关于“Python”的核心知识点整理大全47

目录
16.1.10 错误检查
highs_lows.py
highs_lows.py
16.2 制作世界人口地图:JSON 格式
16.2.1 下载世界人口数据
16.2.2 提取相关的数据
population_data.json
world_population.py
16.2.3 将字符串转换为数字值
world_population.py
2world_population.py
16.2.4 获取两个字母的国别码
countries.py
country_codes.py
往期快速传送门👆(在文章最后):
感谢大家的支持!欢迎订阅收藏!专栏将持续更新!

16.1.10 错误检查
我们应该能够使用有关任何地方的天气数据来运行highs_lows.py中的代码,但有些气象站会 偶尔出现故障,未能收集部分或全部其应该收集的数据。缺失数据可能会引发异常,如果不妥善 地处理,还可能导致程序崩溃。 例如,我们来看看生成加利福尼亚死亡谷的气温图时出现的情况。将文件death_valley_ 2014.csv复制到本章程序所在的文件夹,再修改highs_lows.py,使其生成死亡谷的气温图:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:
--snip-- 运行这个程序时,出现了一个错误,如下述输出的最后一行所示:
Traceback (most recent call last):File "highs_lows.py", line 17, in <module>high = int(row[1])
ValueError: invalid literal for int() with base 10: '' 该traceback指出,Python无法处理其中一天的最高气温,因为它无法将空字符串(' ')转换 为整数。只要看一下death_valley_2014.csv,就能发现其中的问题:
2014-2-16,,,,,,,,,,,,,,,,,,,0.00,,,-1 其中好像没有记录2014年2月16日的数据,表示最高温度的字符串为空。为解决这种问题, 我们在从CSV文件中读取值时执行错误检查代码,对分析数据集时可能出现的异常进行处理,如 下所示:
highs_lows.py
--snip--
# 从文件中获取日期、最高气温和最低气温
filename = 'death_valley_2014.csv'
with open(filename) as f:reader = csv.reader(f)header_row = next(reader)dates, highs, lows = [], [], []for row in reader:
1 try:current_date = datetime.strptime(row[0], "%Y-%m-%d")high = int(row[1])low = int(row[3])except ValueError:
2 print(current_date, 'missing data')else:
3 dates.append(current_date)highs.append(high)lows.append(low)
#根据数据绘制图形
--snip--
#设置图形的格式
4 title = "Daily high and low temperatures - 2014\nDeath Valley, CA"
plt.title(title, fontsize=20)
--snip-- 对于每一行,我们都尝试从中提取日期、最高气温和最低气温(见1)。只要缺失其中一项 数据,Python就会引发ValueError异常,而我们可这样处理:打印一条错误消息,指出缺失数据 的日期(见2)。打印错误消息后,循环将接着处理下一行。如果获取特定日期的所有数据时没 有发生错误,将运行else代码块,并将数据附加到相应列表的末尾(见3)。鉴于我们绘图时使 用的是有关另一个地方的信息,我们修改了标题,在图表中指出了这个地方(见4)。 如果你现在运行highs_lows.py,将发现缺失数据的日期只有一个:
2014-02-16 missing data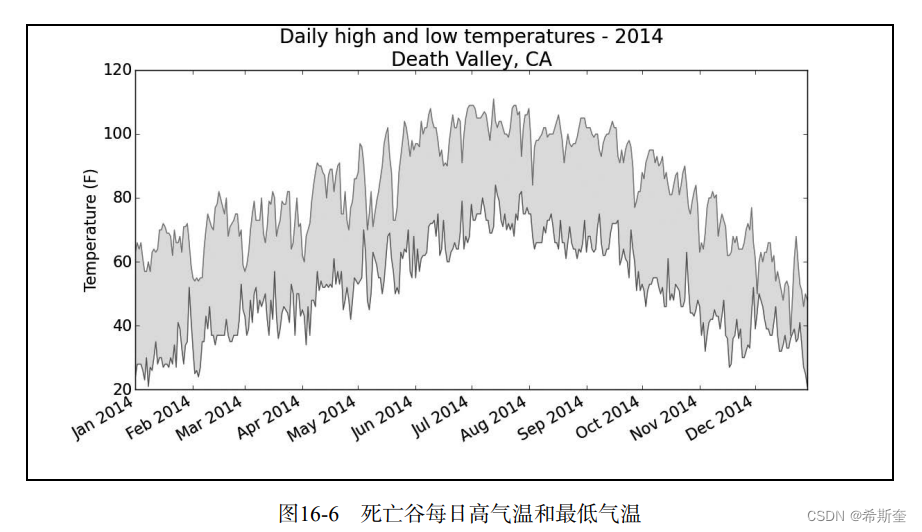
将这个图表与锡特卡的图表对比可知,总体而言,死亡谷比阿拉斯加东南部暖和,这可能符 合预期,但这个沙漠中每天的温差也更大,从着色区域的高度可以明显看出这一点。
使用的很多数据集都可能缺失数据、数据格式不正确或数据本身不正确。对于这样的情形, 可使用本书前半部分介绍的工具来处理。在这里,我们使用了一个try-except-else代码块来处理 数据缺失的问题。在有些情况下,需要使用continue来跳过一些数据,或者使用remove()或del 将已提取的数据删除。可采用任何管用的方法,只要能进行精确而有意义的可视化就好。
16.2 制作世界人口地图:JSON 格式
