Hadoop集群找不到native-hadoop
1.问题描述
========hive 运行中的问题,需要把把native复制进去 /usr/lib
2023-02-15 19:59:42,165 WARN scheduler.TaskSetManager: Lost task 11.0 in stage 1.0 (TID 3, common4, executor 2): java.lang.RuntimeException: Hive Runtime Error while closing operators: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.exec.spark.SparkReduceRecordHandler.close(SparkReduceRecordHandler.java:626)
at org.apache.hadoop.hive.ql.exec.spark.HiveReduceFunctionResultList.closeRecordProcessor(HiveReduceFunctionResultList.java:67)
at org.apache.hadoop.hive.ql.exec.spark.HiveBaseFunctionResultList.hasNext(HiveBaseFunctionResultList.java:96)
at scala.collection.convert.Wrappers$JIteratorWrapper.hasNext(Wrappers.scala:43)
at scala.collection.Iterator.foreach(Iterator.scala:941)
at scala.collection.Iterator.foreach$(Iterator.scala:941)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1429)
at org.apache.spark.rdd.AsyncRDDActions.$anonfun$foreachAsync$2(AsyncRDDActions.scala:127)
at org.apache.spark.rdd.AsyncRDDActions.$anonfun$foreachAsync$2$adapted(AsyncRDDActions.scala:127)
at org.apache.spark.SparkContext.$anonfun$submitJob$1(SparkContext.scala:2242)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:127)
at org.apache.spark.executor.Executor$TaskRunner.$anonfun$run$3(Executor.scala:444)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1377)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:447)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.exec.GroupByOperator.closeOp(GroupByOperator.java:1112)
at org.apache.hadoop.hive.ql.exec.Operator.close(Operator.java:733)
at org.apache.hadoop.hive.ql.exec.spark.SparkReduceRecordHandler.close(SparkReduceRecordHandler.java:610)
... 17 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.exec.GroupByOperator.flush(GroupByOperator.java:1086)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.closeOp(GroupByOperator.java:1109)
... 19 more
Caused by: org.apache.hadoop.hive.ql.metadata.HiveException: org.apache.hadoop.hive.ql.metadata.HiveException: java.lang.IllegalArgumentException: SequenceFile doesn't work with GzipCodec without native-hadoop code!
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.createBucketFiles(FileSinkOperator.java:742)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.process(FileSinkOperator.java:897)
at org.apache.hadoop.hive.ql.exec.Operator.baseForward(Operator.java:995)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:941)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:928)
at org.apache.hadoop.hive.ql.exec.SelectOperator.process(SelectOperator.java:95)
at org.apache.hadoop.hive.ql.exec.Operator.baseForward(Operator.java:995)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:941)
at org.apache.hadoop.hive.ql.exec.Operator.forward(Operator.java:928)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.forward(GroupByOperator.java:1050)
at org.apache.hadoop.hive.ql.exec.GroupByOperator.flush(GroupByOperator.java:1076)
... 20 more
2.原因分析
找不到压缩类型支持的包,hadoop的依赖没有找到
3.问题解决
#cp -d 表示带软连接复制
sudo cp -d /data/module/hadoop-3.3.4/lib/native/lib* /usr/lib/
sudo chown hadoop:hadoop /usr/lib/lib*
#有必要查看libhadoop.so.1.0.0是否是空的,很重要。。。。
测试
(base) [hadoop@hadoop1 native]$ hadoop checknative
2023-12-25 14:20:21,615 INFO bzip2.Bzip2Factory: Successfully loaded & initialized native-bzip2 library system-native
2023-12-25 14:20:21,618 INFO zlib.ZlibFactory: Successfully loaded & initialized native-zlib library
2023-12-25 14:20:21,623 WARN erasurecode.ErasureCodeNative: Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory)
2023-12-25 14:20:21,623 WARN erasurecode.ErasureCodeNative: ISA-L support is not available in your platform... using builtin-java codec where applicable
2023-12-25 14:20:21,658 INFO nativeio.NativeIO: The native code was built without PMDK support.
Native library checking:
hadoop: true /data/module/hadoop-3.3.4/lib/native/libhadoop.so.1.0.0
zlib: true /lib64/libz.so.1
zstd : true /lib64/libzstd.so.1
bzip2: true /lib64/libbz2.so.1
openssl: false Cannot load libcrypto.so (libcrypto.so: cannot open shared object file: No such file or directory)!
ISA-L: false Loading ISA-L failed: Failed to load libisal.so.2 (libisal.so.2: cannot open shared object file: No such file or directory)
PMDK: false The native code was built without PMDK support.
相关文章:

Hadoop集群找不到native-hadoop
1.问题描述 hive 运行中的问题,需要把把native复制进去 /usr/lib 2023-02-15 19:59:42,165 WARN scheduler.TaskSetManager: Lost task 11.0 in stage 1.0 (TID 3, common4, executor 2): java.lang.RuntimeException: Hive Runtime Error while closing operators…...

解决阿里云远程连接yum无法安装问题(Ubuntu 22.04)
解决阿里云远程连接yum无法安装问题(Ubuntu 22.04) 第一步 进入阿里云远程连接后,尝试安装宝塔面包第二步:尝试更新软件包等一些列操作第三步:完成上述操作之后,尝试安装yum第四步:尝试更换清华…...

springboot 查询
ServiceImpl中 getBaseMapper()的使用 public IPage<ProductPageVO> getProductPage(Integer regionOrCityCode, Integer brandId, LocalDate usedDate, Page<ProductPageVO> page) {return getBaseMapper().getProductPage(regionOrCityCode, brandId, usedDate, …...
【分布式链路追踪技术】sleuth+zipkin
目录 1.概述 2.搭建演示工程 3.sleuth 4.zipkin 5.插拔式存储 5.1.存储到MySQL中 5.2.用MQ来流量削峰 6.联系作者 1.概述 当采用分布式架构后,一次请求会在多个服务之间流转,组成单次调用链的服务往往都分散在不同的服务器上。这就会带来一个问…...

Windows 源码编译 MariaDB
环境 Win11, vs2022, git, cmake, Bison from GnuWin32, perl, Gnu Diff. 默认都安装好。 perl 看之前博客教程。perl Bison from GnuWin32 默认安装到 C:\GnuWin32 Add C:\GnuWin32\bin to your system PATH after installation. 下载mariadb源码 地址:MariaD…...

