案例系列:Movielens_预测用户对电影的评分_基于行为序列Transformer的推荐系统
文章目录
- 简介
- 数据集
- 设置
- 准备数据
- 下载并准备数据框
- 将电影评分数据转换为序列
- 定义元数据
- 为训练和评估创建 `tf.data.Dataset`
- 创建模型输入
- 编码输入特征
- 创建一个二叉搜索树模型
- 运行训练和评估实验
- 结论
描述: 使用行为序列Transformer(BST)模型在Movielens上进行评分预测。
简介
本示例演示了由Qiwei Chen等人使用Movielens数据集使用行为序列转换器(BST)模型。BST模型利用用户在观看和评分电影时的顺序行为,以及用户配置文件和电影特征,来预测用户对目标电影的评分。
更具体地说,BST模型旨在通过接受以下输入来预测目标电影的评分:
- 用户观看的电影的固定长度的序列,其中包含
movie_ids。 - 用户观看的电影的固定长度的序列,其中包含电影的
ratings。 - 用户特征的集合,包括
user_id、sex、occupation和age_group。 - 输入序列和目标电影中每个电影的
genres的集合。 - 要预测评分的
target_movie_id。
本示例对原始BST模型进行了以下修改:
- 我们将电影特征(genres)合并到每个输入序列和目标电影的嵌入处理中,而不是将它们视为转换器层外的“其他特征”。
- 我们利用输入序列中电影的评分以及它们在序列中的位置,在将它们馈送到自注意力层之前对它们进行更新。
请注意,此示例应在TensorFlow 2.4或更高版本上运行。
数据集
我们使用Movielens数据集的1M版本。
该数据集包括来自6000个用户对4000部电影的大约100万个评分,
还包括一些用户特征和电影类型。此外,还提供了每个用户-电影评分的时间戳,
这允许为每个用户创建电影评分序列,正如BST模型所期望的那样。
设置
# 导入所需的库
import os # 用于操作系统相关的功能
os.environ["KERAS_BACKEND"] = "tensorflow" # 设置环境变量,指定使用tensorflow作为Keras的后端import math # 用于数学计算
from zipfile import ZipFile # 用于解压缩zip文件
from urllib.request import urlretrieve # 用于从URL下载文件import keras # Keras库,用于构建深度学习模型
import numpy as np # 用于处理数值数组和矩阵
import pandas as pd # 用于处理数据表格
import tensorflow as tf # TensorFlow库,用于构建和训练机器学习模型
from keras import layers # Keras库中的层模块
from keras.layers import StringLookup # Keras库中的字符串查找层模块
准备数据
下载并准备数据框
首先,让我们下载movielens数据。
下载的文件夹将包含三个数据文件:users.dat,movies.dat和ratings.dat。
# 导入必要的库
from urllib.request import urlretrieve
from zipfile import ZipFile# 下载movielens数据集的zip文件
urlretrieve("http://files.grouplens.org/datasets/movielens/ml-1m.zip", "movielens.zip")# 创建一个ZipFile对象,用于解压缩zip文件
zip_file = ZipFile("movielens.zip", "r")# 解压缩zip文件中的所有内容到当前目录
zip_file.extractall()
然后,我们使用正确的列名将数据加载到pandas DataFrames中。
# 导入所需的库
import pandas as pd# 读取用户数据
users = pd.read_csv("ml-1m/users.dat", # 用户数据文件路径sep="::", # 分隔符为双冒号names=["user_id", "sex", "age_group", "occupation", "zip_code"], # 列名encoding="ISO-8859-1", # 使用ISO-8859-1编码engine="python", # 使用Python解析引擎
)# 读取评分数据
ratings = pd.read_csv("ml-1m/ratings.dat", # 评分数据文件路径sep="::", # 分隔符为双冒号names=["user_id", "movie_id", "rating", "unix_timestamp"], # 列名encoding="ISO-8859-1", # 使用ISO-8859-1编码engine="python", # 使用Python解析引擎
)# 读取电影数据
movies = pd.read_csv("ml-1m/movies.dat", # 电影数据文件路径sep="::", # 分隔符为双冒号names=["movie_id", "title", "genres"], # 列名encoding="ISO-8859-1", # 使用ISO-8859-1编码engine="python", # 使用Python解析引擎
)
在这里,我们对列的数据类型进行一些简单的数据处理,以修复数据类型。
# 给用户数据添加user_id前缀
users["user_id"] = users["user_id"].apply(lambda x: f"user_{x}")# 给用户数据添加age_group前缀
users["age_group"] = users["age_group"].apply(lambda x: f"group_{x}")# 给用户数据添加occupation前缀
users["occupation"] = users["occupation"].apply(lambda x: f"occupation_{x}")# 给电影数据添加movie_id前缀
movies["movie_id"] = movies["movie_id"].apply(lambda x: f"movie_{x}")# 给评分数据添加movie_id前缀
ratings["movie_id"] = ratings["movie_id"].apply(lambda x: f"movie_{x}")# 给评分数据添加user_id前缀
ratings["user_id"] = ratings["user_id"].apply(lambda x: f"user_{x}")# 将评分数据中的rating转换为浮点型
ratings["rating"] = ratings["rating"].apply(lambda x: float(x))
每部电影都有多个类型。我们在movies数据框中将它们拆分为单独的列。
# 定义电影类型列表
genres = ["Action", "Adventure", "Animation", "Children's", "Comedy", "Crime"]
genres += ["Documentary", "Drama", "Fantasy", "Film-Noir", "Horror", "Musical"]
genres += ["Mystery", "Romance", "Sci-Fi", "Thriller", "War", "Western"]# 遍历电影类型列表
for genre in genres:# 对于每个电影类型,将movies["genres"]中的每个电影的类型字符串进行处理# 使用lambda函数将字符串转换为对应的二进制值(1表示包含该类型,0表示不包含该类型)movies[genre] = movies["genres"].apply(lambda values: int(genre in values.split("|")))
将电影评分数据转换为序列
首先,让我们使用unix_timestamp对评分数据进行排序,然后按user_id对movie_id值和rating值进行分组。
输出的DataFrame将为每个user_id记录两个有序列表(按评分日期排序):他们评价过的电影和他们对这些电影的评分。
# 导入必要的库
import pandas as pd# 按照"unix_timestamp"列对"ratings"数据集进行排序,并按"user_id"分组
ratings_group = ratings.sort_values(by=["unix_timestamp"]).groupby("user_id")# 创建一个新的数据框ratings_data,包含以下列:user_id, movie_ids, ratings, timestamps
ratings_data = pd.DataFrame(data={"user_id": list(ratings_group.groups.keys()), # 获取分组后的用户ID"movie_ids": list(ratings_group.movie_id.apply(list)), # 获取每个用户对应的电影ID列表"ratings": list(ratings_group.rating.apply(list)), # 获取每个用户对应的评分列表"timestamps": list(ratings_group.unix_timestamp.apply(list)), # 获取每个用户对应的时间戳列表}
)
现在,让我们将movie_ids列表分割成一组固定长度的序列。
我们对ratings也做同样的操作。设置sequence_length变量来改变输入序列的长度。
