【AI】注意力机制与深度学习模型
目录
一、注意力机制
二、了解发展历程
2.1 早期萌芽:
2.2 真正意义的注意力机制:
2.3 2015 年及以后:
2.4 自注意力与 Transformer:
2.5 BERT 与预训练模型:
三、基本框架
1. 打分函数(Score Function)
2. 校准函数(Alignment Function / Softmax)
3. 融合(Fusion / Weighted Sum)
比如机器翻译任务
四、分类
4.1 根据注意力的计算区域分类
4.2 根据注意力的可微性分类
4.3 根据注意力的来源分类
4.4 根据注意力的层次结构分类
4.5 其他形式的注意力模型
一、注意力机制
从人工智能专家的角度来看,注意力机制(Attention Mechanism)是一种在深度学习模型中,尤其是在处理序列数据(如文本、语音、时间序列等)时非常重要的技术。其核心思想是让模型在处理信息时能够“集中注意力”在更相关的部分,而忽略不那么重要的信息。
视觉注意力机制是人类视觉所特有的大脑信号处理机制。人类视觉通过快速扫描全局图像,获得需要重点关注的目标区域,也就是一般所说的注意力焦点,而后对这一区域投入更多注意力资源,以获取更多所需要关注目标的细节信息,而抑制其他无用信息。这是人类利用有限的注意力资源从大量信息中快速筛选出高价值信息的手段,是人类在长期进化中形成的一种生存机制,人类视觉注意力机制极大地提高了视觉信息处理的效率与准确性。计算机视觉中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似,核心目标也是从众多信息中选择出对当前任务目标更关键的信息。
以下是注意力机制的一些关键要点:
-
直观理解:想象一下你正在阅读一篇文章。你不会一字不漏地看完每一个字,而是会集中注意力在那些对你而言最重要或最相关的词或句子上。这就是注意力机制希望模拟的行为。
-
工作原理:在深度学习模型中,注意力机制通常通过计算一个权重分布来实现。这个分布决定了在生成输出时,输入序列中的哪些部分应该被更多地关注。例如,在机器翻译任务中,生成目标语言的一个词时,模型可能会更多地关注源语言中与之对应的词或短语。
-
数学表达:给定一个查询(Query)和一个键值对集合(Key-Value pairs),注意力机制可以计算出一个加权的输出。查询、键和值通常都是向量。输出的计算通常涉及查询与每个键的点积,然后应用一个softmax函数来得到权重分布,最后用这个分布加权所有的值来得到最终的输出。
-
类型:有多种注意力机制,包括但不限于:
- 全局注意力与局部注意力:全局注意力考虑输入序列的所有位置,而局部注意力只关注输入序列的特定子集。
- 自注意力(Self-Attention):在自注意力中,查询、键和值都来自同一个输入序列。这种机制在Transformer模型中得到了广泛应用。
- 多头注意力(Multi-Head Attention):在这种机制中,多个独立的注意力模块并行运行,并将它们的输出拼接或平均起来,以捕获输入数据的不同方面。
-
优势与应用:注意力机制可以提高模型的可解释性(因为可以看到模型关注了哪些输入),并允许模型处理变长输入序列。它们在各种NLP任务中都取得了巨大成功,如机器翻译、问答系统、情感分析和文本摘要等。此外,注意力机制也被应用于其他领域,如计算机视觉和语音识别。
二、了解发展历程
2.1 早期萌芽:
- 在深度学习兴起之前,注意力机制的思想已经在一些传统的机器学习模型中有所体现,比如隐马尔可夫模型(HMM)中的对齐(Alignment)概念,但这并不算是真正的“注意力”。
2.2 真正意义的注意力机制:
- 注意力机制在深度学习中的首次明确提出通常与 Bahdanau 等人在 2014 年的工作《Neural Machine Translation by Jointly Learning to Align and Translate》相关联。在这篇论文中,作者们为机器翻译任务引入了一种名为“加性注意力”(Additive Attention)的机制,允许模型在生成目标语言句子时自动搜索源语言句子中的相关部分。这种方法极大地改善了之前基于编码-解码(Encoder-Decoder)架构的机器翻译系统的性能,尤其是当处理长句子时。
2.3 2015 年及以后:
- Luong 等人在 2015 年的论文《Effective Approaches to Attention-based Neural Machine Translation》中提出了两种新的注意力机制:全局注意力(Global Attention)和局部注意力(Local Attention),并对加性注意力和点积注意力(Dot-Product Attention)进行了比较。
