Kafka设计原理详解
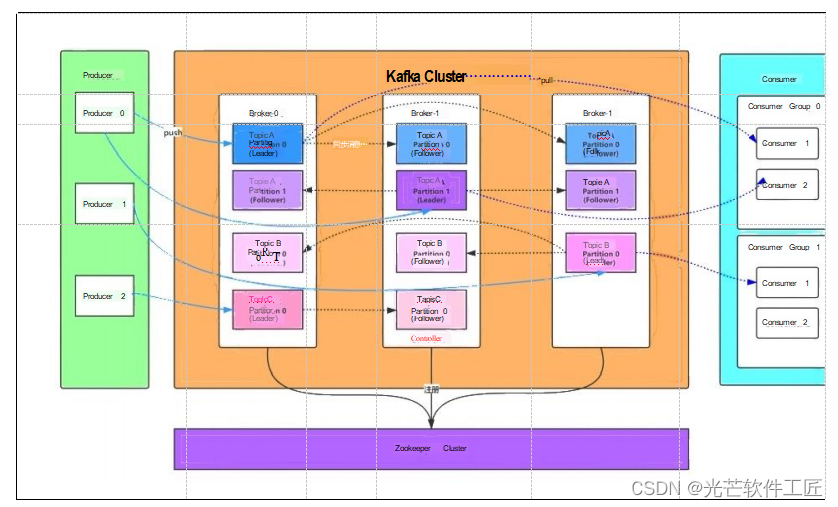
Kafka核心总控制器 (Controller)
在Kafka集群中,通常会有一个或多个broker,其中一个会被选举为控制器 (Kafka Controller),其主要职责是管理整个集群中所有分区和副本的状态。具体来说:
- 当某个分区的leader副本出现故障时,控制器负责选举新的leader副本。
- 当探测到某个分区的ISR集合发生变化时,控制器负责通知所有broker更新其元数据信息。
- 当使用kafka-topics.sh脚本为某个topic增加分区数量时,同样由控制器负责确保新分区被其他节点感知到。
Controller选举机制
Kafka集群在启动时会自动选举一台broker作为控制器,该选举过程的关键在于每个broker都尝试在Zookeeper上创建一个临时节点/controller,而Zookeeper会确保只有一个broker能够成功创建此节点,成为集群的控制器。如果当前的控制器宕机,其临时节点将消失,其他broker将监听该节点的变化,一旦发现节点消失,它们将再次竞选成为新的控制器,这便构成了控制器的选举机制。
控制器角色的broker需要承担一些额外的职责,包括:
- 监听与broker相关的变化,通过为Zookeeper中的
/brokers/ids/节点添加BrokerChangeListener来处理broker的增减变化。 - 监听与topic相关的变化,通过为Zookeeper中的
/brokers/topics节点添加TopicChangeListener来处理topic的增减变化,同时为/admin/delete_topics节点添加TopicDeletionListener以处理删除topic的操作。 - 从Zookeeper中读取并管理与topic、partition以及broker有关的所有信息,通过为所有topic对应的
/brokers/topics/[topic]节点添加PartitionModificationsListener来监听topic中分区分配的变化。 - 更新集群的元数据信息,并将其同步到其他普通的broker节点中。
Partition副本选举Leader机制
当控制器检测到某个分区的leader所在的broker宕机时,它会从ISR列表中选择第一个可用的broker作为新的leader,前提是参数unclean.leader.election.enable设置为false,这意味着只有在ISR列表中的副本之间进行选举。如果unclean.leader.election.enable设置为true,则表示在ISR列表中的所有副本都宕机时,也可以从ISR列表之外的副本中选择新的leader,这种设置可以提高可用性,但可能导致新leader的数据同步滞后。副本进入ISR列表需要满足以下两个条件:
- 副本节点不能产生分区,必须能够与Zookeeper保持会话并与leader副本保持网络连接。
- 副本必须能够复制leader上的所有写操作,并且不能滞后太多。滞后时间由
replica.lag.time.max.ms配置决定,超过此时间没有与leader同步的副本将被移出ISR列表。
消费者消费消息的offset记录机制
每个消费者定期将其消费分区的offset提交到名为__consumer_offsets的Kafka内部主题。提交时,使用key表示consumerGroupId + topic + 分区号,value表示当前的offset值。Kafka会定期清理__consumer_offsets主题中的消息,保留最新的offset记录。由于__consumer_offsets可能会受到高并发请求的影响,Kafka默认将其分配了50个分区(可以通过offsets.topic.num.partitions进行配置),以增加其并发处理能力。
消费者Rebalance机制
Rebalance指的是在消费组中的消费者数量发生变化或者消费的分区数发生变化时,Kafka会重新分配消费者与分区的关系。例如,如果消费组中的某个消费者崩溃,Kafka会自动将分配给它的分区重新分配给其他消费者,如果该消费者重新启动,则会再次接收到一些分区。需要注意的是,Rebalance仅适用于使用subscribe方式消费的情况,而不适用于使用assign方式手动指定分区的情况。
触发消费者Rebalance的情况包括:
- 消费组中的消费者数量发生变化。
- 动态增加了topic的分区。
- 消费组订阅了更多的topic。
在Rebalance过程中,消费者无法从Kafka消费消息,这可能会对Kafka的吞吐量产生影响,特别是在包含大量节点的Kafka集群中,Rebalance可能会耗费较长时间,因此应尽量避免在系统高峰期进行Rebalance操作。
Rebalance的过程可以概括如下:
当有新的消费者加入消费组时,消费者、消费组和组协调器之间会经历以下几个阶段。

