Quartz持久化(springboot整合mybatis版本实现调度任务持久化)--提供源码下载
1、Quartz持久化功能概述
1、实现使用quartz提供的默认11张持久化表存储quartz相关信息。
2、实现定时任务的编辑、启动、关闭、删除。
3、实现自定义持久化表存储quartz定时任务信息。
4、本案例使用springboot整合mybatis框架和MySQL数据库实现持久化
5、提供源码下载
2、认识quartz持久化
可以将调度信息存储到数据库中,进行持久化,当程序中断,再次启动的时候。任然会保留中断之前的数据,继续执行。
1、Quartz中通过JobStore来存储任务和触发器信息,Quartz默认使用RAMJobstore将任务和触发器的信息存储在内存中,但是当服务器宕机内存中的信息会丢失。
2、Quartz中通过JDBCJobStore将任务和触发器等信息保存在数据库中,实现持久化。
3、JDBCJobStoreSupport中包含两个子类:
JobStoreTX:表示自己管理事务,存储在数据库中,当程序中断,调度信息不会丢失,
支持事务,支持集群,再次启动时,会恢复因程序关闭,重启而错过的任务。
JobStoreCMT:表示使用容器管理事务
3、Quartz+MySQL持久化默认依赖的表信息
针对不同的数据库,表就放在不同的sql文件中。
如果你使用的是mysql数据库表信息就在tables_mysql.sql文件中。
重点:这些表不会自动执行,需要拷贝出来手动创建在你的数据库中。


