Hudi的7种索引
1、Bloom Index
Bloom Index (default) 使用根据记录键构建的bloom过滤器,也可以使用记录键范围修剪候选文件.原理为计算RecordKey的hash值然后将其存储到bitmap中,为避免hash冲突一般选择计算3次
-
HoodieKey 主键信息:主要包含recordKey 和patitionPath 。recordkey 是由hoodie.datasource.write.recordkey.field 配置项根据列名从记录中获取的主键值。patitionPath 是分区路径。Hudi 会根据hoodie.datasource.write.partitionpath.field 配置项的列名从记录中获取的值作为分区路径。
-
https://llimllib.github.io/bloomfilter-tutorial/zh_CN/
原理:计算RecordKey的hash值然后将其存储到bitmap中去,key值做hash可能出现hash 碰撞的问题,为了较少hash 值的碰撞使用多个hash算法进行计算后将hash值存入BitMap,一般三次hash最佳
查找步骤:
1、提取所有的分区路径和主键值,然后计算每个分区路径中需要根据主键查找的索引的数量。
2、有了需要加载的分区后,调用LoadInvolvedFiles 方法加载分区下所有的parquet 文件。在加载paquet文件只是加载文件中的页脚信息,页脚存放的有布隆过滤器、记录最小值、记录最大值。对于布隆过滤器其实是存放的是bitmap序列化的对象。
3、加载好parquet 的页脚信息后会根据最大值和最小值构造线段树。
4、据Rdd 中RecordKey 进行数据匹配查找数据属于那个parqeut 文件中,对于RecordKey查找只有符合最大值和最小值范围才会去查找布隆过滤器中的bitmap ,RecordKey小于最小值找左子树,RecordKey大于最大值的key找右子树。递归查询后如果查找到节点为空说明RecordKey在当前分区中不存在,当前Recordkey是新增数据。查找索引时spark会自定义分区避免大量数据在一个分区查找导致分区数据倾斜。查找到RecordKey位置信息后会构造<HoodieKey,HoodieRecordLocation> Rdd 对象。
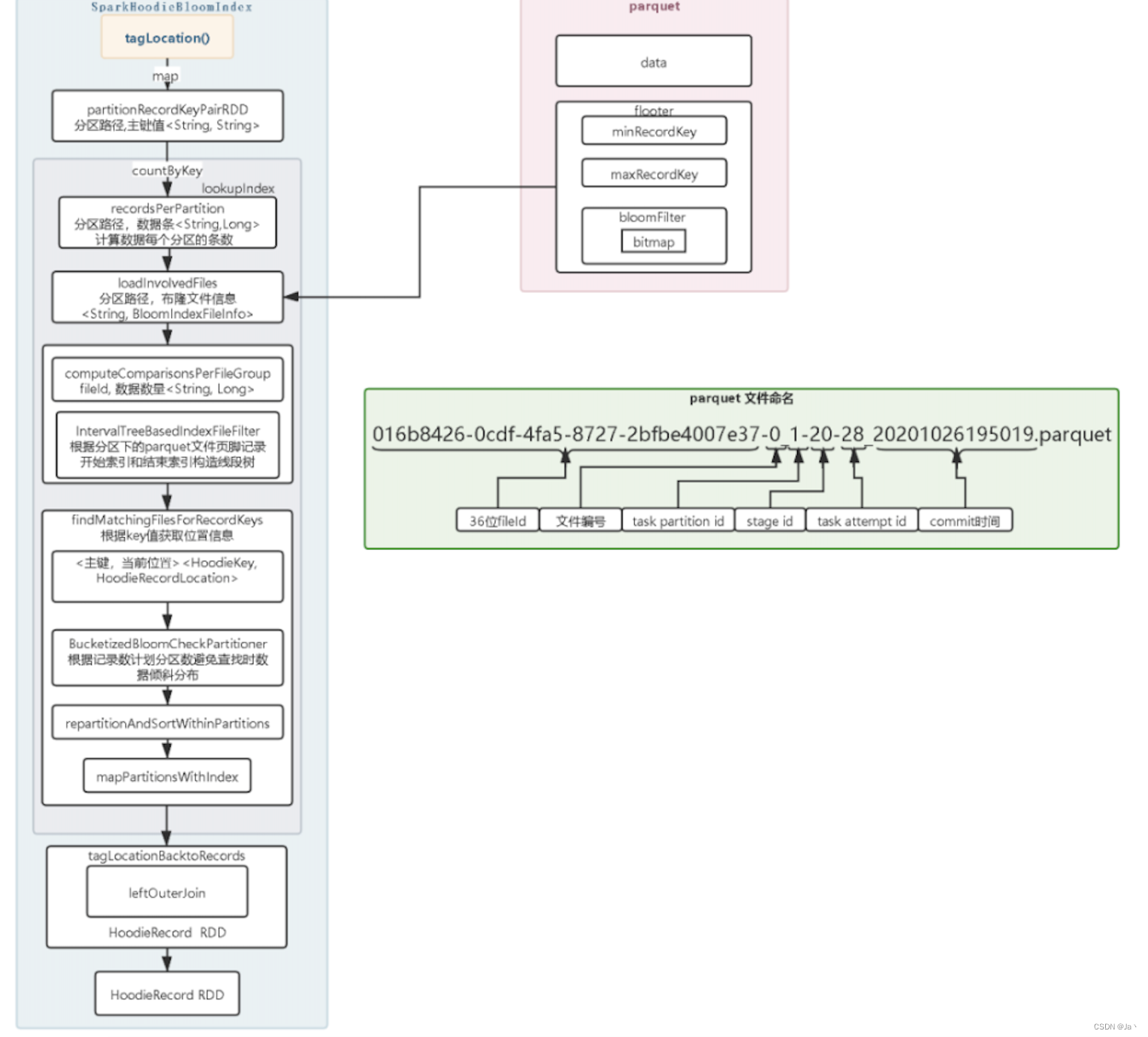
查找步骤,以Spark举例:
tagLocation:
-
从Spark Rdd中提取partitionPath以及recordKey,构建partitionRecordKeyPairRDD对象
-
调用lookupIndex方法,获取文件位置,返回值为:JavaPairRDD<HoodieKey, HoodieRecordLocation>
-
//1、将从Rdd中提取的一批值根据partition,进行分组 //key:partition value:数据数量 Map<String, Long> recordsPerPartition = partitionRecordKeyPairRDD.countByKey(); //2、根据recordsPerPartition,将对应partition下的全部parquet文件加载上来 //tuple2.t1:partitionPath,tuple2.t2:BloomIndexFileInfo->fileId、parquet footer max min List<Tuple2<String, BloomIndexFileInfo>> fileInfoList =loadInvolvedFiles(affectedPartitionPathList, context, hoodieTable); //3、根据partitionPath,对parquet元数据进行分组 final Map<String, List<BloomIndexFileInfo>> partitionToFileInfo =fileInfoList.stream().collect(groupingBy(Tuple2::_1, mapping(Tuple2::_2, toList()))); //4、record与parquet文件进行匹配 fileid对应有HoodieKey的数据 -- 根据配置决定构建线段树还是暴力查找 //返回值 Tuple2 t1:fileId t2:partitionPath and recordKey 形成对应关系 JavaRDD<Tuple2<String, HoodieKey>> fileComparisonsRDD =explodeRecordRDDWithFileComparisons(partitionToFileInfo, partitionRecordKeyPairRDD); //5、计算对每个文件组执行的布隆过滤器比较的估计数量 //返回值:key:fileId value:数据数量 Map<String, Long> comparisonsPerFileGroup =computeComparisonsPerFileGroup(recordsPerPartition, partitionToFileInfo, fileComparisonsRDD, context); //6、将partition数量与配置项 config.getBloomIndexParallelism()对比 //索引查找并行度 int joinParallelism = Math.max(inputParallelism, config.getBloomIndexParallelism()); //7、根据key值获取位置信息 //返回值:JavaPairRDD<HoodieKey, HoodieRecordLocation> //String instantTime; String fileId; findMatchingFilesForRecordKeys(fileComparisonsRDD, joinParallelism, hoodieTable,comparisonsPerFileGroup); -
