[编程相关]正则表达式Regex语法
--目录--
- 0. 前言
- 1. 正则语法
- 2. 正则搜索语法
- (1)字符集 Character_Classes
- (2)锚定符 Anchors
- (3)计数 Quantifiers
- (4)分组与索引 Group_And_Reference
- (5)周围 Look_Around
- (6)转义符 Escape_Characters
- (7)交替/或 Alternation
- (8)标志 flags
- 3. 正则替换语法
- 4. 正则性能
- 5. 结束
0. 前言
偶尔会触及到正则的使用,每次有点一知半解,查得到就用了,自己需求有点不一样,改改就错了。终于找个空闲时间研究了一下正则,且记录下来以后可以查略,也希望对你有所收获。
附上无意间逛到的两个网站。一个校验、尝试、学习正则的网站,虽然是英文的,但用起来还挺好用的!推荐!本文挺多内容也是从这里学的。然后,原本还想整理一下常用式,但发现大家伙整理得还挺多的,就不再弄了,附上一个博主的整理。
// 校验、尝试、学习正则的网站(随便逛到的,英文)
https://regexr.com/
// 常用式整理(其他博主的)
https://blog.csdn.net/weixin_39359534/article/details/118676496
好了接下来就开始进入正题吧。
1. 正则语法
正则表达式 (Regular Expression)(regex、regexp或RE),描述满足某一规则的字符串,用于检索、替换字符串。检索和替换是关键,所以这里大概可以分成怎么描述要检索的字符,以及怎么描述替换的内容两个大部分,只不过大部分时候我们一般只用到了检索。替换用的少。
而且正则的内容是非常有固定逻辑和规则的,如果把特殊字符都独立来看,列一张元字符表作用这种,看着都头晕。所以还是应该把正则的相关匹配逻辑分开,逐一理解就不容易混乱了。一个简单正则描述,在js/ts中可以这样被表示,两侧的斜杠只是表示这是一个正则表达式,没有实际意义。
let regex = /hello/ //在字符串中查找hello
简单查一个hello的一个正则,如果用于检测在js中我们可以用test,如果用于替换,可以用replace
let s1 = "hello world"
let s2 = "hellA world"
let regex = /hello/ //在字符串中查找hello
regex.test(s1) // true
regex.test(s2) // false
s1.replace(regex, 'hi') // "hi world"
s2.replace(regex, 'hi') // "hellA world"
如果我们要查询的内容规则比较复杂的话,就需要更多的语法来描述了。
2. 正则搜索语法
对于正则的搜索部分呢,有相当多内容,也可以带着独立的4个要求去学内容,检查字符串是否满足正则。如果下面这几种问题都解决了,那正则的内容,也就差不多了。
1 - 只包含数字
2 - 没有“he”
3 - 有“ha”或者“^_^"
4 - 有“HAahahHahahHA”,忽略大小写
(1)字符集 Character_Classes
有些时候,我们某位置要查的内容是数字0到9都行,或者小写字符都行,并不是一个具体的字符,那此时就需要一种语法来描述一下我们要查的非具体的字符(某一个)是啥,所以我们就可以用字符集了!
| 符号 | 含义 |
|---|---|
| . | 任意字符 |
| [] | 表示包含字符中任意的一个 |
| [^] | 不表示包含字符中任意的一个,^必须紧跟[ |
要注意的是这里针对的,都是在描述字符,而非字符串,比如“.”,用来指代任意一个字符,“[ABC]”指代“A“、“B“或者”C“。“[^ABC]"这里则相反,不能是“A“、“B“或者”C“,如下。
let regex_all = /hell./
regex_all.test("hello world") // true
regex_all.test("hellA world") // true
regex_all.test("hel world") // falselet regex_set = /hell[ABC]/
regex_set.test("hello world") // false
regex_set.test("hellA world") // truelet regex_nSet = /hell[^ABC]/
regex_nSet.test("hello world") // true
regex_nSet.test("hellA world") // false
如果字符集很多的情况下我们也不可能每个都写,有一些特定的情况可以被简化描述,比如 字符是一串连续的符号。
| 符号 | 含义 |
|---|---|
| [A-C] | a-b,指代a和b中间的任意字符,字符码范围 |
注意这里是字符码范围,比如[1-a],可以指代字符码为49-97的所有字符,[a-c]等同于[abc]。更常用的比如字母、数字、单词等,有更简化的表述,如下也可以在字符集[]或者[^]外直接可以使用,相当于自动套上[]
| 符号 | 含义 |
|---|---|
| [\w] | 匹配单词,等同于[A-Za-z0-9_] |
| [\W] | 匹配非单词,\w的相反结果 |
| [\d] | 匹配数字,等同于[1-9] |
| [\D] | 匹配非数字,\d的相反结果 |
| [\s] | 匹配空白符(空格换行制表符等),类似于[\n\r\t] |
| [\S] | 匹配单词,等同于’A-Za-z0-9_’ |
其他的比如\p{L},\P{L},\p{Han},\P{Han},用于匹配一下特殊的Unicode字符,需要注意的是,所有的浏览器都适用。这里也用一些小例子
let regex_a2d = /[a-d]/
regex_a2d.test("windows10") // false
regex_a2d.test("android") // truelet regex_w = /[\w]/
regex_w.test("windows10") // true
regex_w.test("android") // truelet regex_d = /[\d]/
regex_d.test("window10") // true
regex_d.test("android") // falselet regex_W = /[\W]/
regex_W.test("windows10") // false
regex_W.test("android") // false
这里不知是否有伙伴会疑惑,为啥/[\d]/,对"window10"是验证通过的。其实是因为正则是描述一个我们需要的字符串,也就是说对于/[\d]/,它表达的意思是我们需要一个0-9的字符,那“window10”中可还有两个了,当然满足了,所以结果不出意外的是true。
那对于想要整个字符串都值包含数字咋办,光靠描述字符可做不到,所以还要看下一节。
