2023年国赛高教杯数学建模E题黄河水沙监测数据分析解题全过程文档及程序
2023年国赛高教杯数学建模
E题 黄河水沙监测数据分析
原题再现
黄河是中华民族的母亲河。研究黄河水沙通量的变化规律对沿黄流域的环境治理、气候变化和人民生活的影响,以及对优化黄河流域水资源分配、协调人地关系、调水调沙、防洪减灾等方面都具有重要的理论指导意义。
附件 1 给出了位于小浪底水库下游黄河某水文站近 6 年的水位、水流量与含沙量的实际监测数据,附件 2 给出了该水文站近 6 年黄河断面的测量数据,附件 3 给出了该水文站部分监测点的相关数据。请建立数学模型研究以下问题:
问题 1 研究该水文站黄河水的含沙量与时间、水位、水流量的关系,并估算近 6 年该水文站的年总水流量和年总排沙量。
问题 2 分析近 6 年该水文站水沙通量的突变性、季节性和周期性等特性,研究水沙通量的变化规律。
问题 3 根据该水文站水沙通量的变化规律,预测分析该水文站未来两年水沙通量的变化趋势,并为该水文站制订未来两年最优的采样监测方案(采样监测次数和具体时间等),使其既能及时掌握水沙通量的动态变化情况,又能最大程度地减少监测成本资源。
问题 4 根据该水文站的水沙通量和河底高程的变化情况,分析每年 6-7 月小浪底水库进行“调水调沙”的实际效果。如果不进行“调水调沙”,10 年以后该水文站的河底高程会如何?
附件 1 2016-2021 年黄河水沙监测数据
附件 2 黄河断面的测量数据
附件 3 黄河部分监测点的监测数据
附录 说明
(1) “水位”和“河底高程”均以“1985 国家高程基准”(海拔 72.26 米)为基准面。
(2) 附件中的“起点距离”以河岸边某定点作为起点。
整体求解过程概述(摘要)
黄河是中国的母亲河,其水资源和水沙情况的准确监测对于维护国家生态安全和水资源管理至关重要。本文分析了位于小浪底水库下游黄河某水文站近六年的水位、水流量与含沙量的实际检测数据,基于时间序列预测模型,建立了含沙量预测模型,并分析了该水文站水沙通量的突变性、季节性和周期性等特性,为水文站制定了未来两年最优的采样监测方案,最后分析了“调水调沙”对该水文站河底高程的影响。
针对问题一,本文使用了线性回归模型,来探讨在特定水文站观测到的黄河水的含沙量与时间、水位和水流量之间的关联关系。以描述这些时间、水位和水流量与含沙量之间的关系,并确定各自的系数,从而更好地理解这些因素对含沙量的影响。并给出了水位、流量和含沙量随时间变化的示意图。
针对问题二,采用滑动窗口分析,我们能够识别和量化水沙通量时间序列中的突变点,从而揭示数据中的异常变化。接着,我们进行季节性分解,将时间序列数据分解成长期趋势、季节性成分和周期性成分,以更全面地理解水沙通量的季节性和周期性特征。
针对问题三,根据问题二得出的水沙通量变化规律,使用 ARIMA 模型对未来两年该水文站的水沙通量变化趋势进行预测。采用遗传算法,并结合预测的水沙通量变化趋势,为该水文站制定了未来两年的采样监测方案。
针对问题四,根据 8-5 月(第二年)该水文站的水沙通量和河底高程变化,对6-7 月未进行调水调沙情况进行预测,使用 DID 方法比较其与进行调水调沙之后的差异,以此来分析调水调沙的实际效果,并预测了 10 年后不进行调水调沙情况下河底高程的变化。
模型假设:
1、水位”和“河底高程”均以“1985国家高程基准”(海拔72.26米)为基准面。
2、附件中的“起点距离”以河岸边某定点作为起点。
问题分析:
问题一的分析
问题一要求研究该水文站黄河水的含沙量与时间、水位、水流量的关系,并估算近 6 年该水文站的年总水流量和年总排沙量。本文对附件 1 中该水文站不同时间段下的水位、水流量以及含沙量进行分析,构建含沙量同水位、流量、时间的关系模型,利用已有的含沙量数据对其他时间段含沙量进行预测,根据预测结果来估算该水文站的总水流量和总排沙量。
问题二的分析
问题二要求分析近 6 年该水文站水沙通量的突变性、季节性和周期性等特性,研究水沙通量的变化规律。本文在问题一的基础上,计算每个时间段下的水沙通量,利用滑动窗口分析近六年水沙通量的突变点,使用箱线图直观感受突变点的分布,在对水沙通量进行季节性分解,分析其中的季节性因素和周期性因素,结合上述三点来分析水沙通量的变化规律。
问题三的分析
问题三要求根据该水文站水沙通量的变化规律,预测分析该水文站未来两年水沙通量的变化趋势,并为该水文站制订未来两年最优的采样监测方案,使其既能及时掌握水沙通量的动态变化情况,又能最大程度地减少监测成本资源。本文根据问题二中得到的水沙通量变化规律,使用 ARIMA 模型对水文站未来两年水沙通量变化趋势进行预测。进一步采用遗传算法,结合预测得到的水沙通量变化情况,制定未来两年最优的采样监测方案,通过计算最小成本来尽可能减少监测成本资源。
问题四的分析
问题四要求根据该水文站的水沙通量和河底高程的变化情况,分析每年 6-7 月小浪底水库进行“调水调沙”的实际效果。如果不进行“调水调沙”,10 年以后该水文站的河底高程变化。本文根据问题二中得到的水沙通量,使用月平均采样得到该水文站平均月水沙通量,利用 8 月到次年 5 月的数据对 6-7 月份不进行“调水调沙”情况下的水沙通量进行预测。使用 DID 方法,根据预测得到的水沙通量同实际 6-7 月份水沙通量得到 DID 差异指标,分析“调水调沙”的实际效果。根据附件 2 中同日期下不同起点距离的河底高程,以及附件 3 中的同日期下不同起点距离的水位和水深,计算每日的平均河底高程,进一步计算年平均高程,预测不进行“调水调沙”情况下 10 年后该水文站的河底高程。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
程序代码:(代码和文档not free)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import statsmodels.api as sm
import pmdarima as pm
from sklearn.linear_model import LinearRegression
imports eaborn as sns
from statsmodels.tsa.arima.model import ARIMA
table=pd.read_excel(r"./data/附件 1.xlsx")
foriinrange(2017,2017+5):
#移除table最后一条数据(重复了)
#print(table.iloc[len(table)-1])
table.drop((len(table)-1),inplace=True)
i=str(i)
temp=pd.read_excel(r"./data/附件 1.xlsx",sheet_name=i)
