Netty-2-数据编解码
解析编解码支持的原理
以编码为例,要将对象序列化成字节流,你可以使用MessageToByteEncoder或MessageToMessageEncoder类。
这两个类都继承自ChannelOutboundHandlerAdapter适配器类,用于进行数据的转换。
其中,对于MessageToMessageEncoder来说,如果把口标设置为ByteBuf,那么效果等同于使用MessageToByteEncodero这就是它们都可以进行数据编码的原因。
//MessageToMessageEncoder@Overridepublic void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {// 创建一个CodecOutputList对象,并将其初始化为nullCodecOutputList out = null;try {// 检查消息是否满足输出条件if (acceptOutboundMessage(msg)) {// 创建一个CodecOutputList对象,并将其赋值给out变量out = CodecOutputList.newInstance();// 将msg强制转换为I类型,并赋值给cast变量@SuppressWarnings("unchecked")I cast = (I) msg;try {// 调用encode方法,将ctx、cast和out作为参数传入encode(ctx, cast, out);} catch (Throwable th) {// 释放cast的引用计数ReferenceCountUtil.safeRelease(cast);// 抛出异常PlatformDependent.throwException(th);}// 释放cast的引用计数ReferenceCountUtil.release(cast);// 检查out是否为空if (out.isEmpty()) {// 抛出编码异常throw new EncoderException(StringUtil.simpleClassName(this) + " must produce at least one message.");}} else {// 直接将msg写入通道ctx.write(msg, promise);}} catch (EncoderException e) {// 抛出编码异常throw e;} catch (Throwable t) {// 抛出编码异常throw new EncoderException(t);} finally {// 最终,释放out的引用计数if (out != null) {try {// 获取out的元素个数final int sizeMinusOne = out.size() - 1;if (sizeMinusOne == 0) {// 将out的第一个元素直接写入通道ctx.write(out.getUnsafe(0), promise);} else if (sizeMinusOne > 0) {// 检查promise是否为voidPromiseif (promise == ctx.voidPromise()) {// 使用voidPromise来减少GC压力writeVoidPromise(ctx, out);} else {// 使用writePromiseCombiner方法来减少GC压力writePromiseCombiner(ctx, out, promise);}}} finally {// 释放out的资源out.recycle();}}}}protected abstract void encode(ChannelHandlerContext ctx, I msg, List<Object> out) throws Exception;
最终的目标是把对象转换为ByteBuf,具体的转换代码则委托子类继承的encode方法来实现。
Netty提供了很多子类来支持前面提及的各种数据编码方式。
解析典型Netty数据编解码的实现
HttpObjectEncoder编码器
//HttpObjectEncoder编码器@Override@SuppressWarnings("ConditionCoveredByFurtherCondition")protected void encode(ChannelHandlerContext ctx, Object msg, List<Object> out) throws Exception {// 为了处理不需要类检查的常见模式的fast-pathif (msg == Unpooled.EMPTY_BUFFER) {out.add(Unpooled.EMPTY_BUFFER);return;}// 以这种顺序进行instanceof检查的原因是,不依赖于ReferenceCountUtil::release作为一种通用释放机制,// 参见https://bugs.openjdk.org/browse/JDK-8180450。// https://github.com/netty/netty/issues/12708包含有关先前版本的此代码如何与JIT instanceof优化交互的更多详细信息。if (msg instanceof FullHttpMessage) {encodeFullHttpMessage(ctx, msg, out);return;}// 判断msg是否为HttpMessage的实例if (msg instanceof HttpMessage) {final H m;try {// 将msg转换为H类型m = (H) msg;} catch (Exception rethrow) {// 出现异常时,释放msg的引用计数并抛出异常ReferenceCountUtil.release(msg);throw rethrow;}// 判断m是否为LastHttpContent的实例if (m instanceof LastHttpContent) {// 调用encodeHttpMessageLastContent方法对LastHttpContent进行编码encodeHttpMessageLastContent(ctx, m, out);} // 判断m是否为HttpContent的实例else if (m instanceof HttpContent) {// 调用encodeHttpMessageNotLastContent方法对HttpContent进行编码encodeHttpMessageNotLastContent(ctx, m, out);} // m既不是LastHttpContent也不是HttpContent的实例else {// 调用encodeJustHttpMessage方法对m进行编码encodeJustHttpMessage(ctx, m, out);}} // msg不是HttpMessage的实例else {// 调用encodeNotHttpMessageContentTypes方法对非HttpMessage的内容类型进行编码encodeNotHttpMessageContentTypes(ctx, msg, out);}}HttpObjectDecoder解码器