您还可以更改step_size来控制为每个用户生成的序列数量。
# 定义窗口大小和步长
sequence_length = 4
step_size = 2# 创建序列函数,输入值、窗口大小和步长,返回序列列表
def create_sequences(values, window_size, step_size):sequences = [] # 存储序列的列表start_index = 0 # 起始索引while True:end_index = start_index + window_size # 结束索引seq = values[start_index:end_index] # 根据窗口大小切片得到序列if len(seq) < window_size: # 如果序列长度小于窗口大小seq = values[-window_size:] # 则取最后窗口大小长度的序列if len(seq) == window_size: # 如果序列长度等于窗口大小sequences.append(seq) # 将序列添加到列表中break # 结束循环sequences.append(seq) # 将序列添加到列表中start_index += step_size # 更新起始索引return sequences # 返回序列列表# 对电影ID列应用create_sequences函数,将结果赋值给movie_ids列
ratings_data.movie_ids = ratings_data.movie_ids.apply(lambda ids: create_sequences(ids, sequence_length, step_size)
)# 对评分列应用create_sequences函数,将结果赋值给ratings列
ratings_data.ratings = ratings_data.ratings.apply(lambda ids: create_sequences(ids, sequence_length, step_size)
)# 删除timestamps列
del ratings_data["timestamps"]
之后,我们处理输出,使每个序列在DataFrame中成为单独的记录。此外,我们将用户特征与评分数据进行连接。
# 导入所需的库
import pandas as pd# 将ratings_data中的"movie_ids"列拆分成多行,每行只包含一个电影ID,并重置索引
ratings_data_movies = ratings_data[["user_id", "movie_ids"]].explode("movie_ids", ignore_index=True)# 将ratings_data中的"ratings"列拆分成多行,每行只包含一个评分,并重置索引
ratings_data_rating = ratings_data[["ratings"]].explode("ratings", ignore_index=True)# 将拆分后的"movie_ids"和"ratings"两列合并为一个DataFrame
ratings_data_transformed = pd.concat([ratings_data_movies, ratings_data_rating], axis=1)# 根据"user_id"列将ratings_data_transformed与users进行连接
ratings_data_transformed = ratings_data_transformed.join(users.set_index("user_id"), on="user_id")# 将"movie_ids"列中的每个元素转换为字符串,并用逗号分隔
ratings_data_transformed.movie_ids = ratings_data_transformed.movie_ids.apply(lambda x: ",".join(x))# 将"ratings"列中的每个元素转换为字符串,并用逗号分隔
ratings_data_transformed.ratings = ratings_data_transformed.ratings.apply(lambda x: ",".join([str(v) for v in x]))# 删除ratings_data_transformed中的"zip_code"列
del ratings_data_transformed["zip_code"]# 将列名"movie_ids"改为"sequence_movie_ids",将列名"ratings"改为"sequence_ratings"
ratings_data_transformed.rename(columns={"movie_ids": "sequence_movie_ids", "ratings": "sequence_ratings"}, inplace=True)
使用sequence_length为4和step_size为2,我们最终得到498,623个序列。
最后,我们将数据分割为训练集和测试集,分别占总数据的85%和15%,并将它们存储为CSV文件。
import numpy as np# 生成一个与ratings_data_transformed.index长度相同的随机数数组,每个元素都是0到1之间的随机数
random_selection = np.random.rand(len(ratings_data_transformed.index)) <= 0.85# 根据随机数数组,选择85%的数据作为训练数据
train_data = ratings_data_transformed[random_selection]# 根据随机数数组,选择15%的数据作为测试数据
test_data = ratings_data_transformed[~random_selection]# 将训练数据保存为CSV文件,不包含索引列,使用竖线作为分隔符,不包含表头
train_data.to_csv("train_data.csv", index=False, sep="|", header=False)# 将测试数据保存为CSV文件,不包含索引列,使用竖线作为分隔符,不包含表头
test_data.to_csv("test_data.csv", index=False, sep="|", header=False)
定义元数据
# 定义CSV_HEADER为ratings_data_transformed的列名列表
CSV_HEADER = list(ratings_data_transformed.columns)# 定义CATEGORICAL_FEATURES_WITH_VOCABULARY为一个字典,包含了几个特征及其对应的唯一值列表
CATEGORICAL_FEATURES_WITH_VOCABULARY = {"user_id": list(users.user_id.unique()), # 用户ID特征对应的唯一值列表"movie_id": list(movies.movie_id.unique()), # 电影ID特征对应的唯一值列表"sex": list(users.sex.unique()), # 性别特征对应的唯一值列表"age_group": list(users.age_group.unique()), # 年龄组特征对应的唯一值列表"occupation": list(users.occupation.unique()), # 职业特征对应的唯一值列表
}# 定义USER_FEATURES为一个列表,包含了用户特征
USER_FEATURES = ["sex", "age_group", "occupation"]# 定义MOVIE_FEATURES为一个列表,包含了电影特征
MOVIE_FEATURES = ["genres"]
为训练和评估创建 tf.data.Dataset
# 定义一个函数get_dataset_from_csv,用于从csv文件中获取数据集
# 参数:
# - csv_file_path:csv文件的路径
# - shuffle:是否对数据进行洗牌,默认为False
# - batch_size:批处理的大小,默认为128def get_dataset_from_csv(csv_file_path, shuffle=False, batch_size=128):# 定义一个内部函数process,用于处理特征# 参数:# - features:特征数据def process(features):# 从特征中获取电影ID序列的字符串movie_ids_string = features["sequence_movie_ids"]# 将电影ID序列字符串按逗号分割,并转换为张量sequence_movie_ids = tf.strings.split(movie_ids_string, ",").to_tensor()# 序列中的最后一个电影ID是目标电影features["target_movie_id"] = sequence_movie_ids[:, -1]# 将特征中的电影ID序列更新为除了最后一个电影ID之外的序列features["sequence_movie_ids"] = sequence_movie_ids[:, :-1]# 从特征中获取评分序列的字符串ratings_string = features["sequence_ratings"]# 将评分序列字符串按逗号分割,并转换为浮点数类型的张量sequence_ratings = tf.strings.to_number(tf.strings.split(ratings_string, ","), tf.dtypes.float32).to_tensor()# 序列中的最后一个评分是模型要预测的目标target = sequence_ratings[:, -1]# 将特征中的评分序列更新为除了最后一个评分之外的序列features["sequence_ratings"] = sequence_ratings[:, :-1]return features, target# 使用tf.data.experimental.make_csv_dataset函数从csv文件中创建数据集dataset = tf.data.experimental.make_csv_dataset(csv_file_path,batch_size=batch_size,column_names=CSV_HEADER,num_epochs=1,header=False,field_delim="|",shuffle=shuffle,).map(process)return dataset
创建模型输入