table=pd.concat([table,temp])
table=table.reset_index(drop=True)
table
#补齐时间
table['年'].fillna(method='ffill',inplace=True)
table['月'].fillna(method='ffill',inplace=True)
table['日'].fillna(method='ffill',inplace=True)
table
#数据预处理
time_list=[]
foriinrange(len(table)):
m,d,h=str(int(table.iloc[i,1])),str(int(table.iloc[i,2])),str(table.iloc[i,3])
if(int(table.iloc[i,1])<10):
m="0"+str(int(table.iloc[i,1]))
if(int(table.iloc[i,2])<10):
d="0"+str(int(table.iloc[i,2]))
#print(m,d)
time=str(int(table.iloc[i,0]))+"-"+m+"-"+d+""+h
#print(time)
time_list.append(time)
temp=pd.DataFrame(time_list,columns=["时刻"])
temp["时刻"]=pd.to_datetime(temp["时刻"])
#temp.to_csv('example3.csv',index=False)
#temp
table1=pd.concat([table,temp],axis=1)
#table
df=table1.iloc[:,[7,4,5,6]]
df.to_csv('example2.csv',index=False)
#将索引转换为日期时间
#df.set_index("时刻",inplace=True)
df
df["时刻"]=pd.to_datetime(df["时刻"])
#将时间序列转换为数值型特征
df1=df.copy()
df1['时刻']=df1['时刻'].apply(lambdax:x.timestamp())
df1
#提取时间、水位、水流量和含沙量的数据
data=df1[pd.notna(df["含沙量(kg/m3)"])]
X=data[['时刻','水位(m)','流量(m3/s)']]
y=data['含沙量(kg/m3)']
y
#建立线性回归模型
model=LinearRegression()
model.fit(X,y)
new_df=df1[pd.isna(df.loc[:,"含沙量(kg/m3)"])]
new_X=new_df.loc[:,['时刻','水位(m)','流量(m3/s)']]
new_df.loc[:,"含沙量(kg/m3)"]=model.predict(new_X)
new_df
#使用fillna方法填充空白部分
table['含沙量(kg/m3)'].fillna(new_df['含沙量(kg/m3)'],inplace=True)
df['含沙量(kg/m3)'].fillna(new_df['含沙量(kg/m3)'],inplace=True)
#table.to_csv('example.csv',index=False)
table
#In[242]:
#计算每年的总水流量和总排沙量
yearly_data=table.groupby(table["年"]).agg({'流量(m3/s)':'sum','含沙量(kg/m3)':'sum'})
#输出近 6 年的年总水流量和年总排沙量
print('近 6 年的年总水流量为:',yearly_data['流量(m3/s)'].sum(),'m³')
print('近 6 年的年总排沙量为:',yearly_data['含沙量(kg/m3)'].sum(),'t')
#In[243]:
#计算水沙通量
df["水沙通量"]=df['含沙量(kg/m3)']*df['流量(m3/s)']
df
#In[14]:
#读取数据
data=pd.read_csv('example2.csv')
#设置日期时间列为索引
data.set_index('时刻',inplace=True)
#创建子图
fig,axes=plt.subplots(nrows=3,ncols=1,figsize=(10,10))
#绘制水位数据
axes[0].plot(data.index,data['水位(m)'],label='WaterLevel',color='blue')
axes[0].set_ylabel('WaterLevel(m)')
axes[0].set_title('WaterLevelOverTime')
#绘制水流量数据
axes[1].plot(data.index,data['流量(m3/s)'],label='FlowRate',color='green')
axes[1].set_ylabel('FlowRate(m^3/s)')
axes[1].set_title('FlowRateOverTime')
#绘制含沙量数据
axes[2].plot(data.index,data['含沙量(kg/m3)'],label='SedimentContent',color='red')
axes[2].set_xlabel('Time')
axes[2].set_ylabel('SedimentContent')
axes[2].set_title('SedimentContentOverTime')
#添加图例
foraxinaxes:
ax.legend()
#调整子图布局
plt.tight_layout()
#显示图形
plt.show()
##分析近 6 年水沙通量的突变性、季节性和周期性等特性
###突变性分析
df
#滑动窗口分析
#定义滑动窗口的大小,这里设置为 10
window_size=10
#创建一个空的DataFrame用于存储突变点
change_points=pd.DataFrame(columns=['时刻','水位(m)','流量(m3/s)','含沙量(kg/m3)','水沙通量'])
#进行滑动窗口分析
foriinrange(len(df)-window_size+1):
window=df.iloc[i:i+window_size]
#计算窗口内数据的均值和标准差
mean_values=window.iloc[:,[4]].mean()
std_values=window.iloc[:,[4]].std()
