log4j学习
依赖
<!--log4j依赖-->
<dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version>
</dependency><!--测试-->
<dependency><groupId>org.junit.jupiter</groupId><artifactId>junit-jupiter</artifactId><version>RELEASE</version><scope>compile</scope>
</dependency>
入门案例以及日志级别说明
@Test
public void test01() {/*Log4入门案例注意在家初始化信息:BasicConfigurator.configure();日志级别说明:Log4j提供了8个级别的日志输出,分别为ALL 最低等级 用于打开所有几倍的日志记录TRACE 程序推进下的追踪信息,这个追踪信息的日志级别非常低,一般情况下不使用DEBUG 指出细粒度信息时间对调试应用程序是非常有帮助的,主要是配合开发,在开发过程中打印一些重要的运行信息INFO 消息的粗粒度级别运行信息WARN 表示警告,程序在运行过程中会出现的有可能会发生的隐形的错误信息注意:,有些信息不是错误,但是这个级别的输出目的就是为了给程序员以提示ERROR 系统的错误信息,发生的错误不影响系统的运行一般情况下,如果不想输出太多的日志,则使用该级别即可FATAL 表示严重错误,它是哪一种一旦发生系统就不可能继续运行的严重错误如果这种级别的错误出现了,表示程序就可以停止运行了OFF 最高等级的级别,用户关闭所有的日志记录其中 DEBUG 是默认的日志输出级别*/// 加載初始化配置BasicConfigurator.configure();Logger logger = Logger.getLogger(Log4jTest.class);logger.fatal("fatal信息");logger.error("error信息");logger.warn("warn信息");logger.info("info信息");logger.debug("debug信息");logger.trace("trace信息");
}
配置文件说明
log4j.rootLogger = trace,console# 配置appender 输出方式 日志输出到哪里,现在是控制台
log4j.appender.console = org.apache.log4j.ConsoleAppender# 表示输出的格式
log4j.appender.console.layout = org.apache.log4j.PatternLayoutlog4j.appender.console.layout.conversionPattern = %r [%t] %p %c %x - %m%n
@Test
public void test02() {/*配置文件的说明1、观察原源码 BasicConfigurator.configure();可以得到两条信息(1)创建根节点对象 Logger root = Logger.getRootLogger();(2)根节点添加了ConsoleAppender对象(表示默认打印到控制台,自定义的格式化输出)2、不使用 BasicConfigurator.configure();加载使用自定义的配置文件来实现功能通过对上边第一点的输出配置文件需要提供Logger、Appender、Layout 3个组件信息(通过配置文件来代替代码)分析Logger logger = Logger.getLogger(Log4jTest.class);进入到getLogger方法,会看到代码LogManager.getLogger(clazz.getName());LogManager:是一个日志管理器LogManager,里边有很多常量,它们代表的就是不同形式(后缀名不同)的配置文件最常使用的就是log4j.properties 这个属性文件(语法简单,使用方便)问题:log4j.properties的加载时机找到LogManager的static代码块在static下遭到下列代码Loader.getResource("log4j.properties");系统会去当前类路径下找到log4j.properties这个文件进行加载对于maven工程resource目录就是当前类路径下的加载完毕后,配置文件是如何读取呢?OptionConverter.selectAndConfigure(url, configuratorClassName,LogManager.getLoggerRepository());进去方法:作为属性文件进行加载: configurator = new PropertyConfigurator();进入到这个PropertyConfigurator这个属性类,看到很多常量,这些常量就是我们在属性配置文件中的配置项如下两项是我们必须配置的static final String ROOT_LOGGER_PREFIX = "log4j.rootLogger";static final String APPENDER_PREFIX = "log4j.appender.";通过这行代码:String prefix = APPENDER_PREFIX + appenderName;我们需要自定义一个appendername 假设蛇我们去的名字是console 就是控制台输出(起名字需要见名之意,console那么我们在配置应该配置控制台输出)log4j.appender.console取值就是log4j中为我们提供的appender类例如log4j.appender.console = org.apache.log4j.ConsoleAppender还可以指定输出格式通过代码:String layoutPrefix = prefix + ".layout";配置:log4j.appender.console.layout = org.apache.log4j.SimpleLayout通过log4j.properties继续在类中搜索找到方法void configureRootCategory在这个方法中找到执行了parseCategory 方法观察这个方法:执行了代码:StringTokenizer st = new StringTokenizer(value, ",");表示要以逗号的方式分割字符串,证明了log4j.rootLogger的取值,其中可以有多个值,但是要以逗号进行分割通过代码:String levelStr = st.nextToken();表示切割后的第一个值是日志的级别通过代码:while(st.hasMoreTokens())表示接下2~n个都是可以通过循环来取得的,具体的内容是:appenderName(日志输出到哪里)证明我们配置方式是:log4j.rootLogger = 日志级别,appenderName1,appenderName2,...,appenderName n表示我们可以同时在根节点上配置多个日志输出的途径通过我们自己的配置文件就可以加载和这个代码了*/// BasicConfigurator.configure();Logger logger = Logger.getLogger(Log4jTest.class);logger.fatal("fatal信息");logger.error("error信息");logger.warn("warn信息");logger.info("info信息");logger.debug("debug信息");logger.trace("trace信息");
