数据结构期末复习(2)链表
链表
链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指向下一个节点)。通过节点之间的指针连接,形成一个链式结构。
链表可以分为单向链表和双向链表两种类型。在单向链表中,每个节点只有一个指针,指向下一个节点;而在双向链表中,每个节点有两个指针,分别指向前一个节点和后一个节点。
链表的优点是插入和删除操作的时间复杂度为O(1),而不受数据规模的影响。但是,访问链表中的特定元素需要从头开始遍历链表,时间复杂度为O(n),其中n是链表的长度。
链表在实际应用中有广泛的用途,比如实现栈、队列、哈希表等数据结构,以及解决一些特定的问题,如反转链表、合并有序链表等。
需要注意的是,在使用链表时,我们需要额外的空间来存储指针,因此链表对内存的利用率较低。同时,在频繁插入和删除操作较多,而对访问操作要求不高的情况下,链表是一个较为合适的选择。

单链表(Singly Linked List)是一种常见的链表结构,由一系列节点按顺序连接而成。每个节点包含两个部分:数据域(存储元素值)和指针域(指向下一个节点)。最后一个节点的指针域指向空(NULL)。
以下是单链表的基本结构:
Node:- 数据域(Data): 存储元素值- 指针域(Next): 指向下一个节点LinkedList:- 头指针(Head): 指向链表的第一个节点
单链表的头指针(Head)用于标识链表的起始位置。通过头指针,可以遍历整个链表,或者在链表中插入、删除节点。
单链表的特点是每个节点只有一个指针域,指向下一个节点,最后一个节点的指针域为空。这意味着,在单链表中,只能从前往后遍历,无法直接访问前一个节点,因此对于某些操作,比如在给定节点之前插入一个新节点,需要额外的操作来处理指针。
需要注意的是,单链表中的节点可以动态地分配内存,这意味着可以根据需求灵活地扩展或缩小链表的长度。
下面是一个示例单链表的结构:
Head -> Node1 -> Node2 -> Node3 -> ... -> NULL
其中,Head是头指针,Node1、Node2、Node3等为节点,箭头表示指针域的指向关系,NULL表示链表的结束。
单链表的操作包括插入节点、删除节点、查找节点、遍历链表等,这些操作可以根据具体需求进行实现。

题1.若线性表采用链式存储,则表中各元素的存储地址()。
A.必须是连续的
B.部分地址是连续的
C.一定是不连续的
D.不一定是连续的
答案:D
题2.单链表中,增加一个头结点的目的是为了()。
A.使单链表至少有一个结点
B.标识表结点中首结点的位置
C.方便运算的实现
D.说明单链表是线性表的链式存储
答案:C
题1的答案是D. 不一定是连续的。
如果线性表采用链式存储方式,表中各元素的存储地址不需要连续。链式存储通过节点之间的指针连接,每个节点可以分配在内存的任意位置。节点的指针域存储着下一个节点的地址,通过指针的链接,实现了元素之间的逻辑关系。
题2的答案是C. 方便运算的实现。
增加一个头结点的目的是为了方便对单链表进行操作和实现一些常用的操作,如插入、删除、查找等。头结点不存储具体的数据,它的存在主要是为了简化操作,使得对链表的操作更加统一和方便。头结点可以作为操作的起点,避免了对空链表的特殊处理,提高了代码的可读性和可维护性。
引入头结点后,可以带来两个优点:
①由于第一个数据结点的位置被存放在头结点的指针域中,所以在链表的第一个位置上的操作和在表的其他位置上的操作一致,无需进行特殊处理。
②无论链表是否为空,其头指针都指向头结点的非空指针(空表中头结点的指针域为空)。
单链表的实现
以下是单链表的详细实现示例(使用C语言):
- 定义节点结构(Node):
struct Node {int data;struct Node *next;
};
- 定义链表结构(LinkedList):
struct LinkedList {struct Node *head;
};
- 实现插入操作:
void insert(struct LinkedList *list, int data) {struct Node *new_node = (struct Node *)malloc(sizeof(struct Node)); // 创建新节点new_node->data = data;new_node->next = NULL;if (list->head == NULL) { // 如果链表为空,将新节点设为头节点list->head = new_node;} else {struct Node *current = list->head;while (current->next != NULL) { // 遍历到最后一个节点current = current->next;}current->next = new_node; // 将新节点插入在最后一个节点之后}
}
- 实现删除操作:
void delete(struct LinkedList *list, int target) {if (list->head == NULL) { // 如果链表为空,无法删除return;}if (list->head->data == target) { // 如果要删除的节点是头节点struct Node *temp = list->head;list->head = list->head->next;free(temp);} else {struct Node *current = list->head;while (current->next != NULL && current->next->data != target) { // 查找要删除节点的前一个节点current = current->next;}if (current->next != NULL) { // 找到要删除的节点struct Node *temp = current->next;current->next = current->next->next;free(temp);}}
}
- 实现查找操作:
int search(struct LinkedList *list, int target) {struct Node *current = list->head;while (current != NULL) {if (current->data == target) { // 找到匹配的节点return 1;}current = current->next;}return 0; // 遍历完链表未找到匹配的节点
}
- 实现遍历操作:
void traverse(struct LinkedList *list) {struct Node *current = list->head;while (current != NULL) {printf("%d ", current->data); // 访问节点的数据域current = current->next;}
}
这是一个简单的单链表实现示例。由于C语言需要手动管理内存,因此在使用malloc函数分配内存时需要检查是否分配成功,并在删除节点时需要使用free函数释放内存。您可以根据这个示例进行自定义扩展和适应具体需求。