#设置阈值,可以根据实际情况调整
threshold=2.8#假设阈值为 2
#检测是否有数据超过阈值,如果有,则认为有突变点
if(window.iloc[:,[4]]-mean_values).abs().max().max()>threshold*std_values.max():
cp=pd.DataFrame(window.iloc[-1,:]).T
change_points=pd.concat([change_points,cp])#将突变点添加到结果DataFrame中
#打印突变点
print("突变点:")
print(change_points)
change_points
#创建一个新的Figure
plt.figure(figsize=(12,6))
plt.subplot(411)
plt.boxplot(df['水位(m)'],labels=['waterlevel'],vert=False)
plt.title('waterlevelBoxPlot')
plt.subplot(412)
plt.boxplot(df['流量(m3/s)'],labels=['FlowRate'],vert=False)
plt.title('FlowRateBoxPlot')
plt.subplot(413)
plt.boxplot(df['含沙量(kg/m3)'],labels=['SedimentContent'],vert=False)
plt.title('SedimentContentBoxPlot')
plt.subplot(414)
plt.boxplot(df['水沙通量'],labels=['WaterAndSedimentFlux'],vert=False)
plt.title('WaterAndSedimentFluxBoxPlot')
#显示图形
plt.show()
#创建一个新的Figure
plt.figure(figsize=(12,6))
#可视化水位数据
plt.subplot(311)
plt.plot(df['时刻'],df['水位(m)'],label='waterlevel',color='blue')
plt.xlabel('Time')
plt.ylabel('WaterLevel')
plt.title('WaterLevelOverTime')
#可视化水流量数据
plt.subplot(312)
plt.plot(df['时刻'],df['流量(m3/s)'],label='FlowRate',color='green')
plt.xlabel('Time')
plt.ylabel('FlowRate')
plt.title('FlowRateOverTime')
#可视化含沙量数据
plt.subplot(313)
plt.plot(df['时刻'],df['含沙量(kg/m3)'],label='SedimentContent',color='red')
plt.xlabel('Time')
plt.ylabel('SedimentContent')
plt.title('SedimentContentOverTime')
#在图上标记突变点
forindex,rowinchange_points.iterrows():
plt.subplot(311)
plt.axvline(row['时刻'],color='gray',linestyle='--',linewidth=1)
plt.annotate('change',xy=(row['时刻'],df['水位(m)'].max()),xytext=(-20,30), textcoords='offsetpoints',arrowprops=dict(arrowstyle="->",color='gray'))
plt.subplot(312)
plt.axvline(row['时刻'],color='gray',linestyle='--',linewidth=1)
plt.annotate('change',xy=(row['时刻'],df['流量(m3/s)'].max()),xytext=(-20,30), textcoords='offsetpoints',arrowprops=dict(arrowstyle="->",color='gray'))
lt.subplot(313)
plt.axvline(row['时刻'],color='gray',linestyle='--',linewidth=1)
plt.annotate('change',xy=(row['时刻'],df['含沙量(kg/m3)'].max()),xytext=(-20,30), textcoords='offsetpoints',arrowprops=dict(arrowstyle="->",color='gray'))
#调整子图的布局
plt.tight_layout()
#显示图形
plt.show()
#In[250]:
#将索引转换为日期时间
df.set_index("时刻",inplace=True)
df
#In[255]:
#计算每日季节性成分
seasonal_window=12#每年季节性
seasonal=df.rolling(window=seasonal_window,min_periods=1).mean()
#计算趋势
trend=df-seasonal
#可视化分解结果
plt.figure(figsize=(12,8))
plt.subplot(311)
plt.plot(df['水沙通量'],label='Original')
plt.legend(loc='best')
plt.subplot(312)
plt.plot(trend['水沙通量'],label='Trend')
plt.legend(loc='best')
plt.subplot(313)
plt.plot(seasonal['水沙通量'],label='Seasonal')
plt.legend(loc='best')
plt.tight_layout()
#显示图形
plt.show()
全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2023年国赛高教杯数学建模E题黄河水沙监测数据分析解题全过程文档及程序
2023年国赛高教杯数学建模 E题 黄河水沙监测数据分析 原题再现 黄河是中华民族的母亲河。研究黄河水沙通量的变化规律对沿黄流域的环境治理、气候变化和人民生活的影响,以及对优化黄河流域水资源分配、协调人地关系、调水调沙、防洪减灾等方面都具有重要的理论指导…...

