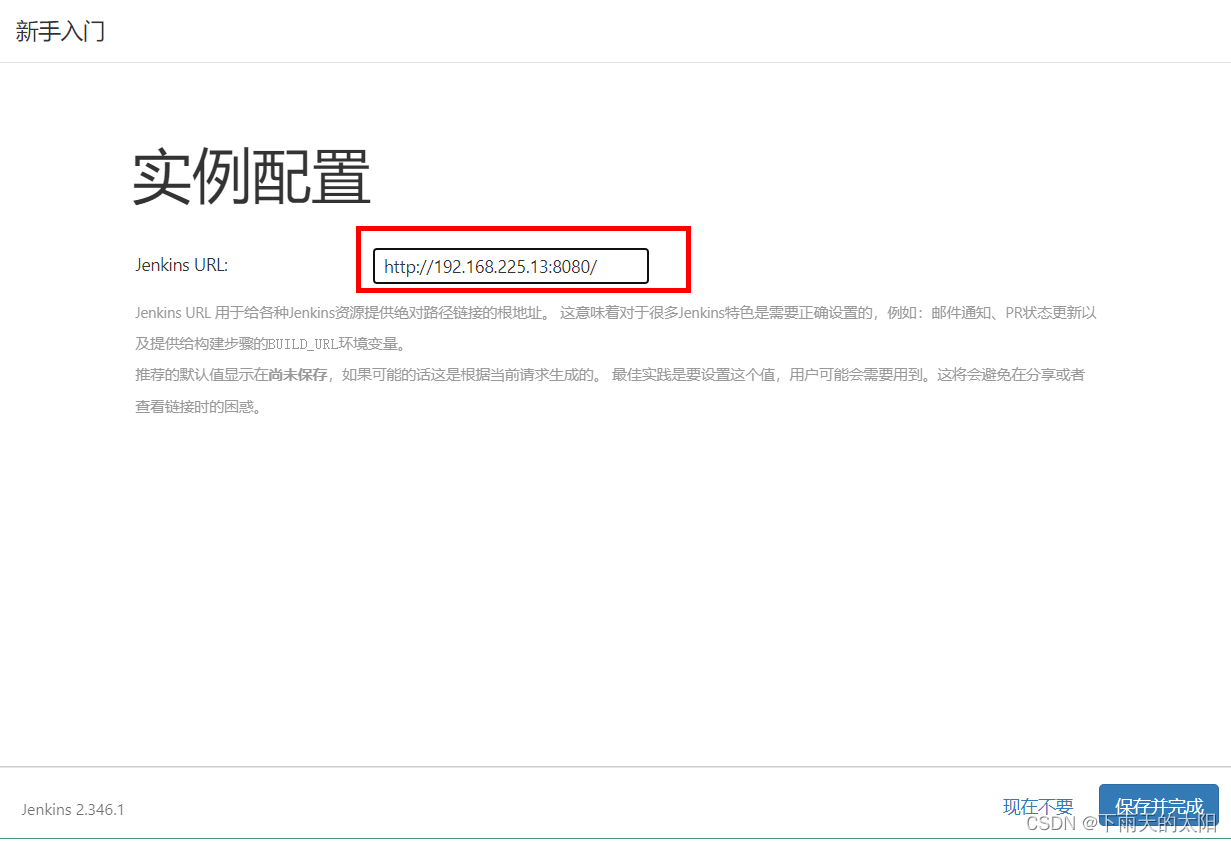
linux下安装jenkins
1.初始化Jenkins安装环境 系统版本:Red Hat Enterprise Linux 8.7 将脚本文件jenkins_install_env.sh 、 jenkins_install.sh和apache-maven-3.6.2-bin.tar.gz、jdk-8u251-linux-x64.tar.gz都上传到/usr/local/src目录下执行jenkins_install_env.sh脚本初始化Jenki…...

IGKBoard(imx6ull)-I2C接口编程之SHT20温湿度采样
文章目录1- 使能开发板I2C通信接口2- SHT20硬件连接3- 编码实现SHT20温湿度采样思路(1)查看sht20从设备地址(i2cdetect)(2)获取数据大体流程【1】软复位【2】触发测量与通讯时序(3)返…...
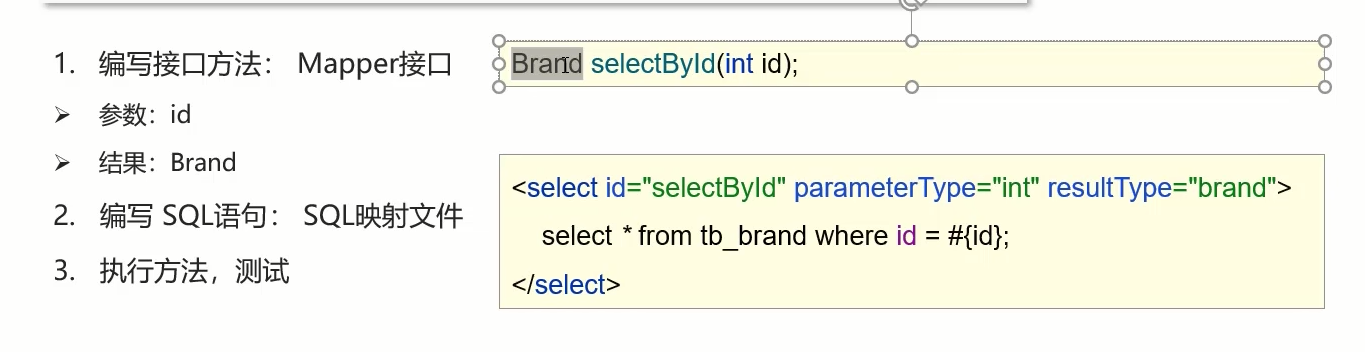
MyBatis——配置文件完成增删改查
1.首先先创建一个新的表,使用下面的sql语句 -- 删除tb_brand表 drop table if exists tb_brand; -- 创建tb_brand表 create table tb_brand (-- id 主键id int primary key auto_increment,-- 品牌名称brand_name varchar(20),-- 企业名称company_name varchar(20…...

