PyTorch中常用的工具(5)使用GPU加速:CUDA
文章目录
- 前言
- 4 使用GPU加速:CUDA
- 5 小结
前言
在训练神经网络的过程中需要用到很多的工具,最重要的是数据处理、可视化和GPU加速。本章主要介绍PyTorch在这些方面常用的工具模块,合理使用这些工具可以极大地提高编程效率。
由于内容较多,本文分成了五篇文章(1)数据处理(2)预训练模型(3)TensorBoard(4)Visdom(5)CUDA与小结。
整体结构如下:
- 1 数据处理
- 1.1 Dataset
- 1.2 DataLoader
- 2 预训练模型
- 3 可视化工具
- 3.1 TensorBoard
- 3.2 Visdom
- 4 使用GPU加速:CUDA
- 5 小结
全文链接:
- PyTorch中常用的工具(1)数据处理
- PyTorch常用工具(2)预训练模型
- PyTorch中常用的工具(3)TensorBoard
- PyTorch中常用的工具(4)Visdom
- PyTorch中常用的工具(5)使用GPU加速:CUDA
4 使用GPU加速:CUDA
这部分内容在前面介绍Tensor、nn.Module时已经有所涉及,这里做一个总结,并深入介绍它的相关应用。
在PyTorch中以下数据结构分为CPU和GPU两个版本。
Tensor。nn.Module(包括常用的layer、损失函数以及容器Sequential等)。
这些数据结构都带有一个.cuda方法,调用该方法可以将它们转为对应的GPU对象。注意,tensor.cuda会返回一个新对象,这个新对象的数据已经转移到GPU,之前的Tensor还在原来的设备上(CPU)。module.cuda会将所有的数据都迁移至GPU,并返回自己。所以module = module.cuda()和module.cuda()效果一致。
除了.cuda方法,它们还支持.to(device)方法,通过该方法可以灵活地转换它们的设备类型,同时这种方法也更加适合编写设备兼容的代码,这部分内容将在后文详细介绍。
nn.Module在GPU与CPU之间的转换,本质上还是利用了Tensor在GPU和CPU之间的转换。nn.Module的.cuda方法是将nn.Module下的所有参数(包括子module的参数)都转移至GPU,而参数本质上也是Tensor。
下面对.cuda方法举例说明,这部分代码需要读者具有两块GPU设备。
注意:为什么将数据转移至GPU的方法叫做.cuda而不是.gpu,就像将数据转移至CPU调用的方法是.cpu呢?这是因为GPU的编程接口采用CUDA,而目前不是所有的GPU都支持CUDA,只有部分NVIDIA的GPU才支持。PyTorch1.8目前已经支持AMD GPU,并提供了基于ROCm平台的GPU加速,感兴趣的读者可以自行查询相关文档。
In: tensor = t.Tensor(3, 4)# 返回一个新的Tensor,保存在第1块GPU上,原来的Tensor并没有改变tensor.cuda(0)tensor.is_cuda # False
Out: False
In: # 不指定所使用的GPU设备,默认使用第1块GPUtensor = tensor.cuda()tensor.is_cuda # True
Out: True
In: module = nn.Linear(3, 4)module.cuda(device = 1)module.weight.is_cuda # True
Out: True
In: # 使用.to方法,将Tensor转移至第1块GPU上tensor = t.Tensor(3, 4).to('cuda:0')tensor.is_cuda
Out: True
In: class VeryBigModule(nn.Module):def __init__(self):super().__init__()self.GiantParameter1 = t.nn.Parameter(t.randn(100000, 20000)).to('cuda:0')self.GiantParameter2 = t.nn.Parameter(t.randn(20000, 100000)).to('cuda:1')def forward(self, x):x = self.GiantParameter1.mm(x.cuda(0))x = self.GiantParameter2.mm(x.cuda(1))return x
在最后一段代码中,两个Parameter所占用的内存空间都非常大,大约是8GB。如果将这两个Parameter同时放在一块显存较小的GPU上,那么显存将几乎被占满,无法再进行任何其他运算。此时可以通过.to(device_i)将不同的计算划分到不同的GPU中。
下面是在使用GPU时的一些建议。
- GPU运算很快,但对于很小的运算量来说,它的优势无法被体现。因此,对于一些简单的操作可以直接利用CPU完成。
- 数据在CPU和GPU之间的传递比较耗时,应当尽量避免。
- 在进行低精度的计算时,可以考虑使用HalfTensor,它相比于FloatTensor可以节省一半的显存,但是需要注意数值溢出的情况。
注意:大部分的损失函数都属于nn.Module,在使用GPU时,用户经常会忘记使用它的.cuda方法,这在大多数情况下不会报错,因为损失函数本身没有可学习参数(learnable parameters),但在某些情况下会出现问题。为了保险起见,同时也为了代码更加规范,用户应记得调用criterion.cuda,下面举例说明:
In: # 交叉熵损失函数,带权重criterion = t.nn.CrossEntropyLoss(weight=t.Tensor([1, 3]))input = t.randn(4, 2).cuda()target = t.Tensor([1, 0, 0, 1]).long().cuda()# 下面这行会报错,因weight未被转移至GPU# loss = criterion(input, target)# 下面的代码则不会报错criterion.cuda()loss = criterion(input, target)criterion._buffers
Out: OrderedDict([('weight', tensor([1., 3.], device='cuda:0'))])
除了调用对象的.cuda方法,还可以使用torch.cuda.device指定默认使用哪一块GPU,或使用torch.set_default_tensor_type让程序默认使用GPU,不需要手动调用.cuda方法:
