10 种顶流聚类算法 Python 实现(附完整代码)
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。
有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每种算法的不同配置。在本教程中,你将发现如何在 python 中安装和使用顶级聚类算法。
完成本教程后,你将知道:
- 聚类是在输入数据的特征空间中查找自然组的无监督问题。
- 对于所有数据集,有许多不同的聚类算法和单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适配和使用顶级聚类算法。
教程概述
本教程分为三部分:
- 聚类
- 聚类算法
- 聚类算法示例
- 库安装
- 聚类数据集
- 亲和力传播
- 聚合聚类
- BIRCH
- DBSCAN
- K-均值
- Mini-Batch K-均值
- Mean Shift
- OPTICS
- 光谱聚类
- 高斯混合模型
一、聚类
聚类分析,即聚类,是一项无监督的机器学习任务。它包括自动发现数据中的自然分组。与监督学习(类似预测建模)不同,聚类算法只解释输入数据,并在特征空间中找到自然组或群集。
聚类技术适用于没有要预测的类,而是将实例划分为自然组的情况。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
群集通常是特征空间中的密度区域,其中来自域的示例(观测或数据行)比其他群集更接近群集。群集可以具有作为样本或点特征空间的中心(质心),并且可以具有边界或范围。
这些群集可能反映出在从中绘制实例的域中工作的某种机制,这种机制使某些实例彼此具有比它们与其余实例更强的相似性。
—源自:《数据挖掘页:实用机器学习工具和技术》2016年。
聚类可以作为数据分析活动提供帮助,以便了解更多关于问题域的信息,即所谓的模式发现或知识发现。例如:
- 该进化树可以被认为是人工聚类分析的结果;
- 将正常数据与异常值或异常分开可能会被认为是聚类问题;
- 根据自然行为将集群分开是一个集群问题,称为市场细分。
聚类还可用作特征工程的类型,其中现有的和新的示例可被映射并标记为属于数据中所标识的群集之一。虽然确实存在许多特定于群集的定量措施,但是对所识别的群集的评估是主观的,并且可能需要领域专家。通常,聚类算法在人工合成数据集上与预先定义的群集进行学术比较,预计算法会发现这些群集。
聚类是一种无监督学习技术,因此很难评估任何给定方法的输出质量。
—源自:《机器学习页:概率观点》2012。
二、聚类算法
有许多类型的聚类算法。许多算法在特征空间中的示例之间使用相似度或距离度量,以发现密集的观测区域。因此,在使用聚类算法之前,扩展数据通常是良好的实践。
聚类分析的所有目标的核心是被群集的各个对象之间的相似程度(或不同程度)的概念。聚类方法尝试根据提供给对象的相似性定义对对象进行分组。
—源自:《统计学习的要素:数据挖掘、推理和预测》,2016年
一些聚类算法要求您指定或猜测数据中要发现的群集的数量,而另一些算法要求指定观测之间的最小距离,其中示例可以被视为“关闭”或“连接”。因此,聚类分析是一个迭代过程,在该过程中,对所识别的群集的主观评估被反馈回算法配置的改变中,直到达到期望的或适当的结果。scikit-learn 库提供了一套不同的聚类算法供选择。下面列出了10种比较流行的算法:
- 亲和力传播
- 聚合聚类
- BIRCH
- DBSCAN
- K-均值
- Mini-Batch K-均值
- Mean Shift
- OPTICS
- 光谱聚类
- 高斯混合
每个算法都提供了一种不同的方法来应对数据中发现自然组的挑战。没有最好的聚类算法,也没有简单的方法来找到最好的算法为您的数据没有使用控制实验。
在本教程中,我们将回顾如何使用来自 scikit-learn 库的这10个流行的聚类算法中的每一个。这些示例将为您复制粘贴示例并在自己的数据上测试方法提供基础。我们不会深入研究算法如何工作的理论,也不会直接比较它们。让我们深入研究一下。
10 种顶流聚类算法 Python 实现(附完整代码)mp.weixin.qq.com/s?__biz=MzUzMTczMDMwMw==&mid=2247520146&idx=1&sn=13d6b5a45518a6cdc1f41fcdd2085584&chksm=fabcd582cdcb5c942dcc9a83fe22e6f5beb1b524be9c6f2b2b9cead95f60c02b3ef6ac10dc56&token=1780081931&lang=zh_CN#rd正在上传…重新上传取消
三、聚类算法示例
在本节中,我们将回顾如何在 scikit-learn 中使用10个流行的聚类算法。这包括一个拟合模型的例子和可视化结果的例子。这些示例用于将粘贴复制到您自己的项目中,并将方法应用于您自己的数据。
1、库安装
首先,让我们安装库。不要跳过此步骤,因为你需要确保安装了最新版本。你可以使用 pip Python 安装程序安装 scikit-learn 存储库,如下所示:
sudo pip install scikit-learn
接下来,让我们确认已经安装了库,并且您正在使用一个现代版本。运行以下脚本以输出库版本号。
# 检查 scikit-learn 版本
import sklearn
print(sklearn.__version__)
运行该示例时,您应该看到以下版本号或更高版本。
0.22.1
2、聚类数据集
我们将使用 make _ classification ()函数创建一个测试二分类数据集。数据集将有1000个示例,每个类有两个输入要素和一个群集。这些群集在两个维度上是可见的,因此我们可以用散点图绘制数据,并通过指定的群集对图中的点进行颜色绘制。
这将有助于了解,至少在测试问题上,群集的识别能力如何。该测试问题中的群集基于多变量高斯,并非所有聚类算法都能有效地识别这些类型的群集。因此,本教程中的结果不应用作比较一般方法的基础。下面列出了创建和汇总合成聚类数据集的示例。
# 综合分类数据集
from numpy import where
from sklearn.datasets import make_classification
from matplotlib import pyplot
%matplotlib inline# 定义数据集
X, y = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 为每个类的样本创建散点图
for class_value in range(2):# 获取此类的示例的行索引row_ix = where(y == class_value)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])# 绘制散点图
pyplot.show()运行该示例将创建合成的聚类数据集,然后创建输入数据的散点图,其中点由类标签(理想化的群集)着色。我们可以清楚地看到两个不同的数据组在两个维度,并希望一个自动的聚类算法可以检测这些分组。