【动画视频生成】
转自:机器之心 动画视频生成这几天火了,这次 NUS、字节的新框架不仅效果自然流畅,还在视频保真度方面比其他方法强了一大截。 最近,阿里研究团队构建了一种名为 Animate Anyone 的方法,只需要一张人物照片࿰…...
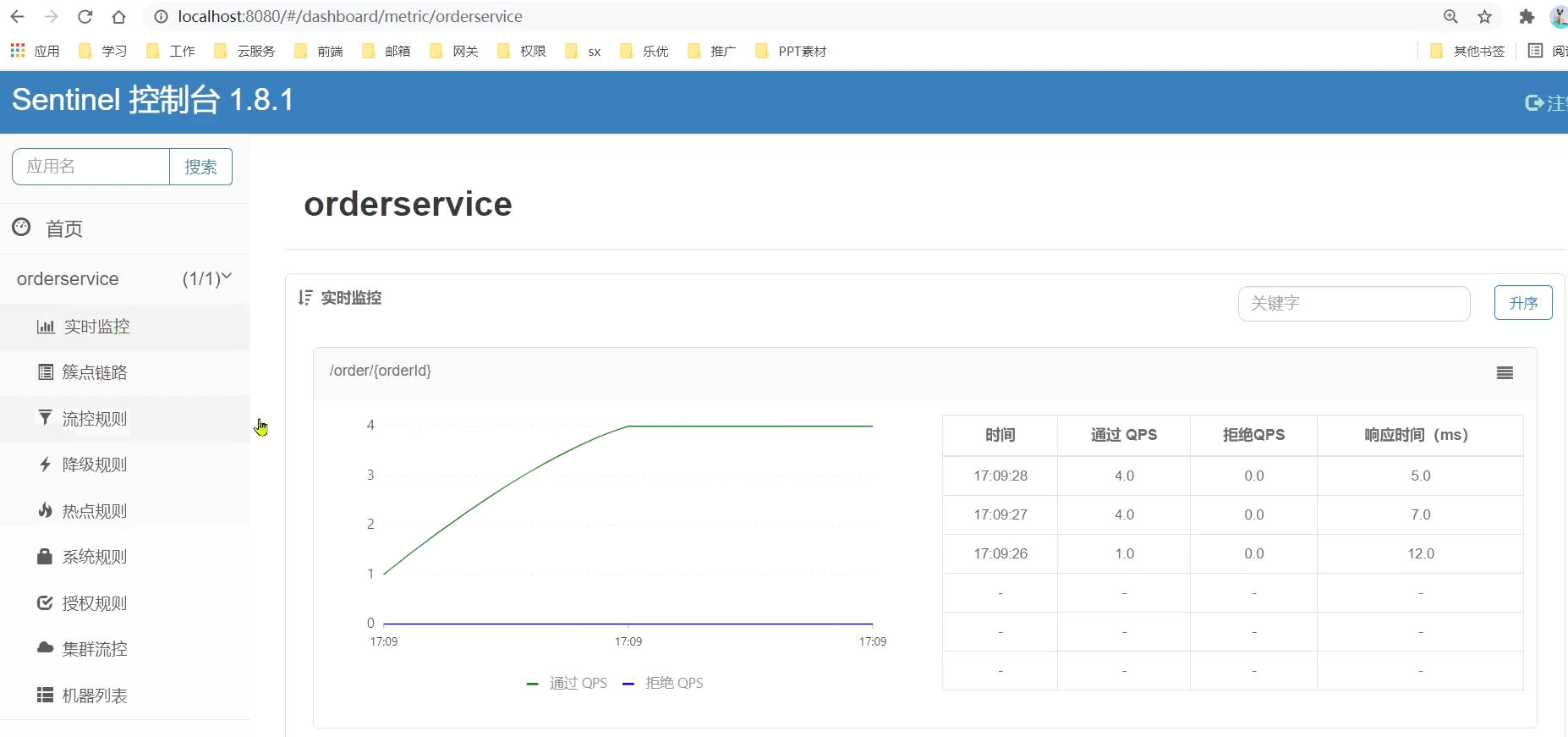
《Spring Cloud学习笔记:微服务保护Sentinel》
Review 解决了服务拆分之后的服务治理问题:Nacos解决了服务治理问题OpenFeign解决了服务之间的远程调用问题网关与前端进行交互,基于网关的过滤器解决了登录校验的问题 流量控制:避免因为突发流量而导致的服务宕机。 隔离和降级:…...

