PyTorch实战:基于Seq2seq模型处理机器翻译任务(模型预测)
文章目录
- 引言
- 数据预处理
- 加载字典对象`en2id`和`zh2id`
- 文本分词
- 加载训练好的Seq2Seq模型
- 模型预测完整代码
- 结束语
引言
随着全球化的深入,翻译需求日益增长。传统的人工翻译方式虽然质量高,但效率低,成本高。机器翻译的出现,为解决这一问题提供了可能。英译中机器翻译任务是机器翻译领域的一个重要分支,旨在将英文文本自动翻译成中文。本博客以《PyTorch自然语言处理入门与实战》第九章的Seq2seq模型处理英译中翻译任务作为基础,附上模型预测模块。
模型的训练及验证模块的详细解析见PyTorch实战:基于Seq2seq模型处理机器翻译任务(模型训练及验证)
数据预处理
加载字典对象en2id和zh2id
在预测阶段中,需要加载模型训练及验证阶段保存的字典对象en2id和zh2id。
代码如下:
import picklewith open("en2id.pkl", 'rb') as f:en2id = pickle.load(f)
with open("zh2id.pkl", 'rb') as f:zh2id = pickle.load(f)
文本分词
在对输入文本进行预测时,需要先将文本进行分词操作。参考代码如下:
def extract_words(sentence): """ 从给定的英文句子中提取单词,并去除单词后的标点符号。 Args: sentence (str): 要提取单词的英文句子。 Returns: List[str]: 提取并处理后的单词列表。 """ en_words = [] for w in sentence.split(' '): # 将英文句子按空格分词 w = w.replace('.', '').replace(',', '') # 去除跟单词连着的标点符号 w = w.lower() # 统一单词大小写 if w: en_words.append(w) return en_words # 测试函数
sentence = 'I am Dave Gallo.'
print(extract_words(sentence))
运行结果:

加载训练好的Seq2Seq模型
代码如下:
import torch
import torch.nn as nnclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.hid_dim = hid_dimself.n_layers = n_layersself.embedding = nn.Embedding(input_dim, emb_dim) # 词嵌入self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.dropout = nn.Dropout(dropout)def forward(self, src):# src = (src len, batch size)embedded = self.dropout(self.embedding(src))# embedded = (src len, batch size, emb dim)outputs, (hidden, cell) = self.rnn(embedded)# outputs = (src len, batch size, hid dim * n directions)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# rnn的输出总是来自顶部的隐藏层return hidden, cellclass Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.output_dim = output_dimself.hid_dim = hid_dimself.n_layers = n_layersself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.fc_out = nn.Linear(hid_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, input, hidden, cell):# 各输入的形状# input = (batch size)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# LSTM是单向的 ==> n directions == 1# hidden = (n layers, batch size, hid dim)# cell = (n layers, batch size, hid dim)input = input.unsqueeze(0) # (batch size) --> [1, batch size)embedded = self.dropout(self.embedding(input)) # (1, batch size, emb dim)output, (hidden, cell) = self.rnn(embedded, (hidden, cell))# LSTM理论上的输出形状# output = (seq len, batch size, hid dim * n directions)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# 解码器中的序列长度 seq len == 1# 解码器的LSTM是单向的 n directions == 1 则实际上# output = (1, batch size, hid dim)# hidden = (n layers, batch size, hid dim)# cell = (n layers, batch size, hid dim)prediction = self.fc_out(output.squeeze(0))# prediction = (batch size, output dim)return prediction, hidden, cellclass Seq2Seq(nn.Module):def __init__(self, input_word_count, output_word_count, encode_dim, decode_dim, hidden_dim, n_layers,encode_dropout, decode_dropout, device):""":param input_word_count: 英文词表的长度 34737:param output_word_count: 中文词表的长度 4015:param encode_dim: 编码器的词嵌入维度:param decode_dim: 解码器的词嵌入维度:param hidden_dim: LSTM的隐藏层维度:param n_layers: 采用n层LSTM:param encode_dropout: 编码器的dropout概率:param decode_dropout: 编码器的dropout概率:param device: cuda / cpu"""super().__init__()self.encoder = Encoder(input_word_count, encode_dim, hidden_dim, n_layers, encode_dropout)self.decoder = Decoder(output_word_count, decode_dim, hidden_dim, n_layers, decode_dropout)self.device = devicedef forward(self, src):# src = (src len, batch size)# 编码器的隐藏层输出将作为解码器的第一个隐藏层输入hidden, cell = self.encoder(src)# 解码器的第一个输入应该是起始标识符<sos>input = src[0, :] # 取trg的第“0”行所有列 “0”指的是索引pred = [0] # 预测的第一个输出应该是起始标识符top1 = 0while top1 != 1 and len(pred) < 100:# 解码器的输入包括:起始标识符的词嵌入input; 编码器输出的 hidden and cell states# 解码器的输出包括:输出张量(predictions) and new hidden and cell statesoutput, hidden, cell = self.decoder(input, hidden, cell)top1 = output.argmax(dim=1) # (batch size, )pred.append(top1.item())input = top1return preddevice = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') # GPU可用 用GPU