Python内置函数 — all,any
1、all 源码注释: def all(*args, **kwargs): # real signature unknown"""Return True if bool(x) is True for all values x in the iterable.If the iterable is empty, return True."""pass 语法格式: all(iterable)…...
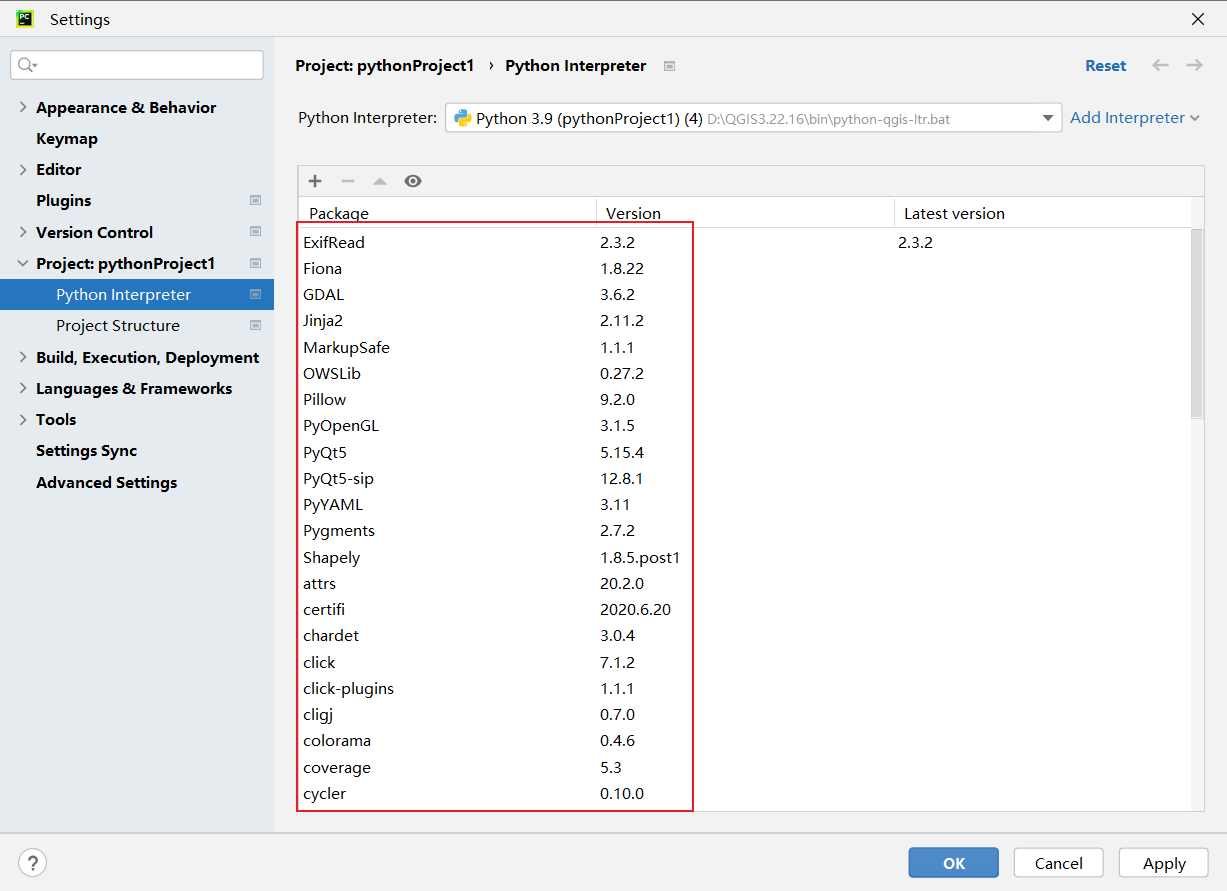
Pycharm配置QGIS环境
版本信息:QGIS: 3.22.16Pycharm:2022.3.2 (Community Edition)在QGIS官网下载安装包,下载稳定版本即可。配置步骤:安装完成后,使用Pycharm新建工程Python编译器选择之前配置好的编译器环境选择左侧第一个Vi…...