}
打开日志输出的详细信息
@Test
public void test03(){/*通过Logger中的开关打开日志输出的详细信息查看LogManager类中的方法:getLoggerRepository()找到代码LogLog.debug(msg, ex);Loglog会使用debug级别的输出为我们展现日志输出的详细信息Logger是记录系统的日志,那么Loglog的使用来记录Logger的日志进入到Loglog.debug(msg, ex)方法中通过代码:if(debugEnabled && !quietMode) {观察到if判断中的这两个开关都是必须开启才行!quietMode 是已经启动的状态,不需要我们去管debugEnabled默认是关闭的所以我们只需要设置debugEnabled为true就可以了*/LogLog.setInternalDebugging(true);Logger logger = Logger.getLogger(Log4jTest.class);logger.fatal("fatal信息");logger.error("error信息");logger.warn("warn信息");logger.info("info信息");logger.debug("debug信息");logger.trace("trace信息");
}
关于log4j.properties 的 layout 的说明
log4j.appender.console.layout.conversionPattern = %r [%t] %p %c %x - %m%n
-X号: X信息输出时左对齐;
%p: 输出日志信息优先级,即DEBUG,INFO,WARN,ERROR,FATAL,
%d: 输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,比如:%d{yyy MMM dd HH:mm:ss,SSS},输出类似:2002年10月18日 22:10:28,921
%r: 输出自应用启动到输出该log信息耗费的毫秒数
%c: 输出日志信息所属的类目,通常就是所在类的全名
%t: 输出产生该日志事件的线程名
%l: 输出日志事件的发生位置,相当于%C.%M(%F:%L)的组合,包括类目名、发生的线程,以及在代码中的行数。举例:Testlog4.main (TestLog4.Java:10)
%x: 输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像Java servlets这样的多客户多线程的应用中。
%%: 输出一个"%“字符
%F: 输出日志消息产生时所在的文件名称
%L: 输出代码中的行号
%m: 输出代码中指定的消息,产生的日志具体信息
%n: 输出一个回车换行符,Windows平台为”/r/n",Unix平台为"/n"输出日志信息换行
**可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式。**如:
1)%20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,默认的情况下右对齐。
2)%-20c:指定输出category的名称,最小的宽度是20,如果category的名称小于20的话,"-"号指定左对齐。
3)%.30c:指定输出category的名称,最大的宽度是30,如果category的名称大于30的话,就会将左边多出的字符截掉,但小于30的话也不会有空格。
4)%20.30c:如果category的名称小于20就补空格,并且右对齐,如果其名称长于30字符,就从左边较远输出的字符截掉。
@Test
public void test04() {/*关于log4j.properties 的 layout 的说明其中PatternLayout 是日常使用最多的方式查看源码setConversionPattern这个方式就是PatterLayout的核心方法conversionPattern在log4j.properties 这个文件中将layout设置为PatterLayout主要配置的属性是conversionPatter[%p]%r %c %t %d{yyyy:MM:dd HH:mm:ss} %m %n可以在%与模式字符之间加上修饰符来控制其最小宽度、最大宽度、和文本的对齐方式[%p]%r %c %t %d{yyyy:MM:dd HH:mm:ss} %m %n[%-5p] 左对齐5个字符,不足5个空格补齐[%5p] 右对齐5个字符,不足5个空格补齐*/Logger logger = Logger.getLogger(Log4jTest.class);logger.fatal("fatal信息");logger.error("error信息");logger.warn("warn信息");logger.info("info信息");logger.debug("debug信息");logger.trace("trace信息");}
将日志输出到文件中
# 第一个是日志输出级别 2-n是appenderName(就是日志在哪里展示)
log4j.rootLogger = trace,file
# 配置appender 输出方式 日志输出到哪里,输出到文件
log4j.appender.file = org.apache.log4j.FileAppender
# 表示输出的格式
log4j.appender.file.layout = org.apache.log4j.PatternLayout
# 自定义layout输出的内容
log4j.appender.file.layout.conversionPattern = [%-5p]%r %c %t %d{yyyy:MM:dd-HH:mm:ss} %m %n