(2)锚定符 Anchors
当我们想查找特定位置为hello的字符串时,单纯描述字符已经无法满足这种需求了,所以需要描述位置的语法,锚定符。
| 符号 | 含义 |
|---|---|
| ^ | 锚定字符串的开头 |
| $ | 锚定字符串的结尾 |
| \b | 锚定单词的两边,单词判断于\w相同 |
| \B | 锚定非单词的两边,单词判断于\w相同 |
锚定符,顾名思义,像锚一样固定了某个位置,比如 ^ 就是指明了这个位置是开始,比如 /^hello/,就是指,开头后面是hello,就是要一个以hello为开头的字符串。同理,\b也就说这个位置是个单词,/\bhello/,单词的开头是hello,/hello\b/,指单词以hello结尾。如果是/\bhello\b/,就是要需要hello单词本身,因为开头到结尾只有hello,注意哦,这里"hellohello"也是不行的,只有hello本身可以。ok来点例子
let regex_start = /^hello/
regex_start.test("hello world") // true
regex_start.test("world hello") // falselet regex_end = /hello$/
regex_end.test("hello world") // false
regex_end.test("world hello") // truelet regex_b = /\bhello/
regex_b.test("hello world") // true
regex_b.test(" hello world") // true
regex_b.test("_hello world") // false
上节讲到,要匹配一个字包含数字的字符串,现在貌似有点办法,/^\b$/,开头到结尾都是得数字!不过有个问题,就是能有一个数字,就是说“1”可以通过,“11”就不行了。数量的问题,就需要下一节的计数来解决了。
(3)计数 Quantifiers
有些时候不只字符内容不确定,有可能字符数量也不确定,比如要1-3个数字。甚至有时候数量也不是确定的,那这个时候,这个时候,就需要计数!来解决这个问题、
| 符号 | 含义 |
|---|---|
| {n,m} | {n,m}:匹配n到m个描述项,{n,m}前面可以为字符、字符集或者字符组 |
| {n,} | {n,}: 匹配n或者更多个描述项 |
计数这个最好理解了,我们直接上例子。
let regex_oneMore = /\d{1,}/
regex_oneMore.test("123") // true
regex_oneMore.test("abc1") // true
regex_oneMore.test("abc") // falselet regex_numOnly = /^\d{1,}$/
regex_oneMore.test("123") // true
regex_oneMore.test("abc1") // false
regex_oneMore.test("abc") // false
这里的话,是的我们成功解决了上边一直提的问题,要一个只包含数字的字符串,就是/^\d{1,}$/,这个正则现在应该很好理解了,就是从头到尾,有任意多个字符。
这里也可以反应一个问题,就是正则的比较好的思考思路是单元化(个人感觉),比如说你要一个“都是字符的字符串”,应该单元的去描述他每个单元的规则。”都是”说明要从开头到结尾/^$/,有任意多个单元所以是{1,},单元是要求字符数字是\d,这样就比较好处理。
一个情况是,数量是不确定时,会优先匹配更多的数量,是贪婪模式的。比如当/xa{2,4}/时,“xaaaaa”,就会被匹配为xaaaa。那如果希望尽量少的匹配字符结果,就可以给计量后加上?,就可以让其变为懒惰模式。比如当/xa{2,4}?/时,“xaaaaa”,就会被匹配为xaa,够了就收手了,相当lazy。检查的时候没有影响,但替换单词的时候就会有影响了,看例子!
let regex_greedy = /\d{2,}/
"12345abcde".replace(regex_greedy,"%") // %abcdelet regex_lazy = /\d{2,}?/
"12345abcde".replace(regex_lazy ,"%") // '%345abcde'
然后这里有没有发现每次都要比较多的字符描述,比如/\d{1,}/,我字符才一个,但计数就得3/4个符号了,这样不够方便、不好理解,看着乱,所以有一些简化的描述。如下!
| 符号 | 含义 |
|---|---|
| {n} | 等价于{n,n} |
| + | 等价于{1,} |
| * | 等价于{0,} |
| ? | 等价于{0,1} |
稍微绕一点的就是??,比如/xa??/,其实等价于/xa{0,1}?/,其他的就不过多描述了。
计量是仅表述前一个项的,比如,/\d{2,3}/就表示要2到3个字符,/ha{2,3}/就表示要“haa”或者“haaa”。但我这人生性爱笑,只想听“hahahahahaha”。又到了处理不了的地方,现在我们只能描述单个字符,所以呢,是的,又到得下一节了。
(4)分组与索引 Group_And_Reference
对于特定的字符序列组合,描述一个字符是不足够的,可以用就()了,字符组!这里套上括号的通常是为了再对这对字符做处理比如,重复匹配多少次这种, 如果只是/ha/和/(ha)/是几乎没有区别的,但比如说要比配多个ha,那就可以用/(ha)+/的这种正则来表述了!所以分组是把固定的字符序列打包成一组,方便我们后续再描述这个字符组。
除了计数这种直接描述前一项的方式,我们也可以通过索引来调用分组,比如 \3 表示第3个分组的内容。表来!~
| 符号 | 含义 |
|---|---|
| () | 特定的字符组 |
| (?: ) | 特定的字符组,但不创建所以不会被索引 |
| \n | 索引到第n个字符组。索引从1开始,比如 /(ha)a\1/相当于/(ha)a(ha) |
有个不被索引的这个分组,不常用,其实主要是为了有时候我们确实需要对某个组做处理,但是后续不想再索引到他了,就可以用了。比如原本需求是/(x)\1\1\1/,需求改了要和气点,需要前面带点“ha”才行。那现在正则也得改,如果直接加/(ha)+(x)\1\1\1/,那就坏了,\1都索引到ha了,所以就可以用改成/(?ha)+(x)\1\1\1/,这样这个组就不会被后面的索引到了,正常运行!
需要注意的是,字符集[][^]中描述的是字符,而()描述的是字符串。所以**()内可以包含[]。但()分组的语法在[]内是无效的**,会被视为普通字符"(“和”)"。就直接上例子了,来点笑脸。
let regex_ha = /(ha)+/
"hahahahahahaxiaohehe".replace(regex_ha ,"^_^") // '^_^xiaohehe'
