elasticsearch 笔记三:查询建议介绍、Suggester、自动完成
一、查询建议介绍
1. 查询建议是什么?
查询建议,为用户提供良好的使用体验。主要包括: 拼写检查; 自动建议查询词(自动补全)
拼写检查如图:
自动建议查询词(自动补全):
2. ES 中查询建议的 API
查询建议也是使用_search 端点地址。在 DSL 中 suggest 节点来定义需要的建议查询
示例 1:定义单个建议查询词
POST twitter/_search
{"query" : {"match": {"message": "tring out Elasticsearch"}},"suggest" : { <!-- 定义建议查询 -->"my-suggestion" : { <!-- 一个建议查询名 -->"text" : "tring out Elasticsearch", <!-- 查询文本 -->"term" : { <!-- 使用词项建议器 -->"field" : "message" <!-- 指定在哪个字段上获取建议词 -->}}}
}
示例 2:定义多个建议查询词
POST _search
{"suggest": {"my-suggest-1" : {"text" : "tring out Elasticsearch","term" : {"field" : "message"}},"my-suggest-2" : {"text" : "kmichy","term" : {"field" : "user"}}}
}
示例 3:多个建议查询可以使用全局的查询文本
POST _search
{"suggest": {"text" : "tring out Elasticsearch","my-suggest-1" : {"term" : {"field" : "message"}},"my-suggest-2" : {"term" : {"field" : "user"}}}
}
二、准备数据
准备一个叫做blogs的索引,配置一个text字段。
PUT /blogs/
{"mappings": {"properties": {"body": {"type": "text"}}}
}
通过bulk api写入几条文档
POST _bulk/?refresh=true
{"index":{"_index":"blogs"}}
{"body":"Lucene is cool"}
{"index":{"_index":"blogs"}}
{"body":"Elasticsearch builds on top of lucene"}
{"index":{"_index":"blogs"}}
{"body":"Elasticsearch rocks"}
{"index":{"_index":"blogs"}}
{"body":"Elastic is the company behind ELK stack"}
{"index":{"_index":"blogs"}}
{"body":"elk rocks"}
{"index":{"_index":"blogs"}}
{"body":"elasticsearch is rock solid"}
此时blogs索引里已经有一些文档了,可以进行下一步的探索。为帮助理解,我们先看看哪些term会存在于词典里。
将输入的文本分析一下:
POST _analyze
{"text": ["Lucene is cool","Elasticsearch builds on top of lucene","Elasticsearch rocks","Elastic is the company behind ELK stack","elk rocks","elasticsearch is rock solid"]
}
这些分出来的token都会成为词典里一个term,注意有些token会出现多次,因此在倒排索引里记录的词频会比较高,同时记录的还有这些token在原文档里的偏移量和相对位置信息。
三、Suggester 介绍
Term Suggester: 对给入的文本进行分词,为每个词进行模糊查询提供词项建议,并不会考虑多个term/词组之间的关系。。API调用方只需为每个token挑选options里的词,组合在一起返回给用户前端即可Phrase Suggester,在Term Suggester的基础上,会考量多个term之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等等Completion Suggester,FST数据结构,类似Trie树,不用打开倒排,快速返回,前缀匹配Context Suggester,在Completion Suggester的基础上,用于filter和boost
1. Term suggester
term 词项建议器,对给入的文本进行分词,为每个词进行模糊查询提供词项建议。对于在索引中存在词默认不提供建议词,不存在的词则根据模糊查询结果进行排序后取一定数量的建议词。
常用的建议选项:
text | 搜索文本。建议文本是必填选项,需要全局或按建议设置。 |
|---|---|
field | 从中获取候选建议的字段。这是必需选项,需要全局设置或根据建议设置。 |
analyzer | 分析器用来分析建议文本。默认为建议字段的搜索分析器。 |
size | 每个建议文本将返回的最大数。 |
sort | 定义每个建议文本术语应如何分类建议。两个可能的值:score:首先按分数排序,然后记录频次,然后是词条本身。frequency:首先按文档频率排序,然后按相似性得分排序,然后再按术语本身排序。 |
suggest_mode | 提示模式控制要包含的建议,或控制建议的文本术语和建议的控件。可以指定三个可能的值:missing:仅对未在索引中的建议文本术语提供建议。这是默认值。popular:仅建议在比原始建议文本术语更多的文档中出现的建议。always:根据建议文本中的术语建议任何匹配的建议。 |
lowercase_terms | 在文本分析之后,将建议的文本术语小写。 |
max_edits | 最大编辑距离候选建议可以具有以便被认为是建议。只能是 1 到 2 之间的值。任何其他值都将导致引发错误的请求错误。默认为 2。 |
prefix_length | 必须匹配的最小前缀字符数才能成为建议的候选者。默认值为 1。增加此数字可提高拼写检查性能。通常,拼写错误不会出现在学期开始时。(旧名称 “prefix_len” 已弃用) |
示例 1:
POST twitter/_search
{"suggest" : { <!-- 定义建议查询 -->"my-suggestion" : { <!-- 一个建议查询名 -->"text" : "lucne rock", <!-- 查询文本 -->"term" : { <!-- 使用词项建议器 -->"suggest_mode": "missing","field" : "body" <!-- 指定在哪个字段上获取建议词 -->}}}
}
返回结果
{"took" : 2,"timed_out" : false,"_shards" : {"total" : 1,"successful" : 1,"skipped" : 0,"failed" : 0},"hits" : {"total" : {"value" : 0,"relation" : "eq"},"max_score" : null,"hits" : [ ]},"suggest" : {"my-suggestion" : [{"text" : "lucne","offset" : 0,"length" : 5,"options" : [{"text" : "lucene","score" : 0.8,"freq" : 2}]},{"text" : "rock","offset" : 6,"length" : 4,"options" : [ ]}]}
}
在返回结果里"suggest" -> “my-suggestion"部分包含了一个数组,每个数组项对应从输入文本分解出来的token(存放在"text"这个key里)以及为该token提供的建议词项(存放在options数组里)。 示例里返回了"lucne”,"rock"这2个词的建议项(options),其中"rock"的options是空的,表示没有可以建议的选项,为什么? 上面提到了,我们为查询提供的suggest mode是"missing",由于"rock"在索引的词典里已经存在了,够精准,就不建议啦。 只有词典里找不到词,才会为其提供相似的选项。
如果将"suggest_mode"换成"popular"会是什么效果?
尝试一下,重新执行查询,返回结果里"rock"这个词的option不再是空的,而是建议为rocks。
"suggest" : {"my-suggestion" : [{"text" : "lucne","offset" : 0,"length" : 5,"options" : [{"text" : "lucene","score" : 0.8,"freq" : 2}]},{"text" : "rock","offset" : 6,"length" : 4,"options" : [{"text" : "rocks","score" : 0.75,"freq" : 2}]}]}