In: # 如果未指定使用哪块GPU,则默认使用GPU 0x = t.cuda.FloatTensor(2, 3)# x.get_device() == 0y = t.FloatTensor(2, 3).cuda()# y.get_device() == 0# 指定默认使用GPU 1with t.cuda.device(1): # 在GPU 1上构建Tensora = t.cuda.FloatTensor(2, 3)# 将Tensor转移至GPU 1b = t.FloatTensor(2, 3).cuda()assert a.get_device() == b.get_device() == 1c = a + bassert c.get_device() == 1z = x + yassert z.get_device() == 0# 手动指定使用GPU 0d = t.randn(2, 3).cuda(0)assert d.get_device() == 0
In: t.set_default_tensor_type('torch.cuda.FloatTensor') # 指定默认Tensor的类型为GPU上的FloatTensora = t.ones(2, 3)a.is_cuda
Out: True
如果服务器具有多个GPU,那么tensor.cuda()方法会将Tensor保存到第一块GPU上,等价于tensor.cuda(0)。如果想要使用第二块GPU,那么需要手动指定tensor.cuda(1),这需要修改大量代码,较为烦琐。这里有以下两种替代方法。
-
先调用
torch.cuda.set_device(1)指定使用第二块GPU,后续的.cuda()都无需更改,切换GPU只需修改这一行代码。 -
设置环境变量
CUDA_VISIBLE_DEVICES,例如export CUDA_VISIBLE_DEVICE=1(下标从0开始,1代表第二块物理GPU),代表着只使用第2块物理GPU,但在程序中这块GPU会被看成是第1块逻辑GPU,此时调用tensor.cuda()会将Tensor转移至第二块物理GPU。CUDA_VISIBLE_DEVICES还可以指定多个GPU,例如export CUDA_VISIBLE_DEVICES=0,2,3,第1、3、4块物理GPU会被映射为第1、2、3块逻辑GPU,此时tensor.cuda(1)会将Tensor转移到第三块物理GPU上。
设置CUDA_VISIBLE_DEVICES有两种方法,一种是在命令行中执行CUDA_VISIBLE_DEVICES=0,1 python main.py,一种是在程序中编写import os;os.environ["CUDA_VISIBLE_DEVICES"] = "2"。如果使用IPython或者Jupyter notebook,那么还可以使用%env CUDA_VISIBLE_DEVICES=1,2设置环境变量。
基于PyTorch本身的机制,用户可能需要编写设备兼容(device-agnostic)的代码,以适应不同的计算环境。在第3章中已经介绍到,可以通过Tensor的device属性指定它加载的设备,同时利用to方法可以很方便地将不同变量加载到不同的设备上。然而,如果要保证同样的代码在不同配置的机器上均能运行,那么编写设备兼容的代码是至关重要的,本节将详细介绍如何编写设备兼容的代码。
首先介绍一下如何指定Tensor加载的设备,这一操作往往通过torch.device()实现,其中device类型包含cpu与cuda,下面举例说明:
In: # 指定设备,使用CPUt.device('cpu')# 另外一种写法:t.device('cpu',0)
Out: device(type='cpu')
In: # 指定设备,使用第1块GPUt.device('cuda:0')# 另外一种写法:t.device('cuda',0)
Out: device(type='cuda', index=0)
In: # 更加推荐的做法(同时也是设备兼容的):如果用户具有GPU设备,那么使用GPU,否则使用CPUdevice = t.device("cuda" if t.cuda.is_available() else "cpu")print(device)
Out: cuda
In: # 在确定了设备之后,可以将数据与模型利用to方法加载到指定的设备上。x = t.empty((2,3)).to(device)x.device
Out: device(type='cuda', index=0)
对于最常见的数据结构Tensor,它封装好的大部分操作也支持指定加载的设备。当拥有加载在一个设备上的Tensor时,通过torch.Tensor.new_*以及torch.*_like操作可以创建与该Tensor相同类型、相同设备的Tensor,举例说明如下:
In: x_cpu = t.empty(2, device='cpu')print(x_cpu, x_cpu.is_cuda)x_gpu = t.empty(2, device=device)print(x_gpu, x_gpu.is_cuda)
Out: tensor([-3.6448e+08, 4.5873e-41]) Falsetensor([0., 0.], device='cuda:0') True
In: # 使用new_*操作会保留原Tensor的设备属性y_cpu = x_cpu.new_full((3,4), 3.1415)print(y_cpu, y_cpu.is_cuda)y_gpu = x_gpu.new_zeros(3,4)print(y_gpu, y_gpu.is_cuda)
Out: tensor([[3.1415, 3.1415, 3.1415, 3.1415],[3.1415, 3.1415, 3.1415, 3.1415],[3.1415, 3.1415, 3.1415, 3.1415]]) Falsetensor([[0., 0., 0., 0.],[0., 0., 0., 0.],[0., 0., 0., 0.]], device='cuda:0') True
In: # 使用ones_like或zeros_like可以创建与原Tensor大小类别均相同的新Tensorz_cpu = t.ones_like(x_cpu)print(z_cpu, z_cpu.is_cuda)z_gpu = t.zeros_like(x_gpu)print(z_gpu, z_gpu.is_cuda)
Out: tensor([1., 1.]) Falsetensor([0., 0.], device='cuda:0') True
在一些实际应用场景下,代码的可移植性是十分重要的,读者可根据上述内容继续深入学习,在不同场景中灵活运用PyTorch的不同特性编写代码,以适应不同环境的工程需要。
本节主要介绍了如何使用GPU对计算进行加速,同时介绍了如何编写设备兼容的PyTorch代码。在实际应用场景中,仅仅使用CPU或一块GPU是很难满足网络的训练需求的,因此能否使用多块GPU来加速训练呢?