解密负载均衡:如何平衡系统负载(下)
🤍 前端开发工程师(主业)、技术博主(副业)、已过CET6 🍨 阿珊和她的猫_CSDN个人主页 🕠 牛客高级专题作者、在牛客打造高质量专栏《前端面试必备》 🍚 蓝桥云课签约作者、已在蓝桥云…...
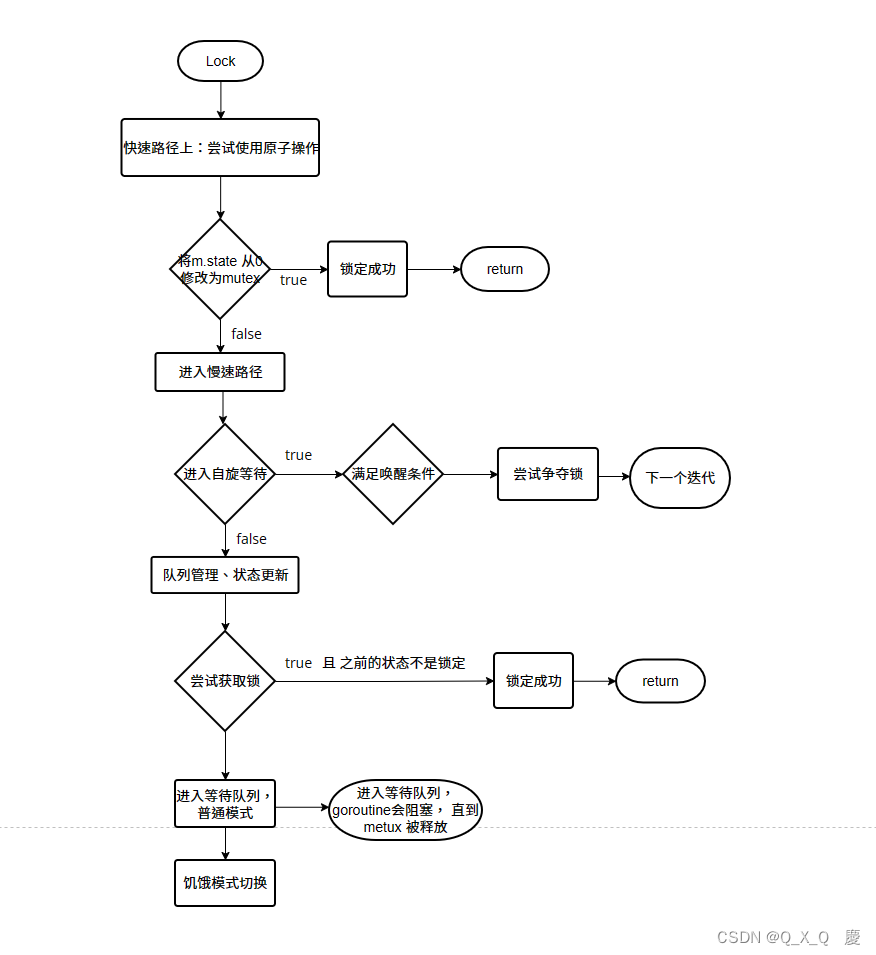
go 源码解读 - sync.Mutex
sync.Mutex mutex简介mutex 方法源码标志位获取锁LocklockSlowUnlock怎么 调度 goroutineruntime 方法 mutex简介 mutex 是 一种实现互斥的同步原语。(go-version 1.21) (还涉及到Go运行时的内部机制)mutex 方法 Lock() 方法用于…...
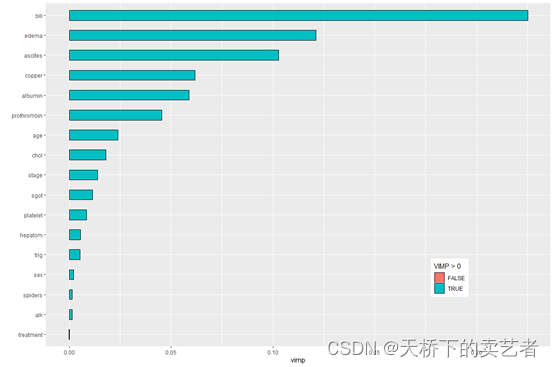
机器学习系列--R语言随机森林进行生存分析(1)