- 同一时期,注意力机制开始被应用到其他自然语言处理任务中,如文本分类、情感分析、问答系统等。
2.4 自注意力与 Transformer:
- 2017 年,Vaswani 等人的论文《Attention is All You Need》彻底改变了注意力的研究方向和应用领域。这篇论文提出了 Transformer 架构,完全基于自注意力(Self-Attention)机制,摒弃了传统的循环神经网络(RNN)和卷积神经网络(CNN)。Transformer 模型通过多头自注意力机制(Multi-Head Self-Attention)实现了对输入序列内部依赖关系的有效建模,并在机器翻译任务上取得了显著的性能提升。
- 自此以后,Transformer 成为了自然语言处理领域的主导架构,并被广泛应用于各种任务中,包括但不限于语言建模、机器翻译、文本摘要、对话系统等。
2.5 BERT 与预训练模型:
- 2018 年,Devlin 等人提出了 BERT(Bidirectional Encoder Representations from Transformers),这是一种基于 Transformer 的预训练语言模型。BERT 通过在大规模无标签文本数据上进行预训练,学习到了通用的语言表示,可以通过微调(Fine-tuning)来适应各种下游任务。BERT 的成功进一步推动了注意力机制在自然语言处理领域的应用和发展。
三、基本框架
注意力机制最早在 NLP 应用中被提出并发展,且大多模型都构建在 RNN 网络上。随着 Transformer 模型的提出,注意力模型开始采用编解码器网络而脱离了 RNN 的局限。之后,注意力模型被广泛应用于计算机视觉领域。视觉注意力模型与NLP 注意力模型略有不同,具体地包含三个部分:
1. 打分函数(Score Function)
打分函数负责为输入序列中的每个元素计算一个与当前焦点(比如解码器中的某个状态)相关的得分。这个得分反映了输入元素对于当前焦点的重要性。常见的打分函数有点积、加性/拼接等。
-
点积打分(Dot-Product Score):
在点积注意力中,打分函数计算解码器当前状态与编码器每个状态的点积。假设解码器当前状态为query,编码器状态集合为keys,则打分函数为:scores = query · keys^T。 -
加性/拼接打分(Additive/Concatenation Score):
在这种注意力中,解码器当前状态和编码器状态首先被拼接起来,然后通过一个全连接层(可能包含非线性激活函数)来计算得分。
2. 校准函数(Alignment Function / Softmax)
校准函数负责将打分函数输出的原始得分转换成一组权重,这些权重将被用于加权输入序列中的元素。通常,这一步是通过softmax函数来实现的,softmax可以将原始得分转换成一组和为1的正数权重。
weights = softmax(scores)
3. 融合(Fusion / Weighted Sum)
最后一步是根据校准后的权重对输入序列进行加权求和,得到一个上下文向量(context vector)。这个上下文向量包含了输入序列中与当前焦点最相关的信息。
context_vector = weights * values
这里的values通常是与keys相对应的编码器输出序列。在自注意力中,keys、values和query都来自同一个输入序列。
比如机器翻译任务
考虑一个英文到中文的机器翻译任务,其中英文句子“I love machine learning”需要被翻译成中文“我爱机器学习”。在生成中文“我”的时候,注意力模型可能会给英文单词“I”一个很高的权重,而给其他单词较低的权重;在生成“爱”的时候,模型可能会关注“love”;以此类推。
- 打分函数:对于解码器生成“我”时的状态,模型会计算它与编码器中每个单词状态的得分,比如通过点积或加性方法。
- 校准函数:得分会被转换成权重,比如通过softmax,这样“I”会得到一个接近1的权重,而其他单词的权重会很小。
- 融合:最后,根据这些权重对编码器的输出进行加权求和,得到一个上下文向量,这个向量会被解码器用来生成“我”。
这个过程会在生成每个中文词的时候重复进行,确保解码器能够关注到输入英文句子中最相关的信息。
四、分类
注意力模型可以根据不同的分类标准有多种形式。以下是对注意力模型不同形式的分类及其详细解释,力求条理清晰、全面无遗漏:
4.1 根据注意力的计算区域分类
——Soft Attention(软注意力):
- 特点:对所有输入数据进行加权处理,每个输入数据都会被赋予一个注意力权重。