加载好parquet 的页脚信息后会根据最大值和最小值构造线段树
-
根据Rdd 中RecordKey 进行数据匹配查找数据属于那个parqeut 文件中,对于RecordKey查找只有符合最大值和最小值范围才会去查找布隆过滤器中的bitmap ,RecordKey小于最小值找左子树,RecordKey大于最大值的key找右子树。递归查询后如果查找到节点为空说明RecordKey在当前分区中不存在,当前Recordkey是新增数据。查找索引时spark会自定义分区避免大量数据在一个分区查找导致分区数据倾斜。查找到RecordKey位置信息后会构造<HoodieKey,HoodieRecordLocation> Rdd 对象。
-
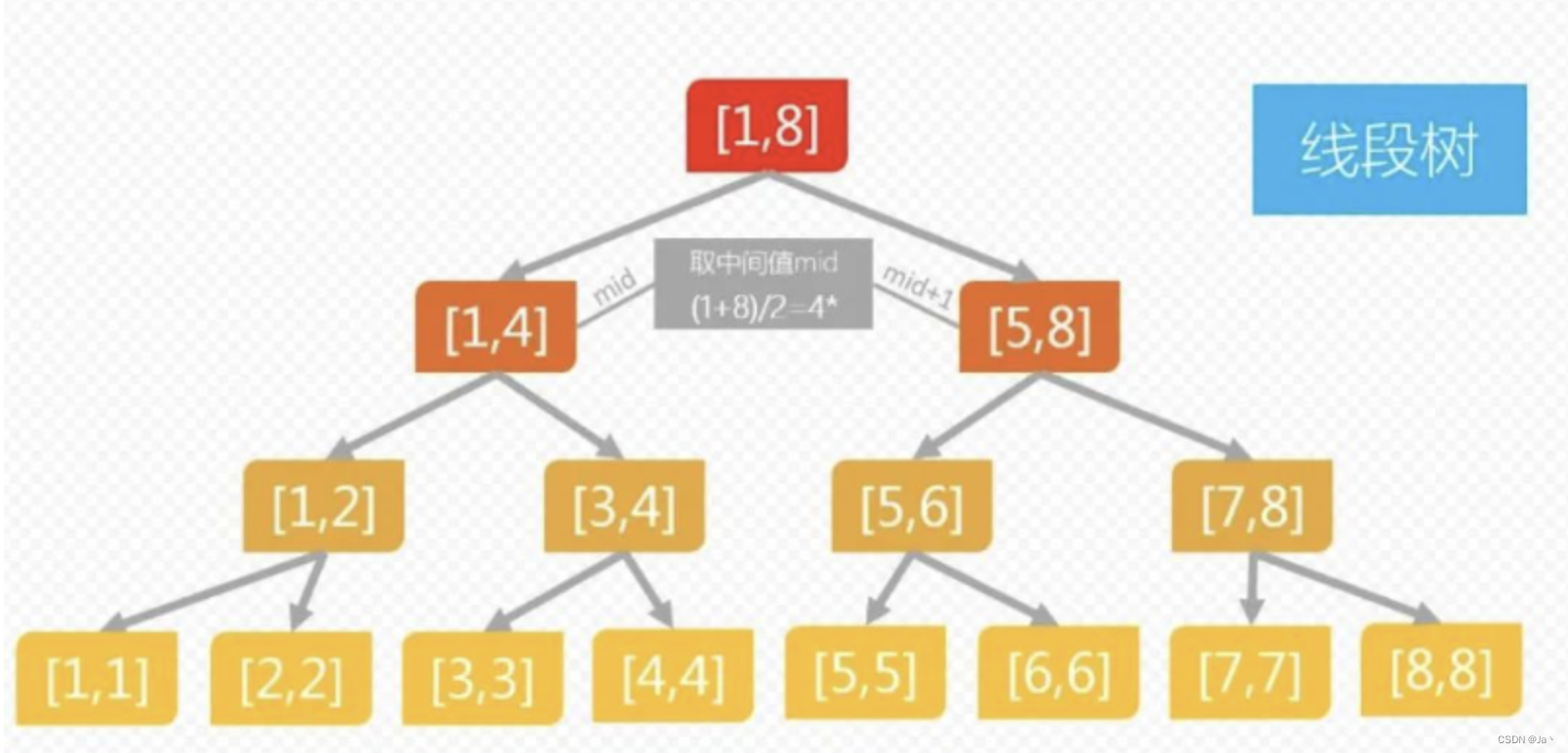
加载paquet文件只是加载文件中的页脚信息,页脚存放的有布隆过滤器、记录最小值、记录最大值。对于布隆过滤器其实是存放的是bitmap序列化的对象。递归查询后如果查找到节点为空说明RecordKey在当前分区中不存在,当前Recordkey是新增数据。
-
-
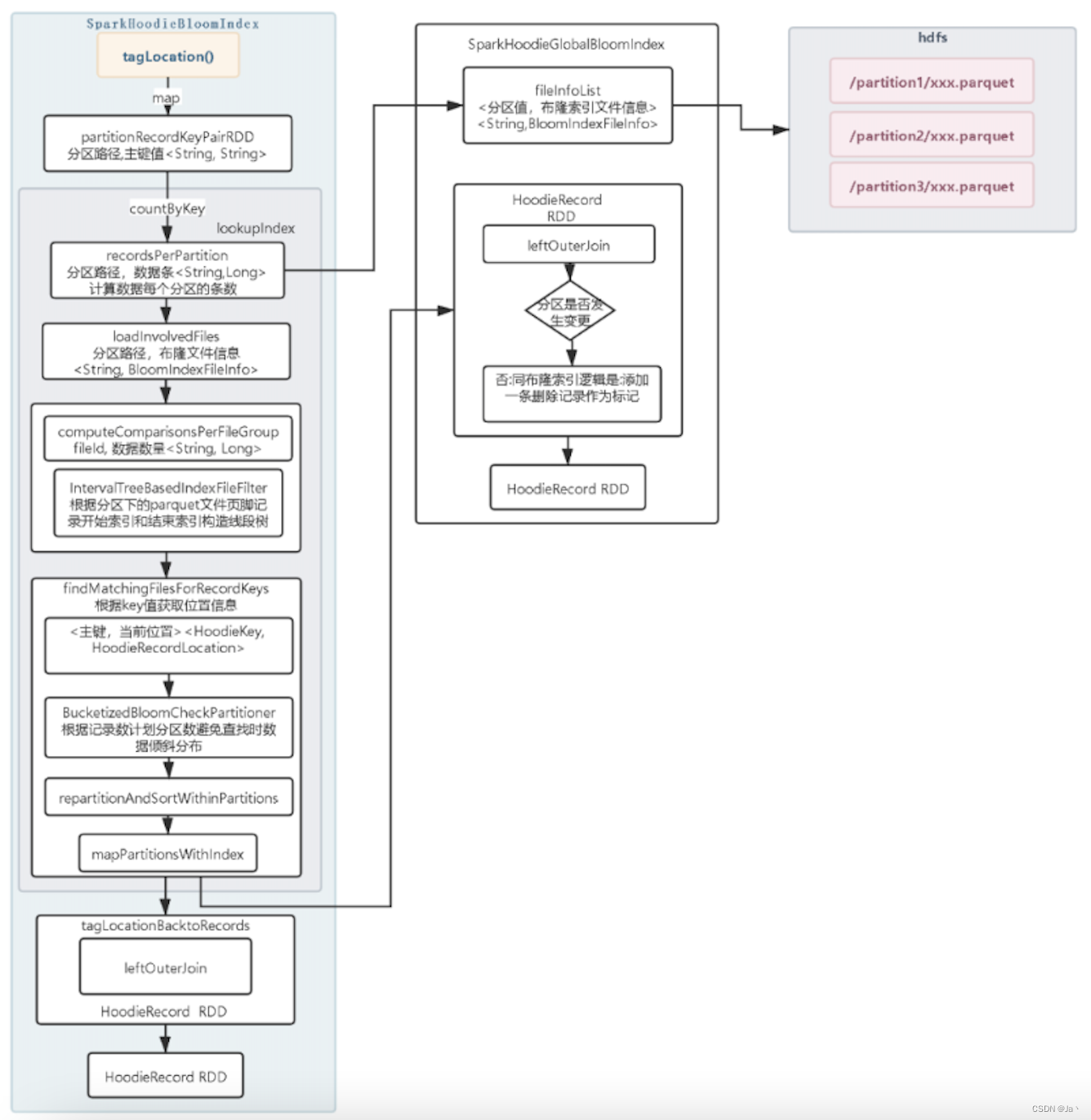
2、 Global Bloom Index
全局布隆索引,与布隆索引的差异点在查找每个RecordKey 属于那个parquet 文件中,会加载所有parquet文件的页脚信息构造线段树,然后在去查询索引。因为Hudi需要加载所有的parquet文件和线段树节点变多对于查找性能会比普通的布隆索引要差。
但是对于分区字段的值发生了修改,如果还是使用普通的布隆索引会导致在当前分区查询不到当成新增数据写入Hudi表。这样我们的数据就重复了,在很多业务场景是不被允许的。所以在选择那个字段做分区列时,尽量选择列值永远不会发生变更的,这样我们使用普通布隆索引就可以了。
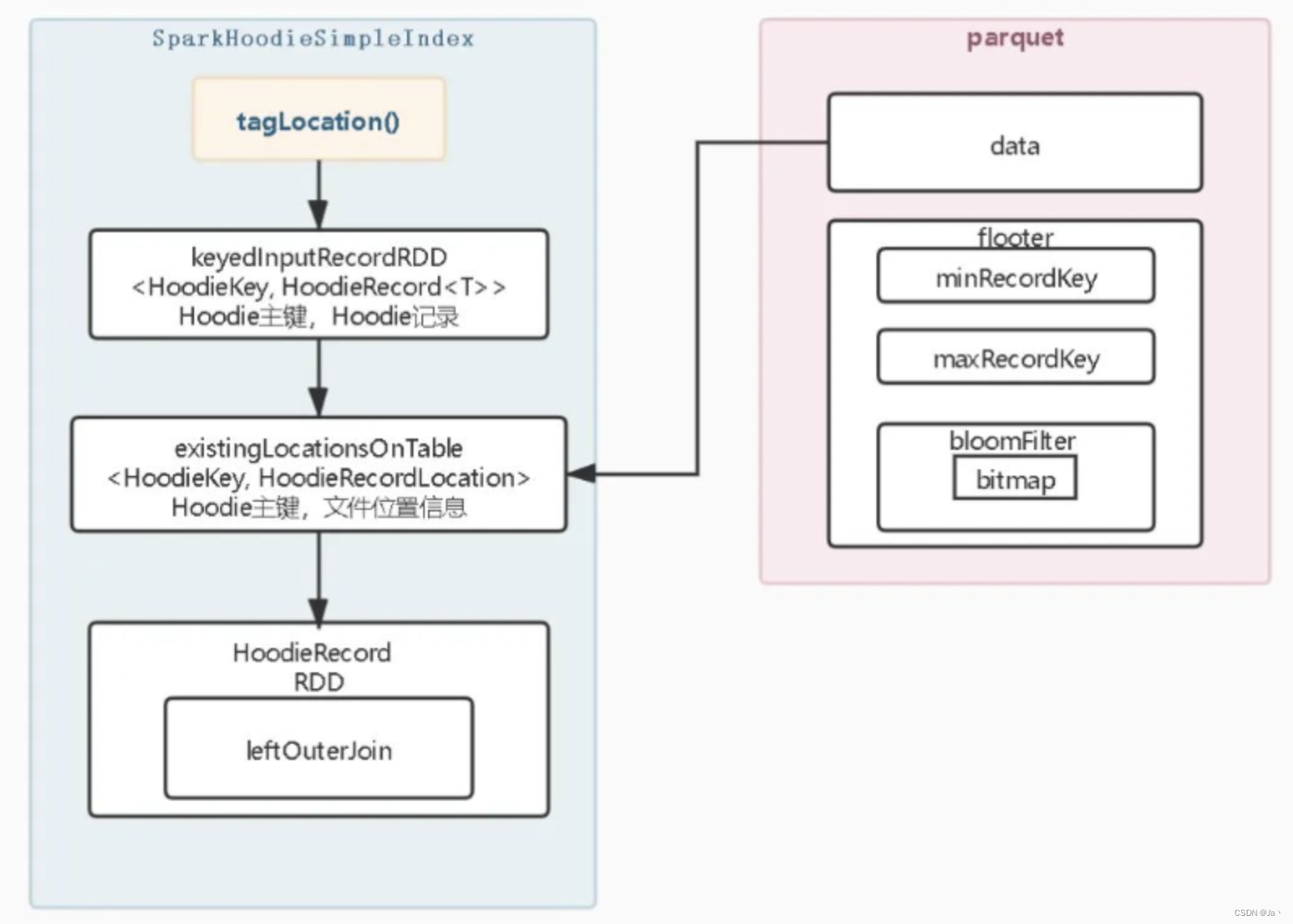
3、Simple Index
简易索引与布隆索引的不同是直接加载分区中所有的parquet数据然后在与当前的数据比较是否存在,实现比较简单。
- 1、提取所有的分区路径和主键值
- 2、根据分区路径加载所有涉及的分区路径内的parquet文件数据,主要加载HooieKey和fileID两列数据
- 3、同布隆索引一样,将原始数据与包含位置信息的查询数据进行做关联,提取位置信息赋值至原始数据上
4、Global Simple Index
简易全局索引同布隆全局索引一样,需要加载所有分区的parquet 文件数据,构造<HoodieKey,HoodieRecordLocation>Rdd然后进行关联。在简易索引中hoodie.simple.index.update.partition.path配置项也是可以选择是否允许分区数据变更。数据文件比较多数据量很大,这个过程会很耗时。
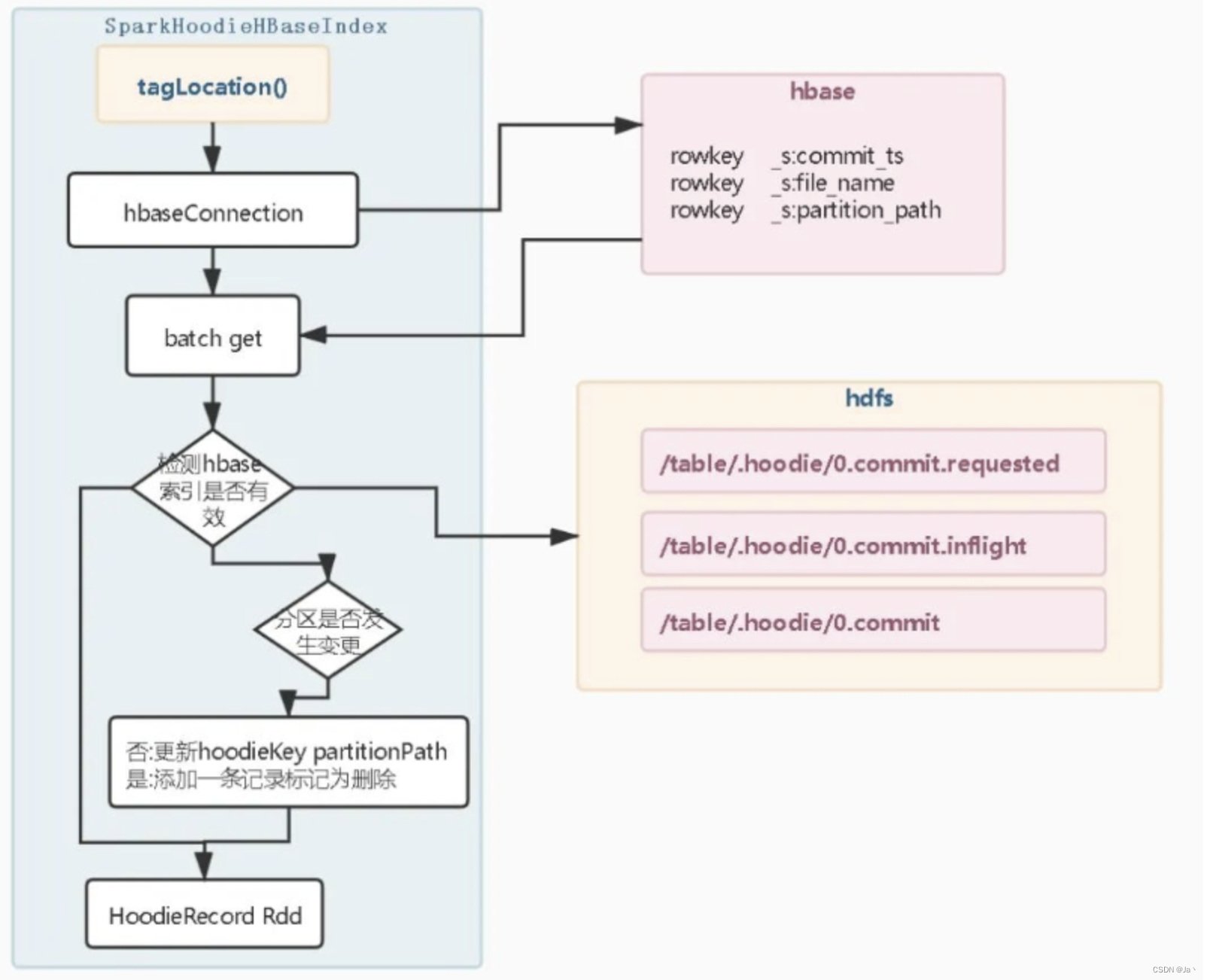
5、HBase Index
将索引映射存储在外部hbase表中,为全局索引。在HBase索引中,文件和索引是分开在特定的情况下可能有一致性问题
HBase索引实现步骤如下:
-
1、连接HBase数据库
-
2、批量请求Hbase数据库
-
3、检查get获取数据是否为有效索引,这时Hudi会连接元数据检查commit时间是否有效,若无效currentLocation将不会被赋值。检查是否为有效索引的目的是当索引更新一半,导致Hbase宕机导致任务失败,保证不会加载过期的索引。避免Hbase索引和数据不一致导致数据进入错误的分区。
-
检查是否开启允许分区变更
-
另一个值得理解的关键方面是全局索引和非全局索引之间的区别。布隆和简单索引都有全局选项 - hoodie.index.type=GLOBAL_BLOOM 和 hoodie.index.type=GLOBAL_SIMPLE。 HBase 索引本质上是一个全局索引。 -
全局索引:全局索引强制跨表的所有分区的键的唯一性,即保证表中对于给定的记录键恰好存在一条记录。 全局索引提供了更强的保证,但更新/删除成本随着表 O(表大小)的大小而增长,这对于较小的表可能仍然是可以接受的。
-
非全局索引:另一方面,默认索引实现仅在特定分区内强制执行此约束。 可以想象,非全局索引依赖于编写器在更新/删除期间为给定的记录键提供相同的一致分区路径,但可以提供更好的性能,因为索引查找操作变为 O(更新/删除的记录数) 并且可以很好地扩展写入量。
6、InMemoryHashIndex(仅适用测试环境)
内存索引目前Spark的实现只是构造一个ConcurrentMap在内存中,不会加载parquet文件中的索引,当调用tagLocation方法会在map中判断key值是否存在
7、Bucket Index (0.11.0版本引入)