# Seq2Seq模型实例化
source_word_count = 34737 # 英文词表的长度 34737
target_word_count = 4015 # 中文词表的长度 4015
encode_dim = 256 # 编码器的词嵌入维度
decode_dim = 256 # 解码器的词嵌入维度
hidden_dim = 512 # LSTM的隐藏层维度
n_layers = 2 # 采用n层LSTM
encode_dropout = 0.5 # 编码器的dropout概率
decode_dropout = 0.5 # 编码器的dropout概率
model = Seq2Seq(source_word_count, target_word_count, encode_dim, decode_dim, hidden_dim, n_layers, encode_dropout,decode_dropout, device).to(device)# 加载训练好的模型
model.load_state_dict(torch.load("best_model.pth"))
model.eval()模型预测完整代码
提示:预测代码是我们基于训练及验证代码进行改造的,不一定完全正确,可以参考后自行修改~
import torch
import torch.nn as nn
import pickleclass Encoder(nn.Module):def __init__(self, input_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.hid_dim = hid_dimself.n_layers = n_layersself.embedding = nn.Embedding(input_dim, emb_dim) # 词嵌入self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.dropout = nn.Dropout(dropout)def forward(self, src):# src = (src len, batch size)embedded = self.dropout(self.embedding(src))# embedded = (src len, batch size, emb dim)outputs, (hidden, cell) = self.rnn(embedded)# outputs = (src len, batch size, hid dim * n directions)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# rnn的输出总是来自顶部的隐藏层return hidden, cellclass Decoder(nn.Module):def __init__(self, output_dim, emb_dim, hid_dim, n_layers, dropout):super().__init__()self.output_dim = output_dimself.hid_dim = hid_dimself.n_layers = n_layersself.embedding = nn.Embedding(output_dim, emb_dim)self.rnn = nn.LSTM(emb_dim, hid_dim, n_layers, dropout=dropout)self.fc_out = nn.Linear(hid_dim, output_dim)self.dropout = nn.Dropout(dropout)def forward(self, input, hidden, cell):# 各输入的形状# input = (batch size)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# LSTM是单向的 ==> n directions == 1# hidden = (n layers, batch size, hid dim)# cell = (n layers, batch size, hid dim)input = input.unsqueeze(0) # (batch size) --> [1, batch size)embedded = self.dropout(self.embedding(input)) # (1, batch size, emb dim)output, (hidden, cell) = self.rnn(embedded, (hidden, cell))# LSTM理论上的输出形状# output = (seq len, batch size, hid dim * n directions)# hidden = (n layers * n directions, batch size, hid dim)# cell = (n layers * n directions, batch size, hid dim)# 解码器中的序列长度 seq len == 1# 解码器的LSTM是单向的 n directions == 1 则实际上# output = (1, batch size, hid dim)# hidden = (n layers, batch size, hid dim)# cell = (n layers, batch size, hid dim)prediction = self.fc_out(output.squeeze(0))# prediction = (batch size, output dim)return prediction, hidden, cellclass Seq2Seq(nn.Module):def __init__(self, input_word_count, output_word_count, encode_dim, decode_dim, hidden_dim, n_layers,encode_dropout, decode_dropout, device):""":param input_word_count: 英文词表的长度 34737:param output_word_count: 中文词表的长度 4015:param encode_dim: 编码器的词嵌入维度:param decode_dim: 解码器的词嵌入维度:param hidden_dim: LSTM的隐藏层维度:param n_layers: 采用n层LSTM:param encode_dropout: 编码器的dropout概率:param decode_dropout: 编码器的dropout概率:param device: cuda / cpu"""super().