Hadoop入门学习笔记——四、MapReduce的框架配置和YARN的部署
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7
课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd=5ay8
Hadoop入门学习笔记(汇总)
目录
- 四、MapReduce的框架配置和YARN的部署
- 4.1. 配置MapReduce和YARN
- 4.2. YARN集群启停脚本
- 4.2.1. 一键启停脚本
- 4.2.2. 单独进程启停
- 4.3. 提交MapReduce示例程序到YARN运行
- 4.3.1. 提交wordcount(单词统计)示例程序
- 4.3.2. 提交根据Monte Carlo蒙特卡罗算法求圆周率的示例程序
四、MapReduce的框架配置和YARN的部署
本次YARN的部署结构如下图所示:
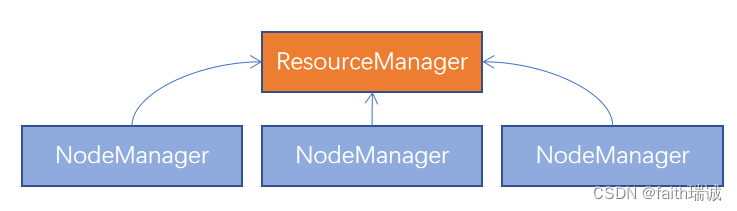
当前,共有三台服务器(虚拟机)构成集群,集群规划如下所示:
| 主机 | 部署的服务 |
|---|---|
| node1 | ResourceManager、NodeManager、ProxyServer、JobHistoryServer |
| node2 | NodeManager |
| node3 | NodeManager |
MapReduce是运行在YARN上的,所以MapReduce只需要配置,YARN需要部署并启动。
4.1. 配置MapReduce和YARN
1、在node1节点,修改mapred-env.sh文件:
# 进入hadoop配置文件目录
cd /export/server/hadoop-3.3.4/etc/hadoop/
# 打开mapred-env.sh文件
vim mapred-env.sh
打开后,在文件中加入以下内容:
# 设置JDK路径
export JAVA_HOME=/export/server/jdk
# 设置JobHistoryServer进程的内存为1G
export HADOOP_JOB_HISTORYSERVER_HEAPSIZE=1000
# 设置日志级别为INFO
export HADOOP_MAPRED_ROOT_LOGGER=INFO,RFA
2、再修改同目录下的mapred-site.xml配置文件,在其configuration标签内增加以下内容:
<property><name>mapreduce.framework.name</name><value>yarn</value><description></description></property><property><name>mapreduce.jobhistory.address</name><value>node1:10020</value><description></description></property><property><name>mapreduce.jobhistory.webapp.address</name><value>node1:19888</value><description></description></property><property><name>mapreduce.jobhistory.intermediate-done-dir</name><value>/data/mr-history/tmp</value><description></description></property><property><name>mapreduce.jobhistory.done-dir</name><value>/data/mr-history/done</value><description></description></property><property><name>yarn.app.mapreduce.am.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.map.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property><property><name>mapreduce.reduce.env</name><value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value></property>
其中,
mapreduce.framework.name 表示MapReduce的运行框架,这里设置为Yarn;
mapreduce.jobhistory.address 表示历史服务器通讯地址和端口号,这里为node1:10020;
mapreduce.jobhistory.webapp.address 表示历史服务器Web端地址和端口号,这里为node1:19888;
mapreduce.jobhistory.intermediate-done-dir 表示历史信息在HDFS的记录临时路径,这里是/data/mr-history/tmp;
mapreduce.jobhistory.done-dir 表示历史信息在HDFS的记录路径,这里是/data/mr-history/done;
yarn.app.mapreduce.am.env 表示MapReduce HOME的路径,这里设置为HADOOP_HOME相同路径;
mapreduce.map.env 表示Map HOME的路径,这里设置为HADOOP_HOME相同路径;
mapreduce.reduce.env 表示Reduce HOME的路径,这里设置为HADOOP_HOME相同路径;
至此,MapReduce的配置完成。
3、接下来,配置YARN。在node1节点,修改yarn-env.sh文件:
# 进入hadoop配置文件目录
cd /export/server/hadoop-3.3.4/etc/hadoop/
# 打开yarn-env.sh文件
vim yarn-env.sh
在文件中添加以下内容:
# 设置JDK路径的环境变量
export JAVA_HOME=/export/server/jdk
# 设置HADOOP_HOME的环境变量
export HADOOP_HOME=/export/server/hadoop
# 设置配置文件路径的环境变量
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
# 设置日志文件路径的环境变量
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
4、修改同目录下的yarn-site.xml配置文件,在其configuration节点中添加以下内容:
<!-- Site specific YARN configuration properties --><property><name>yarn.log.server.url</name><value>http://node1:19888/jobhistory/logs</value><description></description></property><property><name>yarn.web-proxy.address</name><value>node1:8089</value><description>proxy server hostname and port</description></property><property><name>yarn.log-aggregation-enable</name><value>true</value><description>Configuration to enable or disable log aggregation</description></property><property><name>yarn.nodemanager.remote-app-log-dir</name><value>/tmp/logs</value><description>Configuration to enable or disable log aggregation</description></property><!-- Site specific YARN configuration properties --><property><name>yarn.resourcemanager.hostname</name><value>node1</value><description></description></property><property><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value><description></description></property><property><name>yarn.nodemanager.local-dirs</name><value>/data/nm-local</value><description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description></property><property><name>yarn.nodemanager.log-dirs</name><value>/data/nm-log</value><description>Comma-separated list of paths on the local filesystem where logs are written.</description></property><property><name>yarn.nodemanager.log.retain-seconds</name><value>10800</value><description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value><description>Shuffle service that needs to be set for Map Reduce applications.</description></property>
其中,核心配置如下:
yarn.resourcemanager.hostname 表示ResourceManager设置在哪个节点,这里是node1节点;
yarn.nodemanager.local-dirs 表示NodeManager中间数据Linux系统本地存储的路径;
yarn.nodemanager.log-dirs 表示NodeManager数据Linux系统日志本地存储的路径;
yarn.nodemanager.aux-services 表示为MapReduce程序开启Shuffle服务;
额外配置如下:
yarn.log.server.url 表示历史服务器的URL;
yarn.web-proxy.address 表示代理服务器的主机和端口号;
yarn.log-aggregation-enable 表示是否开启日志聚合;
yarn.nodemanager.remote-app-log-dir 表示程序日志在HDFS中的存放路径;
yarn.resourcemanager.scheduler.class 表示选择Yarn使用的调度器,这里选的是公平调度器;
5、完成上述配置后,需要将MapReduce和YARN的配置文件分发到node2和node3服务器相同位置中,使用hadoop用户身份执行以下命令
# 将mapred-env.sh、mapred-site.xml、yarn-env.sh、yarn-site.xml四个配置文件,复制到node2的相同路径下
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
# 将mapred-env.sh、mapred-site.xml、yarn-env.sh、yarn-site.xml四个配置文件,复制到node3的相同路径下
scp mapred-env.sh mapred-site.xml yarn-env.sh yarn-site.xml node2:`pwd`/
4.2. YARN集群启停脚本
在启动YARN集群前,需要确保HDFS集群已经启动。同样,启停YARN集群也必须使用hadoop用户身份。
4.2.1. 一键启停脚本
$HADOOP_HOME/sbin/start-yarn.sh或start-yarn.sh一键启动YARN集群
- 会基于yarn-site.xml中配置的yarn.resourcemanager.hostname来决定在哪台机器上启动resourcemanager;
- 会基于workers文件配置的主机启动NodeManager;
- 在当前机器启动ProxyServer(代理服务器)。
命令执行效果如下图所示:

此时通过jps命令查看进程,可以看到如下效果:
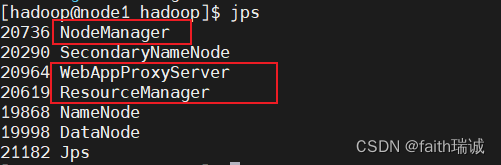
此时,可以看到ResourceManager、NodeManager和WebAppProxyServer都已经启动,还需要启动HistoryServer,可以通过后续章节介绍的mapred --daemon start historyserver命令启动。
至此,整个YARN集群启动完成。
此时,可以通过访问http://node1:8088/ 即可看到YARN集群的监控页面(即ResourceManager的WebUI)
$HADOOP_HOME/sbin/stop-yarn.sh或stop-yarn.sh一键关闭YARN集群。- 配置部署好YARN集群后,可以关闭YARN集群、关闭JobHistoryServer、关闭HDFS集群、关闭虚拟机之后,对虚拟机创建快照,保存好当前环境。
4.2.2. 单独进程启停
- 在每一台机器,单独启动或停止进程,可以通过如下命令执行:
$HADOOP_HOME/bin/yarn --daemon start|stop resourcemanager|nodemanager|proxyserver
start和stop决定启动和停止;
可控制resourcemanager、nodemanager、webappproxyserver三种进程。
例如:
# 在node1启动ResourceManager
yarn --daemon start resourcemanager
# 在node1、node2、node3分别启动NodeManager
yarn --daemon start nodemanager
# 在node1启动WebProxyServer
yarn --daemon start proxyserver
- 历史服务器(JobHistoryServer)的启动和停止
$HADOOP_HOME/bin/mapred --daemon start|stop historyserver
用法:
# 启动JobHistoryServer
mapred --daemon start historyserver
# 停止JobHistoryServer
mapred --daemon stop historyserver
4.3. 提交MapReduce示例程序到YARN运行
YARN作为资源调度管控框架,其本身提供资供许多程序运行,常见的有:
- MapReduce程序
- Spark程序
- Flink程序
Hadoop官方提供了一些预置的MapReduce程序代码,存放于$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.1.jar文件内。
上述程序可使用hadoop har命令提交至YARN运行,其命令语法为:
hadoop jar 程序文件 java类名 [程序参数] ... [程序参数]
4.3.1. 提交wordcount(单词统计)示例程序
1、程序内容
- 给定数据输入的路径(HDFS)、给定结果输出的路径(HDFS)
- 将输入路径内的数据中的单词进行计数,将结果写到输出路径
2、准备一份待统计的数据文件并上传至HDFS中
使用vim words.txt命令,在Linux本地创建words.txt文件,其内容如下:
itheima itcast itheima itcast
hadoop hdfs hadoop hdfs
hadoop mapreduce hadoop yarn
itheima hadoop itcast hadoop
itheima itcast hadoop yarn mapreduce
使用命令hdfs dfs -mkdir -p /input在HDFS根目录创建input文件夹(用于存储待统计的文件),使用hdfs dfs -mkdir -p /output命令在HDFS根目录创建output文件夹(用于存储统计结果),使用hdfs dfs -put words.txt /input命令将本地的words.txt文件上传至HDFS系统中。
3、提交MapReduce程序
使用如下命令:
hadoop jar /export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input/ hdfs://8020/output/wc
其中,
hadoop jar 表示向YARN提交一个Java程序;
/export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar 表示所要提交的程序路径;
wordcount 表示要运行的java类名;
hdfs://node1:8020/input/ 表示参数1,在本程序中是待统计的文件夹,这里写了hdfs协议头,指明了是HDFS文件系统的路径(经测试,不写也可以,默认读取HDFS文件系统路径);
hdfs://8020/output/wc 表示参数2,在本程序中是统计结果输出的文件夹,这里写明了hdfs协议头,指明了是HDFS文件系统的路径(经测试,不写也可以,默认读取HDFS文件系统路径),这里需要确保该文件夹不存在,否则会报错。
运行日志如下所示:
[hadoop@node1 ~]$ hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar wordcount hdfs://node1:8020/input hdfs://node1:8020/output/wc
2023-12-14 15:31:53,988 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.101:8032
2023-12-14 15:31:55,818 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1702538855741_0001
2023-12-14 15:31:56,752 INFO input.FileInputFormat: Total input files to process : 1
2023-12-14 15:31:57,040 INFO mapreduce.JobSubmitter: number of splits:1
2023-12-14 15:31:57,607 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1702538855741_0001
2023-12-14 15:31:57,607 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-12-14 15:31:58,167 INFO conf.Configuration: resource-types.xml not found
2023-12-14 15:31:58,170 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-12-14 15:31:59,119 INFO impl.YarnClientImpl: Submitted application application_1702538855741_0001
2023-12-14 15:31:59,406 INFO mapreduce.Job: The url to track the job: http://node1:8089/proxy/application_1702538855741_0001/
2023-12-14 15:31:59,407 INFO mapreduce.Job: Running job: job_1702538855741_0001
2023-12-14 15:32:23,043 INFO mapreduce.Job: Job job_1702538855741_0001 running in uber mode : false
2023-12-14 15:32:23,045 INFO mapreduce.Job: map 0% reduce 0%
2023-12-14 15:32:37,767 INFO mapreduce.Job: map 100% reduce 0%
2023-12-14 15:32:50,191 INFO mapreduce.Job: map 100% reduce 100%
2023-12-14 15:32:51,220 INFO mapreduce.Job: Job job_1702538855741_0001 completed successfully
2023-12-14 15:32:51,431 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=84FILE: Number of bytes written=553527FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=248HDFS: Number of bytes written=54HDFS: Number of read operations=8HDFS: Number of large read operations=0HDFS: Number of write operations=2HDFS: Number of bytes read erasure-coded=0Job CountersLaunched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=11593Total time spent by all reduces in occupied slots (ms)=9650Total time spent by all map tasks (ms)=11593Total time spent by all reduce tasks (ms)=9650Total vcore-milliseconds taken by all map tasks=11593Total vcore-milliseconds taken by all reduce tasks=9650Total megabyte-milliseconds taken by all map tasks=11871232Total megabyte-milliseconds taken by all reduce tasks=9881600Map-Reduce FrameworkMap input records=6Map output records=21Map output bytes=233Map output materialized bytes=84Input split bytes=98Combine input records=21Combine output records=6Reduce input groups=6Reduce shuffle bytes=84Reduce input records=6Reduce output records=6Spilled Records=12Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=300CPU time spent (ms)=2910Physical memory (bytes) snapshot=353423360Virtual memory (bytes) snapshot=5477199872Total committed heap usage (bytes)=196218880Peak Map Physical memory (bytes)=228843520Peak Map Virtual memory (bytes)=2734153728Peak Reduce Physical memory (bytes)=124579840Peak Reduce Virtual memory (bytes)=2743046144Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=150File Output Format CountersBytes Written=544、查看运行结果
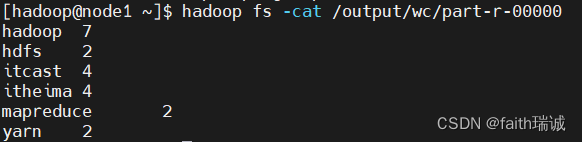
运行完毕后,使用hadoop fs -ls /output/wc可以看到运行结果输出的文件