跨国企业传输大文件注意事项和解决方案
随着全球化的推进,越来越多的企业需要在跨国业务合作、项目交付、数据分析等方面展开合作,这就带来了大量大文件的传输需求。大文件传输是指文件大小超过1GB的传输,通常涉及视频、音频、图片、文档、压缩包等多种格式。跨国传输大文件不仅需要…...

【Redis】Redis 的数据类型
有五种常用数据类型:String、Hash、Set、List、SortedSet。以及三种特殊的数据类型:Bitmap、HyperLogLog、Geospatial ,其中HyperLogLog、Bitmap的底层都是 String 数据类型,Geospatial 的底层是 Sorted Set 数据类型。 五种常用…...
QT小技巧 - 使用QMovie进行gif切帧
简介 使用QMovie 将 gif 进行切帧, magick 进行合并代码 QString gifPath "E:\\workspace\\qt\\gif2imgs\\203526qre64haq3ccoobqi.gif"; // 你的图片QMovie movie(gifPath); movie.setCacheMode(QMovie::CacheNone);qDebug() << movie.frameCou…...
ES-搜索
聚合分析 聚合分析,英文为Aggregation,是es 除搜索功能外提供的针对es 数据做统计分析的功能 - 功能丰富,提供Bucket、Metric、Pipeline等多种分析方式,可以满足大部分的分析需求 实时性高,所有的计算结果都是即时返回…...