回想一下,rock和rocks在索引词典里都是有的。 不难看出即使用户输入的token在索引的词典里已经有了,但是因为存在一个词频更高的相似项,这个相似项可能是更合适的,就被挑选到options里了。 最后还有一个"always" mode,其含义是不管token是否存在于索引词典里都要给出相似项。
Term suggester正如其名,只基于analyze过的单个term去提供建议,并不会考虑多个term之间的关系。API调用方只需为每个token挑选options里的词,组合在一起返回给用户前端即可。 那么有无更直接办法,API直接给出和用户输入文本相似的内容? 答案是有,这就要求助Phrase Suggester了。
2. phrase suggester
phrase 短语建议,在 term 的基础上,会考量多个 term 之间的关系,比如是否同时出现在索引的原文里,相邻程度,以及词频等
看个范例就比较容易明白了:
POST /blogs/_search
{"suggest": {"my-suggestion": {"text": "lucne and elasticsear rock","phrase": {"field": "body","highlight": {"pre_tag": "<em>","post_tag": "</em>"}}}}
}
返回结果:
"suggest" : {"my-suggestion" : [{"text" : "lucne and elasticsear rock","offset" : 0,"length" : 26,"options" : [{"text" : "lucene and elasticsearch rock","highlighted" : "<em>lucene</em> and <em>elasticsearch</em> rock","score" : 0.004993905},{"text" : "lucne and elasticsearch rock","highlighted" : "lucne and <em>elasticsearch</em> rock","score" : 0.0033391973},{"text" : "lucene and elasticsear rock","highlighted" : "<em>lucene</em> and elasticsear rock","score" : 0.0029183894}]}]}
options直接返回一个phrase列表,由于加了highlight选项,被替换的term会被高亮。因为lucene和elasticsearch曾经在同一条原文里出现过,同时替换2个term的可信度更高,所以打分较高,排在第一位返回。Phrase suggester有相当多的参数用于控制匹配的模糊程度,需要根据实际应用情况去挑选和调试。
3. Completion suggester 自动补全
针对自动补全(“Auto Completion”)场景而设计的建议器。此场景下用户每输入一个字符的时候,就需要即时发送一次查询请求到后端查找匹配项,在用户输入速度较高的情况下对后端响应速度要求比较苛刻。因此实现上它和前面两个 Suggester 采用了不同的数据结构,索引并非通过倒排来完成,而是将 analyze 过的数据编码成 FST 和索引一起存放。对于一个 open 状态的索引,FST 会被 ES 整个装载到内存里的,进行前缀查找速度极快。 但是 FST 只能用于前缀查找,这也是 Completion Suggester 的局限所在。
官网链接:
https://www.elastic.co/guide/en/elasticsearch/reference/current/search-suggesters-completion.html
-
completion:es 的一种特有类型,专门为 suggest 提供,基于内存,性能很高。
-
prefix query:基于前缀查询的搜索提示,是最常用的一种搜索推荐查询。
- prefix:客户端搜索词
- field:建议词字段
- size:需要返回的建议词数量(默认 5)
- skip_duplicates:是否过滤掉重复建议,默认 false
-
fuzzy query
- fuzziness:允许的偏移量,默认 auto
- transpositions:如果设置为 true,则换位计为一次更改而不是两次更改,默认为 true。
- min_length:返回模糊建议之前的最小输入长度,默认 3
- prefix_length:输入的最小长度(不检查模糊替代项)默认为 1
- unicode_aware:如果为 true,则所有度量(如模糊编辑距离,换位和长度)均以 Unicode 代码点而不是以字节为单位。这比原始字节略慢,因此默认情况下将其设置为 false。
-
regex query:可以用正则表示前缀,不建议使用
为了使用自动补全,索引中用来提供补全建议的字段需特殊设计,字段类型为 completion。
PUT /blogs_completion/
{"mappings": {"properties": {"body": {"type": "completion"}}}
}
用bulk API索引点数据:
POST _bulk/?refresh=true
{"index":{"_index":"blogs_completion"}}
{"body":"Lucene is cool"}
{"index":{"_index":"blogs_completion"}}
{"body":"Elasticsearch builds on top of lucene"}
{"index":{"_index":"blogs_completion"}}
{"body":"Elasticsearch rocks"}
{"index":{"_index":"blogs_completion"}}
{"body":"Elastic is the company behind ELK stack"}
{"index":{"_index":"blogs_completion"}}
{"body":"the elk stack rocks"}
{"index":{"_index":"blogs_completion"}}
{"body":"elasticsearch is rock solid"}
查找:
POST blogs_completion/_search?pretty
{"size": 0,"suggest": {"blog-suggest": {"prefix": "elastic i","completion": {"field": "body"}}}
}
结果:
"suggest" : {"blog-suggest" : [{"text" : "elastic i","offset" : 0,"length" : 9,"options" : [{"text" : "Elastic is the company behind ELK stack","_index" : "blogs_completion","_type" : "_doc","_id" : "8nI0YYwBPMQ17EXsspBh","_score" : 1.0,"_source" : {"body" : "Elastic is the company behind ELK stack"}}]}]}
值得注意的一点是Completion Suggester在索引原始数据的时候也要经过analyze阶段,取决于选用的analyzer不同,某些词可能会被转换,某些词可能被去除,这些会影响FST编码结果,也会影响查找匹配的效果。
比如我们删除上面的索引,重新设置索引的mapping,将analyzer更改为"english":
DELETE blogs_completion
PUT /blogs_completion/
{"mappings": {"properties": {"body": {"type": "completion","analyzer": "english"}}}
}
bulk api索引同样的数据后,执行下面的查询:
POST blogs_completion/_search?pretty
{"size": 0,"suggest": {"blog-suggest": {"prefix": "elastic i","completion": {"field": "body"}}}
}
居然没有匹配结果了,多么费解! 原来我们用的english analyzer会剥离掉stop word,而is就是其中一个,被剥离掉了!
用analyze api测试一下:
POST _analyze
{"analyzer": "english","text": "elasticsearch is rock solid"
}
会发现只有3个token:
{"tokens" : [{"token" : "elasticsearch","start_offset" : 0,"end_offset" : 13,"type" : "<ALPHANUM>","position" : 0},{"token" : "rock","start_offset" : 17,"end_offset" : 21,"type" : "<ALPHANUM>","position" : 2},{"token" : "solid","start_offset" : 22,"end_offset" : 27,"type" : "<ALPHANUM>","position" : 3}]