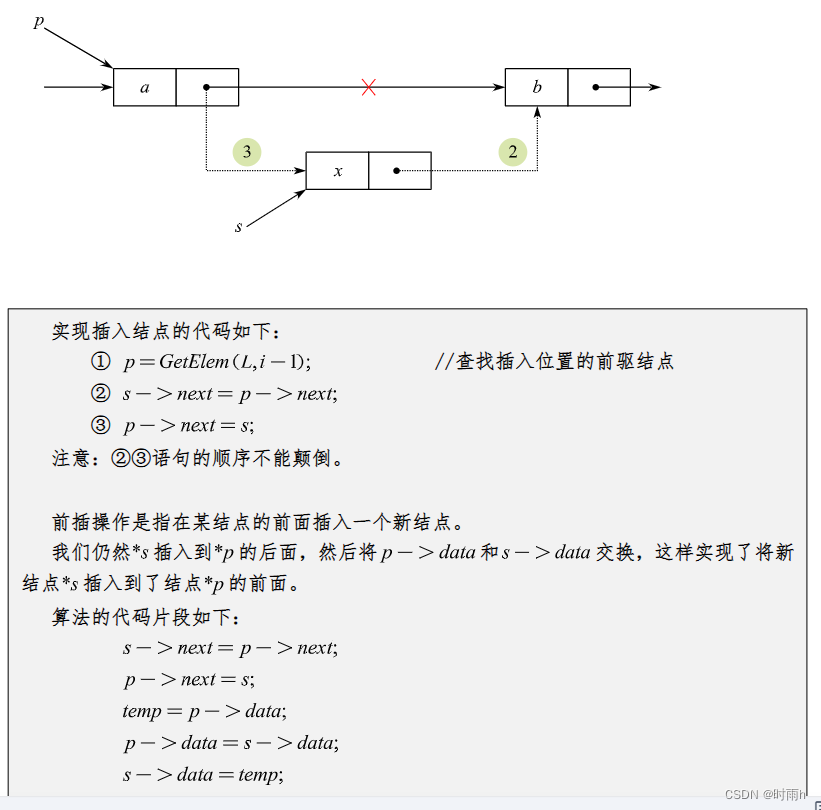
双链表

双链表(Doubly Linked List)是一种常见的数据结构,它与单链表相比,在每个节点中都有两个指针,分别指向前一个节点和后一个节点,因此可以实现双向遍历。这使得在双链表中插入、删除节点等操作更加高效。
下面是一个更详细的双链表的 C 代码实现:
#include <stdio.h>
#include <stdlib.h>// 双链表节点结构
typedef struct Node {int data;struct Node* prev;struct Node* next;
} Node;// 创建新节点
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node));if (newNode == NULL) {printf("内存分配失败\n");exit(1);}newNode->data = data;newNode->prev = NULL;newNode->next = NULL;return newNode;
}// 在链表头部插入节点
void insertFront(Node** head, int data) {Node* newNode = createNode(data);if (*head == NULL) {*head = newNode;} else {newNode->next = *head;(*head)->prev = newNode;*head = newNode;}
}// 在链表末尾插入节点
void insertEnd(Node** head, int data) {Node* newNode = createNode(data);if (*head == NULL) {*head = newNode;} else {Node* curr = *head;while (curr->next != NULL) {curr = curr->next;}curr->next = newNode;newNode->prev = curr;}
}// 在指定位置插入节点
void insertAt(Node** head, int data, int position) {if (position < 1) {printf("无效的位置\n");return;}if (position == 1) {insertFront(head, data);return;}Node* newNode = createNode(data);Node* curr = *head;int count = 1;while (count < position - 1 && curr != NULL) {curr = curr->next;count++;}if (curr == NULL) {printf("无效的位置\n");return;}newNode->next = curr->next;newNode->prev = curr;if (curr->next != NULL) {curr->next->prev = newNode;}curr->next = newNode;
}// 删除链表头部节点
void deleteFront(Node** head) {if (*head == NULL) {printf("链表为空\n");return;}Node* temp = *head;*head = (*head)->next;if (*head != NULL) {(*head)->prev = NULL;}free(temp);
}// 删除链表末尾节点
void deleteEnd(Node** head) {if (*head == NULL) {printf("链表为空\n");return;}Node* curr = *head;while (curr->next != NULL) {curr = curr->next;}if (curr->prev != NULL) {curr->prev->next = NULL;} else {*head = NULL;}free(curr);
}// 删除指定位置节点
void deleteAt(Node** head, int position) {if (*head == NULL || position < 1) {printf("无效的位置\n");return;}if (position == 1) {deleteFront(head);return;}Node* curr = *head;int count = 1;while (count < position && curr != NULL) {curr = curr->next;count++;}if (curr == NULL) {printf("无效的位置\n");return;}if (curr->prev != NULL) {curr->prev->next = curr->next;} else {*head = curr->next;}if (curr->next != NULL) {curr->next->prev = curr->prev;}free(curr);
}// 打印链表
void printList(Node* head) {Node* curr = head;while (curr != NULL) {printf("%d ", curr->data);curr = curr->next;}printf("\n");
