【privateGPT】使用privateGPT训练您自己的LLM
了解如何在不向提供商公开您的私人数据的情况下训练您自己的语言模型
使用OpenAI的ChatGPT等公共人工智能服务的主要担忧之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用人工智能技术的公司最大的担忧。
很多时候,你想创建自己的语言模型,根据你的数据集(如销售见解、客户反馈等)进行训练,但同时你不想将所有这些敏感数据暴露给OpenAI等人工智能提供商。因此,理想的方法是在本地训练自己的LLM,而无需将数据上传到云。
如果你的数据是公开的,并且你不介意将它们暴露给ChatGPT,我有另一篇文章展示了如何将ChatGPT与你自己的数据连接起来:
-
Connecting ChatGPT with Your Own Data using LlamaIndex
-
Learn how to create your own chatbot for your business
-
levelup.gitconnected.com
在这篇文章中,我将向您展示如何使用一个名为privateGPT的开源项目来利用LLM,这样它就可以根据您的自定义训练数据回答问题(如ChatGPT),而不会牺牲数据的隐私。
需要注意的是,privateGPT目前只是一个概念验证,尚未做好生产准备。
正在下载私有GPT
要试用privateGPT,您可以使用以下链接转到GitHub:https://github.com/imartinez/privateGPT.
您可以单击“代码|下载ZIP”按钮下载存储库:
或者,如果您的系统上安装了git,请在终端中使用以下命令克隆存储库:
$ git clone https://github.com/imartinez/privateGPT
无论哪种情况,一旦将存储库下载到您的计算机上,privateGPT目录应具有以下文件和文件夹:
安装所需的Python包
privateGPT使用许多Python包。它们封装在requirements.txt文件中:
langchain==0.0.171 pygpt4all==1.1.0 chromadb==0.3.23 llama-cpp-python==0.1.50 urllib3==2.0.2 pdfminer.six==20221105 python-dotenv==1.0.0 unstructured==0.6.6 extract-msg==0.41.1 tabulate==0.9.0 pandoc==2.3 pypandoc==1.11
安装它们最简单的方法是使用pip:
$ cd privateGPT $ pip install -r requirements.txt
根据我的实验,在执行上述安装时,可能无法安装某些必需的Python包。稍后当您尝试运行intake.py或privateGPT.py文件时,您就会知道这一点。在这种情况下,只需单独安装丢失的软件包即可。
编辑环境文件
example.env文件包含privateGPT使用的几个设置。内容如下:
PERSIST_DIRECTORY=db MODEL_TYPE=GPT4All MODEL_PATH=models/ggml-gpt4all-j-v1.3-groovy.bin EMBEDDINGS_MODEL_NAME=all-MiniLM-L6-v2 MODEL_N_CTX=1000
- PERSIST_DIRECTORY-加载和处理文档后将保存本地矢量存储的目录
- MODEL_TYPE-您正在使用的模型的类型。在这里,它被设置为GPT4All(由OpenAI提供的ChatGPT的免费开源替代方案)。
- MODEL_PATH—LLM所在的路径。在这里,它被设置为models目录,使用的模型是ggml-gpt4all-j-v1.3-groovy.bin(您将在下一节中了解该模型的下载位置)
- EMBEDDINGS_MODEL_NAME-这是指变压器模型的名称。在这里,它被设置为全MiniLM-L6-v2,它将句子和段落映射到384维的密集向量空间,并可用于聚类或语义搜索等任务。
- MODEL_N_CTX-嵌入和LLM模型的最大令牌限制
将example.env重命名为.env。
完成此操作后,.env文件将变为隐藏文件。
下载模型
为了使私有GPT工作,它需要预先训练模型(LLM)。由于privateGPT正在使用GPT4All,您可以从以下位置下载LLM:https://gpt4all.io/index.html:
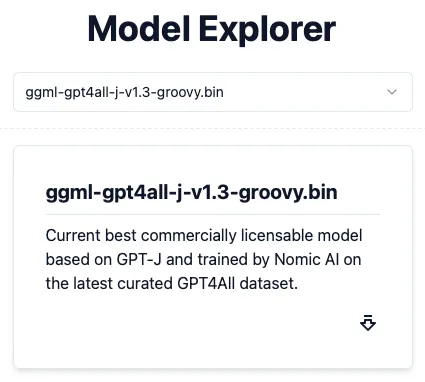
由于默认环境文件指定了ggml-gpt4all-j-v1.3-groovy.bin LLM,因此下载第一个模型,然后在privateGPT文件夹中创建一个名为models的新文件夹。将ggml-gpt4all-j-v1.3-groovy.bin文件放入models文件夹中:
准备您的数据
如果您查看intect.py文件,您会注意到以下代码片段:
".csv": (CSVLoader, {}),
# ".docx": (Docx2txtLoader, {}),
".doc": (UnstructuredWordDocumentLoader, {}),
".docx": (UnstructuredWordDocumentLoader, {}),
".enex": (EverNoteLoader, {}),
".eml": (UnstructuredEmailLoader, {}),
".epub": (UnstructuredEPubLoader, {}),
".html": (UnstructuredHTMLLoader, {}),
".md": (UnstructuredMarkdownLoader, {}),
".odt": (UnstructuredODTLoader, {}),
".pdf": (PDFMinerLoader, {}),
".ppt": (UnstructuredPowerPointLoader, {}),
".pptx": (UnstructuredPowerPointLoader, {}),
".txt": (TextLoader, {"encoding": "utf8"}),
这意味着privateGPT能够支持以下文档类型:
.csv: CSV.doc: Word Document.docx: Word Document.enex: EverNote.eml: Email.epub: EPub.html: HTML File.md: Markdown.odt: Open Document Text.pdf: Portable Document Format (PDF).ppt: PowerPoint Document.pptx: PowerPoint Document.txt: Text file (UTF-8)
每种类型的文档都由相应的文档加载器指定。例如,您可以使用UnstructuredWordDocumentLoader类来加载.doc和.docx Word文档。
默认情况下,privateGPT附带位于source_documents文件夹中的state_of_the_union.txt文件。我将删除它,并用一份名为Singapore.pdf的文件取而代之。