}
FST只编码了这3个token,并且默认的还会记录他们在文档中的位置和分隔符。 用户输入"elastic i"进行查找的时候,输入被分解成"elastic"和"i",FST没有编码这个“i” , 匹配失败。
好吧,如果你现在还足够清醒的话,试一下搜索"elastic is",会发现又有结果,why? 因为这次输入的text经过english analyzer的时候is也被剥离了,只需在FST里查询"elastic"这个前缀,自然就可以匹配到了。
其他能影响completion suggester结果的,还有诸如"preserve_separators","preserve_position_increments"等等mapping参数来控制匹配的模糊程度。以及搜索时可以选用Fuzzy Queries,使得上面例子里的"elastic i"在使用english analyzer的情况下依然可以匹配到结果。
因此用好Completion Sugester并不是一件容易的事,实际应用开发过程中,需要根据数据特性和业务需要,灵活搭配analyzer和mapping参数,反复调试才可能获得理想的补全效果。
回到篇首百度搜索框的补全/纠错功能,如果用ES怎么实现呢?我能想到的一个的实现方式:
- 在用户刚开始输入的过程中,使用Completion Suggester进行关键词前缀匹配,刚开始匹配项会比较多,随着用户输入字符增多,匹配项越来越少。如果用户输入比较精准,可能Completion Suggester的结果已经够好,用户已经可以看到理想的备选项了。
- 如果Completion Suggester已经到了零匹配,那么可以猜测是否用户有输入错误,这时候可以尝试一下Phrase Suggester。
- 如果Phrase Suggester没有找到任何option,开始尝试term Suggester。
精准程度上(Precision)看: Completion > Phrase > term, 而召回率上(Recall)则反之。从性能上看,Completion Suggester是最快的,如果能满足业务需求,只用Completion Suggester做前缀匹配是最理想的。 Phrase和Term由于是做倒排索引的搜索,相比较而言性能应该要低不少,应尽量控制suggester用到的索引的数据量,最理想的状况是经过一定时间预热后,索引可以全量map到内存。
4. context suggester
完成建议者会考虑索引中的所有文档,但是通常来说,我们在进行智能推荐的时候最好通过某些条件过滤,并且有可能会针对某些特性提升权重。
-
contexts:上下文对象,可以定义多个
-
name:context的名字,用于区分同一个索引中不同的context对象。需要在查询的时候指定当前name
-
type:context对象的类型,目前支持两种:category和geo,分别用于对suggest item分类和指定地理位置。
-
boost:权重值,用于提升排名
-
-
path:如果没有path,相当于在PUT数据的时候需要指定context.name字段,如果在Mapping中指定了path,在PUT数据的时候就不需要了,因为 Mapping是一次性的,而PUT数据是频繁操作,这样就简化了代码。这段解释有木有很牛逼,网上搜到的都是官方文档的翻译,觉悟雷同。
# context suggester
# 定义一个名为 place_type 的类别上下文,其中类别必须与建议一起发送。
# 定义一个名为 location 的地理上下文,类别必须与建议一起发送
DELETE place
PUT place
{"mappings": {"properties": {"suggest": {"type": "completion","contexts": [{"name": "place_type","type": "category"},{"name": "location","type": "geo","precision": 4}]}}}
}PUT place/_doc/1
{"suggest": {"input": [ "timmy's", "starbucks", "dunkin donuts" ],"contexts": {"place_type": [ "cafe", "food" ] }}
}
PUT place/_doc/2
{"suggest": {"input": [ "monkey", "timmy's", "Lamborghini" ],"contexts": {"place_type": [ "money"] }}
}GET place/_search
POST place/_search?pretty
{"suggest": {"place_suggestion": {"prefix": "sta","completion": {"field": "suggest","size": 10,"contexts": {"place_type": [ "cafe", "restaurants" ]}}}}
}
# 某些类别的建议可以比其他类别提升得更高。以下按类别过滤建议,并额外提升与某些类别相关的建议
GET place/_search
POST place/_search?pretty
{"suggest": {"place_suggestion": {"prefix": "tim","completion": {"field": "suggest","contexts": {"place_type": [ { "context": "cafe" },{ "context": "money", "boost": 2 }]}}}}
}# 地理位置筛选器
PUT place/_doc/3
{"suggest": {"input": "timmy's","contexts": {"location": [{"lat": 43.6624803,"lon": -79.3863353},{"lat": 43.6624718,"lon": -79.3873227}]}}
}
POST place/_search
{"suggest": {"place_suggestion": {"prefix": "tim","completion": {"field": "suggest","contexts": {"location": {"lat": 43.662,"lon": -79.380}}}}}
}# 定义一个名为 place_type 的类别上下文,其中类别是从 cat 字段中读取的。
# 定义一个名为 location 的地理上下文,其中的类别是从 loc 字段中读取的
DELETE place_path_category
PUT place_path_category
{"mappings": {"properties": {"suggest": {"type": "completion","contexts": [{"name": "place_type","type": "category","path": "cat"},{"name": "location","type": "geo","precision": 4,"path": "loc"}]},"loc": {"type": "geo_point"}}}
}
# 如果映射有路径,那么以下索引请求就足以添加类别
# 这些建议将与咖啡馆和食品类别相关联
# 如果上下文映射引用另一个字段并且类别被明确索引,则建议将使用两组类别进行索引
PUT place_path_category/_doc/1
{"suggest": ["timmy's", "starbucks", "dunkin donuts"],"cat": ["cafe", "food"]
}
POST place_path_category/_search?pretty
{"suggest": {"place_suggestion": {"prefix": "tim","completion": {"field": "suggest","contexts": {"place_type": [ { "context": "cafe" }]}}}}
}
参考
官网
相关文章:
elasticsearch 笔记三:查询建议介绍、Suggester、自动完成
一、查询建议介绍 1. 查询建议是什么? 查询建议,为用户提供良好的使用体验。主要包括: 拼写检查; 自动建议查询词(自动补全) 拼写检查如图: 自动建议查询词(自动补全)…...
【hyperledger-fabric】将智能合约部署到通道
简介 本文主要来自于B站视频教学视频,也主要参看了官方文档中下图这一章节。针对自己开发的代码做出相应的总结。 1.启动网络 # 跳转到指定的目录 cd /root/fabric/fabric-samples/test-network# 启动docker容器并且创建通道 ./network.sh up createChannel2.打…...