}int main() {Node* head = NULL;// 插入节点insertFront(&head, 1);insertEnd(&head, 2);insertEnd(&head, 3);insertAt(&head, 4, 2);// 打印链表printf("双链表:");printList(head);// 删除节点deleteFront(&head);deleteEnd(&head);deleteAt(&head, 1);// 打印链表printf("删除节点后的双链表:");printList(head);return 0;
}
这段代码实现了双链表的创建节点、在链表头部、末尾和指定位置插入节点,以及删除链表头部、末尾和指定位置节点,并且可以打印链表。你可以根据自己的需求进行扩展和修改。
双链表的插入操作
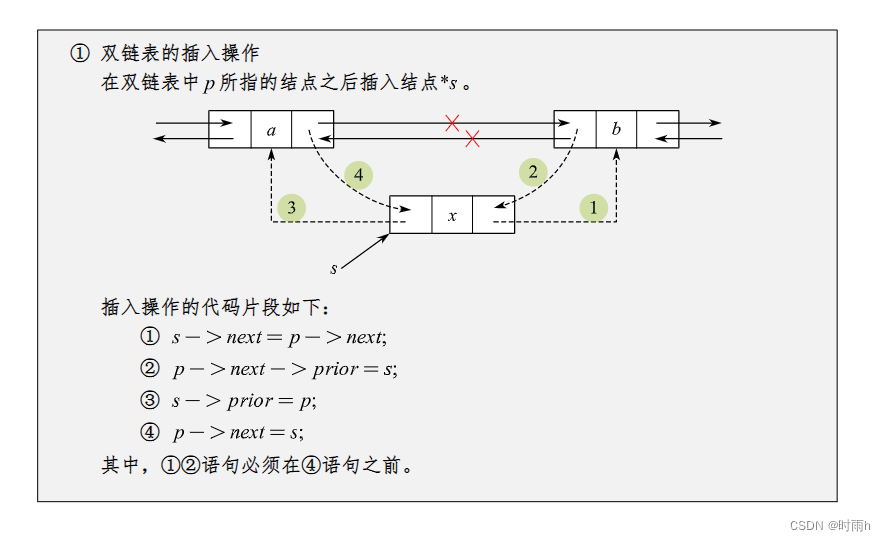
双链表的插入操作有三种情况:
- 在链表头部插入节点
- 在链表末尾插入节点
- 在指定位置插入节点
下面是这三种情况的详细说明和代码实现。
- 在链表头部插入节点
在链表头部插入节点,只需要将新节点插入到原头节点前面,并更新头节点的指针。
void insertFront(Node** head, int data) {Node* newNode = createNode(data);if (*head == NULL) {*head = newNode;} else {newNode->next = *head;(*head)->prev = newNode;*head = newNode;}
}
- 在链表末尾插入节点
在链表末尾插入节点,需要遍历整个链表,找到最后一个节点,并将新节点插入到最后一个节点后面。
void insertEnd(Node** head, int data) {Node* newNode = createNode(data);if (*head == NULL) {*head = newNode;} else {Node* curr = *head;while (curr->next != NULL) {curr = curr->next;}curr->next = newNode;newNode->prev = curr;}
}
- 在指定位置插入节点
在指定位置插入节点,需要遍历链表,找到指定位置的节点,并将新节点插入到该节点的前面,并更新相邻节点的指针。
void insertAt(Node** head, int data, int position) {if (position < 1) {printf("无效的位置\n");return;}if (position == 1) {insertFront(head, data);return;}Node* newNode = createNode(data);Node* curr = *head;int count = 1;while (count < position - 1 && curr != NULL) {curr = curr->next;count++;}if (curr == NULL) {printf("无效的位置\n");return;}newNode->next = curr->next;newNode->prev = curr;if (curr->next != NULL) {curr->next->prev = newNode;}curr->next = newNode;
}
注意,如果指定位置为1,则直接调用insertFront()函数插入节点。如果指定位置大于链表长度,则插入失败,输出错误信息。
上述代码中,createNode()函数创建一个新节点,Node** head表示指向头节点指针的指针,因为在插入操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
双链表的删除操作
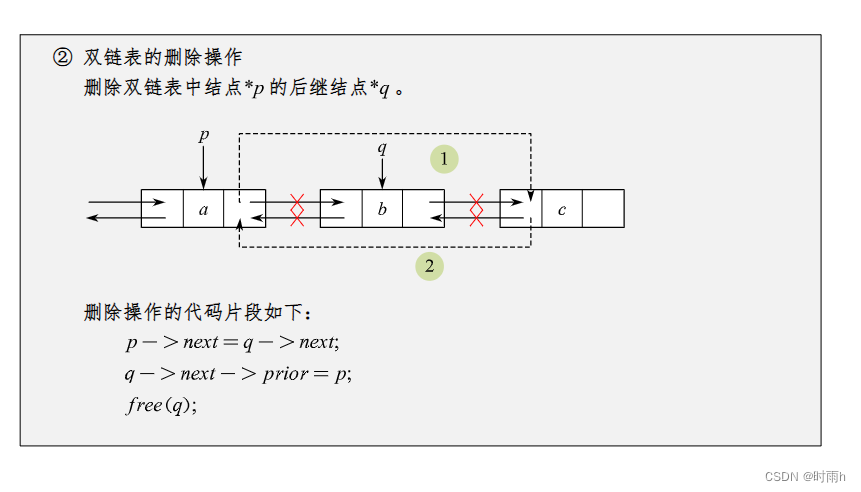
双链表的删除操作有三种情况:
- 删除链表头部节点
- 删除链表末尾节点
- 删除指定位置节点
下面是这三种情况的详细说明和代码实现。
- 删除链表头部节点
删除链表头部节点,只需要将头节点的下一个节点作为新的头节点,并释放原头节点的内存。
void deleteFront(Node** head) {if (*head == NULL) {printf("链表为空\n");return;}Node* temp = *head;*head = (*head)->next;if (*head != NULL) {(*head)->prev = NULL;}free(temp);
}
- 删除链表末尾节点
删除链表末尾节点,需要遍历整个链表,找到最后一个节点,并将倒数第二个节点的next指针置为NULL,并释放最后一个节点的内存。
void deleteEnd(Node** head) {if (*head == NULL) {printf("链表为空\n");return;}Node* curr = *head;while (curr->next != NULL) {curr = curr->next;}if (curr->prev != NULL) {curr->prev->next = NULL;} else {*head = NULL;}free(curr);
}
- 删除指定位置节点
删除指定位置节点,需要遍历链表,找到指定位置的节点,更新相邻节点的指针,并释放目标节点的内存。