mysql表信息如下
QRTZ _JOB_DETAILS 存储每一个已配置的Job的详细信息
QRTZ _TRIGGERS 存储已配置的Trigger的信息
QRTZ_BLOB_TRIGGERS Trigger作为Blob类型存储
QRTZ _SIMPLE_TRIGGERS 存储SimpleTrigger的信息,包括重复次数、间隔、以及已触的次数
QRTZ _CRON_TRIGGERS 存储CronTrigger,包括Cron表达式和时区信息
QRTZ _SIMPROP_TRIGGERS存储CalendarIntervalTrigger和DailyTimeIntervalTrigger两种触发器
QRTZ _CALENDARS 存储Quartz的Calendar信息
QRTZ _PAUSED_TRIGGER_GRPS 存储已暂停的Trigger组的信息
QRTZ _FIRED_TRIGGERS 存储与已触发的Trigger相关的状态信息,以及相关Job的执行信息
QRTZ _SCHEDULER_STATE 存储少量的有关Scheduler的状态信息,和别的Scheduler实例
QRTZ _LOCKS 存储程序的悲观锁的信息
创表信息如下:
#
# Quartz seems to work best with the driver mm.mysql-2.0.7-bin.jar
#
# PLEASE consider using mysql with innodb tables to avoid locking issues
#
# In your Quartz properties file, you'll need to set
# org.quartz.jobStore.driverDelegateClass = org.quartz.impl.jdbcjobstore.StdJDBCDelegate
#DROP TABLE IF EXISTS QRTZ_FIRED_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_PAUSED_TRIGGER_GRPS;
DROP TABLE IF EXISTS QRTZ_SCHEDULER_STATE;
DROP TABLE IF EXISTS QRTZ_LOCKS;
DROP TABLE IF EXISTS QRTZ_SIMPLE_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_SIMPROP_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_CRON_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_BLOB_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_TRIGGERS;
DROP TABLE IF EXISTS QRTZ_JOB_DETAILS;
DROP TABLE IF EXISTS QRTZ_CALENDARS;CREATE TABLE QRTZ_JOB_DETAILS(SCHED_NAME VARCHAR(120) NOT NULL,JOB_NAME VARCHAR(200) NOT NULL,JOB_GROUP VARCHAR(200) NOT NULL,DESCRIPTION VARCHAR(250) NULL,JOB_CLASS_NAME VARCHAR(250) NOT NULL,IS_DURABLE VARCHAR(1) NOT NULL,IS_NONCONCURRENT VARCHAR(1) NOT NULL,IS_UPDATE_DATA VARCHAR(1) NOT NULL,REQUESTS_RECOVERY VARCHAR(1) NOT NULL,JOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,JOB_NAME VARCHAR(200) NOT NULL,JOB_GROUP VARCHAR(200) NOT NULL,DESCRIPTION VARCHAR(250) NULL,NEXT_FIRE_TIME BIGINT(13) NULL,PREV_FIRE_TIME BIGINT(13) NULL,PRIORITY INTEGER NULL,TRIGGER_STATE VARCHAR(16) NOT NULL,TRIGGER_TYPE VARCHAR(8) NOT NULL,START_TIME BIGINT(13) NOT NULL,END_TIME BIGINT(13) NULL,CALENDAR_NAME VARCHAR(200) NULL,MISFIRE_INSTR SMALLINT(2) NULL,JOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,JOB_NAME,JOB_GROUP)REFERENCES QRTZ_JOB_DETAILS(SCHED_NAME,JOB_NAME,JOB_GROUP)
);CREATE TABLE QRTZ_SIMPLE_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,REPEAT_COUNT BIGINT(7) NOT NULL,REPEAT_INTERVAL BIGINT(12) NOT NULL,TIMES_TRIGGERED BIGINT(10) NOT NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CRON_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,CRON_EXPRESSION VARCHAR(200) NOT NULL,TIME_ZONE_ID VARCHAR(80),PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_SIMPROP_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,STR_PROP_1 VARCHAR(512) NULL,STR_PROP_2 VARCHAR(512) NULL,STR_PROP_3 VARCHAR(512) NULL,INT_PROP_1 INT NULL,INT_PROP_2 INT NULL,LONG_PROP_1 BIGINT NULL,LONG_PROP_2 BIGINT NULL,DEC_PROP_1 NUMERIC(13,4) NULL,DEC_PROP_2 NUMERIC(13,4) NULL,BOOL_PROP_1 VARCHAR(1) NULL,BOOL_PROP_2 VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_BLOB_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,BLOB_DATA BLOB NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP),FOREIGN KEY (SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)REFERENCES QRTZ_TRIGGERS(SCHED_NAME,TRIGGER_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_CALENDARS(SCHED_NAME VARCHAR(120) NOT NULL,CALENDAR_NAME VARCHAR(200) NOT NULL,CALENDAR BLOB NOT NULL,PRIMARY KEY (SCHED_NAME,CALENDAR_NAME)
);CREATE TABLE QRTZ_PAUSED_TRIGGER_GRPS(SCHED_NAME VARCHAR(120) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,PRIMARY KEY (SCHED_NAME,TRIGGER_GROUP)
);CREATE TABLE QRTZ_FIRED_TRIGGERS(SCHED_NAME VARCHAR(120) NOT NULL,ENTRY_ID VARCHAR(95) NOT NULL,TRIGGER_NAME VARCHAR(200) NOT NULL,TRIGGER_GROUP VARCHAR(200) NOT NULL,INSTANCE_NAME VARCHAR(200) NOT NULL,FIRED_TIME BIGINT(13) NOT NULL,SCHED_TIME BIGINT(13) NOT NULL,PRIORITY INTEGER NOT NULL,STATE VARCHAR(16) NOT NULL,JOB_NAME VARCHAR(200) NULL,JOB_GROUP VARCHAR(200) NULL,IS_NONCONCURRENT VARCHAR(1) NULL,REQUESTS_RECOVERY VARCHAR(1) NULL,PRIMARY KEY (SCHED_NAME,ENTRY_ID)
);CREATE TABLE QRTZ_SCHEDULER_STATE(SCHED_NAME VARCHAR(120) NOT NULL,INSTANCE_NAME VARCHAR(200) NOT NULL,LAST_CHECKIN_TIME BIGINT(13) NOT NULL,CHECKIN_INTERVAL BIGINT(13) NOT NULL,PRIMARY KEY (SCHED_NAME,INSTANCE_NAME)
);CREATE TABLE QRTZ_LOCKS(SCHED_NAME VARCHAR(120) NOT NULL,LOCK_NAME VARCHAR(40) NOT NULL,PRIMARY KEY (SCHED_NAME,LOCK_NAME)
);commit;
4、在MySQL数据库中创建表

5、quartz默认配置文档
配置文件位置:

配置参考文档:
https://www.w3cschool.cn/quartz_doc/quartz_doc-i7oc2d9l.html
6、创建springboot工程配置quartz持久化
在正式开始之前我们需要明确一点,quartz自带的表数据的添加功能是quartz源码中自带的,我们只需要正确的配置数据源即可自动的添加数据。
6.1、创建工程引入相关包信息
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>3.1.7</version><relativePath/> <!-- lookup parent from repository --></parent><groupId>com.example</groupId><artifactId>quartzpersistencedemo3</artifactId><version>0.0.1-SNAPSHOT</version><name>quartzpersistencedemo3</name><description>quartzpersistencedemo3</description><properties><java.version>17</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-quartz</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.mybatis.spring.boot</groupId><artifactId>mybatis-spring-boot-starter</artifactId><version>3.0.3</version></dependency><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId><version>5.1.49</version></dependency><dependency><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId><optional>true</optional></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-test</artifactId><scope>test</scope></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId><configuration><image><builder>paketobuildpacks/builder-jammy-base:latest</builder></image><excludes><exclude><groupId>org.projectlombok</groupId><artifactId>lombok</artifactId></exclude></excludes></configuration></plugin></plugins></build>
</project>
6.2、配置连接数据相关参数
最重要的配置就是连接数据库及job-store-type: jdbc,其他的配置如果不需要都可以不写。
最重要的配置就是连接数据库及job-store-type: jdbc,其他的配置如果不需要都可以不写。
spring:datasource:url: jdbc:mysql://localhost:3306/quartz?characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=falsedriver-class-name: com.mysql.jdbc.Driverusername: rootpassword: 123456quartz:# 任务存储类型job-store-type: jdbc# 关闭时等待任务完成wait-for-jobs-to-complete-on-shutdown: false# 是否覆盖已有的任务overwrite-existing-jobs: true# 是否自动启动计划程序auto-startup: true# 延迟启动startup-delay: 0sjdbc:# 数据库架构初始化模式(never:从不进行初始化;always:每次都清空数据库进行初始化;embedded:只初始化内存数据库(默认值))# 注意:第一次启动后,需要将always改为never,否则后续每次启动都会重新初始化quartz数据库initialize-schema: never# 用于初始化数据库架构的SQL文件的路径# schema: classpath:sql/tables_mysql_innodb.sql# 相关属性配置properties:org:quartz:scheduler:# 调度器实例名称instanceName: QuartzScheduler# 分布式节点ID自动生成instanceId: AUTOjobStore:class: org.springframework.scheduling.quartz.LocalDataSourceJobStoredriverDelegateClass: org.quartz.impl.jdbcjobstore.StdJDBCDelegate# 表前缀tablePrefix: QRTZ_# 是否开启集群isClustered: true# 数据源别名(自定义)dataSource: quartz# 分布式节点有效性检查时间间隔(毫秒)clusterCheckinInterval: 10000useProperties: false# 线程池配置threadPool:class: org.quartz.simpl.SimpleThreadPoolthreadCount: 10threadPriority: 5threadsInheritContextClassLoaderOfInitializingThread: true
6.3、创建quartz配置类
在配置类中配置JobDetail和trigger监听器
这个配置类只是添加任务的快捷方式,这中方式在下面的添加任务中会被替代。
@Configuration
public class QuartzJobConfig {@Beanpublic JobDetail jobDetail(){JobDetail detail= JobBuilder.newJob(MyQuartzJob.class).withIdentity("job33","group33").storeDurably()//设置Job持久化//设置job数据.usingJobData("username","xiaochun2").usingJobData("useraddr","安徽合肥2").build();return detail;}//创建触发器,触发实例@Beanpublic Trigger trigger(){//每隔5秒执行一次CronScheduleBuilder cronScheduleBuilder = CronScheduleBuilder.cronSchedule("0/5 * * * * ?");Trigger trigger= TriggerBuilder.newTrigger().forJob(jobDetail()).withIdentity("trigger33","group33").withSchedule(cronScheduleBuilder).startNow().build();return trigger;}
}
6.4、创建job,配置任务具体内容
@Slf4j
public class MyQuartzJob extends QuartzJobBean {@Overrideprotected void executeInternal(JobExecutionContext context) throws JobExecutionException {//执行的具体内容log.info("=========quartzpersistencedemo3--quartz具体内容============");System.out.println(context.getJobInstance());System.out.println(context.getJobDetail().getJobDataMap().get("username"));}
}
6.5、启动任务并自动向数据库添加数据
从图中可以看出,任务已经顺利的启动