# 定义一个函数create_model_inputs,用于创建模型的输入def create_model_inputs():# 返回一个字典,包含模型的输入return {"user_id": keras.Input(name="user_id", shape=(1,), dtype="string"), # 用户ID,输入形状为(1,),数据类型为字符串"sequence_movie_ids": keras.Input(name="sequence_movie_ids", shape=(sequence_length - 1,), dtype="string"), # 电影序列ID,输入形状为(sequence_length - 1,),数据类型为字符串"target_movie_id": keras.Input(name="target_movie_id", shape=(1,), dtype="string"), # 目标电影ID,输入形状为(1,),数据类型为字符串"sequence_ratings": keras.Input(name="sequence_ratings", shape=(sequence_length - 1,), dtype=tf.float32), # 电影评分序列,输入形状为(sequence_length - 1,),数据类型为浮点数"sex": keras.Input(name="sex", shape=(1,), dtype="string"), # 性别,输入形状为(1,),数据类型为字符串"age_group": keras.Input(name="age_group", shape=(1,), dtype="string"), # 年龄组,输入形状为(1,),数据类型为字符串"occupation": keras.Input(name="occupation", shape=(1,), dtype="string"), # 职业,输入形状为(1,),数据类型为字符串}
编码输入特征
encode_input_features 方法的工作原理如下:
-
使用
layers.Embedding对每个分类用户特征进行编码,其中嵌入维度等于特征的词汇量的平方根。
这些特征的嵌入被连接起来形成一个单一的输入张量。 -
使用
layers.Embedding对电影序列中的每个电影和目标电影进行编码,其中维度大小为电影数量的平方根。 -
对每个电影的多热流派向量与其嵌入向量进行连接,并使用非线性
layers.Dense处理,输出相同电影嵌入维度的向量。 -
在序列中的每个电影嵌入中添加位置嵌入,然后乘以其来自评分序列的评分。
-
将目标电影嵌入连接到序列电影嵌入中,生成一个形状为
[batch size, sequence length, embedding size]的张量,符合变压器架构的注意力层的预期形状。 -
该方法返回一个由两个元素组成的元组:
encoded_transformer_features和encoded_other_features。
# 编码输入特征## 定义函数encode_input_features,用于将输入特征进行编码
### 参数:
- inputs:包含输入特征的字典
- include_user_id:是否包含用户ID,默认为True
- include_user_features:是否包含用户特征,默认为True
- include_movie_features:是否包含电影特征,默认为True### 返回值:
- encoded_transformer_features:编码后的转换器特征
- encoded_other_features:编码后的其他特征## 初始化编码后的转换器特征列表和其他特征列表
encoded_transformer_features = []
encoded_other_features = []## 初始化其他特征名称列表
other_feature_names = []## 如果include_user_id为True,则将"user_id"添加到其他特征名称列表中
if include_user_id:other_feature_names.append("user_id")## 如果include_user_features为True,则将USER_FEATURES中的特征名称添加到其他特征名称列表中
if include_user_features:other_feature_names.extend(USER_FEATURES)## 对用户特征进行编码
for feature_name in other_feature_names:# 将字符串输入值转换为整数索引vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY[feature_name]idx = StringLookup(vocabulary=vocabulary, mask_token=None, num_oov_indices=0)(inputs[feature_name])# 计算嵌入维度embedding_dims = int(math.sqrt(len(vocabulary)))# 创建指定维度的嵌入层embedding_encoder = layers.Embedding(input_dim=len(vocabulary),output_dim=embedding_dims,name=f"{feature_name}_embedding",)# 将索引值转换为嵌入表示encoded_other_features.append(embedding_encoder(idx))## 创建用户特征的单个嵌入向量
if len(encoded_other_features) > 1:encoded_other_features = layers.concatenate(encoded_other_features)
elif len(encoded_other_features) == 1:encoded_other_features = encoded_other_features[0]
else:encoded_other_features = None## 创建电影嵌入编码器
movie_vocabulary = CATEGORICAL_FEATURES_WITH_VOCABULARY["movie_id"]
movie_embedding_dims = int(math.sqrt(len(movie_vocabulary)))
# 创建查找表,将字符串值转换为整数索引
movie_index_lookup = StringLookup(vocabulary=movie_vocabulary,mask_token=None,num_oov_indices=0,name="movie_index_lookup",
)
# 创建指定维度的嵌入层
movie_embedding_encoder = layers.Embedding(input_dim=len(movie_vocabulary),output_dim=movie_embedding_dims,name=f"movie_embedding",
)
# 创建电影类型的向量查找表
genre_vectors = movies[genres].to_numpy()
movie_genres_lookup = layers.Embedding(input_dim=genre_vectors.shape[0],output_dim=genre_vectors.shape[1],embeddings_initializer=keras.initializers.Constant(genre_vectors),trainable=False,name="genres_vector",
)
# 创建电影类型的处理层
movie_embedding_processor = layers.Dense(units=movie_embedding_dims,activation="relu",name="process_movie_embedding_with_genres",
)## 定义一个函数,用于编码给定的电影ID
def encode_movie(movie_id):# 将字符串输入值转换为整数索引movie_idx = movie_index_lookup(movie_id)movie_embedding = movie_embedding_encoder(movie_idx)encoded_movie = movie_embeddingif include_movie_features:movie_genres_vector = movie_genres_lookup(movie_idx)encoded_movie = movie_embedding_processor(layers.concatenate([movie_embedding, movie_genres_vector]))return encoded_movie## 编码目标电影ID
