[MySQL] MySQL 高级(进阶) SQL 语句
一、高效查询方式
1.1 指定指字段进行查看
事先准备好两张表

select 字段1,字段2 from 表名;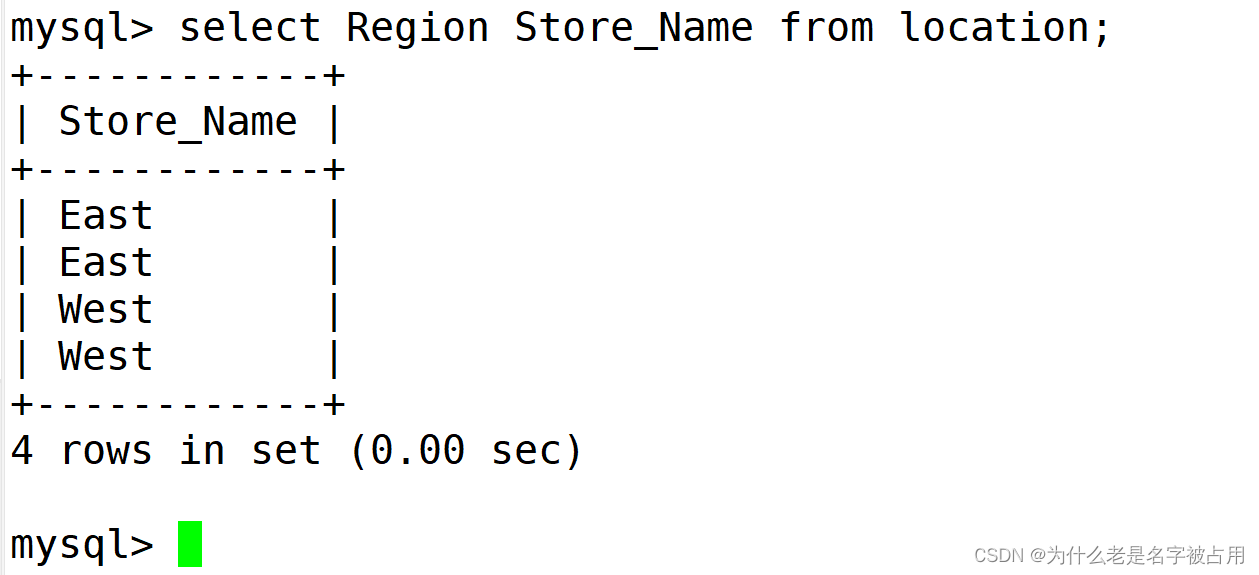
1.2 对字段进行去重查看
SELECT DISTINCT "字段" FROM "表名";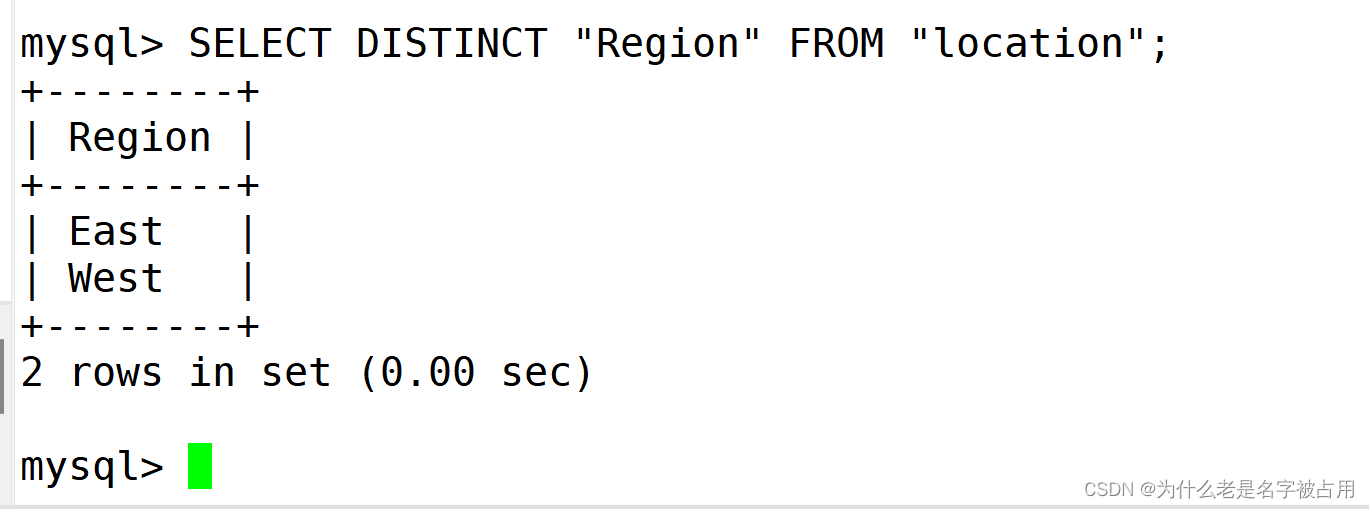
1.3 where条件查询
SELECT "字段" FROM 表名" WHERE "条件";
1.4 and 和 or 进行逻辑关系的增加
SELECT "字段" FROM "表名" WHERE "条件1" AND "条件2";