原文链接10 种顶流聚类算法 Python 实现(附完整代码)
图:已知聚类着色点的合成聚类数据集的散点图
接下来,我们可以开始查看应用于此数据集的聚类算法的示例。我已经做了一些最小的尝试来调整每个方法到数据集。
3、亲和力传播
亲和力传播包括找到一组最能概括数据的范例。
我们设计了一种名为“亲和传播”的方法,它作为两对数据点之间相似度的输入度量。在数据点之间交换实值消息,直到一组高质量的范例和相应的群集逐渐出现
—源自:《通过在数据点之间传递消息》2007。
它是通过 AffinityPropagation 类实现的,要调整的主要配置是将“ 阻尼 ”设置为0.5到1,甚至可能是“首选项”。
下面列出了完整的示例。
# 亲和力传播聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AffinityPropagation
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AffinityPropagation(damping=0.9)
# 匹配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法取得良好的结果。

图:数据集的散点图,具有使用亲和力传播识别的聚类
4、聚合聚类
聚合聚类涉及合并示例,直到达到所需的群集数量为止。它是层次聚类方法的更广泛类的一部分,通过 AgglomerationClustering 类实现的,主要配置是“ n _ clusters ”集,这是对数据中的群集数量的估计,例如2。下面列出了完整的示例。
# 聚合聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import AgglomerativeClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = AgglomerativeClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组。

图:使用聚集聚类识别出具有聚类的数据集的散点图
5、BIRCH
BIRCH 聚类( BIRCH 是平衡迭代减少的缩写,聚类使用层次结构)包括构造一个树状结构,从中提取聚类质心。
BIRCH 递增地和动态地群集传入的多维度量数据点,以尝试利用可用资源(即可用内存和时间约束)产生最佳质量的聚类。
—源自:《 BIRCH :1996年大型数据库的高效数据聚类方法》
它是通过 Birch 类实现的,主要配置是“ threshold ”和“ n _ clusters ”超参数,后者提供了群集数量的估计。下面列出了完整的示例。
# birch聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import Birch
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1, random_state=4)
# 定义模型
model = Birch(threshold=0.01, n_clusters=2)
# 适配模型
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个很好的分组。