# 文件存储的位置 第一个file是我们自己命名的appenderName 第二个file是我们用来指定文件位置的属性
log4j.appender.file.file = E://test//log4j.log
# 配置输出的字符编码
log4j.appender.file.encoding = utf-8
@Test
public void test05() {/*将日志输出到文件中console是输出控制台的,将日志输出到文件中,也可以做多方向的输出查看FileAppender的源码查看属性信息protected boolean fileAppend = true; 表示是否追加日志信息,true表示追加protected int bufferSize = 8*1024; 缓冲区的大小 kb继续观察找到 setFile 方法 设置文件的位置通过ognl可以推断出setFile这个方法操作的就是File如果有输出中文的需求怎么办观察FileAppender的父类 WriterAppenderprotected String encoding; 有一个这个属性,就是来设置日志输出的字符编码*/Logger logger = Logger.getLogger(Log4jTest.class);logger.fatal("fatal信息");logger.error("error信息");logger.warn("warn信息");logger.info("info信息");logger.debug("debug信息");logger.trace("trace信息");}
日志太大对其进行分割----按照文件大小
# 第一个是日志输出级别 2-n是appenderName(就是日志在哪里展示)
log4j.rootLogger = trace,rollingFile
# 配置RollingFileAppender 输出方式 日志输出到哪里,输出到文件
log4j.appender.rollingFile = org.apache.log4j.RollingFileAppender
# 表示输出的格式
log4j.appender.rollingFile.layout = org.apache.log4j.PatternLayout
# 自定义layout输出的内容
log4j.appender.rollingFile.layout.conversionPattern = [%-5p]%r %c %t %d{yyyy:MM:dd-HH:mm:ss} %m %n
# 文件存储的位置 第一个file是我们自己命名的appenderName 第二个file是我们用来指定文件位置的属性
log4j.appender.rollingFile.file = E://test//log4j.log
# 配置输出的字符编码
log4j.appender.rollingFile.encoding = utf-8
# 指定日志文件内容大小 1兆b 超过就进行拆分
log4j.appender.rollingFile.maxFileSize = 1MB
# 指定日志拆分的数量
log4j.appender.rollingFile.maxBackupIndex = 5
@Test
public void test06() {/*将日志输出到文件中日志太多了,不方便管理怎么维护FileAppender为我们提供了好用的子类来进一步对文件输出进行处理RollingFileAppenderDailyRollingFileAppender1、RollingFileAppender这个类表示按照文件的大小来进行拆分的方式进行操作配置文件进行RollingFileAppender的相关配置如何拆分,观察RollingFileAppender的源码protected long maxFileSize = 10*1024*1024;表示拆分文件的大小,默认是10mprotected int maxBackupIndex = 1; 拆分文件的书名# 指定日志文件内容大小 1兆b 超过就进行拆分log4j.appender.rollingFile.maxFileSize = 1MB# 指定日志拆分的数量log4j.appender.rollinFile.maxBackupIndex = 5只要文件超过1MB,那么则会生成另外一个文件,文件的数量最多是5个文件1 记录日志 1MB文件2 记录日志 1MB......文件5 记录日志 1MB如果5个文件不够怎么办,作为日志管理来说,也不可能让日志无休止的继续增长下去所以,覆盖策略,按照时间来进行覆盖,原则就是保留新的,覆盖旧的*/Logger logger = Logger.getLogger(Log4jTest.class);for (int i = 0; i < 10000; i++) {logger.fatal(i + "fatal信息" );logger.error(i + "error信息");logger.warn(i + "warn信息");logger.info(i + "info信息");logger.debug(i + "debug信息");logger.trace(i + "trace信息");}日志太大对其进行分割----按照时间大小
配置文件
# 第一个是日志输出级别 2-n是appenderName(就是日志在哪里展示)
log4j.rootLogger = trace,dailyRollingFile
# 配置DailyRollingFileAppender 输出方式 日志输出到哪里,输出到文件
log4j.appender.dailyRollingFile = org.apache.log4j.DailyRollingFileAppender
# 表示输出的格式
log4j.appender.dailyRollingFile.layout = org.apache.log4j.PatternLayout
# 自定义layout输出的内容
log4j.appender.dailyRollingFile.layout.conversionPattern = [%-5p]%r %c %t %d{yyyy:MM:dd-HH:mm:ss} %m %n
# 文件存储的位置 第一个file是我们自己命名的appenderName 第二个file是我们用来指定文件位置的属性
log4j.appender.dailyRollingFile.file = E://test//log4j.log
# 配置输出的字符编码
log4j.appender.dailyRollingFile.encoding = utf-8
# 根据时间来进行拆分
# 设置DatePattern属性为'.'yyyy-ww 这个是按照周来进行拆分日志
log4j.appender.dailyRollingFile.datePattern = '.'yyyy-MM-dd HH-mm-ss
相关文章:

log4j学习
依赖 <!--log4j依赖--> <dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version> </dependency><!--测试--> <dependency><groupId>org.junit.jupiter</g…...

【Vue2+3入门到实战】(4)Vue基础之指令修饰符 、v-bind对样式增强的操作、v-model应用于其他表单元素 详细示例
目录 一、今日学习目标1.指令补充 二、指令修饰符1.什么是指令修饰符?2.按键修饰符3.v-model修饰符4.事件修饰符 三、v-bind对样式控制的增强-操作class1.语法:2.对象语法3.数组语法4.代码练习 四、京东秒杀-tab栏切换导航高亮1.需求:2.准备代…...
【数据结构和算法】找到最高海拔
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、题目描述 二、题解 2.1 前缀和的解题模板 2.1.1 最长递增子序列长度 2.1.2 寻找数组中第 k 大的元素 2.1.3 最长公共子序列…...

redis相关问题
1、概述: 1. 非关系型数据库 2. 是分布式缓存数据库 3. 使用 key -value结构存储 2、作用: 用作缓存降低数据库压力,提高性能;可以用作消息队列(削峰、解耦、异步调用) 3、基础语法: 基础命令…...

第41节: Vue3 watch函数
在UniApp中使用Vue3框架时,你可以使用watch函数来观察和响应Vue实例上的数据变化。以下是一个示例,演示了如何在UniApp中使用Vue3框架使用watch函数: <template> <view> <input v-model"message" type"text…...

Centos7:升级gcc、g++到版本5.2.0
背景 Centos7.9版本默认的g版本是4.8.5,在实践golang项目中,用到C14,编译时会报错:gcc: error: unrecognized command line option ‘-stdc14’ 因此,gcc需要升级到更高版本,我这里使用源码编译形式升级到g…...

Pytohn data mode plt
文章目录 文件的读写创建.csv类型的文件,并读取文件创建.xlsx文件 使用Python做图生成数据集切片取值操作修改张量中指定位置的数据 知识点torch.arange(x)torch.tensor(2)Atorch.randn(36).reshape(6,6)shapenumel()reshape(x,y,z)torch.zeros(3,3,4)torch.ones(2,…...