//HttpObjectDecoder.java/*** 定义了一个私有枚举类型State,表示不同的状态*/private enum State {/*** 用于跳过控制字符*/SKIP_CONTROL_CHARS,/*** 读取初始内容*/READ_INITIAL,/*** 读取头部信息*/READ_HEADER,/*** 读取可变长度的内容*/READ_VARIABLE_LENGTH_CONTENT,/*** 读取固定长度的内容*/READ_FIXED_LENGTH_CONTENT,/*** 读取分块大小*/READ_CHUNK_SIZE,/*** 读取分块内容*/READ_CHUNKED_CONTENT,/*** 读取分块分隔符*/READ_CHUNK_DELIMITER,/*** 读取分块脚注*/READ_CHUNK_FOOTER,/*** 错误消息*/BAD_MESSAGE,/*** 升级协议*/UPGRADED}//解码器相应实现@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf buffer, List<Object> out) throws Exception {// 如果 resetRequested 为真if (resetRequested) {// 调用 resetNow() 方法resetNow();}switch (currentState) {case SKIP_CONTROL_CHARS:// 跳过控制字符case READ_INITIAL: try {// 解析缓冲区中的数据AppendableCharSequence line = lineParser.parse(buffer);if (line == null) {return;}// 拆分初始行String[] initialLine = splitInitialLine(line);if (initialLine.length < 3) {// 初始行无效 - 忽略currentState = State.SKIP_CONTROL_CHARS;return;}// 创建消息对象message = createMessage(initialLine);currentState = State.READ_HEADER;// 继续读取头部} catch (Exception e) {// 处理异常情况out.add(invalidMessage(buffer, e));return;}case READ_HEADER: try {State nextState = readHeaders(buffer);if (nextState == null) {return;}currentState = nextState;switch (nextState) {case SKIP_CONTROL_CHARS:// 快速路径// 无需期望任何内容out.add(message);out.add(LastHttpContent.EMPTY_LAST_CONTENT);resetNow();return;case READ_CHUNK_SIZE:if (!chunkedSupported) {throw new IllegalArgumentException("不支持分块消息");}// 分块编码 - 首先生成HttpMessage。后续将跟随HttpChunks。out.add(message);return;default:/*** <a href="https://tools.ietf.org/html/rfc7230#section-3.3.3">RFC 7230, 3.3.3</a> 规定,如果请求没有传输编码头或内容长度头,则消息体长度为0。* 但是对于响应,body长度是在服务器关闭连接之前接收到的字节数目。因此我们将此情况视为可变长度的分块编码。*/long contentLength = contentLength();if (contentLength == 0 || contentLength == -1 && isDecodingRequest()) {out.add(message);out.add(LastHttpContent.EMPTY_LAST_CONTENT);resetNow();return;}assert nextState == State.READ_FIXED_LENGTH_CONTENT ||nextState == State.READ_VARIABLE_LENGTH_CONTENT;out.add(message);if (nextState == State.READ_FIXED_LENGTH_CONTENT) {// 随着READ_FIXED_LENGTH_CONTENT状态逐块读取数据,分块大小将减小。chunkSize = contentLength;}// 在这里返回,这将强制再次调用解码方法,在那里我们将解码内容return;}} catch (Exception e) {out.add(invalidMessage(buffer, e));return;}case READ_VARIABLE_LENGTH_CONTENT: {// 一直读取数据直到连接结束。