SELECT "字段" FROM "表名" WHERE "条件1" OR "条件2";
1.5 查询取值列表中的数据
SELECT "字段" FROM "表名" WHERE "字段" IN ('值1', '值2', ...); #in,遍历一个取值列表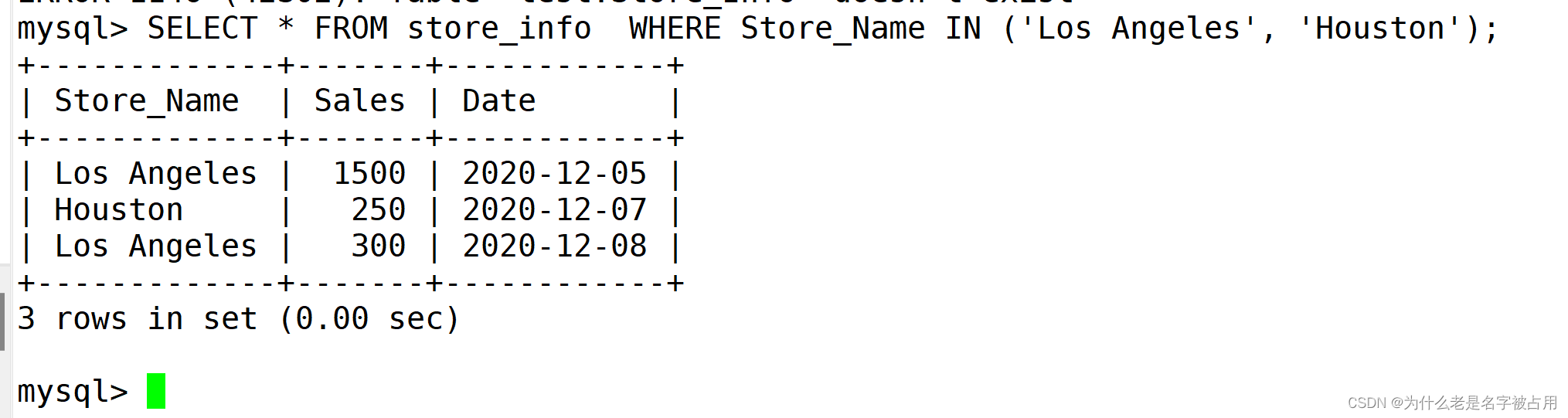
1.6 between的引用
SELECT "字段" FROM "表名" WHERE "字段" BETWEEN '值1' AND '值2';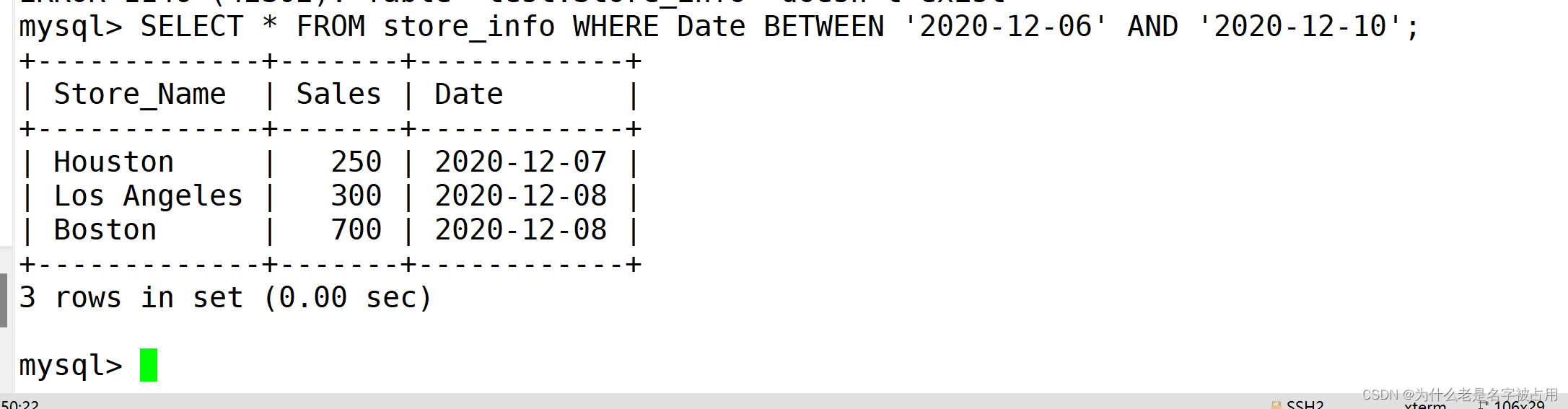
1.7 like的查询方式
like查询通常会与通配符配合使用
%:百分号表示零个、一一个或多个字符
_:划线表示单个字符
SELECT * FROM Store_Info WHERE Store_Name like '%os%';
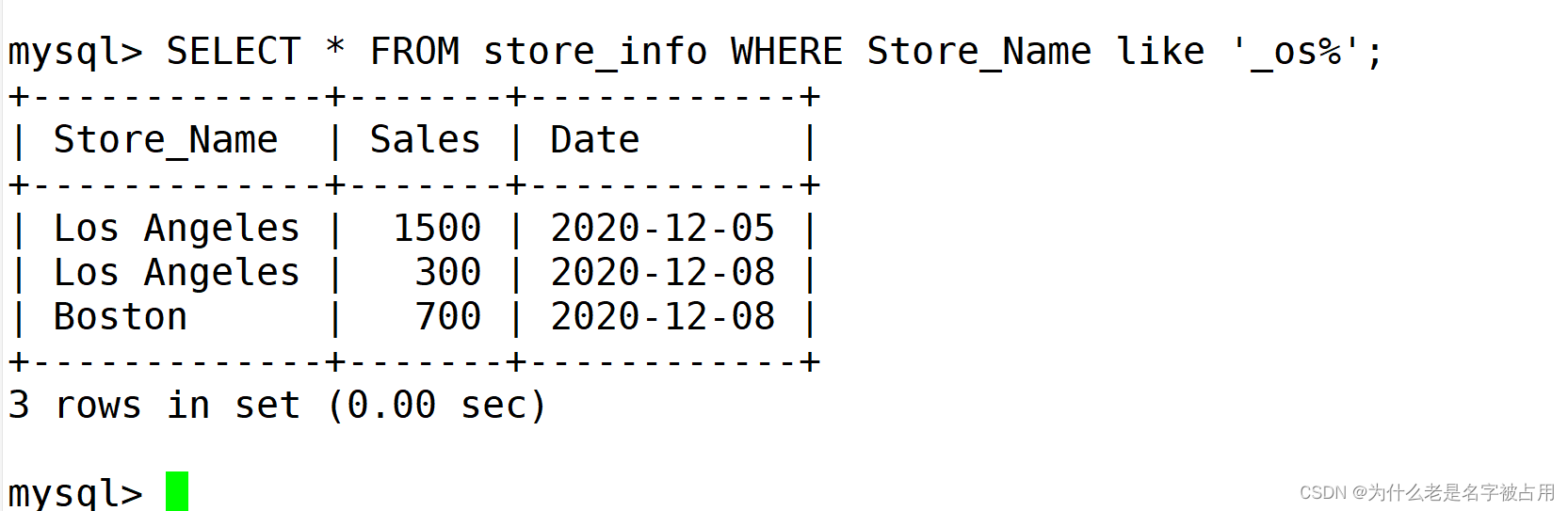
SELECT * FROM store_info WHERE Store_Name like '_os%';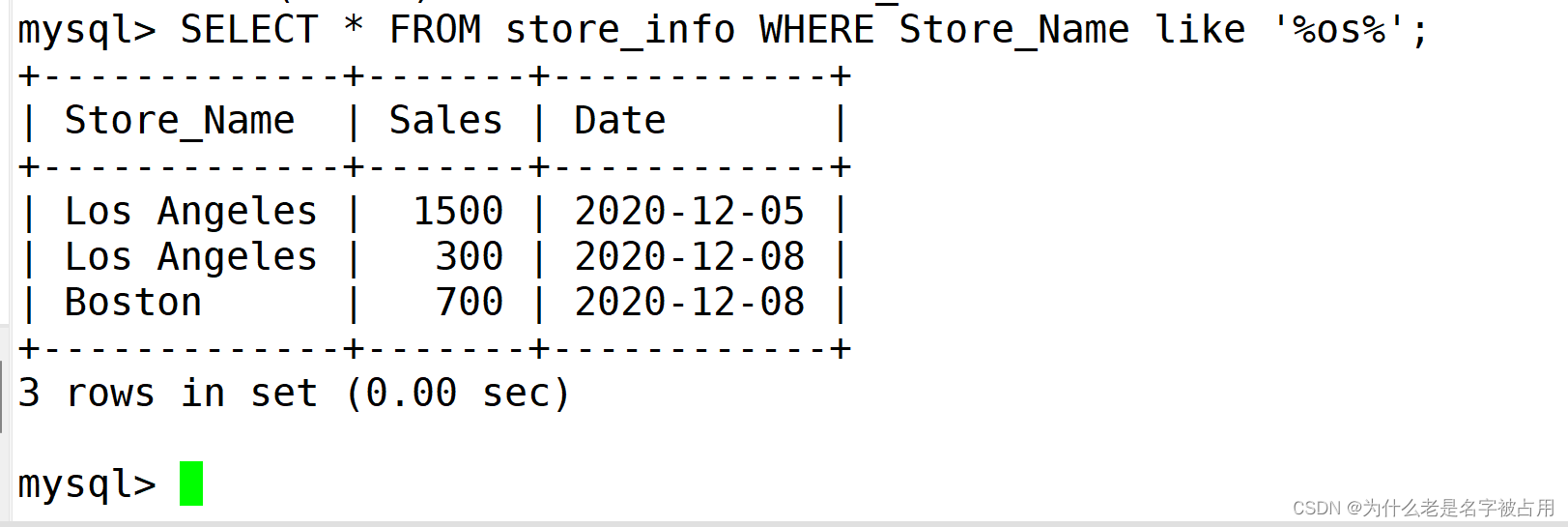
 1.8 排序方式进行查询
1.8 排序方式进行查询
order by,按关键字排序。
注意:
- 一般对数值字段进行排序。
- 如果对字符类型的字段进行排序,则会按首字母排序。
SELECT Store_Name,Sales,Date FROM store_info ORDER BY Sales DESC;
SELECT Store_Name,Sales,Date FROM store_info ORDER BY Sales asc;
#ASC是按照升序进行排序的,是默认的排序方式。#DESC是按降序方式进行排序。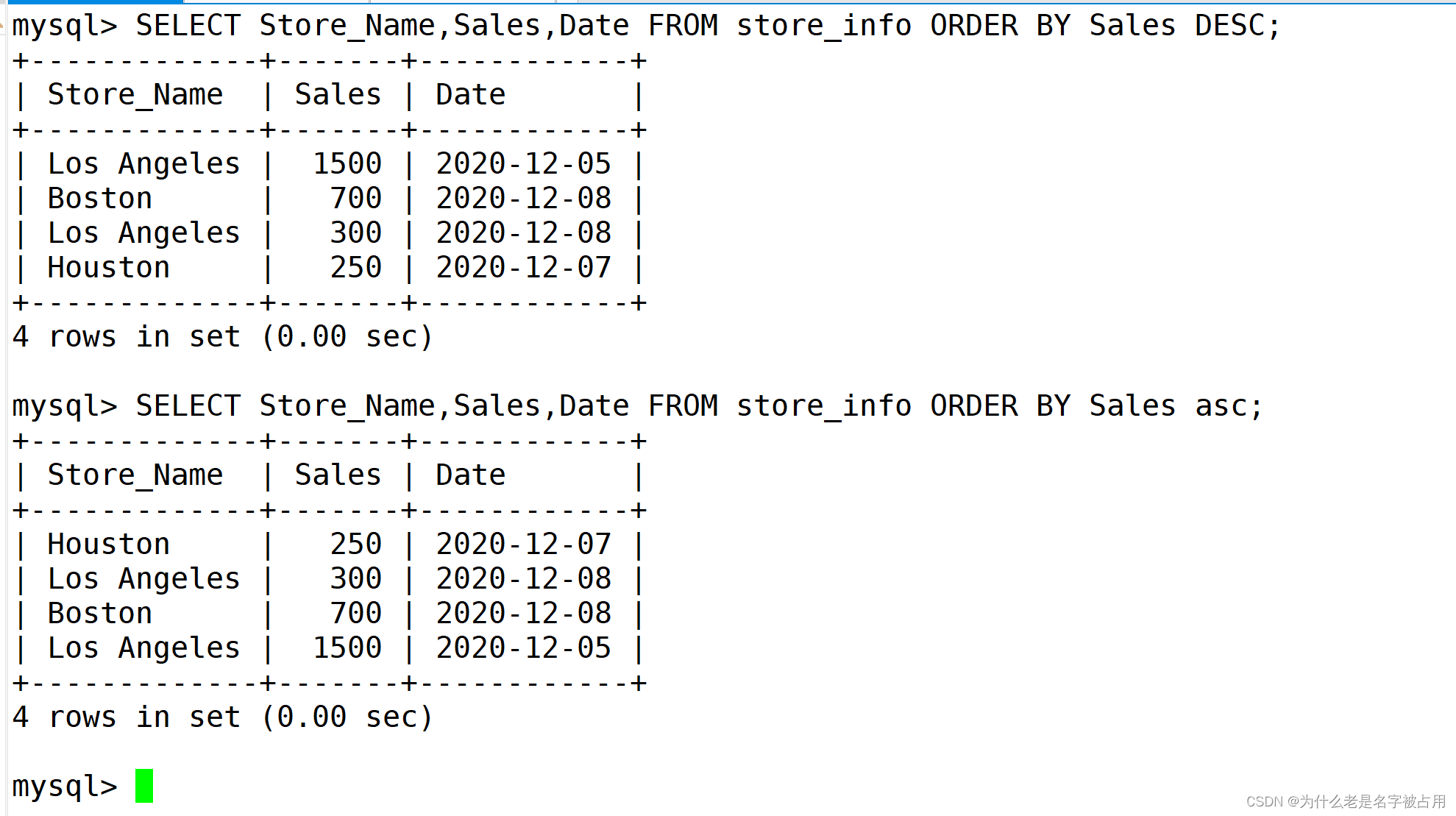 二、运用函数查询
二、运用函数查询
2.1 数据库中常用数学的函数
| 数学函数 | 作用 |
| abs(x) | 返回x的绝对值 |
| rand() | 返回0到1的随机数 |
| mod(x, y) | 返回x除以y以后的余数 |
| power(x, y) | 返回x的y次方 |
| round(x) | 返回离x最近的整数 |
| round(x, y) | 保留x的y位小数四舍五入后的值 |
| sqrt(x) | 返回x的平方根 |
| truncate(x, y) | 返回数字x截断为y位小数的值 #不四舍五入 |
| ceil(x) | 返回大于或等于x的最小整数 |
| floor(x) | 返回小于或等于x的最大整数 |
| greatest(x1,x2,...) | 返回集合中最大的值 |
| least(x1,x2,...) | 返回集合中最小的值 |
SELECT abs(-1), rand(), mod(5,3), power(2,3), round(1.89);
SELECT round(1.8937,3), truncate(1.235,2), ceil(5.2), floor(2.1), least(1.89,3,6.1,2.1);

2.2 聚合函数
| 聚合函数 | 含义 |
| avg() | 返回指定列的平均值 |
| count() | 返回指定列中非 NULL 值的个数 |
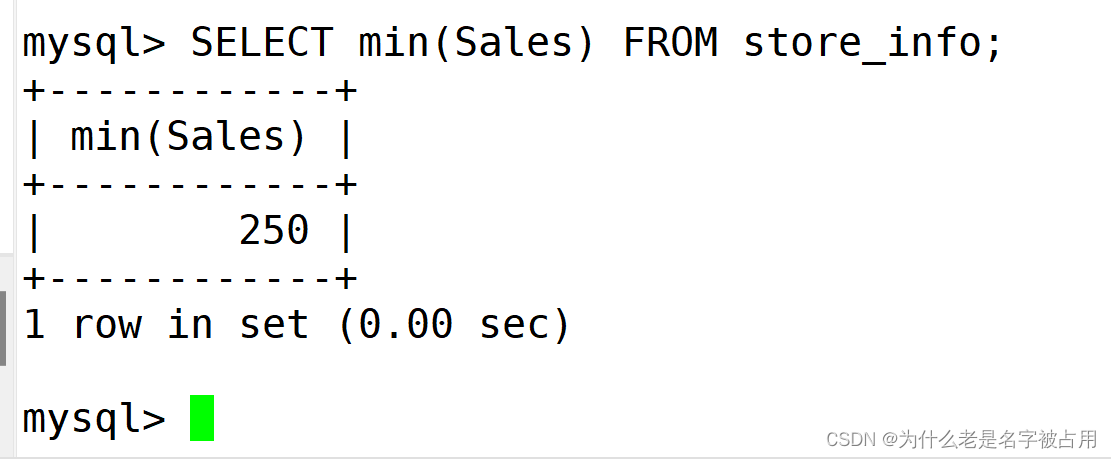
| min() | 返回指定列的最小值 |
| max() | 返回指定列的最大值 |
| sum(字段) | 返回指定列的所有值之和 |
SELECT avg(Sales) FROM Store_Info;
SELECT count(Store_Name) FROM store_info;
SELECT count(DISTINCT Store_Name) FROM Store_Info;SELECT max(Sales) FROM Store_Info;
SELECT min(Sales) FROM Store_Info;SELECT sum(Sales) FROM Store_Info;