随机森林(Breiman 2001a)(RF)是一种非参数统计方法,需要没有关于响应的协变关系的分布假设。RF是一种强大的、非线性的技术,通过拟合一组树来稳定预测精度模型估计。随机生存森林(RSF࿰…...
<JavaEE> TCP 的通信机制(四) -- 流量控制 和 拥塞控制
目录 TCP的通信机制的核心特性 五、流量控制 1)什么是“流量控制”? 2)如何做到“流量控制”? 3)“流量控制”的作用 六、拥塞控制 1)什么是“拥塞控制”? 2)如何做到“拥塞…...
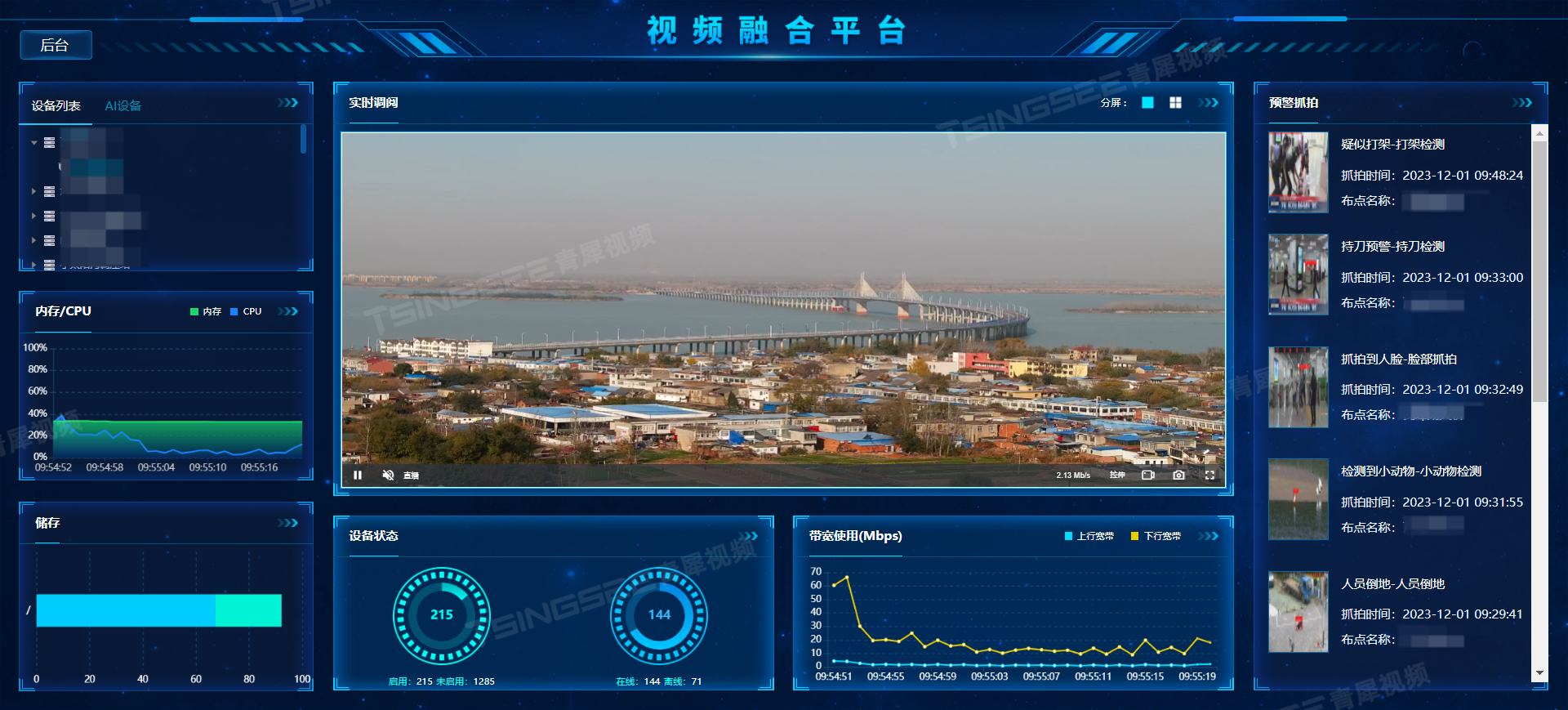
智慧监控平台/AI智能视频EasyCVR接口调用编辑通道详细步骤
视频监控TSINGSEE青犀视频平台EasyCVR能在复杂的网络环境中,将分散的各类视频资源进行统一汇聚、整合、集中管理,在视频监控播放上,GB28181视频安防监控汇聚平台可支持1、4、9、16个画面窗口播放,可同时播放多路视频流,…...