6.6、查看数据库数据情况
【qrtz_cron_triggers表数据】

【qrtz_job_details表数据】

【qrtz_triggers表数据】
![]()
【qrtz_scheduler_state表数据】

6.7、暂停任务
说明1:通过scheduler.pauseJob暂停任务。
说明2:scheduler.pauseJob需要的两个参数是qrtz_job_details表中的JOB_NAME和JOB_GROUP字段的值。
说明3:本案例中只涉及到任务本身的暂停,考虑到业务的并发和分布式的情况,在暂停前可以判断一下任务是否存在,如果还创建了自己的业务表,应该在任务暂停后修改自己的表状态。个人业务表的所有操作按照常规操作即可。
@Controller
public class QuartzController {@ResourceScheduler scheduler;//暂停任务@RequestMapping("/suspendJob")@ResponseBodypublic String suspendJob(){String jobName="job33";String jobGroup="group33";try{scheduler.pauseJob(JobKey.jobKey(jobName,jobGroup));return "暂停成功";}catch (Exception e){return "暂停失败";}}
}
6.8、重启任务
重点说明:这个时候重启项目,程序会自动的加载QuartzConfig并创建JobDetail和Trigger并自动的向数据库添加数据。
核心添加的qrtz_cron_triggers、qrtz_job_details、qrtz_triggers、qrtz_scheduler_state
说明1:通过scheduler.resumeJob重启任务
说明2:scheduler. resumeJob需要的两个参数是qrtz_job_details表中的JOB_NAME和JOB_GROUP字段的值。
@Controller
public class QuartzController {@ResourceScheduler scheduler;//重启任务@RequestMapping("/resumeJob")@ResponseBodypublic String resumeJob() {String jobName="job33";String jobGroup="group33";try {//恢复任务scheduler.resumeJob(JobKey.jobKey(jobName,jobGroup));return "重启成功";} catch (SchedulerException e) {return "重启失败";}}
}
6.9、删除任务
删除任务会清除数据库中的数据
@Controller
public class QuartzController {@ResourceScheduler scheduler;//删除任务@RequestMapping("/removeJob")@ResponseBodypublic String removeJob() throws SchedulerException {String jobName="job33";String jobGroup="group33";//先暂停任务scheduler.pauseJob(JobKey.jobKey(jobName,jobGroup));//获取任务触发器TriggerKey triggerKey = TriggerKey.triggerKey(jobName, jobGroup);try {//停止触发器scheduler.pauseTrigger(triggerKey);//移除触发器scheduler.unscheduleJob(triggerKey);//删除任务scheduler.deleteJob(JobKey.jobKey(jobName,jobGroup));return "删除任务成功";} catch (SchedulerException e) {return "删除任务失败";}}
}
6.10、立即启动任务
重点:只会启动一次
@Controller
public class QuartzController {@ResourceScheduler scheduler;//立即启动任务@RequestMapping("/triggerJob")@ResponseBodypublic String triggerJob() {String jobName="job33";String jobGroup="group33";try {scheduler.triggerJob(JobKey.jobKey(jobName,jobGroup));return "启动成功";} catch (SchedulerException e) {return "启动失败";}}
}
6.11、添加任务
【添加任务依赖对象】
对时区不了解,可以看这篇文章:Java中ZonedDateTime使用详解及时间转化(java中获取时区)_java zoneddatetime-CSDN博客
6.11.1、添加任务依赖对象
对时区不了解,可以看这篇文章:Java中ZonedDateTime使用详解及时间转化(java中获取时区)_java zoneddatetime-CSDN博客
@Setter
@Getter
@AllArgsConstructor
@NoArgsConstructor
@ToString
public class JobInfo {private String jobName;//job名称private String jobGroup;//job所属组private String triggerName;//触发器名称private String jobDescription;//job任务描述private Map<String,Object> userData;//job携带的用户参数private String cron;//触发器规则private String timeZoneId;//当前时区
}
6.11.2、实现任务添加代码
在项目中使用到了ObjectMapper对象,将map转化成json字符串,不了解可以看文章:
Springboot中解析JSON字符串(jackson库ObjectMapper解析JSON字符串)-CSDN博客
重点:小伙伴需要注意了,创建任务的时候MyQuartzJob任务本身这个是需要提前创建的。
//添加任务
@RequestMapping(value = "/addJob",method = RequestMethod.POST)
@ResponseBody
public String addJob(@RequestBody JobInfo jobInfo) throws JsonProcessingException {System.out.println("======addJob==="+jobInfo.toString());//通过jobKey判断任务是否唯一// jobKey有jobName和jobGroup组成JobKey jobKey = JobKey.jobKey(jobInfo.getJobName(), jobInfo.getJobGroup());try {JobDetail jobDetail = scheduler.getJobDetail(jobKey);if (Objects.nonNull(jobDetail)) {scheduler.deleteJob(jobKey);}} catch (SchedulerException e) {e.printStackTrace();}//将map转化成json的工具ObjectMapper objectMapper=new ObjectMapper();//任务详情JobDetail jobDetail = JobBuilder.newJob(MyQuartzJob.class)//jobDetail描述.withDescription(jobInfo.getJobDescription()) //任务描述.usingJobData("userData",objectMapper.writeValueAsString(jobInfo.getUserData())).withIdentity(jobKey) //指定任务.build();//根据cron,TimeZone时区,指定执行计划CronScheduleBuilder builder =CronScheduleBuilder//任务表达式.cronSchedule(jobInfo.getCron()).inTimeZone(TimeZone.getTimeZone(jobInfo.getTimeZoneId()));//触发器Trigger trigger = TriggerBuilder.newTrigger().withIdentity(jobInfo.getTriggerName(), jobInfo.getJobGroup()).startNow().withSchedule(builder).build();//添加任务try {scheduler.scheduleJob(jobDetail, trigger);return "任务添加成功";} catch (SchedulerException e) {System.out.println(e.getMessage());}return "任务添加失败";
}
6.11.3、在postman中的测试
由于我们是在body中传递的数据,在addJob方法接受的参数需要使用@RequestBody注解,
如果不使用请求获取不到body的raw传递的数据。