void deleteAt(Node** head, int position) {if (*head == NULL || position < 1) {printf("无效的位置\n");return;}if (position == 1) {deleteFront(head);return;}Node* curr = *head;int count = 1;while (count < position && curr != NULL) {curr = curr->next;count++;}if (curr == NULL) {printf("无效的位置\n");return;}if (curr->prev != NULL) {curr->prev->next = curr->next;} else {*head = curr->next;}if (curr->next != NULL) {curr->next->prev = curr->prev;}free(curr);
}
注意,如果指定位置为1,则直接调用deleteFront()函数删除头部节点。如果指定位置大于链表长度,则删除失败,输出错误信息。
上述代码中,Node** head表示指向头节点指针的指针,因为在删除操作中需要修改头节点指针的值,而头节点指针本身是一个指针变量,所以需要使用指向指针的指针来实现修改。
循环链表
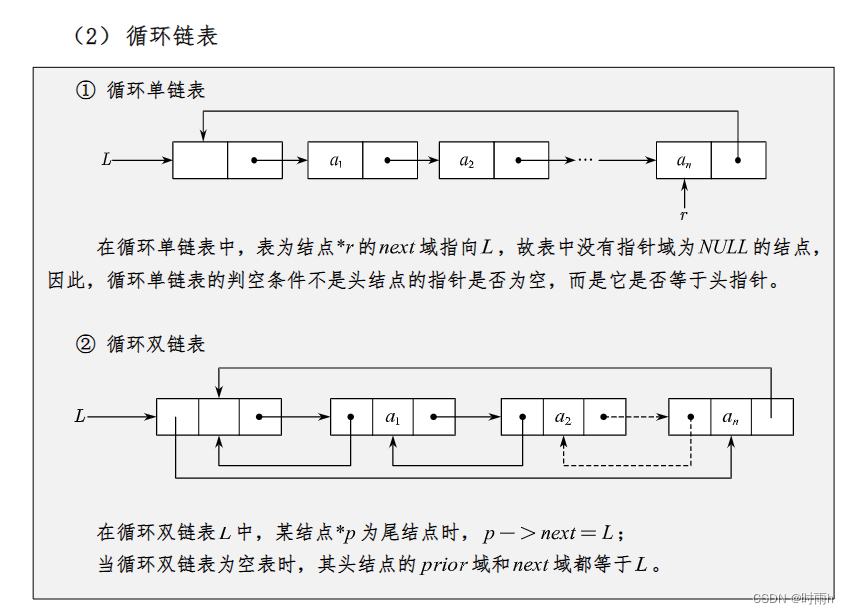
循环链表是一种特殊的链表,它与普通链表的区别在于,最后一个节点的next指针不是指向NULL,而是指向第一个节点,从而形成一个环形结构。
循环链表有两种基本类型:单向循环链表和双向循环链表。单向循环链表中每个节点只有一个指针域,即指向下一个节点的指针,而双向循环链表中每个节点有两个指针域,即分别指向前一个节点和后一个节点的指针。
下面是一个单向循环链表的定义:
typedef struct Node {int data;struct Node* next;
} Node;typedef struct CircularLinkedList {Node* head;
} CircularLinkedList;
在单向循环链表中,头节点的next指针指向第一个节点,而最后一个节点的next指针则指向头节点。
循环链表的插入和删除操作与普通链表类似,唯一的区别是在插入和删除末尾节点时需要特殊处理,因为末尾节点的next指针指向头节点而非NULL。
下面是一个简单的单向循环链表的插入和删除操作的示例代码:
// 创建新节点
Node* createNode(int data) {Node* newNode = (Node*)malloc(sizeof(Node));newNode->data = data;newNode->next = NULL;return newNode;
}// 在链表末尾插入节点
void insertEnd(CircularLinkedList* list, int data) {Node* newNode = createNode(data);if (list->head == NULL) {list->head = newNode;newNode->next = list->head;} else {Node* curr = list->head;while (curr->next != list->head) {curr = curr->next;}curr->next = newNode;newNode->next = list->head;}
}// 删除指定位置的节点
void deleteAt(CircularLinkedList* list, int position) {if (list->head == NULL) {printf("链表为空\n");return;}Node* curr = list->head;Node* prev = NULL;int count = 1;while (count < position && curr->next != list->head) {prev = curr;curr = curr->next;count++;}if (count < position) {printf("无效的位置\n");return;}if (prev == NULL) {Node* tail = list->head;while (tail->next != list->head) {tail = tail->next;}list->head = curr->next;tail->next = list->head;} else {prev->next = curr->next;}free(curr);
}
注意,上述代码中,在删除末尾节点时需要特判。如果目标节点是头节点,则需要更新头节点指针的值,并将最后一个节点的next指针指向新的头节点。如果目标节点不是头节点,则直接更新相邻节点的指针即可。
循环链表的遍历和其他操作与普通链表类似,只需要判断是否回到了头节点即可。
相关文章:
数据结构期末复习(2)链表
链表 链表(Linked List)是一种常见的数据结构,用于存储一系列具有相同类型的元素。链表由节点(Node)组成,每个节点包含两部分:数据域(存储元素值)和指针域(指…...
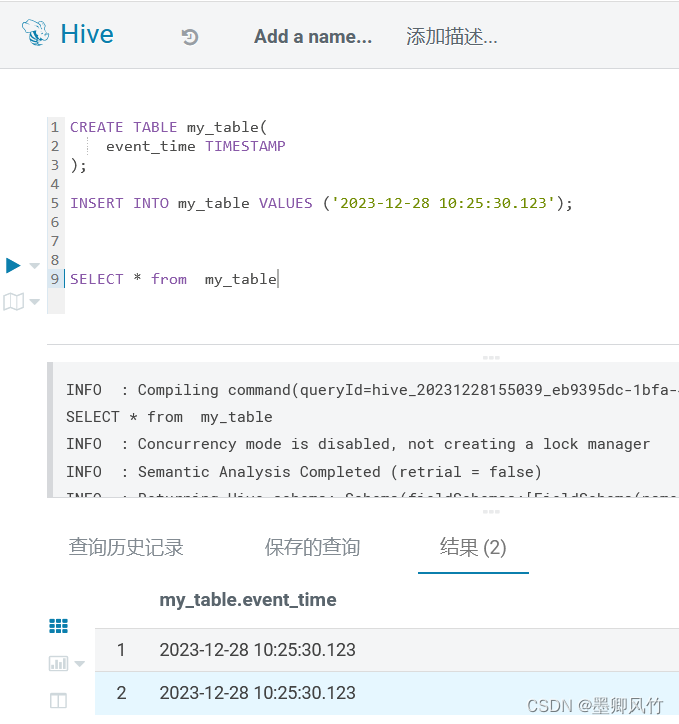
Hive中支持毫秒级别的时间精度
实际上,Hive 在较新的版本中已经支持毫秒级别的时间精度。你可以通过设置 hive.exec.default.serialization.format 和 mapred.output.value.format 属性为 1,启用 Hive 的时间精度为毫秒级。可以使用以下命令进行设置: set hive.exec.defau…...
【深度学习:Recurrent Neural Networks】循环神经网络(RNN)的简要概述
【深度学习】循环神经网络(RNN):连接过去与未来的桥梁 循环神经网络简介什么是循环神经网络 (RNN)?传统 RNN 的架构循环神经网络如何工作?常用激活函数RNN的优点和缺点RNN 的优点:RNN 的缺点: 循…...

