无监督关键词提取算法:TF-IDF、TextRank、RAKE、YAKE、 keyBERT
TF-IDF
TF-IDF是一种经典的基于统计的方法,TF(Term frequency)是指一个单词在一个文档中出现的次数,通常一个单词在一个文档中出现的次数越多说明该词越重要。IDF(Inverse document frequency)是所有文档数比上出现某单词的个数,通常一个单词在整个文本集合中出现的文本数越少,这个单词就越能表示其所在文本的特点,重要性就越高;IDF计算一般会再取对数,设总文档数为N,出现单词t的文档数为 d f t df_t dft(为了防止分母为0,一般会对分母加一):
i d f t = l o g N d f t + 1 idf_t = log \frac{N}{df_t + 1} idft=logdft+1N
TF-IDF是TF和IDF两部分的乘积,是一个综合重要度,通常IDF会在尽可能大的文档集合来计算得出。TF-IDF的好处是原理简单好解释,但是因为使用了词频来衡量词的重要性,可能会漏掉一些出现次数不多但是相对重要的词,另外它也没有考虑到单词的位置信息。
使用Scikit-Learns利用TF-IDF提取关键词的代码如下:
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizerdef sort_coo(coo_matrix):tuples = zip(coo_matrix.col, coo_matrix.data)return sorted(tuples, key=lambda x: (x[1], x[0]), reverse=True)
def extract_topn_from_vector(feature_names, sorted_items, topn=10):"""get the feature names and tf-idf score of top n items"""#use only topn items from vectorsorted_items = sorted_items[:topn]score_vals = []feature_vals = []for idx, score in sorted_items:fname = feature_names[idx]#keep track of feature name and its corresponding scorescore_vals.append(round(score, 3))feature_vals.append(feature_names[idx])#create a tuples of feature,score#results = zip(feature_vals,score_vals)results= {}for idx in range(len(feature_vals)):results[feature_vals[idx]]=score_vals[idx]return json.dumps(results)#docs 集合,如果是中文可以先分词或者在CountVectorizer里定义tokenizer
docs=[]#创建单词词汇表, 忽略在85%的文档中出现的词
cv=CountVectorizer(max_df=0.85)
word_count_vector=cv.fit_transform(docs)
print(word_count_vector.shape)tfidf_transformer=TfidfTransformer(smooth_idf=True,use_idf=True)
tfidf_transformer.fit(word_count_vector)
tfidf_transformer.idf_# 单词名
feature_names=cv.get_feature_names_out()
# tf-idf计算
tf_idf_vector=tfidf_transformer.transform(word_count_vector)results=[]
for i in range(tf_idf_vector.shape[0]):# 获取单个文档的向量curr_vector=tf_idf_vector[i]#根据tfidf分数对向量进行排序sorted_items=sort_coo(curr_vector.tocoo())# 取top 10 的关键词keywords=extract_topn_from_vector(feature_names, sorted_items, 10) results.append(keywords)
TextRank
TextRank 出自2004年的论文《TextRank: Bringing Order into Text》,它是一种基于图的排序算法,其思想借鉴了PageRank算法(当然除了PageRank之外,也可以用其他的图排序算法来计算节点的权重)。
使用TextRank进行关键词提取的步骤如下:
-
对文本进行分词,并对单词进行词性标注,只保留指定词性如名词和动词作为图的节点。
-
根据单词之间的共现关系进行构图:使用一个大小为N的滑动窗口(N一般取2到10),如果两个节点同时出现在一个滑动窗口中,则说明两个节点之间可以构成一条边。具体构图时按是否考虑单词之间的先后顺序来构建无向图或有向图,按照是否考虑单词之间共现次数构建加权图或无权重图。
-
对已经构建好的图按照下式来迭代计算重要度直到收敛,式中d是阻尼系数,取值为[0, 1],一般取0.85。 I n ( V i ) In(V_i) In(Vi)表示某节点的入边集合, O u t ( V j ) Out(V_j) Out(Vj)表示某节点的出边集合, w j i w_{ji} wji是节点j到i的权重,对于无权图 w j i = 1 w_{ji}=1 wji=1。
W S ( V i ) = ( 1 − d ) + d ∗ ∑ V j ∈ I n ( V i ) w j i ∑ V k ∈ O u t ( V j ) w j k W S ( V j ) WS(V_i) = (1-d) + d\ * \sum_{V_j \in In(V_i)} \frac{w_{ji}}{\sum_{V_k \in Out(V_j)} w_{jk}} WS(V_j) WS(Vi)=(1−d)+d ∗Vj∈In(Vi)∑∑Vk∈Out(Vj)wjkwjiWS(Vj) -