target_movie_id = inputs["target_movie_id"]
encoded_target_movie = encode_movie(target_movie_id)## 编码序列电影ID
sequence_movies_ids = inputs["sequence_movie_ids"]
encoded_sequence_movies = encode_movie(sequence_movies_ids)
# 创建位置嵌入
position_embedding_encoder = layers.Embedding(input_dim=sequence_length,output_dim=movie_embedding_dims,name="position_embedding",
)
positions = tf.range(start=0, limit=sequence_length - 1, delta=1)
encodded_positions = position_embedding_encoder(positions)
# 获取序列评分,将其合并到电影编码中
sequence_ratings = inputs["sequence_ratings"]
sequence_ratings = keras.ops.expand_dims(sequence_ratings, -1)
# 将位置编码添加到电影编码中,并乘以评分
encoded_sequence_movies_with_poistion_and_rating = layers.Multiply()([(encoded_sequence_movies + encodded_positions), sequence_ratings]
)# 构建转换器的输入
for i in range(sequence_length - 1):feature = encoded_sequence_movies_with_poistion_and_rating[:, i, ...]feature = keras.ops.expand_dims(feature, 1)encoded_transformer_features.append(feature)
encoded_transformer_features.append(encoded_target_movie)encoded_transformer_features = layers.concatenate(encoded_transformer_features, axis=1
)return encoded_transformer_features, encoded_other_features
创建一个二叉搜索树模型
# 创建模型## 设置参数include_user_id = False # 是否包含用户ID特征
include_user_features = False # 是否包含用户特征
include_movie_features = False # 是否包含电影特征hidden_units = [256, 128] # 隐藏层单元数
dropout_rate = 0.1 # Dropout比例
num_heads = 3 # 多头注意力机制的头数## 创建模型函数def create_model():inputs = create_model_inputs() # 创建模型输入transformer_features, other_features = encode_input_features(inputs, include_user_id, include_user_features, include_movie_features) # 编码输入特征# 创建多头注意力层attention_output = layers.MultiHeadAttention(num_heads=num_heads, key_dim=transformer_features.shape[2], dropout=dropout_rate)(transformer_features, transformer_features)# Transformer块attention_output = layers.Dropout(dropout_rate)(attention_output)x1 = layers.Add()([transformer_features, attention_output])x1 = layers.LayerNormalization()(x1)x2 = layers.LeakyReLU()(x1)x2 = layers.Dense(units=x2.shape[-1])(x2)x2 = layers.Dropout(dropout_rate)(x2)transformer_features = layers.Add()([x1, x2])transformer_features = layers.LayerNormalization()(transformer_features)features = layers.Flatten()(transformer_features)# 添加其他特征if other_features is not None:features = layers.concatenate([features, layers.Reshape([other_features.shape[-1]])(other_features)])# 全连接层for num_units in hidden_units:features = layers.Dense(num_units)(features)features = layers.BatchNormalization()(features)features = layers.LeakyReLU()(features)features = layers.Dropout(dropout_rate)(features)outputs = layers.Dense(units=1)(features) # 输出层model = keras.Model(inputs=inputs, outputs=outputs) # 创建模型return modelmodel = create_model() # 创建模型
运行训练和评估实验
# 编译模型
model.compile(optimizer=keras.optimizers.Adagrad(learning_rate=0.01), # 使用Adagrad优化器,学习率为0.01loss=keras.losses.MeanSquaredError(), # 使用均方误差作为损失函数metrics=[keras.metrics.MeanAbsoluteError()], # 使用平均绝对误差作为评估指标
)# 读取训练数据
train_dataset = get_dataset_from_csv("train_data.csv", shuffle=True, batch_size=265)# 使用训练数据拟合模型
model.fit(train_dataset, epochs=5)# 读取测试数据
test_dataset = get_dataset_from_csv("test_data.csv", batch_size=265)# 在测试数据上评估模型
_, rmse = model.evaluate(test_dataset, verbose=0)
print(f"Test MAE: {round(rmse, 3)}") # 打印测试数据上的平均绝对误差
你应该在测试数据上达到或接近0.7的平均绝对误差(MAE)。
结论
BST模型在其架构中使用Transformer层来捕捉推荐中用户行为序列的顺序信号。
您可以尝试使用不同的配置来训练该模型,例如增加输入序列长度并将模型训练更多个周期。此外,您还可以尝试包括其他特征,如电影发布年份和客户邮编,以及包括性别X类型等交叉特征。
相关文章:
案例系列:Movielens_预测用户对电影的评分_基于行为序列Transformer的推荐系统
文章目录 简介数据集设置准备数据下载并准备数据框将电影评分数据转换为序列 定义元数据为训练和评估创建 tf.data.Dataset创建模型输入编码输入特征创建一个二叉搜索树模型运行训练和评估实验结论 描述: 使用行为序列Transformer(BST)模型在…...
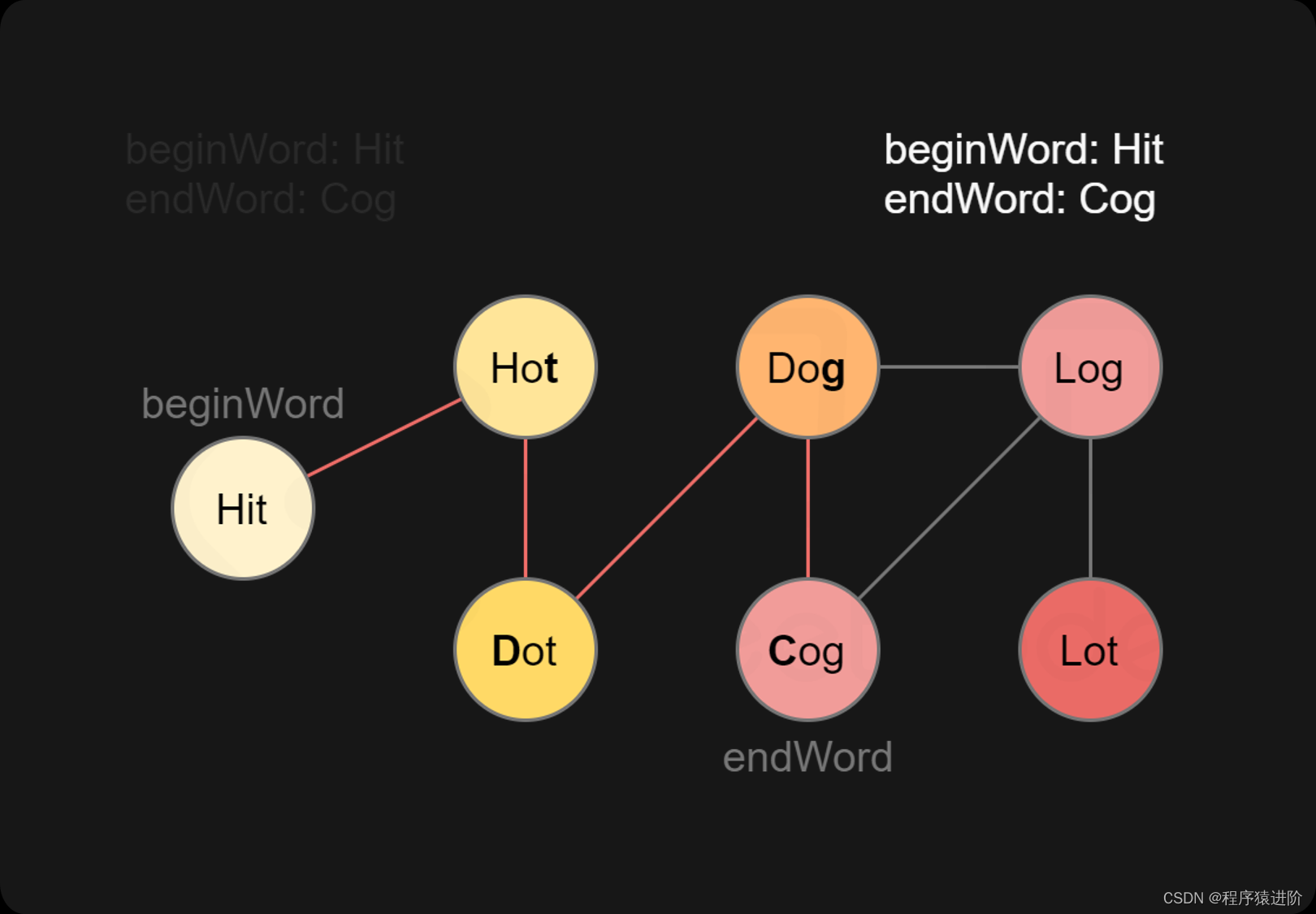
单词接龙[中等]
一、题目 字典wordList中从单词beginWord和endWord的 转换序列 是一个按下述规格形成的序列beginWord -> s1 -> s2 -> ... -> sk: 1、每一对相邻的单词只差一个字母。 2、对于1 < i < k时,每个si都在wordList中。注意,beg…...
机器人制作开源方案 | 森林管理员
作者:李佳骏、常睿康、张智斌、李世斌、高华耸 单位:山西能源学院 指导老师:赵浩成、郜敏 1. 研究背景 森林作为地球上可再生自然资源及陆地生态的主体,在人类生存和发展的历史中起着不可代替的作用,它不仅能提供…...
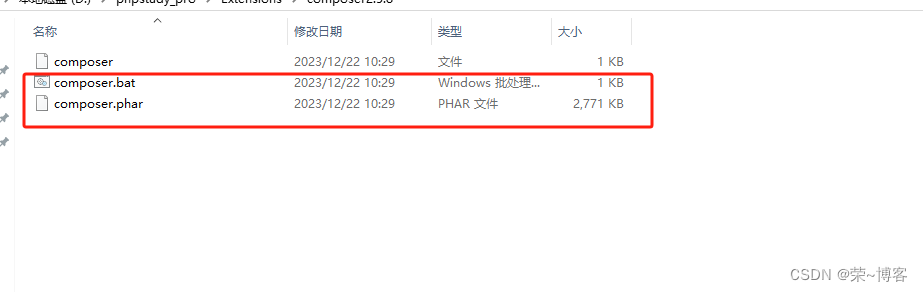
Laravel框架使用phpstudy本地安装的composer用Laravel 安装器进行安装搭建
一、首先需要安装Laravel 安装器 composer global require laravel/installer 二、安装器安装好后,可以使用如下命令创建项目 laravel new sys 三、本地运行 php artisan serve 四、 使用Composer快速安装Laravel5.8框架 安装指定版本的最新版本(推荐&a…...