nginx设置跨域访问
目录 一:前端请求 二:后端设置 网站架构前端使用jquery请求,后端使用nginxphp-fpm 一:前端请求 <script> $.getJSON(http://nngzh.youjoy.com/cc.php, { openid: sd, }, function(res) { alert(res); if(res.code 0) …...

Go语言学习第二天
Go语言数组详解 var 数组变量名 [元素数量]Type 数组变量名:数组声明及使用时的变量名。 元素数量:数组的元素数量,可以是一个表达式,但最终通过编译期计算的结果必须是整型数值,元素数量不能含有到运行时才能确认大小…...
阿里云OpenSearch-LLM智能问答故障的一天
上周五使用阿里云开放搜索问答版时,故障了一整天,可能这个服务使用的人比较少,没有什么消息爆出来,特此记录下这几天的阿里云处理过程,不免让人怀疑阿里云整体都外包出去了,反应迟钝,水平业余&a…...

城市分站优化系统源码:提升百度关键排名 附带完整的搭建教程
城市分站优化已成为企业网络营销的重要手段,今天来给大家分享一款城市分站优化系统源码。 以下是部分代码示例: 系统特色功能一览: 1.多城市分站管理:该系统支持多个城市分站的管理,用户可以根据业务需求,…...

【华为OD题库-107】编码能力提升计划-java
题目 为了提升软件编码能力,小王制定了刷题计划,他选了题库中的n道题,编号从0到n-1,并计划在m天内按照题目编号顺序刷完所有的题目(注意,小王不能用多天完成同一题) 在小王刷题计划中,小王需要用time[i]的时…...

使用pytorch进行图像预处理的常用方法的详细解释
一般来说,我们在使用pytorch进行图像分类任务时都会对训练集数据做必要的格式转换和增广处理,对测试集做格式处理。 以下是常用的数据集处理函数: data_transform { "train": transforms.Compose([transforms.RandomResizedCro…...