This document was created from https://en.wikipedia.org/wiki/Singapore. You can download any page from Wikipedia as a PDF document by clicking Tools | Download as PDF:

您可以将privateGPT支持的任何文档放入source_documents文件夹。以我为例,我只放了一份文件。
为文档创建嵌入
一旦文档就位,就可以为文档创建嵌入了。
创建嵌入是指为单词、句子或其他文本单元生成向量表示的过程。这些向量表示捕获了有关文本的语义和句法信息,使机器能够更有效地理解和处理自然语言。
在终端中键入以下内容(在privateGPT文件夹中提供了摄取.py文件):
$ python ingest.py
根据您使用的机器和您放入source_documents文件夹中的文档数量,嵌入处理可能需要相当长的时间才能完成。
完成后,您将看到以下内容:
Loading documents from source_documents Loaded 1 documents from source_documents Split into 692 chunks of text (max. 500 characters each) Using embedded DuckDB with persistence: data will be stored in: db
嵌入以Chroma db的形式保存在db文件夹中:
Chroma是开源嵌入数据库。
提出问题
您现在可以提问了!在“终端”中键入以下命令:
$ python privateGPT.py
加载模型需要一段时间。在此过程中,您将看到以下内容:
Using embedded DuckDB with persistence: data will be stored in: db gptj_model_load: loading model from 'models/ggml-gpt4all-j-v1.3-groovy.bin' - please wait ... gptj_model_load: n_vocab = 50400 gptj_model_load: n_ctx = 2048 gptj_model_load: n_embd = 4096 gptj_model_load: n_head = 16 gptj_model_load: n_layer = 28 gptj_model_load: n_rot = 64 gptj_model_load: f16 = 2 gptj_model_load: ggml ctx size = 4505.45 MB gptj_model_load: memory_size = 896.00 MB, n_mem = 57344 gptj_model_load: ................................... done gptj_model_load: model size = 3609.38 MB / num tensors = 285Enter a query:
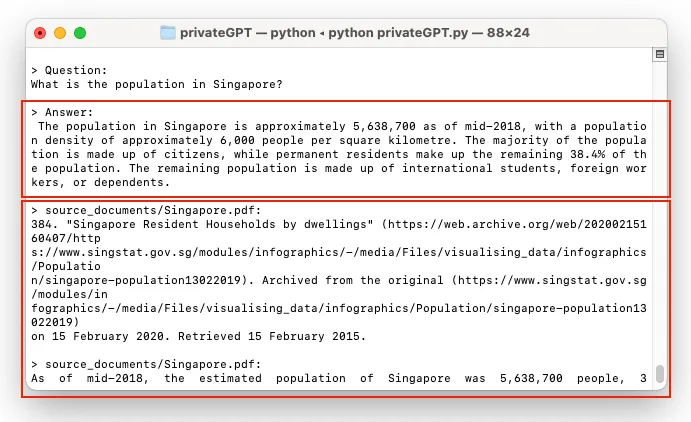
在提示下,你可以输入你的问题。我问:“新加坡的人口是多少?”。私人GPT花了很长时间才得出答案。一旦它找到了答案,它就会给你答案,并引用答案的来源:
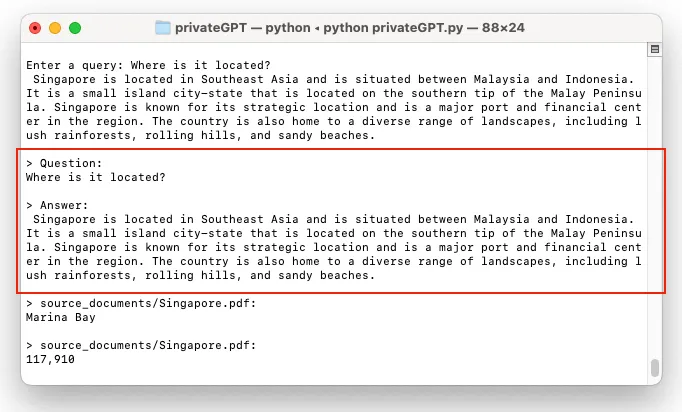
您可以继续询问后续问题:
总结
虽然privateGPT目前是一个概念验证,但它看起来很有前景,然而,它还没有准备好生产。有几个问题:
- 推理缓慢。执行文本嵌入需要一段时间,但这是可以接受的,因为这是一次性过程。然而,推理是缓慢的,尤其是在速度较慢的机器上。我用了一台32GB内存的M1 Mac,但还是花了一段时间才找到答案。
- 内存猪。privateGPT使用大量内存,在问了一两个问题后,我会得到一个内存不足的错误,如下所示:
segmentation fault python privateGPT.py. /Users/weimenglee/miniforge3/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown. warnings.warn(‘resource_tracker: There appear to be %d ‘
在privateGPT的作者解决上述两个问题之前,privateGPT仍然是一个实验,看看如何在不将私人数据暴露给云的情况下训练LLM。
文章链接
【privateGPT】使用privateGPT训练您自己的LLM | 开发者开聊
自我介绍
- 做一个简单介绍,酒研年近48 ,有20多年IT工作经历,目前在一家500强做企业架构.因为工作需要,另外也因为兴趣涉猎比较广,为了自己学习建立了三个博客,分别是【全球IT瞭望】,【架构师研究会】和【开发者开聊】,有更多的内容分享,谢谢大家收藏。
- 企业架构师需要比较广泛的知识面,了解一个企业的整体的业务,应用,技术,数据,治理和合规。之前4年主要负责企业整体的技术规划,标准的建立和项目治理。最近一年主要负责数据,涉及到数据平台,数据战略,数据分析,数据建模,数据治理,还涉及到数据主权,隐私保护和数据经济。 因为需要,比如数据资源入财务报表,另外数据如何估值和货币化需要财务和金融方面的知识,最近在学习财务,金融和法律。打算先备考CPA,然后CFA,如果可能也想学习法律,备战律考。
- 欢迎爱学习的同学朋友关注,也欢迎大家交流。全网同号【架构师研究会】
欢迎收藏 【全球IT瞭望】,【架构师酒馆】和【开发者开聊】.
相关文章:

【privateGPT】使用privateGPT训练您自己的LLM
了解如何在不向提供商公开您的私人数据的情况下训练您自己的语言模型 使用OpenAI的ChatGPT等公共人工智能服务的主要担忧之一是将您的私人数据暴露给提供商的风险。对于商业用途,这仍然是考虑采用人工智能技术的公司最大的担忧。 很多时候,你想创建自己…...

权威Scrum敏捷开发企业培训分享
课程简介 Scrum是目前运用最为广泛的敏捷开发方法,是一个轻量级的项目管理和产品研发管理框架。 这是一个两天的实训课程,面向研发管理者、项目经理、产品经理、研发团队等,旨在帮助学员全面系统地学习Scrum和敏捷开发, 帮助企业快速启动敏…...

面试要点,算法,数据结构等练习大全
有趣的算法,面试常常碰到,多种语言实现~ 1 从数组中找出两个数字使得他们的和是给定的数字 tags: #hash 使用一个散列,存储数字和他对应的索引。然后遍历数组,如果另一半在散列当中,那么返回 这两个数的索引&#x…...

八皇后问题(C语言)
了解题意 在一个8x8的棋盘上放置8个皇后,使得任何两个皇后都不能处于同一行、同一列或同一斜线上。问有多少种方法可以放置这8个皇后? 解决这个问题的目标是找到所有符合要求的皇后摆放方式,通常使用回溯算法来求解。回溯算法会尝试所有可能…...

利用网络教育系统构建个性化学习平台
在现代教育中,网络教育系统作为一种创新的学习方式,为学生提供了更加个性化和灵活的学习体验。在本文中,我们将通过简单的技术代码,演示如何构建一个基础的网络教育系统,为学生提供个性化的学习路径和资源。 1. 环境…...

滤波器opencv
在OpenCV中,滤波器用于对图像进行平滑、锐化、边缘检测等操作。以下是一些常用的滤波器及其在OpenCV中的Python代码示例: 均值滤波器(平滑图像): import cv2 import numpy as np# 读取图像 image cv2.imread(path_t…...

使用 Docker Compose 部署 Halo 2.x 与 MySQL
使用 Docker Compose 部署 Halo 2.x 与 MySQL 本文主要介绍使用 Docker Compose 部署 Halo 2.x 和 MySQL, 主要针对小白。 有一定基础的, 可以直接去官网查看。 博主博客 https://blog.uso6.comhttps://blog.csdn.net/dxk539687357 一、Docker 与 Dock…...

openGauss学习笔记-179 openGauss 数据库运维-逻辑复制-发布订阅
文章目录 openGauss学习笔记-179 openGauss 数据库运维-逻辑复制-发布订阅179.1 发布179.2 订阅179.3 冲突处理179.4 限制179.5 架构179.6 监控179.7 安全性179.8 配置设置179.9 快速设置 openGauss学习笔记-179 openGauss 数据库运维-逻辑复制-发布订阅 发布和订阅基于逻辑复…...

2023十大编程语言及未来展望
2023十大编程语言及未来展望 1. 2023年十大编程语言排行榜2. 十大编程语言未来展望PythonCCJavaC#JavaScriptPHPVisual BasicSQLAssembly language 1. 2023年十大编程语言排行榜 TIOBE排行榜是根据互联网上有经验的程序员、课程和第三方厂商的数量,并使用搜索引擎&a…...

Docker启动各种服务
文章目录 1 启动MySQL2 启动maven,用于编译java程序3 容器内启动sshd,用于远程编码和调试 1 启动MySQL 守护方式运行一个容器: docker run --name mysql5.7 -e MYSQL_ROOT_PASSWORD123456 -p 3307:3306 -d mysql进入容器: dock…...