HTML 基础
文章目录 01-标签语法标签结构 03-HTML骨架04-标签的关系05-注释06-标题标签07-段落标签08-换行和水平线09-文本格式化标签10-图像标签图像属性 11-路径相对路径绝对路径 12-超链接标签13-音频14-视频 01-标签语法 HTML 超文本标记语言——HyperText Markup Language。 超文本…...

大学物理II-作业1【题解】
1.【单选题】——考查高斯定理 下面关于高斯定理描述正确的是(D )。 A.高斯面上的电场强度是由高斯面内的电荷激发的 B.高斯面上的各点电场强度为零时,高斯面内一定没有电荷 C.通过高斯面的电通量为零时,高斯面上各点电场强度…...

Unity引擎有哪些优点
Unity引擎是一款跨平台的游戏引擎,拥有很多的优点,如跨平台支持、强大的工具和编辑器、灵活的脚本支持、丰富的资源库和强大的社区生态系统等,让他成为众多开发者选择的游戏开发引擎。下面我简单的介绍一下Unity引擎的优点。 跨平台支持 跨…...

【华为机试】2023年真题B卷(python)-猴子爬山
一、题目 题目描述: 一天一只顽猴想去从山脚爬到山顶,途中经过一个有个N个台阶的阶梯,但是这猴子有一个习惯: 每一次只能跳1步或跳3步,试问猴子通过这个阶梯有多少种不同的跳跃方式? 二、输入输出 输入描述…...

