《Python机器学习原理与算法实现》学习笔记
以下为《Python机器学习原理与算法实现》(杨维忠 张甜 著 2023年2月新书 清华大学出版社)的学习笔记。
根据输入数据是否具有“响应变量”信息,机器学习被分为“监督式学习”和“非监督式学习”。
“监督式学习”即输入数据中即有X变量,也有y变量,特色在于使用“特征(X变量)”来预测“响应变量(y变量)”。“非监督式学习”即算法在训练模型时期不对结果进行标记,而是直接在数据点之间找有意义的关系,或者说输入数据中仅有X变量而没有y变量,特色在于针对X变量进行降维或者聚类,以挖掘特征变量的自身特征。
“监督式学习”机器学习又分为回归问题和分类问题,在python中,Classifier一般针对分类问题,Regressor一般针对回归问题(logistic除外)。错误率、精度、查准率、查全率都是“分类问题监督式学习”的常用性能度量标准。ROC曲线下方的区域又被称为AUC值,一般情况下AUC值越大,说明学习效果越好。
训练样本:即计算机用来应用算法构建模型时使用的样本。
测试样本:即计算机用来检验机器学习效果、检验外推泛化应用能力时使用的样本
偏差度量的是学习算法的期望预测与真实结果的偏离程度,反映的是学习算法的拟合能力。
方差度量的是在大量重复抽样过程中,同样大小的训练样本的变动导致的学习性能的变化,反映的是数据扰动所造成的影响,也就是模型的稳定性。
噪声度量的是针对既定学习任务,使用任何学习算法所能达到的期望泛化误差的最小值,属于不可约减误差,反映的是学习问题本身的难度,或者说是无法用机器学习算法解决的问题。噪声大小取决于数据本身的质量,当数据给定时,机器学习所能达到的泛化能力的上限也就确定。
“泛化误差”反映的模型的“泛化”能力,“泛化误差”越小,模型“泛化”能力越强。我们之所以开展机器学习是为了基于既有数据来预测未知,以期进一步改善未来商业表现,所以从应用的角度出发,我们主要关注的是泛化误差而不是经验误差,如果某种机器学习模型比另一种具有更小的泛化误差,那么这种模型就相对更加有效。 为了度量模型的泛化能力,通常我们需要进行样本分割,可以选用的方法包括验证集法、K折交叉验证、自助法、留一法等。 在机器学习项目的数据清洗与特征工程环节,有归一化、标准化、离散化、缺失值处理等多种方式。
input函数用来实现基本的输入;print函数用来实现基本的输出:使用时如果括号内容为字符串,则可以使用搭配单引号、搭配双引号、搭配三引号。
列表:list=[a,b,c,d]。列表中的元素可以为整数、实数、字符串、元组、列表等任意类型。
元组:tuple=(a,b,c,d)。元组为不可变序列,元组中的元素不可单独修改。元组中的元素可以为整数、实数、字符串、元组、列表等任意类型,可以相同(重复),也可以不同,甚至相互不同的类型。
字典:dict = {key1 : value1, key2 : value2 }。字典由键(key)和值(value)成对组成,本质上是键和值的映射。
索引就是序列中的每个元素所在的位置,可以通过从左往右的正整数索引,也可以通过从右往左的负整数索引。从左往右的正整数索引:在Python序列中,第一个元素的索引值为0,第二个元素的索引值为1,以此类推。假设序列中共有n个元素,那么最后一个元素的索引值为n-1。从右往左的负整数索引:在Python序列中,最后一个元素的索引值为-1,倒数第二个元素的索引值为-2,以此类推。
假设序列中共有n个元素,那么第一个元素的索引值为-n。Python中使用数字n乘以一个序列(非numpy模块中的数组、非pandas模块中的序列,只是普通的序列)会生成新的序列,内容为原来序列被重复n 次的结果 序列的切片就是将序列切成小的子序列,通过切片操作可以访问一定范围内的元素或者生成一个新的子序列。
Python的保留字区分大小写。
流程控制语句: 选择语句对应选择执行,选择语句包括三种:if语句,if…else语句和if…elif…else语句。if语句相当于“如果……就……”;if…else语句相当于“如果……就……,否则……”;if…elif…else语句相当于“如果……则……,否则如果满足某种条件则……,不满足某种条件则……,” 循环语句包括两种:while语句和for语句。while循环语句通过设定条件语句来控制是否循环执行循环体代码块中的语句,只要条件语句为真,循环就会一直执行下去,直到条件语句不再为真为止。for循环语句为重复一定次数的循环,适用于遍历或迭代对象中的元素。 跳转语句依托于循环语句,适用于从循环体中提前离开,比如在while循环达到结束条件之前离开,或者在for循环完成之前离开。跳转语句包括两种:break语句和continue语句。
线性回归算法: 理解起来比较简单,实现起来也比较容易;是许多强大的非线性模型的基础;具有一定的稳定性和可解释性;蕴含着机器学习的很多重要思想。
朴素贝叶斯算法: 朴素贝叶斯方法是在贝叶斯算法的基础上进行了相应的简化,即假定给定目标值时特征变量之间相互条件独立。包括高斯朴素贝叶斯、多项式朴素贝叶斯、补集朴素贝叶斯、二项式朴素贝叶斯等,均可通过Python的sklearn模块实现。
决策树算法: 常用的特征变量选择及其临界值确定方法包括信息增益(Information Gain)、增益比率(Gain Ratio)、基尼指数(Gini Index)。在决策树算法中,先采用的特征变量未必是贡献最大的,而是要看信息增益等指标的变动程度。
二元Logistic回归算法:二元Logistic回归算法中所估计的参数,不是特征变量对响应变量的边际效应,而是一种“概率优势比”的概念。
集成学习(组合学习、模型融合)的方式,即将单一的弱学习器组合在一起,通过群策群力形成强学习器,达到模型性能的提升。
针对集成方法的不同,集成学习可以分为并行集成和串行集成。 如果弱学习器间存在强依赖的关系,后一个弱学习器的生成需依赖前一个弱学习器的结果,则集成学习方式为串行集成,代表算法为Boosting(提升法),包括AdaBoost、GBDT、XGBoost等。其中AdaBoost算法会使得难于分类的样本的权值呈指数增长,后续的训练过程将会过于偏向这类困难样本,从而导致AdaBoost算法容易受极端值干扰。
回归问题损失函数常用平方损失函数、拉普拉斯损失函数(绝对损失函数)、胡贝尔损失函数和分位数损失函数,分类问题损失函数常用指数损失函数、逻辑损失函数、交叉熵损失函数。
如果弱学习器间不存在依赖关系,可以同时训练多个基学习器,适合分布式并行计算,则集成学习方式为并行集成,代表算法为装袋法、随机森林算法,其中装袋法是随机森林算法一种特例。装袋法在构建基分类器时,将所有特征变量都考虑进去,随机森林算法仅考虑部分特征变量。
自助法本质上是一种有放回的再抽样。
入门学Python,也真的不难。关键是找到学习入口,如果只是看语法,会很枯燥,也记不住。需要找到应用场景,也就是说要用Python来干什么?比如做个表、做个图,还是开展个数据分析、甚至建个模型。少儿编程很多都用Python了,为什么小孩们都能学的进去?因为学完了可以接着用于开发一个小游戏,回馈很快。从我周边朋友的经历来看,真正学进去的,基本上都是有数据分析需要的朋友们,因为工作中真的需要。所以我给大家推荐的学习场景入口是数据应用。
针对数据分析或机器学习推荐两本入门级的图书:《Python机器学习原理与算法实现》(杨维忠 张甜 著 2023年2月新书 清华大学出版社)《Python数据科学应用从入门到精通》(张甜 杨维忠 著 2023年11月新书 清华大学出版社)。这两本书的特色是在数据分析、机器学习各种算法的介绍方面通俗易懂,较少涉及数学推导,对数学基础要求相对不高,在python代码方面讲的很细致,看了以后根据自身需要选取算法、优化代码、科学调参。都有配套免费提供的源代码、数据文件和视频讲解,也有PPT、思维导图、习题等。 为什么说这两本书值得?首先说《Python机器学习原理与算法实现》(杨维忠 张甜 著 2023年2月新书 清华大学出版社),内容非常详实,包含了Python和机器学习,相当于一次获得了两本书。在讲解各类机器学习算法时,逐一详解用到的各种Python代码,针对每行代码均有恰当注释(这一点基本上是大多数书目做不到的)。山东大学经济学院教学实验中心主任 副教授 韩振,德勤华永会计师事务所 华文伟 合伙人,首创证券深圳分公司机构业务部 樊磊 总经理 中国准精算师,山东省农村信用社联合社数据管理项目组 郝路安 总监等一众大牛联袂推荐。这本书在出版之前曾开发成9次系列课程,在恒丰银行全行范围类开展培训,490人跟随杨维忠老师上课学习(课程限报490人),培训完成后课程在知鸟平台上回放超过3万人次。很多银行员工通过这些学习一下子就学会了Python,并且用于工作中开展数据分析、机器学习、数据可视化等,这本书也被多家商业银行选做数字化人才培训教材,成为银行员工的一本网红书。