字节跳动引入,引入原因:初始使用bloom过滤器,数据量达到30TB,约5千亿条记录分布在40000个file Group中,bloom Filter Index假阳性很频繁。Hudi 需要确定该 Record Key 是否真的存在这个操作需要读取文件里的实际数据一条一条做对比,而实际数据量规模很大,这会导致查询 Record Key 跟 File ID 的映射关系代价非常大,因此造成了索引的性能下滑。
为什么没有使用Hbase替代?
业务方不希望引入 HBase 这一额外依赖,且担心运维 Hbase 过程中存在新的问题,认为 Hbase Index 整体不够轻量,因此在整个业务场景中也无法作为 Bloom Filter 索引的替代。
设计原理
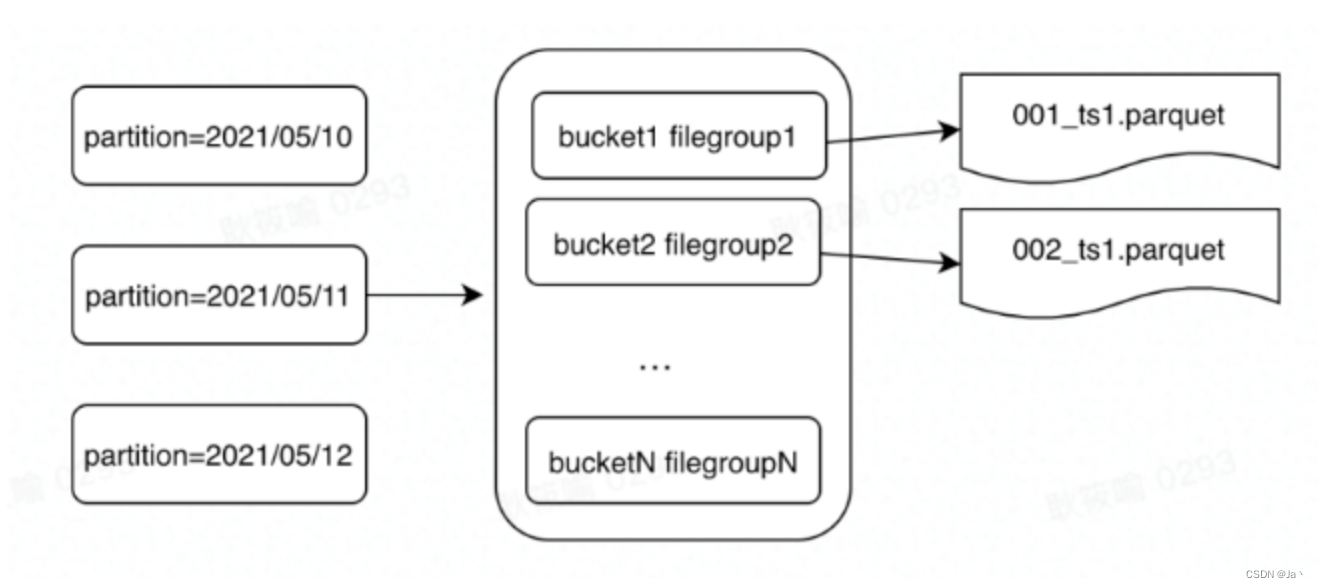
Bucket Index 是一种基于哈希的索引,借鉴了数据库里的 Hash Index。给定 n 个桶, 用 Hash 函数决定某个记录属于哪个桶。最终所有分区被分成 N 个桶,每个桶对应一个 File Group。
相比较 Bloom Filter Index 来说,Hash Index 在逻辑层面提供了 Record Key 跟 File Group 的映射关系,不存在假阳性问题。相同 key 的数据一定是落在同一个桶里面。最终一分区内的结构如下,目前一个 Partition 里面 Bucket 和 File Group 是一一对应的关系。
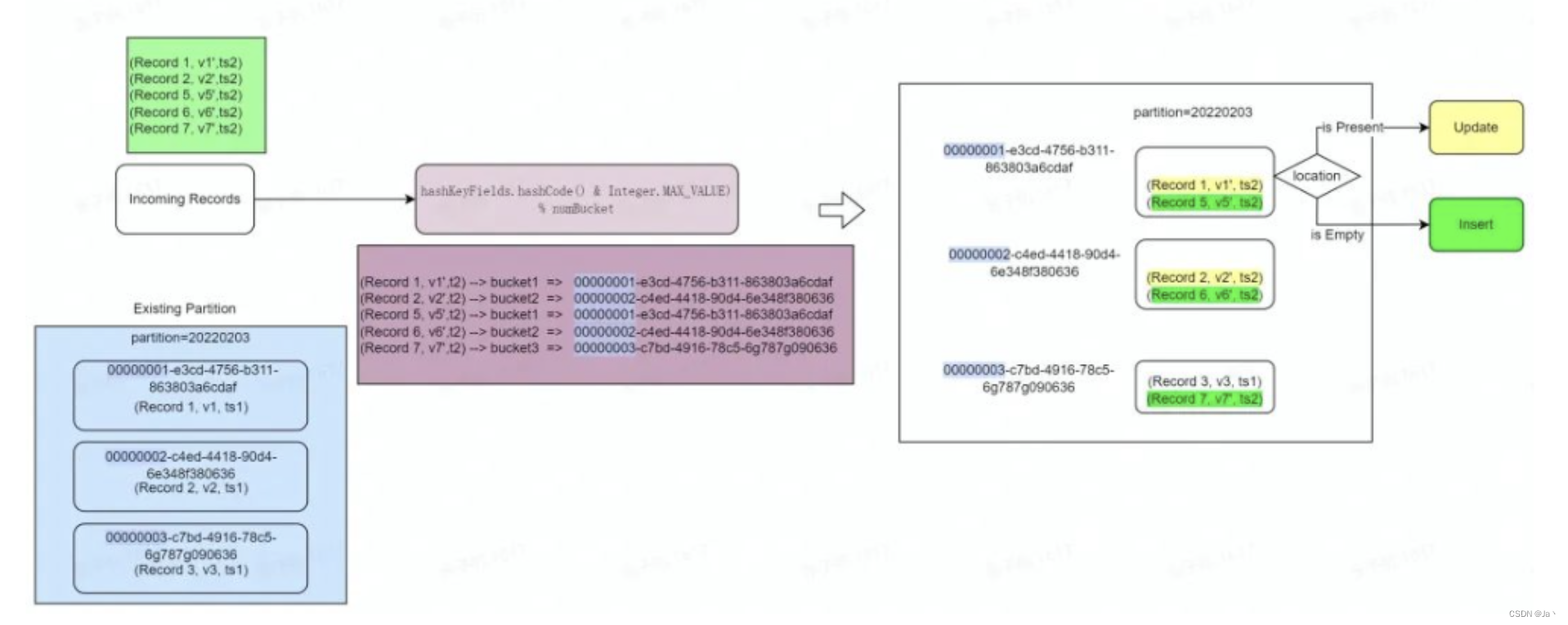
数据写入原理
Bucket Index 的实际写入流程可以参考下面的过程示意图。以下面的实时插入场景为例,某业务批次新增了 5 条记录,并且需要 Upsert 到已有的分区 partition=20220203 中,对已有数据根据主键 Record 做一个更新,保留最新的数据。整个过程可以用下面的示意图表示:
- 在建表时先预估表的单个分区数据存储大小,设置一个分桶数 numBuckets。
- 在数据插入前,首先生成 n 个 File ID, 将 File ID 的前 8 位替换成 bucketId 的数字
- 00000000-e929-4327-8b0c-7d0d66091321
- 00000001-e3cd-4756-b311-863803a6cdaf
- 00000002-c4ed-4418-90d4-6e348f380636
- 00000003-c7bd-4916-78c5-6g787g090636
在插入过程中,最重要的一步就是标记每条新插入的记录属于哪个文件 File Group,然后找到对应的 File Group 去更新或者合并。在目前的设计中, 分桶数跟 File Group 是一一对应的映射关系,因此找到每条 Record 对应的桶 ID ,即可确定 Record Key 跟 File Group 的映射关系。
在具体实现中,我们会对更新数据的索引键计算哈希,再对分桶数取模快速定位到每个 Record 对应的桶,整个过程如下面的 Hash 函数所示:
hashKeyFields.hashCode() & Integer.MAX_VALUE) % numBuckets
其中 hashKeyFields 可以由用户指定,是 Record Key 的一个子集,当默认不指定时,会以 Record Key 本身作为 hash 键。在计算好后,每条记录即可知道即将写入的桶。
经过索引层之后,每条数据都会带有一个 File ID,引擎会根据 File ID 进行一次 Shuffle,将相同 File ID 的数据导入到同一个子任务中。对于 COW 表而言,更新 Update 部分需要和已有的 BaseFile 合并生成新的 BaseFile。而 MOR 表将 Update 的数据直接写入对应 File Group 的 delta log,Insert 部分生成新的 BaseFile,最终完成该批次数据的 Upsert。
由此可见,整个过程中 Bucket Index 不需要对现有的数据进行扫描组成类似 Bloom Filter 一样的过滤器,因此可以省去整个定位 File Group 的查询时间,定位 File Group 的时间也不会随着已有 Record 条数的增加而导致性能下降。同时分桶操作会在每个桶内对分桶列排序,排序后的数据一般能获得更高的压缩率,也能节省存储。
相关文章:
Hudi的7种索引
1、Bloom Index Bloom Index (default) 使用根据记录键构建的bloom过滤器,也可以使用记录键范围修剪候选文件.原理为计算RecordKey的hash值然后将其存储到bitmap中,为避免hash冲突一般选择计算3次 HoodieKey 主键信息:主要包含recordKey 和p…...
系统软中断 software)
Linux内核(十三)系统软中断 software
文章目录中断概述Linux内核中断软中断相关代码解析软中断结构体软中断类型软中断两种触发方式函数__do_softirq解析定时器的软中断实现解析定时器相关代码总结Linux版本:linux-3.18.24.x 中断概述 中断要求 快进快出,提高执行效率,…...
Linux -- 查看进程 PS 命令 详解
我们上篇介绍了, Linux 中的进程等概念,那么,在Linux 中如何查看进程呢 ??我们常用到的有两个命令, PS 和 top 两个命令,今天先来介绍下 PS 命令~!PS 命令 :作用 &#x…...