此外(?<name>ABC) 创建可以被特定名字索引的字符组,但不是所有的浏览器都适用,也没试出所以然,就不多说了。
不过呢,作为ha党,是不喜欢hehe的,所以我希望匹配一个不带“he”的字符串,问题又来了,这个处理不了。因为没有非字符组这个概念。直接下一章!
(5)周围 Look_Around
有些字符我们是希望其周围有某个字符组,但不要匹配到他,比如匹配png图标名,“test1.png,test2.txt”,只希望匹配到test1这个名字,就可以使用(?=)或者(?!)去查询到结果后,剔除掉周围(前或者后看具体位置)不包含所需结果的匹配项。此外(?<=)和(?<!)用于在查询之前先匹配周围字符组,但不是所有的浏览器都适用,不讨论了。表来。
| 符号 | 含义 |
|---|---|
| (?=) | 查询到结果后,剔除周围不包含所需结果的匹配项 |
| (?!) | 查询到结果后,剔除周围包含所需结果的匹配项 |
这里看起来是稍微有点绕,但看例子就很容易理解了。.下面例子中会用到/g,其实是一个标志位,表示全局匹配,找到所有的匹配项才结束。标志位将会在后面(*)再具体介绍。
"1pt 2px 3em 4px".replace(/\d(?=px)/g,"-") //'1pt -px 3em -px'
"1pt 2px 3em 4px".replace(/\d(?!px)/g,"-") //'-pt 2px -em 4px'
在拥有了这个语法之后,现在我们可以用不包含字符组来描述我们的需求了。比如我们希望,匹配一个不包含字符组"he"的字符串,用来过滤一下我们不想看到的日志,就可以用/^((?!he).)*$/,其实是描述了我们通过描述期望的字符单元,来达到不需要某个字符串的结果。(?!he)表达字符前面不能包含"he",那外面/^()*$/就表示字符串从开始到结尾要匹配上组(),所以整个字符串,也就包含不了"he"
同理,字符串不包含"ABC"或者"XYZ",那就是/^((?!ABC)(?!XYZ).)*$/
let regex = /^((?!he).)*$/
regex.test("hahahaha123") // true
regex.test("hahahahe123") // false
现在呢,学得多一些了,想法也多一些,不满于“hahahahaha”了,要加点颜表情,“^ _ ^”,那可和锚定字符冲突了呀,咋搞?这个估计大家都懂,转义!有请超级字符,转义符 "\“ 登场。
(6)转义符 Escape_Characters
转义符,感觉用得都很频繁了,就是当有些字符是有特殊意义的,而我们需要匹配这个字符本身的时候就可以使用转义符,将其变为字符本身的含义。
此外,有些字符是不好被打出来的,那么就可以8进制或者16进制来表示,比如\141,\x61,都是指代字符码97也就是a。一些老牌搭档,比如\r,\n这种也是可以正常使用的。表来~
| 符号 | 含义 |
|---|---|
| +*?^$.[]{}()|/ | 正则用到的特殊字符,都可以加\转义为字符原本的意义 |
| \000 | 指代8进制表示字符码对应的字符,从0-255,为\000)到\377,比如\141表示a |
| \xFF | 指代8进制表示字符码对应的字符,比如\x61表示a |
| \cZ | 指代控制字符1-26对应A-Z(a-z),比如\cI或者\ci,等价于\x09(字符码9) |
| \t\n\v\f\r\0 | 制表\t,换行\n,垂直制表\v,换页\f,光标换行\r,空字符\0 |
| \u{FFFF} | 指代unicode编码的字符,但不是所有浏览器都支持,比如/[\u4e00-\u9fa5]/ |
“正则用到的特殊字符”中特殊的是,字符集[]或者[^]中,只有其中只有 \-] 可以被转义,因为其他字符在字符集中不能发挥作用 ,没有特殊意义。
有一个和之前冲突的点是,当\1在有1分组的时候,希望被当成字符使用,比如用\1查询字符码为1的字符,可以用[\1]指代,利用分组在字符集中不生效的方法来实现。此外,当没有对应字符组的时候,会直接当转义符用,比如\2,但只有一个或者更少的字符组,那么就是指代字符码为2的字符。
无压力,来点颜表情~
let regex_xiao = /\^_\^/
"^_^xiao".replace(regex_xiao ,"haha") // 'hahaxiao'
现在总算可以很完美的使用颜文字了。那有些时候呢,我们是希望能找到haha或者颜表情^_^,就,下一节。
(7)交替/或 Alternation
上述的操作经常是处于一种 并且 的逻辑中,比如/(win)(mac)/,就只能匹配上winmac这个字符了,因为是win并且mac的一种逻辑,那如果我们想要win或者mac都能匹配上,就是 或 逻辑,此时"|"就应运而生。这个在正则中为Alternation,交替,应该原意是指用左右交替匹配。
| 符号 | 含义 |
|---|---|
| | | 匹配左或者右任意中一个成立,左右是一个正则表达式 |
/(win)|(mac)/,这样就达到我们要的效果了。当然也不只能用一次,比如可以用多个或逻辑结合,比如(win)|(mac)|(ios)|(android)。
let regex_mobile = /(ios)|(android)/
regex_mobile.test("win11") // false
regex_mobile.test("ios") // true
regex_mobile.test("mac") // false
regex_mobile.test("android") // truelet regex_more = /(win)|(mac)|(linux)|(ios)|(android)/
regex_more.test("win11") // true
regex_more.test("ios") // true
regex_more.test("mac") // true
regex_more.test("android") // true
那ha或颜文字的问题也就解决了
let regex = /(ha)|(\^_\^)/
regex.test("hahaha") // true
regex.test("^_^++") // true
regex.test("-_-+++") // false
(8)标志 flags
标志位一共是有igmuys这6个标志位,用于表示正则的匹配模式,几个模式一般是独立的,有不可同时一起使用的可以。
| 符号 | 含义 |
|---|---|
| i | ignore case,忽略大小写 |
| g | global search,全局搜索,不加标志g只会匹配第一个然后就退出 |
| m | multiline,多行,会影响锚定符的判定,^和&会分别匹配到行的开头和行的结尾 |
| u | unicode, 使用unicode模式,但有些服务器不支持 |
| y | sticky,忽略g标志,只会匹配最后一个匹配项,但有些服务器不支持 |
| s | dot All,使得符号.可以适配所有的字符,包括换行符,但有些服务器不支持 |