使用hadoop fs -cat /output/wc/part-r-00000命令,可以看到程序运行的结果
除此之外,在YARN集群的监控页面http://node1:8088/ 点击左侧的Applications菜单,可以看到刚才运行过的任务
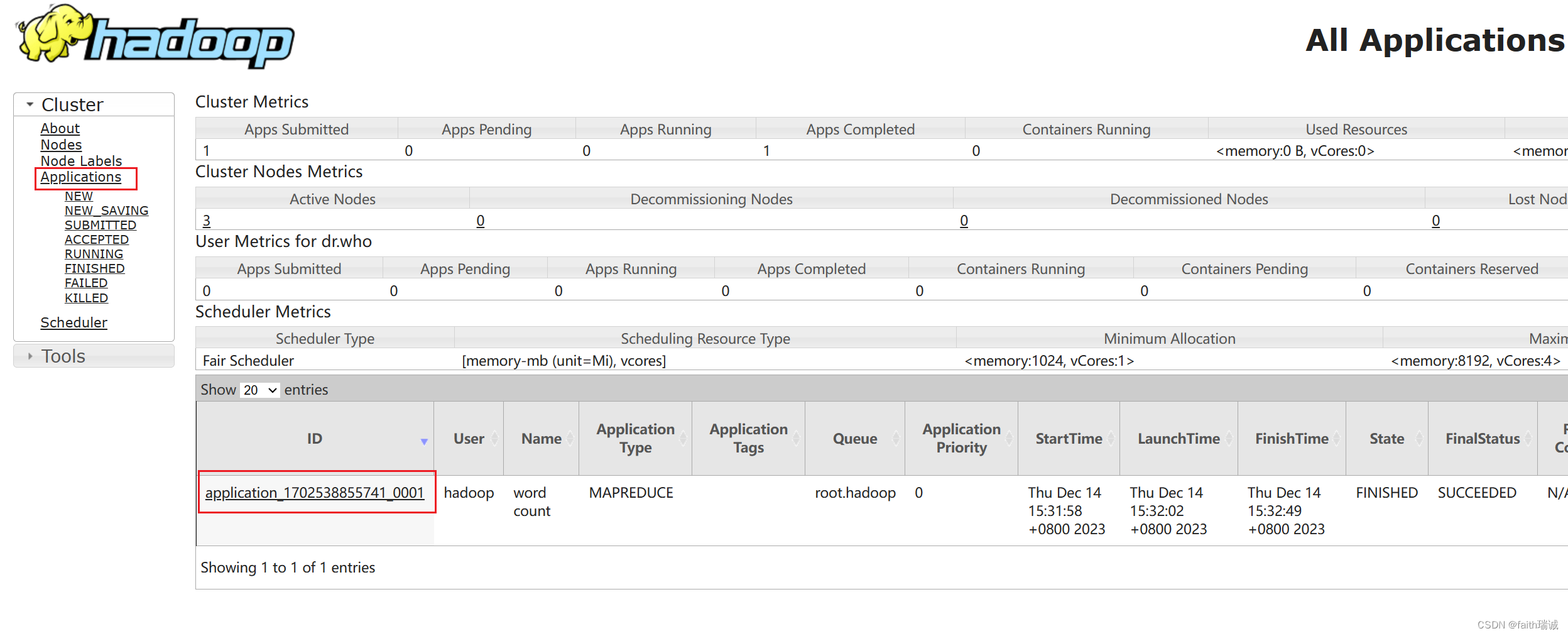
再点击任务的ID,可以进入任务详情页面
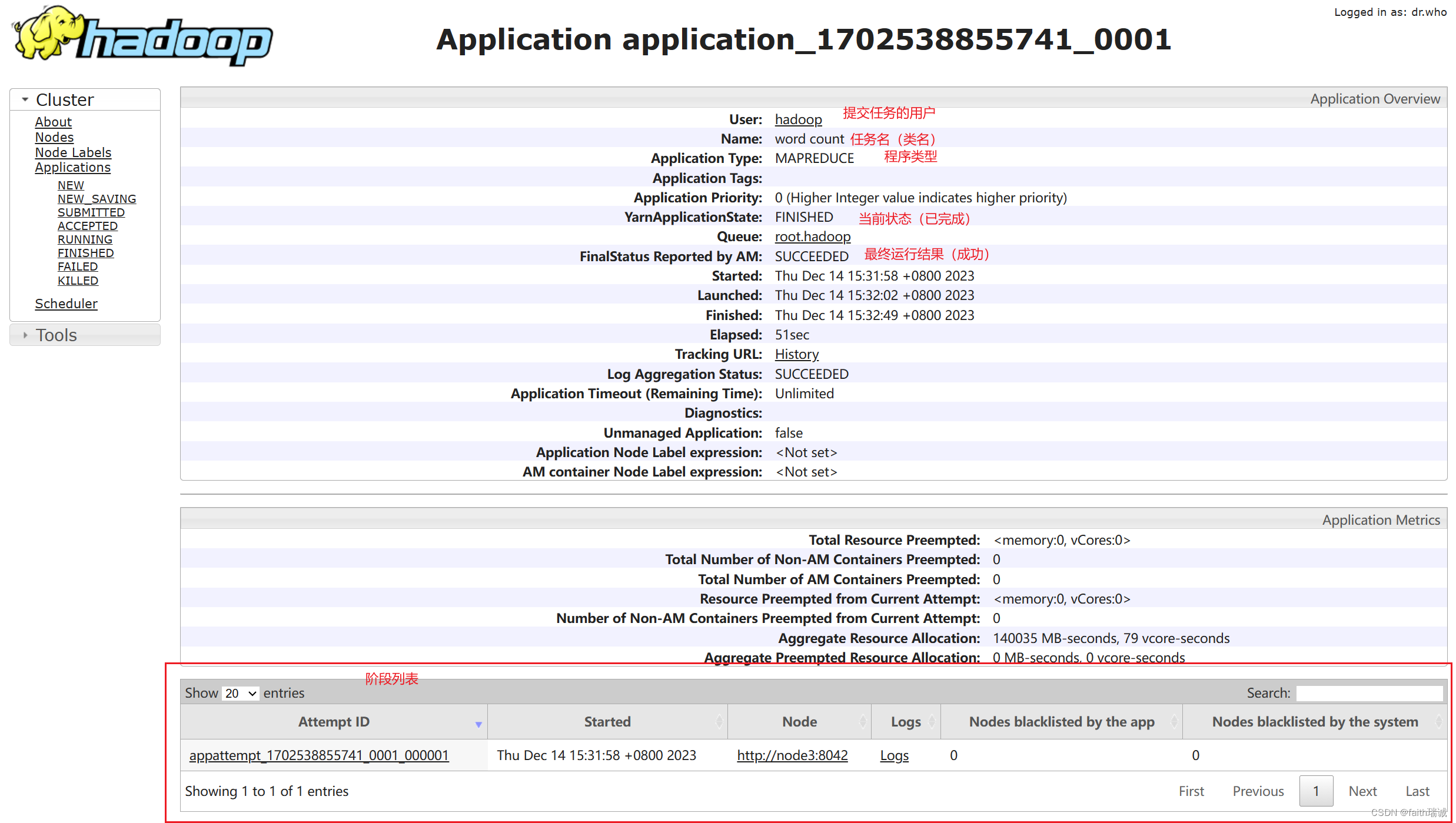
再点击某一个阶段的Logs链接,可以看到对应阶段的运行的客户端日志(在配置yarn-site.xml文件时,配置了开启日志聚合),这个页面本质上是JobHistoryServer提供的页面(19888端口)