第一阶段:选择组协调器(Selecting the Group Coordinator)
在消费者组(Consumer Group)中,每个消费者组会选择一个代表自己的组协调器(Group Coordinator)。这个组协调器的主要职责是监控该消费组内所有消费者的心跳,检测宕机情况,并启动消费者再平衡(Consumer Rebalance)。
每个消费者在启动时都会向 Kafka 集群的某个节点发送 FindCoordinatorRequest 请求,以查找与其对应的组协调器(Group Coordinator),然后建立与该协调器的网络连接。
组协调器的选择方式遵循以下公式:hash(consumer group id) % _consumer_offsets 主题的分区数。其中,分区的 leader 代表着该消费者组的协调器。
第二阶段:加入消费组(Joining the Consumer Group)
一旦成功找到了消费者组对应的 Group Coordinator,消费者将进入加入消费组的阶段。在这个阶段,消费者会向 Group Coordinator 发送 JoinGroupRequest 请求,并等待响应。然后,Group Coordinator 从消费者组中选择第一个加入的消费者作为组的领袖(Consumer Group Coordinator),并将消费者组的信息发送给领袖。
第三阶段:同步消费组(Sync Group)
消费者领袖通过向 Group Coordinator 发送 SyncGroupRequest 来同步消费组的状态。随后,Group Coordinator 将分区分配方案下发给各个消费者,消费者将根据指定的分区 leader broker 进行网络连接和消息消费。
消费者再平衡的分区分配策略
消费者再平衡有三种主要策略:range(范围)、round-robin(轮询)和sticky(粘性)。Kafka 提供了消费者客户端参数 partition.assignment.strategy 来设置消费者与订阅主题之间的分区分配策略,默认情况下是使用 range 分配策略。
以一个主题具有 10 个分区(0-9)和三个消费者为例,不同策略的分配如下:
-
Range 策略:按照分区序号排序,前 1 个消费者分配 4 个分区,后 2 个消费者分配 3 个分区。
- 消费者 1:分区 0-3
- 消费者 2:分区 4-6
- 消费者 3:分区 7-9
-
Round-robin 策略:轮流分配分区,每个消费者分到不同的分区。
- 消费者 1:分区 0, 3, 6, 9
- 消费者 2:分区 1, 4, 7
- 消费者 3:分区 2, 5, 8
-
Sticky 策略:初始时类似于 round-robin,但在再平衡时,需要确保两个原则:
- 分区分配尽可能均匀。
- 分区分配尽可能与上次分配相同。 当两者发生冲突时,第一个原则优先考虑。例如,如果第三个消费者挂掉,重新分配后的结果如下:
- 消费者 1:分区 0-3, 7
- 消费者 2:分区 4-6, 8, 9
生产者发布消息机制剖析
-
写入方式:生产者采用推送(push)模式将消息发布到 Kafka Broker。每条消息都被附加到相应的分区,从而实现顺序写入磁盘。这种顺序写入方式提高了 Kafka 的吞吐量,因为与随机写入内存相比,顺序写入磁盘更加高效。
-
消息路由:当生产者发送消息到 Broker 时,会根据分区算法选择将消息存储到哪个分区。路由机制如下:
- 如果指定了分区,则直接使用指定的分区。
- 如果未指定分区但指定了键(key),则根据键的值进行哈希计算,以选出一个分区。
- 如果既未指定分区也未指定键,则使用轮询方式选出一个分区。
这些步骤组成了 Kafka 生产者的消息发布流程。
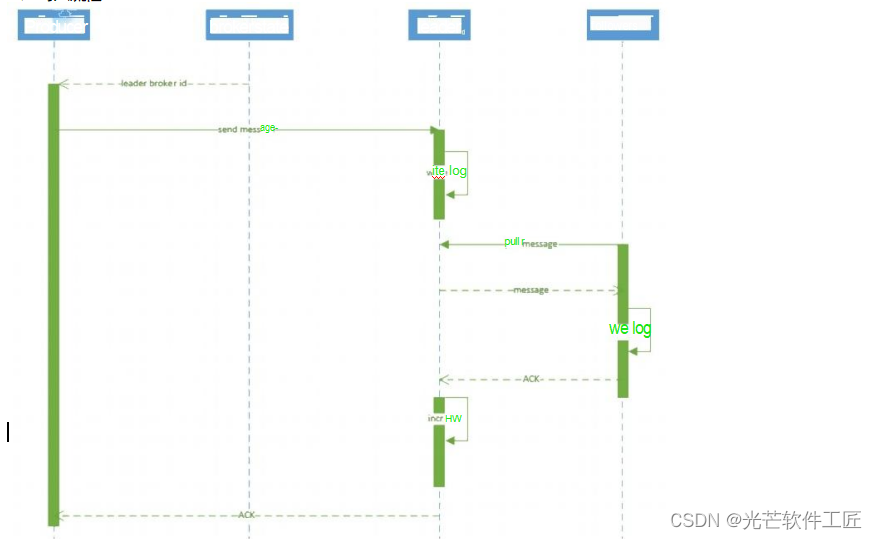
Kafka 消息写入和高水位(HW)详解
Kafka 中消息的写入和高水位(High Watermark,简称 HW)有关重要步骤,这些步骤如下:
-
生产者查找分区 leader: 生产者首先从 Zookeeper 的"/brokers/.../state"节点中找到该分区的 leader。
-
生产者向 leader 发送消息: 生产者将要发送的消息发送给分区的 leader。
-
Leader 写入消息到本地日志: 分区的 leader 将接收到的消息写入自己的本地日志。
-
Followers 从 Leader 拉取消息: 非 leader 的 followers 从分区的 leader 拉取消息,并将这些消息写入自己的本地日志。随后,followers 向 leader 发送确认 ACK。
-
Leader 收到所有 ISR 中的 Replica 的 ACK: Leader 收到来自 ISR(In-Sync Replicas,同步副本)中所有副本的确认 ACK 后,将高水位(HW,即最后 commit 的 offset)增加,并向生产者发送 ACK。
高水位(HW)和日志末尾偏移(LEO)详解
高水位(HW)通常用于限制消费者的读取位置。在 Kafka 中,HW 是 ISR 中最小的 LEO(Log-End-Offset)的值。消费者最多只能消费到 HW 所在的位置。每个 Replica(副本)都维护自己的 HW 状态,包括 Leader 和 Followers。Leader 负责等待消息被 ISR 中的所有副本同步后,才会更新 HW。这确保了消息不会在被生产后立即被消费,而是要等待所有 ISR 中的副本都同步成功后才能被消费。这种机制保证了即使 Leader 所在的 Broker 失效,消息仍然可以从新选举的 Leader 中获取。
对于来自内部 Broker 的读取请求,通常不会受到 HW 的限制,因为这些请求是针对 Kafka 内部的,而不需要考虑消费者的限制。HW 主要用于外部消费者,以确保它们不会读取到未同步的消息。