图:使用BIRCH聚类确定具有聚类的数据集的散点图
6、DBSCAN
DBSCAN 聚类(其中 DBSCAN 是基于密度的空间聚类的噪声应用程序)涉及在域中寻找高密度区域,并将其周围的特征空间区域扩展为群集。
…我们提出了新的聚类算法 DBSCAN 依赖于基于密度的概念的集群设计,以发现任意形状的集群。DBSCAN 只需要一个输入参数,并支持用户为其确定适当的值
-源自:《基于密度的噪声大空间数据库聚类发现算法》,1996
它是通过 DBSCAN 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。
下面列出了完整的示例。
# dbscan 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import DBSCAN
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = DBSCAN(eps=0.30, min_samples=9)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,尽管需要更多的调整,但是找到了合理的分组。

图:使用DBSCAN集群识别出具有集群的数据集的散点图
7、K均值
K-均值聚类可以是最常见的聚类算法,并涉及向群集分配示例,以尽量减少每个群集内的方差。
本文的主要目的是描述一种基于样本将 N 维种群划分为 k 个集合的过程。这个叫做“ K-均值”的过程似乎给出了在类内方差意义上相当有效的分区。
-源自:《关于多元观测的分类和分析的一些方法》1967年
它是通过 K-均值类实现的,要优化的主要配置是“ n _ clusters ”超参数设置为数据中估计的群集数量。下面列出了完整的示例。
# k-means 聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2,n_redundant=0,n_clusters_per_class=1, random_state=4)
# 定义模型
model = KMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以找到一个合理的分组,尽管每个维度中的不等等方差使得该方法不太适合该数据集。
图:使用K均值聚类识别出具有聚类的数据集的散点图
8、Mini-Batch K-均值
Mini-Batch K-均值是 K-均值的修改版本,它使用小批量的样本而不是整个数据集对群集质心进行更新,这可以使大数据集的更新速度更快,并且可能对统计噪声更健壮。
...我们建议使用 k-均值聚类的迷你批量优化。与经典批处理算法相比,这降低了计算成本的数量级,同时提供了比在线随机梯度下降更好的解决方案。
—源自:《Web-Scale K-均值聚类》2010
它是通过 MiniBatchKMeans 类实现的,要优化的主配置是“ n _ clusters ”超参数,设置为数据中估计的群集数量。下面列出了完整的示例。
# mini-batch k均值聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MiniBatchKMeans
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1,random_state=4)
# 定义模型
model = MiniBatchKMeans(n_clusters=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,会找到与标准 K-均值算法相当的结果。

图:带有最小批次K均值聚类的聚类数据集的散点图
9、均值漂移聚类
均值漂移聚类涉及到根据特征空间中的实例密度来寻找和调整质心。
对离散数据证明了递推平均移位程序收敛到最接近驻点的基础密度函数,从而证明了它在检测密度模式中的应用。
—源自:《Mean Shift :面向特征空间分析的稳健方法》,2002
它是通过 MeanShift 类实现的,主要配置是“带宽”超参数。下面列出了完整的示例。
# 均值漂移聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import MeanShift
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000,n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1,random_state=4)
# 定义模型
model = MeanShift()
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,可以在数据中找到一组合理的群集。
图:具有均值漂移聚类的聚类数据集散点图
10、OPTICS
OPTICS 聚类( OPTICS 短于订购点数以标识聚类结构)是上述 DBSCAN 的修改版本。
我们为聚类分析引入了一种新的算法,它不会显式地生成一个数据集的聚类;而是创建表示其基于密度的聚类结构的数据库的增强排序。此群集排序包含相当于密度聚类的信息,该信息对应于范围广泛的参数设置。
—源自:《OPTICS :排序点以标识聚类结构》,1999
它是通过 OPTICS 类实现的,主要配置是“ eps ”和“ min _ samples ”超参数。下面列出了完整的示例。
# optics聚类
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import OPTICS
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0, n_clusters_per_class=1, random_state=4)
# 定义模型
model = OPTICS(eps=0.8, min_samples=10)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我无法在此数据集上获得合理的结果。