按照计算好的重要度进行倒序排序,挑选出重要度最大的T个词(T可考虑根据根据文本长度来决定),并将挑选出的词还原到原文本中,将位置相邻的词合并成一个词。
TextRank相比于TF-IDF考虑了词汇之间的关系,把文章中的词组成了一个图,从全局角度来考虑不同词的重要性。
RAKE
RAKE(rapid automatic keyword extraction)出自2010年的论文《Automatic Keyword Extraction from Individual Documents》,作者们基于关键词一般包括多个单词并且不包含停用词标点符号的观察,提出了RAKE算法。
- RAKE首先用停用词和标点符号将文本分割成候选词序列
Compatibility of systems of linear constraints over the set of natural numbers Criteria of compatibility of a system of linear Diophantine equations, strict inequations, and nonstrict inequations are considered. Upper bounds for components of a minimal set of solutions and algorithms of construction of minimal generating sets of solutions for all types of systems are given. These criteria and the corresponding algorithms for constructing a minimal supporting set of solutions can be used in solving all the considered types of systems and systems of mixed types.
对于上面一段文本,分割之后将得到
Compatibility – systems – linear constraints – set – natural numbers – Criteria – compatibility – system – linear Diophantine equations – strict inequations – nonstrict inequations – Upper bounds – components – minimal set – solutions – algorithms – minimal generating sets – solutions – systems – criteria – corresponding algorithms – constructing – minimal supporting set – solving – systems – systems
-
对分割得到的候选词序列生成词共现图,也就是如果两个词同时出现,两者之间就构成一条边,并计算每个词之间的共现次数。比如上面的例子得到的图对应的邻接矩阵示意如下(对角线即每个单词本身出现的次数,图片来自论文):

-
计算每个关键词的分数,设每个单词的词频为 f r e q ( w ) freq(w) freq(w),单词在生成的图里对应的度为 d e g ( w ) deg(w) deg(w),则每个单词的分数为 d e g ( w ) / f r e q ( w ) deg(w)/freq(w) deg(w)/freq(w),而每个候选关键词的分数为其所有单词之和。上面例子中对应的计算结果如下图:

- 考虑到有时候关键词可能会包括停用词,比如“axis of evil”,RAKE规定如果一对候选关键词出现在文章中相邻的位置至少2次以上,就将他们合并成一个关键词,其分数是其合并前的关键词分数之和。
- 挑选出分数最大的T个词作为关键词。
YAKE
YAKE出自2018年的论文《A Text Feature Based Automatic Keyword Extraction Method for Single Documents》且有开源github。
YAKE是一种基于统计的关键词提取方法,分成四个主要的部分:(1) 文本预处理;(2) 特征提取;(3)单词权重计算;(4)候选关键词生成。
-
文本预处理,因为这篇论文提出背景主要使用于西方文字系统,所以仅仅使用空格或其他字符如括号逗号句号等将文本切分成单个单词。
-
特征提取,提出了5种特征来捕获每个term的特征。
-
Casing( W C a s e W_{Case} WCase): 关注一个词以大写字母开头(句子中以大写字母开头的词不算)或是缩略词(一个词全部由大写字母组成)的次数。设 T F ( U ( w ) ) TF(U(w)) TF(U(w))是单词w以大写字母开头的次数, T F ( A ( w ) ) TF(A(w)) TF(A(w))是单词w被标记为缩略词的次数, T F ( w ) TF(w) TF(w)是单词w的词频:
W C a s e = m a x ( T F ( U ( w ) ) , T F ( A ( w ) ) ) l o g 2 ( T F ( w ) ) W_{Case} = \frac {max(TF(U(w)), TF(A(w)))}{log_2(TF(w))} WCase=log2(TF(w))max(TF(U(w)),TF(A(w))) -
Word Position( W P o s i t i o n W_{Position} WPosition):单词在文档中的位置可能是一个关键词提取的重要特征,因为通常出现在文档前面的单词是关键词的概率更大。设 M e d i a n Median Median是中位数, S e n w Sen_w Senw是单词w出现过的句子集的位置。 W P o s i t i o n W_{Position} WPosition 的定义如下(定义中的2是为了保证 W P o s i t i o n > 0 W_{Position}>0 WPosition>0):