在任务详情页面点击History链接,可以看到任务的历史运行状态,在其中可以看到其Map任务和Reduce任务,也可以继续点进Map和Reduce任务查看相关的日志等信息,对于程序出错时的排查很有帮助。
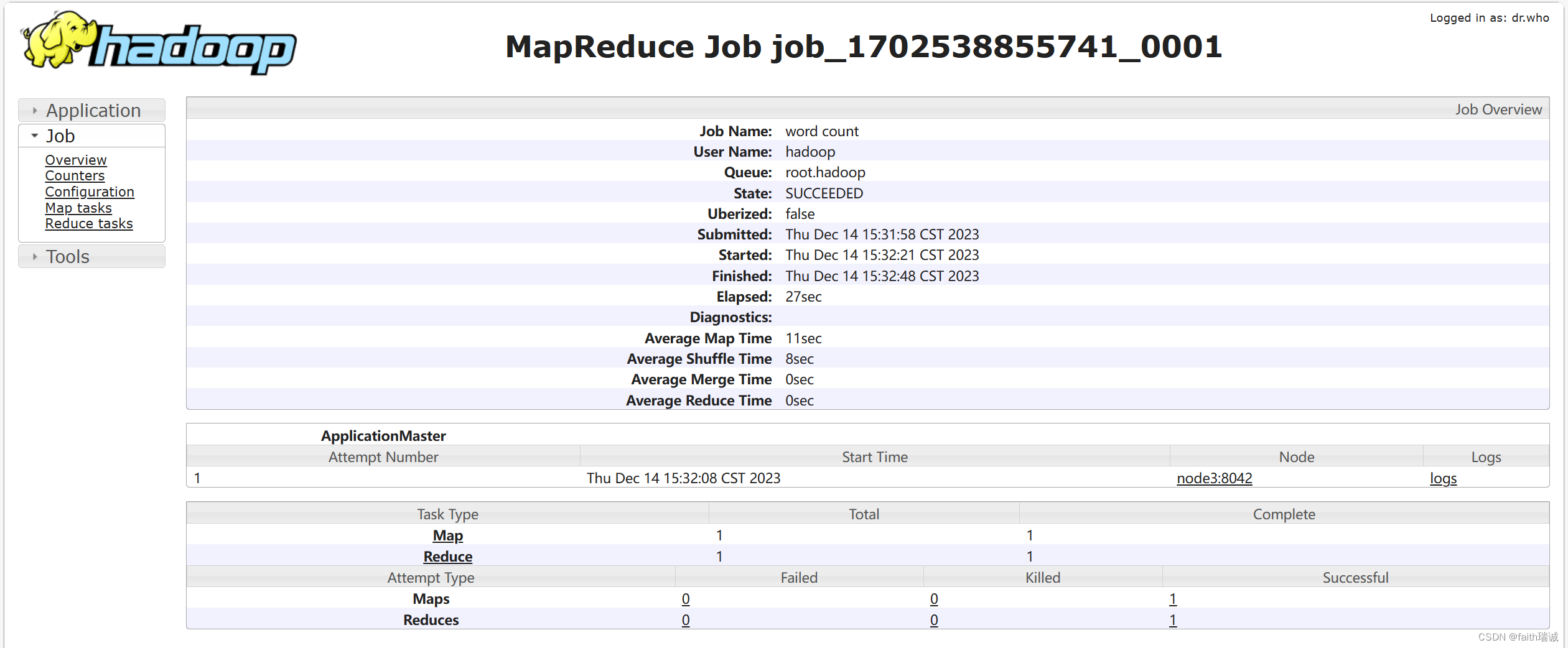
4.3.2. 提交根据Monte Carlo蒙特卡罗算法求圆周率的示例程序
1、提交程序
hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
hadoop jar 表示向YARN提交一个Java程序;
/export/server/hadoop-3.3.4/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar 表示所要提交的程序路径;
pi 表示运行的Java类名;
3 表示使用3个Map任务;
1000 表示样本数为1000,样本数越多,求得的圆周率越准确,但是程序运行时长越长。
运行日志如下所示:
[hadoop@node1 ~]$ hadoop jar /export/server/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.4.jar pi 3 1000
Number of Maps = 3
Samples per Map = 1000
Wrote input for Map #0
Wrote input for Map #1
Wrote input for Map #2
Starting Job
2023-12-14 16:06:12,042 INFO client.DefaultNoHARMFailoverProxyProvider: Connecting to ResourceManager at node1/192.168.88.101:8032
2023-12-14 16:06:13,550 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/hadoop/.staging/job_1702538855741_0002
2023-12-14 16:06:13,888 INFO input.FileInputFormat: Total input files to process : 3
2023-12-14 16:06:14,149 INFO mapreduce.JobSubmitter: number of splits:3
2023-12-14 16:06:14,658 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1702538855741_0002
2023-12-14 16:06:14,659 INFO mapreduce.JobSubmitter: Executing with tokens: []
2023-12-14 16:06:15,065 INFO conf.Configuration: resource-types.xml not found
2023-12-14 16:06:15,065 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2023-12-14 16:06:15,256 INFO impl.YarnClientImpl: Submitted application application_1702538855741_0002
2023-12-14 16:06:15,403 INFO mapreduce.Job: The url to track the job: http://node1:8089/proxy/application_1702538855741_0002/
2023-12-14 16:06:15,404 INFO mapreduce.Job: Running job: job_1702538855741_0002
2023-12-14 16:06:32,155 INFO mapreduce.Job: Job job_1702538855741_0002 running in uber mode : false
2023-12-14 16:06:32,156 INFO mapreduce.Job: map 0% reduce 0%
2023-12-14 16:06:47,156 INFO mapreduce.Job: map 67% reduce 0%
2023-12-14 16:06:50,188 INFO mapreduce.Job: map 100% reduce 0%
2023-12-14 16:06:57,275 INFO mapreduce.Job: map 100% reduce 100%
2023-12-14 16:06:58,328 INFO mapreduce.Job: Job job_1702538855741_0002 completed successfully