AndroidR集成三方Native服务组件
一、背景 该项目为海外欧盟市场版本,需集成三方IDS安全组件,进程运行时注入iptables指令至链表,检测网络运行状态,并收集异常日志并压缩打包成gz文件,提供给Android上层应用上报云端。 二、分析 1、将提供的组件包集成至系统vendor分区 /vendor/bin/idsLogd/vendor/li…...
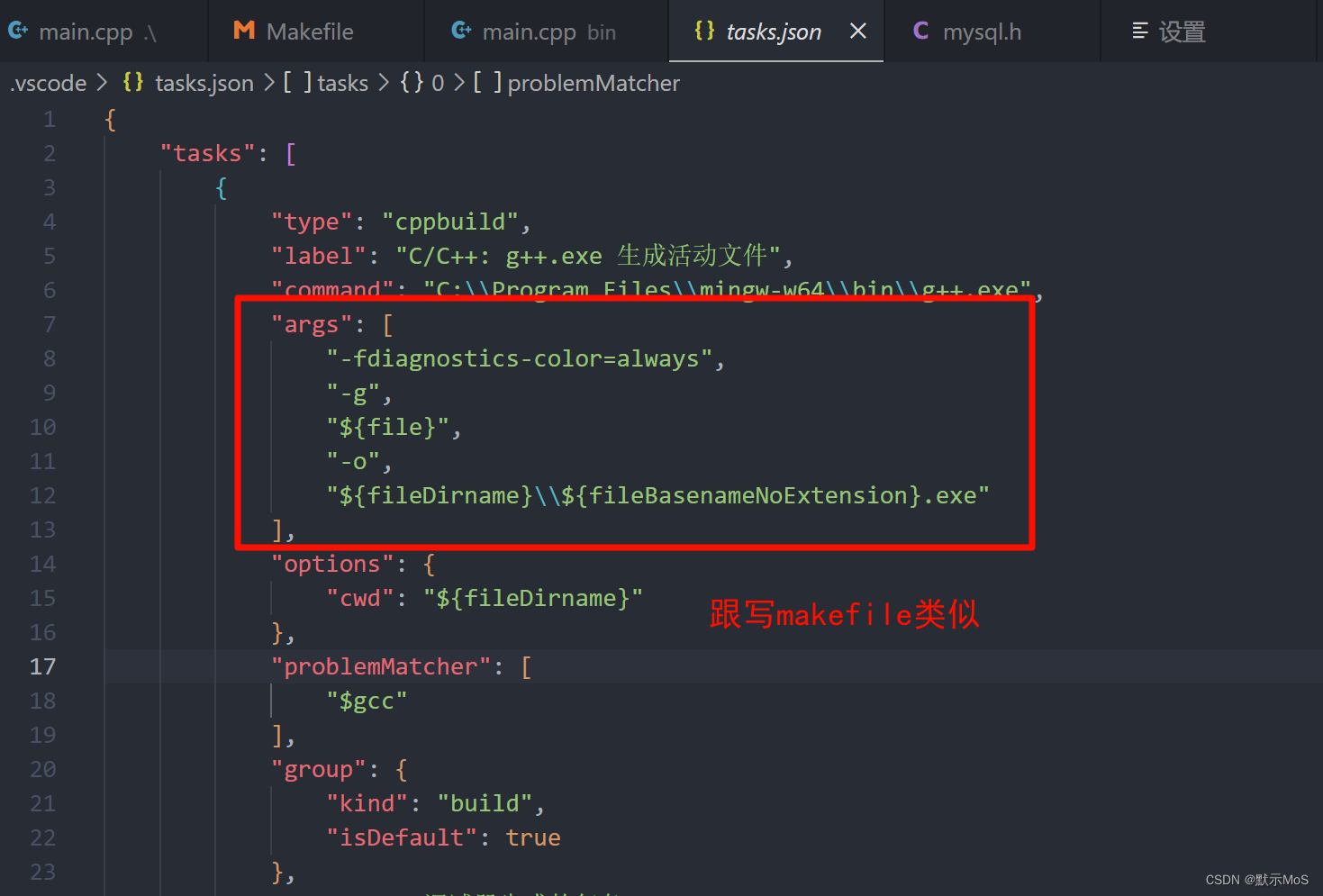
C++连接数据库(DataBase)之加载外部依赖项
文章目录 在VS中进行配置一、 先找到VS的解决方案资源管理器:二、 找到“属性”,进行附加项配置三、 移植libmysql.dll目录 在VSCode中进行配置依赖文件的移动库文件的移动可能遇到的问题 重点!!!!…...
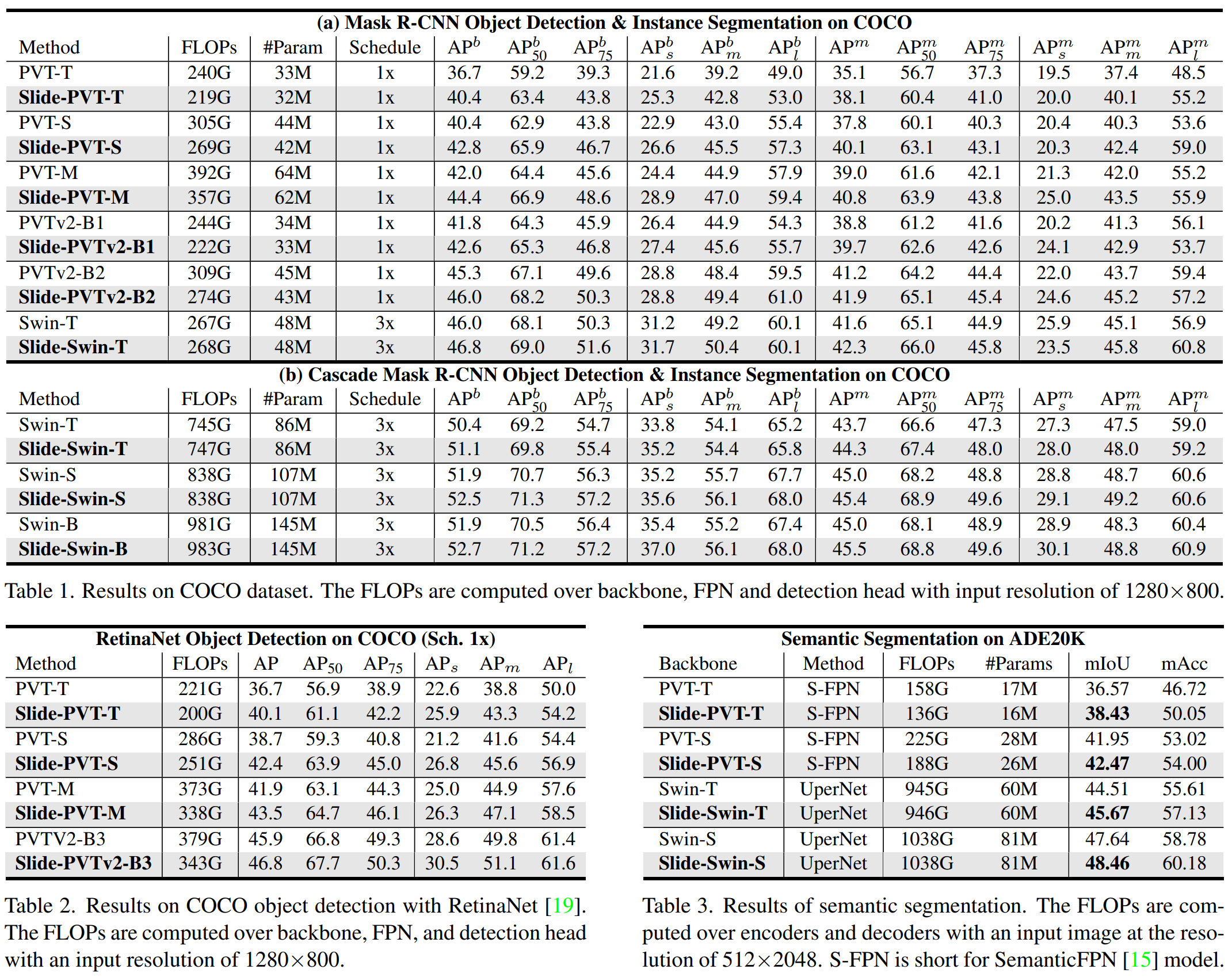
