Hadoop(2):常见的MapReduce[在Ubuntu中运行!]
1 以词频统计为例子介绍 mapreduce怎么写出来的
弄清楚MapReduce的各个过程:

将文件输入后,返回的<k1,v1>代表的含义是:k1表示偏移量,即v1的第一个字母在文件中的索引(从0开始数的);v1表示对应的一整行的值
map阶段:将每一行的内容按照空格进行分割后作为k2,将v2的值写为1后输出
reduce阶段:将相同的k2合并后,输出
1.1 创建Mapper、Reducer、Driver类
创建这三种类用的是一种方法,用Mapper举例如下:
注意选择父类
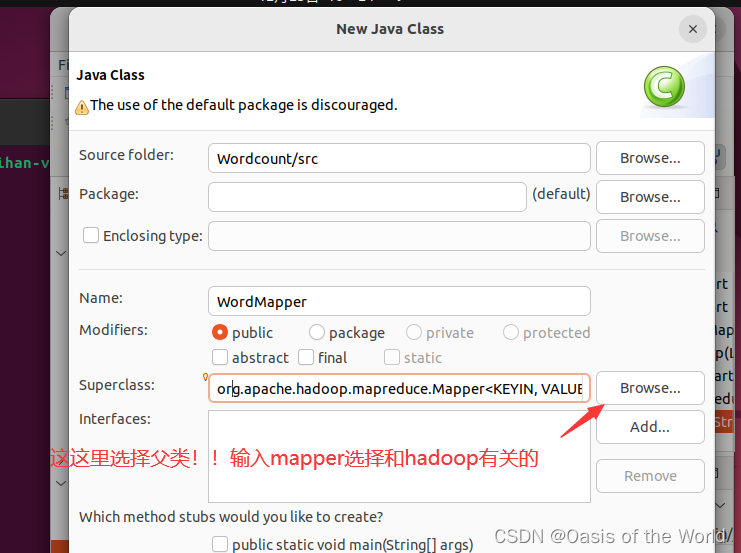
1.2 map阶段代码书写
(1)mapper源码
本来可以按住ctrl键后,点击open 后查看mapper源代码,但是在虚拟机里一直调不出来。所以从网上搜索出具体代码如下:
/*** Licensed to the Apache Software Foundation (ASF) under one* or more contributor license agreements. See the NOTICE file* distributed with this work for additional information* regarding copyright ownership. The ASF licenses this file* to you under the Apache License, Version 2.0 (the* "License"); you may not use this file except in compliance* with the License. You may obtain a copy of the License at** http://www.apache.org/licenses/LICENSE-2.0** Unless required by applicable law or agreed to in writing, software* distributed under the License is distributed on an "AS IS" BASIS,* WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.* See the License for the specific language governing permissions and* limitations under the License.*/package org.apache.hadoop.mapreduce;import java.io.IOException;import org.apache.hadoop.classification.InterfaceAudience;
import org.apache.hadoop.classification.InterfaceStability;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.io.RawComparator;
import org.apache.hadoop.io.compress.CompressionCodec;
import org.apache.hadoop.mapreduce.task.MapContextImpl;@InterfaceAudience.Public
@InterfaceStability.Stable
public class Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> {/*** The <code>Context</code> passed on to the {@link Mapper} implementations.*/public abstract class Contextimplements MapContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {}/*** Called once at the beginning of the task.*/protected void setup(Context context) throws IOException, InterruptedException {// NOTHING}/*** Called once for each key/value pair in the input split. Most applications* should override this, but the default is the identity function.*/@SuppressWarnings("unchecked")protected void map(KEYIN key, VALUEIN value, Context context) throws IOException, InterruptedException {context.write((KEYOUT) key, (VALUEOUT) value);}/*** Called once at the end of the task.*/protected void cleanup(Context context) throws IOException, InterruptedException {// NOTHING}/*** Expert users can override this method for more complete control over the* execution of the Mapper.* @param context* @throws IOException*/public void run(Context context) throws IOException, InterruptedException {setup(context);try {while (context.nextKeyValue()) {map(context.getCurrentKey(), context.getCurrentValue(), context);}} finally {cleanup(context);}}
}(2)修改的注意事项
注意我们需要修改的只是map方法
1. Mapper组件开发方式:自定义一个类,继承Mapper
2. Mapper组件的作用是定义每一个MapTask具体要怎么处理数据。例如一个文件,256MB,会生成2个MapTask(每个切片大小,默认是128MB,所以MapTask的多少有处理的数据大小来决定)。即2个MapTask处理逻辑是一样的,只是每个MapTask处理的数据不一样。
3. 下面是Mapper类中的4个泛型含义:a.泛型一:KEYIN:LongWritable,对应的Mapper的输入key。输入key是每行的行首偏移量b.泛型二: VALUEIN:Text,对应的Mapper的输入Value。输入value是每行的内容c.泛型三:KEYOUT:对应的Mapper的输出key,根据业务来定义d.泛型四:VALUEOUT:对应的Mapper的输出value,根据业务来定义
4. 注意:初学时,KEYIN和VALUEIN写死(LongWritable,Text)。KEYOUT和VALUEOUT不固定,根据业务来定
5. Writable机制是Hadoop自身的序列化机制,常用的类型:a. LongWritable b. Text(String)c. IntWritabled. NullWritable
