缓存和缓冲的区别
近期被这两个词汇困扰了,感觉有本质的区别,搜了一些资料,整理如下
计算机内部的几个部分图如下
缓存(cache)
https://baike.baidu.com/item/%E7%BC%93%E5%AD%98
提到缓存(cache),就想到了 cpu 高速缓存,其实最开始的缓存也是这个。
目的就是为了让 cpu 和内存之间的数据交互速度变快设计的。
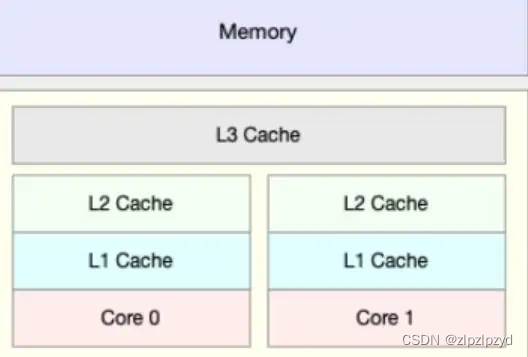
从下到上访问速度依次递减,容量也越来越大。内存的访问速度比 cpu 缓存访问速度慢 100倍。
https://www.zhihu.com/question/349982942/answer/2935754503
其他缓存
浏览器缓存
https://baike.baidu.com/item/%E6%B5%8F%E8%A7%88%E5%99%A8%E7%BC%93%E5%AD%98
之前的时代,网络不发达,带宽小,有了浏览器,打开一个网页需要每次加载页面需要的资源会时间长,后面浏览器的开发者就想到了重复的资源没必要重新加载,就考虑到浏览器缓存。
对于访问的资源如果每个请求后面都加了时间戳就没缓存了(缓存失效),相对于不加对于打开一个页面会发现明显变慢。
内存缓存 redis
对于数据库访问这块,为了减少数据库的访问次数,redis 的大神就想到了在内存中暂存这些数据。
因为内存通常来讲大一些,速度比硬盘快多了,所以在内存上暂存数据是一个不错的选择。
但是 redis 不是只有缓存功能,还有一些其他的功能。
缓冲(buffer)
为了提高内存和硬盘或其他io设备之间数据交换的速度设计的。在上面 cpu 缓存的基础上,硬盘比内存慢了几个数量级。
本质就是在内存上单独开辟了一个数组来存储当前的数据,将对磁盘的操作由随机操作变为顺序操作。由于磁盘的随机操作与顺序操作之间的数量级差距,在执行结果中会看到明显的差距。是用空间换时间的思想的实现。
压缩文件类似原理,将一个文件夹中的多个文件进行压缩,将多个小文件整理为一个文件,在磁盘上空间连续,在传输的过程中感觉快,如果是复制整个文件夹,会发现传输时间相对于压缩文件长,对于那些小文件数量多的情况下特别明显。
java 实现
如下 java.io 自带的原始的缓冲类
BufferedInputStream
package java.io;public class BufferedInputStream extends FilterInputStream {private static int DEFAULT_BUFFER_SIZE = 8192;protected volatile byte buf[];public BufferedInputStream(InputStream in) {this(in, DEFAULT_BUFFER_SIZE);}
}
BufferedOutputStream
package java.io;public class BufferedOutputStream extends FilterOutputStream {protected byte buf[];public BufferedOutputStream(OutputStream out) {this(out, 8192);}
} BufferedReader
package java.io;public class BufferedReader extends Reader {private Reader in;private char cb[];private static int defaultCharBufferSize = 8192;public BufferedReader(Reader in, int sz) {super(in);if (sz <= 0)throw new IllegalArgumentException("Buffer size <= 0");this.in = in;cb = new char[sz];nextChar = nChars = 0;}public BufferedReader(Reader in) {this(in, defaultCharBufferSize);}
}
BufferedWriter
package java.io;public class BufferedWriter extends Writer {private Writer out;private static int defaultCharBufferSize = 8192;public BufferedWriter(Writer out) {this(out, defaultCharBufferSize);}
}每个类中声明的缓冲数组在没有指定大小的情况下都是 8192,即 8MB。体现了预读的思想。
https://blog.csdn.net/qingfan_714/article/details/115439234
数据库中的 join buffer
mysql 中针对多表联合查询,在驱动表中会查询出符合要求的数据放在内存中与被驱动表进行嵌套查询。因为数据库的数据存储在磁盘上,由于存储设备与内存数据访问的速度差距,将数据放在内存中暂存是一个很好的选择,但是驱动表的数据需要做筛选,数据量不能多,遵循小表驱动大表原则。
总结
缓存和缓冲都是为了解决计算机的各个部分的访问速度设计的。
针对 cpu 和内存之间的速度慢的问题,设计了 cpu 与内存中间的三个级别的缓存。
针对内存与存储设备之间的速度慢的问题,编码在内存层面设计了缓冲区域将读取或者写入的数据批量处理。将存储设备的随机处理变为顺序处理,是空间换时间思想的实现。
在日常开发中,遇到的问题瓶颈一般是缓冲的问题。因为内存和 cpu 之间的缓存我们无法控制,但是在内存和硬盘层面的缓冲现有的工具无法满足我们可以自己编码处理。
参考链接
https://zhidao.baidu.com/question/7153396.html
https://blog.csdn.net/weixin_42559574/article/details/115290225
https://zhuanlan.zhihu.com/p/376380293
https://www.cnblogs.com/smalldong/p/14337528.html
https://baike.baidu.com/item/%E7%BC%93%E5%86%B2%E6%8A%80%E6%9C%AF/1937843
https://www.cnblogs.com/taking/p/15707375.html
https://zhuanlan.zhihu.com/p/563185831
https://www.jianshu.com/p/d049943a9cc5
相关文章:
缓存和缓冲的区别
近期被这两个词汇困扰了,感觉有本质的区别,搜了一些资料,整理如下 计算机内部的几个部分图如下 缓存(cache) https://baike.baidu.com/item/%E7%BC%93%E5%AD%98 提到缓存(cache),就…...