C2科一考试道路通行规定
目录 低能见度等恶劣环境下的通行规定 驾驶机动车禁止行为 停车规定 通行常识 高速公路限速规定 三观不一样的人,无论重来多少次,结果都一样 他不会懂你的委屈 只是觉得自已没错 两个人真正的可悲连吵架都不在一个点上 有句话说得好 我要是没点自我…...
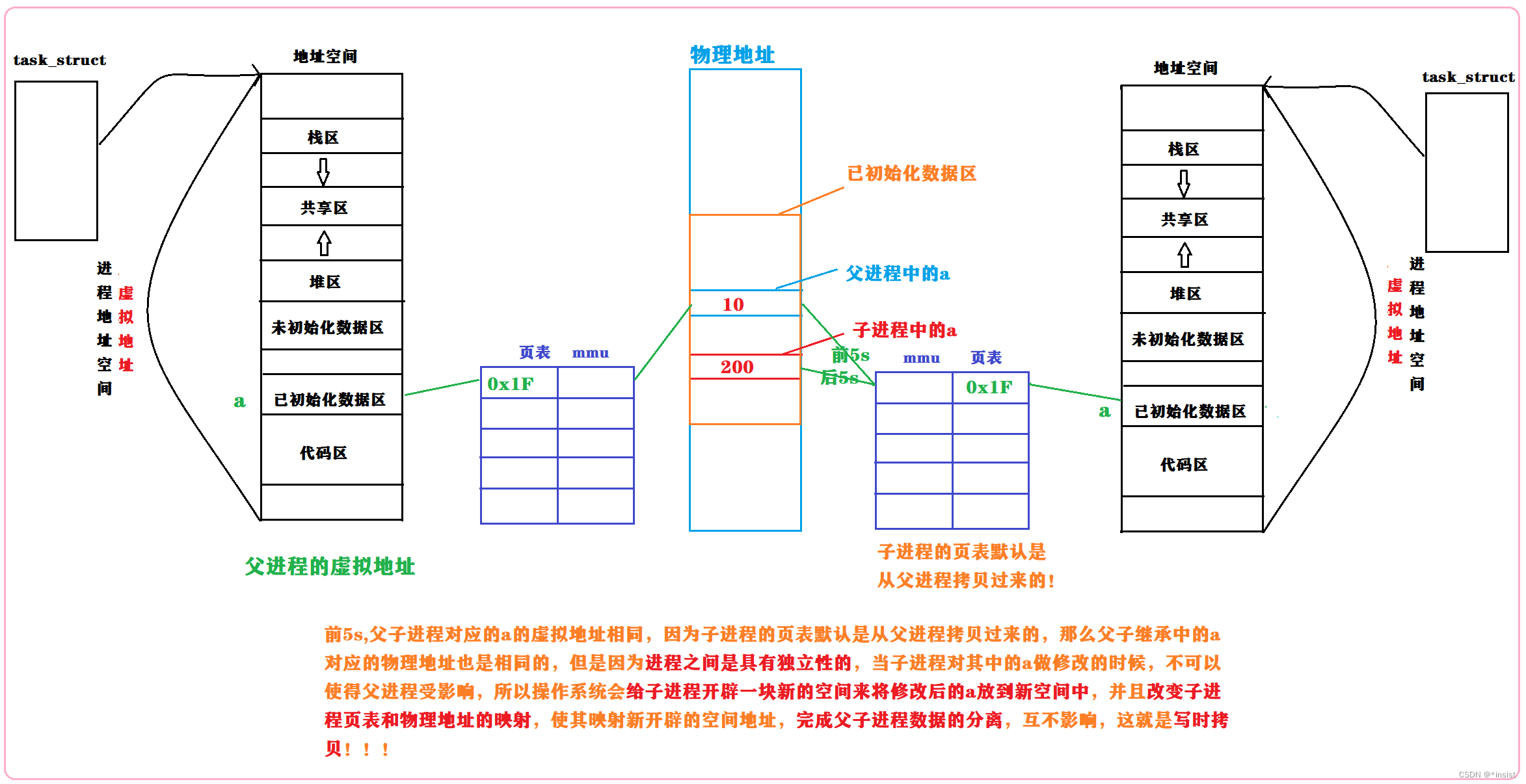
进程概念(详细版)
进程的概念本文主要介绍进程的相关知识 文章目录认识冯诺依曼体系结构操作系统的基本概念操作系统的作用是什么系统调用和库函数相关概念进程基本概念描述进程进程控制块(PCB)task_struct 结构体进程是如何被操作系统管理起来的先描述再组织描述好,组织好࿰…...
学习大数据应该掌握哪些技能
想要了解大数据开发需要掌握哪些技术,不妨先一起来了解一下大数据开发到底是做什么的~ 1、什么是大数据? 关于大数据的解释,比较官方的定义是指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,是需要新处理模…...
【spring】Spring Data --Spring Data JPA
Spring Data 的委托是为数据访问提供熟悉且符合 Spring 的编程模型,同时仍保留着相关数据存储的特殊特征。 它使使用数据访问技术、关系和非关系数据库、map-reduce 框架和基于云的数据服务变得容易。这是一个伞形项目,其中包含许多特定于给定数据库…...