2023-12-14 16:06:58,589 INFO mapreduce.Job: Counters: 54File System CountersFILE: Number of bytes read=72FILE: Number of bytes written=1108329FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=786HDFS: Number of bytes written=215HDFS: Number of read operations=17HDFS: Number of large read operations=0HDFS: Number of write operations=3HDFS: Number of bytes read erasure-coded=0Job CountersLaunched map tasks=3Launched reduce tasks=1Data-local map tasks=3Total time spent by all maps in occupied slots (ms)=39354Total time spent by all reduces in occupied slots (ms)=7761Total time spent by all map tasks (ms)=39354Total time spent by all reduce tasks (ms)=7761Total vcore-milliseconds taken by all map tasks=39354Total vcore-milliseconds taken by all reduce tasks=7761Total megabyte-milliseconds taken by all map tasks=40298496Total megabyte-milliseconds taken by all reduce tasks=7947264Map-Reduce FrameworkMap input records=3Map output records=6Map output bytes=54Map output materialized bytes=84Input split bytes=432Combine input records=0Combine output records=0Reduce input groups=2Reduce shuffle bytes=84Reduce input records=6Reduce output records=0Spilled Records=12Shuffled Maps =3Failed Shuffles=0Merged Map outputs=3GC time elapsed (ms)=699CPU time spent (ms)=11980Physical memory (bytes) snapshot=775233536Virtual memory (bytes) snapshot=10945183744Total committed heap usage (bytes)=466890752Peak Map Physical memory (bytes)=227717120Peak Map Virtual memory (bytes)=2734153728Peak Reduce Physical memory (bytes)=113000448Peak Reduce Virtual memory (bytes)=2742722560Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format CountersBytes Read=354File Output Format CountersBytes Written=97
Job Finished in 46.895 seconds
Estimated value of Pi is 3.14133333333333333333
2、查看运行情况
在在YARN集群的监控页面,可以查看对应任务的History信息,可以看到当前任务使用了3个Map任务和1个Reduce任务,同时,也可以查看相应的运行日志信息。
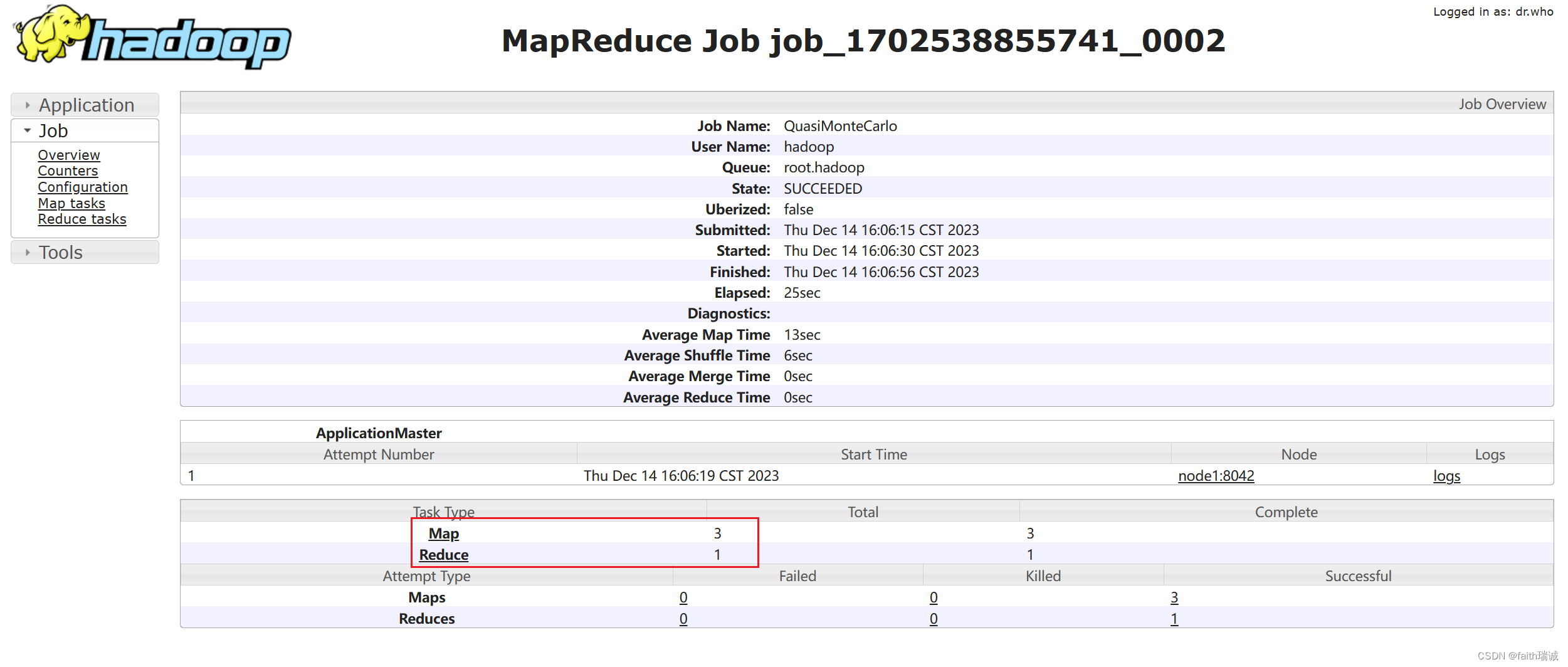
相关文章:
Hadoop入门学习笔记——四、MapReduce的框架配置和YARN的部署
视频课程地址:https://www.bilibili.com/video/BV1WY4y197g7 课程资料链接:https://pan.baidu.com/s/15KpnWeKpvExpKmOC8xjmtQ?pwd5ay8 Hadoop入门学习笔记(汇总) 目录 四、MapReduce的框架配置和YARN的部署4.1. 配置MapReduce…...
list集合
List集合 List集合的概述 有序集合(也称之为序列),用户可以精确的控制列表中的每个元素的插入位置。用户可以通过整数索引访问元素,并搜索列表中的元素 与 Set 集合不同,列表通常允许重复的元素 List 集合的特点 有…...
Vue3学习(后端开发)
目录 一、安装Node.js 二、创建Vue3工程 三、用VSCode打开 四、源代码目录src 五、入门案例——手写src 六、测试案例 七、ref和reactive的区别 一、安装Node.js 下载20.10.0 LTS版本 https://nodejs.org/en 使用node命令检验安装是否成功 node 二、创建Vue3工程 在…...
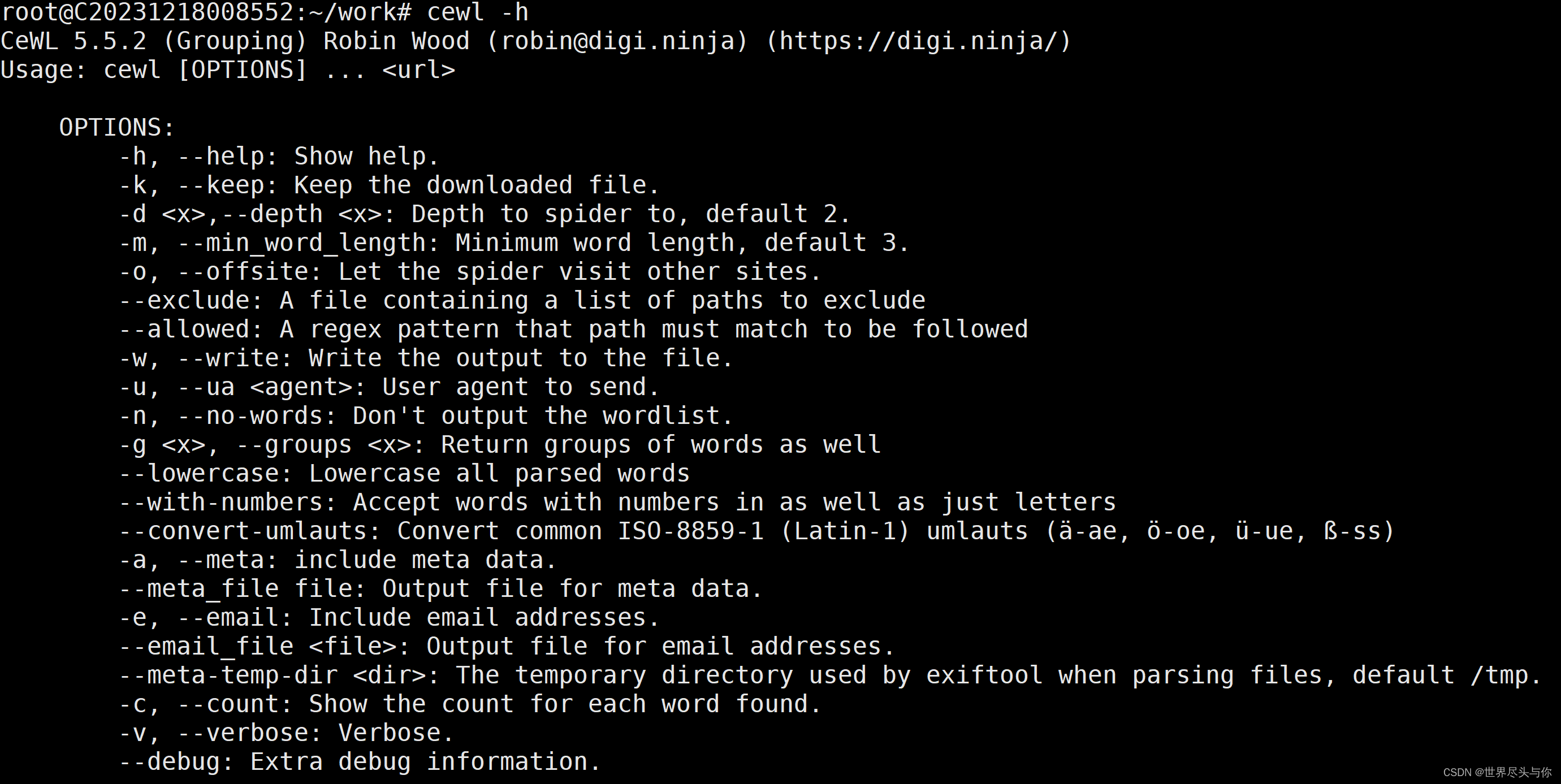
爬虫字典生成工具,CeWL使用教程
爬虫字典生成工具,CeWL使用教程 1.工具概述2.参数解析3.使用实例1.工具概述 CeWL 是一个 ruby 应用程序,它将给定的 URL 爬到指定的深度,可以选择跟随外部链接,并返回一个单词列表,然后可用于密码破解者 Cewl 是黑客武器库中的强大工具,因为它允许创建有针对性的单词列…...
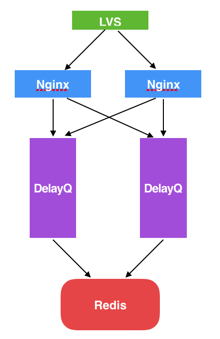
消息队列之关于如何实现延时队列
一、延时队列的应用 1.1 什么是延时队列? 顾名思义:首先它要具有队列的特性,再给它附加一个延迟消费队列消息的功能,也就是说可以指定队列中的消息在哪个时间点被消费。 延时队列在项目中的应用还是比较多的,尤其像…...