答案是肯定的。自PyTorch 0.2版本后,PyTorch新增了分布式GPU支持。分布式是指有多个GPU在多台服务器上,并行一般指一台服务器上的多个GPU。分布式涉及到了服务器之间的通信,因此比较复杂。幸运的是,PyTorch封装了相应的接口,可以用简单的几行代码实现分布式训练。在训练数据集较大或者网络模型较为复杂时,合理地利用分布式与并行可以加快网络的训练。关于分布式与并行的更多内容将在本书第7章进行详细的介绍。
5 小结
本章介绍了一些工具模块,这些工具有的已经封装在PyTorch之中,有的是独立于PyTorch的第三方模块。这些模块主要涉及数据加载、可视化与GPU加速的相关内容,合理使用这些模块能够极大地提升编程效率。
3,4)
print(y_gpu, y_gpu.is_cuda)
Out: tensor([[3.1415, 3.1415, 3.1415, 3.1415],
[3.1415, 3.1415, 3.1415, 3.1415],
[3.1415, 3.1415, 3.1415, 3.1415]]) False
tensor([[0., 0., 0., 0.],
[0., 0., 0., 0.],
[0., 0., 0., 0.]], device=‘cuda:0’) True
```python
In: # 使用ones_like或zeros_like可以创建与原Tensor大小类别均相同的新Tensorz_cpu = t.ones_like(x_cpu)print(z_cpu, z_cpu.is_cuda)z_gpu = t.zeros_like(x_gpu)print(z_gpu, z_gpu.is_cuda)
Out: tensor([1., 1.]) Falsetensor([0., 0.], device='cuda:0') True
在一些实际应用场景下,代码的可移植性是十分重要的,读者可根据上述内容继续深入学习,在不同场景中灵活运用PyTorch的不同特性编写代码,以适应不同环境的工程需要。
本节主要介绍了如何使用GPU对计算进行加速,同时介绍了如何编写设备兼容的PyTorch代码。在实际应用场景中,仅仅使用CPU或一块GPU是很难满足网络的训练需求的,因此能否使用多块GPU来加速训练呢?
答案是肯定的。自PyTorch 0.2版本后,PyTorch新增了分布式GPU支持。分布式是指有多个GPU在多台服务器上,并行一般指一台服务器上的多个GPU。分布式涉及到了服务器之间的通信,因此比较复杂。幸运的是,PyTorch封装了相应的接口,可以用简单的几行代码实现分布式训练。在训练数据集较大或者网络模型较为复杂时,合理地利用分布式与并行可以加快网络的训练。关于分布式与并行的更多内容将在本书第7章进行详细的介绍。
相关文章:
使用GPU加速:CUDA)
PyTorch中常用的工具(5)使用GPU加速:CUDA
文章目录 前言4 使用GPU加速:CUDA5 小结 前言 在训练神经网络的过程中需要用到很多的工具,最重要的是数据处理、可视化和GPU加速。本章主要介绍PyTorch在这些方面常用的工具模块,合理使用这些工具可以极大地提高编程效率。 由于内容较多&am…...

Qt+opencv 视频分解为图片
最近遇到一些售前提供的BUG,但是他们提供的是录像视频,因为处理显示速度比较快,因此很难找到出现问题的位置。需要反复播放,自己编写了一个视频分解成图片这样就可以一张图一张图的对比,方便查看。 开发环境 qtopenv…...

一篇文章认识微服务的优缺点和微服务技术栈
目录 1、微服务 2、微服务架构 3、微服务优缺点 3.1 优点 3.2 缺点 4、微服务技术栈 1、微服务 微服务化的核心就是将传统的一站式应用,根据业务拆分成一个一个的服务,彻底地去耦合,每一个微服务提供单个业务功能的服务,一…...

[spark] dataframe的数据导入Mysql5.6
在 Spark 项目中使用 Scala 连接 MySQL 5.6 并将 DataFrame 中的数据保存到 MySQL 中的步骤如下: 添加 MySQL 连接驱动依赖: 在 Spark 项目中,你需要在项目的构建工具中添加 MySQL 连接驱动的依赖。 如果使用 Maven,可以在 pom.xm…...