2.3 字符串函数
| 字符串函数 | 作用 |
| trim() | 返回去除指定格式的值 |
| concat(x,y) | 将提供的参数 x 和 y 拼接成一个字符串 |
| substr(x,y) | 获取从字符串 x 中的第 y 个位置开始的字符串,跟substring()函数作用相同 |
| substr(x,y,z) | 获取从字符串 x 中的第 y 个位置开始长度为 z 的字符串 |
| length(x) | 返回字符串 x 的长度 |
| replace(x,y,z) | 将字符串 z 替代字符串 x 中的字符串 y |
| upper(x) | 将字符串 x 的所有字母变成大写字母 |
| lower(x) | 将字符串 x 的所有字母变成小写字母 |
| left(x,y) | 返回字符串 x 的前 y 个字符 |
| right(x,y) | 返回字符串 x 的后 y 个字符 |
| repeat(x,y) | 将字符串 x 重复 y 次 |
| space(x) | 返回 x 个空格 |
| strcmp(x,y) | 比较 x 和 y,返回的值可以为-1,0,1 |
| reverse(x) | 将字符串 x 反转 |
(1)去除字符 trim
SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);SELECT TRIM ([ [位置] [要移除的字符串] FROM ] 字符串);#[位置]:值可以为 LEADING (起头), TRAILING (结尾), BOTH (起头及结尾)。 #[要移除的字符串]:从字串的起头、结尾,或起头及结尾移除的字符串。缺省时为空格。
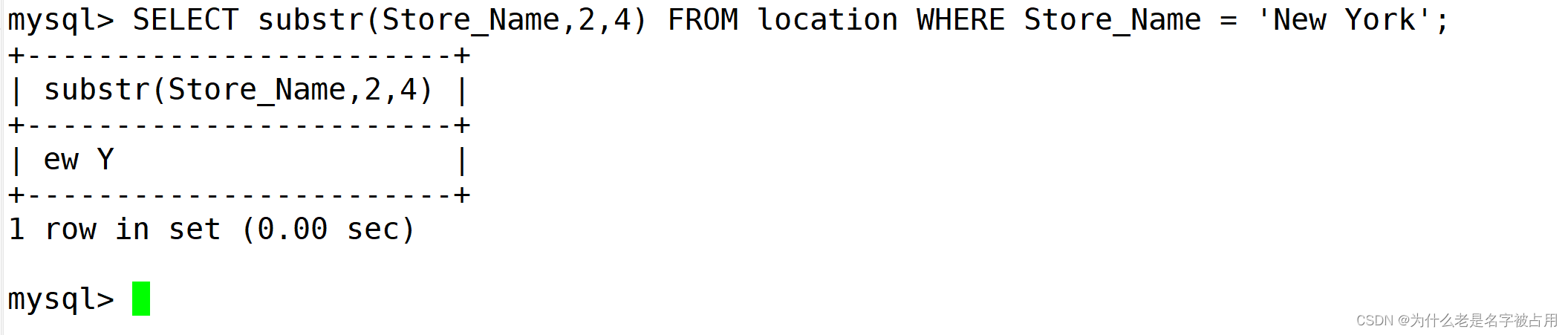
(2) 截取 substr
SELECT substr(Store_Name,3) FROM location WHERE Store_Name = 'Los Angeles';
SELECT substr(Store_Name,2,4) FROM location WHERE Store_Name = 'New York';
(3)字段拼接
1)concat(x,y)
SELECT concat(Region, Store_Name) FROM location WHERE Store_Name = 'Boston';
2)使用 || 符号
SELECT Region || ' ' || Store_Name FROM location WHERE Store_Name = 'Boston';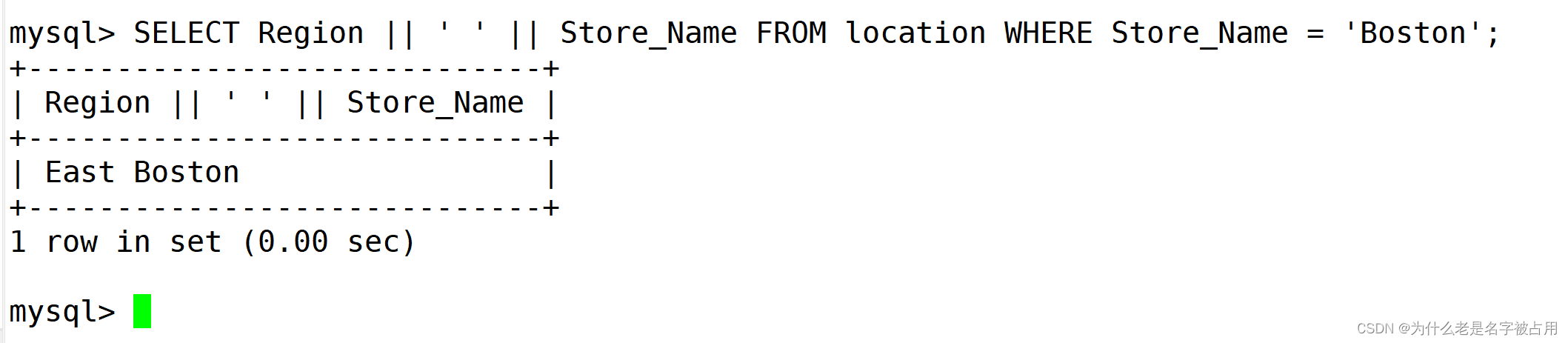
(4)返回字符长度 length
select length(name) from city;
(5)替换 replace
SELECT REPLACE(Region,'ast','astern')FROM location;
三、高级查询语句
3.1 GROUP BY(用于分组和汇总)
对GROUPBY后面的字段的查询结果进行汇总分组,通常是结合聚合函数一起使用的
"GROUP BY"有一个原则,凡是在"GROUP BY"后面出现的字段,必须在SELECT 后面出现;
凡是在SELECT 后面出现的、且未在聚合函数中出现的字段,必须出现在"GROUP BY"后面。
(1)汇总统计
select name, count(name) from city group by name;
(2)汇总并对其指定字段(数字类)进行累加
select name,sum(name) from city group by name;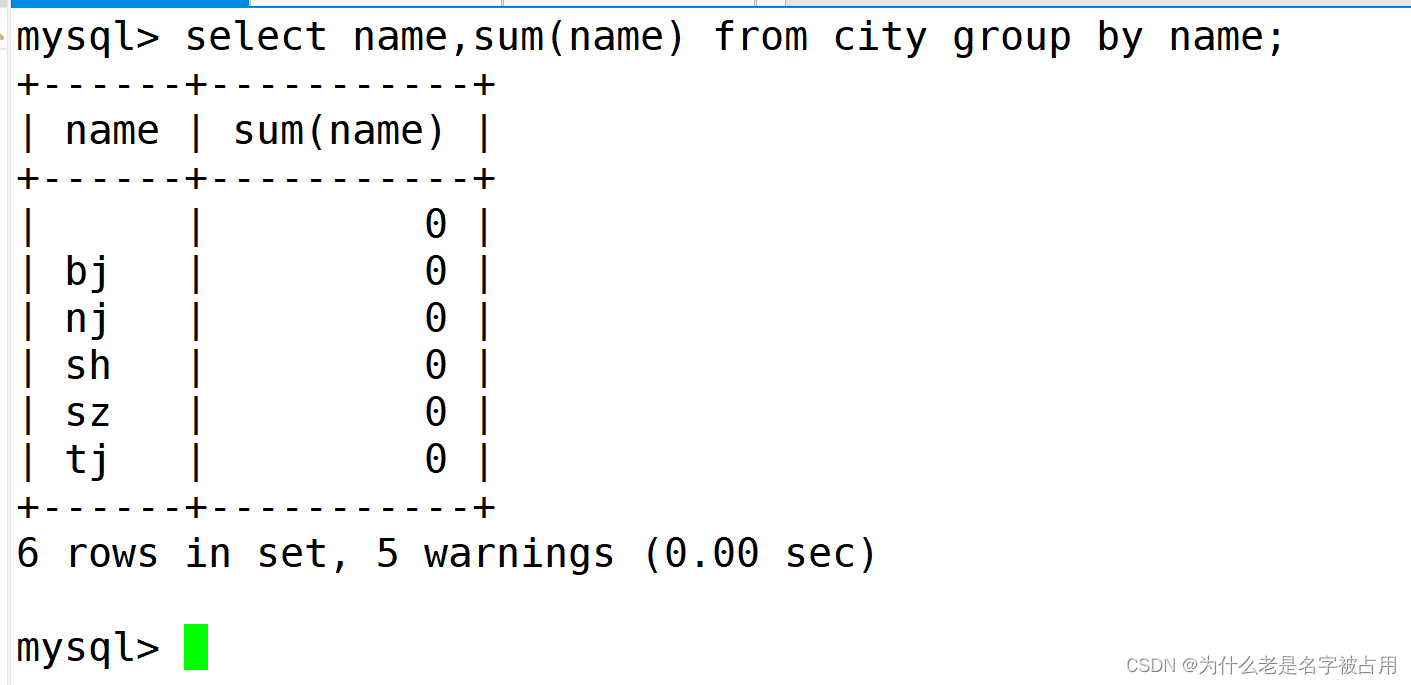
(3)汇总并对其指定字段(数字类)进行累加,再进行降序
select name,sum(name) from city group by name order by sum(name) desc;
3.2 HAVING 过滤
用来过滤由"GROUP BY"语句返回的记录集,通常与"GROUP BY"语句联合使用。
HAVING语句的存在弥补了WHERE 关键字不能与聚合函数联合使用的不足。
where只能对原表中的字段进行筛选,不能对group by后的结果进行筛选。
SELECT Store_Name, SUM(Sales) FROM store_info GROUP BY Store_Name HAVING SUM(Sales) > 1500;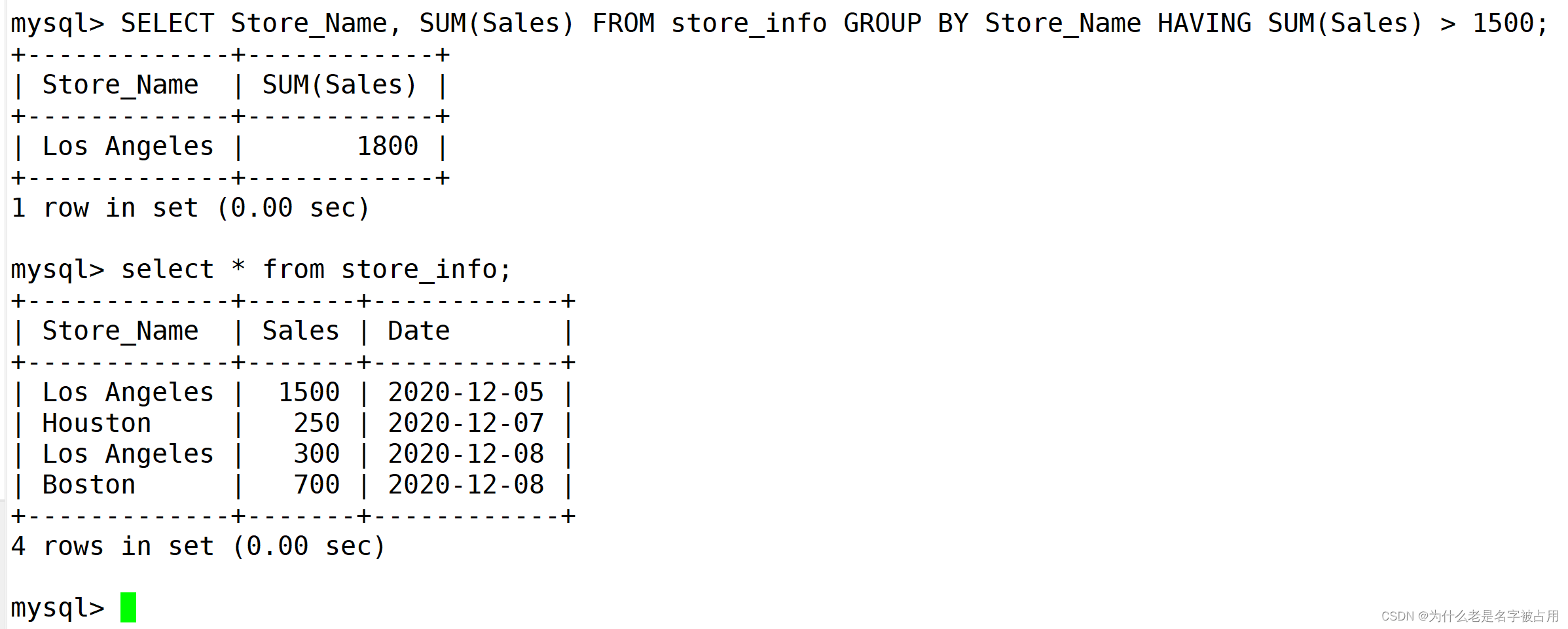
3.3 别名设置查询
语法格式:
SELECT 字段1,字段2 AS 字段2的别名 from 表名; #AS可以省略不写(1)字段别名