C++高级-STL库概述
目录 一、概念 二、STL的历史背景 三、STL的版本 四、STL的主要优势...

uniapp 统一获取授权提示和48小时间隔授权
应用商店审核要求 获取权限前需要给提示,拒绝之后48小时不能给弹窗授权 项目用的是uniapp getImagePermission(v?: string, tag?: any, source?: any, proj?: any) {// proj proj || vueSelf.$proj(tag, source);let data {state: false,//是否原生授权denied…...

Halcon点云重建
dev_close_window () *点云文件数据的读取 read_object_model_3d (‘E:/1.om3’, ‘mm’, [], [], ObjectModel3D, Status) *获得点云的数据,例如高度 get_object_model_3d_params (ObjectModel3D, ‘point_coord_z’, GenParamValue) dev_open_window (0, 0, 512, …...
docker学习(二十一、network使用示例container、自定义)
文章目录 一、container应用示例1.需要共用同一个端口的服务,不适用container方式2.可用示例3.停掉共享源的容器,其他容器只有本地回环lo地址 总结 二、自定义网络应用示例默认bridge,容器间ip通信默认bridge,容器间服务名不通 自…...

【Python机器学习系列】一文带你了解机器学习中的Pipeline管道机制(理论+源码)
这是Python机器学习原创文章,我的第183篇原创文章。 一、引言 对于表格数据,一套完整的机器学习建模流程如下: 背景知识1:机器学习中的学习器 【Python机器学习系列】一文搞懂机器学习中的转换器和估计器(附案例&…...