2023年度业务风险报告:四个新风险趋势
目录 倒票的黄牛愈加疯狂 暴增的恶意网络爬虫 愈加猖獗的羊毛党 层出不穷的新风险 业务风险呈现四个趋势 防御云业务安全情报中心“2023年业务风险数据”统计显示,恶意爬虫风险最多,占总数的37.8%;其次是虚假账号注册,占18.79%&am…...
python编程从入门到实践(1)
文章目录 2.2.1命名的说明2.3字符串2.3.1使用方法修改字符串的大小写2.3.2 在字符串中使用变量2.3.3 制表符 和 换行符2.5.4删除空白2.5.5 删除前缀+后缀 2.2.1命名的说明 只能包含:字母,下划线,数字 必须:字母&#…...
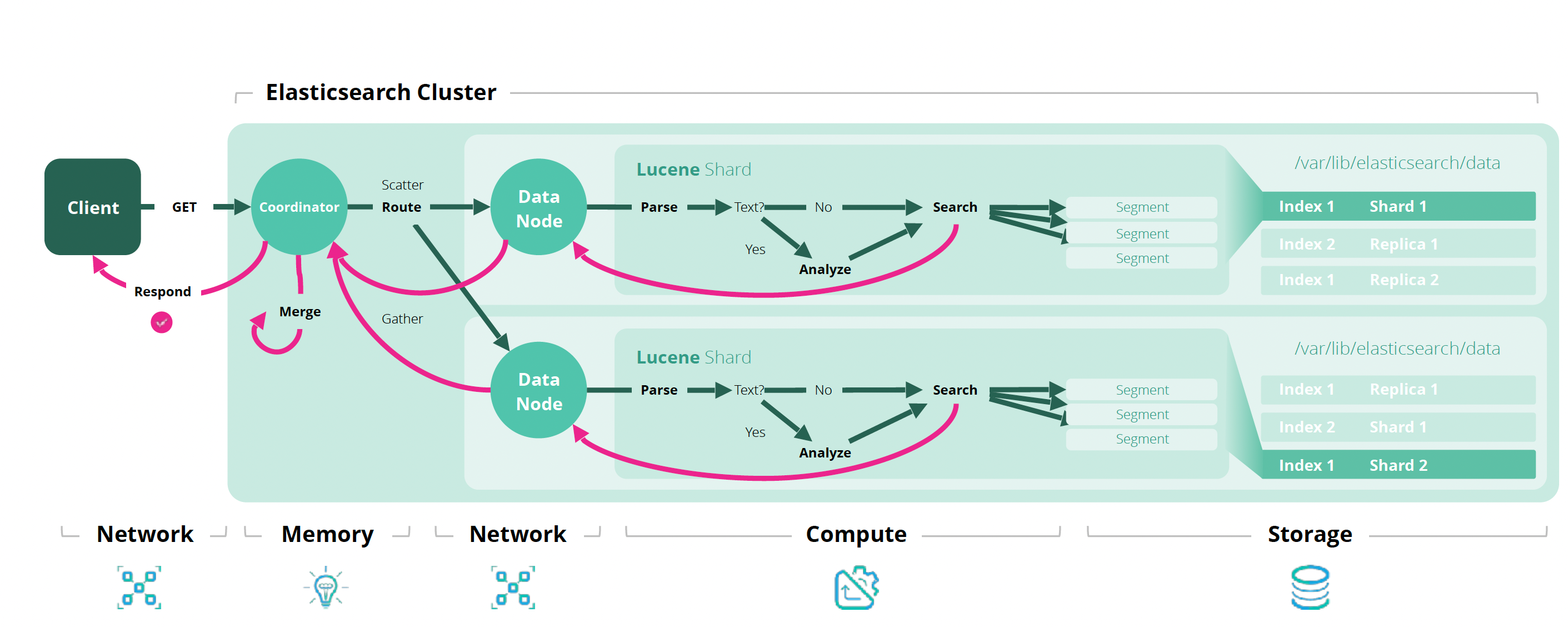
ElasticSearch 文档操作
创建文档 指定id // 无则插入,有则覆盖(覆盖的逻辑是先删除,再插入) PUT /<target>/_doc/<_id> // 无则插入,有则覆盖 POST /<target>/_doc/<_id> // 无则插入,有则报错 PUT /&l…...