SELECT A.Store_Name Store, SUM(A.Sales) "Total Sales" FROM store_info A GROUP BY A.Store_Name;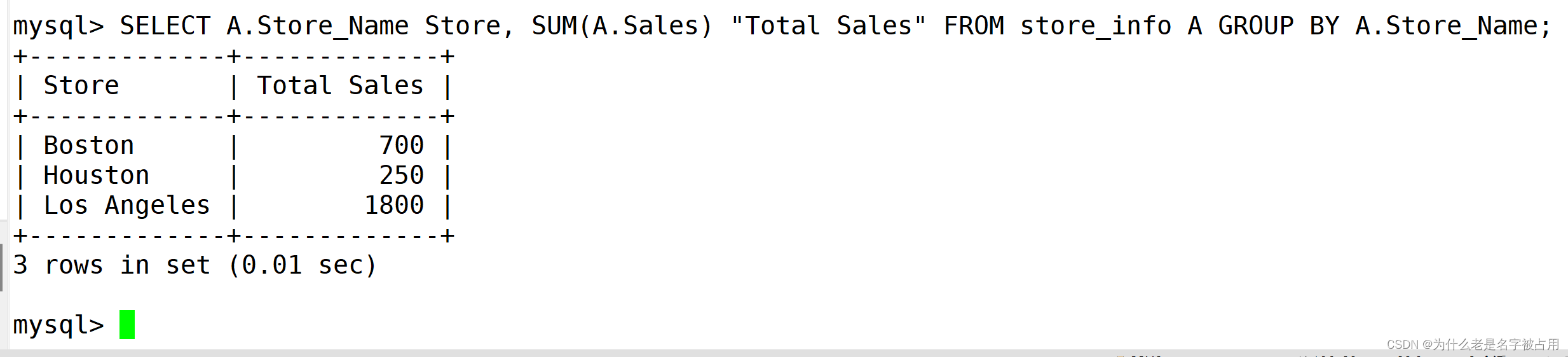 (2)表别名
(2)表别名
SELECT 表格别名.字段1 [AS] 字段别名 FROM 表格名 [AS] 表格别名; #AS可以省略不写3.4 子查询语句
子查询:连接表格,在WHERE 子句或HAVING 子句中插入另一个SQL语句。
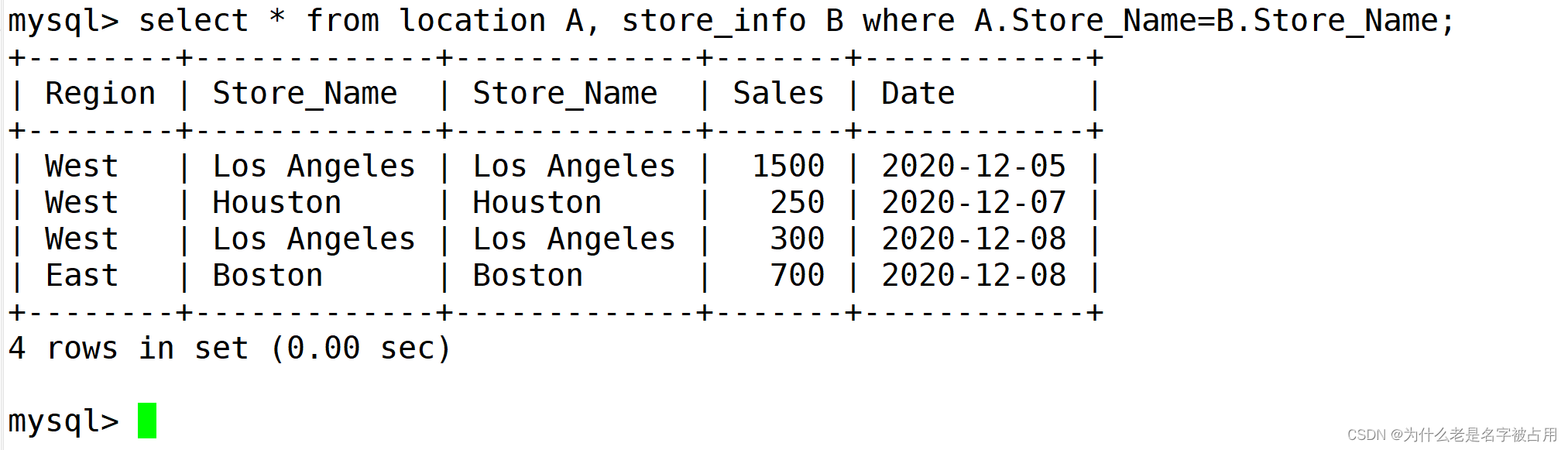
SELECT "字段1" FROM "表格1" WHERE "字段2" [比较运算符] #外查询(SELECT "字段1" FROM "表格2" WHERE "条件") ; #内查询普通的表数据连接:
select * from location A, store_info B where A.Store_Name=B.Store_Name;
子查询加入表连接 :
select * from store_info where Store_Name in(select Store_Name from location where Sales > 1000);
3.5 EXISTS
- 用来测试内查询有没有产生任何结果,类似布尔值是否为真。
- 如果内查询有结果的话,系统就会执行外查询中的SQL语句。若是没有结果的话,那整个SQL语句就不会产生任何结果。
格式:
SELECT "字段1" FROM "表格1" WHERE EXISTS (SELECT * FROM "表格2" WHERE "条件");SELECT SUM(Sales) FROM store_info WHERE EXISTS (SELECT * FROM location WHERE Region = 'West');
四、表连接查询
MYSQL数据库中常用的表连接有三种:
- inner join(内连接):只返回两个表中联结字段相等的行(有交集的值)
- left join(左连接):返回包括左表中的所有记录和右表中联结字段相等的记录
- A left join B : A为左表,B为右表
- right join(右连接):返回包括右表中的所有记录和左表中联结字段相等的记录
- A right join B: A为左表 ,B为右表
(1) 内连接 inner join
SELECT * FROM location A INNER JOIN store_info B on A.Store_Name = B.Store_Name ;
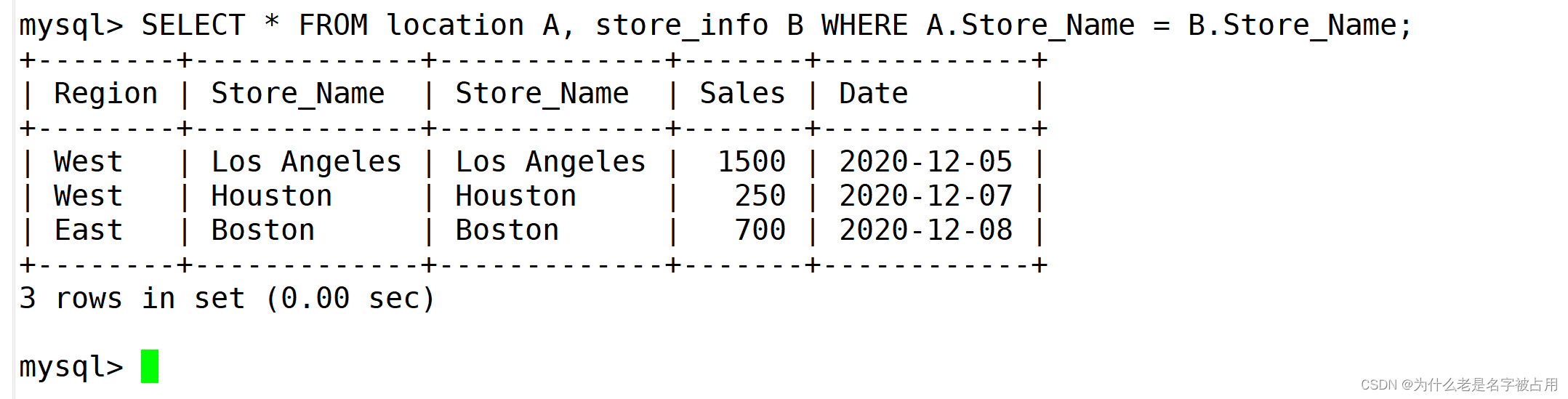
SELECT * FROM location A, store_info B WHERE A.Store_Name = B.Store_Name;
SELECT A.Region REGION, SUM(B.Sales) SALES FROM location A, store_info B
WHERE A.Store_Name = B.Store_Name GROUP BY REGION;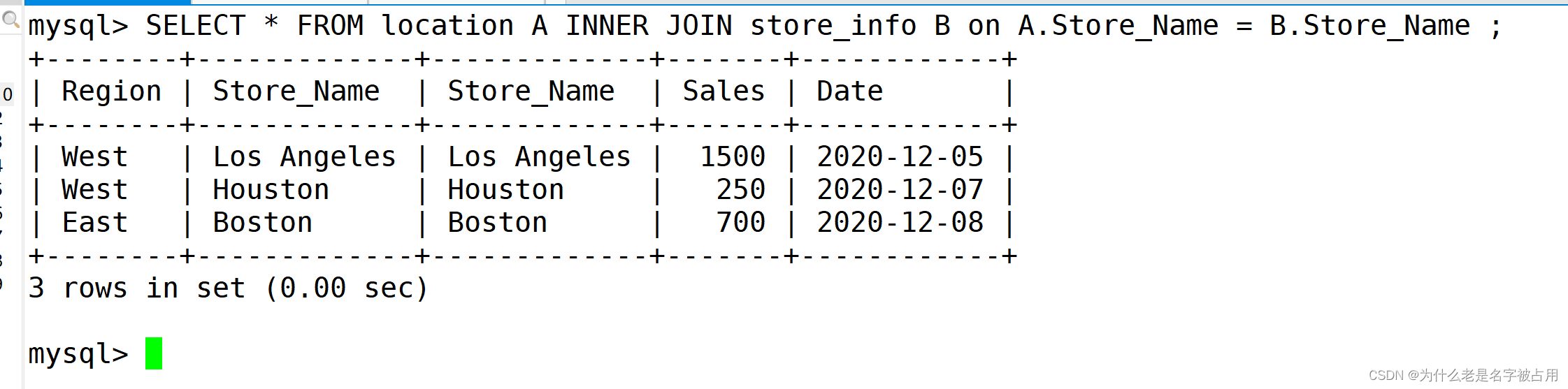
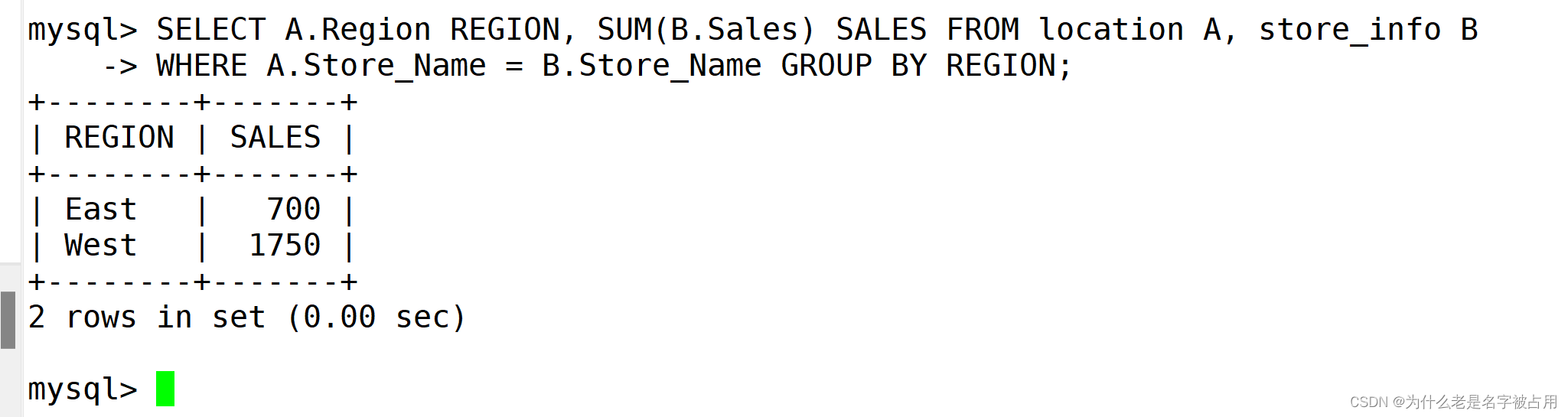
(2)左连接 left join
SELECT * FROM location A LEFT JOIN store_info B on A.Store_Name = B.Store_Name ;
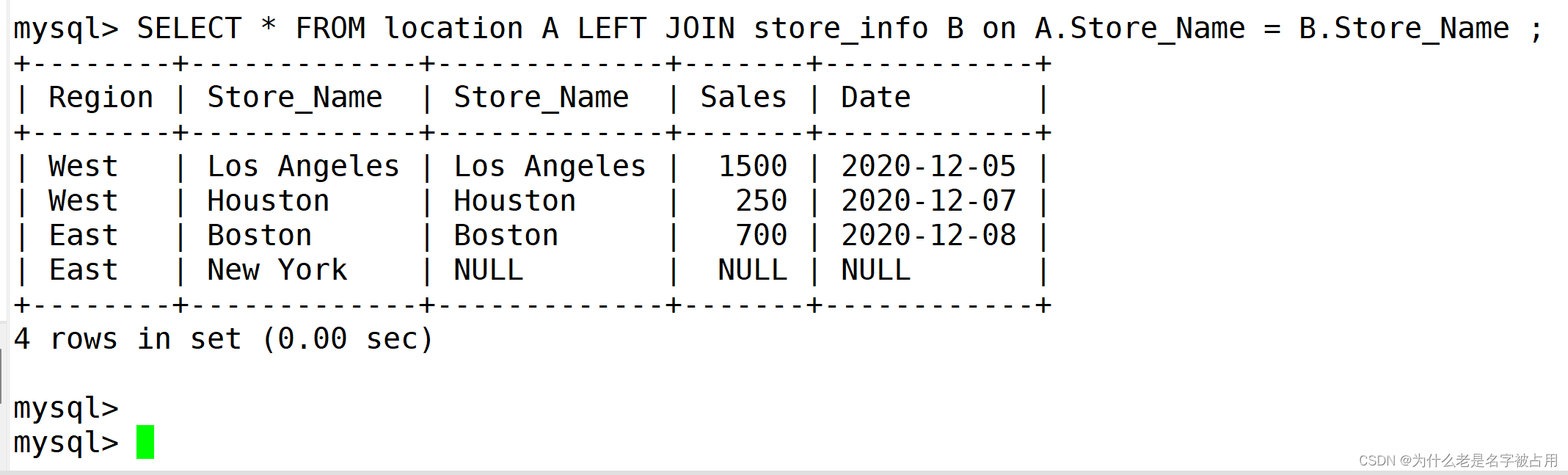
(3)右连接 left join
SELECT * FROM location A RIGHT JOIN store_info B on A.Store_Name = B.Store_Name ;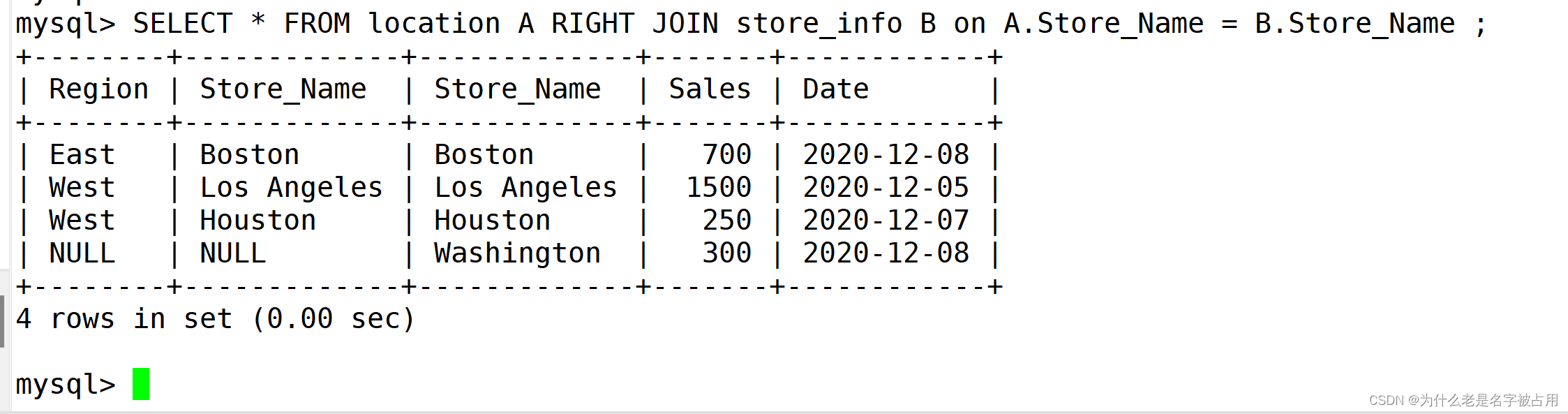
五、view 视图的运用
视图:可以被当作是虚拟表或存储查询。
- 视图跟表格的不同是,表格中有实际储存数据记录,而视图是建立在表格之上的一个架构,它本身并不实际储存数据记录。
- 临时表在用户退出或同数据库的连接断开后就自动消失了,而视图不会消失。
- 视图不含有数据,只存储它的定义,它的用途一般可以简化复杂的查询。 比如你要对几个表进行连接查询,而且还要进行统计排序等操作,写SQL语句会很麻烦的,用视图将几个表联结起来,然后对这个视图进行查询操作,就和对一个表查询一样,很方便。
格式:
CREATE VIEW "视图表名" AS "SELECT 语句"; #创建视图表DROP VIEW "视图表名"; #删除视图表(1)视图的创建
view V_sales as select store_namee,sum(sales) from store_info group by store_namme;