__init__()self.encoder = Encoder(input_word_count, encode_dim, hidden_dim, n_layers, encode_dropout)self.decoder = Decoder(output_word_count, decode_dim, hidden_dim, n_layers, decode_dropout)self.device = devicedef forward(self, src):# src = (src len, batch size)# 编码器的隐藏层输出将作为解码器的第一个隐藏层输入hidden, cell = self.encoder(src)# 解码器的第一个输入应该是起始标识符<sos>input = src[0, :] # 取trg的第“0”行所有列 “0”指的是索引pred = [0] # 预测的第一个输出应该是起始标识符top1 = 0while top1 != 1 and len(pred) < 100:# 解码器的输入包括:起始标识符的词嵌入input; 编码器输出的 hidden and cell states# 解码器的输出包括:输出张量(predictions) and new hidden and cell statesoutput, hidden, cell = self.decoder(input, hidden, cell)top1 = output.argmax(dim=1) # (batch size, )pred.append(top1.item())input = top1return predif __name__ == '__main__':sentence = 'I am Dave Gallo.'en_words = []for w in sentence.split(' '): # 英文内容按照空格字符进行分词# 按照空格进行分词后,某些单词后面会跟着标点符号 "." 和 “,”w = w.replace('.', '').replace(',', '') # 去掉跟单词连着的标点符号w = w.lower() # 统一单词大小写if w:en_words.append(w)print(en_words)with open("en2id.pkl", 'rb') as f:en2id = pickle.load(f)with open("zh2id.pkl", 'rb') as f:zh2id = pickle.load(f)device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu') # GPU可用 用GPU# Seq2Seq模型实例化source_word_count = 34737 # 英文词表的长度 34737target_word_count = 4015 # 中文词表的长度 4015encode_dim = 256 # 编码器的词嵌入维度decode_dim = 256 # 解码器的词嵌入维度hidden_dim = 512 # LSTM的隐藏层维度n_layers = 2 # 采用n层LSTMencode_dropout = 0.5 # 编码器的dropout概率decode_dropout = 0.5 # 编码器的dropout概率model = Seq2Seq(source_word_count, target_word_count, encode_dim, decode_dim, hidden_dim, n_layers, encode_dropout,decode_dropout, device).to(device)model.load_state_dict(torch.load("best_model.pth"))model.eval()src = [0] # 0 --> 起始标识符的编码for i in range(len(en_words)):src.append(en2id[en_words[i]])src = src + [1] # 1 --> 终止标识符的编码text_input = torch.LongTensor(src)text_input = text_input.unsqueeze(-1).to(device)text_output = model(text_input)print(text_output)id2zh = dict()for k, v in zh2id.items():id2zh[v] = ktext_output = [id2zh[index] for index in text_output]text_output = " ".join(text_output)print(text_output)
结束语
- 亲爱的读者,感谢您花时间阅读我们的博客。我们非常重视您的反馈和意见,因此在这里鼓励您对我们的博客进行评论。
- 您的建议和看法对我们来说非常重要,这有助于我们更好地了解您的需求,并提供更高质量的内容和服务。
- 无论您是喜欢我们的博客还是对其有任何疑问或建议,我们都非常期待您的留言。让我们一起互动,共同进步!谢谢您的支持和参与!
- 我会坚持不懈地创作,并持续优化博文质量,为您提供更好的阅读体验。
- 谢谢您的阅读!
相关文章:
PyTorch实战:基于Seq2seq模型处理机器翻译任务(模型预测)
文章目录 引言数据预处理加载字典对象en2id和zh2id文本分词 加载训练好的Seq2Seq模型模型预测完整代码结束语 引言 随着全球化的深入,翻译需求日益增长。传统的人工翻译方式虽然质量高,但效率低,成本高。机器翻译的出现,为解决这…...
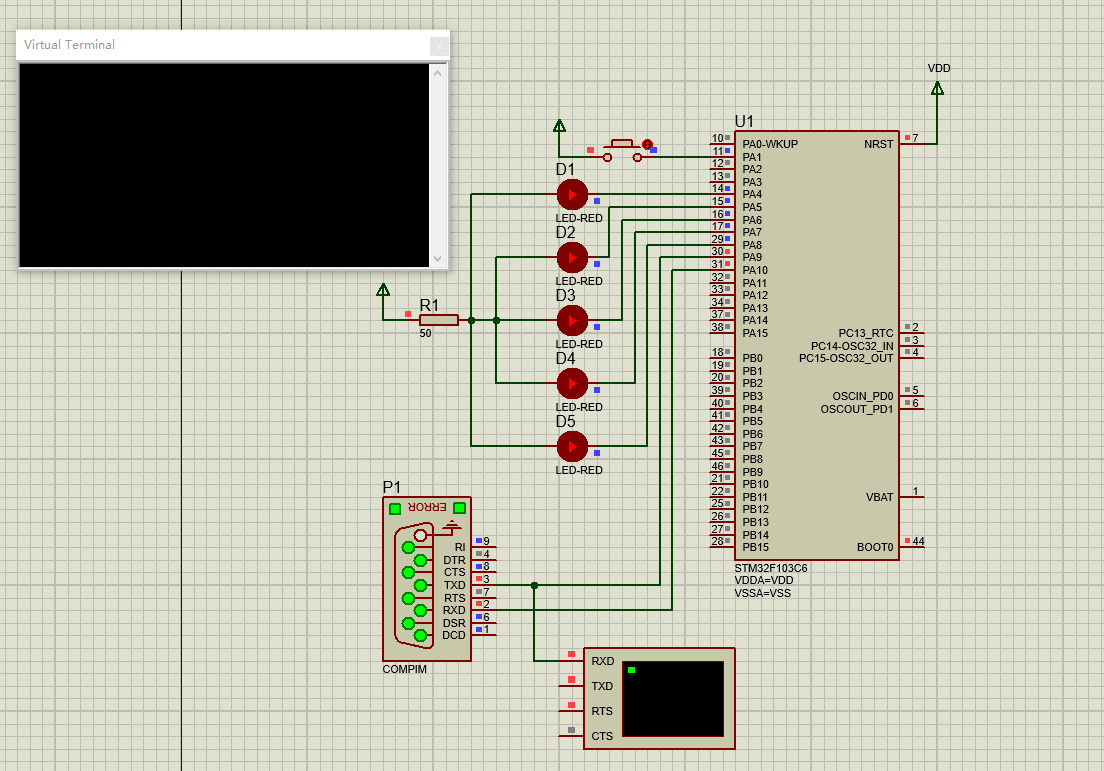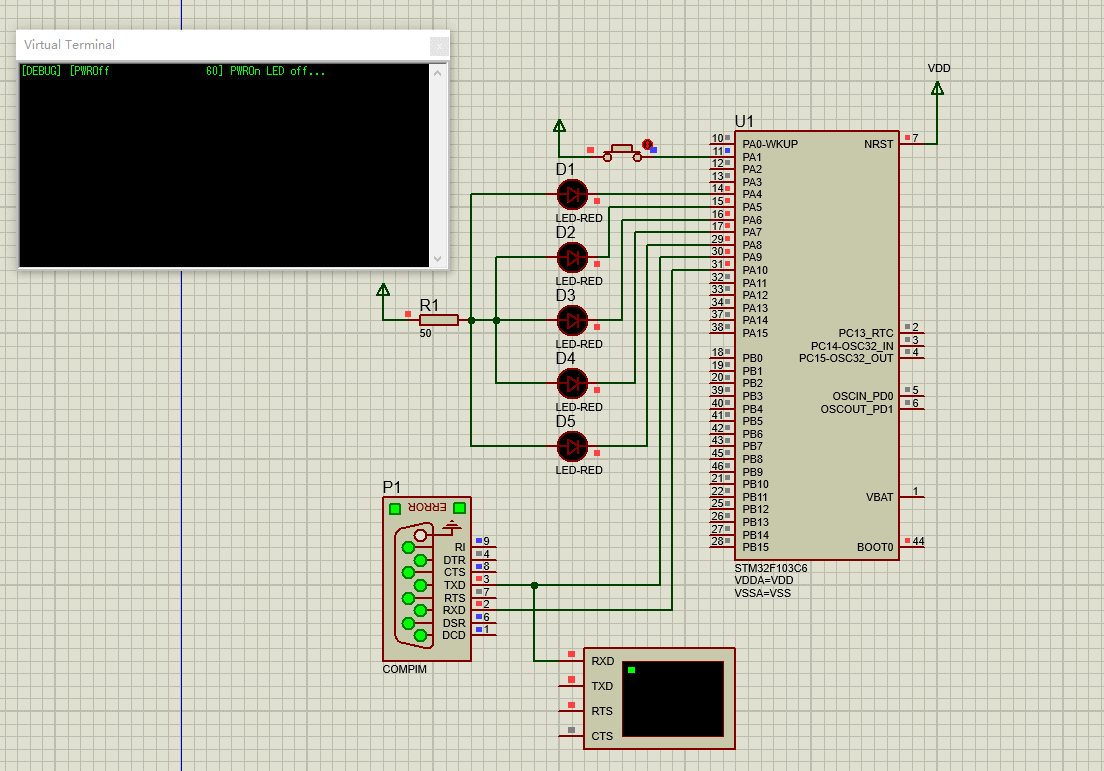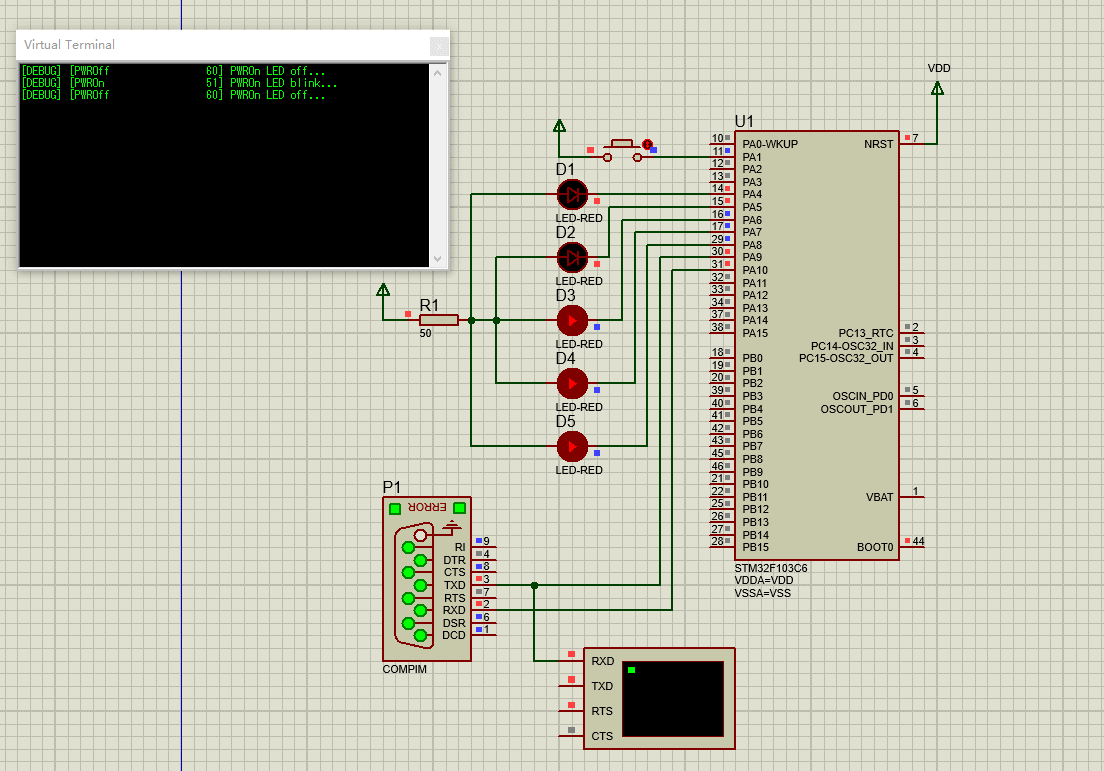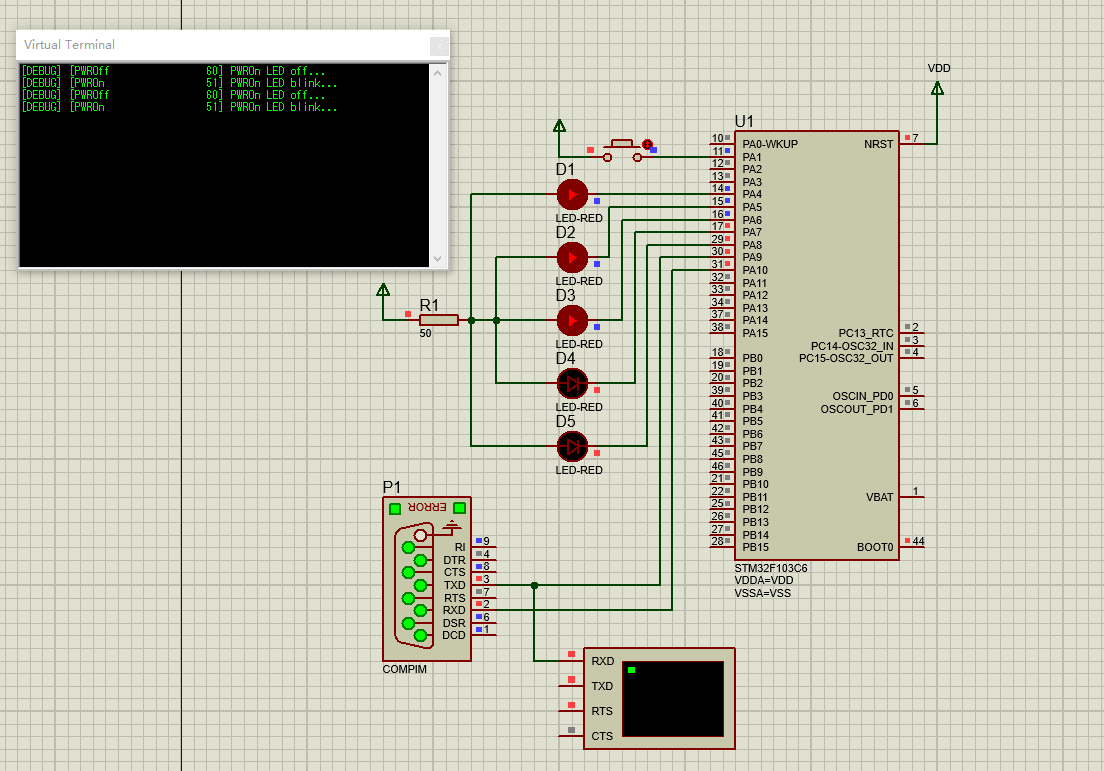
stm32学习总结:5、Proteus8+STM32CubeMX+MDK仿真串口并使用串口打印日志(注意重定向printf到串口打印的问题)
stm32学习总结:5、Proteus8STM32CubeMXMDK仿真串口并使用串口打印日志(注意重定向printf到串口打印的问题) 文章目录 stm32学习总结:5、Proteus8STM32CubeMXMDK仿真串口并使用串口打印日志(注意重定向printf到串口打印…...