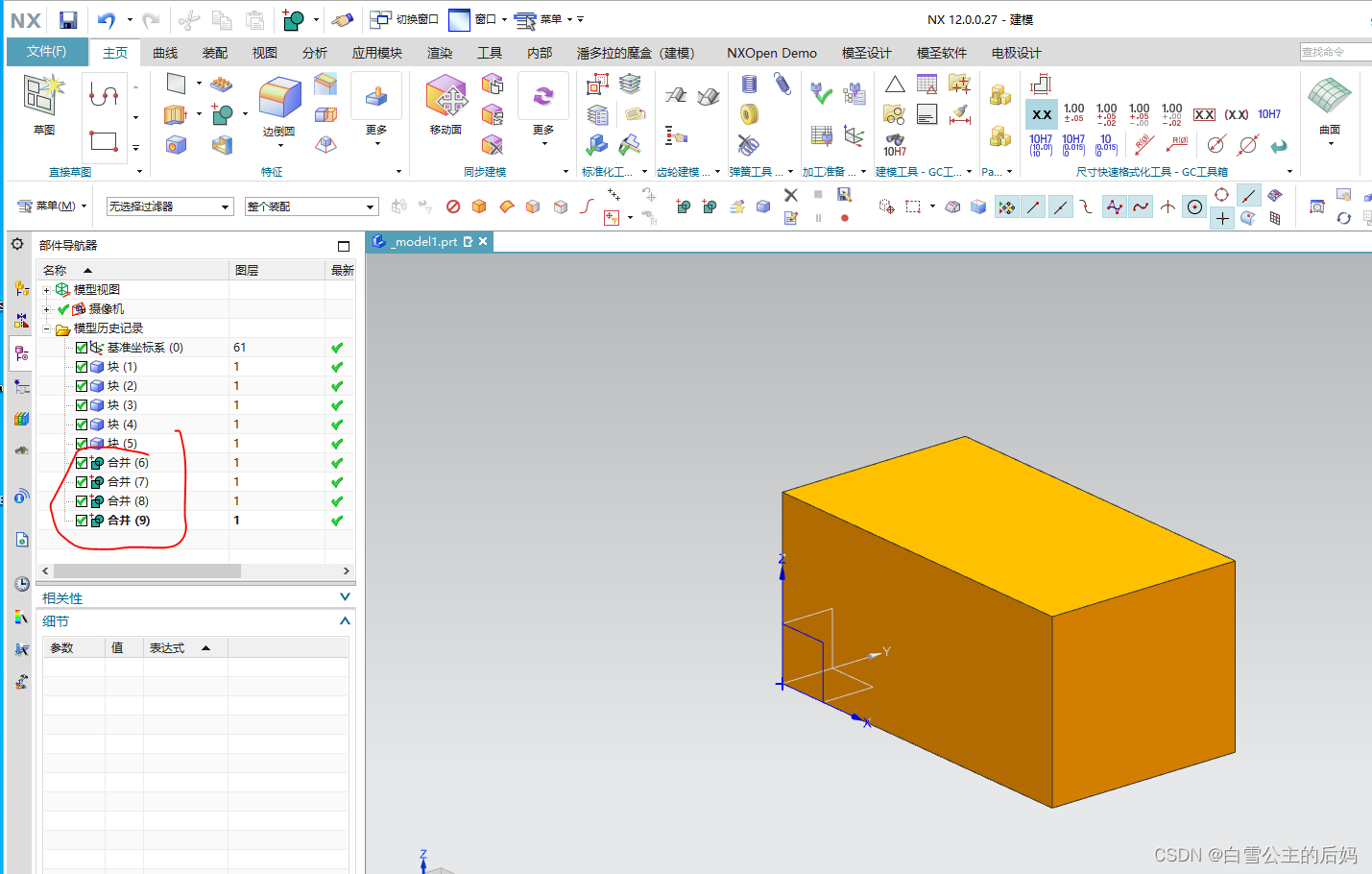
NXOpenC++布尔求和命令
一、概述 在进行批量布尔求和时,采用NXOpenC的方式要比UFun的方式美观的多,个人认为,ufun中UF_MODL_unite_bodies函数采用的是两两进行合并,显示多个步骤,而NXOpenC采用的是一个工具体和多个目标体进行合并,…...
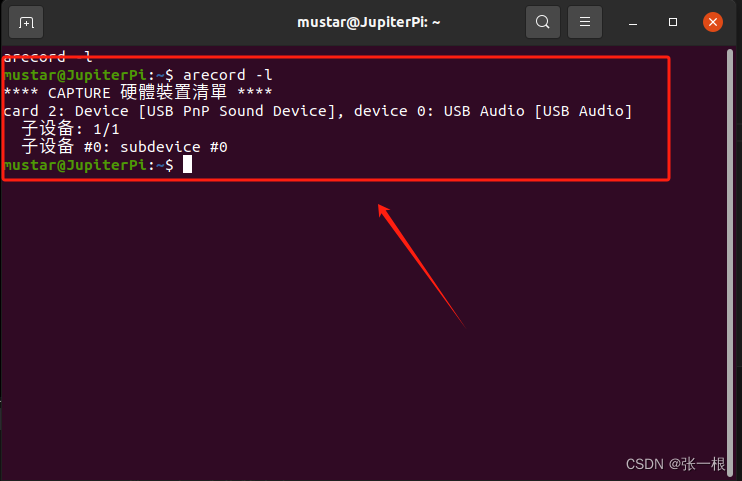
ubuntu python播放MP3,wav音频和录音
目录 一.利用pygame(略显麻烦,有时候播放不太正常)1.安装依赖库2.代码 二.利用mpg123(简洁方便,但仅争对mp3)1.安装依赖库2.代码 三.利用sox(简单方便,支持的文件格式多)…...

Rust学习笔记000 安装
安装命令 curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh $ curl --proto https --tlsv1.2 -sSf https://sh.rustup.rs | sh info: downloading installerWelcome to Rust!This will download and install the official compiler for the Rust programming la…...

python AI五子棋对战
我写过一篇c++五子棋 c++五子棋代码-CSDN博客 现在又写了python import copy import time from enum import IntEnum import pygame from pygame.locals import *time = time.strftime("%Y-%m-%d %H:%M:%S") version = str(time)# 基础参数设置 square_size = 40 …...