6. 定义MapTask的任务逻辑是通过重写map()方法来实现的。
读取一行数据就会调用一次此方法,同时会把输入key和输入value进行传递
7. 在实际开发中,最重要的是拿到输入value(每行内容)
8. 输出方法:通过context.write(输出key,输出value)
9. 开发一个MapReduce程序(job),Mapper可以单独存储,此时,最后的输出的结果文件内容就是Mapper的输出。
10. Reducer组件不能单独存在,因为Reducer要依赖于Mapper的输出。当引入了Reducer之后,最后输出的结果文件的结果就是Reducer的输出。
(3)具体实例
重写map方法:输入map后 按住"alt"加"?" 后,就可以自动补全代码!
然后进行编写:
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;public class WordMapper extends Mapper<LongWritable, Text, Text, IntWritable> {@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text,IntWritable>.Context context)throws IOException, InterruptedException {//将value转换成字符串,再将其转化成字符串数组String line = value.toString(); //hello wordString[] wordarr = line.split(" ");for (String word:wordarr) {context.write(new Text(word), new IntWritable(1));} }}1.3 reducer阶段代码的书写
(1)reducer源码
和mapper差不多
(2)修改时的注意事项
1. Reducer组件用于接收Mapper组件的输出
2. reduce的输入key,value需要和mapper的输出key,value类型保持一致
3. reduce的输出key,value类型,根据具体业务决定
4. reduce收到map的输出,会按相同的key做聚合,
形成:key Iterable 形式然后通过reduce方法进行传递
5. reduce方法中的Iterable是一次性的,即遍历一次之后,再遍历,里面就没有数据了。
所以,在某些业务场景,会涉及到多次操作此迭代器,处理的方法是
:①先创建一个List ②把Iterable装到List ③多次去使用List即可
(3)具体案例
注意:IntWriter是一个迭代器!context负责输出!
import java.io.IOException;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.examples.SecondarySort.Reduce;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;public class WordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {@Overrideprotected void reduce(Text key, Iterable<IntWritable> values,Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {int total =0; for (IntWritable value:values) {total = total + value.get(); }context.write(key, new IntWritable(total));}
1.4 主函数代码的书写
【1】还未进行reducer阶段时
(1)主函数也就是驱动函数一般包含以下几个阶段:
注意:实例化job、设置输入文件地址、输出文件地址。这三个代码是固定的!!!每次都这样哦
import java.io.IOException;
public class WordDriver {public static void main(String[] args) throws Exception {//1.实例化jobConfiguration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");//2.关联class文件job.setJarByClass(WordDriver.class);job.setMapperClass(WordMapper.class);//3.设置"mapper"的输出数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//4.设置reducer的是输出数据类型//5.设置输入文件路径for(int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//6.设置输出文件路径FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); //7.提交job文件!System.exit(job.waitForCompletion(true)?0:1);}}
输出的结果为:
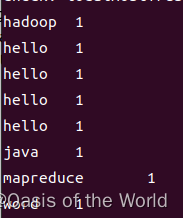
!!!!!!!!就是我们map阶段应该产生的结果!!!
【2】进行reducer阶段后
import java.io.IOException;
public class WordDriver {public static void main(String[] args) throws Exception {//1.实例化jobConfiguration conf = new Configuration();String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();if(otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");//2.关联class文件job.setJarByClass(WordDriver.class);job.setMapperClass(WordMapper.class);job.setReducerClass(WordReducer.class);//3.设置"mapper"的输出数据类型job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//4.设置reducer的是输出数据类型job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);//5.设置输入文件路径for(int i = 0; i < otherArgs.length - 1; ++i) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}//6.设置输出文件路径FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1])); //7.提交job文件!System.exit(job.waitForCompletion(true)?0:1);}}
1.5 在Ubuntu上运行
1.5.1 编译打包程序
现在就可以编译上面编写的代码。可以直接点击Eclipse工作界面上部的运行程序的快捷按钮,当把鼠标移动到该按钮上时,在弹出的菜单中选择“Run as”,继续在弹出来的菜单中选择“Java Application”,如下图所示。
然后,会弹出如下图所示界面。