测试参数:
{
"jobName":"jobName1",
"jobGroup":"jobGroup1",
"triggerName":"triggerName1",
"jobDescription":"三点、六点、九点发优惠卷。",
"cron":"0/5 * * * * ?",
"timeZoneId":"Asia/Shanghai",
"userData":{"name":"123"}
}
数据库参数:

结果输出:

6.12、修改任务
修改任务的本质就是添加任务,只要保证jobName,jobGroup,triggerName等关键参数不变,即可修改数据。
7、自定义任务表
Quartz总共提供了11张表来持久化分布式任务调度的相关信息,总体来说功能强大,但是比较冗余。这个时候很多人希望自己创建一张简单的表,实现任务管理也是可以的。但是这个时候对自定义表的增删改查操作都需要自己写,而无法使用默认提供了功能。
创建信息可以参照如下:
CREATE TABLE `my_job` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID',
`jobName` varchar(50) NOT NULL COMMENT '任务名称',
`jobGroupName` varchar(50) NOT NULL COMMENT '任务组名',`jobTriggerName` varchar(50) NOT NULL COMMENT '触发器名称',
`jobCron` varchar(50) NOT NULL COMMENT '时间规则表达式',
`jobClassPath` varchar(200) NOT NULL COMMENT '类全类型',
`jobDataMap` varchar(100) DEFAULT NULL COMMENT '用户数据',
`jobStatus` int(2) NOT NULL COMMENT '任务状态',
`jobDescribe` varchar(100) DEFAULT NULL COMMENT '任务功能描述',
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
值得注意的是,如果这个时候通过自定义修改了任务状态为体质状态(如停止状态为1),修改之后还需要调用scheduler.pauseJob(JobKey.jobKey(jobName,jobGroup));,任他任务也是。因为我们的停止本质只是修改数据库的值。
8、源码下载
https://download.csdn.net/download/tangshiyilang/88660404
相关文章:
Quartz持久化(springboot整合mybatis版本实现调度任务持久化)--提供源码下载
1、Quartz持久化功能概述 1、实现使用quartz提供的默认11张持久化表存储quartz相关信息。 2、实现定时任务的编辑、启动、关闭、删除。 3、实现自定义持久化表存储quartz定时任务信息。 4、本案例使用springboot整合mybatis框架和MySQL数据库实现持久化 5、提供源码下载 …...

