新手能掌握 PyTorch 的填充技术:深入理解反射、复制、零值和常数填充
目录
torch.nn子模块详解
nn.ReflectionPad1d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ReflectionPad2d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ReflectionPad3d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ReplicationPad1d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ReplicationPad2d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ReplicationPad3d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ZeroPad1d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ZeroPad2d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ZeroPad3d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ConstantPad1d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ConstantPad2d
参数说明:
形状(Shape):
使用示例:
注意事项:
nn.ConstantPad3d
参数说明:
形状(Shape):
使用示例:
注意事项:
总结
torch.nn子模块详解
nn.ReflectionPad1d
torch.nn.ReflectionPad1d 是 PyTorch 深度学习框架中的一个类,用于对输入的张量(tensor)进行边界反射填充。这意味着它会复制输入张量的边界值来增加其大小。这种填充方式常用于卷积神经网络中,以保持数据的空间维度。
参数说明:
padding:这个参数可以是一个整数或一个二元组(tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是二元组,它表示左右两边的填充大小,格式为(padding_left, padding_right)。
形状(Shape):
- 输入:其形状可以是
(C, W)或(N, C, W),其中C是通道数,W是输入宽度,N是批大小(如果有的话)。 - 输出:形状为
(C, W_out)或(N, C, W_out),其中W_out = W_in + padding_left + padding_right。这里,W_out是填充后的宽度。
使用示例:
1. 基本使用:如果你使用 nn.ReflectionPad1d(2),这意味着在输入张量的每一边添加两个单位的反射填充。
m = nn.ReflectionPad1d(2)
input = torch.arange(8, dtype=torch.float).reshape(1, 2, 4)
output = m(input)
这将在输入张量的左右两侧分别添加两个单位的反射填充。
2. 使用不同的填充大小:你可以通过传递一个二元组来为左右两边设置不同的填充大小,比如 nn.ReflectionPad1d((3, 1))。
m = nn.ReflectionPad1d((3, 1))
output = m(input)
这将在输入张量的左边添加三个单位,右边添加一个单位的反射填充。
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 边界效应:由于反射填充是通过复制边缘值实现的,因此在某些情况下可能会引入不希望的边界效应。
- 使用场景:反射填充在视觉任务中特别有用,因为它可以保持图像边缘的连续性,而不是简单地填充零或其他值。
在数学公式中,W_out = W_in + padding_left + padding_right 描述了输出宽度(W_out)是如何根据输入宽度(W_in)以及左右两侧的填充大小计算出来的。
nn.ReflectionPad2d
torch.nn.ReflectionPad2d 是 PyTorch 框架中用于二维数据的一个填充类,它使用输入边界的反射进行填充。这种类型的填充在处理图像或其他二维数据时非常有用,尤其是在进行卷积操作时,需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个四元组(4-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是四元组,它表示四个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom)。
形状(Shape):
- 输入:其形状可以是
(N, C, H_in, W_in)或(C, H_in, W_in),其中N是批大小,C是通道数,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, H_out, W_out)或(C, H_out, W_out),其中H_out = H_in + padding_top + padding_bottom和W_out = W_in + padding_left + padding_right。这里的H_out和W_out分别是填充后的高度和宽度。
使用示例:
-
基本使用:如果使用
nn.ReflectionPad2d(2),这意味着在所有四个边界上添加两个单位的反射填充。
m = nn.ReflectionPad2d(2)
input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3)
output = m(input)
这将在输入张量的每一边添加两个单位的反射填充。
2. 使用不同的填充大小:你可以传递一个四元组来为每个边界设置不同的填充大小,比如 nn.ReflectionPad2d((1, 1, 2, 0))。
m = nn.ReflectionPad2d((1, 1, 2, 0))
output = m(input)
这将在输入张量的左、右边各添加一个单位,顶部添加两个单位,底部不添加填充的反射填充。
注意事项:
- 数据类型:确保输入数据的类型与模型其他部分一致。
- 边界效应:反射填充通过复制边缘值,可能在某些情况下引入边界效应,需要注意这一点。
- 适用场景:反射填充尤其适用于视觉任务,因为它在填充时保持了图像边缘的连续性。
在数学公式中,H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的高度(H_out)和宽度(W_out)是如何基于输入的高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ReflectionPad3d
torch.nn.ReflectionPad3d 是 PyTorch 深度学习框架中的一个类,专门用于对三维数据进行反射填充。这种填充方式在处理三维数据(如体积数据或视频帧)时非常有用,尤其是在卷积神经网络中需要保持数据尺寸不变的场景中。
参数说明:
padding:这个参数可以是一个整数或一个六元组(6-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是六元组,它表示六个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom, padding_front, padding_back)。
形状(Shape):
- 输入:其形状可以是
(N, C, D_in, H_in, W_in)或(C, D_in, H_in, W_in),其中N是批大小,C是通道数,D_in是输入深度,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, D_out, H_out, W_out)或(C, D_out, H_out, W_out),其中D_out = D_in + padding_front + padding_back,H_out = H_in + padding_top + padding_bottom,W_out = W_in + padding_left + padding_right。这里的D_out、H_out和W_out分别是填充后的深度、高度和宽度。
使用示例:
基本使用:如果使用 nn.ReflectionPad3d(1),这意味着在所有六个边界上添加一个单位的反射填充。
m = nn.ReflectionPad3d(1)
input = torch.arange(8, dtype=torch.float).reshape(1, 1, 2, 2, 2)
output = m(input)
这将在输入张量的每一个边界添加一个单位的反射填充。
使用不同的填充大小:你可以传递一个六元组来为每个边界设置不同的填充大小。
# 示例:设置不同的填充大小
m = nn.ReflectionPad3d((1, 1, 2, 0, 1, 2))
# 然后使用 m(input) 来应用填充
这将在输入张量的不同边界上添加不同大小的反射填充。