《Python数据科学应用从入门到精通》一书,旨在教会读者实现全流程的数据分析,并且相对《Python机器学习原理与算法实现》一书增加了很多概念性、科普性的内容,进一步降低了学习难度。国务院发展研究中心创新发展研究部第二研究室主任杨超 ,山东大学经济学院金融系党支部书记、副主任、副教授、硕士生导师张博,山东管理学院信息工程学院院长 袁锋 教授、硕士生导师,山东大学经济学院刘一鸣副研究员、硕士生导师,得厚投资合伙人张伟民等一众大牛联袂推荐。书中全是干活,买这一本书相当于一下子得到了5本书(Python基础、数据清洗、特征工程、数据可视化、数据挖掘与建模),而且入门超级简单,不需要编程基础,也不需要过多数学推导,非常适用于零基础学生。全书内容共分13章。其中第1章为数据科学应用概述,第2章讲解Python的入门基础知识,第3章讲解数据清洗。第4~6章介绍特征工程,包括特征选择、特征处理、特征提取。第7章介绍数据可视化。第8~13章介绍6种数据挖掘与建模方法,分别为线性回归、Logistic回归、决策树、随机森林、神经网络、RFM分析。从数据科学应用和Python的入门,再到数据清洗与特征工程,最终完成数据挖掘与建模或数据可视化,从而可以为读者提供“从拿到数据开始,一直到构建形成最终模型或可视化报告成果”的一站式、全流程指导。