天线根据什么进行分类
天线是信息化时代的一个标准,广播信号塔,通信基站塔,卫星天线还有每天都要用到的手机,都是含有天线的,只是各种天线的作用不同,大小不同。今天给大家说一下,天线是如何分类的。 1.按工作性质可…...
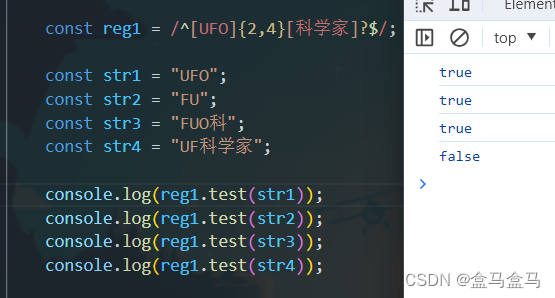
JavaScript:正则表达式
JavaScript:正则表达式 什么是正则表达式正则表达式语法定义正则表达式判断是否有匹配的字符串查找匹配的字符串 正则表达式匹配法则元字符边界符量词字符类 什么是正则表达式 正则表达式用于匹配字符串中字符的组合模式。 正则表达式会依据其自身语法,…...
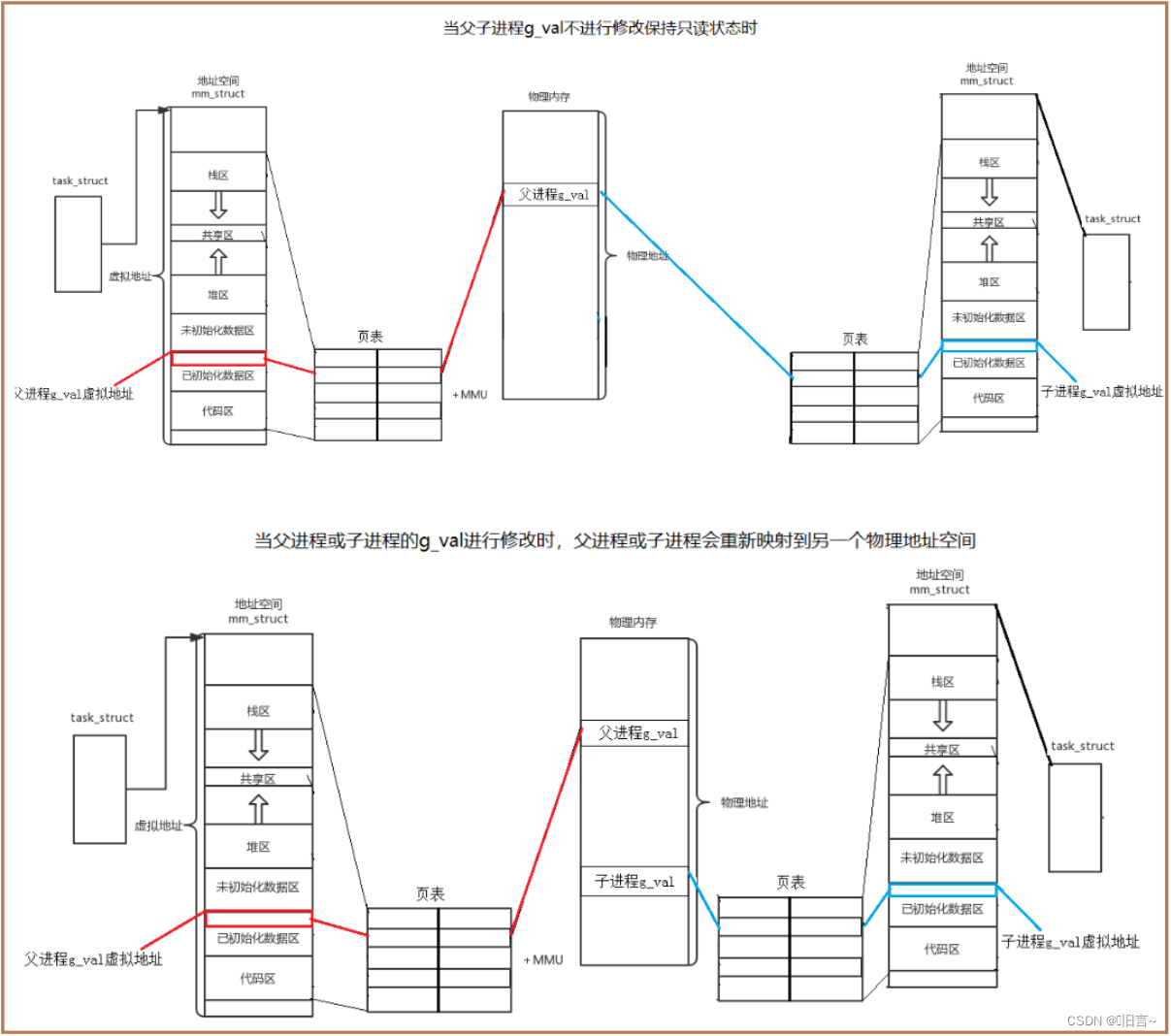
【Linux】深挖进程地址空间
> 作者简介:დ旧言~,目前大二,现在学习Java,c,c,Python等 > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:熟悉【Linux】进程地址空间 > 毒鸡汤ÿ…...

SVM(支持向量机)-机器学习
支持向量机(Support Vector Machine,SVM)是一种用于分类和回归分析的监督学习算法。它属于机器学习中的一类强大而灵活的模型,广泛应用于模式识别、图像分类、自然语言处理等领域。 基本原理: SVM的基本原理是通过找到能够有效分…...

解决生成的insert语句内有单引号的情况
背景 因为Mybatis-Plus的saveBatch()方法的批量插入其实也是循环插入,而不是真正的一个SqlSession完成的批插,效率很低。所以我们在写批量插入的时候是自己实现了一个工具类去生成批量插入的sql再去执行,但是会遇到有些文本里有单引号导致插…...