注意事项:
- 数据类型:确保输入数据的类型与模型其他部分一致。
- 边界效应:反射填充通过复制边缘值,可能在某些情况下引入边界效应,需要特别注意。
- 适用场景:反射填充尤其适用于处理三维数据,如医学图像、视频处理等领域。
在数学公式中,D_out = D_in + padding_front + padding_back、H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的深度(D_out)、高度(H_out)和宽度(W_out)是如何基于输入的深度(D_in)、高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ReplicationPad1d
torch.nn.ReplicationPad1d 是 PyTorch 框架中用于一维数据的填充类,它通过复制输入边界的值来进行填充。这种填充方式在处理一维序列数据(如时间序列、音频信号等)时非常有用,尤其是在进行卷积操作时需要保持数据长度不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个二元组(tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是二元组,它表示左右两边的填充大小,格式为(padding_left, padding_right)。
形状(Shape):
- 输入:其形状可以是
(C, W_in)或(N, C, W_in),其中C是通道数,W_in是输入宽度,N是批大小(如果有的话)。 - 输出:形状为
(C, W_out)或(N, C, W_out),其中W_out = W_in + padding_left + padding_right。这里的W_out是填充后的宽度。
使用示例:
-
基本使用:如果使用
nn.ReplicationPad1d(2),这意味着在输入张量的每一边添加两个单位的复制填充。
m = nn.ReplicationPad1d(2)
input = torch.arange(8, dtype=torch.float).reshape(1, 2, 4)
output = m(input)
这将在输入张量的左右两侧分别添加两个单位的复制填充。
2. 使用不同的填充大小:你可以通过传递一个二元组来为左右两边设置不同的填充大小,比如 nn.ReplicationPad1d((3, 1))。
m = nn.ReplicationPad1d((3, 1))
output = m(input)
这将在输入张量的左边添加三个单位,右边添加一个单位的复制填充。
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:由于复制填充是通过重复边缘值实现的,因此在某些情况下可能会引入不希望的效果,特别是在边缘值与邻近数据差异较大时。
- 使用场景:复制填充在处理一维数据时特别有用,因为它在填充时尽可能保持了数据的局部特性。
在数学公式中,W_out = W_in + padding_left + padding_right 描述了输出宽度(W_out)是如何根据输入宽度(W_in)以及左右两侧的填充大小计算出来的。
nn.ReplicationPad2d
torch.nn.ReplicationPad2d 是 PyTorch 框架中用于二维数据的填充类,它通过复制输入边界的值来进行填充。这种填充方式在处理图像或其他二维数据时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个四元组(4-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是四元组,它表示四个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom)。
形状(Shape):
- 输入:其形状可以是
(N, C, H_in, W_in)或(C, H_in, W_in),其中N是批大小,C是通道数,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, H_out, W_out)或(C, H_out, W_out),其中H_out = H_in + padding_top + padding_bottom和W_out = W_in + padding_left + padding_right。这里的H_out和W_out分别是填充后的高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ReplicationPad2d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ReplicationPad2d(2)
input = torch.arange(9, dtype=torch.float).reshape(1, 1, 3, 3)
output_same_padding = m_same_padding(input)# 使用不同的填充大小
m_different_padding = nn.ReplicationPad2d((1, 1, 2, 0))
output_different_padding = m_different_padding(input)# 打印输出
print("Output with same padding on all sides:\n", output_same_padding)
print("\nOutput with different padding:\n", output_different_padding)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:由于复制填充是通过重复边缘值实现的,因此在某些情况下可能会引入不希望的效果,特别是在边缘值与邻近数据差异较大时。
- 使用场景:复制填充在处理二维数据时特别有用,因为它在填充时尽可能保持了数据的局部特性。
在数学公式中,H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的高度(H_out)和宽度(W_out)是如何基于输入的高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ReplicationPad3d
torch.nn.ReplicationPad3d 是 PyTorch 框架中用于三维数据的填充类,它通过复制输入边界的值来进行填充。这种填充方式在处理三维数据(如体积数据、三维图像)时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个六元组(6-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是六元组,它表示六个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom, padding_front, padding_back)。
形状(Shape):
- 输入:其形状可以是
(N, C, D_in, H_in, W_in)或(C, D_in, H_in, W_in),其中N是批大小,C是通道数,D_in是输入深度,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, D_out, H_out, W_out)或(C, D_out, H_out, W_out),其中D_out = D_in + padding_front + padding_back,H_out = H_in + padding_top + padding_bottom,W_out = W_in + padding_left + padding_right。这里的D_out、H_out和W_out分别是填充后的深度、高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ReplicationPad3d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ReplicationPad3d(3)
input = torch.randn(16, 3, 8, 320, 480)
output_same_padding = m_same_padding(input)# 使用不同的填充大小
m_different_padding = nn.ReplicationPad3d((3, 3, 6, 6, 1, 1))
output_different_padding = m_different_padding(input)# 打印输出
print("Output with same padding on all sides:\n", output_same_padding.shape)
print("\nOutput with different padding:\n", output_different_padding.shape)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:由于复制填充是通过重复边缘值实现的,因此在某些情况下可能会引入不希望的效果,特别是在边缘值与邻近数据差异较大时。