两本书随书赠送的学习资料也很多,包括全部的源代码、PPT、思维导图,还有10小时以上的讲解视频,每一章后面还有练习题及参考答案,还有学习群,相对于只看网络上的视频,一方面更加系统、高效,另一方面照着书一步步操作学起来也事半功倍。全网热销中,当当、京东等平台搜索“Python机器学习 杨维忠”“Python数据科学 杨维忠”即可。
《Python机器学习原理与算法实现》(杨维忠、张甜著,2023年2月,清华大学出版社),适用于学习Python/机器学习

《Python数据科学应用从入门到精通》(张甜 杨维忠 著 2023年11月新书 清华大学出版社)适用于学习数据分析、数据科学、数据可视化等。

创作不易,恳请多多点赞,感谢您的支持!也期待大家多多关注我,让我共同学习数据分析知识。
相关文章:
《Python机器学习原理与算法实现》学习笔记
以下为《Python机器学习原理与算法实现》(杨维忠 张甜 著 2023年2月新书 清华大学出版社)的学习笔记。 根据输入数据是否具有“响应变量”信息,机器学习被分为“监督式学习”和“非监督式学习”。 “监督式学习”即输入数据中即有X变量&…...
k8s集群通过helm部署skywalking
1、安装helm 下载脚本安装 ~# curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 ~# chmod 700 get_helm.sh ~# ./get_helm.sh或者下载包进行安装 ~# wget https://get.helm.sh/helm-canary-linux-amd64.tar.gz ~# mv helm …...