结合HW 和LEO看下 acks=1的情况

日志分段存储
Kafka一个分区的消息数据对应存储在一个文件夹下,以topic名称+分区号命名,消息在分区内是分段(segment)存储, 每个段的消息都存储在不一样的log文件里,这种特性方便old segment file快速被删除,kafka规定了一个段位的 log 文 件最大为1G, 做这个限制目的是为了方便把 log 文件加载到内存去操作:

这个9936472之类的数字,就是代表了这个日志段文件里包含的起始 Offset, 也就说明这个分区里至少都写入了接近 1000万条数据了。
Kafka Broker 有一个参数,log.segment.bytes,限定了每个日志段文件的大小,最大就是1GB。
一个日志段文件满了,就自动开一个新的日志段文件来写入,避免单个文件过大,影响文件的读写性能,这个过程叫做
log rolling, 正 在 被 写 入 的 那 个 日 志 段 文 件 , 叫 做 active log segment。
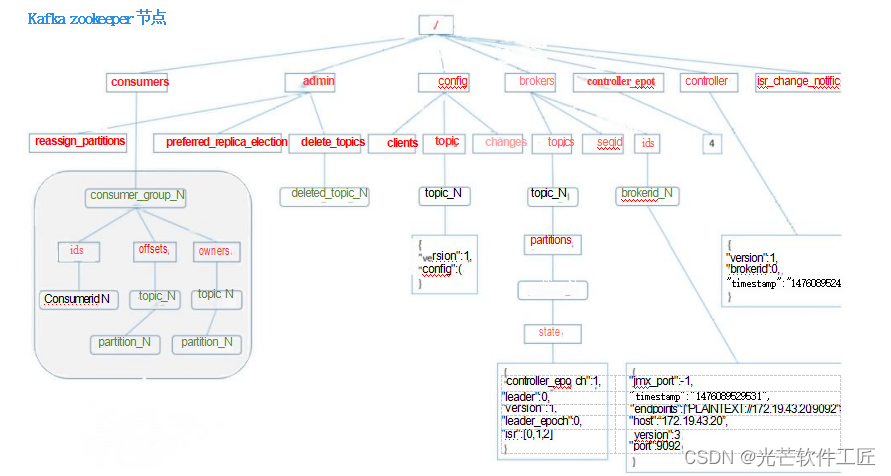
最后附一张zookeeper 节点数据图:
相关文章:
Kafka设计原理详解
Kafka核心总控制器 (Controller) 在Kafka集群中,通常会有一个或多个broker,其中一个会被选举为控制器 (Kafka Controller),其主要职责是管理整个集群中所有分区和副本的状态。具体来说: 当某个分区的leader副本出现故障时&#…...