W P o s i t i o n = l o g 2 ( l o g 2 ( 2 + M e d i a n ( S e n w ) ) ) W_{Position} = log_2(log_2(2 + Median(Sen_w))) WPosition=log2(log2(2+Median(Senw))) -
Word Frequency( W F r e q W_{Freq} WFreq):通常一个单词出现越多说明其越重要,为了减少因为长文档使词频偏大的偏差,计算词频时将除去平均词频(MeanTF)和词频标准差( σ \sigma σ)之和:
W F r e q = T F ( w ) M e a n T F + 1 ∗ σ W_{Freq} = \frac{TF(w)} {MeanTF + 1*\sigma } WFreq=MeanTF+1∗σTF(w) -
Word Relatedness to Context( W R e l W_{Rel} WRel):量化一个词是否与停用词相似。设WL[WR]是候选单词w左侧(右侧)n大小窗口内与候选单词共现的不同单词的个数比上与候选单词共现过的所有单词的个数。 TF是单词w的词频,MaxTF是所有单词里的最大词频。PL[PR]是候选单词w左侧(右侧)n大小窗口内与候选单词共现的不同单词的个数比上MaxTF,与停用词相似的单词的分数会越大:
W R e l = ( 0.5 + ( ( W L ∗ T F ( w ) M a x T F ) + P L ) ) + ( 0.5 + ( ( W R ∗ T F ( w ) M a x T F ) + P R ) ) W_{Rel} = \left( 0.5 + \left( \left( WL * \frac{TF(w)}{MaxTF} \right) + PL \right) \right) + \left( 0.5 + \left( \left( WR * \frac{TF(w)}{MaxTF} \right) + PR \right) \right) WRel=(0.5+((WL∗MaxTFTF(w))+PL))+(0.5+((WR∗MaxTFTF(w))+PR)) -
Word DifSentence( W D i f S e n t e n c e ) W_{DifSentence}) WDifSentence)):量化一个单词在不同句子中出现的次数, S F ( w ) SF(w) SF(w)是单词w出现在句子中的频次, # S e n t e n c e s \#Sentences #Sentences 是文本中的总句子数。
W D i f S e n t e n c e = S F ( w ) # S e n t e n c e s W_{DifSentence} = \frac {SF(w)} {\#Sentences} WDifSentence=#SentencesSF(w)
-
单词权重计算: 按照下式来计算每个单词w的分数 S ( w ) S(w) S(w), S ( w ) S(w) S(w)越小,则单词w越重要。
S ( w ) = W R e l ∗ W P o s i t i o n W C a s e + W F r e q W R e l + W D i f S e n t e n c e W R e l S(w) = \frac {W_{Rel} * W_{Position}} {W_{Case} + \frac{W_{Freq}}{W_{Rel}} + \frac{W_{DifSentence}}{W_{Rel}} } S(w)=WCase+WRelWFreq+WRelWDifSentenceWRel∗WPosition -
候选关键词生成: 因为关键词通常不仅仅由一个单词构成,所以使用一个大小为3的滑动窗口,不考虑停用词,生成长度为1、2、3的候选关键词,每个候选关键词的分数 S ( k w ) S(kw) S(kw)(越小越重要)计算如下:
S ( k w ) = ∏ w ∈ k w S ( w ) T F ( k w ) ∗ ( 1 + ∑ w ∈ k w S ( w ) ) S(kw) = \frac {\prod_{w \in kw} S(w)} {TF(kw) * (1 + \sum_{w \in kw} S(w))} S(kw)=TF(kw)∗(1+∑w∈kwS(w))∏w∈kwS(w)
为了过滤掉相似候选词,使用编辑距离Levenshtein distance来判断两个候选词的相似性,如果相似性高于指定阈值,则只保留 S ( k w ) S(kw) S(kw)更低的候选词。最后算法将输出一个重要性靠前的关键词列表。
keyBERT
keyBERT是一个使用BERT embedding向量来生成关键词的工具,其思路是对文档用BERT编码成向量,再将文档使用Scikit-Learns 的 CountVectorizer 对文档进行分词,然后比较文档中的每个单词向量与文档向量之间的相似度,选择相似度最大的一些词作为关键词。
其基本用法:
from keybert import KeyBERT# 英文文档关键词提取示例,不指定embedding模型,默认使用sentence-transformers的all-MiniLM-L6-v2模型
doc = """
When we want to understand key information from specific documents, we typically turn towards keyword extraction. Keyword extraction is the automated process of extracting the words and phrases that are most relevant to an input text."""
