用Python自己写一个分词器,python实现分词功能,隐马尔科夫模型预测问题之维特比算法(Viterbi Algorithm)的Python实现
☕️ 本文系列文章汇总:
(1)HMM开篇:基本概念和几个要素
(2)HMM计算问题:前后向算法
代码实现
(3)HMM学习问题:Baum-Welch算法
代码实现
(4) HMM预测问题:维特比算法本篇算法原理分析及公式推导请参考:HMM预测问题:维特比算法
目录
1. 模型参数估计
2. 维特比实现
3. 完整代码Github
4. 实例
事实上维特比算法属于隐马尔科夫模型的“应用篇”,特别是在NLP的分词领域,维特比算法无处不在。我们先需要根据HMM的学习算法来学习得到一个模型λ=(π,A,B),然后再通过这个模型,利用维特比算法对数据进行预测。本篇基于维特比算法实现一个简单的分词器,有助于大家深入理解。
1. 模型参数估计
我们先通过训练集来估计出一个模型。训练集是一堆已经分好词的文本,一行一条训练样本。在训练集中,我们的观测数据是每一个字,我们的状态是每一个字对应的分词标志,一共有4种状态:S,表示单字成词;B,表示一个分出来的词的起始字;M,表示一个分出来的词的中间字;E,表示一个分出来的词的结尾字。例如:
说|什么|难过|,|只不过|是|一次|错过
S|BE|BE|S|BME|S|BE|BE
注意,由于我们的训练集包含了事实上包含了观测值和状态值,因此我们不需要用无监督的Baum Welch算法来学习模型,只需要简单的有监督统计方法来估计模型参数即可,这个思想主要用到《统计学习方法》中10.3.1节中提到的方法。
class Model:"""模型的参数估计,非Baum Welch算法,而是采用有监督的统计方法"""def __init__(self, trainfile, N, M, Q):"""初始化一些参数:param trainfile: 训练集路径:param N: 所有可能的状态数:param M: 所有可能的观测数:param Q: 所有可能的状态"""self.trainfile = trainfileself.N = Nself.M = Mself.Pi = np.zeros(N)self.A = np.zeros((N, N))self.B = np.zeros((N, M))# 用id来表示每个状态self.Q2id = {x: i for i, x in enumerate(Q)}def cal_rate(self):"""通过【10.3.1】节的内容来计算π、A、B中各个元素的频数;:return:"""reader = dataloader(self.trainfile)for i, line in enumerate(reader):line = line.strip().strip('\n')if not line:continueword_list = line.split(' ')status_sequence = []# 计算π和B中每个元素的频数for j, item in enumerate(word_list):if len(item) == 1:flag = 'S'else:flag = 'B' + 'M' * (len(item) - 2) + 'E'if j == 0:# 初始状态π的值是每条样本第一个字的状态出现的次数;self.Pi[self.Q2id[flag[0]]] += 1for t, s in enumerate(flag):# B有几行就代表有几种状态,每一列代表该状态下每种观测生成的次数;self.B[self.Q2id[s]][ord(item[t])] += 1# 构建状态序列status_sequence.extend(flag)# 计算A元素的频数for t, s in enumerate(status_sequence):# A[i][j]表示由上一时刻的状态i转移到当前时刻状态j的次数prev = status_sequence[t - 1]self.A[self.Q2id[prev]][self.Q2id[s]] += 1def generate_model(self):"""构建模型参数:主要是将频数表示的模型参数转化成频率表示的模型参数,在本代码中,利用"频数/总数"来表示各个参数中的值,取log是为了将乘法计算改为加法计算,这样可以便于计算,且防止乘积过小的情况;:return:"""self.cal_rate()norm = -2.718e+16denominator = sum(self.Pi)for i, pi in enumerate(self.Pi):if pi == 0.:self.Pi[i] = normelse:self.Pi[i] = np.log(pi / denominator)# 公式【10.30】for row in range(self.A.shape[0]):denominator = sum(self.A[row])for col, a in enumerate(self.A[row]):if a == 0.:self.A[row][col] = normelse:self.A[row][col] = np.log(a / denominator)# 公式【10.31】for row in range(self.B.shape[0]):denominator = sum(self.B[row])for col, b in enumerate(self.B[row]):if b == 0.:self.B[row][col] = normelse:self.B[row][col] = np.log(b / denominator)return AttrDict(pi=self.Pi,A=self.A,B=self.B)2. 维特比实现
这一部分的代码完全是按照课本中算法流程【10.5】中的步骤来的,注意矩阵的运算正确即可。