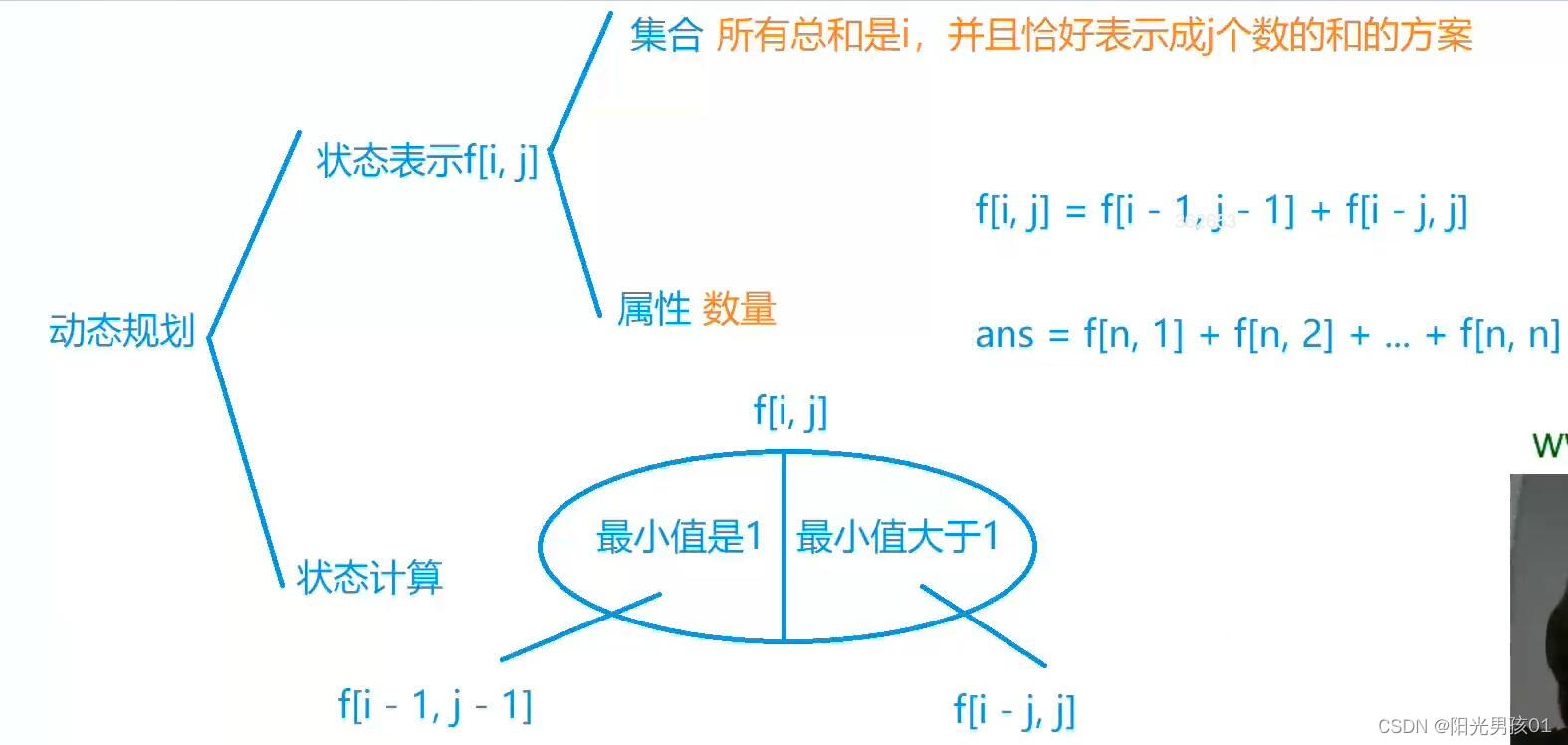
算法基础之整数划分
整数划分 核心思想: 计数类dp 背包做法 f[i][j] 表示 取 1 – i 的物品 总容量为j的选法数量 f[i][j] f[i-1][j] f[i-1][j-v[i]] f[i-1][j-2v[i]] f[i-1][j-3v[i]] ……f[i-1][j-kv[i]] f[i][j-v[i]] f[i-1][j-v[i]] f[i-1][j-2v[i]] f[i-1][j-3v[i]] ……f[i…...
关于“Python”的核心知识点整理大全47
目录 16.1.10 错误检查 highs_lows.py highs_lows.py 16.2 制作世界人口地图:JSON 格式 16.2.1 下载世界人口数据 16.2.2 提取相关的数据 population_data.json world_population.py 16.2.3 将字符串转换为数字值 world_population.py 2world_population…...
Android 8.1 设置USB传输文件模式(MTP)
项目需求,需要在电脑端adb发送通知手机端接收指令,将USB的仅充电模式更改成传输文件(MTP)模式,便捷用户在我的电脑里操作内存文件,下面是我们的常见的修改方式 1、android12以下、android21以上是这种方式…...
模型量化 | Pytorch的模型量化基础
官方网站:Quantization — PyTorch 2.1 documentation Practical Quantization in PyTorch | PyTorch 量化简介 量化是指执行计算和存储的技术 位宽低于浮点精度的张量。量化模型 在张量上执行部分或全部操作,精度降低,而不是 全精度…...