介绍一款PDF在线工具
PDF是我们日常工作中的一种常见格式,其处理也是我们工作的重要基础性环节,一款可靠的处理工具显得十分重要。 完全免费、易于使用、丰富的PDF处理工具,包括:合并、拆分、压缩、转换、旋转和解锁PDF文件,以及给PDF文件…...

docker学习——汇总版
历时一个月将docker系统的学习了一下,并且记录了详细的笔记和实践过程。 希望能对工作需要的小伙伴们有所帮助~ docker基础篇 docker学习(一、docker与VM对比) docker学习(二、安装docker) docker学习(…...

百度沧海文件存储CFS推出新一代Namespace架构
随着移动互联网、物联网、AI 计算等技术和市场的迅速发展,数据规模指数级膨胀,对于分布式文件系统作为大规模数据场景的存储底座提出了更高的要求。已有分布式文件系统解决方案存在着短板,只能适应有限的场景: >> 新型分布式…...
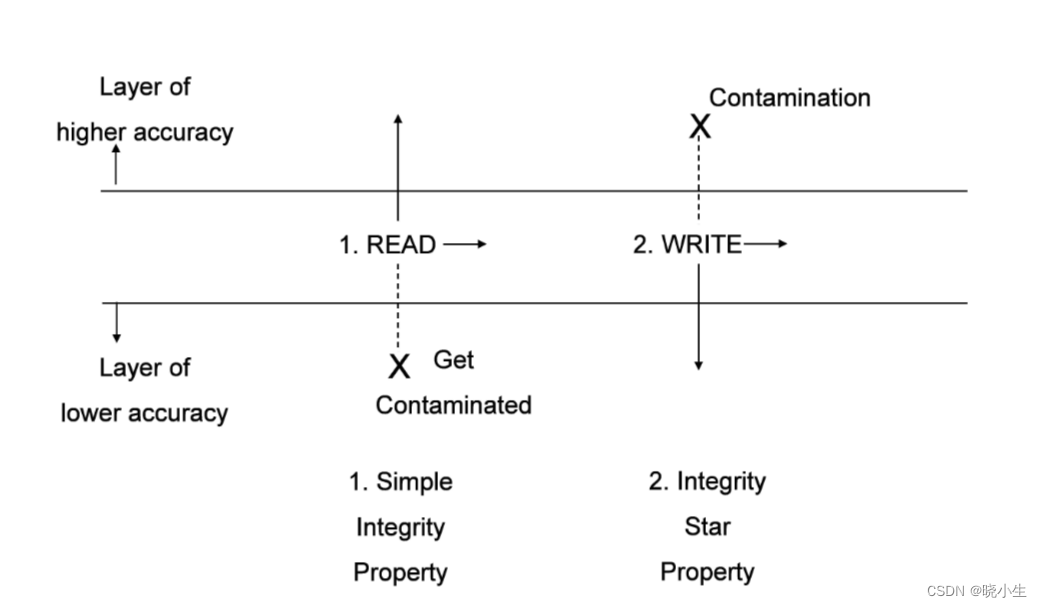
16-网络安全框架及模型-BiBa完整性模型
目录 BiBa完整性模型 1 背景概述 2 模型原理 3 主要特性 4 优势和局限性 5 应用场景 BiBa完整性模型 1 背景概述 Biba完整性模型是用于保护数据完整性的模型,它的主要目标是确保数据的准确性和一致性,防止未授权的修改和破坏。在这个模型中&#…...
ssm基于冲突动态监测算法的健身房预约系统的设计与实现论文
摘 要 传统办法管理信息首先需要花费的时间比较多,其次数据出错率比较高,而且对错误的数据进行更改也比较困难,最后,检索数据费事费力。因此,在计算机上安装健身房预约系统软件来发挥其高效地信息处理的作用ÿ…...