光耦继电器
光耦继电器(光电继电器) AQW282SX 282SZ 280SX 280SZ 284SX 284SZ 212S 212SX 21 2SZ 文章目录 光耦继电器(光电继电器)前言一、光耦继电器是什么二、光耦继电器的类型三、光电耦合器的应用总结前言 光耦继电器在工业控制、通讯、医疗设备、家电及汽车电子等领域得到广泛应…...
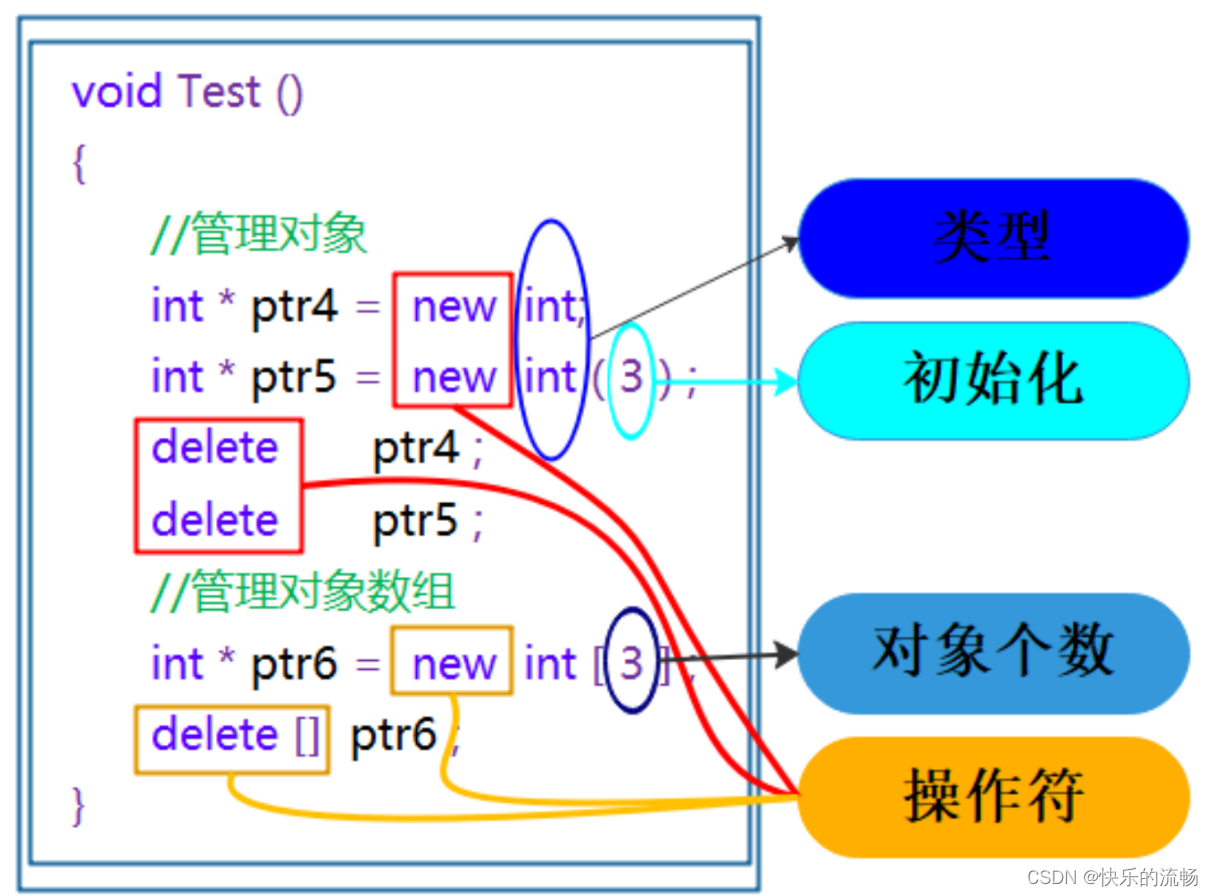
【C++练级之路】【Lv.5】动态内存管理(都2023年了,不会有人还不知道new吧?)
目录 一、C/C内存分布二、new和delete的使用方式2.1 C语言内存管理2.2 C内存管理2.2.1 new和delete操作内置类型2.2.2 new和delete操作自定义类型 三、new和delete的底层原理3.1 operator new与operator delete函数3.2 原理总结3.2.1 内置类型3.2.2 自定义类型 四、定位new表达…...
2016年第五届数学建模国际赛小美赛A题臭氧消耗预测解题全过程文档及程序
2016年第五届数学建模国际赛小美赛 A题 臭氧消耗预测 原题再现: 臭氧消耗包括自1970年代后期以来观察到的若干现象:地球平流层(臭氧层)臭氧总量稳步下降,以及地球极地附近平流层臭氧(称为臭氧空洞&#x…...
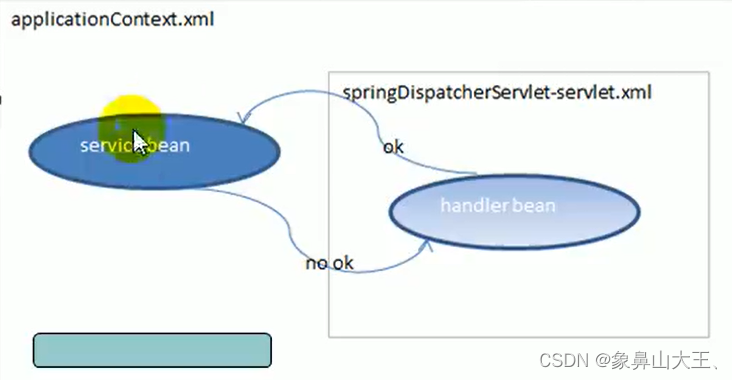
springMVC-与spring整合
一、基本介绍 在项目开发中,spring管理的 Service和 Respository,SrpingMVC管理 Controller和ControllerAdvice,分工明确 当我们同时配置application.xml, springDispatcherServlet-servlet.xml , 那么注解的对象会被创建两次, 故…...