在js/ts中,斜杠后面加上标志就要可以了,比如/ha/g。用的最多的应该就是g,i。注意了,g是查找所有,不是要求所有,/ha/g并不是要求整个字符串都是“ha”,只是要找到所有的“ha”,通常在需要替换全部的时候才会用到。
let regex = /ha/gi
"hahaha1".replace(regex,"^_^") //^_^^_^^_^1
"haHahA".replace(regex,"^_^") //^_^^_^^_^
3. 正则替换语法
讲完了正则描述的部分,有些时候我们需要做替换处理都比较简单的时候,比如将abc,替换成ABC,直接"zabcd".replace(/abc/,“ABC”) ,输出zABCd。如果我们还需要用到我们匹配中涉及的内容,就需要**替换(substitution)**语法,用$来做相关的处理。
| 符号 | 含义 |
|---|---|
| $& | 指代匹配到的内容 |
| $` | 指代匹配到内容的前面字符串 |
| $’ | 指代匹配到内容的后面字符串 |
| $n | 指代匹配到内容的第n个组 |
| $$ | 转义,$$指代$本身 |
注意了,这里已经不是用在正则表达式中了,而是用在替换内容中,来点例子。
// $&指代匹配到的内容
"zabcd".replace(/abc/,"$&ABC") // 输出zabcABCd,$`替换成了"abc"
// $`指代匹配到内容的前面字符串
"zabcd".replace(/abc/,"$`ABC") // 输出zzABCd,$`替换成了"z"
// $'指代匹配到内容的后面字符串
"zabcd".replace(/abc/,"$'ABC") // 输出zdABCd,$'替换成了"d"
// $n指代匹配到内容的第n个组
"zabcd".replace(/(a)(b)/,"x$2") // 输出zxbcd,$'替换成了第二组,就是b,所以将ab,替换为xb
转义$$,解决一下想替换为$但识别成替换操作的内容的问题。如果不被误识别,也可以直接用$
"zabcd".replace(/(a)(b)/,"$$1") // 输出z$1cd,$$为$字符本身,所以将ab,替换为$1
"zabcd".replace(/(a)(b)/,"$3") // 输出z$3cd,没有字符组3,$识别为$字符本身,将ab,替换为%$-
"zabcd".replace(/(a)(b)/,"%$-") // 输出z%$-cd,$为$字符本身,将ab,替换为%$-
到这里,正则语法已经基本讲完了,不知不觉已经1w字了。正则用在编程中可以很方便的用来,检查或者替换字符,但注意的是,过于复杂的表达式是理解成本很高的,多加点注释吧,不然明天再看到就得再思考好一会,这串东西是用来干嘛的。
4. 正则性能
语法结束,我们研究一下性能问题,用正则方便了,但会不会开销挺大的?虽然js考虑啥性能…但还是写段小代码测试一下。
// 生成a-z的随机字符,长度10000
let len = 10000
let s = ''
let aCode = 'a'.charCodeAt(0)
for (let i = 0; i < len; i++) {let code = aCode + Math.floor(Math.random() * 26)s += String.fromCharCode(code)
}// 测试时间,查询10w次abc
let count = 100000
{let regex = /abc/let t1 = new Date().getTime()for (let i = 0; i < count; i++) {regex.test(s)}let t2 = new Date().getTime()console.log('/abc/ - 正则查询:', t2 - t1)
}
{let t1 = new Date().getTime()for (let i = 0; i < count; i++) {let regex = /abc/regex.test(s)}let t2 = new Date().getTime()console.log('/abc/ - 正则查询(每次新建正则):', t2 - t1)
}
{let t1 = new Date().getTime()for (let i = 0; i < count; i++) {let regex = new RegExp(/abc/)regex.test(s)}let t2 = new Date().getTime()console.log('/abc/ - 正则查询(每次新建regExp):', t2 - t1)
}
{let t1 = new Date().getTime()for (let i = 0; i < count; i++) {for (let j = 0; j < len; j++) {if (s[j] == 'a' && s[j + 1] == 'b' && s[j + 2] == 'c') {break}}}let t2 = new Date().getTime()console.log('/abc/ - 遍历查询:', t2 - t1)
}// 测试时间,查询10w次a
{let regex = /a/let t1 = new Date().getTime()for (let i = 0; i < count; i++) {regex.test(s)}let t2 = new Date().getTime()console.log('/a/ - 正则查询:', t2 - t1)
}
{let t1 = new Date().getTime()for (let i = 0; i < count; i++) {for (let j = 0; j < len; j++) {if (s[j] == 'a') {break}}}let t2 = new Date().getTime()console.log('/a/ - 遍历查询:', t2 - t1)
}
结果就是
/abc/ - 正则查询: 210
/abc/ - 正则查询(每次新建正则): 206
/abc/ - 正则查询(每次新建regExp): 218
/abc/ - 遍历查询: 1832
/a/ - 正则查询: 1
/a/ - 遍历查询: 5
可见比起我们自己手动去遍历,正则的通常性能是要更优的,至少在js引擎中,其他引擎可能差不多。此外,正则的创建开销不大,每次都创建可以可行的,甚至每次都每次新建正则,反而更快,真是奇妙的js…。总的来说就是,无内鬼放心用。稍微注意下可读性问题,要注释,不然后天就忘记了,出bug又得再想一遍。
5. 结束
写完咯,终于!希望能够对各位有所帮助吧。如果有用的话,就点赞或者评论一下吧,倒也没啥特殊作用。毕竟也不是靠文章过活,真有这念头估计穷困潦倒了。只是絮絮叨叨写了好多字,若是无人反馈,也是遗憾。如果有点赞评论,倒也不至于像说与树洞听。
然后,希望明天的班,不要太清闲也不要太忙,完结~
相关文章:

[编程相关]正则表达式Regex语法
--目录-- 0. 前言1. 正则语法2. 正则搜索语法(1)字符集 Character_Classes(2)锚定符 Anchors(3)计数 Quantifiers(4)分组与索引 Group_And_Reference(5)周围 …...

axios实例配置和使用
一.vite项目中引入axios 1.1.安装axios pnpm add axios --save 二.配置axios实例 2.1实例配置 import axios from ‘axios’ import router from ‘/router’ const instance axios.create({ baseURL:“http://127.0.0.1:8080”, timeout:10*1000, //最长响应时间 }) instan…...
uni-app 工程目录结构介绍
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...

YOLOv8改进 | 主干篇 | 利用SENetV2改进网络结构 (全网首发改进)
一、本文介绍 本文给大家带来的改进机制是SENetV2,其是2023.11月的最新机制(所以大家想要发论文的可以在上面下点功夫),其是一种通过调整卷积网络中的通道关系来提升性能的网络结构。SENet并不是一个独立的网络模型,而是一个可以和现有的任何…...

TUP实现一对一聊天
package TCP; import java.io.BufferedReader; import java.io.IOException; import java.io.InputStreamReader; import java.io.PrintWriter; import java.net.ServerSocket; import java.net.Socket; import java.util.Scanner; /** * 发送消息线程 */ class Send ext…...
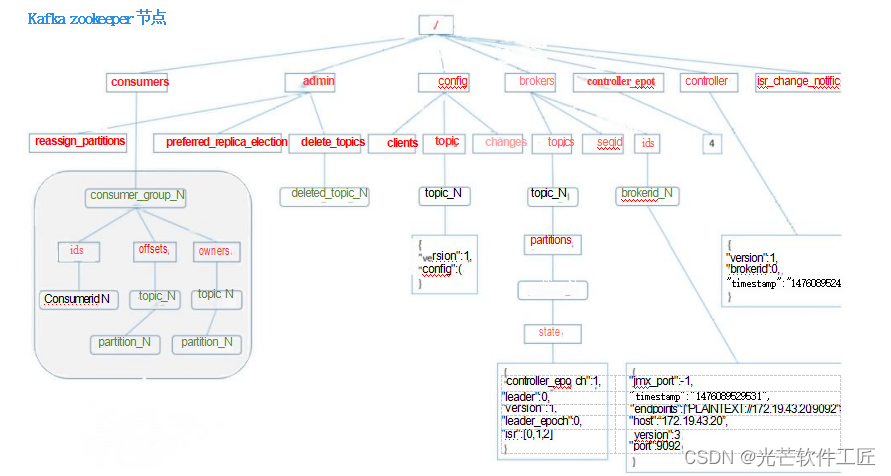
Kafka设计原理详解
Kafka核心总控制器 (Controller) 在Kafka集群中,通常会有一个或多个broker,其中一个会被选举为控制器 (Kafka Controller),其主要职责是管理整个集群中所有分区和副本的状态。具体来说: 当某个分区的leader副本出现故障时&#…...