在本节中,你将下载JSON格式的人口数据,并使用json模块来处理它们。Pygal提供了一个 适合初学者使用的地图创建工具,你将使用它来对人口数据进行可视化,以探索全球人口的分布 情况。
16.2.1 下载世界人口数据
将文件population_data.json复制到本章程序所在的文件夹中,这个文件包含全球大部分国家 1960~2010年的人口数据。Open Knowledge Foundation(http://data.okfn.org/)提供了大量可以免 费使用的数据集,这些数据就来自其中一个数据集。
16.2.2 提取相关的数据
我们来研究一下population_data.json,看看如何着手处理这个文件中的数据:
population_data.json
[{"Country Name": "Arab World","Country Code": "ARB","Year": "1960","Value": "96388069"}, {"Country Name": "Arab World","Country Code": "ARB","Year": "1961","Value": "98882541.4"},--snip--
] 这个文件实际上就是一个很长的Python列表,其中每个元素都是一个包含四个键的字典:国 家名、国别码、年份以及表示人口数量的值。我们只关心每个国家2010年的人口数量,因此我们 首先编写一个打印这些信息的程序:
world_population.py
import json
# 将数据加载到一个列表中
filename = 'population_data.json'
with open(filename) as f:
1 pop_data = json.load(f)
# 打印每个国家2010年的人口数量
2 for pop_dict in pop_data:
3 if pop_dict['Year'] == '2010':
4 country_name = pop_dict['Country Name']population = pop_dict['Value']print(country_name + ": " + population)我们首先导入了模块json,以便能够正确地加载文件中的数据,然后,我们将数据存储在 pop_data中(见)。函数json.load()将数据转换为Python能够处理的格式,这里是一个列表。 在处,我们遍历pop_data中的每个元素。每个元素都是一个字典,包含四个键—值对,我们将 每个字典依次存储在pop_dict中。 在处,我们检查字典的'Year'键对应的值是否是2010(由于population_data.json中的值都是 用引号括起的,因此我们执行的是字符串比较)。如果年份为2010,我们就将与'Country Name' 相关联的值存储到country_name中,并将与'Value'相关联的值存储在population中(见)。接下 来,我们打印每个国家的名称和人口数量。 输出为一系列国家的名称和人口数量:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Zimbabwe: 12571000我们捕获的数据并非都包含准确的国家名,但这开了一个好头。现在,我们需要将数据转换为Pygal能够处理的格式。
16.2.3 将字符串转换为数字值
population_data.json中的每个键和值都是字符串。为处理这些人口数据,我们需要将表示人 口数量的字符串转换为数字值,为此我们使用函数int():
world_population.py
--snip--
for pop_dict in pop_data:if pop_dict['Year'] == '2010':country_name = pop_dict['Country Name']
1 population = int(pop_dict['Value'])
2 print(country_name + ": " + str(population))在1处,我们将每个人口数量值都存储为数字格式。打印人口数量值时,需要将其转换为字 符串(见2)。 然而,对于有些值,这种转换会导致错误,如下所示:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Traceback (most recent call last):File "print_populations.py", line 12, in <module>population = int(pop_dict['Value'])
1 ValueError: invalid literal for int() with base 10: '1127437398.85751'原始数据的格式常常不统一,因此经常会出现错误。导致上述错误的原因是,Python不能直 接将包含小数点的字符串'1127437398.85751'转换为整数(这个小数值可能是人口数据缺失时通 过插值得到的)。为消除这种错误,我们先将字符串转换为浮点数,再将浮点数转换为整数:
2world_population.py
--snip--
for pop_dict in pop_data:if pop_dict['Year'] == '2010':country = pop_dict['Country Name']population = int(float(pop_dict['Value']))print(country + ": " + str(population)) 函数float()将字符串转换为小数,而函数int()丢弃小数部分,返回一个整数。现在,我们 可以打印2010年的完整人口数据,不会导致错误了:
Arab World: 357868000
Caribbean small states: 6880000
East Asia & Pacific (all income levels): 2201536674
--snip--
Zimbabwe: 12571000每个字符串都成功地转换成了浮点数,再转换为整数。以数字格式存储人口数量值后,就可 以使用它们来制作世界人口地图了。
16.2.4 获取两个字母的国别码
制作地图前,还需要解决数据存在的最后一个问题。Pygal中的地图制作工具要求数据为特 定的格式:用国别码表示国家,以及用数字表示人口数量。处理地理政治数据时,经常需要用到 几个标准化国别码集。population_data.json中包含的是三个字母的国别码,但Pygal使用两个字母 的国别码。我们需要想办法根据国家名获取两个字母的国别码。 Pygal使用的国别码存储在模块i18n(internationalization的缩写)中。字典COUNTRIES包含的 键和值分别为两个字母的国别码和国家名。要查看这些国别码,可从模块i18n中导入这个字典, 并打印其键和值:
countries.py
from pygal.i18n import COUNTRIES
1 for country_code in sorted(COUNTRIES.keys()):print(country_code, COUNTRIES[country_code])在上面的for循环中,我们让Python将键按字母顺序排序(见),然后打印每个国别码及其 对应的国家:
ad Andorra
ae United Arab Emirates
af Afghanistan
--snip--
zw Zimbabwe 为获取国别码,我们将编写一个函数,它在COUNTRIES中查找并返回国别码。我们将这个函 数放在一个名为country_codes的模块中,以便能够在可视化程序中导入它:
country_codes.py
from pygal.i18n import COUNTRIES
1 def get_country_code(country_name):"""根据指定的国家,返回Pygal使用的两个字母的国别码"""
3 for code, name in COUNTRIES.items():
if name == country_name:return code# 如果没有找到指定的国家,就返回None
4 return None
print(get_country_code('Andorra'))
print(get_country_code('United Arab Emirates'))
print(get_country_code('Afghanistan')) 关于“Python”的核心知识点整理大全37-CSDN博客
关于“Python”的核心知识点整理大全25-CSDN博客
关于“Python”的核心知识点整理大全12-CSDN博客
往期快速传送门👆(在文章最后):
感谢大家的支持!欢迎订阅收藏!专栏将持续更新!
相关文章:
关于“Python”的核心知识点整理大全47
目录 16.1.10 错误检查 highs_lows.py highs_lows.py 16.2 制作世界人口地图:JSON 格式 16.2.1 下载世界人口数据 16.2.2 提取相关的数据 population_data.json world_population.py 16.2.3 将字符串转换为数字值 world_population.py 2world_population…...
Android 8.1 设置USB传输文件模式(MTP)
项目需求,需要在电脑端adb发送通知手机端接收指令,将USB的仅充电模式更改成传输文件(MTP)模式,便捷用户在我的电脑里操作内存文件,下面是我们的常见的修改方式 1、android12以下、android21以上是这种方式…...
模型量化 | Pytorch的模型量化基础
官方网站:Quantization — PyTorch 2.1 documentation Practical Quantization in PyTorch | PyTorch 量化简介 量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度…...