【Harmony OS - Stage应用模型】
基本概念 大类分为: Ability Module: 功能模块 、Library Module: 共享功能模块 编译时概念: Ability Module在编译时打包生成HAP(Harmony Ability Package),一个应用可能会有多个HAP…...

Java 8 中的 Stream 轻松遍历树形结构!
可能平常会遇到一些需求,比如构建菜单,构建树形结构,数据库一般就使用父id来表示,为了降低数据库的查询压力,我们可以使用Java8中的Stream流一次性把数据查出来,然后通过流式处理,我们一起来看看…...
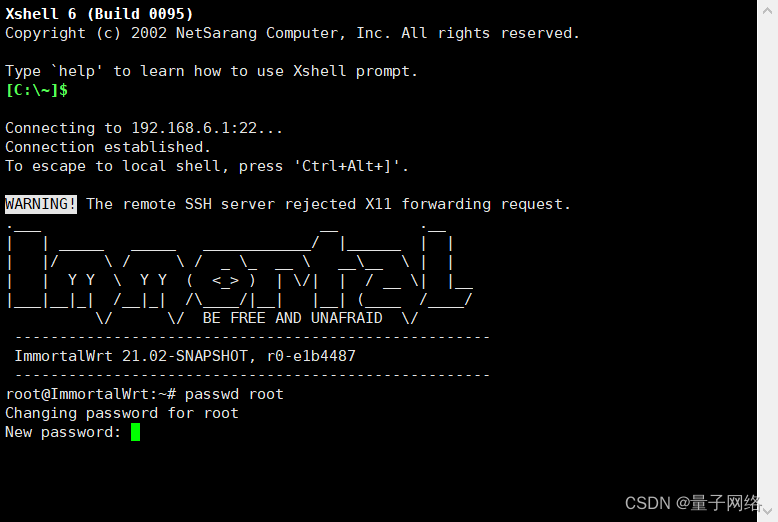
Openwrt修改Dropbear ssh root密码
使用ssh工具连接路由器 输入:passwd root 输入新密码 重复新密码 设置完成 rootImmortalWrt:~# passwd root Changing password for root New password:...