图:使用OPTICS聚类确定具有聚类的数据集的散点图
11、光谱聚类
光谱聚类是一类通用的聚类方法,取自线性线性代数。
最近在许多领域出现的一个有希望的替代方案是使用聚类的光谱方法。这里,使用从点之间的距离导出的矩阵的顶部特征向量。
—源自:《关于光谱聚类:分析和算法》,2002年
它是通过 Spectral 聚类类实现的,而主要的 Spectral 聚类是一个由聚类方法组成的通用类,取自线性线性代数。要优化的是“ n _ clusters ”超参数,用于指定数据中的估计群集数量。下面列出了完整的示例。
# spectral clustering
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.cluster import SpectralClustering
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2, n_redundant=0,n_clusters_per_class=1, random_state=4)
# 定义模型
model = SpectralClustering(n_clusters=2)
# 模型拟合与聚类预测
yhat = model.fit_predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。
在这种情况下,找到了合理的集群。
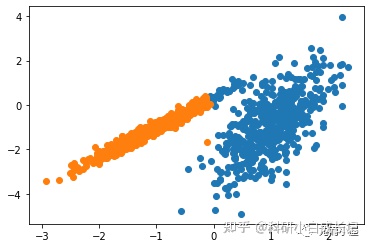
图:使用光谱聚类聚类识别出具有聚类的数据集的散点图
12、高斯混合模型
高斯混合模型总结了一个多变量概率密度函数,顾名思义就是混合了高斯概率分布。它是通过 Gaussian Mixture 类实现的,要优化的主要配置是“ n _ clusters ”超参数,用于指定数据中估计的群集数量。下面列出了完整的示例。
# 高斯混合模型
from numpy import unique
from numpy import where
from sklearn.datasets import make_classification
from sklearn.mixture import GaussianMixture
from matplotlib import pyplot
# 定义数据集
X, _ = make_classification(n_samples=1000, n_features=2, n_informative=2,n_redundant=0,n_clusters_per_class=1, random_state=4)
# 定义模型
model = GaussianMixture(n_components=2)
# 模型拟合
model.fit(X)
# 为每个示例分配一个集群
yhat = model.predict(X)
# 检索唯一群集
clusters = unique(yhat)
# 为每个群集的样本创建散点图
for cluster in clusters:# 获取此群集的示例的行索引row_ix = where(yhat == cluster)# 创建这些样本的散布pyplot.scatter(X[row_ix, 0], X[row_ix, 1])
# 绘制散点图
pyplot.show()
运行该示例符合训练数据集上的模型,并预测数据集中每个示例的群集。然后创建一个散点图,并由其指定的群集着色。在这种情况下,我们可以看到群集被完美地识别。这并不奇怪,因为数据集是作为 Gaussian 的混合生成的。

图:使用高斯混合聚类识别出具有聚类的数据集的散点图
三、总结
在本教程中,您发现了如何在 python 中安装和使用顶级聚类算法。具体来说,你学到了:
- 聚类是在特征空间输入数据中发现自然组的无监督问题。
- 有许多不同的聚类算法,对于所有数据集没有单一的最佳方法。
- 在 scikit-learn 机器学习库的 Python 中如何实现、适合和使用10种顶级聚类算法
相关文章:
10 种顶流聚类算法 Python 实现(附完整代码)
聚类或聚类分析是无监督学习问题。它通常被用作数据分析技术,用于发现数据中的有趣模式,例如基于其行为的客户群。 有许多聚类算法可供选择,对于所有情况,没有单一的最佳聚类算法。相反,最好探索一系列聚类算法以及每…...