- 使用场景:复制填充在处理三维数据时特别有用,因为它在填充时尽可能保持了数据的局部特性。
在数学公式中,D_out = D_in + padding_front + padding_back、H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的深度(D_out)、高度(H_out)和宽度(W_out)是如何基于输入的深度(D_in)、高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ZeroPad1d
torch.nn.ZeroPad1d 是 PyTorch 框架中用于一维数据的填充类,它通过在输入张量的边界添加零来进行填充。这种填充方式在处理一维序列数据(如时间序列、音频信号等)时非常有用,尤其是在进行卷积操作时需要保持数据长度不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个二元组(tuple)。如果是整数,它会在两边边界上应用相同的填充大小。如果是二元组,它表示左右两边的填充大小,格式为(padding_left, padding_right)。
形状(Shape):
- 输入:其形状可以是
(C, W_in)或(N, C, W_in),其中C是通道数,W_in是输入宽度,N是批大小(如果有的话)。 - 输出:形状为
(C, W_out)或(N, C, W_out),其中W_out = W_in + padding_left + padding_right。这里的W_out是填充后的宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ZeroPad1d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ZeroPad1d(2)
input1 = torch.randn(1, 2, 4)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ZeroPad1d((3, 1))
input2 = torch.randn(1, 2, 3)
output2 = m_different_padding(input2)# 打印输出
print("Output with same padding on both sides:\n", output1)
print("\nOutput with different padding:\n", output2)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:零填充会在序列的边界添加零值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:零填充在处理一维数据时特别有用,尤其是在需要保持数据长度不变时。
在数学公式中,W_out = W_in + padding_left + padding_right 描述了输出宽度(W_out)是如何根据输入宽度(W_in)以及左右两侧的填充大小计算出来的。
nn.ZeroPad2d
torch.nn.ZeroPad2d 是 PyTorch 框架中用于二维数据的填充类,它通过在输入张量的边界添加零来进行填充。这种填充方式在处理图像或其他二维数据时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个四元组(4-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是四元组,它表示四个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom)。
形状(Shape):
- 输入:其形状可以是
(N, C, H_in, W_in)或(C, H_in, W_in),其中N是批大小,C是通道数,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, H_out, W_out)或(C, H_out, W_out),其中H_out = H_in + padding_top + padding_bottom和W_out = W_in + padding_left + padding_right。这里的H_out和W_out分别是填充后的高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ZeroPad2d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ZeroPad2d(2)
input1 = torch.randn(1, 1, 3, 3)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ZeroPad2d((1, 1, 2, 0))
input2 = torch.randn(1, 1, 3, 3)
output2 = m_different_padding(input2)# 打印输出
print("Output with same padding on all sides:\n", output1)
print("\nOutput with different padding:\n", output2)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:零填充会在图像的边界添加零值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:零填充在处理二维数据时特别有用,尤其是在需要保持数据尺寸不变时。
在数学公式中,H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的高度(H_out)和宽度(W_out)是如何基于输入的高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ZeroPad3d
torch.nn.ZeroPad3d 是 PyTorch 框架中用于三维数据的填充类,它通过在输入张量的边界添加零来进行填充。这种填充方式在处理三维数据(如体积数据、三维图像等)时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个六元组(6-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是六元组,它表示六个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom, padding_front, padding_back)。
形状(Shape):
- 输入:其形状可以是
(N, C, D_in, H_in, W_in)或(C, D_in, H_in, W_in),其中N是批大小,C是通道数,D_in是输入深度,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, D_out, H_out, W_out)或(C, D_out, H_out, W_out),其中D_out = D_in + padding_front + padding_back,H_out = H_in + padding_top + padding_bottom,W_out = W_in + padding_left + padding_right。这里的D_out、H_out和W_out分别是填充后的深度、高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ZeroPad3d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ZeroPad3d(3)
input1 = torch.randn(16, 3, 10, 20, 30)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ZeroPad3d((3, 3, 6, 6, 0, 1))
output2 = m_different_padding(input1)# 打印输出
print("Output with same padding on all sides:\n", output1.shape)
print("\nOutput with different padding:\n", output2.shape)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:零填充会在三维数据的边界添加零值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:零填充在处理三维数据时特别有用,尤其是在需要保持数据尺寸不变时。
在数学公式中,D_out = D_in + padding_front + padding_back、H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的深度(D_out)、高度(H_out)和宽度(W_out)是如何基于输入的深度(D_in)、高度(H_in)、宽度(W_in)以及各边的填充大小计算出来的。
nn.ConstantPad1d