class Viterbi:def __init__(self, model: dict):"""初始化一些参数:param model: 由训练而成的模型作为维特比算法预测依据"""self.pi = model.piself.A = model.Aself.B = model.Bdef predict(self, datapath):"""根据算法【10.5】生成预测序列:param datapath: 测试集路径:return:"""reader = dataloader(datapath)self.O = [line.strip().strip('\n') for line in reader]N = self.pi.shape[0]self.segs = []for o in self.O:o = [w for w in o if w]if not o:self.segs.append([])continueT = len(o)# 定义δ和ψdelta_t = np.zeros((T, N))psi_t = np.zeros((T, N))for t in range(T):if not t:# t=1时,根据算法【10.5】第(1)步,计算δ_{1}和ψ_{1}delta_t[t][:] = self.pi + self.B.T[:][ord(o[0])] # 由于log转换,所以原先的*变成+psi_t[t][:] = np.zeros((1, N))else:# 根据算法【10.5】第(2)步,递推计算δ_{t}和ψ_{t}deltaTemp = delta_t[t - 1] + self.A.Tfor i in range(N):delta_t[t][i] = max(deltaTemp[:][i]) + self.B[i][ord(o[t])]psi_t[t][i] = np.argmax(deltaTemp[:][i])I = []# 当计算完所有δ和ψ后,找到T时刻的δ中的最大值的索引,即算法【10.5】第(3)步中的i*_{T}maxNode = np.argmax(delta_t[-1][:])I.append(int(maxNode))for t in range(T - 1, 0, -1):# 算法【10.5】第(4)步,回溯找i*_{t}maxNode = int(psi_t[t][maxNode])I.append(maxNode)I.reverse()self.segs.append(I)def segment(self):"""根据状态序列对句子进行分词:return: 分词结果列表"""segments = []for i, line in enumerate(self.segs):curText = ""temp = []for j, w in enumerate(line):if w == 0:# 如果该字的状态为"S",为单字temp.append(self.O[i][j])else:if w != 3:# 如果该字的状态不为"E",那么要么为"B",要么为"M",说明一个词还没结束;curText += self.O[i][j]else:# 遇到结束状态符"E"时,该词分词结束;curText += self.O[i][j]temp.append(curText)curText = ''segments.append(temp)return segments3. 完整代码Github
import numpy as npclass AttrDict(dict):# 一个小trick,将结果返回成一个字典格式def __init__(self, *args, **kwargs):super(AttrDict, self).__init__(*args, **kwargs)self.__dict__ = selfdef dataloader(datapath):with open(datapath, 'r') as reader:for line in reader:yield lineclass Model:"""模型的参数估计,非Baum Welch算法,而是采用有监督的统计方法"""def __init__(self, trainfile, N, M, Q):"""初始化一些参数:param trainfile: 训练集路径:param N: 所有可能的状态数:param M: 所有可能的观测数:param Q: 所有可能的状态"""self.trainfile = trainfileself.N = Nself.M = Mself.Pi = np.zeros(N)self.A = np.zeros((N, N))self.B = np.zeros((N, M))# 用id来表示每个状态self.Q2id = {x: i for i, x in enumerate(Q)}def cal_rate(self):"""通过【10.3.1】节的内容来计算π、A、B中各个元素的频数;:return:"""reader = dataloader(self.trainfile)for i, line in enumerate(reader):line = line.strip().strip('\n')if not line:continueword_list = line.split(' ')status_sequence = []# 计算π和B中每个元素的频数for j, item in enumerate(word_list):if len(item) == 1:flag = 'S'else:flag = 'B' + 'M' * (len(item) - 2) + 'E'if j == 0:# 初始状态π的值是每条样本第一个字的状态出现的次数;self.Pi[self.Q2id[flag[0]]] += 1for t, s in enumerate(flag):# B有几行就代表有几种状态,每一列代表该状态下每种观测生成的次数;self.B[self.Q2id[s]][ord(item[t])] += 1# 构建状态序列status_sequence.extend(flag)# 计算A元素的频数for t, s in enumerate(status_sequence):# A[i][j]表示由上一时刻的状态i转移到当前时刻状态j的次数prev = status_sequence[t - 1]self.A[self.Q2id[prev]][self.Q2id[s]] += 1def generate_model(self):"""构建模型参数:主要是将频数表示的模型参数转化成频率表示的模型参数,在本代码中,利用"频数/总数"来表示各个参数中的值,取log是为了将乘法计算改为加法计算,这样可以便于计算,且防止乘积过小的情况;:return:"""self.cal_rate()norm = -2.718e+16denominator = sum(self.Pi)for i, pi in enumerate(self.Pi):if pi == 0.:self.Pi[i] = normelse:self.Pi[i] = np.log(pi / denominator)# 公式【10.30】for row in range(self.A.shape[0]):denominator = sum(self.A[row])for col, a in enumerate(self.A[row]):if a == 0.:self.A[row][col] = normelse:self.A[row][col] = np.log(a / denominator)# 公式【10.31】for row in range(self.B.shape[0]):denominator = sum(self.B[row])for col, b in enumerate(self.B[row]):if b == 0.:self.B[row][col] = normelse:self.B[row][col] = np.log(b / denominator)return AttrDict(pi=self.Pi,A=self.A,B=self.B)class Viterbi:def __init__(self, model: dict):"""初始化一些参数:param model: 由训练而成的模型作为维特比算法预测依据"""self.pi = model.piself.A = model.Aself.B = model.Bdef predict(self, datapath):"""根据算法【10.5】生成预测序列:param datapath: 测试集路径:return:"""reader = dataloader(datapath)self.O = [line.strip().strip('\n') for line in reader]N = self.pi.shape[0]self.segs = []for o in self.O:o = [w for w in o if w]if not o:self.segs.append([])continueT = len(o)# 定义δ和ψdelta_t = np.zeros((T, N))psi_t = np.zeros((T, N))for t in range(T):if not t:# t=1时,根据算法【10.5】第(1)步,计算δ_{1}和ψ_{1}delta_t[t][:] = self.pi + self.B.T[:][ord(o[0])] # 由于log转换,所以原先的*变成+psi_t[t][:] = np.zeros((1, N))else:# 根据算法【10.5】第(2)步,递推计算δ_{t}和ψ_{t}deltaTemp = delta_t[t - 1] + self.A.Tfor i in range(N):delta_t[t][i] = max(deltaTemp[:][i]) + self.B[i][ord(o[t])]psi_t[t][i] = np.argmax(deltaTemp[:][i])I = []# 当计算完所有δ和ψ后,找到T时刻的δ中的最大值的索引,即算法【10.5】第(3)步中的i*_{T}maxNode = np.argmax(delta_t[-1][:])I.append(int(maxNode))for t in range(T - 1, 0, -1):# 算法【10.5】第(4)步,回溯找i*_{t}maxNode = int(psi_t[t][maxNode])I.append(maxNode)I.reverse()self.segs.append(I)def segment(self):"""根据状态序列对句子进行分词:return: 分词结果列表"""segments = []for i, line in enumerate(self.segs):curText = ""temp = []for j, w in enumerate(line):if w == 0:# 如果该字的状态为"S",为单字temp.append(self.O[i][j])else:if w != 3:# 如果该字的状态不为"E",那么要么为"B",要么为"M",说明一个词还没结束;curText += self.O[i][j]else:# 遇到结束状态符"E"时,该词分词结束;curText += self.O[i][j]temp.append(curText)curText = ''segments.append(temp)return segments4. 实例
if __name__ == '__main__':# 我们用编码表示汉字字符,用`ord()`方法获得汉字编码,所以构建所有可能观测值的数为65536,保证所有字都能覆盖到;# S:单字表示符;# B:一个词的起始符;# M:一个属于一个词中间字的标识;# E:一个词的结束符;trainer = Model(N=4, M=65536, Q=['S', 'B', 'M', 'E'], trainfile='train.txt')model = trainer.generate_model()segment = Viterbi(model)segment.predict('test.txt')print(segment.segment())我们的训练集大概长这样:

给一条测试数据:
![]()
分词后:
[['他', '强调', ',', '党校', '始终', '不', '变', '的', '初心', '就', '是', '为', '党育', '才', '、', '为', '党', '献策', '。', '各级', '党校', '要', '坚守', '这个', '初心', ',锐', '意', '进', '取', '、', '奋发', '有', '为', ',', '为', '全', '面建', '设社', '会', '主义现', '代化国', '家', '、', '全面', '推进', '中华', '民族', '伟大', '复兴', '作', '出', '新', '的', '贡献', '。']]
可以看出,这是一般非常粗糙的分词器,虽然有些词分的不准,但是总体上还是可以的。由于我们的模型参数估计方法不是自发的学习过程,所以对于语料的依赖特别强,语料中没见过的词,就可能分错。
相关文章:

用Python自己写一个分词器,python实现分词功能,隐马尔科夫模型预测问题之维特比算法(Viterbi Algorithm)的Python实现
☕️ 本文系列文章汇总: (1)HMM开篇:基本概念和几个要素 (2)HMM计算问题:前后向算法 代码实现 (3)HMM学习问题:Baum-Welch算法 代码实现(…...
刷题笔记2 | 977.有序数组的平方 ,209.长度最小的子数组 ,59.螺旋矩阵II ,总结
977.有序数组的平方 给你一个按 非递减顺序 排序的整数数组 nums,返回 每个数字的平方 组成的新数组,要求也按 非递减顺序 排序。 输入:nums [-4,-1,0,3,10] 输出:[0,1,9,16,100] 解释:平方后,数组变为 […...
python 支付宝营销活动现金红包开发接入流程-含接口调用加签
1 创建网页/移动应用 2 配置接口加签方式 涉及到金额的需要上传证书,在上传页面有教程, 在支付宝开放平台秘钥工具中生成CSR证书,会自动保存应用公钥和私钥到电脑上,调用支付宝接口需要应用私钥进行加签 上传完CSR证书后会有三个…...