基于 Element UI 适用于 Vue 2 版本的虚拟列表选择器组件el-select
背景:在某些使用情况下,单个选择器可能最终加载数万行数据。 将这么多的数据渲染至 DOM 中可能会给浏览器带来负担,从而造成性能问题。 ——vue3element-plus有现成的轮子。而vue2element-ui没有。 以下 文章大部分 摘自 源组件中的README.md…...

java常见面试题:请解释一下Java中的常用分布式框架,如Spring Boot、Dubbo等。
下面我将详细介绍Java中的两个常用分布式框架:Spring Boot和Dubbo。 1. Spring Boot Spring Boot是一个用于创建独立、可运行的、生产级别的Spring应用程序的框架。它简化了Spring应用程序的创建和部署,使得开发人员能够专注于编写业务逻辑,…...

FreeRTOS列表与列表项相关知识总结以及列表项的插入与删除实战
1.列表与列表项概念及结构体介绍 1.1列表项简介 列表相当于链表,列表项相当于节点,FreeRTOS 中的列表是一个双向环形链表 1.2 列表、列表项、迷你列表项结构体 1)列表结构体 typedef struct xLIST { listFIRST_LIST_INTEGRITY_CHECK_VAL…...

07|输出解析:用OutputParser生成鲜花推荐列表
07|输出解析:用OutputParser生成鲜花推荐列表 模型 I/O Pipeline 下面先来看看 LangChain 中的输出解析器究竟是什么,有哪些种类。 LangChain 中的输出解析器 语言模型输出的是文本,这是给人类阅读的。但很多时候,你…...
)
cfa一级考生复习经验分享系列(十二)
背景:就职于央企金融机构,本科金融背景,一直在传统金融行业工作。工作比较忙,用了45天准备考试,几乎每天在6小时以上。 写在前面的话 先讲一下,整体一级考下来,我觉得知识点多,偏基础…...
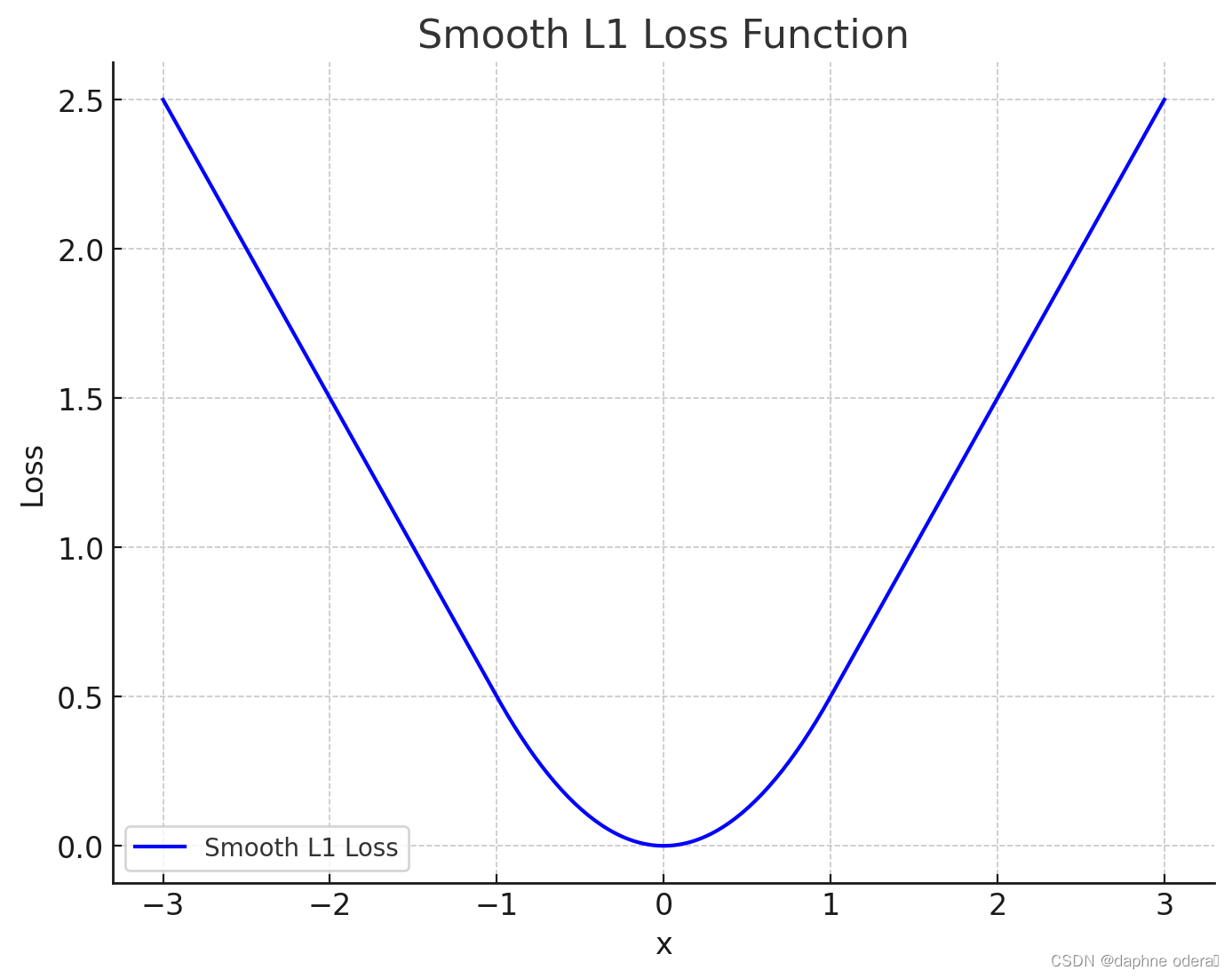
【损失函数】SmoothL1Loss 平滑L1损失函数
1、介绍 torch.nn.SmoothL1Loss 是 PyTorch 中的一个损失函数,通常用于回归问题。它是 L1 损失和 L2 损失的结合,旨在减少对异常值的敏感性。 loss_function nn.SmoothL1Loss(reductionmean, beta1.0) 2、参数 size_average (已弃用): 以前用于确定是…...