adb和logcat常用命令
adb的作用 adb构成 client端,在电脑上,负责发送adb命令daemon守护进程adbd,在手机上,负责接收和执行adb命令server端,在电脑上,负责管理client和daemon之间的通信 adb工作原理 client端将命令发送给ser…...
千巡翼X4轻型无人机 赋能智慧矿山
千巡翼X4轻型无人机 赋能智慧矿山 传统的矿山测绘需要大量测绘员通过采用手持RTK、全站仪对被测区域进行外业工作,再通过方格网法、三角网法、断面法等进行计算,需要耗费大量人力和时间。随着无人机航测技术的不断发展,利用无人机作业可以大…...
:编译服务器的配置、AOSP源码的下载、编译、运行)
【Android 13】使用Android Studio调试系统应用之Settings移植(一):编译服务器的配置、AOSP源码的下载、编译、运行
文章目录 1. 篇头语2. 系列文章3. ubuntu 最佳版本3.1 下载并安装3.2 配置AOSP工具链3.3 配置Python多版本支持4. AOSP源码下载4.1 配置repo工具4.2 源码下载5. AOSP编译5.1 添加emulator模拟器配置5.1.1 哪些是支持模拟器的Products?5.1.2 添加方法5.2 编译...

【1】Docker详解与部署微服务实战
Docker 详解 Docker 简介 Docker 是一个开源的容器化平台,可以帮助开发者将应用程序和其依赖的环境打包成一个可移植、可部署的容器。Docker 的主要目标是通过容器化技术实现应用程序的快速部署、可移植性和可扩展性,从而简化应用程序的开发、测试和部…...

C# JsonString转Object以及Object转JsonString
主要讲述了两种方法的转换,最后提供了格式化输出JsonString字符串。 需要引用程序集 System.Web.Extensions.dll、Newtonsoft.Json.dll System.Web.Extensions.dll可直接在程序集中引用,Newtonsoft.Json.dll需要在NuGet中下载引用。 详细代码…...
)
华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)
题目描述: 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。 说明: 1.精确分词: 字符串分词后,不会出现重叠。即“ilovechina” ,不同词库可分割为 “i,love,china” “ilove,c…...

【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList
在并发编程领域,其实除了使用上一篇中的属性不可变。还有一种方式那就是针对读多写少的场景下。我们可以读不加锁,只针对于写操作进行加锁。本质上就是读写复制。读的直接读取,写的使用写一份数据的拷贝数据,然后进行写入。在将新…...

OpenCV中使用Mask R-CNN实现图像分割的原理与技术实现方案
本文详细介绍了在OpenCV中利用Mask R-CNN实现图像分割的原理和技术实现方案。Mask R-CNN是一种先进的深度学习模型,通过结合区域提议网络(Region Proposal Network)和全卷积网络(Fully Convolutional Network)…...

论文阅读《Rethinking Efficient Lane Detection via Curve Modeling》
目录 Abstract 1. Introduction 2. Related Work 3. BezierLaneNet 3.1. Overview 3.2. Feature Flip Fusion 3.3. End-to-end Fit of a Bezier Curve 4. Experiments 4.1. Datasets 4.2. Evalutaion Metics 4.3. Implementation Details 4.4. Comparisons 4.5. A…...
Leetcode—2660.保龄球游戏的获胜者【简单】
2023每日刷题(七十二) Leetcode—2660.保龄球游戏的获胜者 实现代码 class Solution { public:int isWinner(vector<int>& player1, vector<int>& player2) {long long sum1 0, sum2 0;int n player1.size();for(int i 0; i &…...

ubuntu服务器上安装KVM虚拟化
今天想着在ubuntu上来安装一个windwos操作系统,原因是因为我们楼上有几台不错的服务器,但是都是linux系统的。 今天我想着要给同事们搭建一个chatgpt环境,用来开发程序,但是ubuntu上其实也可以安装我嫌麻烦,刚好想折腾…...
SpreadJS 集成使用案例
SpreadJS 集成案例 介绍: SpreadJS 基于 HTML5 标准,支持跨平台开发和集成,支持所有主流浏览器,无需预装任何插件或第三方组件,以原生的方式嵌入各类应用,可以与各类后端技术框架相结合。SpreadJS 以 纯前…...
SQL题:534. 游戏玩法分析 III(难度:中等))
单挑力扣(LeetCode)SQL题:534. 游戏玩法分析 III(难度:中等)
题目:534. 游戏玩法分析 III (通过次数23,825 | 提交次数34,947,通过率68.17%) Table:Activity----------------------- | Column Name | Type | ----------------------- | player_id | int | | device_id | int…...

【OpenCV】告别人工目检:深度学习技术引领工业品缺陷检测新时代
目录 前言 机器视觉 缺陷检测 工业上常见缺陷检测方法 内容简介 作者简介 目录 读者对象 如何阅读本书 获取方式 前言 前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。 点击跳转到网站 机器视觉…...