内网离线搭建之----kafka集群
1.系统版本 虚拟机192.168.9.184 虚拟机192.168.9.185 虚拟机192.168.9.186系统 centos7 7.6.1810 2.依赖下载 ps:置顶资源里已经下载好了,直接用!!!!!!!!…...
)
5.1 显示窗口的内容(一)
一,如何显示窗口的内容? 显示器用于在物理硬件(如计算机显示器或触摸屏显示器)上显示窗口的内容。 屏幕API提供的功能允许我们创建同时写入多个窗口和显示的应用程序。屏幕支持多个显示器,但创建和管理使用多个显示器…...
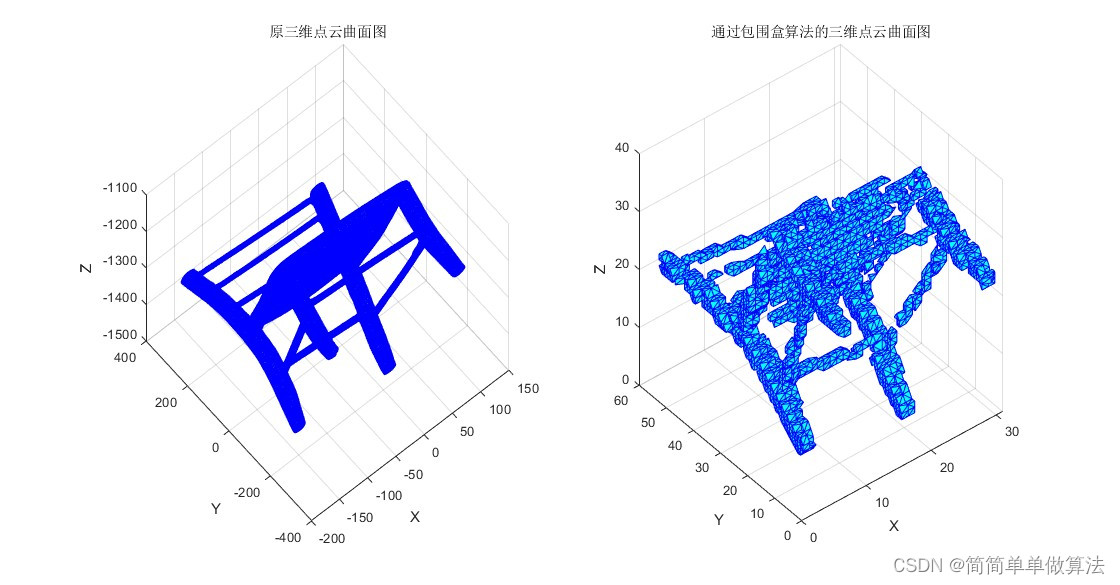
基于包围盒算法的三维点云数据压缩和曲面重建matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 包围盒构建 4.2 点云压缩 4.3 曲面重建 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ...........................................…...
关于Python里xlwings库对Excel表格的操作(十八)
这篇小笔记主要记录如何【设置单元格数据的对齐方式】。前面的小笔记已整理成目录,可点链接去目录寻找所需更方便。 【目录部分内容如下】【点击此处可进入目录】 (1)如何安装导入xlwings库; (2)如何在Wps下…...
VScode远程连接服务器,Pycharm专业版下载及远程连接(深度学习远程篇)
Visual Code、PyCharm专业版,本地和远程交互。 远程连接需要用到SSH协议的技术,常用的代码编辑器vscode 和 pycharm都有此类功能。社区版的pycharm是免费的,但是社区版不支持ssh连接服务器,只有专业版才可以,需要破解…...
------$bus)
Vue2和Vue3组件间通信方式汇总(3)------$bus
组件间通信方式是前端必不可少的知识点,前端开发经常会遇到组件间通信的情况,而且也是前端开发面试常问的知识点之一。接下来开始组件间通信方式第三弹------$bus,并讲讲分别在Vue2、Vue3中的表现。 Vue2Vue3组件间通信方式汇总(1)…...
PyTorch加载数据以及Tensorboard的使用
一、PyTorch加载数据初认识 Dataset:提供一种方式去获取数据及其label 如何获取每一个数据及其label 总共有多少的数据 Dataloader:为后面的网络提供不同的数据形式 数据集 在编译器中导入Dataset from torch.utils.data import Dataset 可以在jupyter中查看Dataset官方文档&…...