Go语言实现KV存储系统:前言
文章目录 前言前提条件持久索引并发总结 前言 你好,我是醉墨居士,最近想做一些存储方面的东西玩玩,我第一时间就想到了能不能自己开发一个保存键值对的存储系统 我找了些资料,准备使用Go语言实现一下,想着有想法咱就…...

代码随想录刷题笔记(DAY1)
前言:因为学校的算法考试让我认识了卡哥,为了下学期冲击大厂实习的理想,我加入了卡哥的算法训练营,从今天开始我每天会更新自己的刷题笔记,与大家一起打卡,一起共勉! Day 1 01. 二分查找 &…...

Linux域名IP映射
本地域名IP映射 在Linux系统中,域名映射可以通过编辑/etc/hosts文件来实现。/etc/hosts文件用于将主机名映射到IP地址,从而实现本地域名解析。它通常被用于在没有DNS服务器的情况下,手动指定特定域名和IP地址的映射关系。 格式:…...

postman使用-03发送请求
文章目录 请求1.新建请求2.选择请求方式3.填写请求URL4.填写请求参数get请求参数在params中填写(填完后在url中会自动显示)post请求参数在body中填写,根据接口文档请求头里面的content-type选择body中的数据类型post请求参数为json-选择raw-选…...

【Spring实战】09 MyBatis Generator
文章目录 1. 依赖2. 配置文件3. 生成代码4. 详细介绍 generatorConfig.xml5. 代码详细总结 Spring MyBatis Generator 是 MyBatis 官方提供的一个强大的工具,它能够基于数据库表结构自动生成 MyBatis 持久层的代码,包括实体类、Mapper 接口和 XML 映射文…...

【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框架
一个理解人类偏好学习的统一理论框架 《A General Theoretical Paradiam to Understand Learning from Human Preferences》 论文地址:https://arxiv.org/pdf/2310.12036.pdf 相关博客 【自然语言处理】【大模型】 ΨPO:一个理解人类偏好学习的统一理论框…...
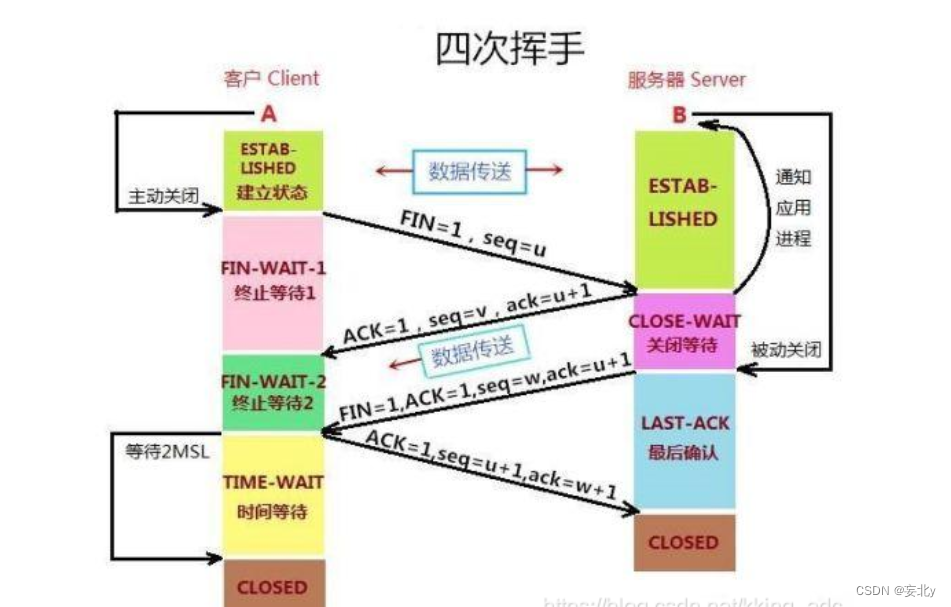
计算机网络——传输层(五)
前言: 最重要的网络层我们已经学习完了,下面让我们再往上一层,对网络层的上一层传输层进行一个学习与了解,学习网络层的基本概念和网络层中的TCP协议和UDP协议 目录 编辑一、传输层的概述: 1.传输层: …...
python3处理docx并flask显示
前言: 最近有需求处理docx文件,并讲内容显示到页面,对world进行在线的阅读,这样我这里就使用flaskDocument对docx文件进行处理并显示,下面直接上代码: Document处理: 首先下载Document的库文…...