Linux Shell 002-基础知识
Linux Shell 002-基础知识 本节关键字:Linux、Bash Shell、基础知识、Bash特性 相关指令:bash、rm、cp、touch、date 基础知识 什么是Shell脚本 简单概括:将需要执行的命令保存到文本中,按照顺序执行。 准备描述:sh…...

前缀和+单调双队列+贪心:LeetCode2945:找到最大非递减数组的长度
本文涉及知识点 C算法:前缀和、前缀乘积、前缀异或的原理、源码及测试用例 包括课程视频 单调双队列 贪心 题目 给你一个下标从 0 开始的整数数组 nums 。 你可以执行任意次操作。每次操作中,你需要选择一个 子数组 ,并将这个子数组用它所…...
【微服务】springboot整合kafka-stream使用详解
目录 一、前言 二、kafka stream概述 2.1 什么是kafka stream 2.2 为什么需要kafka stream 2.2.1 对接成本低 2.2.2 节省资源 2.2.3 使用简单 2.3 kafka stream特点 2.4 kafka stream中的一些概念 2.5 Kafka Stream应用场景 三、环境准备 3.1 搭建zk 3.1.1 自定义d…...
什么是动态代理?
目录 一、为什么需要代理? 二、代理长什么样? 三、Java通过什么来保证代理的样子? 四、动态代理实现案例 五、动态代理在SpringBoot中的应用 导入依赖 数据库表设计 OperateLogEntity实体类 OperateLog枚举 RecordLog注解 上下文相…...
【OAuth2】:赋予用户控制权的安全通行证--原理篇
🥳🥳Welcome Huihuis Code World ! !🥳🥳 接下来看看由辉辉所写的关于OAuth2的相关操作吧 目录 🥳🥳Welcome Huihuis Code World ! !🥳🥳 一.什么是OAuth? 二.为什么要用OAuth?…...
【K8s】2# 使用kuboard管理K8s集群(kuboard安装)
文章目录 安装 Kuboard v3部署计划 安装登录测试 安装 Kuboard v3 部署计划 在正式安装 kuboard v3 之前,需做好一个简单的部署计划的设计,在本例中,各组件之间的连接方式,如下图所示: 假设用户通过 http://外网IP:80…...