- 工作机制:不设置筛选条件,而是通过计算每个输入与当前焦点的相关度来分配权重。
- 应用场景:常见于需要全局考虑输入信息的情况,如机器翻译、文本摘要等。
——Hard Attention(硬注意力):
- 特点:只关注输入序列中的特定部分,忽略其他不相关的部分。
- 工作机制:在生成注意力权重后,通过设定阈值或采样方式选择性地关注某些输入。
- 应用场景:适用于需要精确定位关键信息的情况,如图像分类中的关键区域定位。
——Local Attention(局部注意力):
- 特点:结合了Soft Attention和Hard Attention的思想,既关注特定区域又保持了一定的灵活性。
- 工作机制:首先通过Hard Attention的方式定位到某个区域,然后在该区域内使用Soft Attention进行加权处理。
- 应用场景:适用于需要同时考虑全局和局部信息的情况,如语音识别中的音素识别。
4.2 根据注意力的可微性分类
——Hard Attention:
- 如上所述,Hard Attention是一个不可微的注意力机制,通常使用强化学习等方法进行优化。
——Soft Attention:
- Soft Attention是一个可微的注意力机制,可以通过梯度下降等优化算法进行训练。由于其可微性,Soft Attention在深度学习模型中得到了广泛应用。
4.3 根据注意力的来源分类
——General Attention(普通注意力):
- 特点:利用外部信息来指导注意力的分配。
- 工作机制:在生成注意力权重时,考虑当前焦点与外部信息(如查询向量)的匹配程度。
- 应用场景:适用于需要利用外部知识或上下文信息来指导注意力分配的情况。
——Self Attention(自注意力):
- 特点:仅利用输入序列内部的信息进行注意力分配,不考虑外部信息。
- 工作机制:将输入序列中的每个元素与其他元素进行比较和关联,从而计算出每个元素的注意力权重。
- 应用场景:自注意力是Transformer模型中的核心机制之一,广泛应用于自然语言处理领域的各种任务中。由于其能够捕捉输入序列内部的依赖关系,自注意力也被用于图像识别、语音识别等其他领域。
- 具体形式:自注意力可以进一步分为单头自注意力和多头自注意力。单头自注意力使用一个注意力头来计算权重;而多头自注意力则使用多个独立的注意力头并行计算权重,然后将它们的结果拼接或平均起来作为最终的输出。这种多头机制可以捕捉输入数据在不同子空间中的特征表示,从而提高模型的表达能力。
4.4 根据注意力的层次结构分类
——单层Attention:
- 在单层Attention中,注意力机制只作用于输入序列的一个层次上(如词级别),没有考虑不同层次之间的关联和交互。
——多层Attention:
- 多层Attention通过堆叠多个注意力层来捕捉输入序列在不同层次上的信息。每个注意力层都可以关注到不同级别的信息(如词级别、短语级别、句子级别等),从而实现更细粒度的信息抽取和表示学习。这种多层结构有助于模型捕捉更复杂的语言现象和语义关系。
——多头Attention(Multi-Head Attention):
- 多头Attention是Transformer模型中的一个关键组件,它通过并行计算多个独立的注意力头来捕捉输入序列在不同子空间中的特征表示。每个头都可以关注到不同的信息片段,从而提高了模型的表达能力和泛化能力。多头Attention的输出通常是将所有头的输出拼接起来或通过线性变换进行融合得到的。
4.5 其他形式的注意力模型
除了上述分类方式外,还有一些其他形式的注意力模型值得提及:
——通道注意力(Channel Attention):
- 通道注意力主要关注输入特征图中不同通道之间的重要性差异。通过对每个通道的特征进行加权处理来强调或抑制某些通道的信息传递,从而提高模型对关键特征的敏感性。常见的通道注意力机制包括SENet中的Squeeze-and-Excitation模块和ECANet中的Efficient Channel Attention模块等。
——空间注意力(Spatial Attention):
- 空间注意力主要关注输入特征图中不同空间位置的重要性差异。通过对每个位置的特征进行加权处理来强调或抑制某些位置的信息传递,从而使模型能够聚焦于关键区域或忽略不相关区域的信息干扰。常见的空间注意力机制包括ConvLSTM中的Spatial Attention模块和STN(Spatial Transformer Networks)中的Affine Transformation等。
综上所述,注意力模型具有多种形式和分类方式,每种形式都有其独特的特点和应用场景。在实际应用中,可以根据具体任务和数据特点选择合适的注意力机制来提高模型的性能和解释性。
相关文章:

【AI】注意力机制与深度学习模型
目录 一、注意力机制 二、了解发展历程 2.1 早期萌芽: 2.2 真正意义的注意力机制: 2.3 2015 年及以后: 2.4 自注意力与 Transformer: 2.5 BERT 与预训练模型: 三、基本框架 1. 打分函数(Score Fun…...
HTML5和JS实现新年礼花效果
HTML5和JS实现新年礼花效果 2023兔年再见,2024龙年来临了! 祝愿读者朋友们在2024年里,身体健康,心灵愉悦,梦想成真。 下面是用HTML5和JS实现新年礼花效果: 源码如下: <!DOCTYPE html>…...
【owt-server】一些构建项目梳理
【owt-server】清理日志:owt、srs、ffmpeg 【owt】p2p client mfc 工程梳理【m98】webrtc vs2017构建带符号的debug库【OWT】梳理构建的webrtc和owt mfc工程 m79的mfc客户端及owt-client...

Linux shell编程学习笔记38:history命令
目录 0 前言 1 history命令的功能、格式和退出状态1.1 history命令的功能1.2 history命令的格式1.3退出状态2 命令应用实例2.1 history:显示命令历史列表2.2 history -a:将当前会话的命令行历史追加到历史文件~/.bash_history中2.3 history -c…...
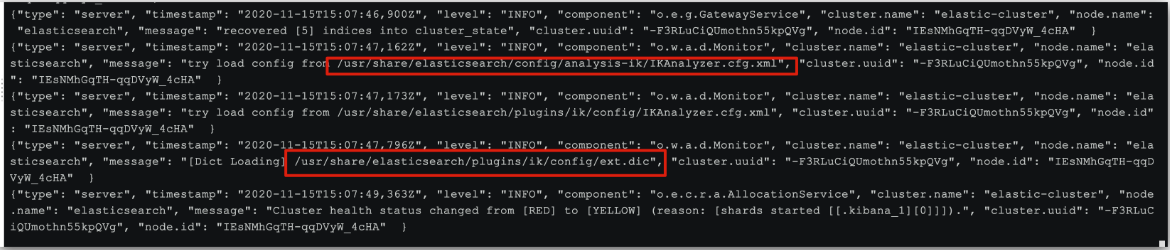