掌握的单词个数 - 华为OD统一考试
OD统一考试 题解: Java / Python / C++ 题目描述 有一个字符串数组 words 和一个字符串 chars。假如可以用 chars 中的字母拼写出 words 中的某个"单词"(字符串),那么我们就认为你掌握了这个单词。 words 的字等仅由 a-z 英文小写宁母组成,例如“abc”。 char…...
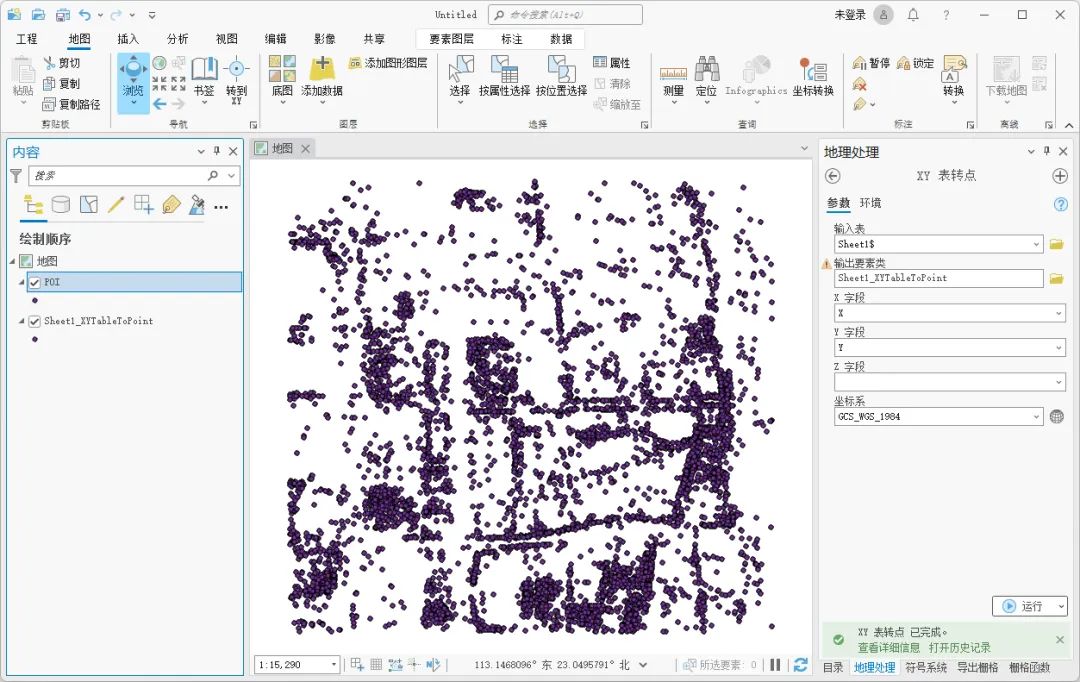
如何使用ArcGIS Pro将Excel表转换为SHP文件
有的时候我们得到的数据是一张张的Excel表格,如果想要在ArcGIS Pro中进行分析或者制图则需要先转换为SHP格式,这里为大家介绍一下转换方法,希望能对你有所帮助。 数据来源 本教程所使用的数据是从水经微图中下载的POI数据,除了P…...
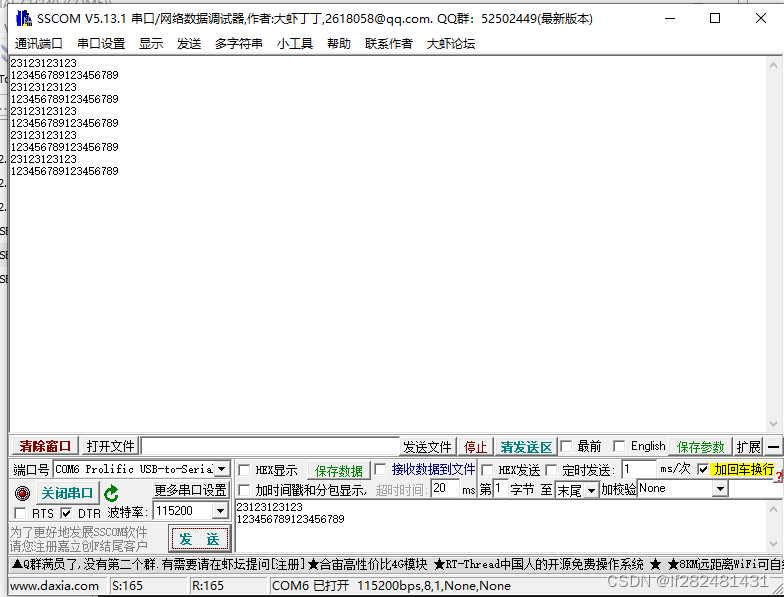
11.1Linux串口应用程序开发
UART简介 UART的全称是Universal Asynchronous Receiver and Transmitter,即异步发送和接收。 串口在嵌入式中用途非常的广泛,主要的用途有: 打印调试信息;外接各种模块:GPS、蓝牙; 串口因为结构简单、稳…...

log4j学习
依赖 <!--log4j依赖--> <dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>1.2.17</version> </dependency><!--测试--> <dependency><groupId>org.junit.jupiter</g…...

【Vue2+3入门到实战】(4)Vue基础之指令修饰符 、v-bind对样式增强的操作、v-model应用于其他表单元素 详细示例
目录 一、今日学习目标1.指令补充 二、指令修饰符1.什么是指令修饰符?2.按键修饰符3.v-model修饰符4.事件修饰符 三、v-bind对样式控制的增强-操作class1.语法:2.对象语法3.数组语法4.代码练习 四、京东秒杀-tab栏切换导航高亮1.需求:2.准备代…...
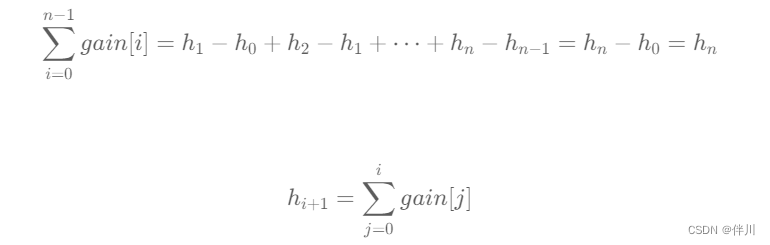
【数据结构和算法】找到最高海拔
其他系列文章导航 Java基础合集数据结构与算法合集 设计模式合集 多线程合集 分布式合集 ES合集 文章目录 其他系列文章导航 文章目录 前言 一、题目描述 二、题解 2.1 前缀和的解题模板 2.1.1 最长递增子序列长度 2.1.2 寻找数组中第 k 大的元素 2.1.3 最长公共子序列…...

redis相关问题
1、概述: 1. 非关系型数据库 2. 是分布式缓存数据库 3. 使用 key -value结构存储 2、作用: 用作缓存降低数据库压力,提高性能;可以用作消息队列(削峰、解耦、异步调用) 3、基础语法: 基础命令…...