点击界面右下角的“OK”按钮,开始运行程序。程序运行结束后,会在底部的“Console”面板中显示运行结果信息(如下图所示)。

下面就可以把Java应用程序打包生成JAR包,部署到Hadoop平台上运行。现在可以把词频统计程序放在“/usr/local/hadoop/myapp”目录下。如果该目录不存在,可以使用如下命令创建:
cd /usr/local/hadoop
mkdir myapp首先,请在Eclipse工作界面左侧的“Package Explorer”面板中,在工程名称“WordCount”上点击鼠标右键,在弹出的菜单中选择“Export”,如下图所示。
然后,会弹出如下图所示界面。
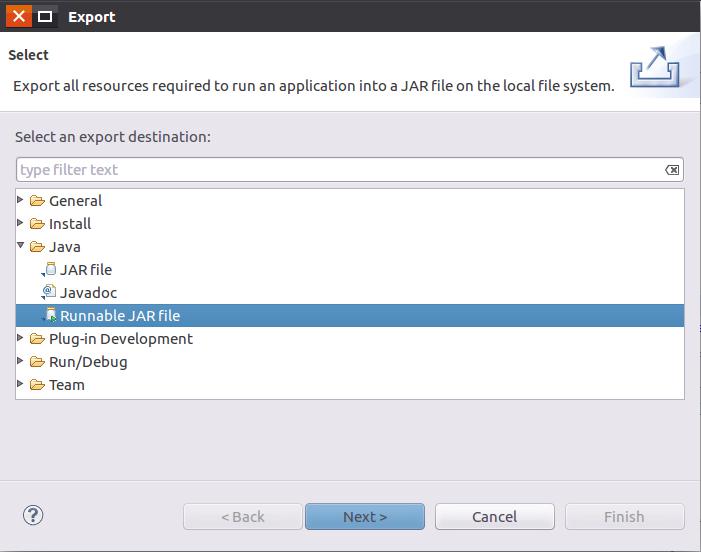
在该界面中,选择“Runnable JAR file”,然后,点击“Next>”按钮,弹出如下图所示界面。

在该界面中,“Launch configuration”用于设置生成的JAR包被部署启动时运行的主类,需要在下拉列表中选择刚才配置的类“WordCount-WordCount”。在“Export destination”中需要设置JAR包要输出保存到哪个目录,比如,这里设置为“/usr/local/hadoop/myapp/WordCount.jar”。在“Library handling”下面选择“Extract required libraries into generated JAR”。然后,点击“Finish”按钮,会出现如下图所示界面。
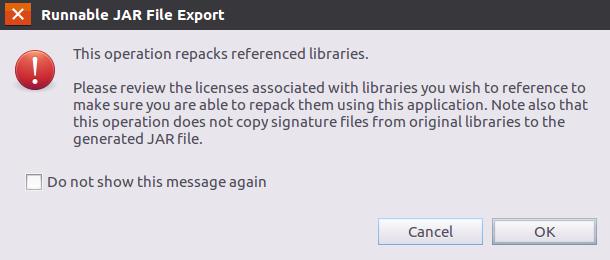
可以忽略该界面的信息,直接点击界面右下角的“OK”按钮,启动打包过程。打包过程结束后,会出现一个警告信息界面,如下图所示。