elasticsearch安装教程(超详细)
1.1 创建网络(单点部署) 因为我们还需要部署 kibana 容器,因此需要让 es 和 kibana 容器互联,所有先创建一个网络: docker network create es-net 1.2.加载镜像 采用的版本为 7.12.1 的 elasticsearch;…...
arkts中@Watch监听的使用
概述 Watch用于监听状态变量的变化,当状态变量变化时,Watch的回调方法将被调用。Watch在ArkUI框架内部判断数值有无更新使用的是严格相等(),遵循严格相等规范。当在严格相等为false的情况下,就会触发Watch的…...
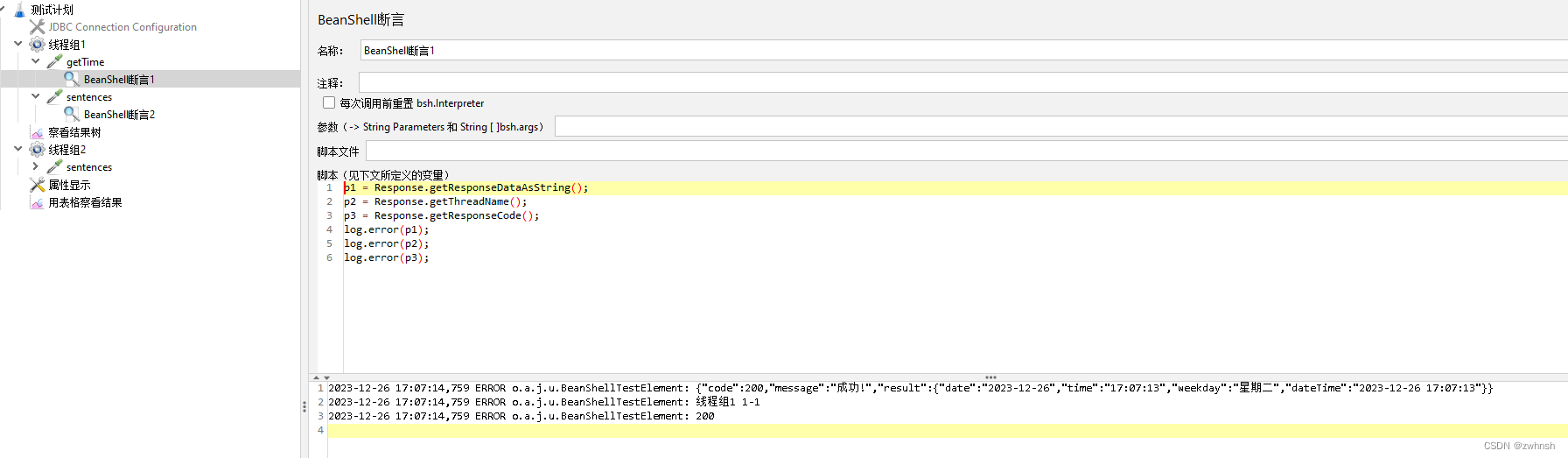
【Jmeter】Jmeter基础9-BeanShell介绍
3、BeanShell BeanShell是一种完全符合Java语法规范的脚本语言,并且又拥有自己的一些语法和方法。 3.1、Jmeter中使用的BeanShell 在Jmeter中,除了配置元件,其他类型的元件中都有BeanShell。BeanShell 是一种完全符合Java语法规范的脚本语言,并且又拥…...
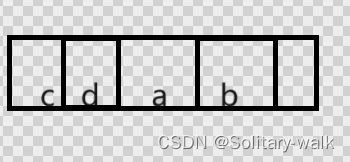
详解数组的轮转
𝙉𝙞𝙘𝙚!!👏🏻‧✧̣̥̇‧✦👏🏻‧✧̣̥̇‧✦ 👏🏻‧✧̣̥̇:Solitary-walk ⸝⋆ ━━━┓ - 个性标签 - :来于“云”的“羽球人”。…...