微信小程序第一节 —— 自定义顶部、底部导航栏以及获取胶囊体位置信息。
一、前言 大家好!我是 是江迪呀。我们在进行微信小程序开发时,常常需要自定义一些东西,比如自定义顶部导航、自定义底部导航等等。那么知道这些自定义内容的具体位置、以及如何适配不同的机型就变得尤为重要。下面让我以在iPhone机型&#x…...
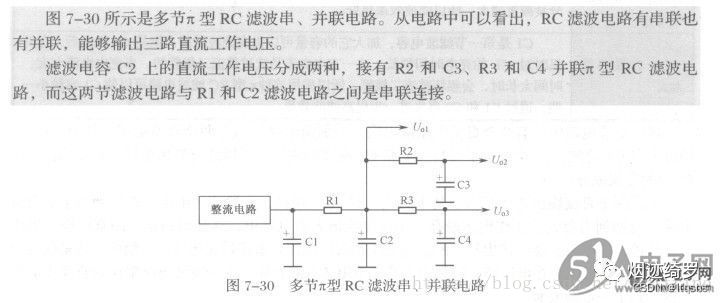
快速吃透π型滤波电路-LC-RC滤波器
π型滤波器简介 π型滤波器包括两个电容器和一个电感器,它的输入和输出都呈低阻抗。π型滤波有RC和LC两种, 在输出电流不大的情况下用RC,R的取值不能太大,一般几个至几十欧姆,其优点是成本低。其缺点是电阻要消耗一些…...
聊聊混沌工程
这是鼎叔的第五十四篇原创文章。行业大牛和刚毕业的小白,都可以进来聊聊。欢迎关注本专栏和微信公众号《敏捷测试转型》,大量原创思考文章陆续推出。混沌工程是一门新兴学科,它不仅仅只是个技术活动,还包含如何设计能够持续协作的…...

做为骨干网络的分类模型的预训代码安装配置简单记录
一、安装配置环境 1、准备工作 代码地址 GitHub - bubbliiiing/classification-pytorch: 这是各个主干网络分类模型的源码,可以用于训练自己的分类模型。 # 创建环境 conda create -n ptorch1_2_0 python3.6 # 然后启动 conda install pytorch1.2.0 torchvision…...

网络协议(九):应用层(域名、DNS、DHCP)
网络协议系列文章 网络协议(一):基本概念、计算机之间的连接方式 网络协议(二):MAC地址、IP地址、子网掩码、子网和超网 网络协议(三):路由器原理及数据包传输过程 网络协议(四):网络分类、ISP、上网方式、公网私网、NAT 网络…...
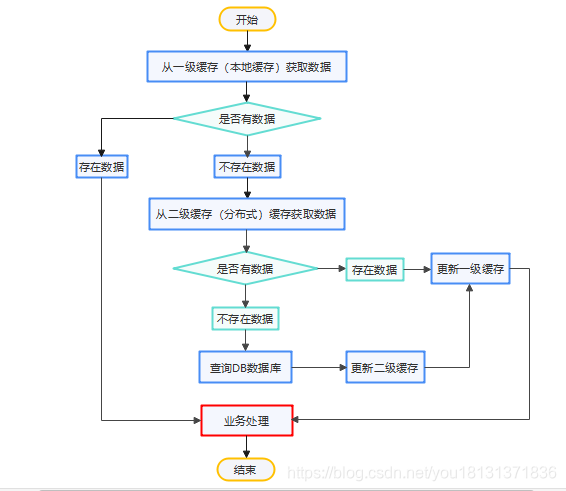
有趣的小知识(三)提升网站速度的秘诀:掌握缓存基础,让你的网站秒开
像MySql等传统的关系型数据库已经不能适用于所有的业务场景,比如电商系统的秒杀场景,APP首页的访问流量高峰场景,很容易造成关系型数据库的瘫痪,随着缓存技术的出现很好的解决了这个问题。 一、缓存的概念(什么是缓存…...