js 对象
js 对象定义 <!DOCTYPE html> <html> <body><h1>JavaScript 对象创建</h1><p id"demo1"></p> <p>new</p> <p id"demo"></p><script> // 创建对象: var persona {fi…...
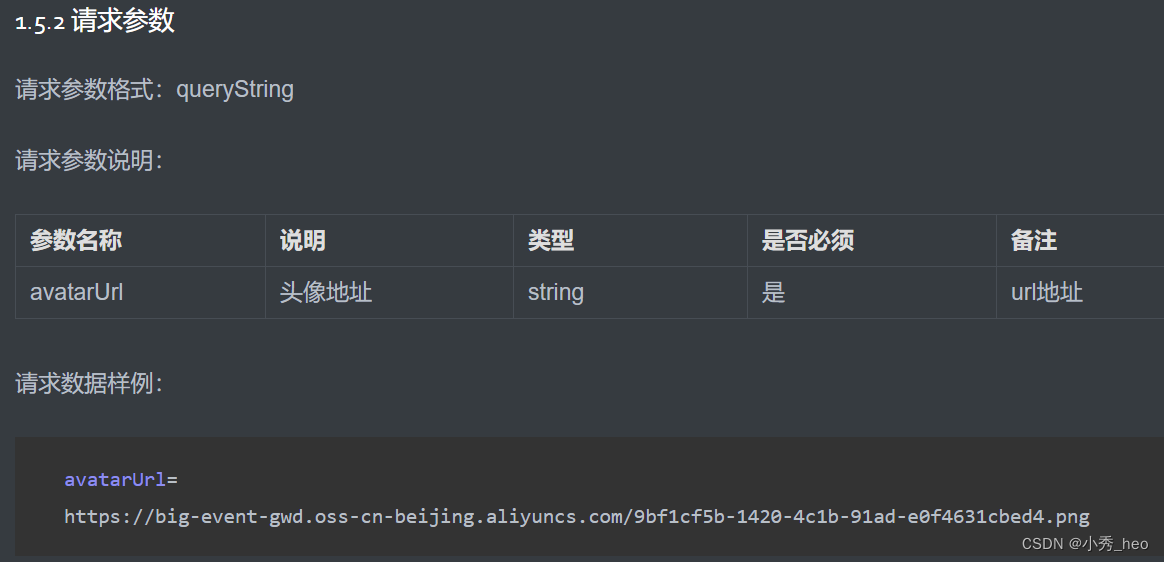
【SpringBoot】常用注解
RequestBody:自动将请求体中的 json 数据转换为实体类对象。 这个例子凑巧传入的json属性键名和User键名一致,可以直接使用User实体类对象,如果键名不一致则需要用一个Map 类接收参数: PutMapping("/update")public R…...
【模拟电路】软件Circuit JS
一、模拟电路软件Circuit JS 二、Circuit JS软件配置 三、Circuit JS 软件 常见的快捷键 四、Circuit JS软件基础使用 五、Circuit JS软件使用讲解 欧姆定律电阻的串联和并联电容器的充放电过程电感器和实现理想超导的概念电容阻止电压的突变,电感阻止电流的突变LR…...
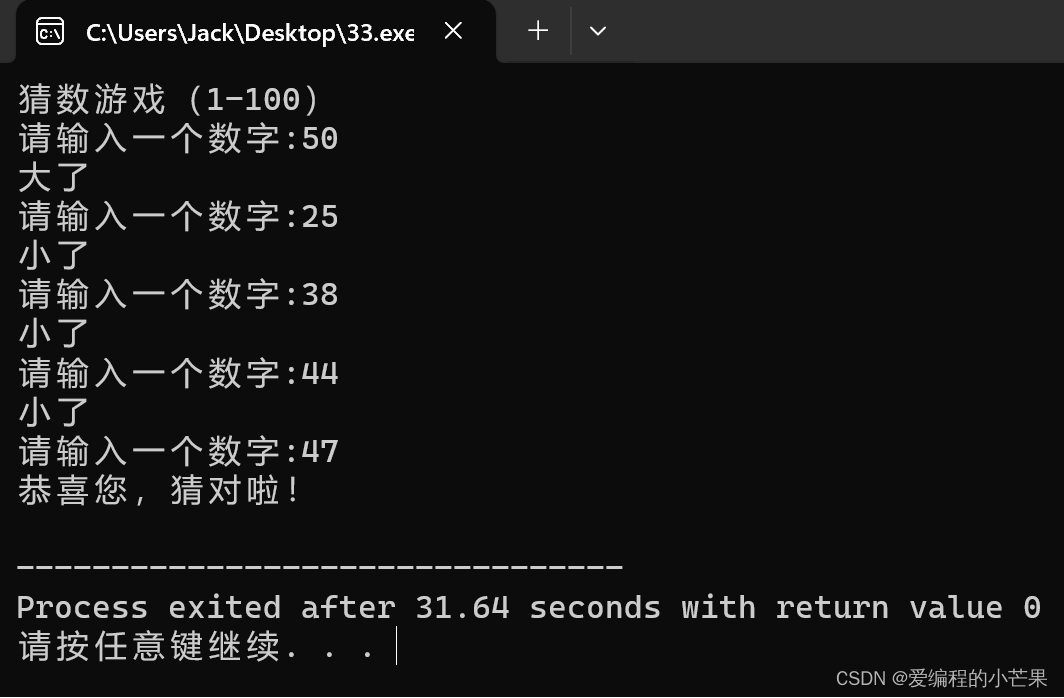
从入门到精通,30天带你学会C++【第十天:猜数游戏】
目录 Everyday English 前言 实战1——猜数游戏 综合指标 游玩方法 代码实现 最终代码 试玩时间 必胜策略 具体演示 结尾 Everyday English All good things come to those who wait. 时间不负有心人 前言 今天是2024年的第一天,新一年,新…...
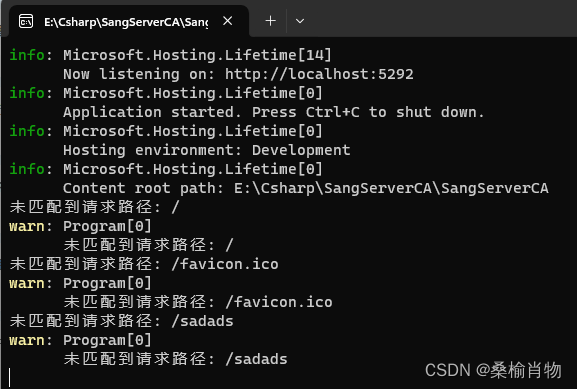
使用ASP.NET MiniAPI 调试未匹配请求路径
本文将介绍如何在使用ASP.NET MiniAPI时调试未匹配到的请求路径。我们将详细讨论使用MapFallback方法、中间件等工具来解决此类问题。 1. 引言 ASP.NET MiniAPI是一个轻量级的Web API框架,它可以让我们快速地构建和部署RESTful服务。然而,在开发过程中如…...

数据结构: 位图
位图 概念 用一个bit为来标识数据在不在 功能 节省空间快速查找一个数在不在一个集合中排序 去重求两个集合的交集,并集操作系统中的磁盘标记 简单实现 1.设计思想:一个bit位标识一个数据, 使用char(8bit位)集合来模拟 2.预备工作:a.计算这个数在第几个char b.是这个ch…...
Nginx 反向代理负载均衡
Nginx 反向代理负载均衡 普通的负载均衡软件,如 LVS,其实现的功能只是对请求数据包的转发、传递,从负载均衡下的节点服务器来看,接收到的请求还是来自访问负载均衡器的客户端的真实用户;而反向代理就不一样了…...