爬虫是什么?起什么作用?
【爬虫】 如果把互联网比作一张大的蜘蛛网,数据便是放于蜘蛛网的各个节点,而爬虫就是一只小蜘蛛,沿着网络抓取自己得猎物(数据)。这种解释可能更容易理解,官网的,就是下面这个。 爬虫是一种自动…...

代码随想录27期|Python|Day24|回溯法|理论基础|77.组合
图片来自代码随想录 回溯法题目目录 理论基础 定义 回溯法也可以叫做回溯搜索法,它是一种搜索的方式。 回溯是递归的副产品,只要有递归就会有回溯。回溯函数也就是递归函数,指的都是一个函数。 基本问题 组合问题(无序&…...
 : 大数据按分区导出数据)
mysql(49) : 大数据按分区导出数据
代码 import com.alibaba.gts.flm.base.util.Mysql8Instance;import java.io.BufferedWriter; import java.io.File; import java.io.FileWriter; import java.math.BigDecimal; import java.util.ArrayList; import java.util.Iterator; import java.util.List; import java.u…...
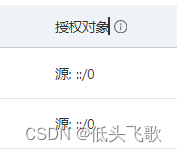
阿里云ECS配置IPv6后,如果无法访问该服务器上的网站,可检查如下配置
1、域名解析到这个IPv6地址,同一个子域名可以同时解析到IPv4和IPv6两个地址,这样就可以给网站配置ip4和ipv6双栈; 2、在安全组规则开通端口可访问,设定端口后注意授权对象要特殊设置“源:::/0” 3、到服务器nginx配置处,增加端口…...
基于SSM的双减后初小教育课外学习生活活动平台的设计与实现
末尾获取源码 开发语言:Java Java开发工具:JDK1.8 后端框架:SSM 前端:Vue 数据库:MySQL5.7和Navicat管理工具结合 服务器:Tomcat8.5 开发软件:IDEA / Eclipse 是否Maven项目:是 目录…...

HTTP前端请求
目录 HTTP 请求1.请求组成2.请求方式与数据格式get 请求示例post 请求示例json 请求示例multipart 请求示例数据格式小结 3.表单3.1.作用与语法3.2.常见的表单项 4.session 原理5.jwt 原理 HTTP 请求 1.请求组成 请求由三部分组成 请求行请求头请求体 可以用 telnet 程序测…...