TensorFlow是什么
TensorFlow是什么 Tensorflow是一个Google开发的第二代机器学习系统,克服了第一代系统DistBelief仅能开发神经网络算法、难以配置、依赖Google内部硬件等局限性,应用更加广泛,并且提高了灵活性和可移植性,速度和扩展性也有了大幅…...
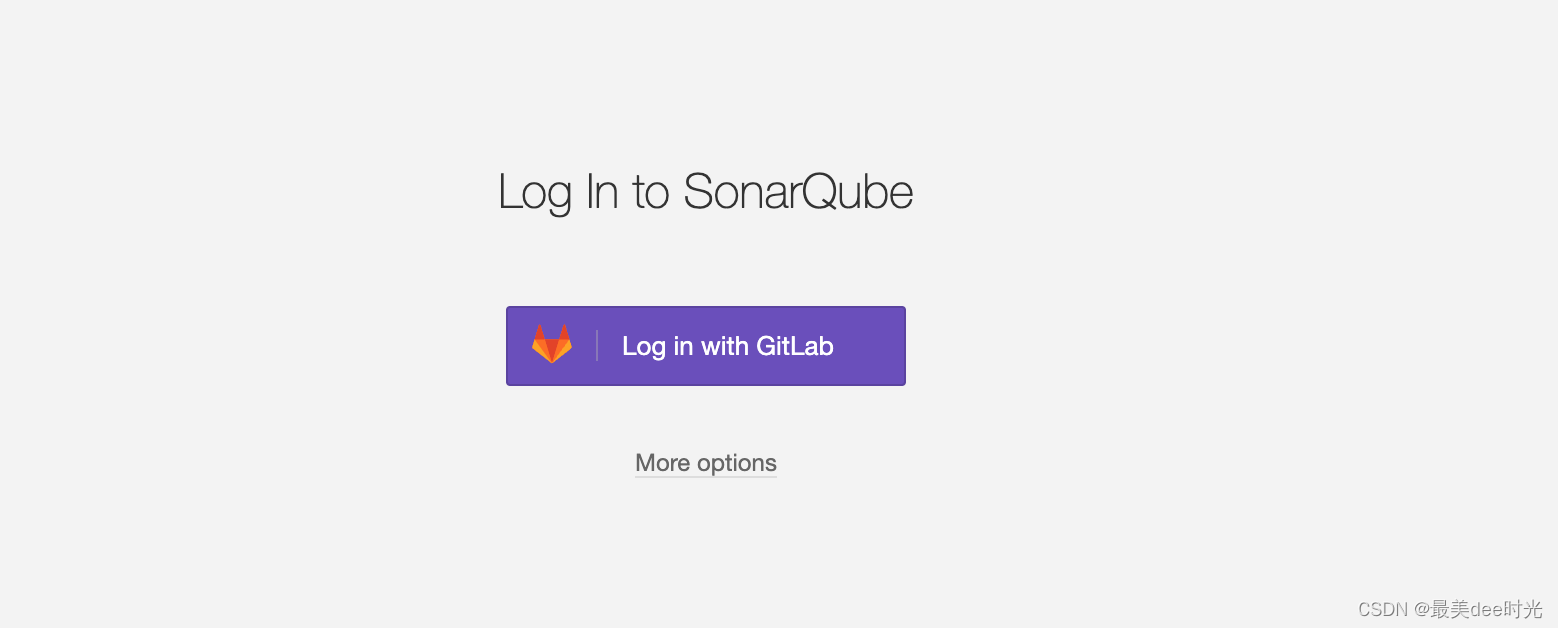
docker-compose 安装Sonar并集成gitlab
文章目录 1. 前置条件2. 编写docker-compose-sonar.yml文件3. 集成 gitlab4. Sonar Login with GitLab 1. 前置条件 安装docker-compose 安装docker 创建容器运行的特有网络 创建挂载目录 2. 编写docker-compose-sonar.yml文件 version: "3" services:sonar-postgre…...

支付平台在选择服务器租用时要注意什么?
如果要建设一个支付平台的话要进行服务器租用,一旦涉及到钱的方面就必须要顾虑到多方面,这样才能保证安全性,今天小编就给大家讲一讲要注意什么呢? 1、带宽:带宽是业务稳定性的直接因素,只有带宽充足,这样…...

IDEA2018升级2023,lombok插件不兼容导致get/set方法无法使用
1、问题 最近了解到一款叫CodeGeeX 的智能编程助手,想要试用一下,但是IDEA2018版本太低了,没有CodeGeeX插件,于是打算将IDEA升级到2023.2.5版本,具体升级过程略过,升级完成后,启动项目…...

企业微信服务商代开发模式获取授权企业的客户信息
服务商代开发素材: 服务商可信ip 企业微信认证 测试时不用再次创建一个企业微信,可以用当前的企业微信作为授权企业使用一、创建代开发应用模板 1,代开发模板回调URL配置 参考 注意:保存代开发应用模板时的corpId是服务商的企业…...