kw_model = KeyBERT()
keywords = kw_model.extract_keywords(doc)# 中文文档关键词提取示例
# 中文需要自定义CountVectorizer,并为它指定分词器,比如下面示例中使用了jieba来分词
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def tokenize_zh(text):words = jieba.lcut(text)return words
vectorizer = CountVectorizer(tokenizer=tokenize_zh)
kw_model = KeyBERT(model='paraphrase-multilingual-MiniLM-L12-v2')
doc = """强化学习是机器通过与环境交互来实现目标的一种计算方法。机器和环境的一轮交互是指,机器在环境的一个状态下做一个动作决策,把这个动作作用到环境当中,这个环境发生相应的改变并且将相应的奖励反馈和下一轮状态传回机器。这种交互是迭代进行的,机器的目标是最大化在多轮交互过程中获得的累积奖励的期望。"""
keywords = kw_model.extract_keywords(doc, vectorizer=vectorizer)
如果我们只选择那些与文档最相似的一些词来作为关键词,很可能会使挑选出的关键词之间的相似度比较高,所以keyBert的作者实现了下面两种来算法来使选择的关键词更多样化一些:
-
Max Sum Distance:设生成关键词个数为 t o p _ n top\_n top_n, 选择一个比 t o p _ n top\_n top_n大的数 n r _ c a n d i d a t e s nr\_candidates nr_candidates,先从文档中挑选出与文档最相似的 n r _ c a n d i d a t e s nr\_candidates nr_candidates个候选词,然后从 n r _ c a n d i d a t e s nr\_candidates nr_candidates个词选择 t o p _ n top\_n top_n个词的所有组合中选择两两相似度之和最小的组合作为返回的关键词。因此 n r _ c a n d i d a t e s nr\_candidates nr_candidates越大选择出来的关键词更多样化,但也可能会选择出一些并不能代表文档的词,作者的建议是 n r _ c a n d i d a t e s nr\_candidates nr_candidates不要超过文档中词汇个数的20%。
# 代码来自keyBERT 源码 https://github.com/MaartenGr/KeyBERT/blob/master/keybert/_maxsum.py import numpy as np import itertools from sklearn.metrics.pairwise import cosine_similarity from typing import List, Tupledef max_sum_distance(doc_embedding: np.ndarray,word_embeddings: np.ndarray,words: List[str],top_n: int,nr_candidates: int, ) -> List[Tuple[str, float]]:"""Calculate Max Sum Distance for extraction of keywordsWe take the 2 x top_n most similar words/phrases to the document.Then, we take all top_n combinations from the 2 x top_n words andextract the combination that are the least similar to each otherby cosine similarity.This is O(n^2) and therefore not advised if you use a large `top_n`Arguments:doc_embedding: The document embeddingsword_embeddings: The embeddings of the selected candidate keywords/phraseswords: The selected candidate keywords/keyphrasestop_n: The number of keywords/keyhprases to returnnr_candidates: The number of candidates to considerReturns:List[Tuple[str, float]]: The selected keywords/keyphrases with their distances"""if nr_candidates < top_n:raise Exception("Make sure that the number of candidates exceeds the number ""of keywords to return.")elif top_n > len(words):return []# Calculate distances and extract keywordsdistances = cosine_similarity(doc_embedding, word_embeddings)distances_words = cosine_similarity(word_embeddings, word_embeddings)# Get 2*top_n words as candidates based on cosine similaritywords_idx = list(distances.argsort()[0][-nr_candidates:])words_vals = [words[index] for index in words_idx]candidates = distances_words[np.ix_(words_idx, words_idx)]# Calculate the combination of words that are the least similar to each othermin_sim = 100_000candidate = Nonefor combination in itertools.combinations(range(len(words_idx)), top_n):sim = sum([candidates[i][j] for i in combination for j in combination if i != j])if sim < min_sim:candidate = combinationmin_sim = simreturn [(words_vals[idx], round(float(distances[0][words_idx[idx]]), 4))for idx in candidate] -
Maximal Marginal Relevance (MMR):除了使关键词与文档尽可能的相似之外,同时降低关键词之间的相似性或者冗余度。