Python操作Windows
用python进行windows端UI自动化的库有很多,比如pywinauto等,本文介绍一个使用autoit3来实现的 pyautoit 库pyautoit 是一个用python写的基于AutoItX3.dll的接口库,用来进行windows窗口的一系列操作,也支持鼠标键盘的操作。安装pip…...
)
Aptos SDK交互笔记(一)
背景 之前我们已经了解TS的一些语法,接下来可以实战训练下,这系列的文章就会介绍如何通过Aptos官网提供的TypeScript SDK与Aptos进行交互,这篇文章主要讲的就是如何使用提供API在aptos区块链上转帐。 官网示例 官网提供了交互的例子&#…...
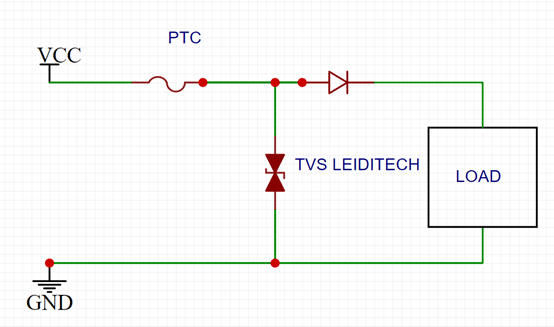
汽车 12V 和 24V 电池输入保护推荐
简介汽车电池电源线路在运行系统时容易出现瞬变。所需的典型保护包括过压、过载、反极性和跨接启动。在汽车 的生命周期中,交流发电机可能会被更换为非OEM 部件。售后市场上的交流发电机可能具有不同的负载突降(LOAD DUMP)保护或没有负载突降…...

龙蜥LoongArch架构研发全揭秘,龙芯开辟龙腾计划技术合作新范式
编者按:在开源新基建加快建设的背景下,越来越多的企业选择加入龙蜥社区,当前社区生态合作伙伴已突破 300 家。于是,龙蜥社区能为加入的企业提供哪些支持成为越多伙伴们更加关注的话题。本文将以龙蜥社区和龙芯中科联合研发龙蜥 Lo…...

剑指 Offer 16. 数值的整数次方
摘要 剑指 Offer 16. 数值的整数次方 本题的方法被称为快速幂算法,有递归和迭代两个版本。这篇题解会从递归版本的开始讲起,再逐步引出迭代的版本。当指数n为负数时,我们可以计算 x^(-n)再取倒数得到结果,因此我们只需要考虑n为…...
在苹果电脑 mac 上安装原神(playCover)
该方法只能在 M1、M2 mac 上安装原神 目录前言一、首先下载安装 playCover1. playCover 下载2. playCover 安装安装出现问题解决方法二、下载安装原神1.安装包下载2.安装原神三、登录、键盘映射及版本更新等问题登录键盘映射版本更新前言 最近买了新的mac,作者本人…...