炫酷登录注册界面【超级简单 jQuery+JS+HTML+CSS实现】
一:源码获取 这两天根据需求写了一个比较好看的有动态效果的登录注册切换页面,这里我将源码资源分享给大家,大家可以直接免费下载使用哦,没有 vip 的小伙伴找我私聊发送"登录注册"即可我给你发文件,此登录注…...

2023年国赛高教杯数学建模E题黄河水沙监测数据分析解题全过程文档及程序
2023年国赛高教杯数学建模 E题 黄河水沙监测数据分析 原题再现 黄河是中华民族的母亲河。研究黄河水沙通量的变化规律对沿黄流域的环境治理、气候变化和人民生活的影响,以及对优化黄河流域水资源分配、协调人地关系、调水调沙、防洪减灾等方面都具有重要的理论指导…...

跨国企业传输大文件注意事项和解决方案
随着全球化的推进,越来越多的企业需要在跨国业务合作、项目交付、数据分析等方面展开合作,这就带来了大量大文件的传输需求。大文件传输是指文件大小超过1GB的传输,通常涉及视频、音频、图片、文档、压缩包等多种格式。跨国传输大文件不仅需要…...

【Redis】Redis 的数据类型
有五种常用数据类型:String、Hash、Set、List、SortedSet。以及三种特殊的数据类型:Bitmap、HyperLogLog、Geospatial ,其中HyperLogLog、Bitmap的底层都是 String 数据类型,Geospatial 的底层是 Sorted Set 数据类型。 五种常用…...
QT小技巧 - 使用QMovie进行gif切帧
简介 使用QMovie 将 gif 进行切帧, magick 进行合并代码 QString gifPath "E:\\workspace\\qt\\gif2imgs\\203526qre64haq3ccoobqi.gif"; // 你的图片QMovie movie(gifPath); movie.setCacheMode(QMovie::CacheNone);qDebug() << movie.frameCou…...
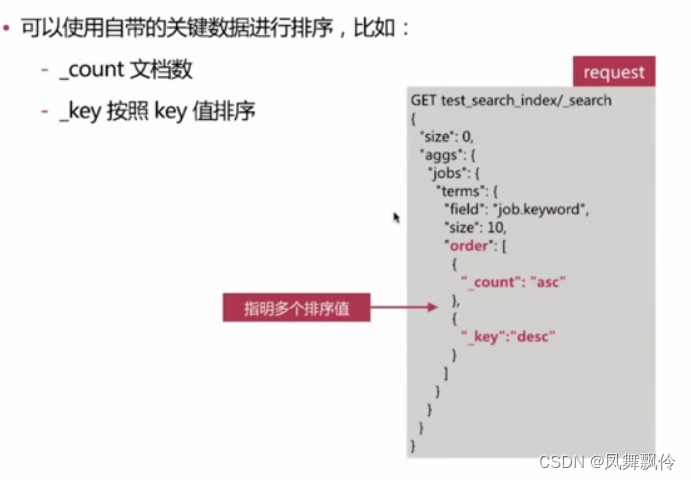
ES-搜索
聚合分析 聚合分析,英文为Aggregation,是es 除搜索功能外提供的针对es 数据做统计分析的功能 - 功能丰富,提供Bucket、Metric、Pipeline等多种分析方式,可以满足大部分的分析需求 实时性高,所有的计算结果都是即时返回…...