光耦继电器
光耦继电器(光电继电器) AQW282SX 282SZ 280SX 280SZ 284SX 284SZ 212S 212SX 21 2SZ 文章目录 光耦继电器(光电继电器)前言一、光耦继电器是什么二、光耦继电器的类型三、光电耦合器的应用总结前言 光耦继电器在工业控制、通讯、医疗设备、家电及汽车电子等领域得到广泛应…...
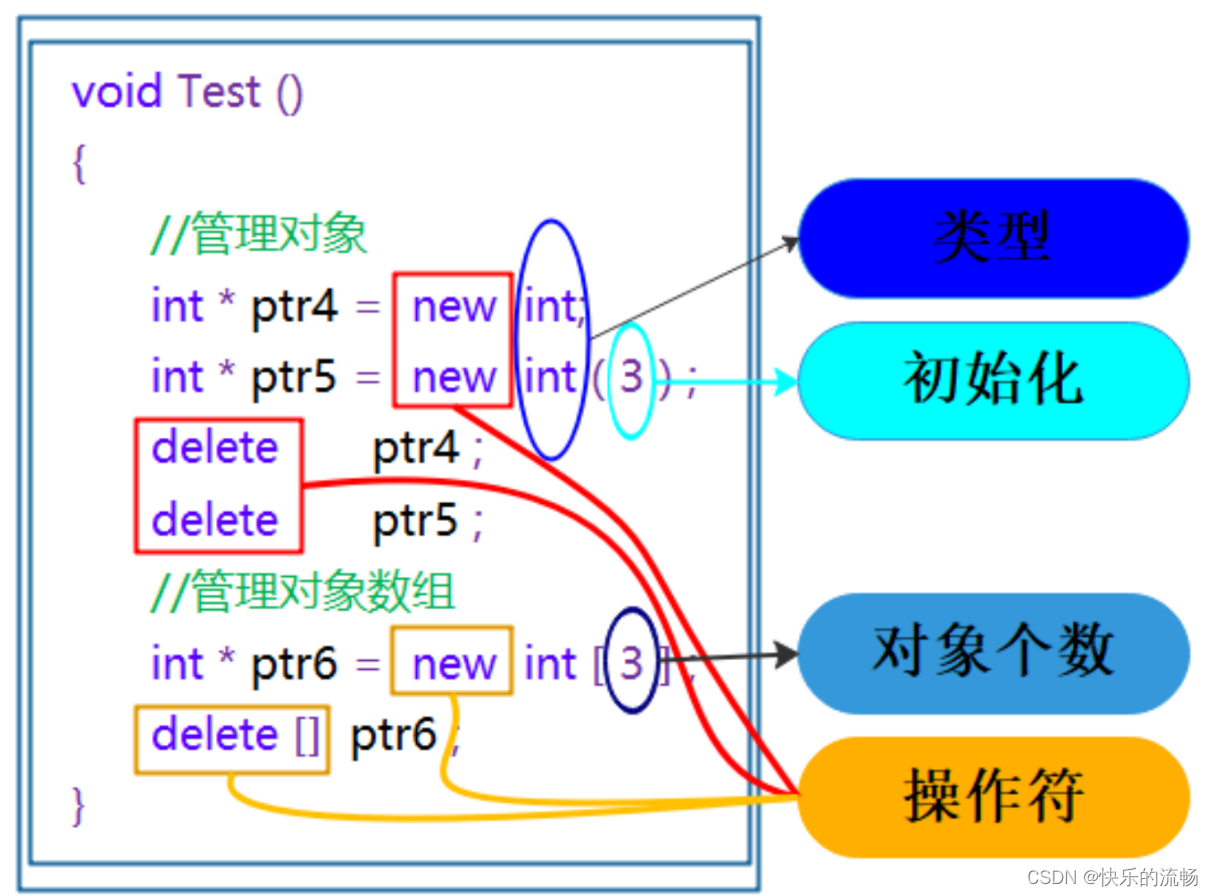
【C++练级之路】【Lv.5】动态内存管理(都2023年了,不会有人还不知道new吧?)
目录 一、C/C内存分布二、new和delete的使用方式2.1 C语言内存管理2.2 C内存管理2.2.1 new和delete操作内置类型2.2.2 new和delete操作自定义类型 三、new和delete的底层原理3.1 operator new与operator delete函数3.2 原理总结3.2.1 内置类型3.2.2 自定义类型 四、定位new表达…...
2016年第五届数学建模国际赛小美赛A题臭氧消耗预测解题全过程文档及程序
2016年第五届数学建模国际赛小美赛 A题 臭氧消耗预测 原题再现: 臭氧消耗包括自1970年代后期以来观察到的若干现象:地球平流层(臭氧层)臭氧总量稳步下降,以及地球极地附近平流层臭氧(称为臭氧空洞&#x…...
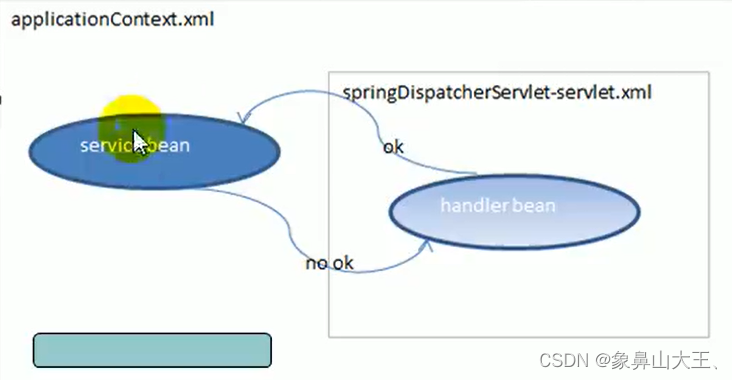
springMVC-与spring整合
一、基本介绍 在项目开发中,spring管理的 Service和 Respository,SrpingMVC管理 Controller和ControllerAdvice,分工明确 当我们同时配置application.xml, springDispatcherServlet-servlet.xml , 那么注解的对象会被创建两次, 故…...

【二叉树】【单调双向队列】LeetCode239:滑动窗口最大值
作者推荐 map|动态规划|单调栈|LeetCode975:奇偶跳 涉及知识点 单调双向队列 二叉树 题目 给你一个整数数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。 返回 滑动…...