SpringBoot-17-MyBatis动态SQL标签之常用标签
文章目录 1 代码1.1 实体User.java1.2 接口UserMapper.java1.3 映射UserMapper.xml1.3.1 标签if1.3.2 标签if和where1.3.3 标签choose和when和otherwise1.4 UserController.java2 常用动态SQL标签2.1 标签set2.1.1 UserMapper.java2.1.2 UserMapper.xml2.1.3 UserController.ja…...

linux之kylin系统nginx的安装
一、nginx的作用 1.可做高性能的web服务器 直接处理静态资源(HTML/CSS/图片等),响应速度远超传统服务器类似apache支持高并发连接 2.反向代理服务器 隐藏后端服务器IP地址,提高安全性 3.负载均衡服务器 支持多种策略分发流量…...

MySQL 隔离级别:脏读、幻读及不可重复读的原理与示例
一、MySQL 隔离级别 MySQL 提供了四种隔离级别,用于控制事务之间的并发访问以及数据的可见性,不同隔离级别对脏读、幻读、不可重复读这几种并发数据问题有着不同的处理方式,具体如下: 隔离级别脏读不可重复读幻读性能特点及锁机制读未提交(READ UNCOMMITTED)允许出现允许…...

全球首个30米分辨率湿地数据集(2000—2022)
数据简介 今天我们分享的数据是全球30米分辨率湿地数据集,包含8种湿地亚类,该数据以0.5X0.5的瓦片存储,我们整理了所有属于中国的瓦片名称与其对应省份,方便大家研究使用。 该数据集作为全球首个30米分辨率、覆盖2000–2022年时间…...

Python 实现 Web 静态服务器(HTTP 协议)
目录 一、在本地启动 HTTP 服务器1. Windows 下安装 node.js1)下载安装包2)配置环境变量3)安装镜像4)node.js 的常用命令 2. 安装 http-server 服务3. 使用 http-server 开启服务1)使用 http-server2)详解 …...

Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement
Cilium动手实验室: 精通之旅---13.Cilium LoadBalancer IPAM and L2 Service Announcement 1. LAB环境2. L2公告策略2.1 部署Death Star2.2 访问服务2.3 部署L2公告策略2.4 服务宣告 3. 可视化 ARP 流量3.1 部署新服务3.2 准备可视化3.3 再次请求 4. 自动IPAM4.1 IPAM Pool4.2 …...

Spring Security 认证流程——补充
一、认证流程概述 Spring Security 的认证流程基于 过滤器链(Filter Chain),核心组件包括 UsernamePasswordAuthenticationFilter、AuthenticationManager、UserDetailsService 等。整个流程可分为以下步骤: 用户提交登录请求拦…...
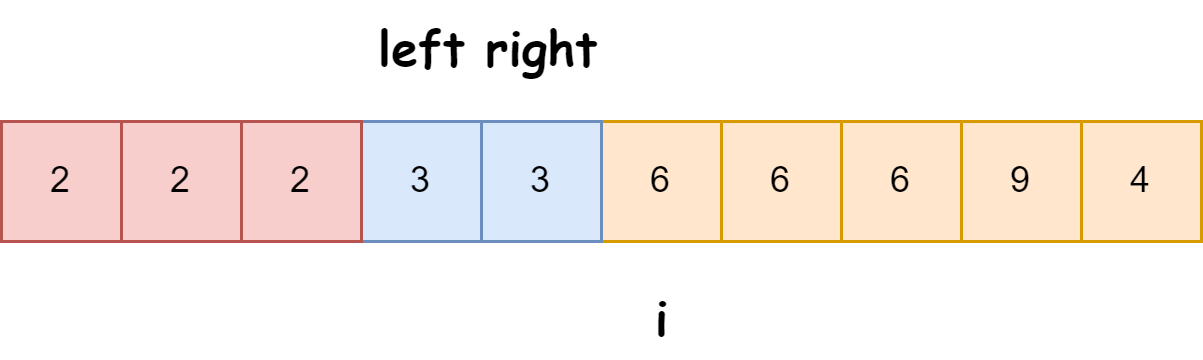
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...

boost::filesystem::path文件路径使用详解和示例
boost::filesystem::path 是 Boost 库中用于跨平台操作文件路径的类,封装了路径的拼接、分割、提取、判断等常用功能。下面是对它的使用详解,包括常用接口与完整示例。 1. 引入头文件与命名空间 #include <boost/filesystem.hpp> namespace fs b…...
轻量级Docker管理工具Docker Switchboard
简介 什么是 Docker Switchboard ? Docker Switchboard 是一个轻量级的 Web 应用程序,用于管理 Docker 容器。它提供了一个干净、用户友好的界面来启动、停止和监控主机上运行的容器,使其成为本地开发、家庭实验室或小型服务器设置的理想选择…...