html 表格 笔记
<!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>第二个页面</title><meta name"language" content"cn"> </head> <body><h2 sytle"width:500px;…...
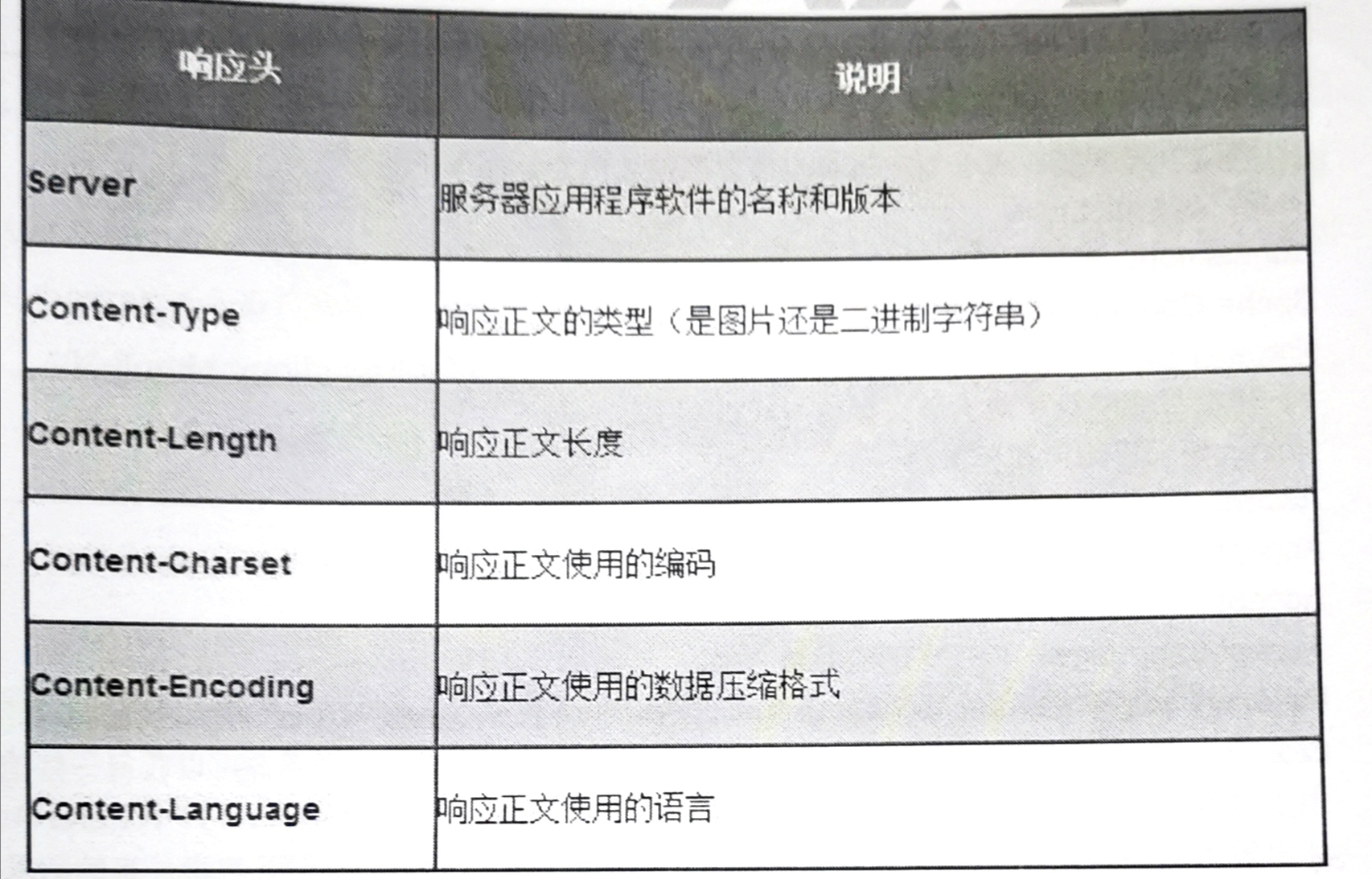
计算机网络【HTTP 面试题】
HTTP的请求报文结构和响应报文结构 HTTP请求报文主要由请求行、请求头、空行、请求正文(Get请求没有请求正文)4部分组成。 1、请求行 由三部分组成,分别为:请求方法、URL以及协议版本,之间由空格分隔;请…...