第41节: Vue3 watch函数
在UniApp中使用Vue3框架时,你可以使用watch函数来观察和响应Vue实例上的数据变化。以下是一个示例,演示了如何在UniApp中使用Vue3框架使用watch函数: <template> <view> <input v-model"message" type"text…...

Centos7:升级gcc、g++到版本5.2.0
背景 Centos7.9版本默认的g版本是4.8.5,在实践golang项目中,用到C14,编译时会报错:gcc: error: unrecognized command line option ‘-stdc14’ 因此,gcc需要升级到更高版本,我这里使用源码编译形式升级到g…...

Pytohn data mode plt
文章目录 文件的读写创建.csv类型的文件,并读取文件创建.xlsx文件 使用Python做图生成数据集切片取值操作修改张量中指定位置的数据 知识点torch.arange(x)torch.tensor(2)Atorch.randn(36).reshape(6,6)shapenumel()reshape(x,y,z)torch.zeros(3,3,4)torch.ones(2,…...

内网离线搭建之----kafka集群
1.系统版本 虚拟机192.168.9.184 虚拟机192.168.9.185 虚拟机192.168.9.186系统 centos7 7.6.1810 2.依赖下载 ps:置顶资源里已经下载好了,直接用!!!!!!!!…...
)
5.1 显示窗口的内容(一)
一,如何显示窗口的内容? 显示器用于在物理硬件(如计算机显示器或触摸屏显示器)上显示窗口的内容。 屏幕API提供的功能允许我们创建同时写入多个窗口和显示的应用程序。屏幕支持多个显示器,但创建和管理使用多个显示器…...
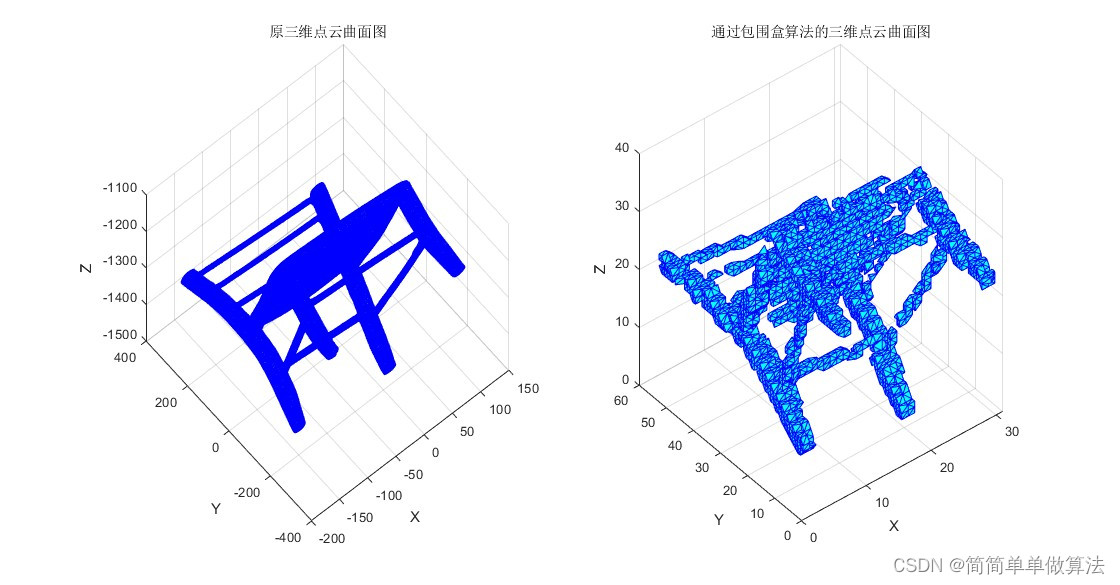
基于包围盒算法的三维点云数据压缩和曲面重建matlab仿真
目录 1.算法运行效果图预览 2.算法运行软件版本 3.部分核心程序 4.算法理论概述 4.1 包围盒构建 4.2 点云压缩 4.3 曲面重建 5.算法完整程序工程 1.算法运行效果图预览 2.算法运行软件版本 matlab2022a 3.部分核心程序 ...........................................…...
关于Python里xlwings库对Excel表格的操作(十八)
这篇小笔记主要记录如何【设置单元格数据的对齐方式】。前面的小笔记已整理成目录,可点链接去目录寻找所需更方便。 【目录部分内容如下】【点击此处可进入目录】 (1)如何安装导入xlwings库; (2)如何在Wps下…...
VScode远程连接服务器,Pycharm专业版下载及远程连接(深度学习远程篇)
Visual Code、PyCharm专业版,本地和远程交互。 远程连接需要用到SSH协议的技术,常用的代码编辑器vscode 和 pycharm都有此类功能。社区版的pycharm是免费的,但是社区版不支持ssh连接服务器,只有专业版才可以,需要破解…...
------$bus)
Vue2和Vue3组件间通信方式汇总(3)------$bus
组件间通信方式是前端必不可少的知识点,前端开发经常会遇到组件间通信的情况,而且也是前端开发面试常问的知识点之一。接下来开始组件间通信方式第三弹------$bus,并讲讲分别在Vue2、Vue3中的表现。 Vue2Vue3组件间通信方式汇总(1)…...
PyTorch加载数据以及Tensorboard的使用
一、PyTorch加载数据初认识 Dataset:提供一种方式去获取数据及其label 如何获取每一个数据及其label 总共有多少的数据 Dataloader:为后面的网络提供不同的数据形式 数据集 在编译器中导入Dataset from torch.utils.data import Dataset 可以在jupyter中查看Dataset官方文档&…...