论文阅读——Slide-Transformer(cvpr2023)
Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention 一、分析 1、改进transformer的几个思路: (1)将全局感受野控制在较小区域,如:PVT,DAT,使用稀疏全局注意力来…...
)
【Flink-Kafka-To-Mysql】使用 Flink 实现 Kafka 数据写入 Mysql(根据对应操作类型进行增、删、改操作)
【Flink-Kafka-To-Mysql】使用 Flink 实现 Kafka 数据写入 Mysql(根据对应操作类型进行增、删、改操作) 1)导入依赖2)resources2.1.appconfig.yml2.2.application.properties2.3.log4j.properties2.4.log4j2.xml 3)uti…...
SpringMVC学习与开发(四)
注:此为笔者学习狂神说SpringMVC的笔记,其中包含个人的笔记和理解,仅做学习笔记之用,更多详细资讯请出门左拐B站:狂神说!!! 11、Ajax初体验 1、伪造Ajax 结果:并未有xhr异步请求 <!DOCTYPE html> &…...
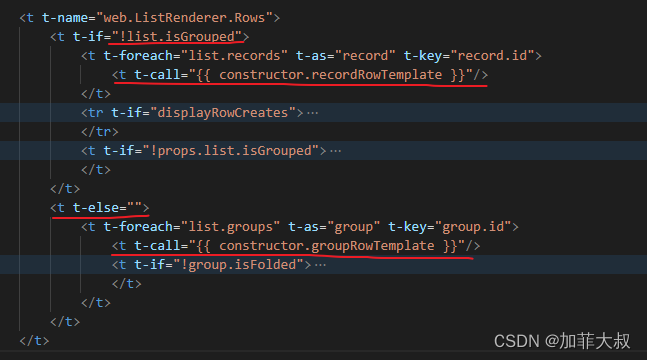
odoo17核心概念view7——listview总体框架分析
这是view系列的第七篇文章,今天主要介绍我们最常用的list视图。 1、先看list_view,这是主文件 /** odoo-module */import { registry } from "web/core/registry"; import { RelationalModel } from "web/model/relational_model/relational_mode…...