微信小程序面试题
微信小程序面试题 请解释微信小程序的生命周期及其对应的钩子函数。 微信小程序的生命周期包括 onLaunch、onShow、onHide、onError、onPageNotFound 等阶段。对应的钩子函数分别是: onLaunch:小程序初始化时触发。onShow:小程序启动或从后台…...

OpenCV之图像匹配与定位
利用图像特征的keypoints和descriptor来实现图像的匹配与定位。图像匹配算法主要有暴力匹配和FLANN匹配,而图像定位是通过图像匹配结果来反向查询它们在目标图片中的具体坐标位置。 以QQ登录界面为例,将整个QQ登录界面保存为QQ.png文件,QQ登…...
掌握JWT:解密身份验证和授权的关键技术
JSON Web Token 1、什么是JWT2、JWT解决了什么问题3、早期的SSO认证4、JWT认证5、JWT优势6、JWT结构Header 标头Payload 负载 Signature 签名 7、代码实现添加依赖生成Token认证token 8、工具类9、JWT整合Web10、拦截器校验11、网关路由校验12、解决多用户登录的问题13、客户端…...
git命令和docker命令
1、git git是分布式的版本控制工具 git可以通过本地仓库管理文件的历史版本记录 # 本地仓库操作的命令 # 初始化本地库 git init # 添加文件到暂存区 git add . git checkout 暂存区要撤销的文件名称 # 提交暂存区文件 git commit -m 注释# 版本穿梭 # 查看提交记录 git log…...
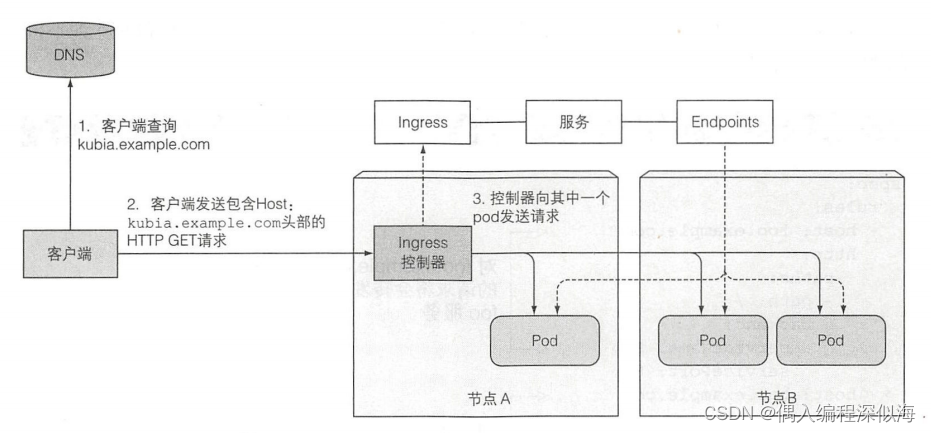
【K8S in Action】服务:让客户端发现pod 并与之通信(2)
一 通过Ingress暴露服务 Ingress (名词) 一一进入或进入的行为;进入的权利;进入的手段或地点;入口。一个重要的原因是每个 LoadBalancer 服务都需要自己的负载均衡器, 以及 独有的公有 IP 地址, 而 Ingres…...

Spring Boot 中实现跨域的几种方式
前言 在现代Web应用中,由于安全性和隐私的考虑,浏览器限制了从一个域向另一个域发起的跨域HTTP请求。解决这个问题的一种常见方式是实现跨域资源共享(CORS)。Spring Boot提供了多种方式来处理跨域请求,本文将介绍其中的…...