可以忽略该界面的信息,直接点击界面右下角的“OK”按钮。至此,已经顺利把WordCount工程打包生成了WordCount.jar。可以到Linux系统中查看一下生成的WordCount.jar文件,可以在Linux的终端中执行如下命令:
cd /usr/local/hadoop/myapp
ls1.5.2 运行程序
在运行程序之前,需要启动Hadoop,命令如下:
cd /usr/local/hadoop
./sbin/start-dfs.sh在启动Hadoop之后,需要首先删除HDFS中与当前Linux用户hadoop对应的input和output目录(即HDFS中的“/user/hadoop/input”和“/user/hadoop/output”目录),这样确保后面程序运行不会出现问题,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r input
./bin/hdfs dfs -rm -r output然后,再在HDFS中新建与当前Linux用户hadoop对应的input目录,即“/user/hadoop/input”目录,具体命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -mkdir input然后,把之前在中在Linux本地文件系统中新建的文件wordfile1.txt(假设这个文件位于“/usr/local/hadoop”目录下,并且里面包含了一些英文语句),上传到HDFS中的“/user/hadoop/input”目录下,命令如下:
cd /usr/local/hadoop
./bin/hdfs dfs -put ./wordfile1.txt input
如果HDFS中已经存在目录“/user/hadoop/output”,则使用如下命令删除该目录:
cd /usr/local/hadoop
./bin/hdfs dfs -rm -r /user/hadoop/output现在,就可以在Linux系统中,使用hadoop jar命令运行程序,命令如下:
cd /usr/local/hadoop
./bin/hadoop jar ./myapp/WordDriver.jar input output上面命令执行以后,当运行顺利结束时,屏幕上会显示类似如下的信息:

词频统计结果已经被写入了HDFS的“/user/hadoop/output”目录中,可以执行如下命令查看词频统计结果:
cd /usr/local/hadoop
./bin/hdfs dfs -cat output/*上面命令执行后,会在屏幕上显示如下词频统计结果:
Hadoop 2
I 2
Spark 2
fast 1
good 1
is 2
love 2至此,词频统计程序顺利运行结束。需要注意的是,如果要再次运行WordCount.jar,需要首先删除HDFS中的output目录,否则会报错。
最后关闭hadoop程序:
cd /usr/local/hadoop
./sbin/stop-dfs.sh相关文章:
Hadoop(2):常见的MapReduce[在Ubuntu中运行!]
1 以词频统计为例子介绍 mapreduce怎么写出来的 弄清楚MapReduce的各个过程: 将文件输入后,返回的<k1,v1>代表的含义是:k1表示偏移量,即v1的第一个字母在文件中的索引(从0开始数的);v1表…...
Unity | 快速修复Animation missing错误
目录 一、背景 二、效果 三、解决办法 一、背景 最近在做2D 骨骼动画相关的Demo,我自己使用Unity引擎进行骨骼绑定并创建了anim后,一切正常,anim也能播放。但是昨天我修改Obj及子物体的名称(由中文改为英文,如&…...
ssm基于web的志愿者管理系统的设计与实现+vue论文
摘 要 使用旧方法对志愿者管理系统的信息进行系统化管理已经不再让人们信赖了,把现在的网络信息技术运用在志愿者管理系统的管理上面可以解决许多信息管理上面的难题,比如处理数据时间很长,数据存在错误不能及时纠正等问题。这次开发的志愿者…...
)
C++运算符重载(插入and提取)
介绍 本文主要介绍 插入(>>) and 提取(<<)的运算符重载 1.插入(>>) 提取(<<)只能是友元函数 2.插入关键词istream 例子:istream& operator>>(istream& in, sumber&Left) 3.提取关键词ostream 例子:ostream&a…...
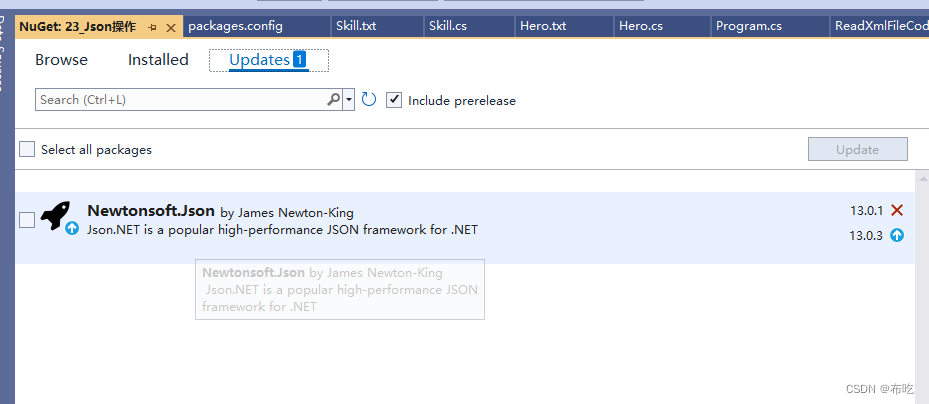
C#高级 08Json操作
1.概念 Json是存储和交换文本信息的语法。类似于XML。Json比XML更小、更快、更易解析。Json与XML一样是一种数据格式。Json是一种轻量级的数据交换格式。它基于ECMAScript的一个子集。Json采取完全独立于语言的文本格式, 但是也使用了类似于C语言的习惯。这些特性使…...