int toRead = Math.min(buffer.readableBytes(), maxChunkSize);if (toRead > 0) {// 从缓冲区中读取指定长度的数据,并以保留引用的形式分割成多个片段ByteBuf content = buffer.readRetainedSlice(toRead);out.add(new DefaultHttpContent(content));}return;}case READ_FIXED_LENGTH_CONTENT: {int readLimit = buffer.readableBytes();// 首先检查缓冲区是否可读,因为我们使用可读字节计数来创建HttpChunk。需要这样做,以防止创建包含空缓冲区的HttpChunk,从而被当作最后一个HttpChunk进行处理。// 参见:https://github.com/netty/netty/issues/433if (readLimit == 0) {return;}int toRead = Math.min(readLimit, maxChunkSize);if (toRead > chunkSize) {toRead = (int) chunkSize;}ByteBuf content = buffer.readRetainedSlice(toRead);chunkSize -= toRead;if (chunkSize == 0) {// 读取所有内容。out.add(new DefaultLastHttpContent(content, validateHeaders));resetNow();} else {out.add(new DefaultHttpContent(content));}return;}/*** 从这里开始处理读取分块的内容。基本上,读取分块大小,读取分块,忽略CRLF,然后重复直到分块大小为0*/case READ_CHUNK_SIZE: try {AppendableCharSequence line = lineParser.parse(buffer);if (line == null) {return;}int chunkSize = getChunkSize(line.toString());this.chunkSize = chunkSize;if (chunkSize == 0) {currentState = State.READ_CHUNK_FOOTER;return;}currentState = State.READ_CHUNKED_CONTENT;// fall-through} catch (Exception e) {out.add(invalidChunk(buffer, e));return;}case READ_CHUNKED_CONTENT: {// 判断chunkSize是否小于等于Integer的最大值assert chunkSize <= Integer.MAX_VALUE;// 计算本次需要读取的字节数,取chunkSize和maxChunkSize中的较小值int toRead = Math.min((int) chunkSize, maxChunkSize);// 如果不允许部分chunk,且buffer中可读取的字节数小于toRead,则返回if (!allowPartialChunks && buffer.readableBytes() < toRead) {return;}// 如果buffer中可读取的字节数小于toRead,则将toRead更新为buffer中可读取的字节数toRead = Math.min(toRead, buffer.readableBytes());// 如果toRead为0,则返回if (toRead == 0) {return;}// 从buffer中获取长度为toRead的slice,并用其创建HttpContent对象HttpContent chunk = new DefaultHttpContent(buffer.readRetainedSlice(toRead));// 更新剩余的chunkSizechunkSize -= toRead;// 将chunk添加到out中// 如果chunkSize不为0,则返回if (chunkSize != 0) {return;}// 设置当前状态为READ_CHUNK_DELIMITERcurrentState = State.READ_CHUNK_DELIMITER;// 继续执行下一个case语句// fall-through}case READ_CHUNK_DELIMITER: {// 读取分隔符final int wIdx = buffer.writerIndex();int rIdx = buffer.readerIndex();while (wIdx > rIdx) {byte next = buffer.getByte(rIdx++);if (next == HttpConstants.LF) {currentState = State.READ_CHUNK_SIZE;break;}}buffer.readerIndex(rIdx);return;}case READ_CHUNK_FOOTER: {try {// 读取尾部的Http头部信息LastHttpContent trailer = readTrailingHeaders(buffer);if (trailer == null) {return;}out.add(trailer);resetNow();return;} catch (Exception e) {// 发生异常时,将异常信息和当前buffer一起添加到输出channelout.add(invalidChunk(buffer, e));return;}}case BAD_MESSAGE: {// 直到断开连接为止,丢弃消息buffer.skipBytes(buffer.readableBytes());break;}case UPGRADED: {int readableBytes = buffer.readableBytes();if (readableBytes > 0) {// 读取可读字节数,如果大于0,则执行以下操作// 由于否则可能会触发一个DecoderException异常,其他处理器会在某个时刻替换此codec为升级的协议codec来接管流量。// 参见 https://github.com/netty/netty/issues/2173out.add(buffer.readBytes(readableBytes));}break;}default:break;}}自定义编解码