数据结构考研习题精选
1 A假设比较t次,由于换或不换,则必然有2^t种可能。又设有n个关键字,n!排列组合,则必然有2^t&…...
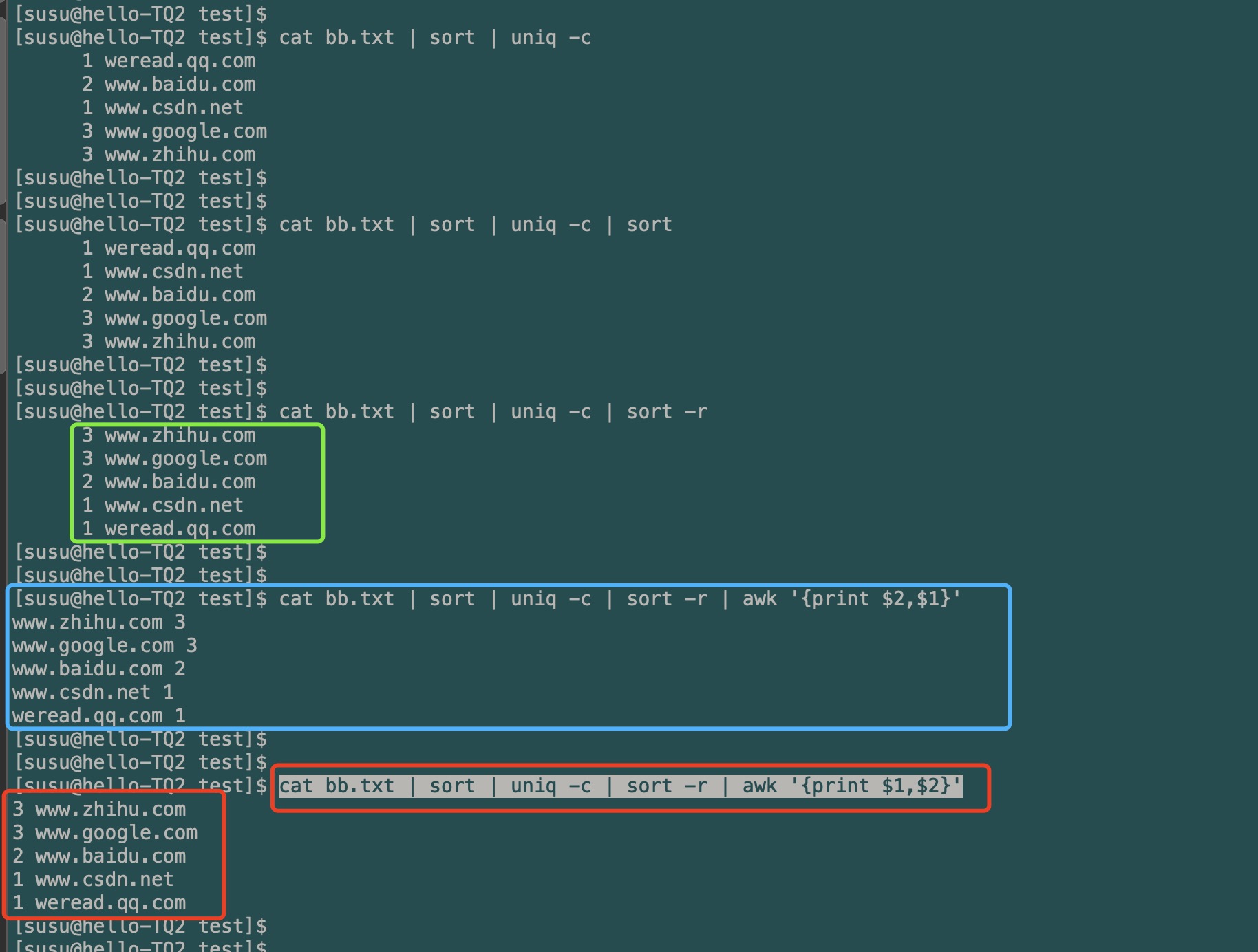
linux常用命令介绍 04 篇——uniq命令使用介绍(Linux重复数据的统计处理)
linux常用命令介绍 04 篇——uniq命令使用介绍(Linux重复数据的统计处理)1. uniq 使用语法2. sort 简单效果3. uniq 使用例子3.1 不加任何选项3.1.1 不用 sort 效果3.1.2 uniq 结合 sort 一起使用3.2 使用选项例子3.2.1 去重打印(或打印不重复…...
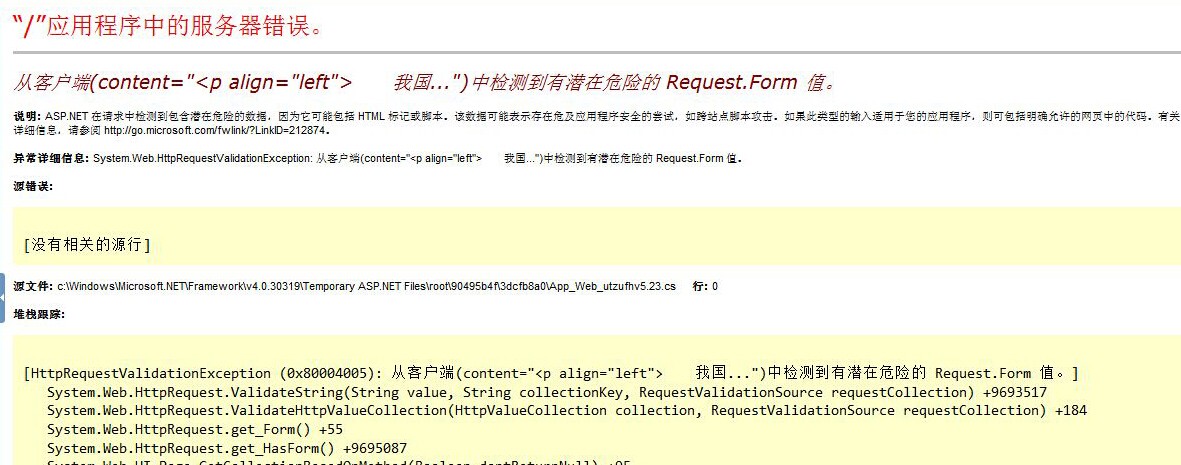
网站打不开数据库错误等常见问题解决方法
1、“主机开设成功!”上传数据后显示此内容,是因为西部数码默认放置的index.htm内容,需要核实wwwroot目录里面是否有自己的程序文件,可以删除index.htm。 2、恭喜,lanmp安装成功!这个页面是wdcp的默认页面&…...