封装uniapp签字板
新开发的业务涉及到签字功能,由于是动态的表单,无法确定它会出现在哪里,不得已封装模块。 其中涉及到一个难点就是this的指向性问题, 第二个是微信小程序写法, 我这个写法里用了u-view的写法,可以自己修改组…...

Mybatis行为配置之Ⅳ—日志
专栏精选 引入Mybatis Mybatis的快速入门 Mybatis的增删改查扩展功能说明 mapper映射的参数和结果 Mybatis复杂类型的结果映射 Mybatis基于注解的结果映射 Mybatis枚举类型处理和类型处理器 再谈动态SQL Mybatis配置入门 Mybatis行为配置之Ⅰ—缓存 Mybatis行为配置…...
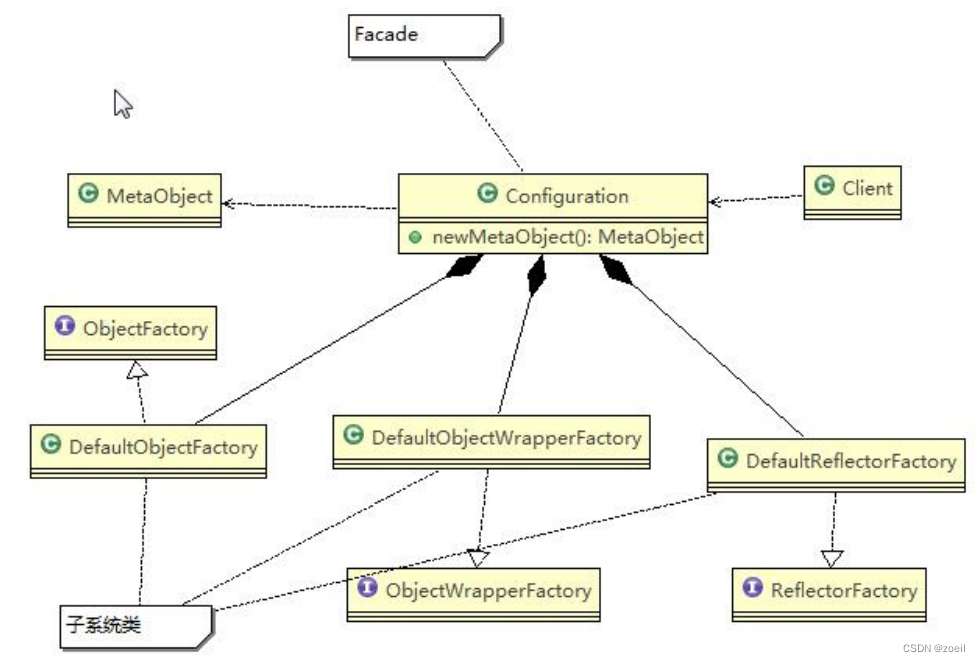
Java设计模式-外观模式
目录 一、影院管理项目 二、外观模式 (一)基本介绍 (二)原理类图 (三)解决影院管理 (四)注意事项和细节 (五)外观模式在MyBatis框架应用的源码分析 一…...

js+css实现颜色选择器
<!DOCTYPE html> <html> <head><meta charset"UTF-8"><title>颜色选择器</title><style>.color-box {width: 50px;height: 50px;border: 1px solid #000;cursor: pointer;}</style> </head> <body><…...