【Linux 程序】1. 程序构建
文章目录 【 1. 配置 】【 2. 编译 】makefile编写的要点makefile中的全局自变量CMake编译依赖的库g编译 【 3. 安装 】 一般源代码提供的程序安装需要通过配置、编译、安装三个步骤; 配置。检查当前环境是否满足要安装软件的依赖关系,以及设置程序安装所…...
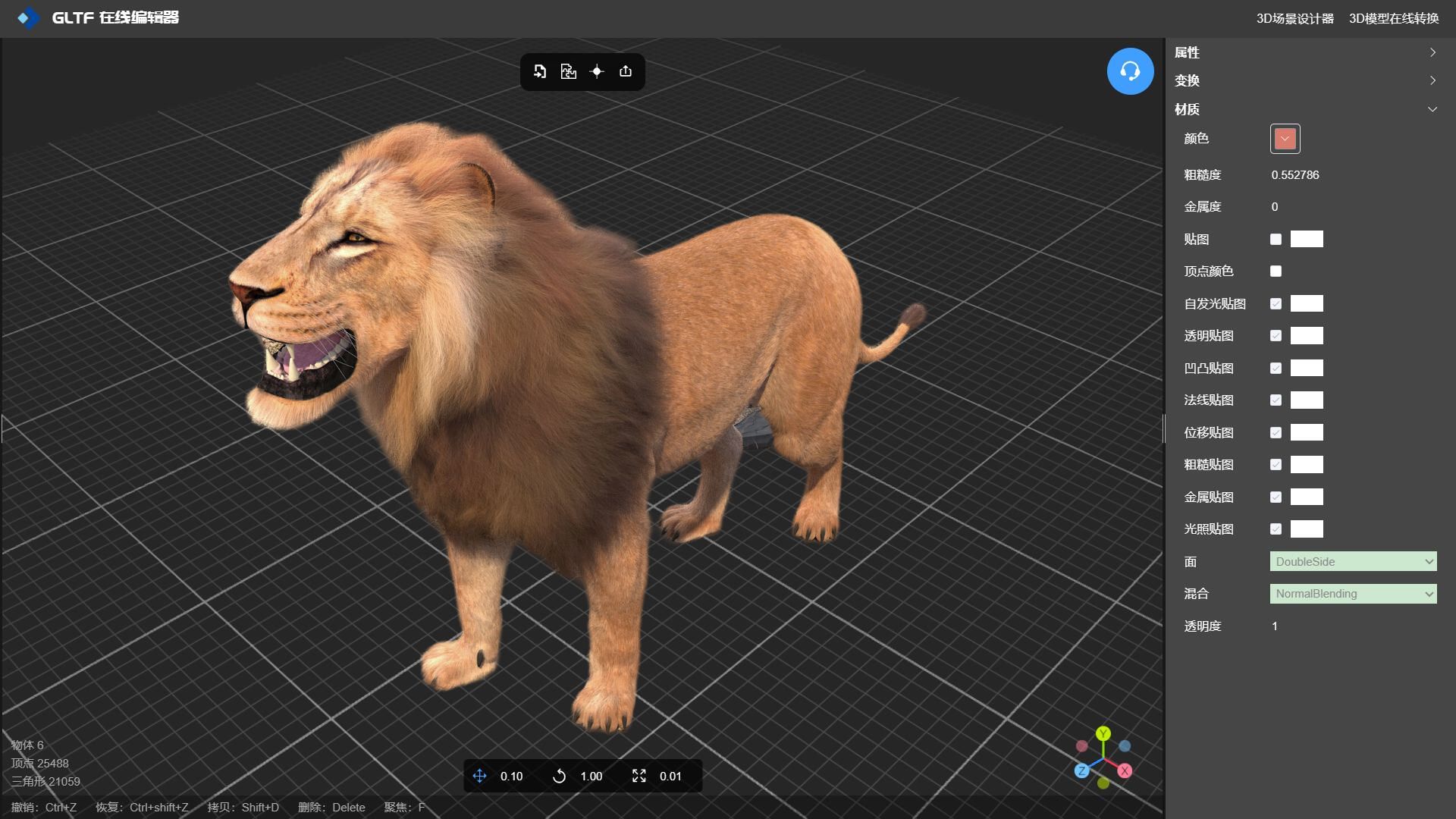
GLTF 编辑器实现逼真3D动物毛发效果
在线工具推荐: 3D数字孪生场景编辑器 - GLTF/GLB材质纹理编辑器 - 3D模型在线转换 - Three.js AI自动纹理开发包 - YOLO 虚幻合成数据生成器 - 三维模型预览图生成器 - 3D模型语义搜索引擎 要实现逼真的3D动物毛发效果,可以采用以下技术和方法&…...