下面先实现一个Netty编码处理程序。
public class OrderProtocolEncoder extends MessageToMessageEncoder<ResponseMessage> {/*** 编码器类,用于将ResponseMessage对象编码为ByteBuf对象并添加到输出列表中*/@Overrideprotected void encode(ChannelHandlerContext ctx, ResponseMessage responseMessage, List<Object> out) throws Exception {/*** 获取一个ByteBuf对象用于存储编码后的数据*/ByteBuf buffer = ctx.alloc().buffer();/*** 对ResponseMessage对象进行编码,并将编码后的数据写入ByteBuf对象中*/responseMessage.encode(buffer);/*** 将编码后的ByteBuf对象添加到输出列表中*/out.add(buffer);}
}接下来,再实现对应的Netty解码处理程序。
/*** 订单协议解码器*/
public class OrderProtocolDecoder extends MessageToMessageDecoder<ByteBuf> {@Overrideprotected void decode(ChannelHandlerContext ctx, ByteBuf byteBuf, List<Object> out) throws Exception {// 创建一个请求消息对象RequestMessage requestMessage = new RequestMessage();// 对字节缓冲区进行解码,将解码后的消息填充到请求消息对象中requestMessage.decode(byteBuf);// 将请求消息对象添加到输出列表中out.add(requestMessage);}
}最后,将这对编解码处理程序添加到处理程序流水线(pipeline)中就可以完成集成工作了。
这是我们第一次提及处理程序流水线这个概念。在这里,只需要将它理解成"一串”有序的处理程序集合并有一个初步印象即可,后续会详细介绍相关内容。
为了完成处理程序流水线的设置,还要构建ServerBootstrap这个“启动”对象。
ServerBootstrap serverBootstrap = new ServerBootstrap(); // 创建一个ServerBootstrap对象serverBootstrap.childHandler(new ChannelInitializer<NioSocketChannel>() { // 为子通道设置ChannelInitializer处理器@Overrideprotected void initChannel(NioSocketChannel ch) throws Exception { // 初始化连接通道ChannelPipeline pipeline = ch.pipeline(); // 获取通道的编排器// 省略其他非核心代码pipeline.addLast("protocolDecoder", new OrderProtocolDecoder()); // 添加一个解码器到通道的最后pipeline.addLast("protocolEncoder", new OrderProtocolEncoder()); // 添加一个编码器到通道的最后// 省略其他非核心代码}});常见疑问解析
为什么Netty自带的编解码方案很少有人使用
其中个很重要的因素就是历史原因,但实际上,除历史原因之外,更重要的原因在于Netty自带的编解码方案大多是具有封帧和解帧功能的编解码器,并且融两层编码于一体,因此从结构上看并不清晰。
另外,Netty自带的编解码方案在使用方式上不够灵活。
在进行序列化和反序列时,字段的顺序弄反了
我们在序列化对象的字段时,使用的顺序是a b c;但是,等到我们解析时,顺序可能不小心写成了 c b a, 因此,我们一定要完全对照好顺序才行。
编解码的顺序问题
有时候,我们往往采用多层编解码。
例如,在得到可传输的字节流之后,我们可能想压缩一下以进一步减少所传输内容占用的空间。
此时,多级编解码就可以派上用场了:对于发送者, 先编码后压缩;而对于接收者,先解压后解码。
但是,代码的添加顺序和我们想要的顺序不一定完全匹配。如果顺序错了,那么代码可能无法工作。
if (compressor != null) {pipeline.addLast("frameDecompressorn", new Frame.Decompressor(compressor));pipeline.addLast("frameCompressor", new Frame.Compressor(compressor));pipeline.addLast("messageDecoder", messageDecoder);pipeline.addLast("messageEncoder", messageEncoderFor(protocolversion));
}
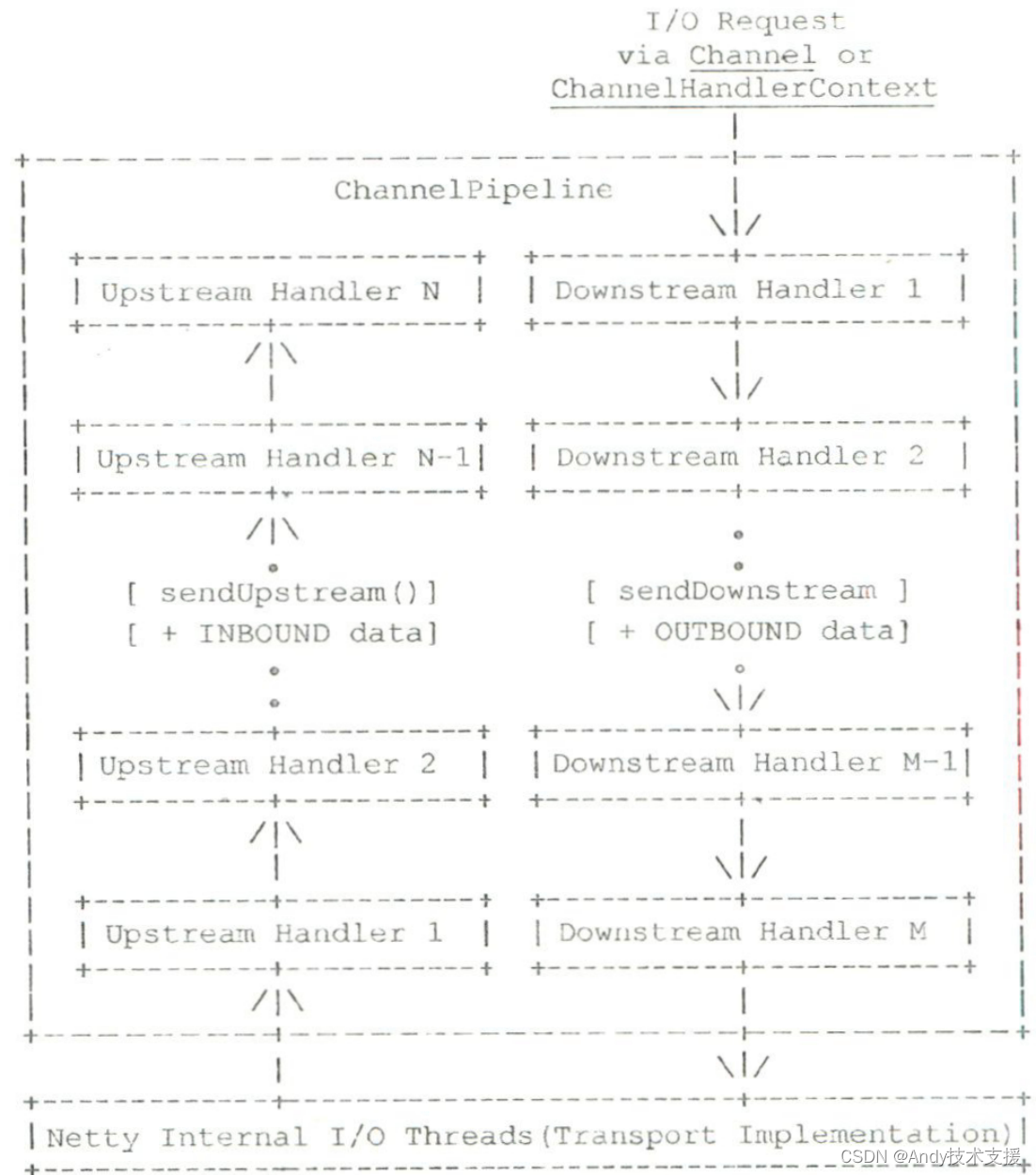
处理程序对于读取操作和写出操作的执行顺序刚好是相反的。
相关文章:
Netty-2-数据编解码
解析编解码支持的原理 以编码为例,要将对象序列化成字节流,你可以使用MessageToByteEncoder或MessageToMessageEncoder类。 这两个类都继承自ChannelOutboundHandlerAdapter适配器类,用于进行数据的转换。 其中,对于MessageToMe…...
伽马校正:FPGA
参考资料: Tone Mapping 与 Gamma Correction - 知乎 (zhihu.com) Book_VIP: 《基于MATLAB与FPGA的图像处理教程》此书是业内第一本基于MATLAB与FPGA的图像处理教程,第一本真正结合理论及算法加速方案,在Matlab验证,以及在FPGA上…...