爬虫实战进阶版【1】——某眼专业版实时票房接口破解
某眼专业版-实时票房接口破解 某眼票房接口:https://piaofang.maoyan.com/dashboard-ajax 前言 当我们想根据某眼的接口获取票房信息的时候,发现它的接口处的参数是加密的,如下图: 红色框框的参数都是动态变化的,且signKey明显是加密的一个参数。对于这种加密的参数,我们需要…...

大话数据结构-普里姆算法(Prim)和克鲁斯卡尔算法(Kruskal)
5 最小生成树 构造连通网的最小代价生成树称为最小生成树,即Minimum Cost Spanning Tree,最小生成树通常是基于无向网/有向网构造的。 找连通网的最小生成树,经典的有两种算法,普里姆算法和克鲁斯卡尔算法。 5.1 普里姆ÿ…...
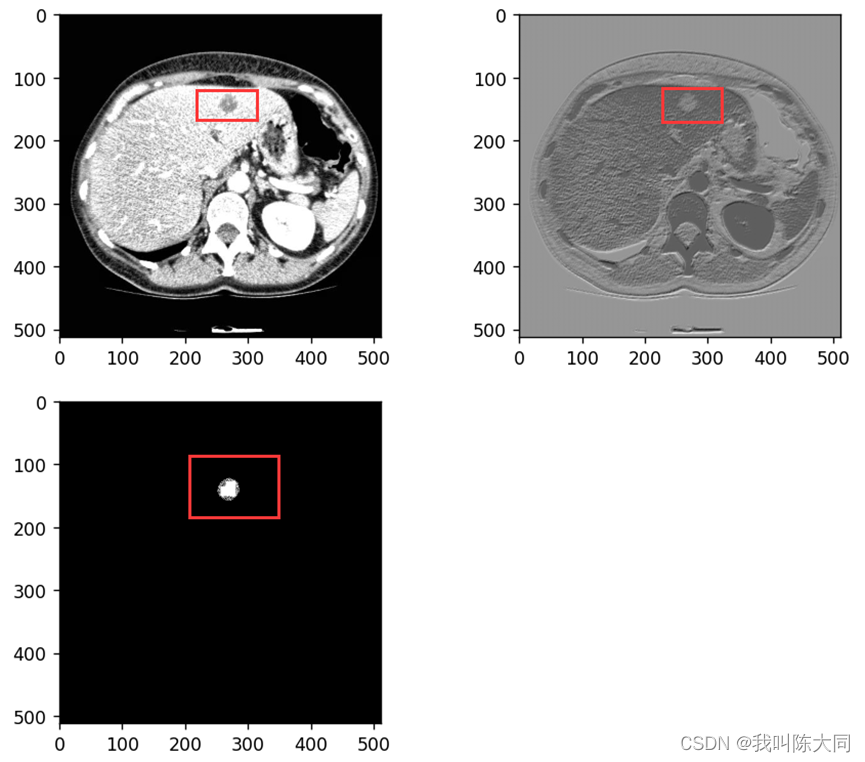
UNet-肝脏肿瘤图像语义分割
目录 一. 语义分割 二. 数据集 三. 数据增强 图像数据处理步骤 CT图像增强方法 :windowing方法 直方图均衡化 获取掩膜图像深度 在肿瘤CT图中提取肿瘤 保存肿瘤数据 四. 数据加载 数据批处理 编辑编辑 数据集加载 五. UNet神经网络模型搭建 单张图片…...

三周爆赚千万 电竞选手在无聊猿游戏赢麻了
如何用3个星期赚到1千万?普通人做梦都不敢想的事,电竞职业选手Mongraal却用几把游戏轻易完成,赚钱地点是蓝筹NFT项目Bored Ape Yacht Club(BAYC无聊猿)出品的新游戏Dookey Dash。 这款游戏类似《神庙逃亡》࿰…...

BERT学习
非精读BERT-b站有讲解视频(跟着李沐学AI) (大佬好厉害,讲的比直接看论文容易懂得多) 写在前面 在计算MLM预训练任务的损失函数的时候,参与计算的Tokens有哪些?是全部的15%的词汇还是15%词汇中真…...
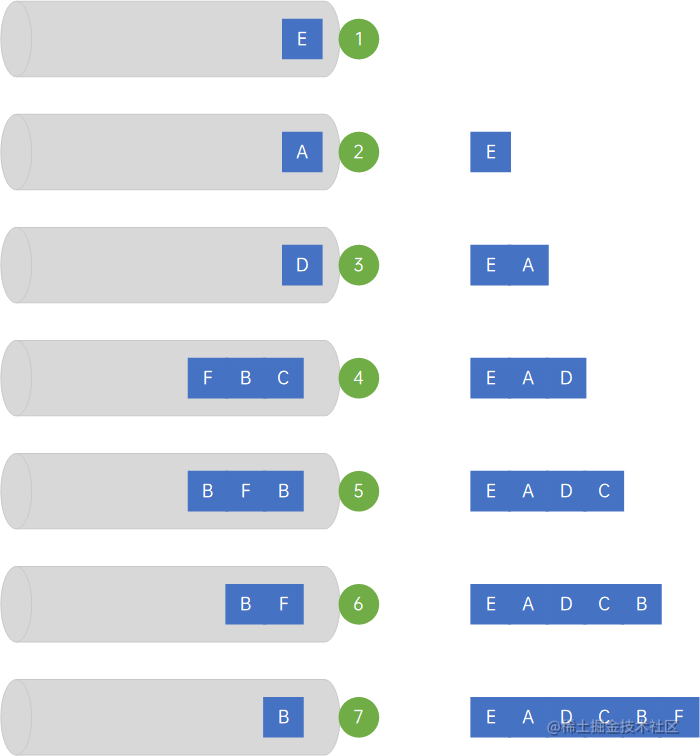
大话数据结构-图的深度优先遍历和广度优先遍历
4 图的遍历 图的遍历分为深度优先遍历和广度优先遍历两种。 4.1 深度优先遍历 深度优先遍历(Depth First Search),也称为深度优先搜索,简称DFS,深度优先遍历,是指从某一个顶点开始,按照一定的规…...