WT2605C音频蓝牙语音芯片:单芯片实现蓝牙+MP3+BLE+电话本多功能应用
在当今的电子产品领域,多功能、高集成度成为了一种趋势。各种产品都需要具备多种功能,以满足用户多样化的需求。针对这一市场趋势,唯创知音推出了一款集成了蓝牙、MP3播放、BLE和电话本功能的音频蓝牙语音芯片——WT2605C,实现了单…...
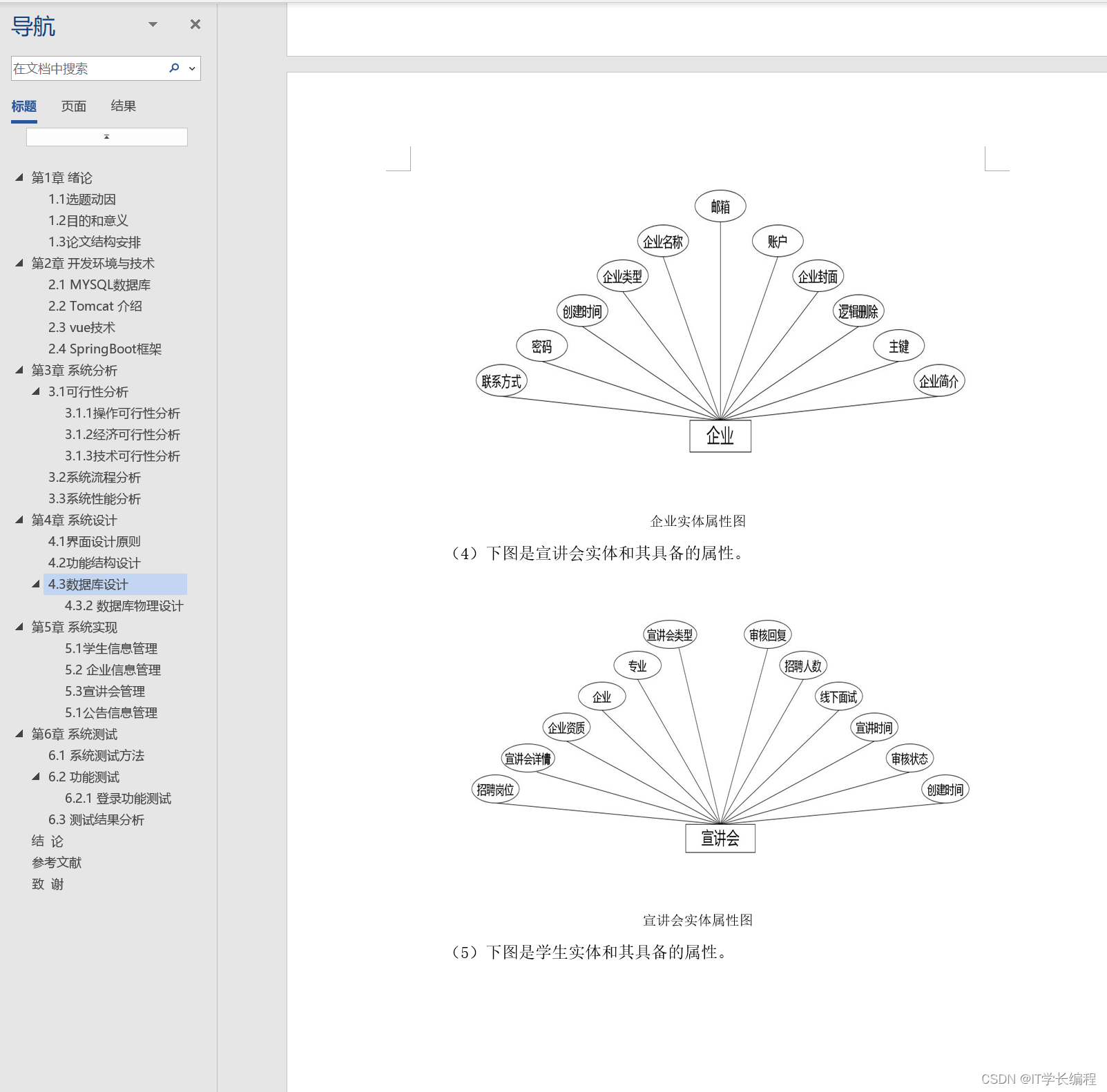
计算机毕业设计 基于SpringBoot的高校宣讲会管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