SpringCloud之服务拆分和实现远程调用案例
服务拆分对单体架构项目来说:简单方便,高度耦合,扩展性差,适合小型项目。而对于分布式架构来说:低耦合,扩展性好,但架构复杂,难度大。微服务就是一种良好的分布式架构方案࿱…...
: com.atguigu.dao.UserDao.save)
mybatis: Invalid bound statement (not found): com.atguigu.dao.UserDao.save
问题描述: 1 问题实质: dao层(又叫mapper接口)跟mapper.xml文件没有映射 2 问题原因: 出现这种映射问题的原因分为低级原因和更低级原因两种 更低级原因: (1)dao层的方法和mapper.xml中的方法不一样; (2)mapper中的namespace 值 和对应的dao层entity层不一致 &…...
JavaScript 代码规范
所有的 JavaScript 项目适用同一种规范。JavaScript 代码规范代码规范通常包括以下几个方面:变量和函数的命名规则空格,缩进,注释的使用规则。其他常用规范……规范的代码可以更易于阅读与维护。代码规范一般在开发前规定,可以跟你的团队成员…...

6综合项目 旅游网 【6.我的收藏和收藏排行榜】
我的收藏分析先登录→拿到当前登录的用户信息,从数据库中获取uid和对应uid的rid集合→将rid集合信息展示到我的收藏前台代码判断用户是否登录,传递uid,通过uid查找其对应的rid集合当查询的属性涉及到多张表,则必须使用多表连接&am…...
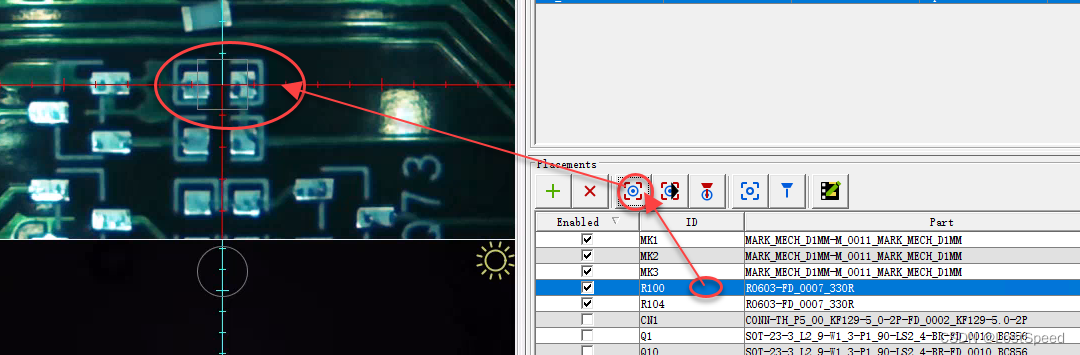
openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法
文章目录openpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法概述想出来一个变通的方法ENDopenpnp - error - 微调mark点坐标后,更新板子其他原件其他坐标报错的变通方法 概述 载入坐标文件后, 指定左下角远点坐标, 然后定位板子上的3个Mark点, 因为…...

借助ChatGPT爆火,股价暴涨又暴跌后,C3.ai仍面临巨大风险
来源:猛兽财经 作者:猛兽财经 C3.ai的股价 作为一家人工智能技术提供商,C3.ai(AI)的股价曾在2021年初随着炒作情绪的增加,达到了历史最高点,但自那以后其股价就下跌了90%,而且炒作情…...

蓝桥杯-数位排序
蓝桥杯-数位排序1、问题描述2、解题思路3、代码实现1、问题描述 小蓝对一个数的数位之和很感兴趣, 今天他要按照数位之和给数排序。当 两个数各个数位之和不同时, 将数位和较小的排在前面, 当数位之和相等时, 将数值小的排在前面。 例如, 2022 排在 409 前面, 因为 2022 的数位…...
)
【ES实战】ES 插件包离线安装(本地文件)
ES 插件包离线安装(本地文件) 文章目录ES 插件包离线安装(本地文件)使用安装命令安装直接解压式验证安装情况常用的分词插件analysis-ik analysis-pinyin analysis-dynamic-synonym 在集群的节点上分发插件的ZIP安装包 使用安…...