【二叉树】【单调双向队列】LeetCode239:滑动窗口最大值
作者推荐 map|动态规划|单调栈|LeetCode975:奇偶跳 涉及知识点 单调双向队列 二叉树 题目 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动…...

如何使用树莓派Bookworm系统中配置网络的新方法NetworkManager
树莓派在 10 月新出的 Bookworm 版本系统中,将使用多年的 dhcpcd 换成了 NetworkManager(以前是在rasp-config中可选),这是因为 Raspberry Pi OS 使用的是 Debian 内核(和 Ubuntu 一样),所以树莓…...
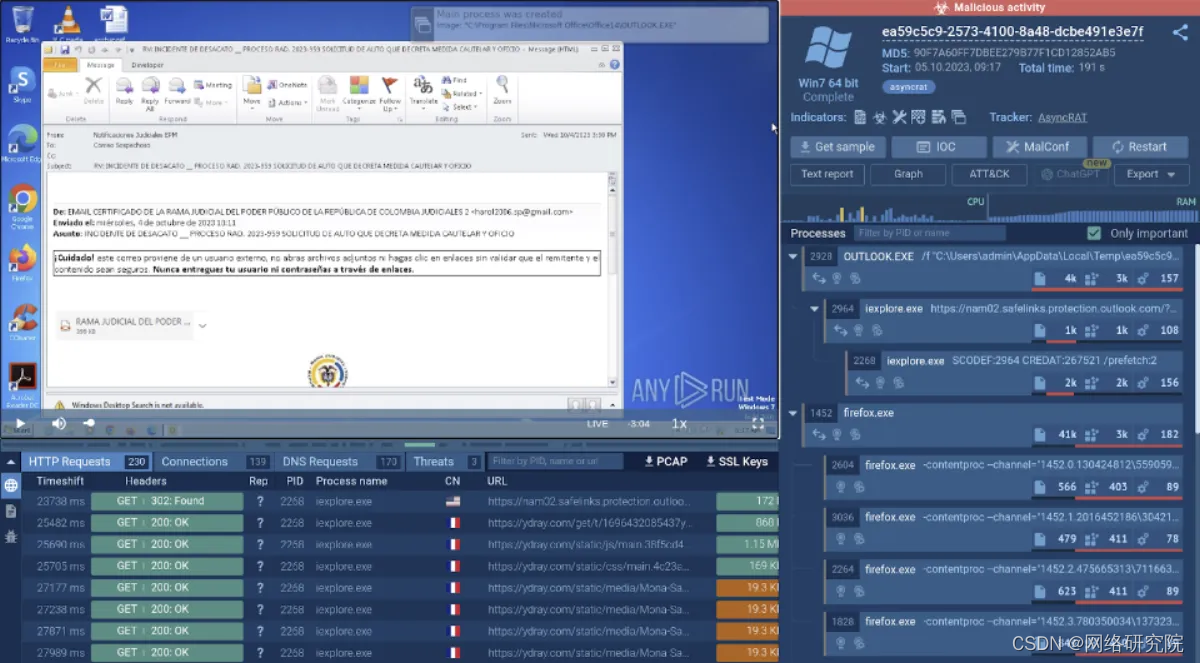
恶意软件分析沙箱在网络安全策略中处于什么位置?
恶意软件分析沙箱提供了一种全面的恶意软件分析方法,包括静态和动态技术。这种全面的评估可以更全面地了解恶意软件的功能和潜在影响。然而,许多组织在确定在其安全基础设施中实施沙箱的最有效方法方面面临挑战。让我们看一下可以有效利用沙盒解决方案的…...
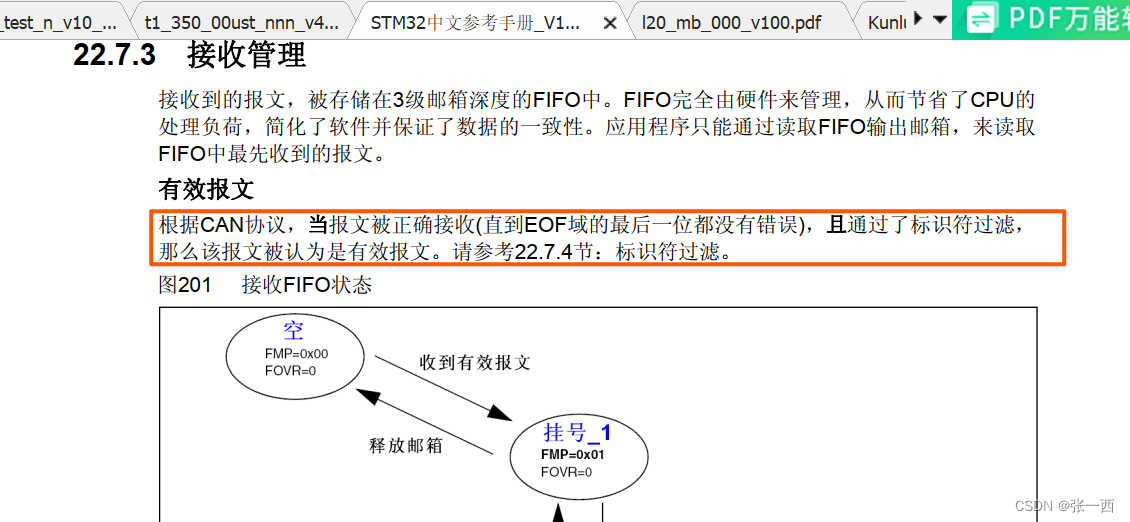
ARM学习(24)Can的高阶认识和错误处理
笔者来聊一下CAN协议帧的认识和错误处理。 1、CAN协议帧认识 CAN 差分信号,是经过CAN收发器转成差分信号的,CAN RX和TX是逻辑电平。CAN的基础知识,可参考笔者这边文章:ARM学习(21)STM32 外设Can的认识与驱…...