【SpringCloud笔记】(8)服务网关之GateWay
GateWay 概述简介 官网地址: 上一代网关Zuul 1.x:https://github.com/Netflix/zuul/wiki(有兴趣可以了解一下) gateway:https://cloud.spring.io/spring-cloud-static/spring-cloud-gateway/2.2.1.RELEASE/reference/…...

Compose常用布局
Compose布局基础知识 上一节对Compose做了简单的介绍,本章节主要介绍Compose中常用的布局,其中包括三个基础布局(Colmun、Row、Box);以及其他常用布局(ConstraintLayout 、BoxWithConstraints、HorizontalP…...
使用keytool查看Android APK签名
文章目录 一、找到JDK位置二、使用方法2.1 打开windows命令行工具2.2 查看签名 三、如何给APK做系统签名呢? 一、找到JDK位置 安卓AS之后,可选择继续安装JDK,如本文使用amazon版本默认位置:C:\Users\66176.jdks\corretto-1.8.0_342可通过自…...

数据库学习日常案例20231221-oracle libray cache lock分析
1 问题概述: 阻塞的源头为两个ddl操作导致大量的libray cache lock 其中1133为gis sde的create table as语句。 其中697为alter index语句。...

【数据结构】最短路径算法实现(Dijkstra(迪克斯特拉),FloydWarshall(弗洛伊德) )
文章目录 前言一、Dijkstra(迪克斯特拉)1.方法:2.代码实现 二、FloydWarshall(弗洛伊德)1.方法2.代码实现 完整源码 前言 最短路径问题:从在带权有向图G中的某一顶点出发,找出一条通往另一顶点…...

算法模板之队列图文详解
🌈个人主页:聆风吟 🔥系列专栏:算法模板、数据结构 🔖少年有梦不应止于心动,更要付诸行动。 文章目录 📋前言一. ⛳️模拟队列1.1 🔔用数组模拟实现队列1.1.1 👻队列的定…...
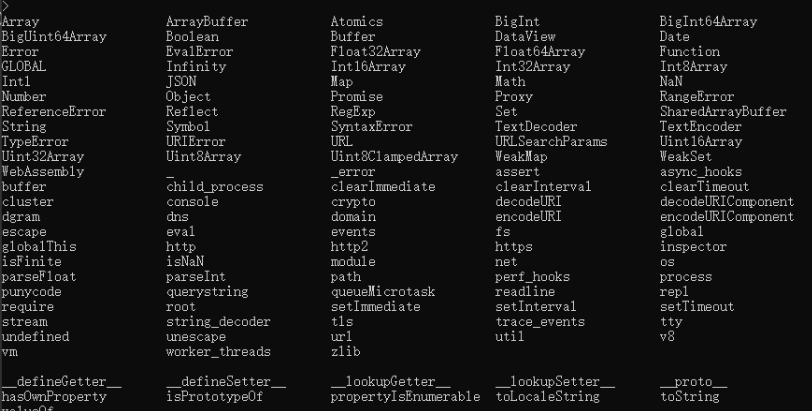
[node]Node.js 中REPL简单介绍
[node]Node.js 中REPL简单介绍 什么是REPL为什么使用REPL如何使用REPL 命令REPL模式node的全局内容展示node全局所有模块查看全局模块具体内容其它命令 实践 什么是REPL Node.js REPL(Read Eval Print Loop:交互式解释器) 表示电脑的环境,类似 Windows 系统的终端或…...
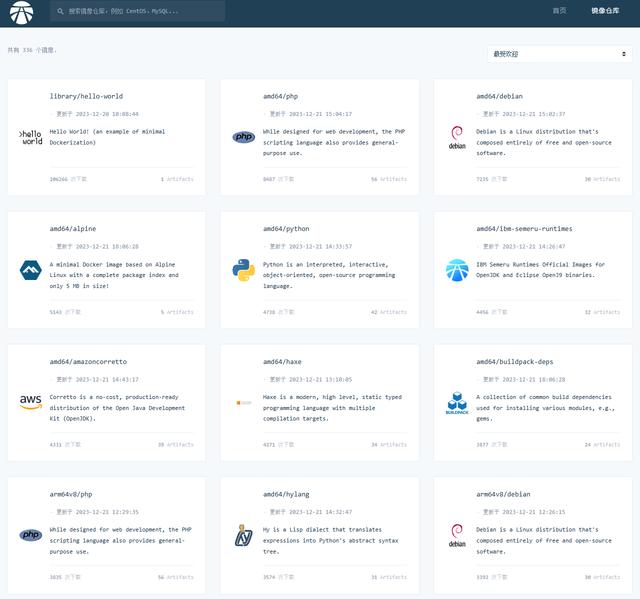
AtomHub 开源容器镜像中心开放公测,国内服务稳定下载
由开放原子开源基金会主导,华为、浪潮、DaoCloud、谐云、青云、飓风引擎以及 OpenSDV 开源联盟、openEuler 社区、OpenCloudOS 社区等成员单位共同发起建设的 AtomHub 可信镜像中心正式开放公测。AtomHub 秉承共建、共治、共享的理念,旨在为开源组织和开…...
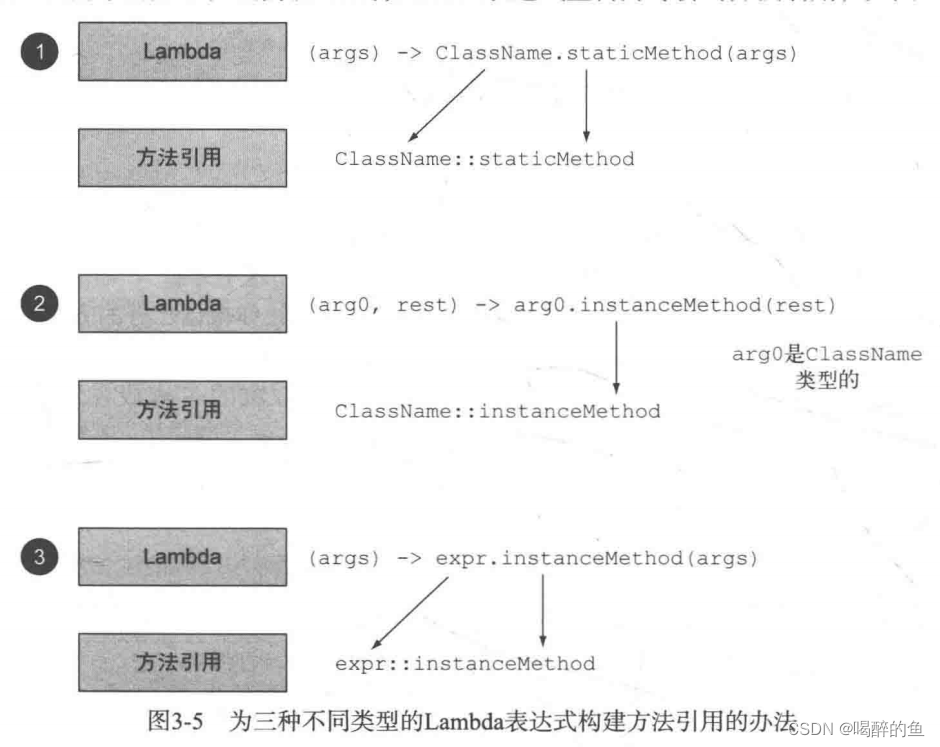
java8实战 lambda表达式、函数式接口、方法引用双冒号(中)
前言 书接上文,上一篇博客讲到了lambda表达式的应用场景,本篇接着将java8实战第三章的总结。建议读者先看第一篇博客 其他函数式接口例子 上一篇有讲到Java API也有其他的函数式接口,书里也举了2个例子,一个是java.util.functi…...