【Go语言入门:Go语言的方法,函数,接口】
文章目录 4.Go语言的方法,函数,接口4.1. 方法4.1.1. 指针接受者4.1.2. 值接收者和指针接收者有什么区别?4.1.3. 方法 4.2. 接口4.2.1. 接口定义 4.3. 函数4.3.1. 函数介绍 4.Go语言的方法,函数,接口 4.1. 方法 4.1.1…...
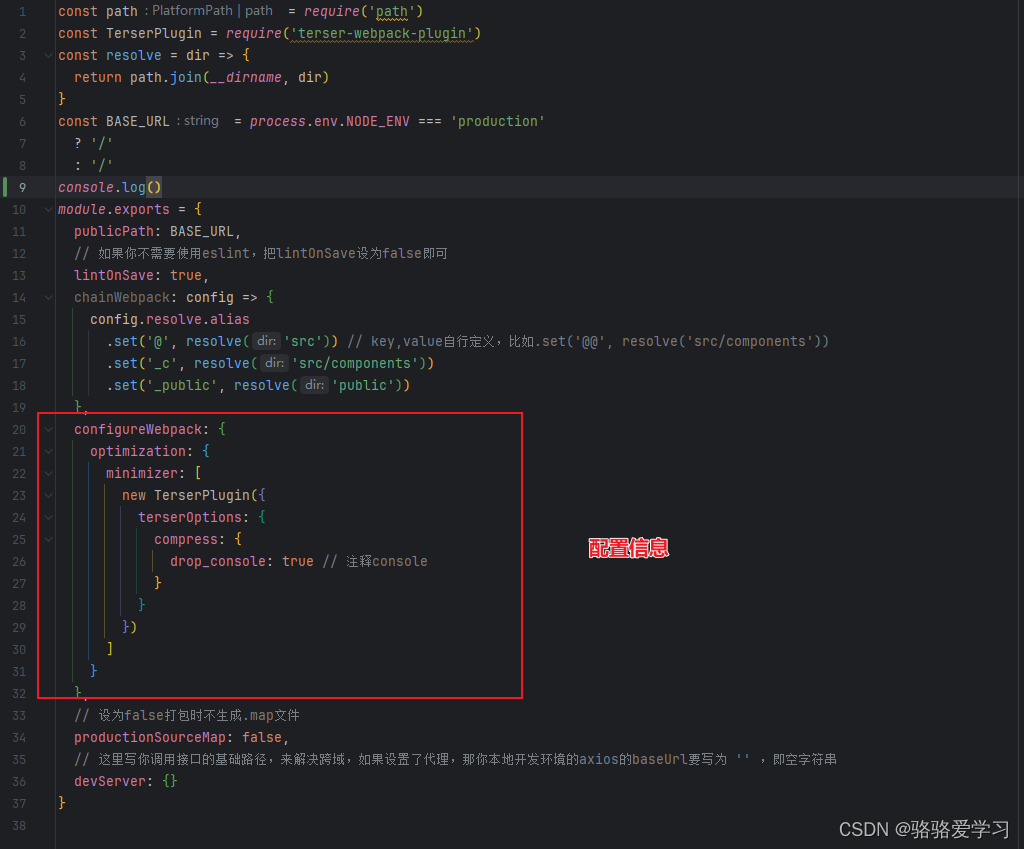
vue-cli3/webpack打包时去掉console.log调试信息
文章目录 前言一、terser-webpack-plugin是什么?二、使用配置vue-cli项目 前言 开发环境下,console.log调试信息,有助于我们找到错误,但在生产环境,不需要console.log打印调试信息,所以打包时需要将consol…...

企业品牌推广在国外媒体投放的意义和作用何在?
海外广告投放是企业在国际市场推广的重要战略,具有多种形式,包括社交媒体广告、短视频广告、电视广告等。这些广告形式在传播信息、推动销售、塑造品牌形象等方面发挥着独特的作用。 其中软文发稿是一种注重叙事和信息传递的广告形式,对于企…...
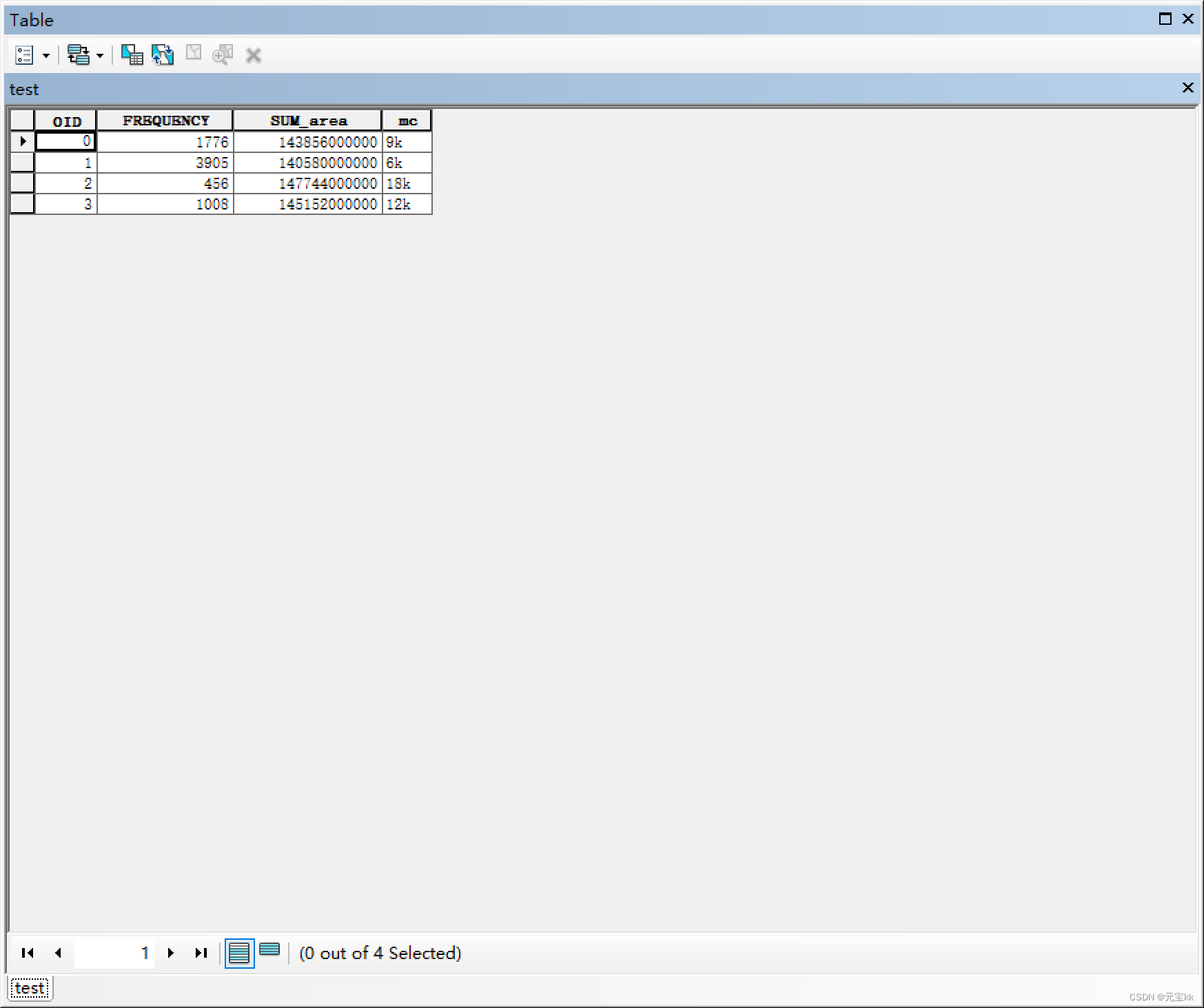
ArcGIS批量计算shp面积并导出shp数据总面积(建模法)
在处理shp数据时, 又是我们需要知道许多个shp字段的批量计算,例如计算shp的总面积、面积平均值等,但是单个查看shp文件的属性进行汇总过于繁琐,因此可以借助建模批处理来计算。 首先准备数据:一个含有多个shp的文件夹。…...
代码质量评价及设计原则
1.评价代码质量的标准 1.1 可维护性 可维护性强的代码指的是: 在不去破坏原有的代码设计以及不引入新的BUG的前提下,能够快速的修改或者新增代码. 不易维护的代码指的是: 在添加或者修改一些功能逻辑的时候,存在极大的引入新的BUG的风险,并且需要花费的时间也很长. 代码可…...