微信小程序面试题
微信小程序面试题 请解释微信小程序的生命周期及其对应的钩子函数。 微信小程序的生命周期包括 onLaunch、onShow、onHide、onError、onPageNotFound 等阶段。对应的钩子函数分别是: onLaunch:小程序初始化时触发。onShow:小程序启动或从后台…...

OpenCV之图像匹配与定位
利用图像特征的keypoints和descriptor来实现图像的匹配与定位。图像匹配算法主要有暴力匹配和FLANN匹配,而图像定位是通过图像匹配结果来反向查询它们在目标图片中的具体坐标位置。 以QQ登录界面为例,将整个QQ登录界面保存为QQ.png文件,QQ登…...
掌握JWT:解密身份验证和授权的关键技术
JSON Web Token 1、什么是JWT2、JWT解决了什么问题3、早期的SSO认证4、JWT认证5、JWT优势6、JWT结构Header 标头Payload 负载 Signature 签名 7、代码实现添加依赖生成Token认证token 8、工具类9、JWT整合Web10、拦截器校验11、网关路由校验12、解决多用户登录的问题13、客户端…...
git命令和docker命令
1、git git是分布式的版本控制工具 git可以通过本地仓库管理文件的历史版本记录 # 本地仓库操作的命令 # 初始化本地库 git init # 添加文件到暂存区 git add . git checkout 暂存区要撤销的文件名称 # 提交暂存区文件 git commit -m 注释# 版本穿梭 # 查看提交记录 git log…...
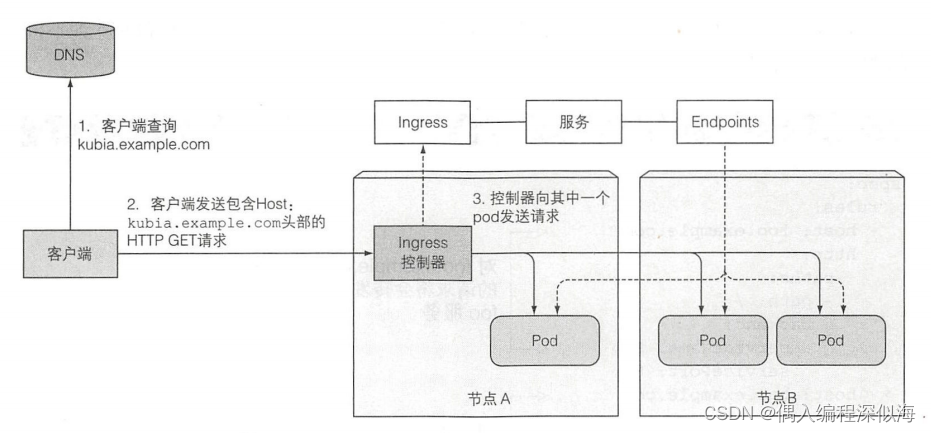
【K8S in Action】服务:让客户端发现pod 并与之通信(2)
一 通过Ingress暴露服务 Ingress (名词) 一一进入或进入的行为;进入的权利;进入的手段或地点;入口。一个重要的原因是每个 LoadBalancer 服务都需要自己的负载均衡器, 以及 独有的公有 IP 地址, 而 Ingres…...