Python爬虫实战:研究feedparser库相关技术
1. 引言 1.1 研究背景与意义 在当今信息爆炸的时代,互联网上存在着海量的信息资源。RSS(Really Simple Syndication)作为一种标准化的信息聚合技术,被广泛用于网站内容的发布和订阅。通过 RSS,用户可以方便地获取网站更新的内容,而无需频繁访问各个网站。 然而,互联网…...

在鸿蒙HarmonyOS 5中使用DevEco Studio实现录音机应用
1. 项目配置与权限设置 1.1 配置module.json5 {"module": {"requestPermissions": [{"name": "ohos.permission.MICROPHONE","reason": "录音需要麦克风权限"},{"name": "ohos.permission.WRITE…...

【C++从零实现Json-Rpc框架】第六弹 —— 服务端模块划分
一、项目背景回顾 前五弹完成了Json-Rpc协议解析、请求处理、客户端调用等基础模块搭建。 本弹重点聚焦于服务端的模块划分与架构设计,提升代码结构的可维护性与扩展性。 二、服务端模块设计目标 高内聚低耦合:各模块职责清晰,便于独立开发…...

优选算法第十二讲:队列 + 宽搜 优先级队列
优选算法第十二讲:队列 宽搜 && 优先级队列 1.N叉树的层序遍历2.二叉树的锯齿型层序遍历3.二叉树最大宽度4.在每个树行中找最大值5.优先级队列 -- 最后一块石头的重量6.数据流中的第K大元素7.前K个高频单词8.数据流的中位数 1.N叉树的层序遍历 2.二叉树的锯…...

用机器学习破解新能源领域的“弃风”难题
音乐发烧友深有体会,玩音乐的本质就是玩电网。火电声音偏暖,水电偏冷,风电偏空旷。至于太阳能发的电,则略显朦胧和单薄。 不知你是否有感觉,近两年家里的音响声音越来越冷,听起来越来越单薄? —…...

算法岗面试经验分享-大模型篇
文章目录 A 基础语言模型A.1 TransformerA.2 Bert B 大语言模型结构B.1 GPTB.2 LLamaB.3 ChatGLMB.4 Qwen C 大语言模型微调C.1 Fine-tuningC.2 Adapter-tuningC.3 Prefix-tuningC.4 P-tuningC.5 LoRA A 基础语言模型 A.1 Transformer (1)资源 论文&a…...

PHP 8.5 即将发布:管道操作符、强力调试
前不久,PHP宣布了即将在 2025 年 11 月 20 日 正式发布的 PHP 8.5!作为 PHP 语言的又一次重要迭代,PHP 8.5 承诺带来一系列旨在提升代码可读性、健壮性以及开发者效率的改进。而更令人兴奋的是,借助强大的本地开发环境 ServBay&am…...

Vue3 PC端 UI组件库我更推荐Naive UI
一、Vue3生态现状与UI库选择的重要性 随着Vue3的稳定发布和Composition API的广泛采用,前端开发者面临着UI组件库的重新选择。一个好的UI库不仅能提升开发效率,还能确保项目的长期可维护性。本文将对比三大主流Vue3 UI库(Naive UI、Element …...