图文证明 费马,罗尔,拉格朗日,柯西
图文证明 罗尔,拉格朗日,柯西 费马引理和罗尔都比较好证,不过多阐述,看图即可: 费马引理: 罗尔定理: 重点来证明拉格朗日和柯西 拉格朗日: 我认为不需要去看l(x)的那一行更好推: 详细的推理过程: 构造 h ( x ) f ( x ) − l ( x ) , 因为 a , b 两点为交点 , f ( a ) l ( …...
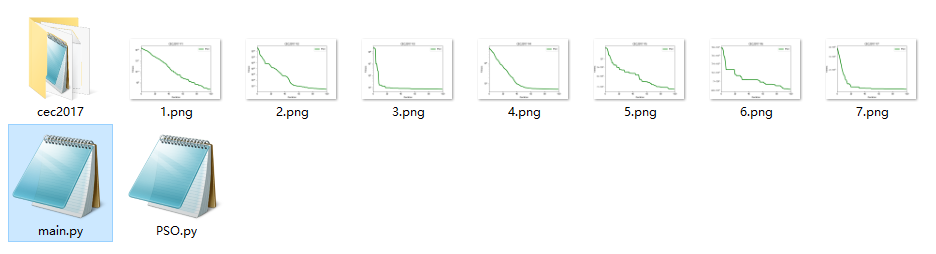
CEC2017(Python):粒子群优化算法PSO求解CEC2017(提供Python代码)
一、CEC2017简介 参考文献: [1]Awad, N. H., Ali, M. Z., Liang, J. J., Qu, B. Y., & Suganthan, P. N. (2016). “Problem definitions and evaluation criteria for the CEC2017 special session and competition on single objective real-parameter numer…...
(一))
AUTOSAR从入门到精通- 虚拟功能总线(RTE)(一)
目录 前言 几个高频面试题目 RTE S/R接口implicit与Explicit的实现与区别 接口的代码 implicit...

B/S架构云端SaaS服务的医院云HIS系统源码,自主研发,支持电子病历4级
医院云HIS系统源码,自主研发,自主版权,电子病历病历4级 系统概述: 一款满足基层医院各类业务需要的云HIS系统。该系统能帮助基层医院完成日常各类业务,提供病患挂号支持、病患问诊、电子病历、开药发药、会员管理、统…...
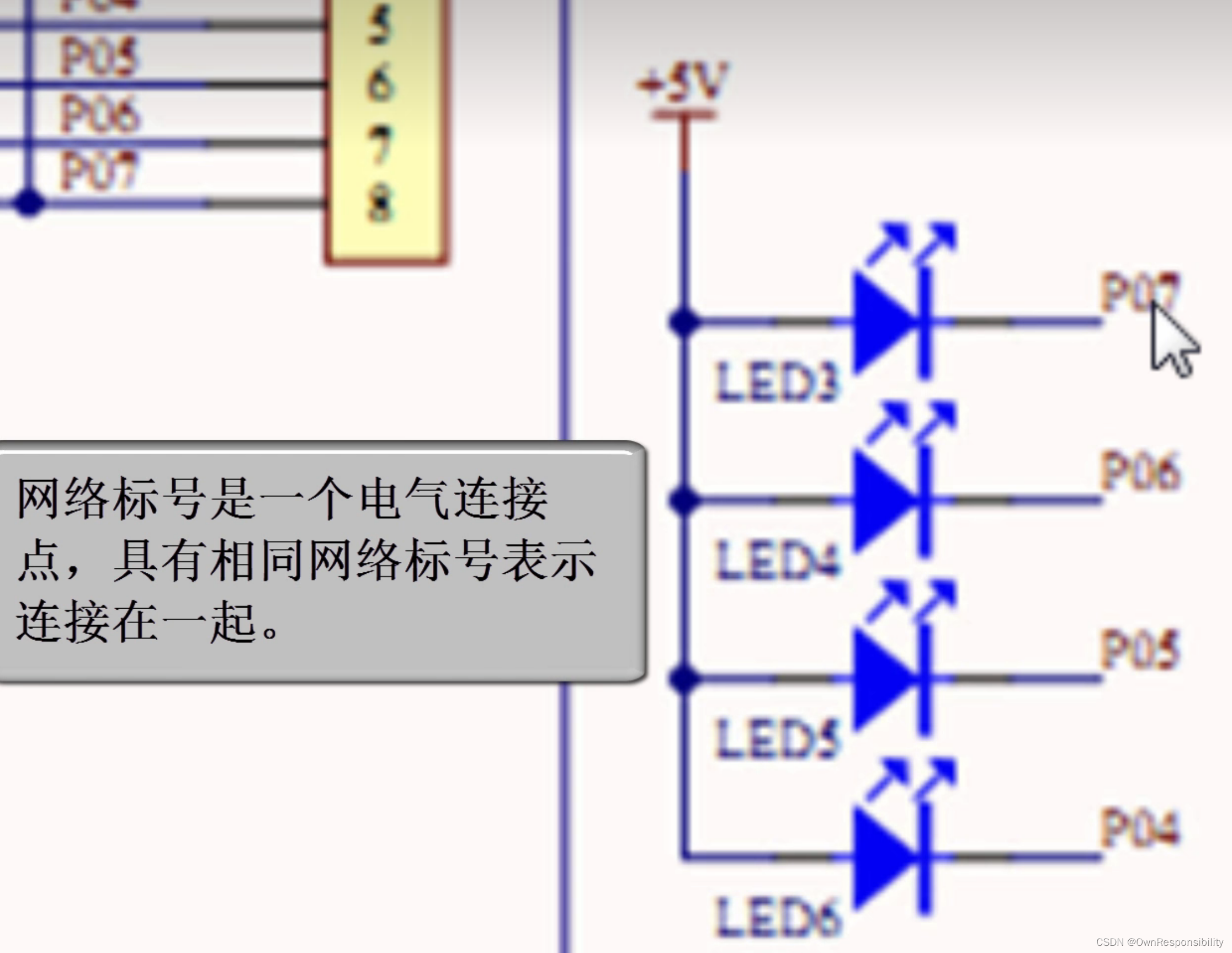
看懂基本的电路原理图(入门)
文章目录 前言一、二极管二、电容三、接地一般符号四、晶体振荡器五、各种符号的含义六、查看原理图的顺序总结 前言 电子入门,怎么看原理图,各个图标都代表什么含义,今天好好来汇总一下。 就比如这个电路原理图来说,各个符号都…...