视图创建的数据验证:

(2) 视图提供的后续便捷操作
视图的好处:创建视图的过程虽然和高级查询语句(通过两个select语句进行组合条件划分生成派生表)一样,过程是复杂的,但是如果该查询操作是需要经常使用的,创建视图就很有必要,不仅能简化查询过程,还能对该查询进行进一步操作,而且十分简便。
select store_name from V_sales group by store_name having count(store_name) = 1;
(3)经典定义问题:视图能否插入数据
视图能否插入数据,要看情况而定:
1)如果视图表是两个表的连接查询(比如视图的A字段来自A表,B字段来自B表,数据是无法插入的)。因为表结构和原表不一致。视图中的字段是根据原表中某个字段,通过函数运算,产生的新字段,而没有真正能够存储的字段,所以该数据是无法插入的。
2)如果视图表结构与原表保持一致,数据是可以插入的,插入的数据是存储在原表中,视图所更新出的数据,其实是映射原表的数据。
六、UNION 联级
UNION联集:将两个SQL语句的结果合并起来,两个SQL语句所产生的字段需要是同样的数据记录种类。
6.1 UNION(合并后去重)
生成结果的数据记录值将没有重复,且按照字段的顺序进行排序。#合并后去重
格式:[select 语句1] UNION [select 语句2];
SELECT Store_Name FROM location UNION SELECT Store_Name FROM store_info;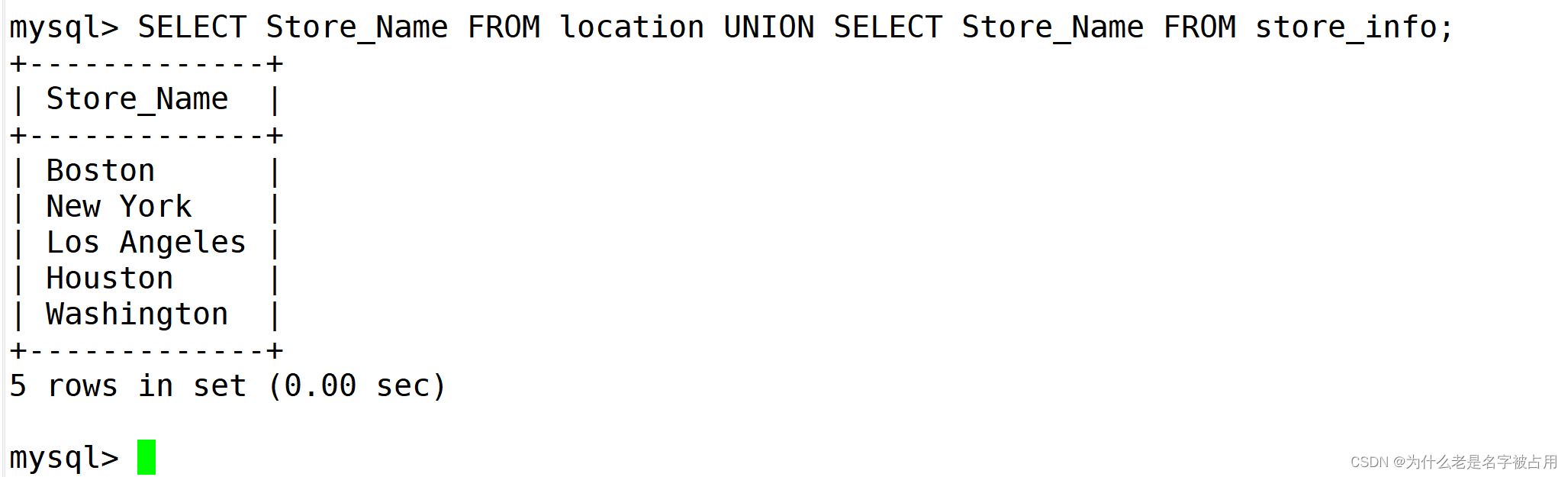
6.2 UNION ALL(合并后不去重)
SELECT Store_Name FROM location UNION ALL SELECT Store_Name FROM store_info;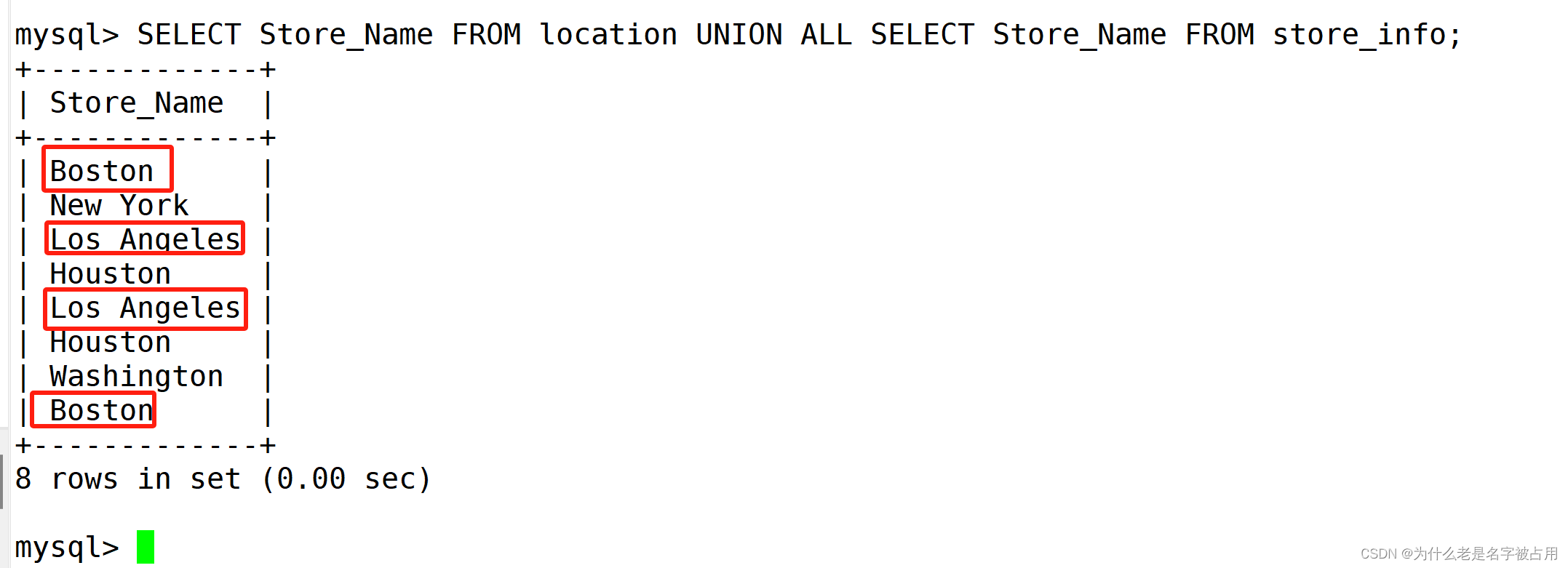
七、交集值与无交集值
7.1 求交集值
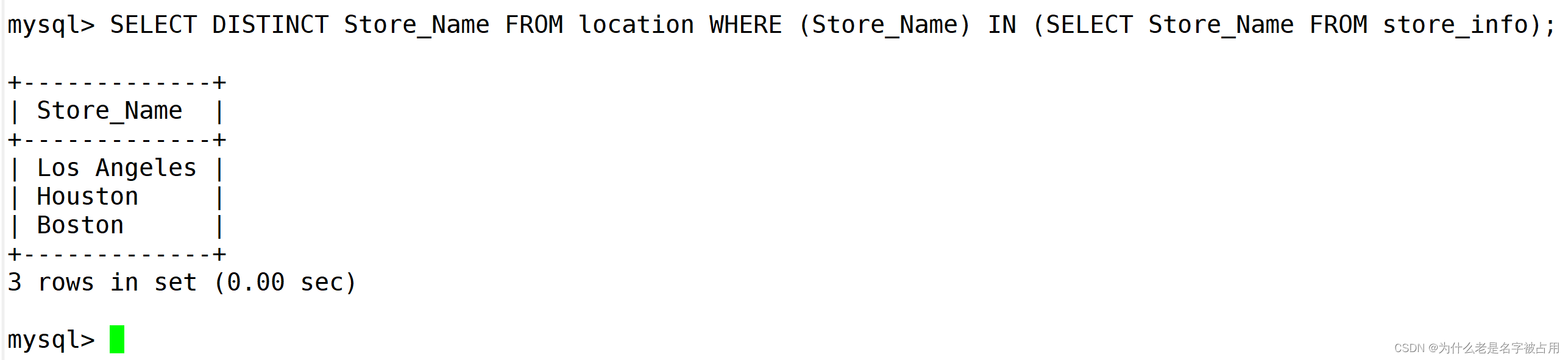
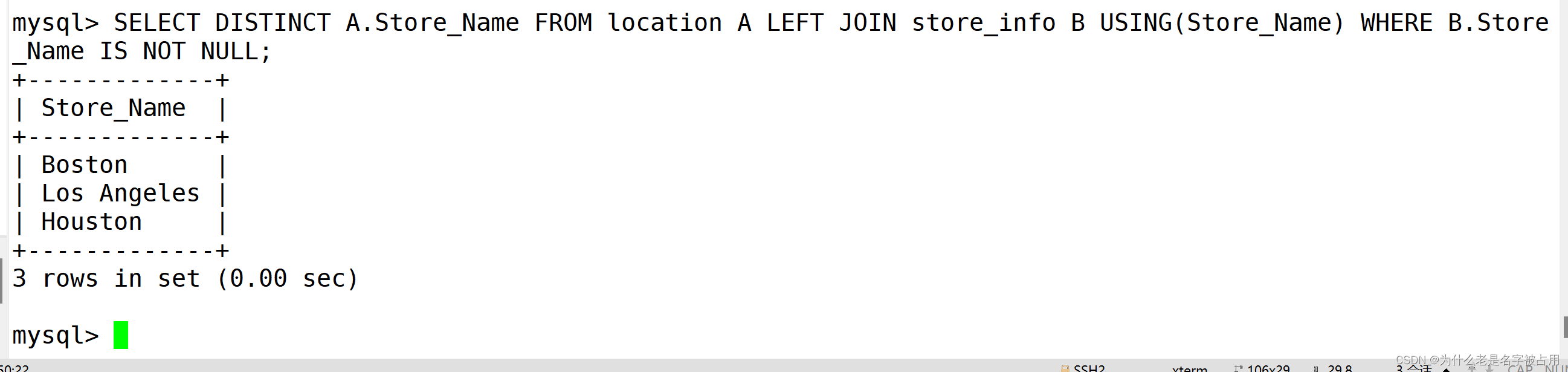
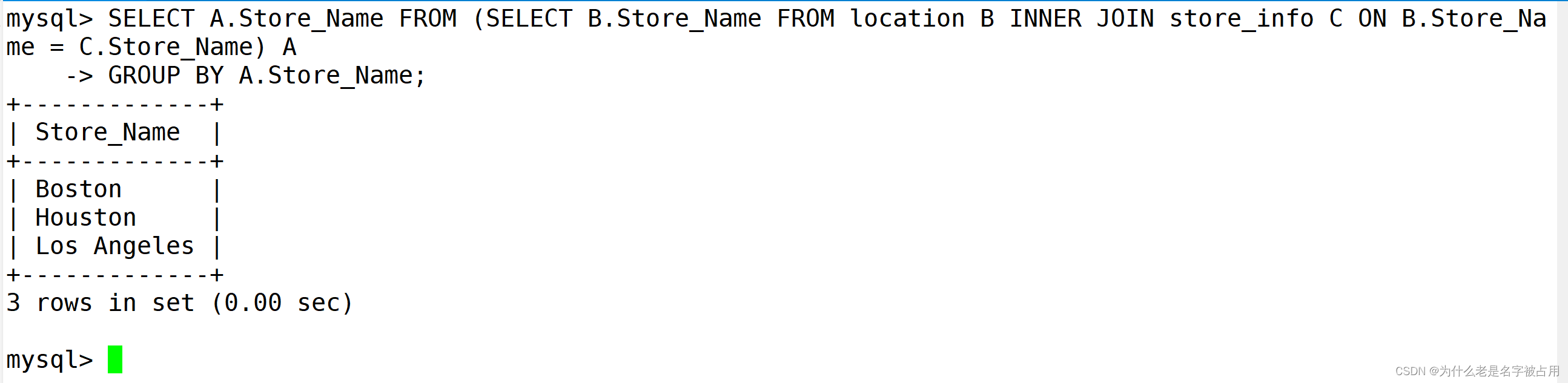
SELECT DISTINCT A.Store_Name FROM location A INNER JOIN store_info B USING(Store_Name);SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) IN (SELECT Store_Name FROM store_info);SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NOT NULL;SELECT A.Store_Name FROM (SELECT B.Store_Name FROM location B INNER JOIN store_info C ON B.Store_Name = C.Store_Name) A
GROUP BY A.Store_Name;SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A.Store_Name HAVING COUNT(*) > 1;