前端性能优化二十四:花裤衩模板第三方库打包
(1). 工作原理: ①. externals配置在所创建bundle时:a. 会依赖于用户环境(consumers environment)中的依赖,防止将某些import的包(package)打包到bundle中b. 在运行时(runtime)再去从外部获取这些扩展依赖(external dependencies)②. webpack会检测这些组件是否在externals中注…...
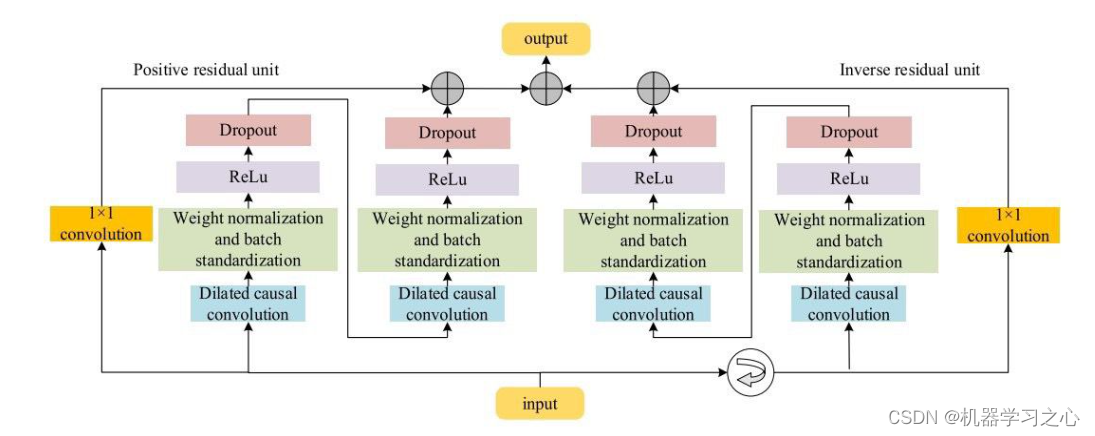
多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测
多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测 目录 多维时序 | MATLAB实现BiTCN-Multihead-Attention多头注意力机制多变量时间序列预测预测效果基本介绍模型描述程序设计参考资料 预测效果 基本介绍 多维时序 | MATLAB实现BiTCN-Multihea…...

Qt的简单游戏实现提供完整代码
文章目录 1 项目简介2 项目基本配置2.1 创建项目2.2 添加资源 3 主场景3.1 设置游戏主场景配置3.2 设置背景图片3.3 创建开始按钮3.4 开始按钮跳跃特效实现3.5 创建选择关卡场景3.6 点击开始按钮进入选择关卡场景 4 选择关卡场景4.1场景基本设置4.2 背景设置4.3 创建返回按钮4.…...

无法与IP建立连接,未能下载VSCode服务器
如题,在远程连接服务器的时候突然遇到了这个提示。 查阅了一圈,发现是VSCode版本自动更新惹的祸!!! 在VSCode的帮助->关于这里发现前几天VSCode自动更新了,我的版本号变成了1.100.3 才导致了远程连接出…...

UE5 学习系列(三)创建和移动物体
这篇博客是该系列的第三篇,是在之前两篇博客的基础上展开,主要介绍如何在操作界面中创建和拖动物体,这篇博客跟随的视频链接如下: B 站视频:s03-创建和移动物体 如果你不打算开之前的博客并且对UE5 比较熟的话按照以…...

2024年赣州旅游投资集团社会招聘笔试真
2024年赣州旅游投资集团社会招聘笔试真 题 ( 满 分 1 0 0 分 时 间 1 2 0 分 钟 ) 一、单选题(每题只有一个正确答案,答错、不答或多答均不得分) 1.纪要的特点不包括()。 A.概括重点 B.指导传达 C. 客观纪实 D.有言必录 【答案】: D 2.1864年,()预言了电磁波的存在,并指出…...

深入理解JavaScript设计模式之单例模式
目录 什么是单例模式为什么需要单例模式常见应用场景包括 单例模式实现透明单例模式实现不透明单例模式用代理实现单例模式javaScript中的单例模式使用命名空间使用闭包封装私有变量 惰性单例通用的惰性单例 结语 什么是单例模式 单例模式(Singleton Pattern&#…...

令牌桶 滑动窗口->限流 分布式信号量->限并发的原理 lua脚本分析介绍
文章目录 前言限流限制并发的实际理解限流令牌桶代码实现结果分析令牌桶lua的模拟实现原理总结: 滑动窗口代码实现结果分析lua脚本原理解析 限并发分布式信号量代码实现结果分析lua脚本实现原理 双注解去实现限流 并发结果分析: 实际业务去理解体会统一注…...

SAP学习笔记 - 开发26 - 前端Fiori开发 OData V2 和 V4 的差异 (Deepseek整理)
上一章用到了V2 的概念,其实 Fiori当中还有 V4,咱们这一章来总结一下 V2 和 V4。 SAP学习笔记 - 开发25 - 前端Fiori开发 Remote OData Service(使用远端Odata服务),代理中间件(ui5-middleware-simpleproxy)-CSDN博客…...

面向无人机海岸带生态系统监测的语义分割基准数据集
描述:海岸带生态系统的监测是维护生态平衡和可持续发展的重要任务。语义分割技术在遥感影像中的应用为海岸带生态系统的精准监测提供了有效手段。然而,目前该领域仍面临一个挑战,即缺乏公开的专门面向海岸带生态系统的语义分割基准数据集。受…...

NPOI操作EXCEL文件 ——CAD C# 二次开发
缺点:dll.版本容易加载错误。CAD加载插件时,没有加载所有类库。插件运行过程中用到某个类库,会从CAD的安装目录找,找不到就报错了。 【方案2】让CAD在加载过程中把类库加载到内存 【方案3】是发现缺少了哪个库,就用插件程序加载进…...

【 java 虚拟机知识 第一篇 】
目录 1.内存模型 1.1.JVM内存模型的介绍 1.2.堆和栈的区别 1.3.栈的存储细节 1.4.堆的部分 1.5.程序计数器的作用 1.6.方法区的内容 1.7.字符串池 1.8.引用类型 1.9.内存泄漏与内存溢出 1.10.会出现内存溢出的结构 1.内存模型 1.1.JVM内存模型的介绍 内存模型主要分…...

MyBatis中关于缓存的理解
MyBatis缓存 MyBatis系统当中默认定义两级缓存:一级缓存、二级缓存 默认情况下,只有一级缓存开启(sqlSession级别的缓存)二级缓存需要手动开启配置,需要局域namespace级别的缓存 一级缓存(本地缓存&#…...