torch.nn.ConstantPad1d 是 PyTorch 框架中用于一维数据的填充类,它通过在输入张量的边界添加一个常数值来进行填充。这种填充方式在处理一维序列数据(如时间序列、音频信号等)时非常有用,尤其是在进行卷积操作时需要保持数据长度不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个二元组(tuple)。如果是整数,它会在两边边界上应用相同的填充大小。如果是二元组,它表示左右两边的填充大小,格式为(padding_left, padding_right)。value:填充的常数值。
形状(Shape):
- 输入:其形状可以是
(C, W_in)或(N, C, W_in),其中C是通道数,W_in是输入宽度,N是批大小(如果有的话)。 - 输出:形状为
(C, W_out)或(N, C, W_out),其中W_out = W_in + padding_left + padding_right。这里的W_out是填充后的宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ConstantPad1d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ConstantPad1d(2, 3.5)
input1 = torch.randn(1, 2, 4)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ConstantPad1d((3, 1), 3.5)
input2 = torch.randn(1, 2, 3)
output2 = m_different_padding(input2)# 打印输出
print("Output with same padding on both sides:\n", output1)
print("\nOutput with different padding:\
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:常数填充会在序列的边界添加特定的常数值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:常数填充在处理一维数据时特别有用,尤其是在需要保持数据长度不变时。
在数学公式中,W_out = W_in + padding_left + padding_right 描述了输出宽度(W_out)是如何根据输入宽度(W_in)以及左右两侧的填充大小和填充值计算出来的。
nn.ConstantPad2d
torch.nn.ConstantPad2d 是 PyTorch 框架中用于二维数据的填充类,它通过在输入张量的边界添加一个常数值来进行填充。这种填充方式在处理图像或其他二维数据时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个四元组(4-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是四元组,它表示四个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom)。value:填充的常数值。
形状(Shape):
- 输入:其形状可以是
(N, C, H_in, W_in)或(C, H_in, W_in),其中N是批大小,C是通道数,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, H_out, W_out)或(C, H_out, W_out),其中H_out = H_in + padding_top + padding_bottom和W_out = W_in + padding_left + padding_right。这里的H_out和W_out分别是填充后的高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ConstantPad2d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ConstantPad2d(2, 3.5)
input1 = torch.randn(1, 2, 2)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ConstantPad2d((3, 0, 2, 1), 3.5)
output2 = m_different_padding(input1)# 打印输出
print("Output with same padding on all sides:\n", output1)
print("\nOutput with different padding:\n", output2)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:常数填充会在图像的边界添加特定的常数值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:常数填充在处理二维数据时特别有用,尤其是在需要保持数据尺寸不变时。
在数学公式中,H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的高度(H_out)和宽度(W_out)是如何基于输入的高度(H_in)、宽度(W_in)以及各边的填充大小和填充值计算出来的。
nn.ConstantPad3d
torch.nn.ConstantPad3d 是 PyTorch 框架中用于三维数据的填充类,它通过在输入张量的边界添加一个常数值来进行填充。这种填充方式在处理三维数据(如体积数据、三维图像等)时非常有用,尤其是在进行卷积操作时需要保持数据尺寸不变的情况下。
参数说明:
padding:这个参数可以是一个整数或一个六元组(6-tuple)。如果是整数,它会在所有边界上应用相同的填充大小。如果是六元组,它表示六个边界的填充大小,格式为(padding_left, padding_right, padding_top, padding_bottom, padding_front, padding_back)。value:填充的常数值。
形状(Shape):
- 输入:其形状可以是
(N, C, D_in, H_in, W_in)或(C, D_in, H_in, W_in),其中N是批大小,C是通道数,D_in是输入深度,H_in是输入高度,W_in是输入宽度。 - 输出:形状为
(N, C, D_out, H_out, W_out)或(C, D_out, H_out, W_out),其中D_out = D_in + padding_front + padding_back,H_out = H_in + padding_top + padding_bottom,W_out = W_in + padding_left + padding_right。这里的D_out、H_out和W_out分别是填充后的深度、高度和宽度。
使用示例:
以下是一个整合的示例,展示了如何使用 nn.ConstantPad3d,包括使用相同的填充大小和不同的填充大小两种情况:
import torch
import torch.nn as nn# 使用相同的填充大小
m_same_padding = nn.ConstantPad3d(3, 3.5)
input1 = torch.randn(16, 3, 10, 20, 30)
output1 = m_same_padding(input1)# 使用不同的填充大小
m_different_padding = nn.ConstantPad3d((3, 3, 6, 6, 0, 1), 3.5)
output2 = m_different_padding(input1)# 打印输出
print("Output with same padding on all sides:\n", output1.shape)
print("\nOutput with different padding:\n", output2.shape)
注意事项:
- 数据类型:确保输入数据的类型(如 float32)与你的模型其他部分一致。
- 填充效果:常数填充会在三维数据的边界添加特定的常数值,这可能会对模型产生特定的影响,尤其是在模型需要解释边界信息时。
- 使用场景:常数填充在处理三维数据时特别有用,尤其是在需要保持数据尺寸不变时。
在数学公式中,D_out = D_in + padding_front + padding_back、H_out = H_in + padding_top + padding_bottom 和 W_out = W_in + padding_left + padding_right 描述了输出的深度(D_out)、高度(H_out)和宽度(W_out)是如何基于输入的深度(D_in)、高度(H_in)、宽度(W_in)以及各边的填充大小和填充值计算出来的。
总结
本文详细介绍了 PyTorch 框架中的多个填充类,用于在深度学习模型中处理不同维度的数据。这些填充方法对于保持卷积神经网络中数据的空间维度至关重要,尤其在图像处理、音频信号处理等领域中有广泛应用。每种填充方法都有其特定的应用场景和注意事项,如数据类型一致性、边界效应的考虑等。文章通过具体的代码示例展示了如何在 PyTorch 中使用这些填充类,并解释了它们的工作原理。
相关文章:

新手能掌握 PyTorch 的填充技术:深入理解反射、复制、零值和常数填充
目录 torch.nn子模块详解 nn.ReflectionPad1d 参数说明: 形状(Shape): 使用示例: 注意事项: nn.ReflectionPad2d 参数说明: 形状(Shape): 使用示例…...
地震烈度速报与预警工程成功案例的经验分享 | TDengine 技术培训班第一期成功落地
近日,涛思数据在成都开设了“国家地震烈度速报与预警工程数据库 TDengine、消息中间件 TMQ 技术培训班”,这次培训活动共分为三期,而本次活动是第一期。其目标是帮助参与者深入了解 TDengine 和 TMQ 的技术特点和应用场景,并学习如…...
集群部署篇--Redis 集群动态伸缩
文章目录 前言一、redis 节点的添加1.1 redis 的实例部署:1.2 redis 节点添加:1.3 槽位分配:1.4 添加从节点: 二、redis 节点的减少2.1 移除主节点2.1.1 迁移槽位2.1.1 删除节点: 三、redis 删除节点的重新加入3.1 加入…...

excel中解决多行文本自动调整行高后打印预览还是显示不全情况
注意:此方法对于多行合并后单元格行高调整不适用,需要手动调整,如大家有简便方法,欢迎评论。 一、调整表格为自动调整行高 1)点击此处全选表格 2)在第一行序号单元格的下端,鼠标成黑十字时&am…...