SAFe大规模敏捷企业级实训
课程简介 SAFe – Scaled Agile Framework是目前全球运用最广泛的大规模敏捷框架,也是成长最快、最被认可、最有价值的规模化敏捷框架,目前全球SAFe认证专业人士已达80万人,福布斯100强的70%都在实施SAFe。本课程是一个2天的 SAFe权威培训课…...

中医电子处方系统,西医个体诊所门诊卫生室病历记录查询软件教程
中医电子处方系统,西医个体诊所门诊卫生室病历记录查询软件教程 一、软件程序问答 1、电子处方软件如何快速开单? 如下图,软件以 佳易王诊所电子处方管理系统V17.1版本为例说明 在开电子处方的时候可以按单个药品开,也可以直…...
:静电放电之原理图设计)
搞定ESD(八):静电放电之原理图设计
文章目录 一、防护对象识别方法1.1 根据应用手册识别防护对象1.2 根据端口信号类型识别防护对象1.3 根据信号类型识别防护对象二、电路级ESD防护设计2.1 静电尖峰脉冲电压钳位设计(ESD器件并联)2.1.1 高速差分信号ESD防护设计2.1.2 低速信号ESD防护设计2.2 静电放电电流限制设…...

微前端 Micro App
MicroApp 官网链接 MicroApp 链接...