FPGA高端项目:UltraScale GTH + SDI 视频编解码,SDI无缓存回环输出,提供2套工程源码和技术支持
目录 1、前言免责声明 2、相关方案推荐我这里已有的 GT 高速接口解决方案我目前已有的SDI编解码方案 3、详细设计方案设计框图3G-SDI摄像头LMH0384均衡EQUltraScale GTH 的SDI模式应用UltraScale GTH 基本结构参考时钟的选择和分配UltraScale GTH 发送和接收处理流程UltraScale…...

为什么react call api in cDidMount
为什么react call api in cDM 首先,放到constructor或者cWillMount不是语法错误 参考1 参考2 根据上2个参考,总结为: 1、官网就是这么建议的: 2、17版本后的react 由于fiber的出现导致 cWM 会调用多次! cWM 方法已…...

openGauss学习笔记-171 openGauss 数据库运维-备份与恢复-导入数据-深层复制
文章目录 openGauss学习笔记-171 openGauss 数据库运维-备份与恢复-导入数据-深层复制171.1 使用CREATE TABLE执行深层复制171.1.1 操作步骤 171.2 使用CREATE TABLE LIKE执行深层复制171.2.1 操作步骤 171.3 通过创建临时表并截断原始表来执行深层复制171.3.1 操作步骤 openGa…...

[kubernetes]控制平面ETCD
什么是ETCD CoreOS基于Raft开发的分布式key-value存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)etcd像是专门为集群环境的服务发现和注册而设计,它提供了数据TTL失效、数据改变监视、多值、目录监听、…...