赫夫曼树基本数据结构
自编头文件: #ifndef HUFFMAN_H_INCLUDED #define HUFFMAN_H_INCLUDED#include<limits.h> #include<string.h> typedef struct {unsigned int weight;unsigned int parent,lchild,rchild; }HTNode,*HuffmanTree; typedef char** HuffmanCode;void Sele…...
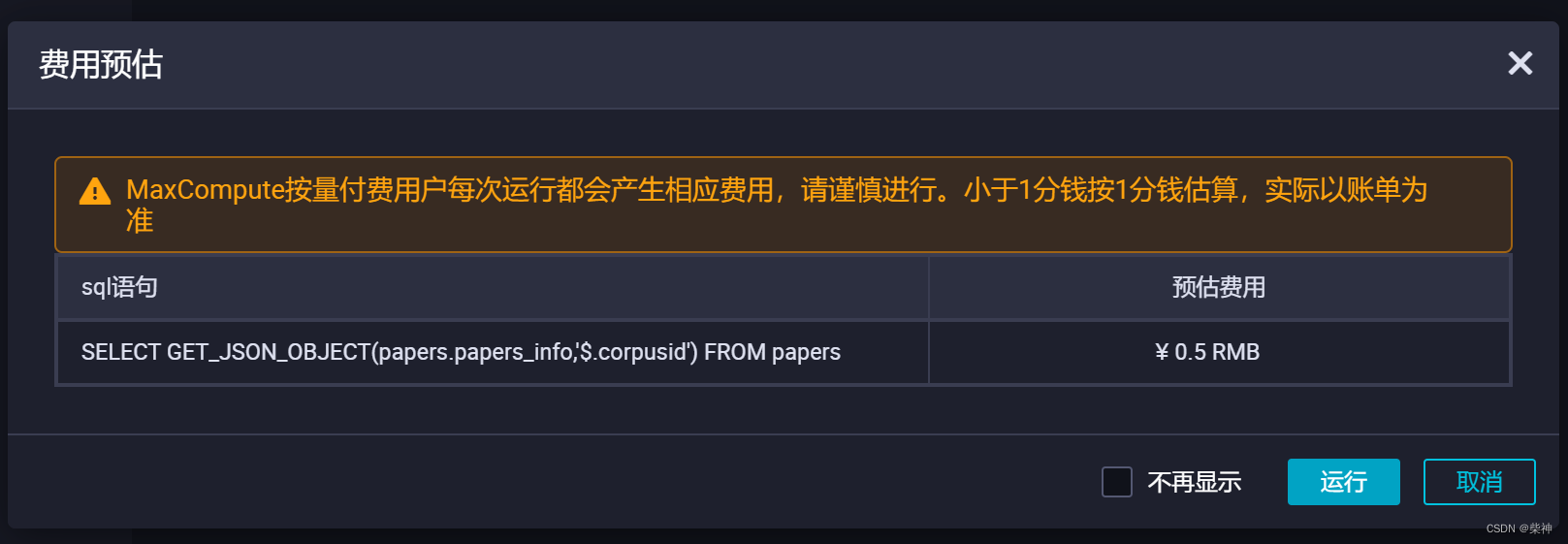
10TB海量JSON数据从OSS迁移至MaxCompute
前提条件 开通MaxCompute。 在DataWorks上完成创建业务流程,本例使用DataWorks简单模式。详情请参见创建业务流程。 将JSON文件重命名为后缀为.txt的文件,并上传至OSS。本文中OSS Bucket地域为华东2(上海)。示例文件如下。 {&qu…...