Android 使用Serialiable接口和Parcelable接口进行数据传送
一、前言 这篇文章主要针对Serialiable和Parcelable接口来传递对象。呈现的功能是跳转到另一个界面,然后通过toast展现我收到的数据。 二、使用Serialiable接口传递数据 1.创建需要传递的对象 //必须实现Serializable接口,此对象才有传递的资格 publ…...
【数据结构入门精讲 | 第十七篇】一文讲清图及各类图算法
在上一篇中我们进行了的并查集相关练习,在这一篇中我们将学习图的知识点。 目录 概念深度优先DFS伪代码 广度优先BFS伪代码 最短路径算法(Dijkstra)伪代码 Floyd算法拓扑排序逆拓扑排序 概念 下面介绍几种在对图操作时常用的算法。 深度优先D…...

Python 直方图的绘制-`hist()`方法(Matplotlib篇-第7讲)
Python 直方图的绘制-hist()方法(Matplotlib篇-第7讲) 🍹博主 侯小啾 感谢您的支持与信赖。☀️ 🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹꧔ꦿ🌹…...

Quartz持久化(springboot整合mybatis版本实现调度任务持久化)--提供源码下载
1、Quartz持久化功能概述 1、实现使用quartz提供的默认11张持久化表存储quartz相关信息。 2、实现定时任务的编辑、启动、关闭、删除。 3、实现自定义持久化表存储quartz定时任务信息。 4、本案例使用springboot整合mybatis框架和MySQL数据库实现持久化 5、提供源码下载 …...

掌握的单词个数 - 华为OD统一考试
OD统一考试 题解: Java / Python / C++ 题目描述 有一个字符串数组 words 和一个字符串 chars。假如可以用 chars 中的字母拼写出 words 中的某个"单词"(字符串),那么我们就认为你掌握了这个单词。 words 的字等仅由 a-z 英文小写宁母组成,例如“abc”。 char…...
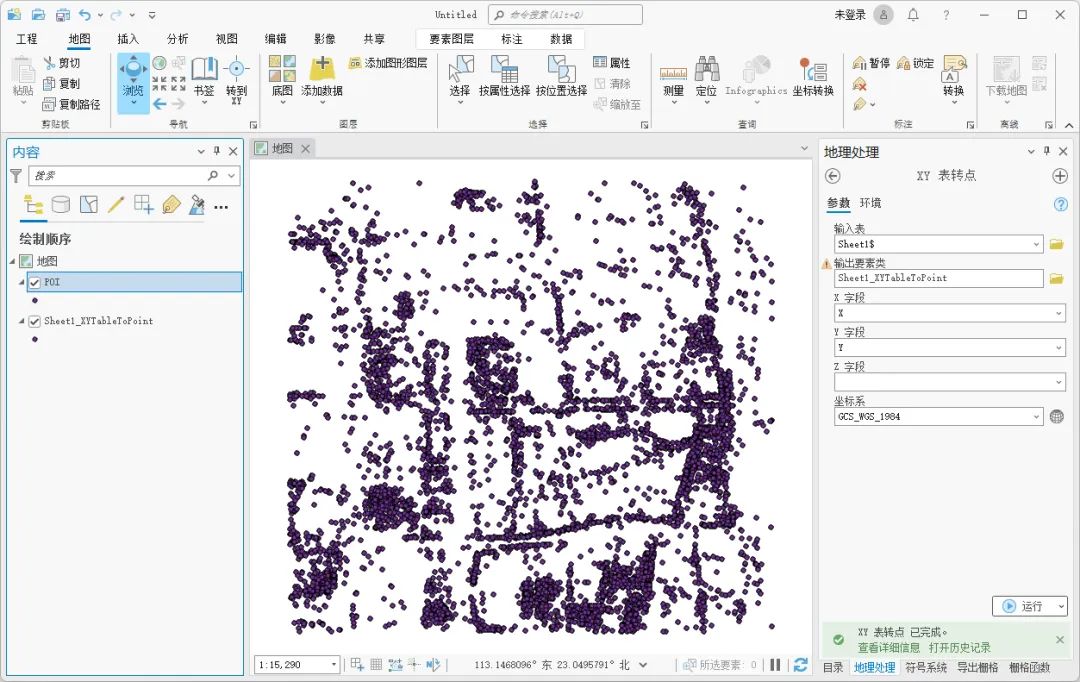
如何使用ArcGIS Pro将Excel表转换为SHP文件
有的时候我们得到的数据是一张张的Excel表格,如果想要在ArcGIS Pro中进行分析或者制图则需要先转换为SHP格式,这里为大家介绍一下转换方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的POI数据,除了P…...
11.1Linux串口应用程序开发
UART简介 UART的全称是Universal Asynchronous Receiver and Transmitter,即异步发送和接收。 串口在嵌入式中用途非常的广泛,主要的用途有: 打印调试信息;外接各种模块:GPS、蓝牙; 串口因为结构简单、稳…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