mysql数据库之视图
视图(view)是一种虚拟的存在,视图中的数据并不在数据库中实际存在,行和列数据来自定义视图的查询中使用的表,并且是在使用视图时动态生成的。 通俗的讲,视图之保存了查询的sql逻辑,不保存查询结…...
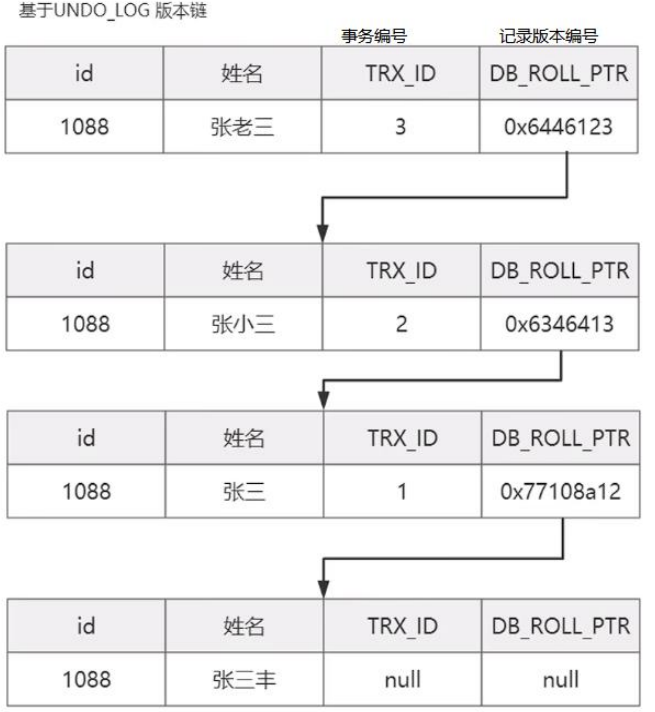
数据库事务详解
概述事务就是数据库为了保证数据的原子性,持久性,隔离性,一致性而提供的一套机制, 在同一事务中, 如果有多条sql执行, 事务可以确保执行的可靠性.数据库事务的四大特性一般来说, 事务是必须满足 4 个条件(ACID):原子性(Atomicity&…...
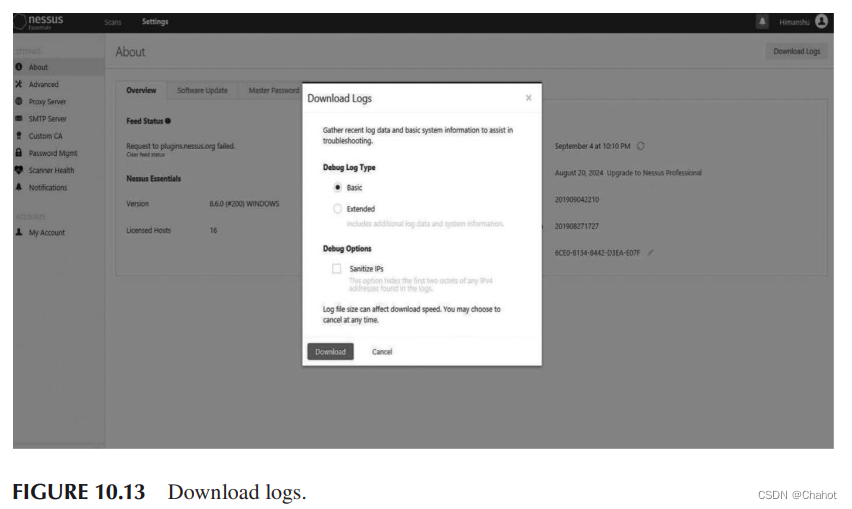
Nessus: 漏洞扫描器-网络取证工具
Nessue 要理解网络漏洞攻击,应该理解攻击者不是单独攻击,而是组合攻击。因此,本文介绍了关于Nessus历史的研究,它是什么以及它如何与插件一起工作。研究了Nessus的特点,使其成为网络取证中非常推荐的网络漏洞扫描工具…...