大创项目推荐 深度学习交通车辆流量分析 - 目标检测与跟踪 - python opencv
文章目录 0 前言1 课题背景2 实现效果3 DeepSORT车辆跟踪3.1 Deep SORT多目标跟踪算法3.2 算法流程 4 YOLOV5算法4.1 网络架构图4.2 输入端4.3 基准网络4.4 Neck网络4.5 Head输出层 5 最后 0 前言 🔥 优质竞赛项目系列,今天要分享的是 🚩 *…...
数字图像处理——亚像素边缘的轮廓提取
像素 像素是图像处理中的基本单位,一个像素是图像中最小的离散化单位,具有特定的位置和颜色信息。在数字图像中,每个像素都有一个特定的坐标,通常以行和列的形式表示。每个像素的颜色信息可以通过不同的表示方式,如灰…...
【六袆 - Framework】vue3入门;vue框架的特点矩阵列举;Vue.js 工作原理
vue框架的特点 Vue.js的特点展开叙述Vue.js的工作原理展开叙述 官方文档: https://cn.vuejs.org/guide/introduction.html Vue.js的特点 ┌────────────────────┬────────────────────────────────────…...
GO学习记录 —— 创建一个GO项目
文章目录 前言一、项目介绍二、目录介绍三、创建过程1.引入Gin框架、创建main2.加载配置文件3.连接MySQL、redis4.创建结构体5.错误处理、返回响应处理 前言 代码地址 下载地址:https://github.com/Lee-ZiMu/Golang-Init.git 一、项目介绍 1、使用Gin框架来创建项…...