2025年能源电力系统与流体力学国际会议 (EPSFD 2025)
2025年能源电力系统与流体力学国际会议(EPSFD 2025)将于本年度在美丽的杭州盛大召开。作为全球能源、电力系统以及流体力学领域的顶级盛会,EPSFD 2025旨在为来自世界各地的科学家、工程师和研究人员提供一个展示最新研究成果、分享实践经验及…...

【SQL学习笔记1】增删改查+多表连接全解析(内附SQL免费在线练习工具)
可以使用Sqliteviz这个网站免费编写sql语句,它能够让用户直接在浏览器内练习SQL的语法,不需要安装任何软件。 链接如下: sqliteviz 注意: 在转写SQL语法时,关键字之间有一个特定的顺序,这个顺序会影响到…...

基于数字孪生的水厂可视化平台建设:架构与实践
分享大纲: 1、数字孪生水厂可视化平台建设背景 2、数字孪生水厂可视化平台建设架构 3、数字孪生水厂可视化平台建设成效 近几年,数字孪生水厂的建设开展的如火如荼。作为提升水厂管理效率、优化资源的调度手段,基于数字孪生的水厂可视化平台的…...

sqlserver 根据指定字符 解析拼接字符串
DECLARE LotNo NVARCHAR(50)A,B,C DECLARE xml XML ( SELECT <x> REPLACE(LotNo, ,, </x><x>) </x> ) DECLARE ErrorCode NVARCHAR(50) -- 提取 XML 中的值 SELECT value x.value(., VARCHAR(MAX))…...

c#开发AI模型对话
AI模型 前面已经介绍了一般AI模型本地部署,直接调用现成的模型数据。这里主要讲述讲接口集成到我们自己的程序中使用方式。 微软提供了ML.NET来开发和使用AI模型,但是目前国内可能使用不多,至少实践例子很少看见。开发训练模型就不介绍了&am…...

【Oracle】分区表
个人主页:Guiat 归属专栏:Oracle 文章目录 1. 分区表基础概述1.1 分区表的概念与优势1.2 分区类型概览1.3 分区表的工作原理 2. 范围分区 (RANGE Partitioning)2.1 基础范围分区2.1.1 按日期范围分区2.1.2 按数值范围分区 2.2 间隔分区 (INTERVAL Partit…...

蓝桥杯 冶炼金属
原题目链接 🔧 冶炼金属转换率推测题解 📜 原题描述 小蓝有一个神奇的炉子用于将普通金属 O O O 冶炼成为一种特殊金属 X X X。这个炉子有一个属性叫转换率 V V V,是一个正整数,表示每 V V V 个普通金属 O O O 可以冶炼出 …...

佰力博科技与您探讨热释电测量的几种方法
热释电的测量主要涉及热释电系数的测定,这是表征热释电材料性能的重要参数。热释电系数的测量方法主要包括静态法、动态法和积分电荷法。其中,积分电荷法最为常用,其原理是通过测量在电容器上积累的热释电电荷,从而确定热释电系数…...

招商蛇口 | 执笔CID,启幕低密生活新境
作为中国城市生长的力量,招商蛇口以“美好生活承载者”为使命,深耕全球111座城市,以央企担当匠造时代理想人居。从深圳湾的开拓基因到西安高新CID的战略落子,招商蛇口始终与城市发展同频共振,以建筑诠释对土地与生活的…...