操作系统实战45讲之现代计算机组成
我以前觉得计算机理论不让我感兴趣,而比较喜欢实践,即敲代码,现在才发现理论学好了,实践才能有可能更顺利,更重要的是理论与实践相结合。 在现代,几乎所有的计算机都是遵循冯诺依曼体系结构,而遵…...

Simple Baselines for Image Restoration
Abstract.尽管近年来在图像恢复领域取得了长足的进步,但SOTA方法的系统复杂性也在不断增加,这可能会阻碍对方法的分析和比较。在本文中,我们提出了一个简单的基线,超过了SOTA方法,是计算效率。为了进一步简化基线&…...
)
Python数据可视化:局部整体图表可视化(基础篇—6)
目录 1、饼图 2、圆环图 3、马赛克图 4、华夫饼图 5、块状/点状柱形图 在学习本篇博文之前请先看一看之前发过的关联知识:...
CSDN新星计划新玩法、年度勋章挑战赛开启
文章目录🌟 写在前面🌟 逐步亮相的活动🌟 勋章挑战赛🌟 新星计划🌟 有付费课程才可参与?🌟 成就铭牌🌟 博客跟社区的关系🌟 写在最后🌟 写在前面 哈喽&#…...
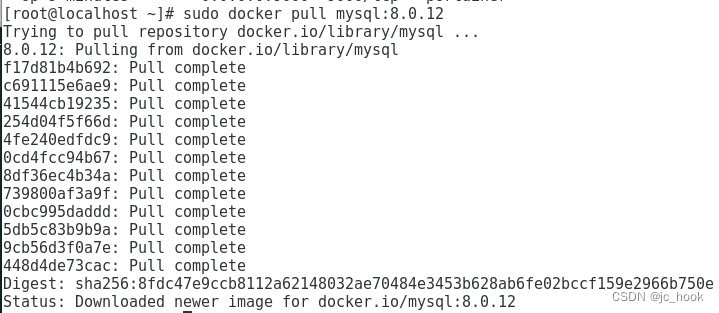
Docker之部署Mysql
通过docker对Mysql进行部署。 如果没有部署过docker,看我之前写的目录拉取镜像运行容器开放端口拉取镜像 前往dockerHub官网地址,搜索mysql。 找到要拉取的镜像版本,在tag下找到版本。 拉取mysql镜像,不指定版本数,…...
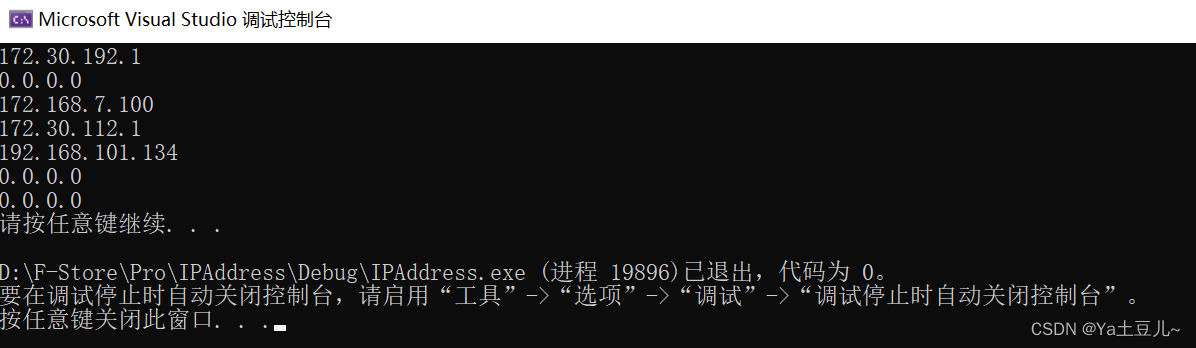
基于C/C++获取电脑网卡的IP地址信息
目录 前言 一、网卡是什么? 二、实现访问网卡信息 1.引入库及相关的头文件 2.操作网卡数据 3. 完整代码实现 4.结果验证 总结 前言 简单示例如何在windows下使用c/c代码实现 ipconfig/all 指令 提示:以下是本篇文章正文内容,下面案例可供参考…...