策略模式+责任链模式配合Nacos实现参数校验链
1、业务场景 在SpringBoot项目中,针对接收的参数信息,根据需求要进行以下校验: 校验客户的apikey是否合法;校验请求的ip地址是否是白名单;校验短信的签名;校验短信的模板;校验手机号的格式合法…...

‘react-native‘ 不是内部或外部命令,也不是可运行的程序或批处理文件。
原因:没有下载react-native 解决下载react-native npm i -g react-native-cli...
c语言:求最小公倍数|练习题
一、题目 输入两个数,求两数的最小公倍数。 如图: 二、思路分析 1、先知道两个数里的最小值(比如:9和6,取6) 2、用2到6,5个数,同时除以9和6,得最小公约数:3 3、用9除33,6除32。得最小…...
嵌入式系统(二)单片机基础 | 单片机特点 内部结构 最小系统 电源 晶振 复位
上一篇文章我们介绍了嵌入式系统 嵌入式系统(Embedded System)是一种特定用途的计算机系统,它通常嵌入在更大的产品或系统中,用于控制、监测或执行特定的任务。这些系统通常由硬件和软件组成,旨在满足特定的需求&…...

NLP基础——中文分词
简介 分词是自然语言处理(NLP)中的一个基本任务,它涉及将连续的文本序列切分成多个有意义的单元,这些单元通常被称为“词”或“tokens”。在英语等使用空格作为自然分隔符的语言中,分词相对简单,因为大部分…...