参数diversity来控制候选词的多样性,diversity越小,则候选关键词之间可能更相似,而diversity越大,则关键词之间的冗余度更小。算法具体为:1. 先生成候选词与文档相似度矩阵、候选词之间的相似度矩阵。2. 挑选与文档最相似的候选词作为第一个关键词。3. 其余关键词逐一挑选,挑选规则为:设剩余候选词与文档相似性矩阵为 c a n _ s i m can\_sim can_sim,剩余候选词与已挑选的关键词最大相似度矩阵为 t a r _ s i m tar\_sim tar_sim,按公式 m m r = ( 1 − d i v e r s i t y ) ∗ c a n _ s i m − d i v e r s i t y ∗ t a r _ s i m mmr = (1-diversity)*can\_sim - diversity*tar\_sim mmr=(1−diversity)∗can_sim−diversity∗tar_sim 计算mmr,挑选mmr最大的候选词作为下一个关键词。
# 代码来自keyBERT 源码 https://github.com/MaartenGr/KeyBERT/blob/master/keybert/_mmr.py
def mmr(doc_embedding: np.ndarray,word_embeddings: np.ndarray,words: List[str],top_n: int = 5,diversity: float = 0.8,
) -> List[Tuple[str, float]]:"""Calculate Maximal Marginal Relevance (MMR)between candidate keywords and the document.MMR considers the similarity of keywords/keyphrases with thedocument, along with the similarity of already selectedkeywords and keyphrases. This results in a selection of keywordsthat maximize their within diversity with respect to the document.Arguments:doc_embedding: The document embeddingsword_embeddings: The embeddings of the selected candidate keywords/phraseswords: The selected candidate keywords/keyphrasestop_n: The number of keywords/keyhprases to returndiversity: How diverse the select keywords/keyphrases are.Values between 0 and 1 with 0 being not diverse at alland 1 being most diverse.Returns:List[Tuple[str, float]]: The selected keywords/keyphrases with their distances"""# Extract similarity within words, and between words and the documentword_doc_similarity = cosine_similarity(word_embeddings, doc_embedding)word_similarity = cosine_similarity(word_embeddings)# Initialize candidates and already choose best keyword/keyphraskeywords_idx = [np.argmax(word_doc_similarity)]candidates_idx = [i for i in range(len(words)) if i != keywords_idx[0]]for _ in range(min(top_n - 1, len(words) - 1)):# Extract similarities within candidates and# between candidates and selected keywords/phrasescandidate_similarities = word_doc_similarity[candidates_idx, :]target_similarities = np.max(word_similarity[candidates_idx][:, keywords_idx], axis=1)# Calculate MMRmmr = (1 - diversity) * candidate_similarities - diversity * target_similarities.reshape(-1, 1)mmr_idx = candidates_idx[np.argmax(mmr)]# Update keywords & candidateskeywords_idx.append(mmr_idx)candidates_idx.remove(mmr_idx)# Extract and sort keywords in descending similaritykeywords = [(words[idx], round(float(word_doc_similarity.reshape(1, -1)[0][idx]), 4))for idx in keywords_idx]keywords = sorted(keywords, key=itemgetter(1), reverse=True)return keywords
理解了keyBERT的原理后,就发现keyBERT提取关键词的效果十分依赖于向量编码模型的质量,所以需要根据自己业务情况挑选适合的向量编码模型。
参考资料
-
scikit-learn CountVectorizer文档, scikit-learn TfiidfTransformer 文档,tfidf提取关键字参考代码
-
textrank的论文:TextRank: Bringing Order into Text textrank 的一些实现:textrank, jieba中实现了textrank关键词提取
-
RAKE python实现: RAKE, multi_rake, RAKE-turorial
-
YAKE github
-
keyBERT github, 知乎上关于keyBERT在实际应用的分享
相关文章:
无监督关键词提取算法:TF-IDF、TextRank、RAKE、YAKE、 keyBERT
TF-IDF TF-IDF是一种经典的基于统计的方法,TF(Term frequency)是指一个单词在一个文档中出现的次数,通常一个单词在一个文档中出现的次数越多说明该词越重要。IDF(Inverse document frequency)是所有文档数比上出现某单词的个数,通常一个单词…...