linux基于用户身份对资源访问进行控制的解析及过程
linux中用户分为三类 1.超级用户(root) 拥有至高无上的权限 2.普通用户 人为创建、权限小,权限受到控制 3.程序用户 运行程序的用户,不是给人使用的,给程序使用的,一般不给登录! 组账…...
手动创建idea SpringBoot 项目
步骤一: 步骤二: 选择Spring initializer -> Project SDK 选择自己的JDK版本 ->Next 步骤三: Maven POM ->Next 步骤四: 根据JDK版本选择Spring Boot版本 11版本及以上JDK建议选用3.2版本,JDK为11版本…...

【Go语言入门:Go语言的数据结构】
文章目录 3.Go语言的数据结构:3.1. 指针3.2. struct(结构体)3.3. Map(映射,哈希) 3.Go语言的数据结构: 简介: 在Go语言中,数据结构体可以分为四种类型:基础类型、聚合类型、引用类型…...

QT designer的ui文件转py文件之后,实现pycharm中运行以方便修改逻辑,即添加实时模板框架
为PyCharm中的实时模板,你需要遵循以下步骤: 打开PyCharm的设置: 选择 File > Settings(在macOS上是 PyCharm > Preferences)。 导航到实时模板: 在设置中找到 Editor > Live Templates。 添加新的模板组 (可选): 为了…...

什么是负载均衡?
负载均衡是指在计算机网络领域中,将客户端请求分配到多台服务器上以实现带宽资源共享、优化资源利用率和提高系统性能的技术。负载均衡可以帮助小云有效解决单个服务器容量不足或性能瓶颈的问题,小云通过平衡流量负载,使得多台服务器能够共同…...

Python和Java的优缺点
Python的优点: 简单易学:Python的语法简洁清晰,易于学习和理解。丰富的库和框架:Python拥有庞大的标准库和活跃的开源社区,可以快速使用各种功能强大的库和框架,比如NumPy、Pandas、Django等。可读性强&am…...
)
AES - 在tiny-AES-c基础上封装了2个应用函数(加密/解密)
文章目录 AES - 在tiny-AES-c基础上封装了2个应用函数(加密/解密)概述增加2个封装函数的AES库aes.haes.c在官方测试程序上改的测试程序(用来测试这2个封装函数)END AES - 在tiny-AES-c基础上封装了2个应用函数(加密/解密) 概述 在github山有个星数很高的AES的C库 tiny-AES-c …...

51和32单片机读取FSR薄膜压力传感器压力变化
文章目录 简介线性电压转换模块51单片机读取DO接线方式51代码实验效果 32单片机读取AO接线方式32代码实验效果 总结 简介 FSR薄膜压力传感器是可以将压力变化转换为电阻变化的一种传感器,单片机可以读取然后作为粗略测量压力(仅提供压力变化,…...

【maven】pom.xml 文件详解
有关 maven 其他配置讲解参考 maven 配置文件 setting.xml 详解 pom.xml 文件是 Maven 项目的核心配置文件,其中包含了项目的元数据、构建配置、依赖管理等信息。以下是一个 pom.xml 文件的主要部分: <?xml version"1.0" encoding"U…...
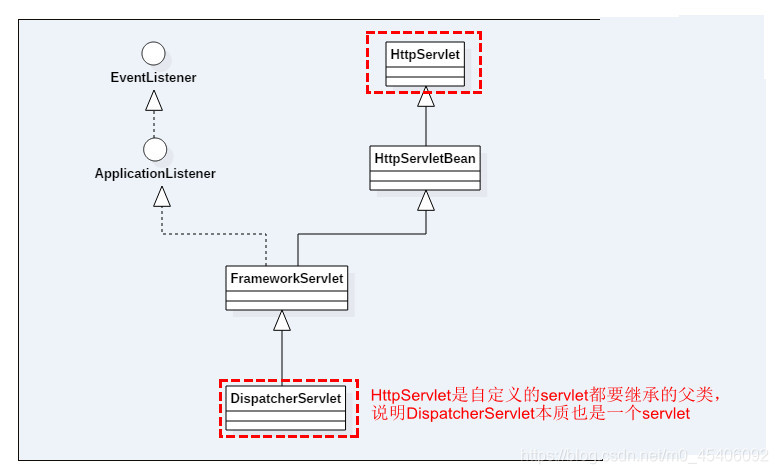
SpringMVC源码解析——DispatcherServlet初始化
在Spring中,ContextLoaderListener只是辅助功能,用于创建WebApplicationContext类型的实例,而真正的逻辑实现其实是在DispatcherServlet中进行的,DispatcherServlet是实现Servlet接口的实现类。Servlet是一个JAVA编写的程序&#…...