序列化类的高级用法
1.3.3 模型类序列化器 如果我们想要使用序列化器对应的是Django的模型类,DRF为我们提供了ModelSerializer模型类序列化器来帮助我们快速创建一个Serializer类。 ModelSerializer与常规的Serializer相同,但提供了: 基于模型类自动生成一系列…...
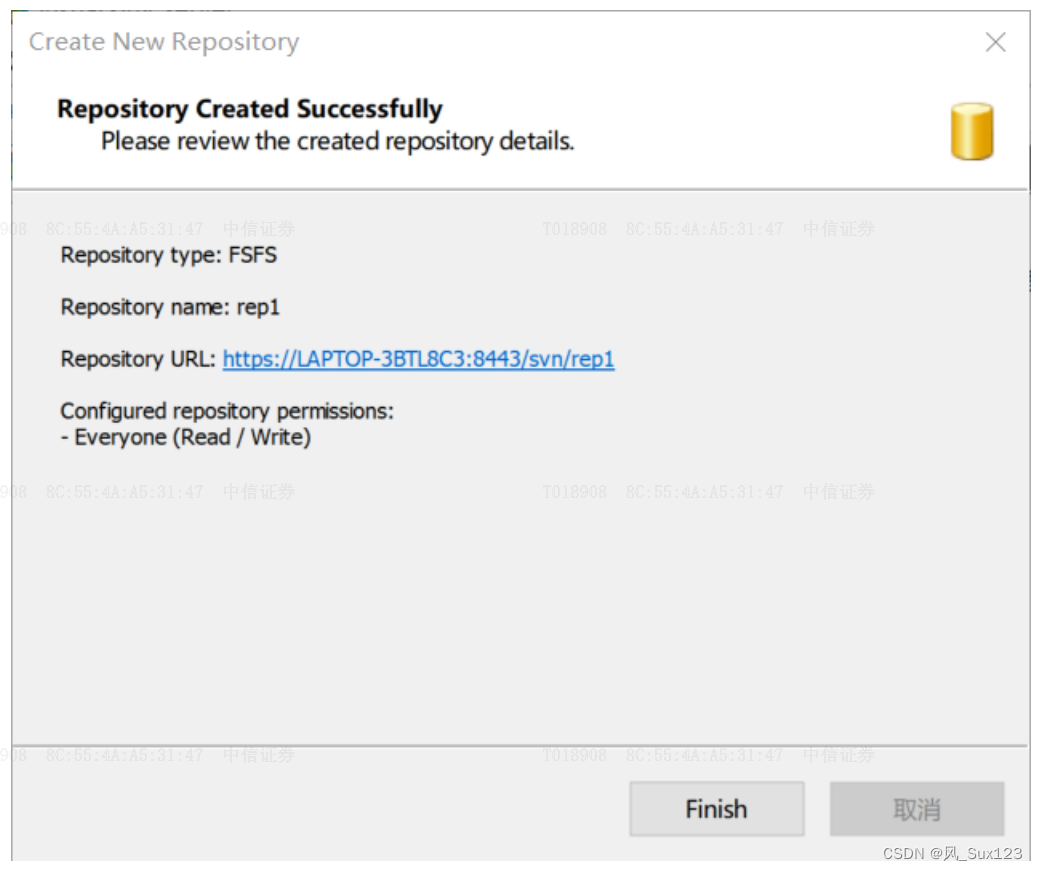
4.svn版本管理工具使用
1. 什么是SVN 版本控制 它可以记录每一次文件和目录的修改情况,这样就可以借此将数据恢复到以前的版本,并可以查看数据的更改细节! Subversion(简称SVN)是一个自由开源的版本控制系统。在Subversion管理下,文件和目录可以超越时空 SVN的优势 统一的版本号 Subversi…...

ZKP Algorithms for Efficient Cryptographic Operations 1 (MSM Pippenger)
MIT IAP 2023 Modern Zero Knowledge Cryptography课程笔记 Lecture 6: Algorithms for Efficient Cryptographic Operations (Jason Morton) Multi-scalar Multiplication(MSM) Naive: nP (((P P) P) P)… (2(2P))…Binary expand $n e_0e_1\alphae_2\alpha2\dots\e_{\…...
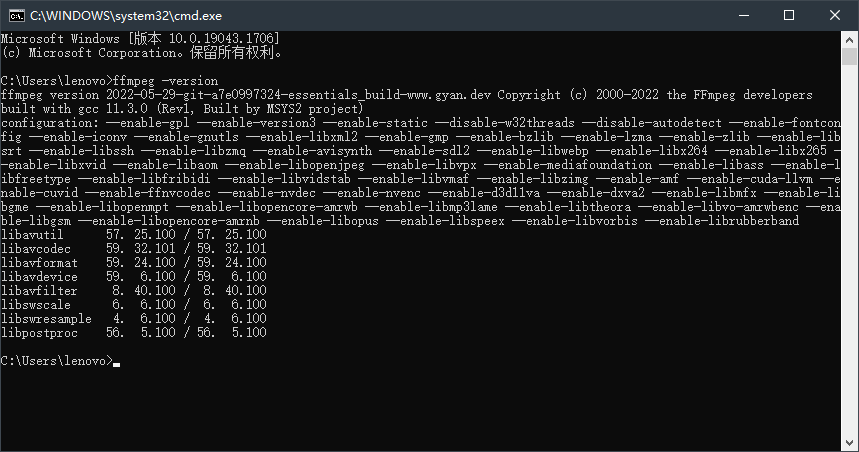
Windows系统安装 ffmpeg
下载及解压 ffmpeg官方下载地址:https://ffmpeg.org/download.html 下载好后将其解压至你想保存的位置中。 环境变量设置 打开Windows设置,在搜索框输入:系统高级设置。 新建环境变量,并输入bin目录具体位置。 安装检查 按住 w…...
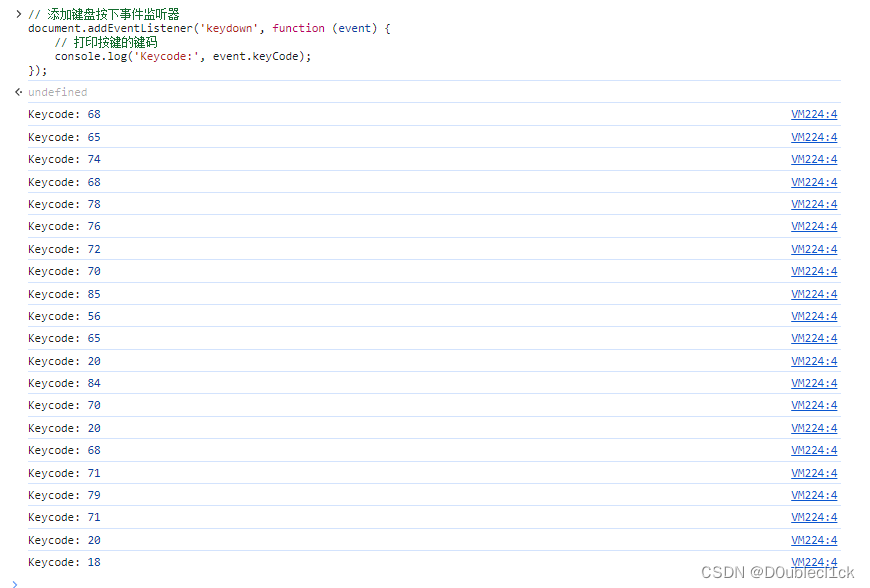
油猴脚本教程案例【键盘监听】-编写 ChatGPT 快捷键优化
文章目录 1. 元数据namenamespaceversiondescriptionauthormatchgranticon 2. 编写函数.1 函数功能2.1.1. input - 聚焦发言框2.1.2. stop - 取消回答2.1.3. newFunction - 开启新窗口2.1.4. scroll - 回到底部 3. 监听键盘事件3.1 监听X - 开启新对话3.2 监听Z - 取消回答3.3 …...