Spring的核心基础——IOC与DI
文章目录一、Spring简介1 Spring介绍1.1 为什么要学1.2 学什么2 初识Spring2.1 Spring家族2.2 Spring发展史3 Spring体系结构3.1 Spring Framework系统架构图4 Spring核心概念问题导入4.1 核心概念二、IOC和DI入门1 IOC入门问题导入1.1 门案例思路分析1.2 实现步骤1.3 实现代码…...

C++正则表达式基础
文章目录1. 查找第一个匹配的2. 查找所有结果3. 打印匹配结果的上下文4. 使用子表达式5. 查找并替换注意: .(点)在括号中没有特殊含义,无需转义用\转义。 1. 查找第一个匹配的 #include <iostream> #include <regex>using names…...

如何在网络安全中使用人工智能并避免受困于此
人工智能在网络安全中的应用正在迅速增长,并对威胁检测、事件响应、欺诈检测和漏洞管理产生了重大影响。根据Juniper Research的一份报告,预计到2023年,使用人工智能进行欺诈检测和预防将为企业每年节省110亿美元。但是,如何将人工…...

生态 | 人大金仓与超聚变的多个产品完成兼容认证
近日,人大金仓与超聚变数字技术有限公司(简称“超聚变”)完成了多款产品的兼容互认测试。测试表明,人大金仓KingbaseES V8数据库与超聚变服务器操作系统FusionOS、超聚变FusionOne基础设施完全兼容,人大金仓异构数据同…...

4自由度串联机械臂按颜色分拣物品功能的实现
1. 功能说明 本实验要实现的功能是:将黑、白两种颜色的工件分别放置在传感器上时,机械臂会根据检测到的颜色,将工件搬运至写有相应颜色字样区域。 2. 使用样机 本实验使用的样机为4自由度串联机械臂。 3. 运动功能实现 3.1 电子硬件 在这个…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...
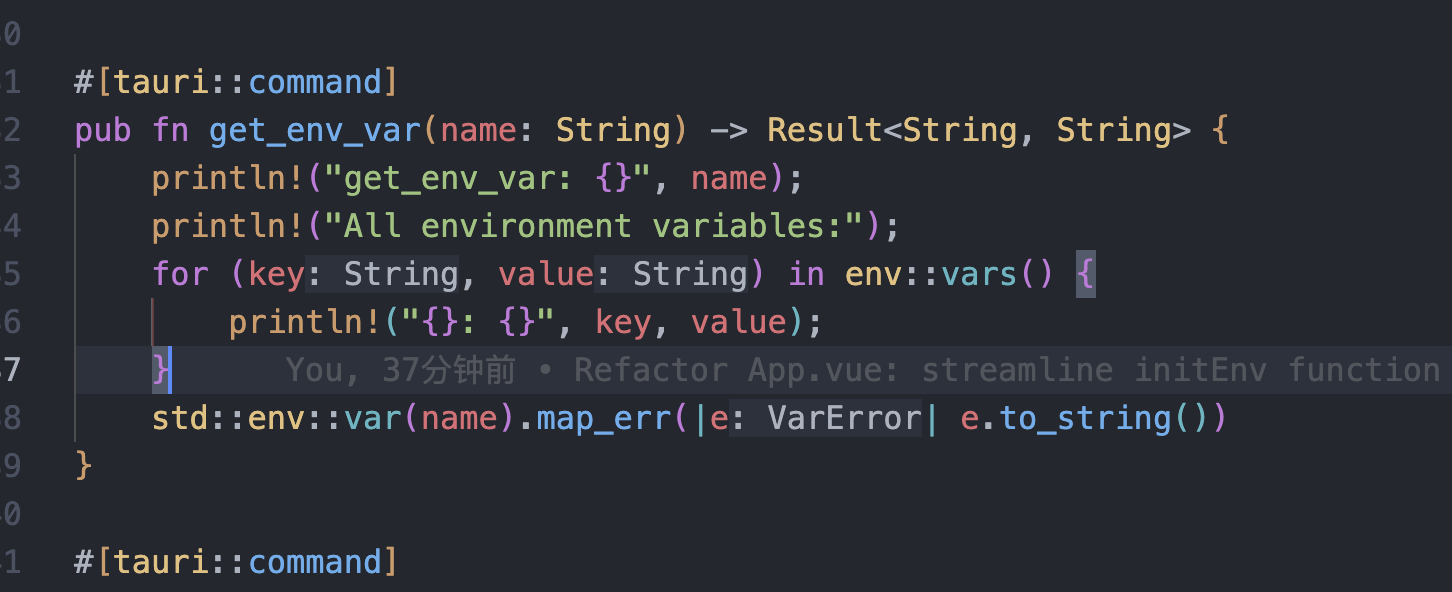
tauri项目,如何在rust端读取电脑环境变量
如果想在前端通过调用来获取环境变量的值,可以通过标准的依赖: std::env::var(name).ok() 想在前端通过调用来获取,可以写一个command函数: #[tauri::command] pub fn get_env_var(name: String) -> Result<String, Stri…...
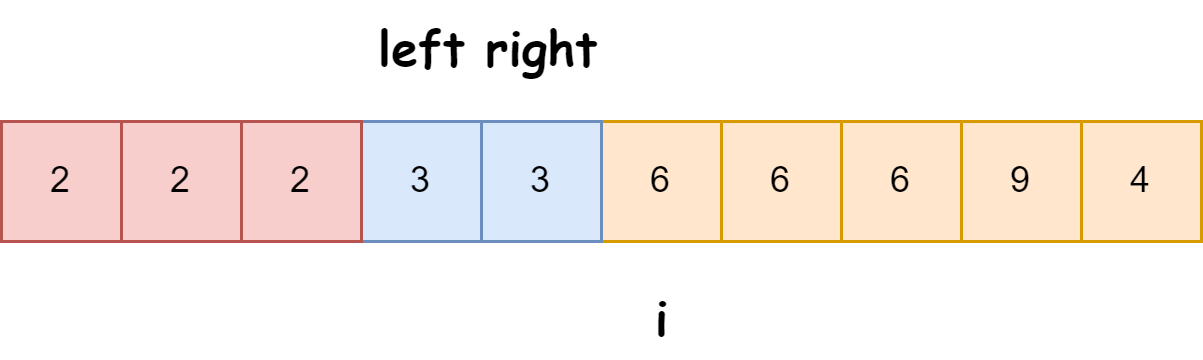
快速排序算法改进:随机快排-荷兰国旗划分详解
随机快速排序-荷兰国旗划分算法详解 一、基础知识回顾1.1 快速排序简介1.2 荷兰国旗问题 二、随机快排 - 荷兰国旗划分原理2.1 随机化枢轴选择2.2 荷兰国旗划分过程2.3 结合随机快排与荷兰国旗划分 三、代码实现3.1 Python实现3.2 Java实现3.3 C实现 四、性能分析4.1 时间复杂度…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...