Vue记事本应用实现教程
文章目录 1. 项目介绍2. 开发环境准备3. 设计应用界面4. 创建Vue实例和数据模型5. 实现记事本功能5.1 添加新记事项5.2 删除记事项5.3 清空所有记事 6. 添加样式7. 功能扩展:显示创建时间8. 功能扩展:记事项搜索9. 完整代码10. Vue知识点解析10.1 数据绑…...

【Linux】shell脚本忽略错误继续执行
在 shell 脚本中,可以使用 set -e 命令来设置脚本在遇到错误时退出执行。如果你希望脚本忽略错误并继续执行,可以在脚本开头添加 set e 命令来取消该设置。 举例1 #!/bin/bash# 取消 set -e 的设置 set e# 执行命令,并忽略错误 rm somefile…...

AI Agent与Agentic AI:原理、应用、挑战与未来展望
文章目录 一、引言二、AI Agent与Agentic AI的兴起2.1 技术契机与生态成熟2.2 Agent的定义与特征2.3 Agent的发展历程 三、AI Agent的核心技术栈解密3.1 感知模块代码示例:使用Python和OpenCV进行图像识别 3.2 认知与决策模块代码示例:使用OpenAI GPT-3进…...

8k长序列建模,蛋白质语言模型Prot42仅利用目标蛋白序列即可生成高亲和力结合剂
蛋白质结合剂(如抗体、抑制肽)在疾病诊断、成像分析及靶向药物递送等关键场景中发挥着不可替代的作用。传统上,高特异性蛋白质结合剂的开发高度依赖噬菌体展示、定向进化等实验技术,但这类方法普遍面临资源消耗巨大、研发周期冗长…...

JVM垃圾回收机制全解析
Java虚拟机(JVM)中的垃圾收集器(Garbage Collector,简称GC)是用于自动管理内存的机制。它负责识别和清除不再被程序使用的对象,从而释放内存空间,避免内存泄漏和内存溢出等问题。垃圾收集器在Ja…...

NLP学习路线图(二十三):长短期记忆网络(LSTM)
在自然语言处理(NLP)领域,我们时刻面临着处理序列数据的核心挑战。无论是理解句子的结构、分析文本的情感,还是实现语言的翻译,都需要模型能够捕捉词语之间依时序产生的复杂依赖关系。传统的神经网络结构在处理这种序列依赖时显得力不从心,而循环神经网络(RNN) 曾被视为…...

ABAP设计模式之---“简单设计原则(Simple Design)”
“Simple Design”(简单设计)是软件开发中的一个重要理念,倡导以最简单的方式实现软件功能,以确保代码清晰易懂、易维护,并在项目需求变化时能够快速适应。 其核心目标是避免复杂和过度设计,遵循“让事情保…...

重启Eureka集群中的节点,对已经注册的服务有什么影响
先看答案,如果正确地操作,重启Eureka集群中的节点,对已经注册的服务影响非常小,甚至可以做到无感知。 但如果操作不当,可能会引发短暂的服务发现问题。 下面我们从Eureka的核心工作原理来详细分析这个问题。 Eureka的…...

高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数
高效线程安全的单例模式:Python 中的懒加载与自定义初始化参数 在软件开发中,单例模式(Singleton Pattern)是一种常见的设计模式,确保一个类仅有一个实例,并提供一个全局访问点。在多线程环境下,实现单例模式时需要注意线程安全问题,以防止多个线程同时创建实例,导致…...

Docker 本地安装 mysql 数据库
Docker: Accelerated Container Application Development 下载对应操作系统版本的 docker ;并安装。 基础操作不再赘述。 打开 macOS 终端,开始 docker 安装mysql之旅 第一步 docker search mysql 》〉docker search mysql NAME DE…...