国防科技大学计算机基础课程笔记02信息编码
1.机内码和国标码 国标码就是我们非常熟悉的这个GB2312,但是因为都是16进制,因此这个了16进制的数据既可以翻译成为这个机器码,也可以翻译成为这个国标码,所以这个时候很容易会出现这个歧义的情况; 因此,我们的这个国…...

DeepSeek 赋能智慧能源:微电网优化调度的智能革新路径
目录 一、智慧能源微电网优化调度概述1.1 智慧能源微电网概念1.2 优化调度的重要性1.3 目前面临的挑战 二、DeepSeek 技术探秘2.1 DeepSeek 技术原理2.2 DeepSeek 独特优势2.3 DeepSeek 在 AI 领域地位 三、DeepSeek 在微电网优化调度中的应用剖析3.1 数据处理与分析3.2 预测与…...

day52 ResNet18 CBAM
在深度学习的旅程中,我们不断探索如何提升模型的性能。今天,我将分享我在 ResNet18 模型中插入 CBAM(Convolutional Block Attention Module)模块,并采用分阶段微调策略的实践过程。通过这个过程,我不仅提升…...

在HarmonyOS ArkTS ArkUI-X 5.0及以上版本中,手势开发全攻略:
在 HarmonyOS 应用开发中,手势交互是连接用户与设备的核心纽带。ArkTS 框架提供了丰富的手势处理能力,既支持点击、长按、拖拽等基础单一手势的精细控制,也能通过多种绑定策略解决父子组件的手势竞争问题。本文将结合官方开发文档,…...

基于uniapp+WebSocket实现聊天对话、消息监听、消息推送、聊天室等功能,多端兼容
基于 UniApp + WebSocket实现多端兼容的实时通讯系统,涵盖WebSocket连接建立、消息收发机制、多端兼容性配置、消息实时监听等功能,适配微信小程序、H5、Android、iOS等终端 目录 技术选型分析WebSocket协议优势UniApp跨平台特性WebSocket 基础实现连接管理消息收发连接…...

Leetcode 3577. Count the Number of Computer Unlocking Permutations
Leetcode 3577. Count the Number of Computer Unlocking Permutations 1. 解题思路2. 代码实现 题目链接:3577. Count the Number of Computer Unlocking Permutations 1. 解题思路 这一题其实就是一个脑筋急转弯,要想要能够将所有的电脑解锁&#x…...

MODBUS TCP转CANopen 技术赋能高效协同作业
在现代工业自动化领域,MODBUS TCP和CANopen两种通讯协议因其稳定性和高效性被广泛应用于各种设备和系统中。而随着科技的不断进步,这两种通讯协议也正在被逐步融合,形成了一种新型的通讯方式——开疆智能MODBUS TCP转CANopen网关KJ-TCPC-CANP…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

【SpringBoot自动化部署】
SpringBoot自动化部署方法 使用Jenkins进行持续集成与部署 Jenkins是最常用的自动化部署工具之一,能够实现代码拉取、构建、测试和部署的全流程自动化。 配置Jenkins任务时,需要添加Git仓库地址和凭证,设置构建触发器(如GitHub…...