28相似矩阵和若尔当标准型
一、关于正定矩阵的一些补充 在此之前,先讲一下对称矩阵中那些特征值为正数的矩阵,这样特殊的矩阵称为正定矩阵。其更加学术的定义是: SSS 是一个正定矩阵,如果对于每一个非零向量xxx,xTSx>0x^TSx>0xTSx>0 正…...

springboot操作MongoDB
启动类及配置import com.mongodb.client.MongoClient;import com.mongodb.client.MongoClients;import com.mongodb.client.internal.MongoClientImpl;import org.springframework.boot.SpringApplication;import org.springframework.boot.autoconfigure.SpringBootApplicatio…...
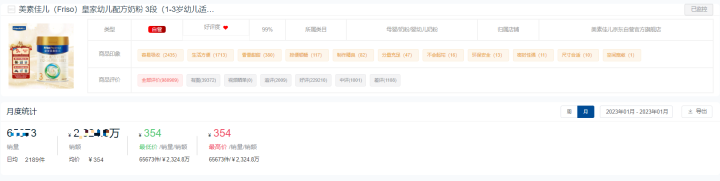
1月奶粉电商销售数据榜单:销售额约20亿,高端化趋势明显
鲸参谋电商数据监测的2023年1月份京东平台“奶粉”品类销售数据榜单出炉! 根据鲸参谋数据显示,1月份京东平台上奶粉的销量约675万件,销售额约20亿元,环比均下降19%左右。与去年相比,整体也下滑了近34%。可以看出&#…...
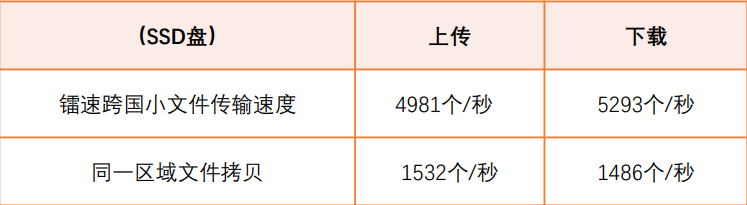
跨境数据传输是日常业务中经常且至关重要的组成部分
跨境数据传输是日常业务中经常且至关重要的组成部分。在过去的20年中,由于全球通信网络和业务流程的发展,全球数据流的模式已迅速发展。随着数据从数据中心移到数据中心和/或跨边界移动,安全漏洞已成为切实的风险。有可能违反国家和国际数据传…...