如何使用树莓派Bookworm系统中配置网络的新方法NetworkManager
树莓派在 10 月新出的 Bookworm 版本系统中,将使用多年的 dhcpcd 换成了 NetworkManager(以前是在rasp-config中可选),这是因为 Raspberry Pi OS 使用的是 Debian 内核(和 Ubuntu 一样),所以树莓…...
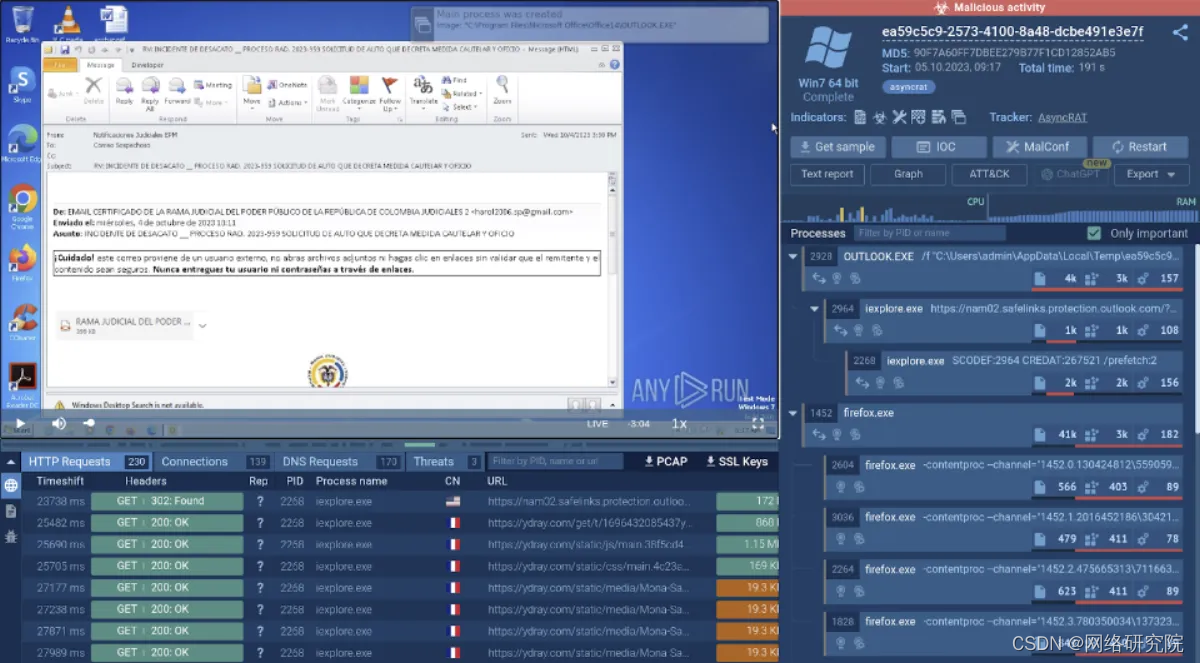
恶意软件分析沙箱在网络安全策略中处于什么位置?
恶意软件分析沙箱提供了一种全面的恶意软件分析方法,包括静态和动态技术。这种全面的评估可以更全面地了解恶意软件的功能和潜在影响。然而,许多组织在确定在其安全基础设施中实施沙箱的最有效方法方面面临挑战。让我们看一下可以有效利用沙盒解决方案的…...
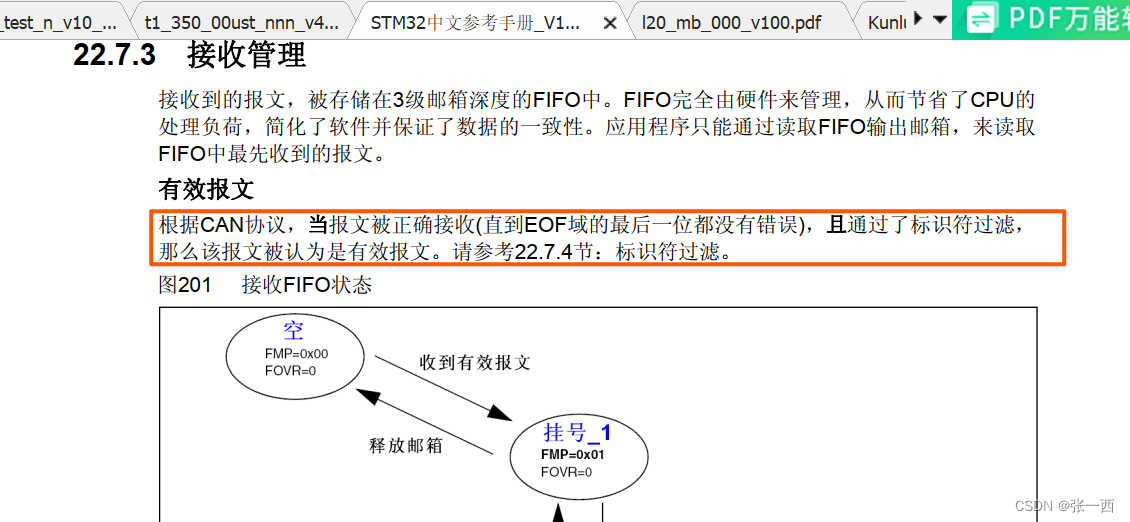
ARM学习(24)Can的高阶认识和错误处理
笔者来聊一下CAN协议帧的认识和错误处理。 1、CAN协议帧认识 CAN 差分信号,是经过CAN收发器转成差分信号的,CAN RX和TX是逻辑电平。CAN的基础知识,可参考笔者这边文章:ARM学习(21)STM32 外设Can的认识与驱…...