Go语言中的包管理工具之Go Modules的使用
GoLang 中常用的包管理的方式 常用的有三种 Go PathGo VendorGo Modules 关于 Go Modules 1 ) 概述 Go的包管理,经过社区和官方的共同努力下,最终在百家争鸣后Go官方在 2018.8 推出了go 1.11版本中的Go Modules,并且很快成为一统江湖的包…...
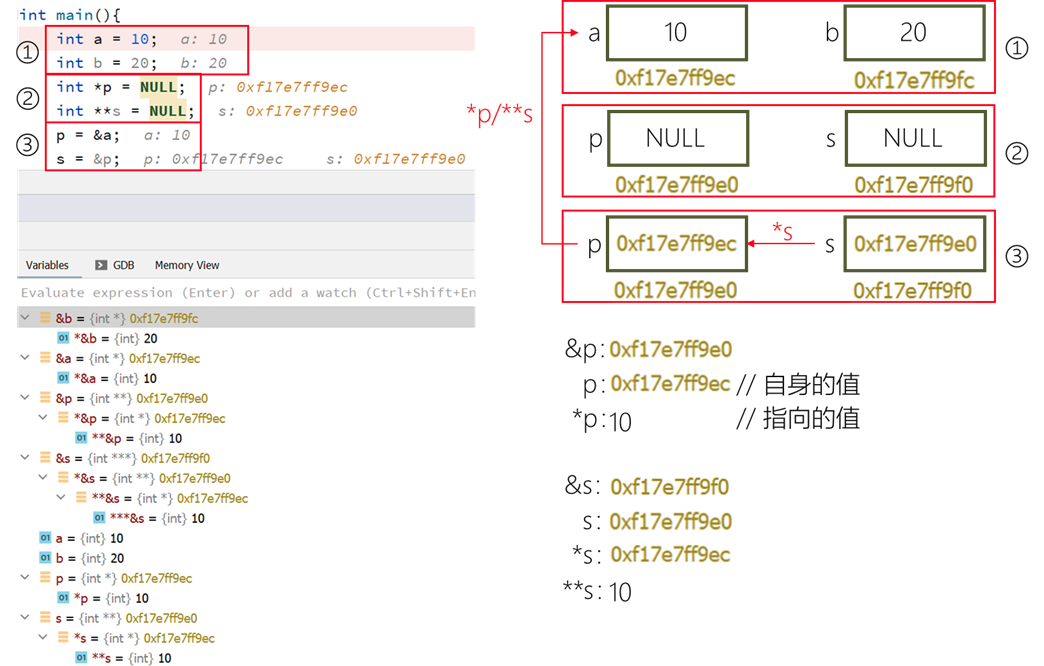
【c/c++】指针例图基础详解
文章目录 指针变量内存指针详解例1例2练习&答案解析 指针变量内存 int main(){// 各类型变量占字节数printf("char: %d\n",sizeof(char)); // 1printf("short: %d\n",sizeof(short)); // 2printf("int: %d\n",sizeof(int)); // 4pri…...

TCP/IP的网络层(即IP层)之IP地址和网络掩码,在视频监控系统中的配置和应用
在给客户讲解我们的AS-V1000视频监控平台的时候,有的客户经常会配置错误IP地址的掩码和网关,导致出现一些网路问题。而在视频监控系统中,IP地址和子网掩码是用于标识网络中设备的重要标识符。IP地址被用来唯一地标识一个网络设备,…...
代码随想录刷题 | Day1
今日学习目标 一、基础 数组 array类 模板类vector 数组是存放在连续内存空间上的相同类型数据的集合。 数组可以方便的通过下标索引的方式获取到下标下对应的数据。 需要两点注意的是 数组下标都是从0开始的。 数组内存空间的地址是连续的 而且大家如果使用C的话&…...
查看IOS游戏FPS
摘要 本篇技术博客将介绍如何使用克魔助手工具来查看iOS游戏的帧率(FPS)。通过克魔助手,开发者可以轻松监测游戏性能,以提升用户体验和游戏质量。 引言 在iOS游戏开发过程中,了解游戏的帧率对于优化游戏性能至关重要…...