Java amr格式转mp3格式
1.问题描述 微信返回的语音是amr格式的,浏览器不能直接使用,所以需要转为mp3 注意:不能直接使用IO流转为mp3,不然H5还是用不了。转换之后的语音只能在播放器上播放,内里的文件格式其实还是amr 2.使用以下方式转换 音…...

Vue2面试题:说一下虚拟DOM的原理?
虚拟dom是对真实dom的抽象,本质是JS对象 在生成真实DOM之前,vue会把模板编译为一个虚拟dom,当里面某个DOM节点发生变动时,通过diff算法对比新旧虚拟DOM,发现不一样的地方直接修改在真实的DOM上 优点: 可以…...
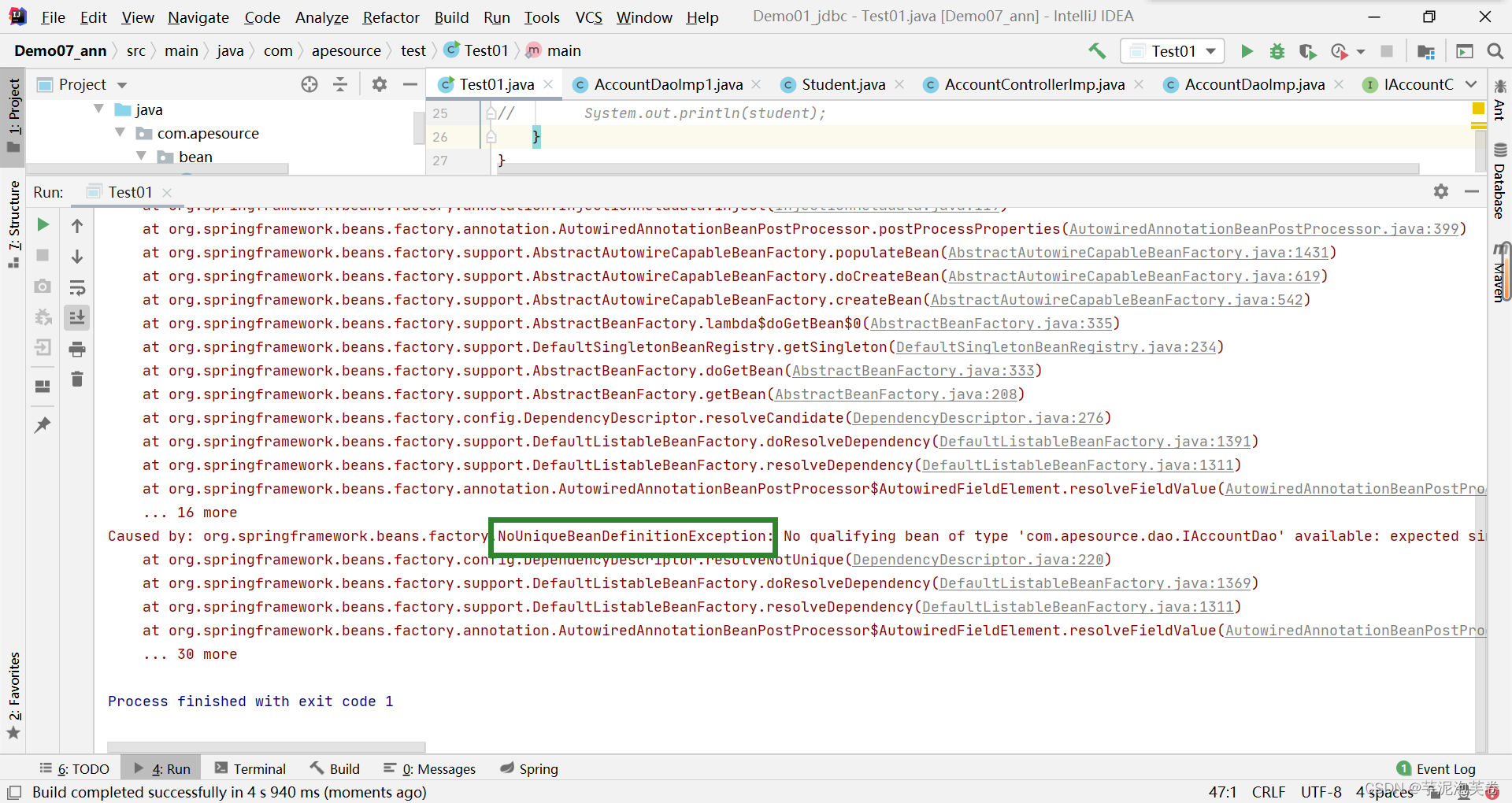
Spring对bean的管理
一.bean的实例化 1.spring通过反射调用类的无参构造方法 在pom.xml文件中导入坐标: <dependencies><dependency><groupId>org.springframework</groupId><artifactId>spring-context</artifactId><version>5.3.29<…...