adb和logcat常用命令
adb的作用 adb构成 client端,在电脑上,负责发送adb命令daemon守护进程adbd,在手机上,负责接收和执行adb命令server端,在电脑上,负责管理client和daemon之间的通信 adb工作原理 client端将命令发送给ser…...
千巡翼X4轻型无人机 赋能智慧矿山
千巡翼X4轻型无人机 赋能智慧矿山 传统的矿山测绘需要大量测绘员通过采用手持RTK、全站仪对被测区域进行外业工作,再通过方格网法、三角网法、断面法等进行计算,需要耗费大量人力和时间。随着无人机航测技术的不断发展,利用无人机作业可以大…...
:编译服务器的配置、AOSP源码的下载、编译、运行)
【Android 13】使用Android Studio调试系统应用之Settings移植(一):编译服务器的配置、AOSP源码的下载、编译、运行
文章目录 1. 篇头语2. 系列文章3. ubuntu 最佳版本3.1 下载并安装3.2 配置AOSP工具链3.3 配置Python多版本支持4. AOSP源码下载4.1 配置repo工具4.2 源码下载5. AOSP编译5.1 添加emulator模拟器配置5.1.1 哪些是支持模拟器的Products?5.1.2 添加方法5.2 编译...

【1】Docker详解与部署微服务实战
Docker 详解 Docker 简介 Docker 是一个开源的容器化平台,可以帮助开发者将应用程序和其依赖的环境打包成一个可移植、可部署的容器。Docker 的主要目标是通过容器化技术实现应用程序的快速部署、可移植性和可扩展性,从而简化应用程序的开发、测试和部…...

C# JsonString转Object以及Object转JsonString
主要讲述了两种方法的转换,最后提供了格式化输出JsonString字符串。 需要引用程序集 System.Web.Extensions.dll、Newtonsoft.Json.dll System.Web.Extensions.dll可直接在程序集中引用,Newtonsoft.Json.dll需要在NuGet中下载引用。 详细代码…...
)
华为OD机试真题-中文分词模拟器-2023年OD统一考试(C卷)
题目描述: 给定一个连续不包含空格字符串,该字符串仅包含英文小写字母及英文文标点符号(逗号、分号、句号),同时给定词库,对该字符串进行精确分词。 说明: 1.精确分词: 字符串分词后,不会出现重叠。即“ilovechina” ,不同词库可分割为 “i,love,china” “ilove,c…...

【并发设计模式】聊聊 基于Copy-on-Write模式下的CopyOnWriteArrayList
在并发编程领域,其实除了使用上一篇中的属性不可变。还有一种方式那就是针对读多写少的场景下。我们可以读不加锁,只针对于写操作进行加锁。本质上就是读写复制。读的直接读取,写的使用写一份数据的拷贝数据,然后进行写入。在将新…...

OpenCV中使用Mask R-CNN实现图像分割的原理与技术实现方案
本文详细介绍了在OpenCV中利用Mask R-CNN实现图像分割的原理和技术实现方案。Mask R-CNN是一种先进的深度学习模型,通过结合区域提议网络(Region Proposal Network)和全卷积网络(Fully Convolutional Network)…...