大模型真的像人一样“思考”和“理解”吗?
Yann LeCun 新研究的核心探讨:大语言模型(LLM)的“理解”和“思考”方式与人类认知的根本差异。 核心问题:大模型真的像人一样“思考”和“理解”吗? 人类的思考方式: 你的大脑是个超级整理师。面对海量信…...

比较数据迁移后MySQL数据库和ClickHouse数据仓库中的表
设计一个MySQL数据库和Clickhouse数据仓库的表数据比较的详细程序流程,两张表是相同的结构,都有整型主键id字段,需要每次从数据库分批取得2000条数据,用于比较,比较操作的同时可以再取2000条数据,等上一次比较完成之后,开始比较,直到比较完所有的数据。比较操作需要比较…...

[C++错误经验]case语句跳过变量初始化
标题:[C错误经验]case语句跳过变量初始化 水墨不写bug 文章目录 一、错误信息复现二、错误分析三、解决方法 一、错误信息复现 write.cc:80:14: error: jump to case label80 | case 2:| ^ write.cc:76:20: note: crosses initialization…...

android计算器代码
本次作业要求实现一个计算器应用的基础框架。以下是布局文件的核心代码: <LinearLayout xmlns:android"http://schemas.android.com/apk/res/android"android:layout_width"match_parent"android:layout_height"match_parent"andr…...