多模态AI框架MMClaw:从编码融合到实战部署全解析
1. 项目概述:一个面向多模态内容理解的“机械爪” 最近在折腾一些多模态项目时,发现一个挺有意思的仓库,叫 leadersboat/MMClaw 。光看名字, MM 大概率指的是 Multimodal(多模态) ,而 Cl…...

语音技能开发框架解析:从事件驱动到插件化实现
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫hermesnest/sister-skill。乍一看这个名字,可能会觉得有点抽象,甚至带点神秘色彩。但如果你对智能语音助手、家庭自动化或者个人AI助理这类话题感兴趣,那这个项目绝对值…...
)
面向零基础初学者,从环境搭建到发布上线,手把手教你开发第一个微信小程序(第5章-WXSS入门)
5.1 WXSS是什么? WXSS(WeiXin Style Sheets)是微信小程序的样式语言,类似于网页开发中的CSS。 WXSS vs CSS对比CSSWXSS选择器支持完整选择器支持大部分选择器单位px, em, remrpx, px布局flex, grid主要用flex最大的区别࿱…...

泰山派3M-RK3576-Linux内核驱动教程-Linux驱动基础-字符驱动设备-字符设备框架
03.字符设备框架 一、什么是字符设备? 字符设备(Character Device)是一类能像“一个字节一个字节”那样进行数据流式读写的设备,常见例子有串口、键盘、鼠标等。用户和程序通过文件操作(open、read、write、close 等&a…...

构建具备长期记忆的AI智能体:Electric-Hydrogen/GPTBot架构解析与实践
1. 项目概述:当GPTBot遇见Electric-Hydrogen最近在开源社区里,我注意到一个挺有意思的项目,叫“Electric-Hydrogen/GPTBot”。光看这个名字,就透着一股跨界融合的味道。Electric-Hydrogen,直译是“电-氢”,…...

走上管理岗进步最快的方式,没有之一
做了这么多年管理,我发现一个规律: 那些成长快的管理者,身上都有一个共同点。这个共同点不是天赋、不是运气、也不是有人带。 是一个可复制的方法。 这个方法说出来不复杂,但大多数人做不到,因为太反人性了。 01 这…...

嵌入式RTOS实战:从OpenFelix内核解析到物联网数据采集系统设计
1. 项目概述:一个为嵌入式与物联网而生的开源实时操作系统如果你正在寻找一个轻量、高效且完全开源的实时操作系统(RTOS)来驱动你的下一个嵌入式或物联网项目,那么fspecii/openfelix绝对值得你花时间深入研究。这个项目并非又一个…...

工程师的充电器管理指南:三级体系告别线缆混乱
1. 一个工程师的“充电器之海”自救指南如果你走进我家客厅的角落,你会看到一个堪称现代科技生活“奇观”的景象:一个号称能收纳所有充电器的“充电站”,上面缠绕着超过十根不同规格的线缆,它们像藤蔓一样交织在一起,连…...

SQL Server如何实现编写表与字段注释_Navicat兼容操作步骤
ASSM表空间不能设为MANUAL,因LMT不支持手动段管理,10g执行SEGMENT SPACE MANAGEMENT MANUAL会报ORA-12913;新建表空间必须用AUTO,FREELIST在LMT下无效。ASSM 表空间为什么不能关自动段管理本地管理表空间(lmtÿ…...

S32K3安全机制深度拆解:当CPU、内存、时钟“生病”时,芯片如何自救与报警?
S32K3安全机制深度拆解:当CPU、内存、时钟“生病”时,芯片如何自救与报警? 想象一下,一辆高速行驶的智能汽车突然遭遇CPU运算错误或内存数据损坏——这不是科幻场景,而是汽车电子系统每天需要防范的真实风险。S32K3系列…...