论文阅读《Rethinking Efficient Lane Detection via Curve Modeling》
目录 Abstract 1. Introduction 2. Related Work 3. BezierLaneNet 3.1. Overview 3.2. Feature Flip Fusion 3.3. End-to-end Fit of a Bezier Curve 4. Experiments 4.1. Datasets 4.2. Evalutaion Metics 4.3. Implementation Details 4.4. Comparisons 4.5. A…...
Leetcode—2660.保龄球游戏的获胜者【简单】
2023每日刷题(七十二) Leetcode—2660.保龄球游戏的获胜者 实现代码 class Solution { public:int isWinner(vector<int>& player1, vector<int>& player2) {long long sum1 0, sum2 0;int n player1.size();for(int i 0; i &…...

智慧工地云平台源码,基于微服务架构+Java+Spring Cloud +UniApp +MySql
智慧工地管理云平台系统,智慧工地全套源码,java版智慧工地源码,支持PC端、大屏端、移动端。 智慧工地聚焦建筑行业的市场需求,提供“平台网络终端”的整体解决方案,提供劳务管理、视频管理、智能监测、绿色施工、安全管…...

练习(含atoi的模拟实现,自定义类型等练习)
一、结构体大小的计算及位段 (结构体大小计算及位段 详解请看:自定义类型:结构体进阶-CSDN博客) 1.在32位系统环境,编译选项为4字节对齐,那么sizeof(A)和sizeof(B)是多少? #pragma pack(4)st…...

【Linux】C语言执行shell指令
在C语言中执行Shell指令 在C语言中,有几种方法可以执行Shell指令: 1. 使用system()函数 这是最简单的方法,包含在stdlib.h头文件中: #include <stdlib.h>int main() {system("ls -l"); // 执行ls -l命令retu…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

CentOS下的分布式内存计算Spark环境部署
一、Spark 核心架构与应用场景 1.1 分布式计算引擎的核心优势 Spark 是基于内存的分布式计算框架,相比 MapReduce 具有以下核心优势: 内存计算:数据可常驻内存,迭代计算性能提升 10-100 倍(文档段落:3-79…...

江苏艾立泰跨国资源接力:废料变黄金的绿色供应链革命
在华东塑料包装行业面临限塑令深度调整的背景下,江苏艾立泰以一场跨国资源接力的创新实践,重新定义了绿色供应链的边界。 跨国回收网络:废料变黄金的全球棋局 艾立泰在欧洲、东南亚建立再生塑料回收点,将海外废弃包装箱通过标准…...

【HTML-16】深入理解HTML中的块元素与行内元素
HTML元素根据其显示特性可以分为两大类:块元素(Block-level Elements)和行内元素(Inline Elements)。理解这两者的区别对于构建良好的网页布局至关重要。本文将全面解析这两种元素的特性、区别以及实际应用场景。 1. 块元素(Block-level Elements) 1.1 基本特性 …...

IT供电系统绝缘监测及故障定位解决方案
随着新能源的快速发展,光伏电站、储能系统及充电设备已广泛应用于现代能源网络。在光伏领域,IT供电系统凭借其持续供电性好、安全性高等优势成为光伏首选,但在长期运行中,例如老化、潮湿、隐裂、机械损伤等问题会影响光伏板绝缘层…...

【从零学习JVM|第三篇】类的生命周期(高频面试题)
前言: 在Java编程中,类的生命周期是指类从被加载到内存中开始,到被卸载出内存为止的整个过程。了解类的生命周期对于理解Java程序的运行机制以及性能优化非常重要。本文会深入探寻类的生命周期,让读者对此有深刻印象。 目录 …...

Java求职者面试指南:计算机基础与源码原理深度解析
Java求职者面试指南:计算机基础与源码原理深度解析 第一轮提问:基础概念问题 1. 请解释什么是进程和线程的区别? 面试官:进程是程序的一次执行过程,是系统进行资源分配和调度的基本单位;而线程是进程中的…...