7.2 求无交集值
SELECT DISTINCT Store_Name FROM location WHERE (Store_Name) NOT IN (SELECT Store_Name FROM store_info);SELECT DISTINCT A.Store_Name FROM location A LEFT JOIN store_info B USING(Store_Name) WHERE B.Store_Name IS NULL;SELECT A.Store_Name FROM
(SELECT DISTINCT Store_Name FROM location UNION ALL SELECT DISTINCT Store_Name FROM store_info) A
GROUP BY A.Store_Name HAVING COUNT(*) = 1;


相关文章:
[MySQL] MySQL 高级(进阶) SQL 语句
一、高效查询方式 1.1 指定指字段进行查看 事先准备好两张表 select 字段1,字段2 from 表名; 1.2 对字段进行去重查看 SELECT DISTINCT "字段" FROM "表名"; 1.3 where条件查询 SELECT "字段" FROM 表名" WHERE "条件…...
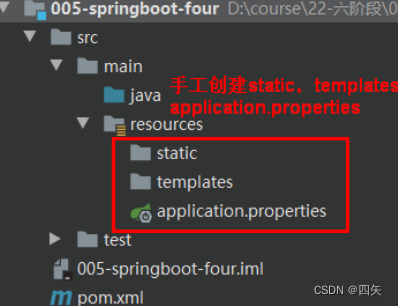
创建springboot项目
SpringBoot 就相当于不需要配置文件的SpringSpringMVC。 常用的框架和第三方库都已经配置好了。 maven安装配置 管理项目依赖库的 maven的安装教程网上有很多,这里简单记录一下。 官网下载maven后并解压。 在其目录下添加一个目录repository 然后在conf目录下…...
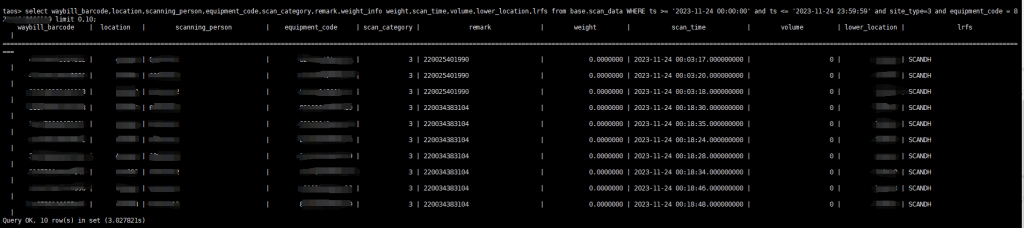
“双十一、二” 业务高峰如何扛住?韵达快递选择 TDengine
小 T 导读: 为了有效处理每日亿级的数据量,早在 2021 年,韵达就选择用 TDengine 替代了 MySQL,并在三台服务器上成功部署和上线了 TDengine 2.0 集群。如今,随着 TDengine 3.0 版本的逐渐成熟,韵达决定将现…...

STM32L432+LIS3DH【加速度传感器】:端侧AI
一、搜集芯片资料 1.LIS3DHTR:加速度传感器 查找链接: https://www.st.com/zh/mems-and-sensors/lis3dh.html 2. NUCLEO-L432KC:芯片 查找连接: https://www.st.com/zh/evaluation-tools/nucleo-l432kc.html#cad-resources 1.原理图 引…...
)
VCG Mesh刚性旋转(变换矩阵)
文章目录 一、简介二、实现代码三、实现效果参考资料一、简介 旋转矩阵如果从线性空间的角度来看,它类似于一个投影过程。假设坐标 P ( x 1 , y 1 , z 1 ) P(x_1,y_1,z_1)...
 在软件包等中查找文件的完整文件名。)
R语言【base】——system.file() 在软件包等中查找文件的完整文件名。
Package base version 4.3.2 Parameters system.file(..., package "base", lib.loc NULL,mustWork FALSE) 参数【...】:字符向量,指定某个软件包中的子目录和文件。默认情况下,没有值则返回软件包的根目录。不支持通配符。 …...

HTML制作暴雨特效
🎀效果展示 🎀代码展示 <body> <!-- partial:index.partial.html --> <canvas id="canvas-club">...
cesium实现区域贴图及加载多个gif动图
1、cesium加载多个gif动图 Cesium的Billboard支持单帧纹理贴图,如果能够将gif动图进行解析,获得时间序列对应的每帧图片,然后按照时间序列动态更新Billboard的纹理,即可实现动图纹理效果。为此也找到了相对于好一点的第三方库libg…...
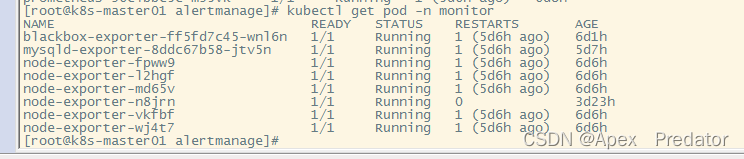
blackbox黑盒监控部署(k8s内)tensuns专用
一、前言 部署在k8s中需要用到deployment、configmap、service服务 二、部署 创建存放yaml的目录 mkdir /opt/blackbox-exporter && cd /opt/blackbox-exporter 编辑blackbox配置文件,使用configmap挂在这 vi configmap.yaml apiVersion: v1 kind: Confi…...