Character Controller Smooth
流畅的角色控制器 Unity的FPS解决方案! 它是一种具有非常平滑运动和多种设置的解决方案: - 移动和跳跃 - 坐的能力 - 侧翻角度 - 不平整表面的处理 - 惯性守恒 - 重力 - 与物理物体的碰撞。 - 支持没有家长控制的平台 此解决方案适用于那些需要角色控制器…...

企业内训系统源码开发实战:搭建实践与经验分享
本篇文章中,小编将带领读者深入探讨企业内训系统的源码开发实战,分享在搭建过程中遇到的挑战与解决方案。 一、项目规划与需求分析 通过对企业内训需求的深入了解,我们可以更好地定义系统架构和数据库设计。 二、技术栈选择 在内训系统开发…...
)
15.三数之和(双指针,C解答附详细分析)
题目描述: 给你一个整数数组 nums ,判断是否存在三元组 [nums[i], nums[j], nums[k]] 满足 i ! j、i ! k 且 j ! k ,同时还满足 nums[i] nums[j] nums[k] 0 。请 你返回所有和为 0 且不重复的三元组。 注意:答案中不可以包含…...

SpringCloud微服务 【实用篇】| Dockerfile自定义镜像、DockerCompose
目录 一:Dockerfile自定义镜像 1. 镜像结构 2. Dockerfile语法 3. 构建Java项目 二: Docker-Compose 1. 初识DockerCompose 2. 部署微服务集群 前些天突然发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,…...
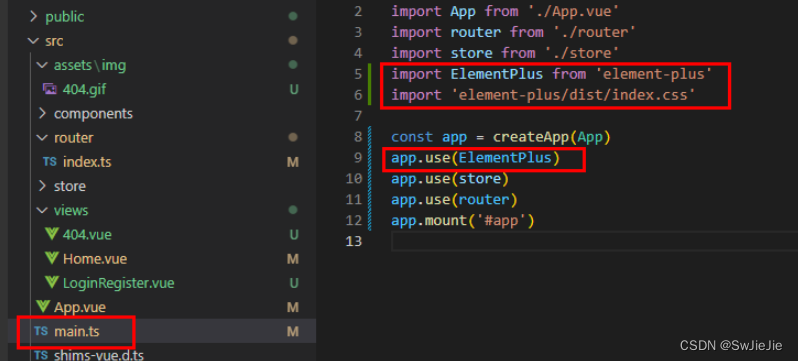
Vue3+TS+ElementPlus的安装和使用教程【详细讲解】
前言 本文简单的介绍一下vue3框架的搭建和有关vue3技术栈的使用。通过本文学习我们可以自己独立搭建一个简单项目和vue3的实战。 随着前端的日月更新,技术的不断迭代提高,如今新vue项目首选用vue3 typescript vite pinia……模式。以前我们通常使用…...
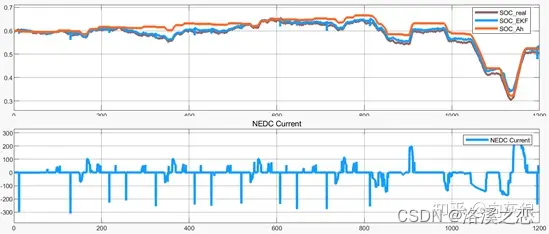
浅析锂电池保护板(BMS)系统设计思路(四)SOC算法-扩展Kalman滤波算法
BMS开发板 1 SOC估算方法介绍 电池SOC的估算是电池管理系统的核心,自从动力电池出现以来,各种各样的电池SOC估算方法不断出现。随着电池管理系统的逐渐升级,电池SOC估算方法的效率与精度不断提高,下面将介绍常用几种电池SOC估算方…...