Go语言中的HTTP重定向
大家好,我是你们可爱的编程小助手,今天我们要一起探讨如何使用Go语言实现HTTP重定向,让我们开始吧! 大家都知道,网站开发中有时候需要将用户的请求从一个URL导向到另一个URL。比如说,你可能想将旧的URL结构…...
ORACLE P6 v23.12 最新虚拟机(VM)全套系统环境分享
引言 根据上周的计划,我简单制作了两套基于ORACLE Primavera P6 最新发布的23.12版本预构建了虚拟机环境,里面包含了全套P6 最新版应用服务 此虚拟机仅用于演示、培训和测试目的。如您在生产环境中使用此虚拟机,请先与Oracle Primavera销售代…...

鸿蒙开发ArkTS基础学习-开发准备工具配置
文章目录 前言1. 准备工作2.开发文档3.鸿蒙开发路径一.详情介绍二.DevEco Studio安装详解-开发环境搭建2.1配置开发环境欢迎各位读者阅读本文,今天我们将介绍鸿蒙(HarmonyOS)应用开发的入门步骤,特别是在准备工作和开发环境搭建方面的重要信息。本文将对鸿蒙官方网站的关键…...
WEB 3D技术 three.js 雾 基础使用讲解
本文 我们说一下 雾 在three.js中有一个 Fog类 它可以创建线性雾的一个效果 她就是模仿现实世界中 雾的一个效果 你看到远处物体会组件模糊 直到完全被雾掩盖 在 three.js 中 有两种雾的形式 一种是线性的 一种是指数的 个人觉得 线性的会看着自然一些 他是 从相机位置开始 雾…...

Python中的网络编程
IP地址 IPv4IPv6查看本机的IP地址 win ipconfiglinux ifconfig ping命令 ping www.baidu.com 查看是否能连通指定的网站ping 192.168.1.222 查看是否能连通指定的IP Port端口 0-65535 TCP/IP协议 传输数据之前要建立连接,通过三次握手建立: 客户端 --&g…...

uni-app js语法
锋哥原创的uni-app视频教程: 2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中..._哔哩哔哩_bilibili2023版uniapp从入门到上天视频教程(Java后端无废话版),火爆更新中...共计23条视频,包括:第1讲 uni…...