挑战Python100题(7)
100+ Python challenging programming exercises 7 Question 61 Print a unicode string "hello world". Hints: Use ustrings format to define unicode string. 打印一个unicode字符串“helloworld”。 提示:使用u“字符串”格式定义unicode字符串。 Solution…...

HarmonyOS自学-Day4(TodoList案例)
目录 文章声明⭐⭐⭐让我们开始今天的学习吧!TodoList小案例 文章声明⭐⭐⭐ 该文章为我(有编程语言基础,非编程小白)的 HarmonyOS自学笔记,此类文章笔记我会默认大家都学过前端相关的知识知识来源为 HarmonyOS官方文…...
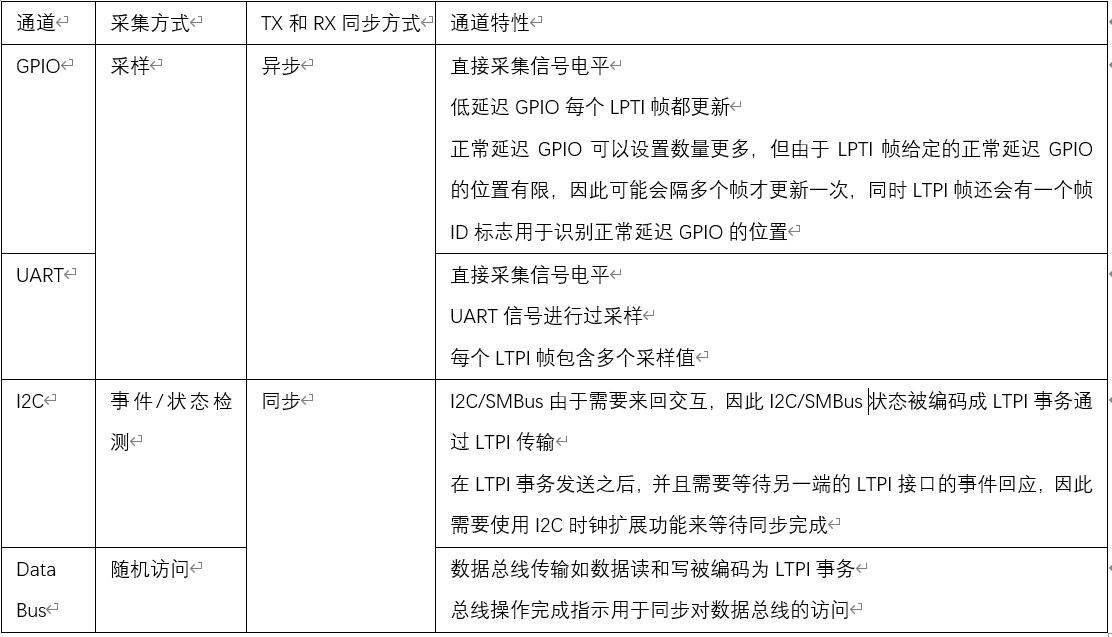
LTPI协议的理解——2、LTPI实现的底层架构
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 LTPI协议的理解——2、LTPI实现的底层架构 前言一、体系结构三、实现细节四、物理接口信号传输方法总结 前言 前面讲了LTPI的定义和大概结构,接下来继续理解LTPI…...
)
CentOS 8.2 安装 Mysql 5.7.26(单机)
Mysql二进制包: mysql-5.7.26-linux-glibc2.12-x86_64.tar.gz 1、卸载旧环境 rpm -qa|grep mysql rpm -qa|grep mariadb rpm -e XXX.rpm --nodeps # 强制卸载rpm包 rm -rf /etc/my.cnf rm -rf /etc/mysql rm -rf /usr/local/mysql 2、安装依赖包 yum -y install libaio yum…...