Spring Boot 中实现跨域的几种方式
前言 在现代Web应用中,由于安全性和隐私的考虑,浏览器限制了从一个域向另一个域发起的跨域HTTP请求。解决这个问题的一种常见方式是实现跨域资源共享(CORS)。Spring Boot提供了多种方式来处理跨域请求,本文将介绍其中的…...

WT2605C音频蓝牙语音芯片:单芯片实现蓝牙+MP3+BLE+电话本多功能应用
在当今的电子产品领域,多功能、高集成度成为了一种趋势。各种产品都需要具备多种功能,以满足用户多样化的需求。针对这一市场趋势,唯创知音推出了一款集成了蓝牙、MP3播放、BLE和电话本功能的音频蓝牙语音芯片——WT2605C,实现了单…...
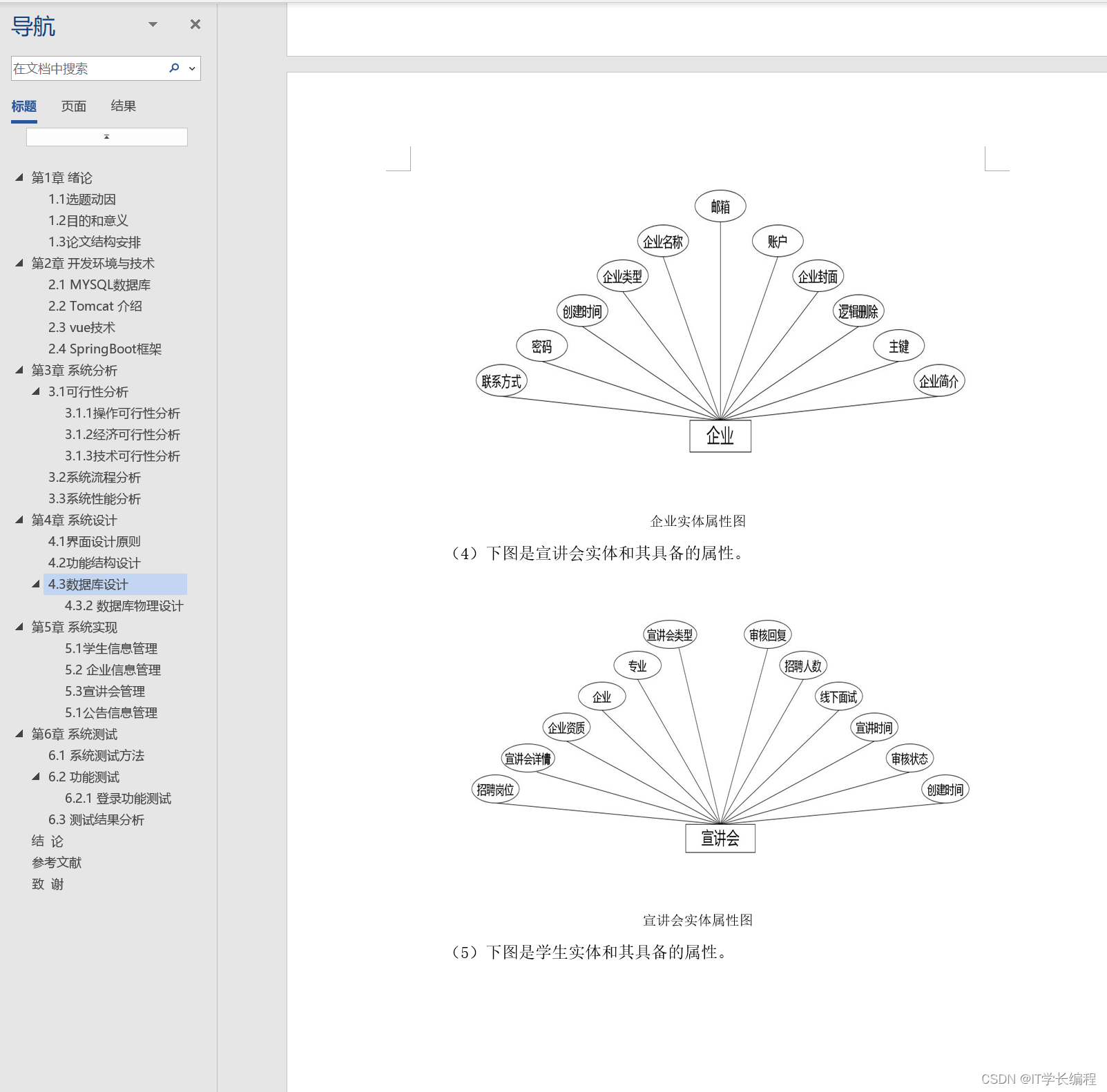
计算机毕业设计 基于SpringBoot的高校宣讲会管理系统的设计与实现 Java实战项目 附源码+文档+视频讲解
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...