【论文阅读笔记】Detecting Camouflaged Object in Frequency Domain
1.论文介绍 Detecting Camouflaged Object in Frequency Domain 基于频域的视频目标检测 2022年发表于CVPR [Paper] [Code] 2.摘要 隐藏目标检测(COD)旨在识别完美嵌入其环境中的目标,在医学,艺术和农业等领域有各种下游应用。…...

Linux应用开发之网络套接字编程(实例篇)
服务端与客户端单连接 服务端代码 #include <sys/socket.h> #include <sys/types.h> #include <netinet/in.h> #include <stdio.h> #include <stdlib.h> #include <string.h> #include <arpa/inet.h> #include <pthread.h> …...

【SpringBoot】100、SpringBoot中使用自定义注解+AOP实现参数自动解密
在实际项目中,用户注册、登录、修改密码等操作,都涉及到参数传输安全问题。所以我们需要在前端对账户、密码等敏感信息加密传输,在后端接收到数据后能自动解密。 1、引入依赖 <dependency><groupId>org.springframework.boot</groupId><artifactId...

SCAU期末笔记 - 数据分析与数据挖掘题库解析
这门怎么题库答案不全啊日 来简单学一下子来 一、选择题(可多选) 将原始数据进行集成、变换、维度规约、数值规约是在以下哪个步骤的任务?(C) A. 频繁模式挖掘 B.分类和预测 C.数据预处理 D.数据流挖掘 A. 频繁模式挖掘:专注于发现数据中…...

解决Ubuntu22.04 VMware失败的问题 ubuntu入门之二十八
现象1 打开VMware失败 Ubuntu升级之后打开VMware上报需要安装vmmon和vmnet,点击确认后如下提示 最终上报fail 解决方法 内核升级导致,需要在新内核下重新下载编译安装 查看版本 $ vmware -v VMware Workstation 17.5.1 build-23298084$ lsb_release…...

大语言模型如何处理长文本?常用文本分割技术详解
为什么需要文本分割? 引言:为什么需要文本分割?一、基础文本分割方法1. 按段落分割(Paragraph Splitting)2. 按句子分割(Sentence Splitting)二、高级文本分割策略3. 重叠分割(Sliding Window)4. 递归分割(Recursive Splitting)三、生产级工具推荐5. 使用LangChain的…...

微信小程序云开发平台MySQL的连接方式
注:微信小程序云开发平台指的是腾讯云开发 先给结论:微信小程序云开发平台的MySQL,无法通过获取数据库连接信息的方式进行连接,连接只能通过云开发的SDK连接,具体要参考官方文档: 为什么? 因为…...

有限自动机到正规文法转换器v1.0
1 项目简介 这是一个功能强大的有限自动机(Finite Automaton, FA)到正规文法(Regular Grammar)转换器,它配备了一个直观且完整的图形用户界面,使用户能够轻松地进行操作和观察。该程序基于编译原理中的经典…...

html-<abbr> 缩写或首字母缩略词
定义与作用 <abbr> 标签用于表示缩写或首字母缩略词,它可以帮助用户更好地理解缩写的含义,尤其是对于那些不熟悉该缩写的用户。 title 属性的内容提供了缩写的详细说明。当用户将鼠标悬停在缩写上时,会显示一个提示框。 示例&#x…...

LeetCode - 199. 二叉树的右视图
题目 199. 二叉树的右视图 - 力扣(LeetCode) 思路 右视图是指从树的右侧看,对于每一层,只能看到该层最右边的节点。实现思路是: 使用深度优先搜索(DFS)按照"根-右-左"的顺序遍历树记录每个节点的深度对于…...

浪潮交换机配置track检测实现高速公路收费网络主备切换NQA
浪潮交换机track配置 项目背景高速网络拓扑网络情况分析通信线路收费网络路由 收费汇聚交换机相应配置收费汇聚track配置 项目背景 在实施省内一条高速公路时遇到的需求,本次涉及的主要是收费汇聚交换机的配置,浪潮网络设备在高速项目很少,通…...