eNSP-Cloud(实现本地电脑与eNSP内设备之间通信)
说明: 想象一下,你正在用eNSP搭建一个虚拟的网络世界,里面有虚拟的路由器、交换机、电脑(PC)等等。这些设备都在你的电脑里面“运行”,它们之间可以互相通信,就像一个封闭的小王国。 但是&#…...

ES6从入门到精通:前言
ES6简介 ES6(ECMAScript 2015)是JavaScript语言的重大更新,引入了许多新特性,包括语法糖、新数据类型、模块化支持等,显著提升了开发效率和代码可维护性。 核心知识点概览 变量声明 let 和 const 取代 var…...

微软PowerBI考试 PL300-选择 Power BI 模型框架【附练习数据】
微软PowerBI考试 PL300-选择 Power BI 模型框架 20 多年来,Microsoft 持续对企业商业智能 (BI) 进行大量投资。 Azure Analysis Services (AAS) 和 SQL Server Analysis Services (SSAS) 基于无数企业使用的成熟的 BI 数据建模技术。 同样的技术也是 Power BI 数据…...

【力扣数据库知识手册笔记】索引
索引 索引的优缺点 优点1. 通过创建唯一性索引,可以保证数据库表中每一行数据的唯一性。2. 可以加快数据的检索速度(创建索引的主要原因)。3. 可以加速表和表之间的连接,实现数据的参考完整性。4. 可以在查询过程中,…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

java 实现excel文件转pdf | 无水印 | 无限制
文章目录 目录 文章目录 前言 1.项目远程仓库配置 2.pom文件引入相关依赖 3.代码破解 二、Excel转PDF 1.代码实现 2.Aspose.License.xml 授权文件 总结 前言 java处理excel转pdf一直没找到什么好用的免费jar包工具,自己手写的难度,恐怕高级程序员花费一年的事件,也…...

高频面试之3Zookeeper
高频面试之3Zookeeper 文章目录 高频面试之3Zookeeper3.1 常用命令3.2 选举机制3.3 Zookeeper符合法则中哪两个?3.4 Zookeeper脑裂3.5 Zookeeper用来干嘛了 3.1 常用命令 ls、get、create、delete、deleteall3.2 选举机制 半数机制(过半机制࿰…...

服务器硬防的应用场景都有哪些?
服务器硬防是指一种通过硬件设备层面的安全措施来防御服务器系统受到网络攻击的方式,避免服务器受到各种恶意攻击和网络威胁,那么,服务器硬防通常都会应用在哪些场景当中呢? 硬防服务器中一般会配备入侵检测系统和预防系统&#x…...

376. Wiggle Subsequence
376. Wiggle Subsequence 代码 class Solution { public:int wiggleMaxLength(vector<int>& nums) {int n nums.size();int res 1;int prediff 0;int curdiff 0;for(int i 0;i < n-1;i){curdiff nums[i1] - nums[i];if( (prediff > 0 && curdif…...

Java-41 深入浅出 Spring - 声明式事务的支持 事务配置 XML模式 XML+注解模式
点一下关注吧!!!非常感谢!!持续更新!!! 🚀 AI篇持续更新中!(长期更新) 目前2025年06月05日更新到: AI炼丹日志-28 - Aud…...