Android 使用Serialiable接口和Parcelable接口进行数据传送
一、前言 这篇文章主要针对Serialiable和Parcelable接口来传递对象。呈现的功能是跳转到另一个界面,然后通过toast展现我收到的数据。 二、使用Serialiable接口传递数据 1.创建需要传递的对象 //必须实现Serializable接口,此对象才有传递的资格 publ…...
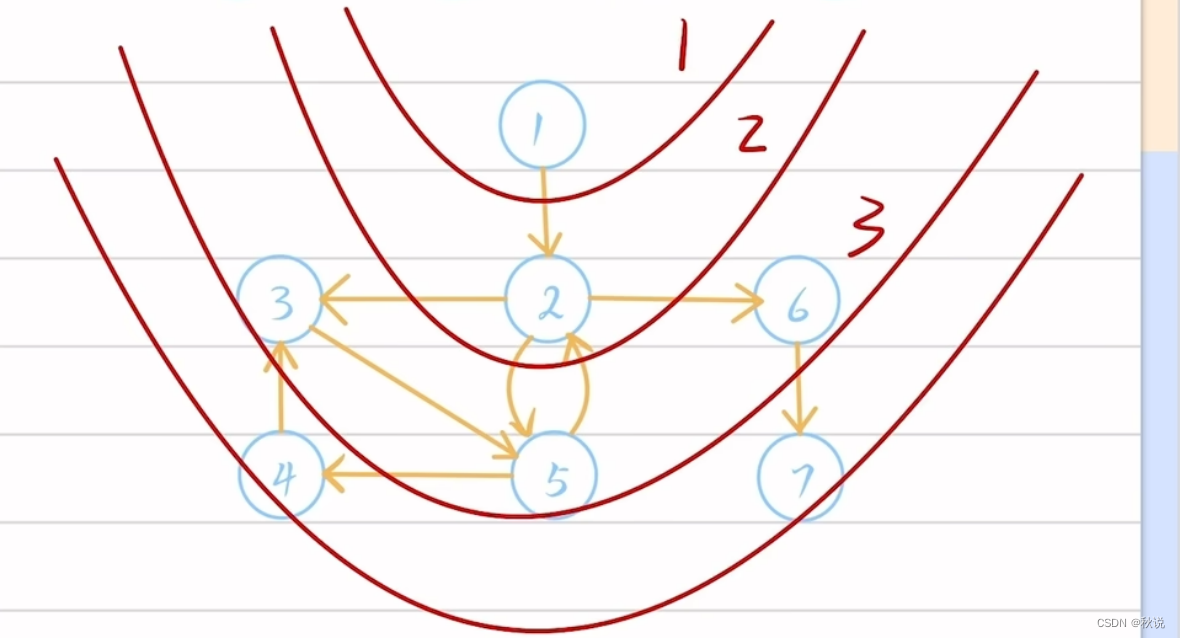
【数据结构入门精讲 | 第十七篇】一文讲清图及各类图算法
在上一篇中我们进行了的并查集相关练习,在这一篇中我们将学习图的知识点。 目录 概念深度优先DFS伪代码 广度优先BFS伪代码 最短路径算法(Dijkstra)伪代码 Floyd算法拓扑排序逆拓扑排序 概念 下面介绍几种在对图操作时常用的算法。 深度优先D…...

QAbstractTableModel进阶实战:构建可编辑数据表格的完整指南
1. 从零理解QAbstractTableModel的核心机制 第一次接触Qt模型视图框架时,很多人会被QAbstractTableModel这个抽象类吓到。但当我真正用它完成第一个可编辑表格后,发现它的设计其实非常优雅。想象你正在开发一个学生管理系统,需要展示包含姓名…...

Agent设计模式全景图——从ReAct到Multi-Agent的完整知识体系
Agent概念在2023年就已出现,2024年是框架快速迭代的一年。到了2026年,Agent设计模式逐渐成熟,成为工程实践的关键。 GitHub上关于Agent的开源项目突破10万个,LangChain、LangGraph、AutoGen、CrewAI……框架层出不穷。但翻遍这些文…...

移动时代数据自主:从云端依赖到物理存储的范式转变
1. 个人通信的现状与核心矛盾我们正处在一个数据爆炸的时代。每天,从清晨被手机闹钟唤醒,到深夜刷完最后一条短视频,我们每个人都在无意识地产生、消费和交换着海量数据。文章里提到一个让我印象深刻的数字:平均每人每天要处理35G…...

终极解决方案:3分钟快速修复VC++运行库缺失问题,彻底告别软件启动失败
终极解决方案:3分钟快速修复VC运行库缺失问题,彻底告别软件启动失败 【免费下载链接】vcredist AIO Repack for latest Microsoft Visual C Redistributable Runtimes 项目地址: https://gitcode.com/gh_mirrors/vc/vcredist 你是否经常遇到游戏或…...

我开会用了之后从怀疑到真香!2026华为手机语音转文字真后悔没早用
我上周差点因为漏记项目评审会的核心需求背锅,前前后后踩了N多会议记录的坑,用过不下10款语音转文字工具,掏心窝子说一句:听脑AI是同类工具中最值得职场人用的,没有之一。之前我真的不信什么语音转文字能解决所有问题&…...
全量上线及直连 API 体验指南)
AI 绘图新进展:GPTimage2 系列(含 4K 超清版)全量上线及直连 API 体验指南
随着 AIGC(人工智能生成内容)技术的快速迭代,近期备受关注的 GPTimage2 系列模型已全量上线。作为 AI 绘图领域的新晋生力军,GPTimage2 在图像生成质量、细节刻画上展现出了极强的竞争力。特别值得一提的是,本次不仅上…...
)
从寄存器到库函数:手把手拆解STM32的RCC时钟树(以F103C8T6为例)
从寄存器到库函数:手把手拆解STM32的RCC时钟树(以F103C8T6为例) 在嵌入式开发领域,STM32系列微控制器因其出色的性能和丰富的外设资源而广受欢迎。然而,对于许多开发者来说,STM32的时钟系统(RCC…...
)
告别玄学调试:手把手教你用Vivado配置Xilinx SRIO IP核(附完整工程源码)
告别玄学调试:手把手教你用Vivado配置Xilinx SRIO IP核(附完整工程源码) 在FPGA开发领域,高速串行通信一直是工程师们又爱又恨的技术难点。特别是当项目需要实现芯片间高速数据交互时,Serial RapidIO(SRIO…...
)
别再只调包了!用PyTorch和DGL从零实现一个GCN层(附Cora节点分类实战代码)
从零构建图卷积网络:PyTorch与DGL实战中的底层逻辑拆解 当你第一次调用g.update_all()时,是否好奇过DGL框架背后究竟发生了什么?那些看似简单的消息传递和聚合操作,实际上隐藏着图卷积网络最精妙的设计思想。本文将带你深入GCN的数…...

Zotero Duplicates Merger:5分钟搞定文献库重复问题
Zotero Duplicates Merger:5分钟搞定文献库重复问题 【免费下载链接】ZoteroDuplicatesMerger A zotero plugin to automatically merge duplicate items 项目地址: https://gitcode.com/gh_mirrors/zo/ZoteroDuplicatesMerger 还在为Zotero文献库中堆积如山…...