“C语言“——scanf()、getchar() 、putchar()、之间的关系
scanf函数说明 scanf函数是对来自于标准输入流的输入数据作格式转换,并将转换结果保存至format后面的实参所指向的对象。 而const char*format 指向的字符串为格式控制字符串,它指定了可输入的字符串以及赋值时转换方法。 简单来说给一个打印格式(输入…...
Spring Boot3 Web开发技术
前期回顾 springboot项目常见的配置文件类型有哪些?哪种类型的优先级最高 yml properties yaml 读取配置文件里的数据用什么注解? value restful风格 RESTful 风格与传统的 HTTP 请求方式相比,更加简洁,安全,能隐…...
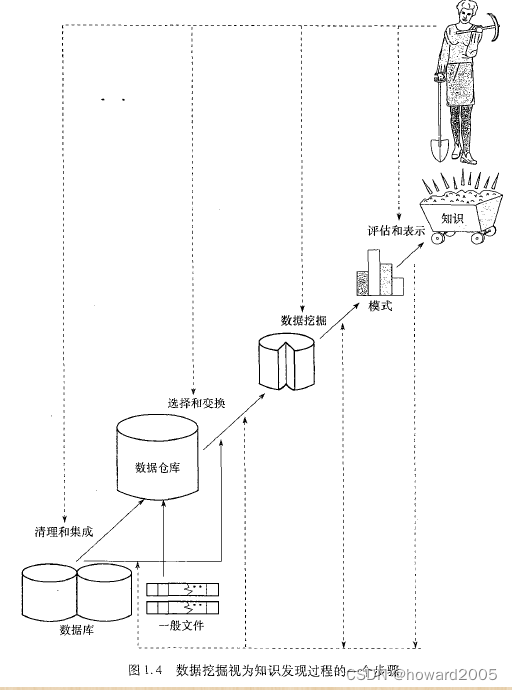
学习笔记:数据挖掘与机器学习
文章目录 一、数据挖掘、机器学习、深度学习的区别(一)数据挖掘(二)机器学习(三)深度学习(四)总结 二、数据挖掘体系三、数据挖掘的流程四、典型的数据挖掘系统 一、数据挖掘、机器学…...
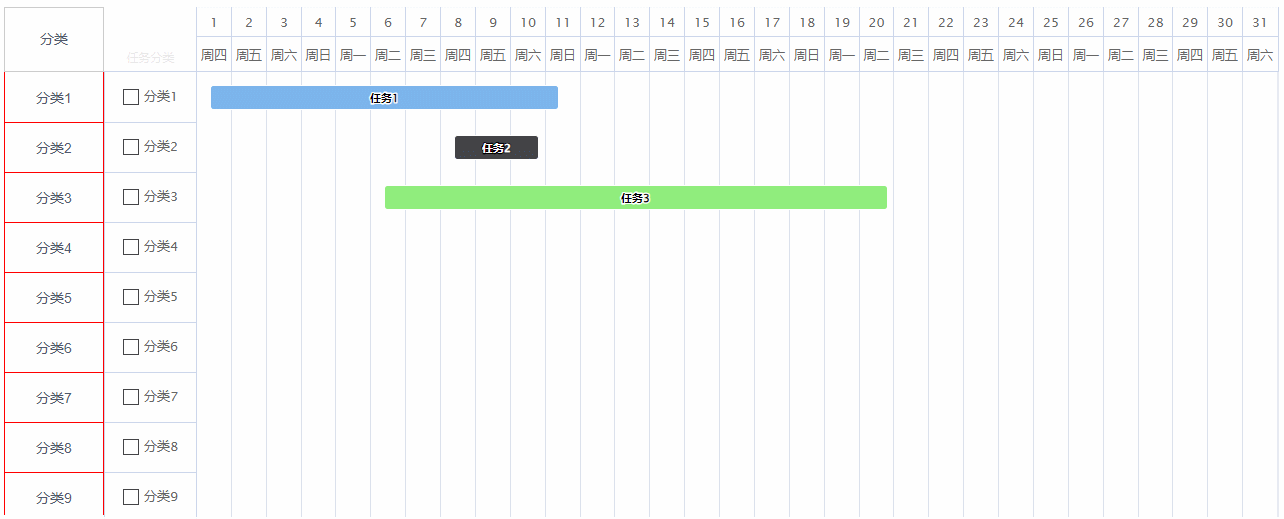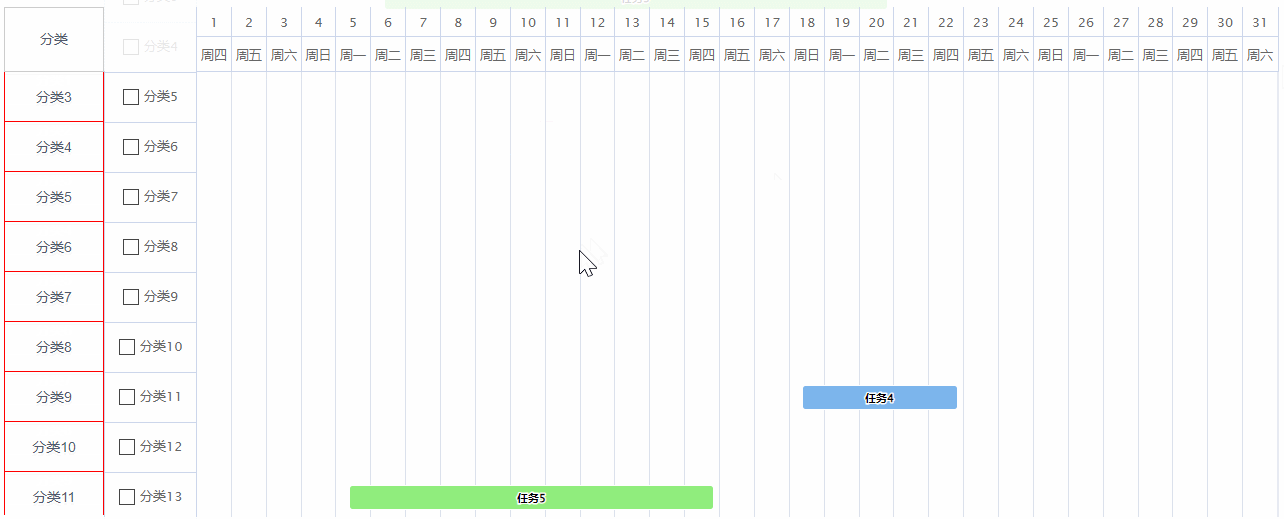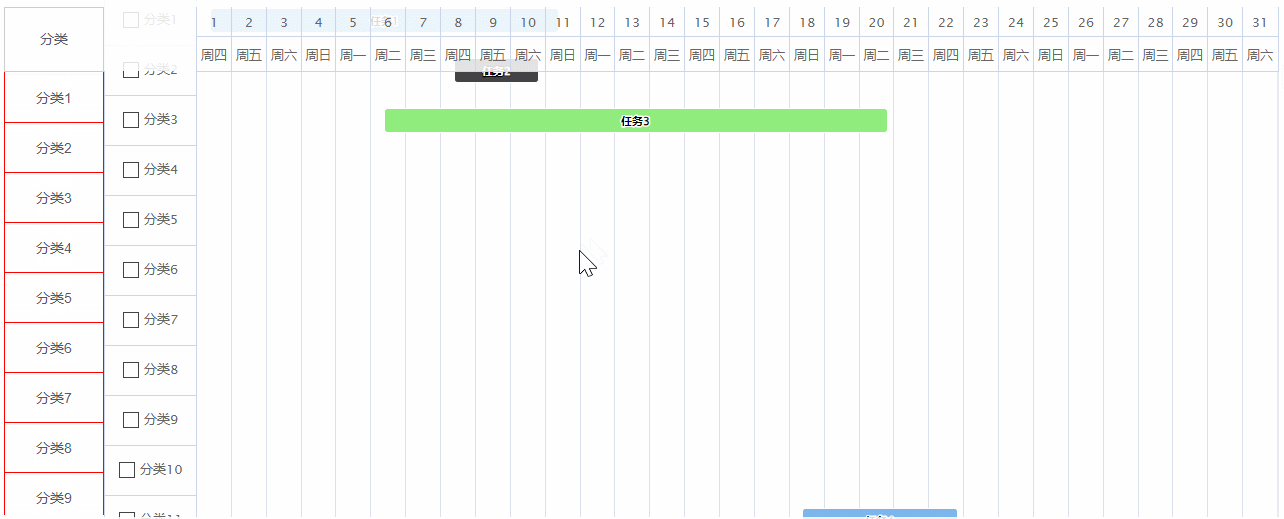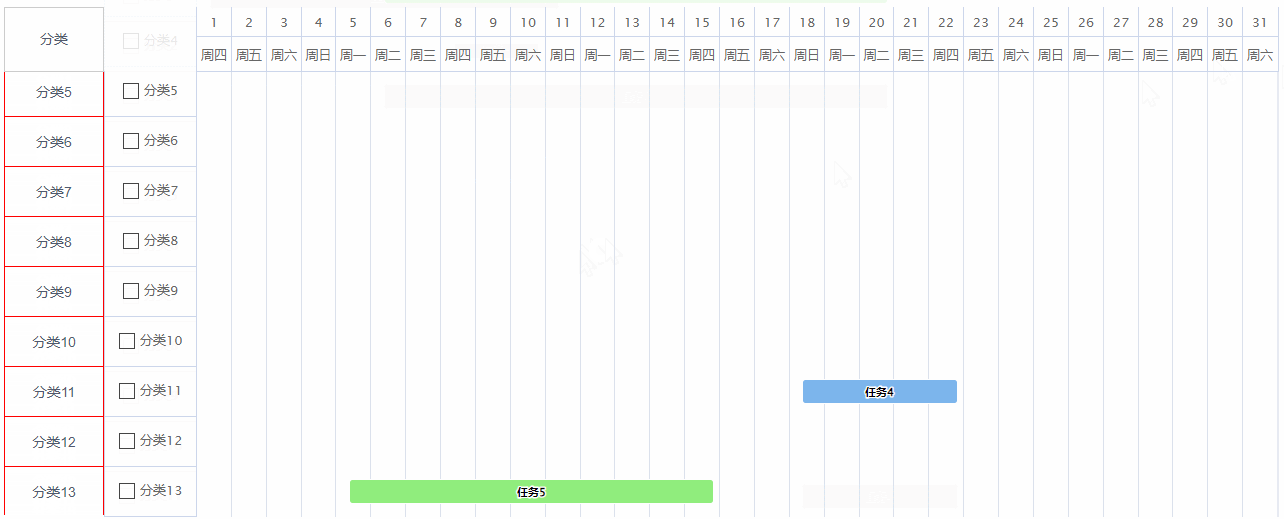
highcharts的甘特图设置滚动时表头固定,让其他内容跟随滚动
效果图:最左侧的分类列是跟随甘特图滚动的,因为这一列如果需要自定义,比如表格的话可能会存在行合并的情况,这个时候甘特图是没有办法做的,然后甘特图的表头又需要做滚动时固定,所以设置了甘特图滚动时&…...
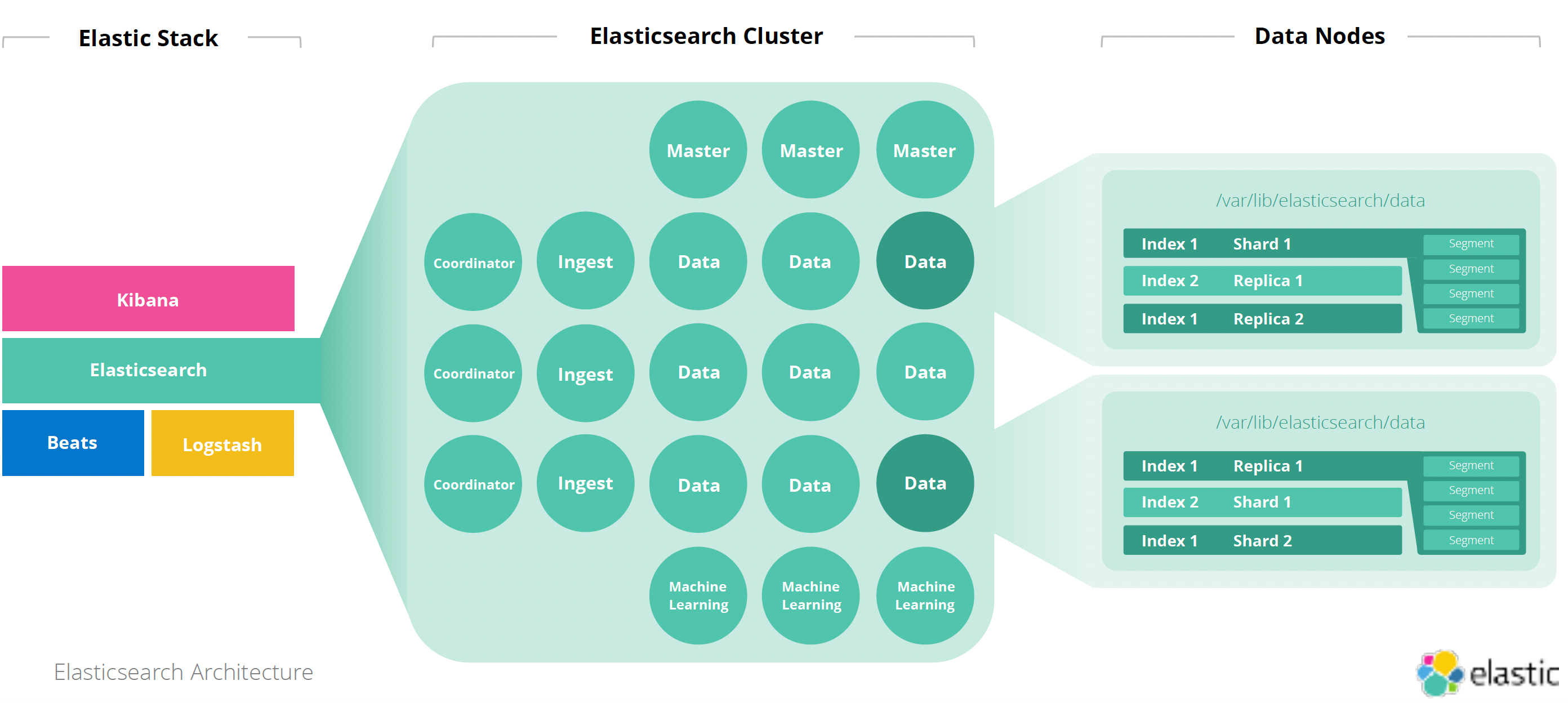
ElasticSearch 架构设计
介绍 ElasticSearchMySQLIndexTableDocumentRowFieldColumnMappingSchemaQuery DSLSQLaggregationsgroup by,avg,sumcardinality去重 distinctreindex数据迁移 ElasticSearch 中的一个索引由一个或多个分片组成 每个分片包含多个 segment(分…...
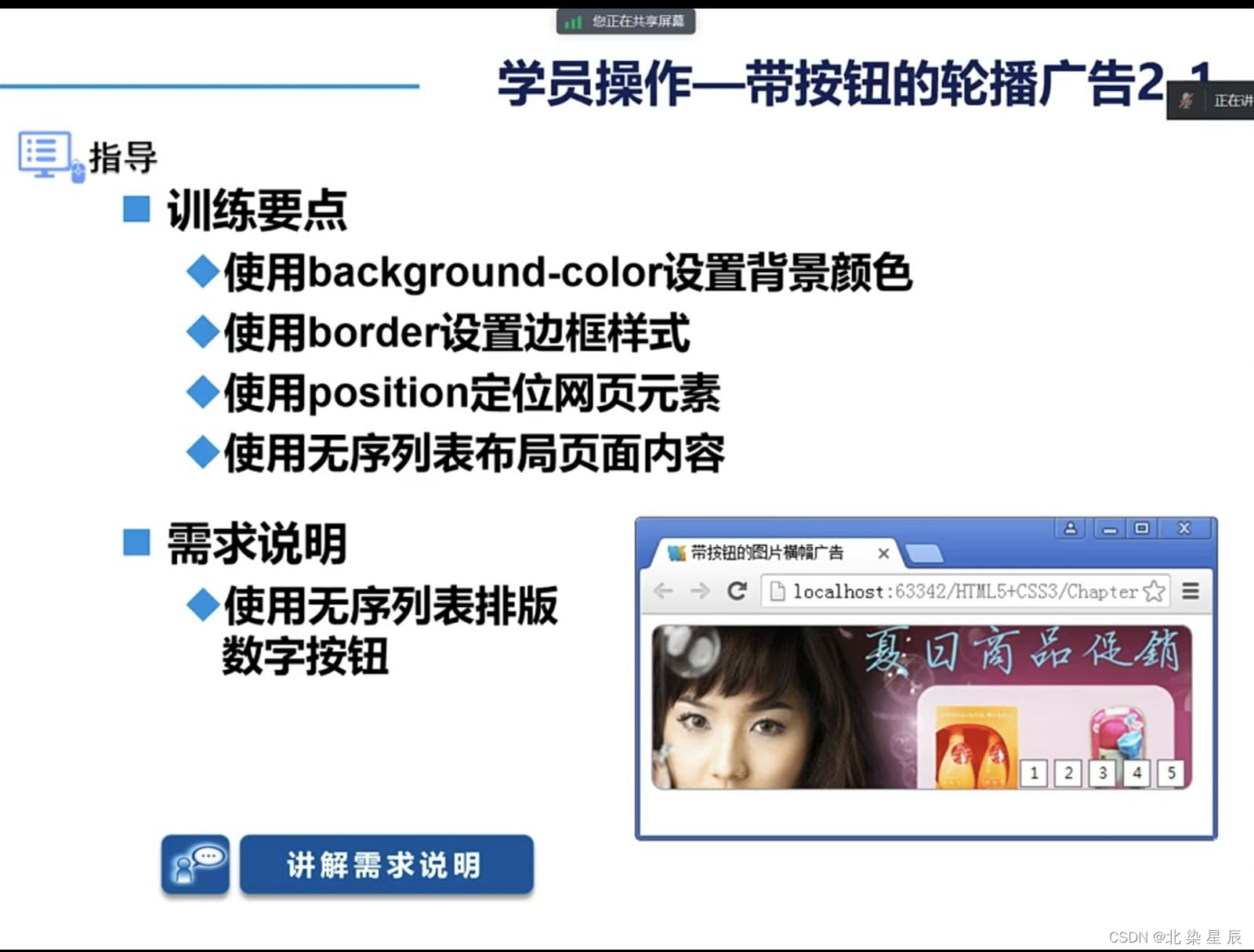
HTML---定位
目录 文章目录 一.定位属性概述 二.position 基础数值 三.z-index属性 网页元素透明度 练习 一.定位属性概述 HTML中的定位属性指的是用来控制HTML元素在页面中的位置和布局的属性,包括position、top、bottom、left和right等。 position属性指定了元素的定位方式&a…...