【大模型RAG】拍照搜题技术架构速览:三层管道、两级检索、兜底大模型
摘要 拍照搜题系统采用“三层管道(多模态 OCR → 语义检索 → 答案渲染)、两级检索(倒排 BM25 向量 HNSW)并以大语言模型兜底”的整体框架: 多模态 OCR 层 将题目图片经过超分、去噪、倾斜校正后,分别用…...

业务系统对接大模型的基础方案:架构设计与关键步骤
业务系统对接大模型:架构设计与关键步骤 在当今数字化转型的浪潮中,大语言模型(LLM)已成为企业提升业务效率和创新能力的关键技术之一。将大模型集成到业务系统中,不仅可以优化用户体验,还能为业务决策提供…...

零门槛NAS搭建:WinNAS如何让普通电脑秒变私有云?
一、核心优势:专为Windows用户设计的极简NAS WinNAS由深圳耘想存储科技开发,是一款收费低廉但功能全面的Windows NAS工具,主打“无学习成本部署” 。与其他NAS软件相比,其优势在于: 无需硬件改造:将任意W…...

多模态2025:技术路线“神仙打架”,视频生成冲上云霄
文|魏琳华 编|王一粟 一场大会,聚集了中国多模态大模型的“半壁江山”。 智源大会2025为期两天的论坛中,汇集了学界、创业公司和大厂等三方的热门选手,关于多模态的集中讨论达到了前所未有的热度。其中,…...

VB.net复制Ntag213卡写入UID
本示例使用的发卡器:https://item.taobao.com/item.htm?ftt&id615391857885 一、读取旧Ntag卡的UID和数据 Private Sub Button15_Click(sender As Object, e As EventArgs) Handles Button15.Click轻松读卡技术支持:网站:Dim i, j As IntegerDim cardidhex, …...

shell脚本--常见案例
1、自动备份文件或目录 2、批量重命名文件 3、查找并删除指定名称的文件: 4、批量删除文件 5、查找并替换文件内容 6、批量创建文件 7、创建文件夹并移动文件 8、在文件夹中查找文件...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

可靠性+灵活性:电力载波技术在楼宇自控中的核心价值
可靠性灵活性:电力载波技术在楼宇自控中的核心价值 在智能楼宇的自动化控制中,电力载波技术(PLC)凭借其独特的优势,正成为构建高效、稳定、灵活系统的核心解决方案。它利用现有电力线路传输数据,无需额外布…...

ServerTrust 并非唯一
NSURLAuthenticationMethodServerTrust 只是 authenticationMethod 的冰山一角 要理解 NSURLAuthenticationMethodServerTrust, 首先要明白它只是 authenticationMethod 的选项之一, 并非唯一 1 先厘清概念 点说明authenticationMethodURLAuthenticationChallenge.protectionS…...

leetcodeSQL解题:3564. 季节性销售分析
leetcodeSQL解题:3564. 季节性销售分析 题目: 表:sales ---------------------- | Column Name | Type | ---------------------- | sale_id | int | | product_id | int | | sale_date | date | | quantity | int | | price | decimal | -…...