阿里云服务器Alibaba Cloud Linux 3镜像版本大全说明
Alibaba Cloud Linux阿里云打造的Linux服务器操作系统发行版,Alibaba Cloud Linux完全兼容完全兼容CentOS/RHEL生态和操作方式,目前已经推出Alibaba Cloud Linux 3,阿里云百科aliyunbaike.com分享Alibaba Cloud Linux 3版本特性说明ÿ…...

WebGIS开发的常见框架及优缺点
WebGIS开发引擎的发展历程: 内容来自公众号:Spatial Data 地图API分类 WebGIS系统通常都围绕地图进行内容表达,但并不是有地图就一定是WebGIS,所以下面要讨论下基于Web的地图API分类及应用场景。Web上的Map API主要分类ÿ…...
ansible 配置jspgou商城上线(MySQL版)
准备环境 准备两台纯净的服务器进行,在实验之前我们关闭防火墙和selinux systemctl stop firewalld #关闭防火墙 setenforce 0 #临时关闭selinux hosts解析(两台服务器都要去做) [rootansible-server ~]# vim /etc/hosts 10.31.162.24 ansible-ser…...
算法导论复习——CHP22 分支限界法
LIFO和FIFO分枝-限界法 采用宽度优先策略,在生成当前E-结点全部儿子之后再生成其它活结点的儿子,且用限界函数帮助避免生成不包含答案结点子树的状态空间的检索方法。两种基本设计策略: FIFO检索:活结点表采用队列&#x…...

鸿蒙系列--装饰器
一、基础UI组件结构 每个UI组件需要定义为Component struct对象,其内部必须包含一个且只能包含一个build(){}函数,用于绘制UI;struct之内、build()函数之外的地方用于存放数据。 二、基本UI装饰器 Entry 装饰struct,页面的入口…...

FairGuard游戏加固产品常见问题解答
针对日常对接中,各位用户对FairGuard游戏加固方案在安全性、稳定性、易用性、接入流程等方面的关注,我们梳理了相关问题与解答,希望可以让您对产品有一个初步的认知与认可。 Q1:FairGuard游戏加固产品都有哪些功能? A:FairGuar…...

Redis(二)数据类型
文章目录 官网备注十大数据类型StringListHashSetZSetBitmapHyperLogLog:GEOStreamBitfield 官网 英文:https://redis.io/commands/ 中文:http://www.redis.cn/commands.html 备注 命令不区分大小写,key区分大小写帮助命令help…...
)
2023年广东省网络安全B模块(笔记详解)
模块B 网络安全事件响应、数字取证调查和应用安全 一、项目和任务描述: 假定你是某网络安全技术支持团队成员,某企业的服务器系统被黑客攻击,你的团队前来帮助企业进行调查并追踪本次网络攻击的源头,分析黑客的攻击方式,发现系统漏洞,提交网络安全事件响应报告,修复系统…...
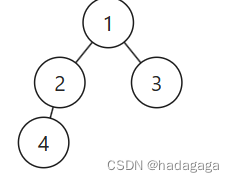
每日力扣算法题(简单篇)
543.二叉树的直径 原题: 给你一棵二叉树的根节点,返回该树的 直径 。 二叉树的 直径 是指树中任意两个节点之间最长路径的 长度 。这条路径可能经过也可能不经过根节点 root 。 两节点之间路径的 长度 由它们之间边数表示。 解题思路: …...
Flume基础知识(三):Flume 实战监控端口数据官方案例
1. 监控端口数据官方案例 1)案例需求: 使用 Flume 监听一个端口,收集该端口数据,并打印到控制台。 2)需求分析: 3)实现步骤: (1)安装 netcat 工具 sudo yum …...