Vue Tinymce富文本组件自定义带下拉框的操作按钮
想实现如下效果 首先在init方法中的props,toolbar属性增加一个自定义按钮 增加一个setup方法 代码 setup: function(editor) { editor.ui.registry.addSplitButton(myDateButton, {text: 日期时间,onAction: (_) > editor.insertContent(getJsMonthDay(getNowDat…...

YOLOv5算法进阶改进(10)— 更换主干网络之MobileViTv3 | 轻量化Backbone
前言:Hello大家好,我是小哥谈。MobileViTv3是一种改进的模型架构,用于图像分类任务。它是在MobileViTv1和MobileViTv2的基础上进行改进的,通过引入新的模块和优化网络结构来提高性能。本节课就给大家介绍一下如何在主干网络中引入MobileViTv3网络结构,希望大家学习之后能够…...

基于大模型的 UI 自动化系统
基于大模型的 UI 自动化系统 下面是一个完整的 Python 系统,利用大模型实现智能 UI 自动化,结合计算机视觉和自然语言处理技术,实现"看屏操作"的能力。 系统架构设计 #mermaid-svg-2gn2GRvh5WCP2ktF {font-family:"trebuchet ms",verdana,arial,sans-…...

基于FPGA的PID算法学习———实现PID比例控制算法
基于FPGA的PID算法学习 前言一、PID算法分析二、PID仿真分析1. PID代码2.PI代码3.P代码4.顶层5.测试文件6.仿真波形 总结 前言 学习内容:参考网站: PID算法控制 PID即:Proportional(比例)、Integral(积分&…...

《从零掌握MIPI CSI-2: 协议精解与FPGA摄像头开发实战》-- CSI-2 协议详细解析 (一)
CSI-2 协议详细解析 (一) 1. CSI-2层定义(CSI-2 Layer Definitions) 分层结构 :CSI-2协议分为6层: 物理层(PHY Layer) : 定义电气特性、时钟机制和传输介质(导线&#…...

什么是库存周转?如何用进销存系统提高库存周转率?
你可能听说过这样一句话: “利润不是赚出来的,是管出来的。” 尤其是在制造业、批发零售、电商这类“货堆成山”的行业,很多企业看着销售不错,账上却没钱、利润也不见了,一翻库存才发现: 一堆卖不动的旧货…...

OkHttp 中实现断点续传 demo
在 OkHttp 中实现断点续传主要通过以下步骤完成,核心是利用 HTTP 协议的 Range 请求头指定下载范围: 实现原理 Range 请求头:向服务器请求文件的特定字节范围(如 Range: bytes1024-) 本地文件记录:保存已…...

汇编常见指令
汇编常见指令 一、数据传送指令 指令功能示例说明MOV数据传送MOV EAX, 10将立即数 10 送入 EAXMOV [EBX], EAX将 EAX 值存入 EBX 指向的内存LEA加载有效地址LEA EAX, [EBX4]将 EBX4 的地址存入 EAX(不访问内存)XCHG交换数据XCHG EAX, EBX交换 EAX 和 EB…...
与常用工具深度洞察App瓶颈)
iOS性能调优实战:借助克魔(KeyMob)与常用工具深度洞察App瓶颈
在日常iOS开发过程中,性能问题往往是最令人头疼的一类Bug。尤其是在App上线前的压测阶段或是处理用户反馈的高发期,开发者往往需要面对卡顿、崩溃、能耗异常、日志混乱等一系列问题。这些问题表面上看似偶发,但背后往往隐藏着系统资源调度不当…...

在Mathematica中实现Newton-Raphson迭代的收敛时间算法(一般三次多项式)
考察一般的三次多项式,以r为参数: p[z_, r_] : z^3 (r - 1) z - r; roots[r_] : z /. Solve[p[z, r] 0, z]; 此多项式的根为: 尽管看起来这个多项式是特殊的,其实一般的三次多项式都是可以通过线性变换化为这个形式…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...
详细解析)
Caliper 负载(Workload)详细解析
Caliper 负载(Workload)详细解析 负载(Workload)是 Caliper 性能测试的核心部分,它定义了测试期间要执行的具体合约调用行为和交易模式。下面我将全面深入地讲解负载的各个方面。 一、负载模块基本结构 一个典型的负载模块(如 workload.js)包含以下基本结构: use strict;/…...