网络通信--深入理解网络和TCP / IP协议
计算机网络体系结构 TCP/IP协议族 TCP / IP 网络传输中的数据术语 网络通信中的地址和端口 window端查看IP地址和MAC地址:ipconfig -all MAC层地址是在数据链路层的;IP工作在网络层的 MAC是48个字节,IP是32个字节 在子网(局域…...
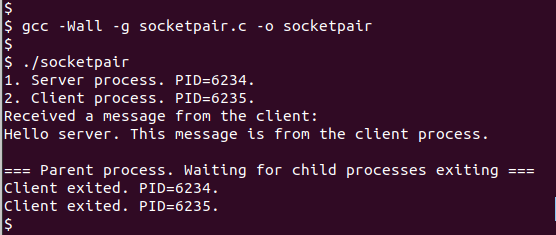
IPC之九:使用UNIX Domain Socket进行进程间通信的实例
socket 编程是一种用于网络通信的编程方式,在 socket 的协议族中除了常用的 AF_INET、AF_RAW、AF_NETLINK等以外,还有一个专门用于 IPC 的协议族 AF_UNIX,IPC 是 Linux 编程中一个重要的概念,常用的 IPC 方式有管道、消息队列、共…...
学习在UE中通过Omniverse实现对USD文件的Live-Sync(实时同步编辑)
目标 前一篇 学习了Omniverse的一些基础概念。本篇在了解这些概念的基础上,我想体验下Omniverse的一些具体的能力,特别是 Live-Sync (实时同步) 相关的能力。 本篇实践了使用Omniverse的力量在UE中建立USD文件的 Live-Sync 编辑。由于相关的知识我是从…...
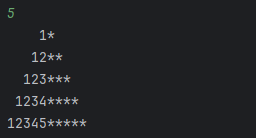
实现打印一个数字金字塔。例如:输入5,图形如下图所示
1*12**123***1234**** 12345*****#include<stdio.h> void main() {int i,j,l,n,k;scanf("%d",&n);/**********Program**********//********** End **********/ } 当我们拿到这个题目的时候可以看见题目给了我们五个变量,其中n是我们输入的数…...

hive sql常用函数
目录 一、数据类型 二、基础运算 三、字符串函数 1、字符串长度函数: length() 2、字符串反转函数:reverse 3、字符串连接函数 4、字符串截取函数 5、字符串分割函数:split 6、字符串查找函数 7、ascii 8、base64 9、character_length 10、c…...

Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中
Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中 把两个分区的数据合并到同一个分区下把其中一个分区的数据通过append方式添加到另一个分区即可 %spark val df spark.sql("select * from optics_prod.product_1h_a where datetime202311142…...