WEB3全栈开发——面试专业技能点P4数据库
一、mysql2 原生驱动及其连接机制 概念介绍 mysql2 是 Node.js 环境中广泛使用的 MySQL 客户端库,基于 mysql 库改进而来,具有更好的性能、Promise 支持、流式查询、二进制数据处理能力等。 主要特点: 支持 Promise / async-await…...
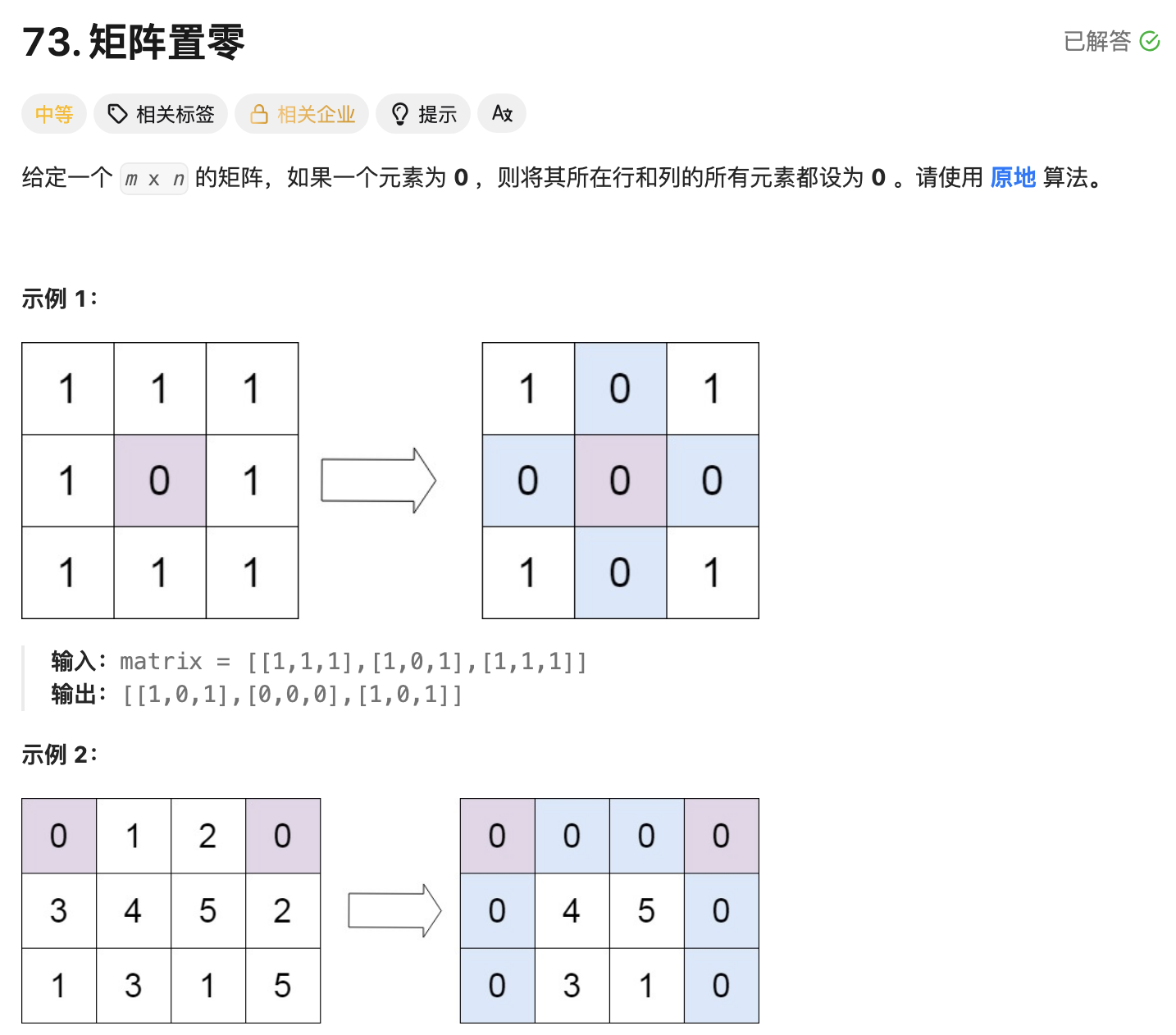
leetcode73-矩阵置零
leetcode 73 思路 记录 0 元素的位置:遍历整个矩阵,找出所有值为 0 的元素,并将它们的坐标记录在数组zeroPosition中置零操作:遍历记录的所有 0 元素位置,将每个位置对应的行和列的所有元素置为 0 具体步骤 初始化…...