网络通信--深入理解网络和TCP / IP协议
计算机网络体系结构 TCP/IP协议族 TCP / IP 网络传输中的数据术语 网络通信中的地址和端口 window端查看IP地址和MAC地址:ipconfig -all MAC层地址是在数据链路层的;IP工作在网络层的 MAC是48个字节,IP是32个字节 在子网(局域…...
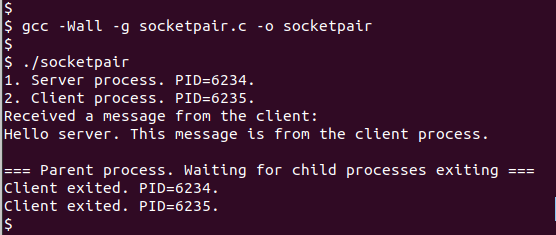
IPC之九:使用UNIX Domain Socket进行进程间通信的实例
socket 编程是一种用于网络通信的编程方式,在 socket 的协议族中除了常用的 AF_INET、AF_RAW、AF_NETLINK等以外,还有一个专门用于 IPC 的协议族 AF_UNIX,IPC 是 Linux 编程中一个重要的概念,常用的 IPC 方式有管道、消息队列、共…...
学习在UE中通过Omniverse实现对USD文件的Live-Sync(实时同步编辑)
目标 前一篇 学习了Omniverse的一些基础概念。本篇在了解这些概念的基础上,我想体验下Omniverse的一些具体的能力,特别是 Live-Sync (实时同步) 相关的能力。 本篇实践了使用Omniverse的力量在UE中建立USD文件的 Live-Sync 编辑。由于相关的知识我是从…...
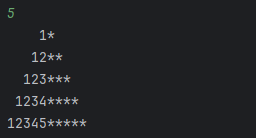
实现打印一个数字金字塔。例如:输入5,图形如下图所示
1*12**123***1234**** 12345*****#include<stdio.h> void main() {int i,j,l,n,k;scanf("%d",&n);/**********Program**********//********** End **********/ } 当我们拿到这个题目的时候可以看见题目给了我们五个变量,其中n是我们输入的数…...

hive sql常用函数
目录 一、数据类型 二、基础运算 三、字符串函数 1、字符串长度函数: length() 2、字符串反转函数:reverse 3、字符串连接函数 4、字符串截取函数 5、字符串分割函数:split 6、字符串查找函数 7、ascii 8、base64 9、character_length 10、c…...

Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中
Spark系列之:使用spark合并hive数据库多个分区的数据到一个分区中 把两个分区的数据合并到同一个分区下把其中一个分区的数据通过append方式添加到另一个分区即可 %spark val df spark.sql("select * from optics_prod.product_1h_a where datetime202311142…...

小电脑4种主流连接方案全解:直连屏/采集卡/网卡网线/NoMachine
在使用嵌入式开发板、迷你主机、机器人机载小电脑等设备时,如何高效连接、显示画面、远程控制是入门第一步。很多同学容易混淆“直连网线、网卡、采集卡、远程桌面”的区别,本文一次性讲清楚四种常用连接方式,包含用途、所需硬件、详细操作、…...

Web-Maker深度解析:理解多预处理器支持的实现原理
Web-Maker深度解析:理解多预处理器支持的实现原理 【免费下载链接】web-maker A blazing fast & offline frontend playground 项目地址: https://gitcode.com/gh_mirrors/we/web-maker Web-Maker是一款强大的离线前端开发工具,它支持多种CSS…...

Facebook无法向他人发送消息?2026原因解析与解决思路
在使用Facebook过程中,有时会遇到无法向他人发送消息的情况。这可能影响正常沟通和工作协作。出现这一现象的原因多种多样,本文将从2026年的实际情况出发,系统梳理常见原因及对应解决方法,帮助你快速排查问题并恢复消息功能。一、…...

如何自定义 rdash-angular 主题:从配色到布局的完全掌控
如何自定义 rdash-angular 主题:从配色到布局的完全掌控 【免费下载链接】rdash-angular AngularJS implementation of the RDash admin dashboard theme 项目地址: https://gitcode.com/gh_mirrors/rd/rdash-angular rdash-angular 是一款基于 AngularJS 实…...

StructBERT中文句向量工具实战教程:构建本地FAQ语义搜索系统的完整流程
StructBERT中文句向量工具实战教程:构建本地FAQ语义搜索系统的完整流程 1. 引言:从“关键词匹配”到“语义理解”的跨越 你有没有遇到过这样的场景?公司内部的知识库文档堆积如山,当新员工想快速找到一个问题的答案时࿰…...

IDEA中Module工程重命名的正确姿势与避坑指南
1. 为什么需要重命名Module工程? 在IntelliJ IDEA中开发多模块项目时,Module命名往往不是一蹴而就的。我遇到过很多次这样的情况:项目初期随便起了个module名字,随着业务发展发现名称与实际功能严重不符。比如有个数据分析项目&a…...
)
从广播风暴到安全隔离:用Wireshark抓包分析VLAN工作原理(实验对比版)
从广播风暴到安全隔离:用Wireshark抓包分析VLAN工作原理(实验对比版) 当你按下回车键发送一个广播消息时,这个数据包会像野火一样蔓延到整个网络——至少在没有VLAN的传统以太网中是这样。我曾亲眼见证过一个简单的ARP请求如何拖垮…...

如何用GHelper替代Armoury Crate,让华硕笔记本性能与续航双丰收?
如何用GHelper替代Armoury Crate,让华硕笔记本性能与续航双丰收? 【免费下载链接】g-helper Lightweight, open-source control tool for ASUS laptops and ROG Ally. Manage performance modes, fans, GPU, battery, and RGB lighting across Zephyrus,…...
✅)
计算机毕业设计:Python智慧航班数据大屏及管理后台 Django框架 可视化 MLP 大数据 机器学习 深度学习(建议收藏)✅
1、项目介绍 技术栈 采用 Python 3.10 编程语言,基于 Django 框架进行后端开发,前端使用 Echarts 可视化技术搭建数据大屏,并结合多层感知器(MLP)神经网络模型实现航班延误状态与机票价格的预测功能。 功能模块飞机航…...

YOLO-v8.3部署优化指南:显存管理+参数调整,解决卡顿难题
YOLO-v8.3部署优化指南:显存管理参数调整,解决卡顿难题 1. 问题诊断:为什么YOLO-v8.3会卡顿? 当你兴奋地部署了最新的YOLO-v8.3模型,准备开始物体检测任务时,突然遇到程序卡顿甚至崩溃的情况,…...