VR全景图片制作时有哪些技巧,VR全景图片能带来哪些好处
引言: VR全景图片是通过虚拟现实技术制作出的具有沉浸感的图片,能够提供给用户一种身临其境的感觉。在宣传方面,它有着独特的优势和潜力,能够帮助吸引更多的潜在客户,那么VR全景图片制作时有哪些技巧,VR全…...

【VUE】Flask+vue-element-admin前后端分离项目发布到linux服务器操作指南
目录 一、Flask后端发布环境搭建1.1 python环境第一步:安装python环境第二步:配置python虚拟环境 1.2 uwsgi环境1.3 nginx配置1.4 测试 二、VUE前端发布环境搭建2.1 配置修改2.2 打包上传服务器2.3 nginx配置2.3 测试 三、联合调试 一、Flask后端发布环境…...

django的gunicorn的异步任务执行
gunicorn 本身是一个WSGI HTTP服务器,用于运行Python的web应用,如Django项目。它并不直接提供执行异步任务的功能。异步任务通常是指那些你想要在web请求之外执行的后台任务,如发送电子邮件、处理长时间运行的计算或与外部API交互等。 在Dja…...

UE5 学习系列(二)用户操作界面及介绍
这篇博客是 UE5 学习系列博客的第二篇,在第一篇的基础上展开这篇内容。博客参考的 B 站视频资料和第一篇的链接如下: 【Note】:如果你已经完成安装等操作,可以只执行第一篇博客中 2. 新建一个空白游戏项目 章节操作,重…...
)
uniapp 对接腾讯云IM群组成员管理(增删改查)
UniApp 实战:腾讯云IM群组成员管理(增删改查) 一、前言 在社交类App开发中,群组成员管理是核心功能之一。本文将基于UniApp框架,结合腾讯云IM SDK,详细讲解如何实现群组成员的增删改查全流程。 权限校验…...

龙虎榜——20250610
上证指数放量收阴线,个股多数下跌,盘中受消息影响大幅波动。 深证指数放量收阴线形成顶分型,指数短线有调整的需求,大概需要一两天。 2025年6月10日龙虎榜行业方向分析 1. 金融科技 代表标的:御银股份、雄帝科技 驱动…...

(十)学生端搭建
本次旨在将之前的已完成的部分功能进行拼装到学生端,同时完善学生端的构建。本次工作主要包括: 1.学生端整体界面布局 2.模拟考场与部分个人画像流程的串联 3.整体学生端逻辑 一、学生端 在主界面可以选择自己的用户角色 选择学生则进入学生登录界面…...

python/java环境配置
环境变量放一起 python: 1.首先下载Python Python下载地址:Download Python | Python.org downloads ---windows -- 64 2.安装Python 下面两个,然后自定义,全选 可以把前4个选上 3.环境配置 1)搜高级系统设置 2…...

聊聊 Pulsar:Producer 源码解析
一、前言 Apache Pulsar 是一个企业级的开源分布式消息传递平台,以其高性能、可扩展性和存储计算分离架构在消息队列和流处理领域独树一帜。在 Pulsar 的核心架构中,Producer(生产者) 是连接客户端应用与消息队列的第一步。生产者…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

3-11单元格区域边界定位(End属性)学习笔记
返回一个Range 对象,只读。该对象代表包含源区域的区域上端下端左端右端的最后一个单元格。等同于按键 End 向上键(End(xlUp))、End向下键(End(xlDown))、End向左键(End(xlToLeft)End向右键(End(xlToRight)) 注意:它移动的位置必须是相连的有内容的单元格…...

Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决
Spring Cloud Gateway 中自定义验证码接口返回 404 的排查与解决 问题背景 在一个基于 Spring Cloud Gateway WebFlux 构建的微服务项目中,新增了一个本地验证码接口 /code,使用函数式路由(RouterFunction)和 Hutool 的 Circle…...

html css js网页制作成品——HTML+CSS榴莲商城网页设计(4页)附源码
目录 一、👨🎓网站题目 二、✍️网站描述 三、📚网站介绍 四、🌐网站效果 五、🪓 代码实现 🧱HTML 六、🥇 如何让学习不再盲目 七、🎁更多干货 一、👨…...