TensorFlow是什么
TensorFlow是什么 Tensorflow是一个Google开发的第二代机器学习系统,克服了第一代系统DistBelief仅能开发神经网络算法、难以配置、依赖Google内部硬件等局限性,应用更加广泛,并且提高了灵活性和可移植性,速度和扩展性也有了大幅…...
docker-compose 安装Sonar并集成gitlab
文章目录 1. 前置条件2. 编写docker-compose-sonar.yml文件3. 集成 gitlab4. Sonar Login with GitLab 1. 前置条件 安装docker-compose 安装docker 创建容器运行的特有网络 创建挂载目录 2. 编写docker-compose-sonar.yml文件 version: "3" services:sonar-postgre…...

Appium+python自动化(十六)- ADB命令
简介 Android 调试桥(adb)是多种用途的工具,该工具可以帮助你你管理设备或模拟器 的状态。 adb ( Android Debug Bridge)是一个通用命令行工具,其允许您与模拟器实例或连接的 Android 设备进行通信。它可为各种设备操作提供便利,如安装和调试…...

从WWDC看苹果产品发展的规律
WWDC 是苹果公司一年一度面向全球开发者的盛会,其主题演讲展现了苹果在产品设计、技术路线、用户体验和生态系统构建上的核心理念与演进脉络。我们借助 ChatGPT Deep Research 工具,对过去十年 WWDC 主题演讲内容进行了系统化分析,形成了这份…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...

ETLCloud可能遇到的问题有哪些?常见坑位解析
数据集成平台ETLCloud,主要用于支持数据的抽取(Extract)、转换(Transform)和加载(Load)过程。提供了一个简洁直观的界面,以便用户可以在不同的数据源之间轻松地进行数据迁移和转换。…...

新能源汽车智慧充电桩管理方案:新能源充电桩散热问题及消防安全监管方案
随着新能源汽车的快速普及,充电桩作为核心配套设施,其安全性与可靠性备受关注。然而,在高温、高负荷运行环境下,充电桩的散热问题与消防安全隐患日益凸显,成为制约行业发展的关键瓶颈。 如何通过智慧化管理手段优化散…...

工业自动化时代的精准装配革新:迁移科技3D视觉系统如何重塑机器人定位装配
AI3D视觉的工业赋能者 迁移科技成立于2017年,作为行业领先的3D工业相机及视觉系统供应商,累计完成数亿元融资。其核心技术覆盖硬件设计、算法优化及软件集成,通过稳定、易用、高回报的AI3D视觉系统,为汽车、新能源、金属制造等行…...

项目部署到Linux上时遇到的错误(Redis,MySQL,无法正确连接,地址占用问题)
Redis无法正确连接 在运行jar包时出现了这样的错误 查询得知问题核心在于Redis连接失败,具体原因是客户端发送了密码认证请求,但Redis服务器未设置密码 1.为Redis设置密码(匹配客户端配置) 步骤: 1).修…...

【网络安全】开源系统getshell漏洞挖掘
审计过程: 在入口文件admin/index.php中: 用户可以通过m,c,a等参数控制加载的文件和方法,在app/system/entrance.php中存在重点代码: 当M_TYPE system并且M_MODULE include时,会设置常量PATH_OWN_FILE为PATH_APP.M_T…...

怎么让Comfyui导出的图像不包含工作流信息,
为了数据安全,让Comfyui导出的图像不包含工作流信息,导出的图像就不会拖到comfyui中加载出来工作流。 ComfyUI的目录下node.py 直接移除 pnginfo(推荐) 在 save_images 方法中,删除或注释掉所有与 metadata …...

ubuntu系统文件误删(/lib/x86_64-linux-gnu/libc.so.6)修复方案 [成功解决]
报错信息:libc.so.6: cannot open shared object file: No such file or directory: #ls, ln, sudo...命令都不能用 error while loading shared libraries: libc.so.6: cannot open shared object file: No such file or directory重启后报错信息&…...