通过IP地址如何进行网络安全防护
IP地址在网络安全防护中起着至关重要的作用,可以用于监控、过滤和控制网络流量,识别潜在威胁并加强网络安全。以下是通过IP地址进行网络安全防护的一些建议: 1. 建立IP地址白名单和黑名单: 白名单:确保只有授权的IP地…...
)
浏览器访问 AWS ECS 上部署的 Docker 容器(监听 80 端口)
✅ 一、ECS 服务配置 Dockerfile 确保监听 80 端口 EXPOSE 80 CMD ["nginx", "-g", "daemon off;"]或 EXPOSE 80 CMD ["python3", "-m", "http.server", "80"]任务定义(Task Definition&…...

【CSS position 属性】static、relative、fixed、absolute 、sticky详细介绍,多层嵌套定位示例
文章目录 ★ position 的五种类型及基本用法 ★ 一、position 属性概述 二、position 的五种类型详解(初学者版) 1. static(默认值) 2. relative(相对定位) 3. absolute(绝对定位) 4. fixed(固定定位) 5. sticky(粘性定位) 三、定位元素的层级关系(z-i…...

[10-3]软件I2C读写MPU6050 江协科技学习笔记(16个知识点)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16...

C# SqlSugar:依赖注入与仓储模式实践
C# SqlSugar:依赖注入与仓储模式实践 在 C# 的应用开发中,数据库操作是必不可少的环节。为了让数据访问层更加简洁、高效且易于维护,许多开发者会选择成熟的 ORM(对象关系映射)框架,SqlSugar 就是其中备受…...

【碎碎念】宝可梦 Mesh GO : 基于MESH网络的口袋妖怪 宝可梦GO游戏自组网系统
目录 游戏说明《宝可梦 Mesh GO》 —— 局域宝可梦探索Pokmon GO 类游戏核心理念应用场景Mesh 特性 宝可梦玩法融合设计游戏构想要素1. 地图探索(基于物理空间 广播范围)2. 野生宝可梦生成与广播3. 对战系统4. 道具与通信5. 延伸玩法 安全性设计 技术选…...

技术栈RabbitMq的介绍和使用
目录 1. 什么是消息队列?2. 消息队列的优点3. RabbitMQ 消息队列概述4. RabbitMQ 安装5. Exchange 四种类型5.1 direct 精准匹配5.2 fanout 广播5.3 topic 正则匹配 6. RabbitMQ 队列模式6.1 简单队列模式6.2 工作队列模式6.3 发布/订阅模式6.4 路由模式6.5 主题模式…...
:观察者模式)
JS设计模式(4):观察者模式
JS设计模式(4):观察者模式 一、引入 在开发中,我们经常会遇到这样的场景:一个对象的状态变化需要自动通知其他对象,比如: 电商平台中,商品库存变化时需要通知所有订阅该商品的用户;新闻网站中࿰…...

基于Java+MySQL实现(GUI)客户管理系统
客户资料管理系统的设计与实现 第一章 需求分析 1.1 需求总体介绍 本项目为了方便维护客户信息为了方便维护客户信息,对客户进行统一管理,可以把所有客户信息录入系统,进行维护和统计功能。可通过文件的方式保存相关录入数据,对…...

Kafka入门-生产者
生产者 生产者发送流程: 延迟时间为0ms时,也就意味着每当有数据就会直接发送 异步发送API 异步发送和同步发送的不同在于:异步发送不需要等待结果,同步发送必须等待结果才能进行下一步发送。 普通异步发送 首先导入所需的k…...

省略号和可变参数模板
本文主要介绍如何展开可变参数的参数包 1.C语言的va_list展开可变参数 #include <iostream> #include <cstdarg>void printNumbers(int count, ...) {// 声明va_list类型的变量va_list args;// 使用va_start将可变参数写入变量argsva_start(args, count);for (in…...