库存管理方法有哪些
库存管理是工作中一个离不开的话题,不管是仓管还是业务员都或多或少接触过库存管理方面的工作,例如:进货、销售、库存盘点等等这些都属于库存管理的范筹,那么库存管理方法有哪些?用哪种方法管理库存比较好,…...

Nunchaku-flux-1-dev在STM32F103C8T6开发中的应用
Nunchaku-flux-1-dev在STM32F103C8T6开发中的应用 1. 场景引入:嵌入式开发的痛点 做STM32开发的朋友都知道,配置外设和调试代码是个挺头疼的事。特别是用STM32F103C8T6这种资源有限的芯片,每个引脚、每个时钟周期都得精打细算。传统的开发方…...

从零到生产:用LangGraph+GPT-4搭建智能客服系统的完整指南
从零到生产:用LangGraphGPT-4搭建智能客服系统的完整指南 在数字化转型浪潮中,智能客服系统已成为企业提升服务效率的关键基础设施。传统规则引擎式客服机器人正被基于大语言模型的智能体所替代,而多智能体协作架构进一步突破了单点智能的局限…...

3大维度提升Godot开发效率的游戏开发效率工具
3大维度提升Godot开发效率的游戏开发效率工具 【免费下载链接】godot-game-template Generic template for Godot games 项目地址: https://gitcode.com/gh_mirrors/go/godot-game-template 🌟价值定位:Godot开发者的效率倍增器 对于Godot引擎开…...
告别重复配置:Immersive Translate云同步功能让翻译偏好跨设备如影随形
告别重复配置:Immersive Translate云同步功能让翻译偏好跨设备如影随形 【免费下载链接】immersive-translate 沉浸式双语网页翻译扩展 , 支持输入框翻译, 鼠标悬停翻译, PDF, Epub, 字幕文件, TXT 文件翻译 - Immersive Dual Web Page Trans…...

ECharts异常检测实战指南:从数据噪声中挖掘关键信息
ECharts异常检测实战指南:从数据噪声中挖掘关键信息 【免费下载链接】echarts ECharts 是一款基于 JavaScript 的开源可视化库,提供了丰富的图表类型和交互功能,支持在 Web、移动端等平台上运行。强大的数据可视化工具,支持多种图…...
)
Trae vs Cursor:哪个AI编程助手更适合你的开发需求?(2024实测对比)
Trae vs Cursor:2024年AI编程助手深度评测与选型指南 在代码量呈指数级增长的今天,AI编程助手已成为开发者工具箱中的标配。2024年,Trae和Cursor这两款工具都迎来了重要版本更新,功能边界不断拓展。但究竟哪款更适合你的工作流&am…...

假外包真派遣:银行大楼里那群“不是员工”的打工人
在银行大厅、科技机房、后台办公区里,每天都在上演一幕最真实的荒诞剧: 一群人穿着统一工装,刷着同样的门禁,坐在同样的工位,做着银行最核心的科技业务。 但他们不是银行的人。 他们是银行外包员工。 是金融科技的隐形…...

【OpenClaw 全面解析:从零到精通】第 001 篇:一只“龙虾“如何改变了 AI 世界——OpenClaw 的诞生与历史背景
系列说明:本系列共计约 20 篇,全面介绍 OpenClaw 开源 AI 智能体框架,从历史背景到核心原理,从安装部署到应用生态。本文为系列第 001 篇,聚焦于 OpenClaw 的诞生历程与时代背景。 摘要 OpenClaw 是 2025 年底由奥地利…...

金仓数据库在MySQL迁移中的实践复盘:某汽车集团近百套系统两周平滑替换路径
金仓数据库在MySQL迁移中的实践复盘:某汽车集团近百套系统两周平滑替换路径观察 “老周,客户刚发来通知——原定三个月的数据库国产化替换,压缩到45天,下周一就要交第一版迁移报告。”上周五下午四点,我正蹲在测试环境…...

解决 SVG 作为 CSS 背景图无法 background-size: 100% 100% 拉伸的问题
1. 问题描述 在 Vue 或 Element Plus 项目中,为容器(如 .el-table__header)设置 SVG 背景图时,即使指定了 background-size: 100% 100%,SVG 依然保持原始比例,导致两侧留白或显示不全,无法自适应…...