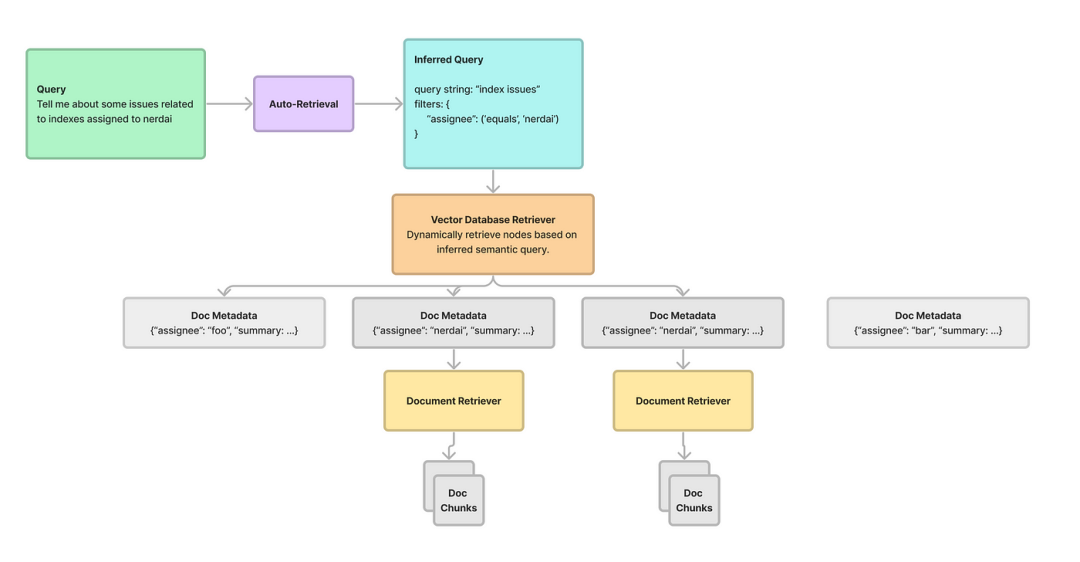
LLM之RAG实战(九)| 高级RAG 03:多文档RAG体系结构
在RAG(检索和生成)这样的框架内管理和处理多个文档有很大的挑战。关键不仅在于提取相关内容,还在于选择包含用户查询所寻求的信息的适当文档。基于用户查询对齐的多粒度特性,需要动态选择文档,本文将介绍结构化层次检索…...

Windows电脑引导损坏?按照这个教程能修复
前言 Windows系统的引导一般情况下是不会坏的,小伙伴们可以不用担心。发布这个帖子是因为要给接下来的文章做点铺垫。 关注小白很久的小伙伴应该都知道,小白的文章都讲得比较细。而且文章与文章之间的关联度其实还是蛮高的。在文章中,你会遇…...

OpenLayers 可视化之热力图
注:当前使用的是 ol 5.3.0 版本,天地图使用的key请到天地图官网申请,并替换为自己的key 热力图(Heatmap)又叫热点图,是一种通过特殊高亮显示事物密度分布、变化趋势的数据可视化技术。采用颜色的深浅来显示…...
)
椭圆曲线密码学(ECC)
一、ECC算法概述 椭圆曲线密码学(Elliptic Curve Cryptography)是基于椭圆曲线数学理论的公钥密码系统,由Neal Koblitz和Victor Miller在1985年独立提出。相比RSA,ECC在相同安全强度下密钥更短(256位ECC ≈ 3072位RSA…...

Vue3 + Element Plus + TypeScript中el-transfer穿梭框组件使用详解及示例
使用详解 Element Plus 的 el-transfer 组件是一个强大的穿梭框组件,常用于在两个集合之间进行数据转移,如权限分配、数据选择等场景。下面我将详细介绍其用法并提供一个完整示例。 核心特性与用法 基本属性 v-model:绑定右侧列表的值&…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

Pinocchio 库详解及其在足式机器人上的应用
Pinocchio 库详解及其在足式机器人上的应用 Pinocchio (Pinocchio is not only a nose) 是一个开源的 C 库,专门用于快速计算机器人模型的正向运动学、逆向运动学、雅可比矩阵、动力学和动力学导数。它主要关注效率和准确性,并提供了一个通用的框架&…...

React---day11
14.4 react-redux第三方库 提供connect、thunk之类的函数 以获取一个banner数据为例子 store: 我们在使用异步的时候理应是要使用中间件的,但是configureStore 已经自动集成了 redux-thunk,注意action里面要返回函数 import { configureS…...

scikit-learn机器学习
# 同时添加如下代码, 这样每次环境(kernel)启动的时候只要运行下方代码即可: # Also add the following code, # so that every time the environment (kernel) starts, # just run the following code: import sys sys.path.append(/home/aistudio/external-libraries)机…...

【从零开始学习JVM | 第四篇】类加载器和双亲委派机制(高频面试题)
前言: 双亲委派机制对于面试这块来说非常重要,在实际开发中也是经常遇见需要打破双亲委派的需求,今天我们一起来探索一下什么是双亲委派机制,在此之前我们先介绍一下类的加载器。 目录 编辑 前言: 类加载器 1. …...

CVPR2025重磅突破:AnomalyAny框架实现单样本生成逼真异常数据,破解视觉检测瓶颈!
本文介绍了一种名为AnomalyAny的创新框架,该方法利用Stable Diffusion的强大生成能力,仅需单个正常样本和文本描述,即可生成逼真且多样化的异常样本,有效解决了视觉异常检测中异常样本稀缺的难题,为工业质检、医疗影像…...

k8s从入门到放弃之HPA控制器
k8s从入门到放弃之HPA控制器 Kubernetes中的Horizontal Pod Autoscaler (HPA)控制器是一种用于自动扩展部署、副本集或复制控制器中Pod数量的机制。它可以根据观察到的CPU利用率(或其他自定义指标)来调整这些对象的规模,从而帮助应用程序在负…...