《重构-改善既有代
重要列表 1、如果你发现自己需要为程序添加一个特性,而代码结构使你无法很方便地达成目的,那就先重构哪个程序,使特性的添加比较容易的进行,然后再添加特性 2、重构前,先检查自己是否有一套可靠的测试机制࿰…...
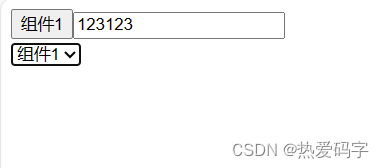
vue3(七)-基础入门之事件总线与动态组件
一、事件总线 事件总线使用场景: 两个兄弟组件之间的传参,或者两个没有关联的组件之间的传参 html :引入 publicmsg 与 acceptmsg 自定义组件 (自定义组件名称必须小写) <body><div id"app"><publicmsg></…...

【计算机网络】网络层——IP协议
目录 一. 基本概念 二. 协议报文格式 三. 网段划分 1. 第一次划分 2. CIDR方案 3. 特殊的IP地址 四. IP地址不足 1. 私有IP和公网IP 2. DHCP协议 3. 路由器 4. NAT技术 内网穿透(NAT穿透) 五. 路由转发 路由表生成算法 结束语 一. 基本概念 IP指网络互连协议…...

《钢结构设计标准》中抗震性能化设计的概念
文章目录 0. 背景1. 前言2. 什么是抗震性能化设计3. 我国规范是如何实现性能化设计的4. 从能量角度理解性能化设计05. 《钢结构设计标准》抗震性能化设计的思路06. 《钢结构设计标准》抗震性能化设计的步骤 0. 背景 关于抗震性能化设计,之前一直理解的很模糊&#…...

【算法】【动规】回文串系列问题
文章目录 跳转汇总链接3.1 回文子串3.2 最长回文子串3.3 分割回文串 IV3.4 分割回文串II(hard) 跳转汇总链接 👉🔗动态规划算法汇总链接 3.1 回文子串 🔗题目链接 给定一个字符串 s ,请计算这个字符串中有多少个回文子字符串。 …...

遍历 Map 类型集合的方法汇总
1 方法一 先用方法 keySet() 获取集合中的所有键。再通过 gey(key) 方法用对应键获取值 import java.util.HashMap; import java.util.Set;public class Test {public static void main(String[] args) {HashMap hashMap new HashMap();hashMap.put("语文",99);has…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

关于nvm与node.js
1 安装nvm 安装过程中手动修改 nvm的安装路径, 以及修改 通过nvm安装node后正在使用的node的存放目录【这句话可能难以理解,但接着往下看你就了然了】 2 修改nvm中settings.txt文件配置 nvm安装成功后,通常在该文件中会出现以下配置&…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

【开发技术】.Net使用FFmpeg视频特定帧上绘制内容
目录 一、目的 二、解决方案 2.1 什么是FFmpeg 2.2 FFmpeg主要功能 2.3 使用Xabe.FFmpeg调用FFmpeg功能 2.4 使用 FFmpeg 的 drawbox 滤镜来绘制 ROI 三、总结 一、目的 当前市场上有很多目标检测智能识别的相关算法,当前调用一个医疗行业的AI识别算法后返回…...

OPenCV CUDA模块图像处理-----对图像执行 均值漂移滤波(Mean Shift Filtering)函数meanShiftFiltering()
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在 GPU 上对图像执行 均值漂移滤波(Mean Shift Filtering),用于图像分割或平滑处理。 该函数将输入图像中的…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

在web-view 加载的本地及远程HTML中调用uniapp的API及网页和vue页面是如何通讯的?
uni-app 中 Web-view 与 Vue 页面的通讯机制详解 一、Web-view 简介 Web-view 是 uni-app 提供的一个重要组件,用于在原生应用中加载 HTML 页面: 支持加载本地 HTML 文件支持加载远程 HTML 页面实现 Web 与原生的双向通讯可用于嵌入第三方网页或 H5 应…...

Hive 存储格式深度解析:从 TextFile 到 ORC,如何选对数据存储方案?
在大数据处理领域,Hive 作为 Hadoop 生态中重要的数据仓库工具,其存储格式的选择直接影响数据存储成本、查询效率和计算资源消耗。面对 TextFile、SequenceFile、Parquet、RCFile、ORC 等多种存储格式,很多开发者常常陷入选择困境。本文将从底…...