SAP FIORI 初步了解
1、对网上存在的部分资料进行收集 一套适合 SAP UI5 开发人员循序渐进的学习教程 SAP Fiori 的学习路线指南 如何根据角色批量激活SAP Fiori服务 关于S/4和Fiori,你必须知道的10件事 SAP Fiori开发教程 SAP FIORI教程 面向ABAP开发人员,SAPUI5 Fiori开发…...
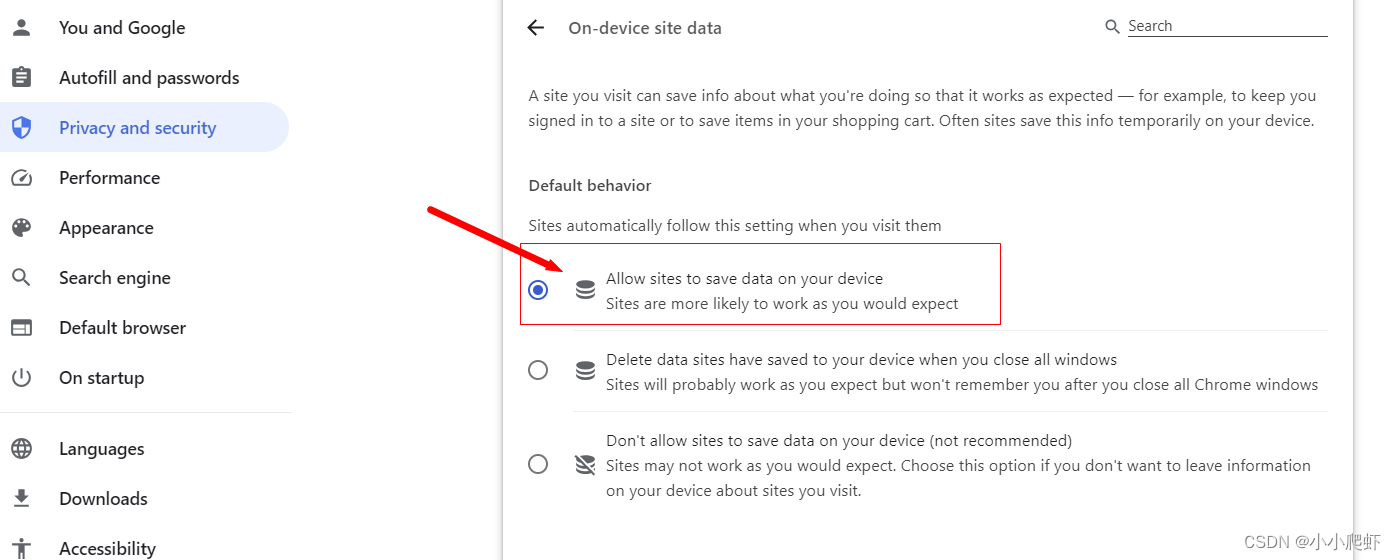
chrome浏览器记录不住网站登录状态,退出后再打开就需要重新登陆的解决办法
chrome浏览器记录不住网站登录状态,退出后再打开就需要重新登陆,比较繁琐。 解决办法: 1、chrome浏览器右上角三个竖的点,然后进入“设置”(Settings),选择“隐私与安全”(Privacy…...
)
Linux lpd命令教程:打印服务管理技巧全解析(附实例教程和注意事项)
Linux lpd命令介绍 lpd是Linux操作系统中的一个命令,全称为line printer daemon,其主要职责是管理和控制打印任务。lpd可以接收打印任务请求并将这些请求放入打印任务队列中。当打印机空闲时,lpd会自动将任务队列中的打印请求发送给打印机以…...

Qt/C++开发监控GB28181系统/取流协议/同时支持udp/tcp被动/tcp主动
一、前言说明 在2011版本的gb28181协议中,拉取视频流只要求udp方式,从2016开始要求新增支持tcp被动和tcp主动两种方式,udp理论上会丢包的,所以实际使用过程可能会出现画面花屏的情况,而tcp肯定不丢包,起码…...

如何在看板中体现优先级变化
在看板中有效体现优先级变化的关键措施包括:采用颜色或标签标识优先级、设置任务排序规则、使用独立的优先级列或泳道、结合自动化规则同步优先级变化、建立定期的优先级审查流程。其中,设置任务排序规则尤其重要,因为它让看板视觉上直观地体…...

(二)原型模式
原型的功能是将一个已经存在的对象作为源目标,其余对象都是通过这个源目标创建。发挥复制的作用就是原型模式的核心思想。 一、源型模式的定义 原型模式是指第二次创建对象可以通过复制已经存在的原型对象来实现,忽略对象创建过程中的其它细节。 📌 核心特点: 避免重复初…...

第一篇:Agent2Agent (A2A) 协议——协作式人工智能的黎明
AI 领域的快速发展正在催生一个新时代,智能代理(agents)不再是孤立的个体,而是能够像一个数字团队一样协作。然而,当前 AI 生态系统的碎片化阻碍了这一愿景的实现,导致了“AI 巴别塔问题”——不同代理之间…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

Rust 异步编程
Rust 异步编程 引言 Rust 是一种系统编程语言,以其高性能、安全性以及零成本抽象而著称。在多核处理器成为主流的今天,异步编程成为了一种提高应用性能、优化资源利用的有效手段。本文将深入探讨 Rust 异步编程的核心概念、常用库以及最佳实践。 异步编程基础 什么是异步…...

Axios请求超时重发机制
Axios 超时重新请求实现方案 在 Axios 中实现超时重新请求可以通过以下几种方式: 1. 使用拦截器实现自动重试 import axios from axios;// 创建axios实例 const instance axios.create();// 设置超时时间 instance.defaults.timeout 5000;// 最大重试次数 cons…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

HarmonyOS运动开发:如何用mpchart绘制运动配速图表
##鸿蒙核心技术##运动开发##Sensor Service Kit(传感器服务)# 前言 在运动类应用中,运动数据的可视化是提升用户体验的重要环节。通过直观的图表展示运动过程中的关键数据,如配速、距离、卡路里消耗等,用户可以更清晰…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...