构建异步高并发服务器:Netty与Spring Boot的完美结合
前言 「作者主页」:雪碧有白泡泡 「个人网站」:雪碧的个人网站 ChatGPT体验地址 文章目录 前言IONetty1. 引入依赖2. 服务端4. 客户端结果 总结引导类-Bootstarp和ServerBootstrap连接-NioSocketChannel事件组-EventLoopGroup和NioEventLoopGroup 送书…...
)
uniapp实现文字超出宽度自动滚动(在宽度范围之内不滚动、是否自动滚动、点击滚动暂停)
效果如下: 文字滚动 组件代码: <template><view class="tip" id="tip" @tap.stop="clickMove"><view class=...

win11 电脑睡眠功能失效了如何修复 win11 禁止鼠标唤醒
1、win11睡眠不管用怎么办,win11电脑睡眠功能失效了如何修复 在win11系统中拥有许多令人激动的新功能和改进,有些用户在使用win11电脑时可能会遇到一个问题:睡眠模式不起作用。当他们尝试将计算机置于睡眠状态时,却发现系统无法进…...

内坐标转换计算
前言 化学这边的库太多了。 cs这边的库太少了。 去看化学的库太累了。 写一个简单的实现思路,让cs的人能看懂。 向量夹角的范围 [0, pi) 这是合理的。 因为两个向量只能构成一个平面系统,平面系统内的夹角不能超过pi。 二面角的范围 涉及二面角&…...

vue中 components自动注册,不需要一个个引入注册方法
1.在compontents文件夹新建js文件 componentRegister 不能引用文件夹里的组件** import Vue from "vue"; function capitalizeFirstLetter(string) { return string.charAt(0).toUpperCase() string.slice(1); } const requireComponent require.context( ".…...

大模型集体“消极怠工”上热搜:你的AI,是不是也开始摆烂了?
文章目录前言一、实测现场:谁是摆烂之王?二、从“拒绝关机”到“罢工写代码”:全球AI都在摸鱼三、“摆烂”的三重面具:你的AI到底在搞什么鬼?四、技术、成本与安全的“不可能三角”五、用户自救指南:如何让…...
)
RTKLIB实战:从零搭建无人机高精度定位系统(附避坑指南)
RTKLIB实战:从零搭建无人机高精度定位系统(附避坑指南) 去年夏天,我带着一台自己组装的四旋翼无人机去山区做地形测绘。当时手头只有普通的消费级GPS模块,飞了几次,发现生成的点云图总是对不上,…...

ccmusic-database一文详解:为何选择CQT而非STFT?VGG19_BN在音频视觉化任务中的优势解析
ccmusic-database一文详解:为何选择CQT而非STFT?VGG19_BN在音频视觉化任务中的优势解析 1. 项目概述:音乐流派分类的创新方案 ccmusic-database是一个基于深度学习的音乐流派自动分类系统,能够准确识别16种不同的音乐流派。这个…...

恒压供水系统实战笔记:西门子全家桶开发实录
全套西门子恒压供水,图纸及程序 西门子plc,smart200触摸屏包含昆仑通泰触摸屏。 恒压供水全套图纸 三拖三全套程序 图纸功能:带超压,缺水保护,模拟量控制变频器最近刚做完一个三泵轮换的恒压供水项目,用到了西门子S…...
)
青蛙跳台阶解密:C语言实现(26.3.13)
#define _CRT_SECURE_NO_WARNINGS #include<stdio.h>int main() {int n 0;int i 0;int a 1;int b 2;int c 0;printf("请输入台阶数\n");scanf("%d", &n);if (n 1)printf("有一种跳法\n");else if (n 2)printf("有2种跳…...

WHAT - 缓存命中 Cache Hit 和缓存未命中 Cache Miss
文章目录一、什么是缓存命中二、前端开发要知道哪些缓存机制(以及命中条件)1. 浏览器缓存(主要针对静态资源)常见的缓存位置关键 HTTP 头字段(决定命中与否)2. 前端应用层缓存(例如数据请求&…...

MEMS惯性导航单元标定与测试的实践指南:从理论到代码实现
1. 为什么你的MEMS惯导不准?从“体检”开始说起 大家好,我是老张,在机器人导航这行摸爬滚打了十几年,用过、拆过、也标定过无数个MEMS惯性导航单元。我发现很多刚入行的工程师,包括一些做无人机、自动驾驶小车或者手持…...
)
Mac用户福音:无需Root实现Android屏幕共享与远程控制的完整指南(附常见问题解决)
Mac用户福音:无需Root实现Android屏幕共享与远程控制的完整指南(附常见问题解决) 作为一名长期在Mac生态下工作的开发者或效率追求者,你是否曾为无法在Mac电脑上流畅地查看和控制Android手机屏幕而烦恼?无论是为了演示…...

LabelMe批量格式转换工具:JSON到其他格式的高效处理
LabelMe批量格式转换工具:JSON到其他格式的高效处理 【免费下载链接】labelme Image Polygonal Annotation with Python (polygon, rectangle, circle, line, point and image-level flag annotation). 项目地址: https://gitcode.com/gh_mirrors/lab/labelme …...

Solarized for PowerShell:Windows命令行的色彩革命
Solarized for PowerShell:Windows命令行的色彩革命 【免费下载链接】solarized precision color scheme for multiple applications (terminal, vim, etc.) with both dark/light modes 项目地址: https://gitcode.com/gh_mirrors/so/solarized Solarized是…...