JVM高频面试题(2023最新版)
JVM面试题 1、JVM内存区域 Jvm包含两个子系统和两个组件。 1.1子系统 Class loader(类加载器):根据给定的全限定名类名(java.lang.object)来装载class文件到Runtime data area(运行时数据区)…...
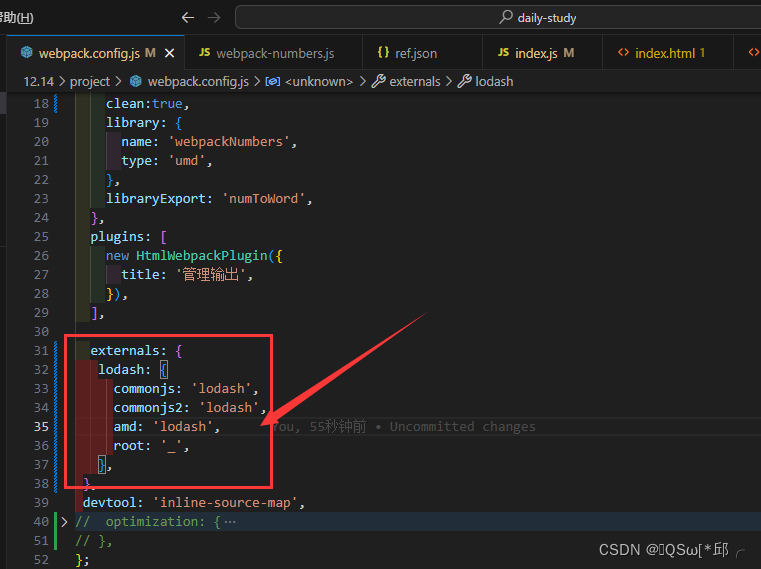
webpack学习-7.创建库
webpack学习-7.创建库 1.暴露库1.1概念1.2验证1.2.1 不导出方法1.2.2 导出方法 2.外部化 lodash3.外部化的限制4.最终步骤5.使用自己的库5.1坑 6.总结 1.暴露库 这个模块学习有点坑。看名字就是把自己写的个包传到npm,而且还要在项目中使用到它,支持各种…...

MQTT - 笔记
1 Mosquitto 官网 https://mosquitto.org/ 2 Windows环境下安装配置Mosquitto服务及入门操作介绍 Windows环境下安装配置Mosquitto服务及入门操作介绍-CSDN博客 3 开源:MQTT安装与配置使用 【C++】开源:MQTT安装与配置使用_c++ mqtt-CSDN博客 4 一文搞懂Qt-MQTT开发...

Django 安装
各位小伙伴想要博客相关资料的话,关注公众号:chuanyeTry即可领取相关资料! Django 安装 在安装 Django 前,系统需要已经安装了 Python 的开发环境。 如果你还没有安装 Python,请先从 Python 官网 https://www.python…...
推荐一个vscode看着比较舒服的主题:Dark High Contrast
主题名称:Dark High Contrast (意思就是,黑色的,高反差的) 步骤:设置→Themes→Color Theme→Dark High Contrast 效果如下: 感觉这个颜色的看起来比较舒服。...
: K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?)
云原生核心技术 (7/12): K8s 核心概念白话解读(上):Pod 和 Deployment 究竟是什么?
大家好,欢迎来到《云原生核心技术》系列的第七篇! 在上一篇,我们成功地使用 Minikube 或 kind 在自己的电脑上搭建起了一个迷你但功能完备的 Kubernetes 集群。现在,我们就像一个拥有了一块崭新数字土地的农场主,是时…...

Linux相关概念和易错知识点(42)(TCP的连接管理、可靠性、面临复杂网络的处理)
目录 1.TCP的连接管理机制(1)三次握手①握手过程②对握手过程的理解 (2)四次挥手(3)握手和挥手的触发(4)状态切换①挥手过程中状态的切换②握手过程中状态的切换 2.TCP的可靠性&…...

【Redis技术进阶之路】「原理分析系列开篇」分析客户端和服务端网络诵信交互实现(服务端执行命令请求的过程 - 初始化服务器)
服务端执行命令请求的过程 【专栏简介】【技术大纲】【专栏目标】【目标人群】1. Redis爱好者与社区成员2. 后端开发和系统架构师3. 计算机专业的本科生及研究生 初始化服务器1. 初始化服务器状态结构初始化RedisServer变量 2. 加载相关系统配置和用户配置参数定制化配置参数案…...

Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility
Cilium动手实验室: 精通之旅---20.Isovalent Enterprise for Cilium: Zero Trust Visibility 1. 实验室环境1.1 实验室环境1.2 小测试 2. The Endor System2.1 部署应用2.2 检查现有策略 3. Cilium 策略实体3.1 创建 allow-all 网络策略3.2 在 Hubble CLI 中验证网络策略源3.3 …...
【机器视觉】单目测距——运动结构恢复
ps:图是随便找的,为了凑个封面 前言 在前面对光流法进行进一步改进,希望将2D光流推广至3D场景流时,发现2D转3D过程中存在尺度歧义问题,需要补全摄像头拍摄图像中缺失的深度信息,否则解空间不收敛…...

Auto-Coder使用GPT-4o完成:在用TabPFN这个模型构建一个预测未来3天涨跌的分类任务
通过akshare库,获取股票数据,并生成TabPFN这个模型 可以识别、处理的格式,写一个完整的预处理示例,并构建一个预测未来 3 天股价涨跌的分类任务 用TabPFN这个模型构建一个预测未来 3 天股价涨跌的分类任务,进行预测并输…...

跨链模式:多链互操作架构与性能扩展方案
跨链模式:多链互操作架构与性能扩展方案 ——构建下一代区块链互联网的技术基石 一、跨链架构的核心范式演进 1. 分层协议栈:模块化解耦设计 现代跨链系统采用分层协议栈实现灵活扩展(H2Cross架构): 适配层…...

鱼香ros docker配置镜像报错:https://registry-1.docker.io/v2/
使用鱼香ros一件安装docker时的https://registry-1.docker.io/v2/问题 一键安装指令 wget http://fishros.com/install -O fishros && . fishros出现问题:docker pull 失败 网络不同,需要使用镜像源 按照如下步骤操作 sudo vi /etc/docker/dae…...

学校时钟系统,标准考场时钟系统,AI亮相2025高考,赛思时钟系统为教育公平筑起“精准防线”
2025年#高考 将在近日拉开帷幕,#AI 监考一度冲上热搜。当AI深度融入高考,#时间同步 不再是辅助功能,而是决定AI监考系统成败的“生命线”。 AI亮相2025高考,40种异常行为0.5秒精准识别 2025年高考即将拉开帷幕,江西、…...

return this;返回的是谁
一个审批系统的示例来演示责任链模式的实现。假设公司需要处理不同金额的采购申请,不同级别的经理有不同的审批权限: // 抽象处理者:审批者 abstract class Approver {protected Approver successor; // 下一个处理者// 设置下一个处理者pub…...