c语言指针怎么理解 第一部分
不理解指针,是因为有人教错了你。 有人告诉你,指针是“指向”某某某的,那就是误导你,给你挖了个坑。初学者小心不要误读这“指向”二字。 第一,“指针”通常用于保存一个地址,这个地址的数据类型在定义指…...
计算机网络安全基础知识2:http超文本传输协议,请求request消息的get和post,响应response消息的格式,响应状态码
计算机网络安全基础知识: 2022找工作是学历、能力和运气的超强结合体,遇到寒冬,大厂不招人,可能很多算法学生都得去找开发,测开 测开的话,你就得学数据库,sql,oracle,尤…...

TikTok风控核心:X-Gorgon协议算法逆向与变种RC4的魔改细节揭秘
TikTok风控体系深度解析:X-Gorgon协议与魔改RC4算法实战 在移动互联网安全攻防领域,应用层协议逆向工程始终是技术对抗的前沿阵地。本文将深入剖析TikTok风控体系中的核心组件X-Gorgon协议,重点解密其基于RC4算法的深度定制化改造方案。不同于…...

后端开发必懂:接口设计、权限、日志、异常处理全套思路
后端开发必懂:接口设计、权限、日志、异常处理全套思路在后端开发的征途中,新手往往沉迷于框架的语法和数据库的CRUD,而资深工程师则更关注系统的健壮性、可维护性和安全性。接口设计、权限控制、日志记录和异常处理,构成了后端架…...

2026年代理IP与指纹浏览器协同架构及网络安全优化方案
一、引言在 2026 年的多账号安全运营体系中,代理 IP 与指纹浏览器已经形成高度耦合的整体架构。代理 IP 负责提供网络身份,指纹浏览器负责提供设备身份,两者协同工作,才能构建完整、安全、真实的虚拟环境。实际运营中,…...

1. LangGraph 综述
Langgraph 系统教程(基于 1.1.X 版本) LangGraph 综述 LangGraph 安装指南 LangGraph 快速入门 用 LangGraph 的思维构建智能体 LangGraph 工作流与智能体详解...

《2026 Python零基础入门:用AI主题学编程》第十一课:简单 AI Agent 雏形——判断用户意图 + 调用不同 prompt / 工具,实现更智能的交互
大家好,我是链上杯子(CSDN:链上杯子)。失业一年了,天天想着怎么翻身。最近的多轮对话虽然能聊了,但模型每次都用同一套风格回复,总觉得不够“聪明”。如果能让程序先判断用户想干什么࿰…...

2026年专科生必看!千笔·降AI率助手,最受欢迎的降AI率网站
在AI技术迅速发展的今天,越来越多的学生和研究人员开始依赖AI工具辅助论文写作。然而,随着知网、维普、万方等查重系统不断升级算法,以及Turnitin对AIGC(人工智能生成内容)的识别愈发严格,AI率超标问题正成…...

安装虚拟机详细教程!!!
...

VibeVoice推理优化终极指南:如何减少内存占用并提升语音生成速度
VibeVoice推理优化终极指南:如何减少内存占用并提升语音生成速度 【免费下载链接】VibeVoice Open-Source Frontier Voice AI 项目地址: https://gitcode.com/GitHub_Trending/vib/VibeVoice VibeVoice作为开源前沿语音AI项目,在提供高质量语音生…...

Swift控制流终极指南:掌握if、guard、switch的最佳写法与实践技巧
Swift控制流终极指南:掌握if、guard、switch的最佳写法与实践技巧 【免费下载链接】swift-style-guide The official Swift style guide for Kodeco. 项目地址: https://gitcode.com/gh_mirrors/sw/swift-style-guide Swift作为一门现代编程语言,…...
高德地图API集成指南:使用coordTransform_py实现地址到坐标的精准转换
高德地图API集成指南:使用coordTransform_py实现地址到坐标的精准转换 【免费下载链接】coordTransform_py 提供百度坐标系(bd-09)、火星坐标系(国测局坐标系、gcj02)、WGS84坐标系直接的坐标互转,也提供了解析高德地址的方法的python版本 项目地址: h…...