web3 : blockscout剖析
Blockscout 是第一个功能齐全的开源区块链浏览器,可供任何以太坊虚拟机 (EVM) 链使用。项目方可以下载并使用Blockscout作为其链的浏览器,用户可以轻松验证交易、余额、区块确认、智能合约和其他记录。 目录 Blockscout可以做什么主要特征blockscoutDocker容器组件Postgres 1…...

【机器学习基础】DBSCAN
🚀个人主页:为梦而生~ 关注我一起学习吧! 💡专栏:机器学习 欢迎订阅!相对完整的机器学习基础教学! ⭐特别提醒:针对机器学习,特别开始专栏:机器学习python实战…...

计算机硬件 4.4键盘与鼠标
第四节 键盘与鼠标 一、认识键盘 1.地位:计算机系统最基本的输入设备。 2.外观结构:面板、键帽、底盘、数据线。 3.组成键区:主键区、功能键区、辅助键区和编辑(控制)键区。 二、键盘分类 1.按接口分 ①AT口&…...

Flappy Bird QDN PyTorch博客 - 代码解读
Flappy Bird QDN PyTorch博客 - 代码解读 介绍环境配置项目目录结构QDN算法重要函数解读preprocess(observation)DeepNetWork(nn.Module)BirdDQN类主程序部分 介绍 在本博客中,我们将介绍如何使用QDN(Quantile Dueling Network)算法…...

听GPT 讲Rust源代码--compiler(9)
File: rust/compiler/rustc_trait_selection/src/traits/select/mod.rs 在Rust源代码中,rust/compiler/rustc_trait_selection/src/traits/select/mod.rs文件的作用是实现Rust编译器的trait选择器。 首先,让我们逐个介绍这些struct的作用: Se…...

Go语言中关于go get, go install, go build, go run指令
go get go get 它会执行两个操作 第一个, 是先将远程的代码克隆到Go Path的 src 目录那二个, 是执行go install命令 那如果指定的包可以生成二进制文件那它就会把这个二进制文件保存到这个 Go Path 的bin目录下面这是 go install 命令执行的操作 如果只需要下载包,…...

石头剪刀布游戏 - 华为OD统一考试
OD统一考试 分值: 100分 题解: Java / Python / C++ 题目描述 石头剪刀布游戏有 3 种出拳形状: 石头、剪刀、布。分别用字母 A,B,C 表示游戏规则: 出拳形状之间的胜负规则如下: A>B; B>C; C>A; 左边一个字母,表示相对优势形状。右边一个字母,表示相对劣势形状。…...
【北亚服务器数据恢复】ZFS文件系统服务器ZPOOL下线的数据恢复案例
服务器数据恢复环境: 服务器中有32块硬盘,组建了3组RAIDZ,部分磁盘作为热备盘。zfs文件系统。 服务器故障: 服务器运行中突然崩溃,排除断电、进水、异常操作等外部因素。工作人员将服务器重启后发现无法进入操作系统。…...
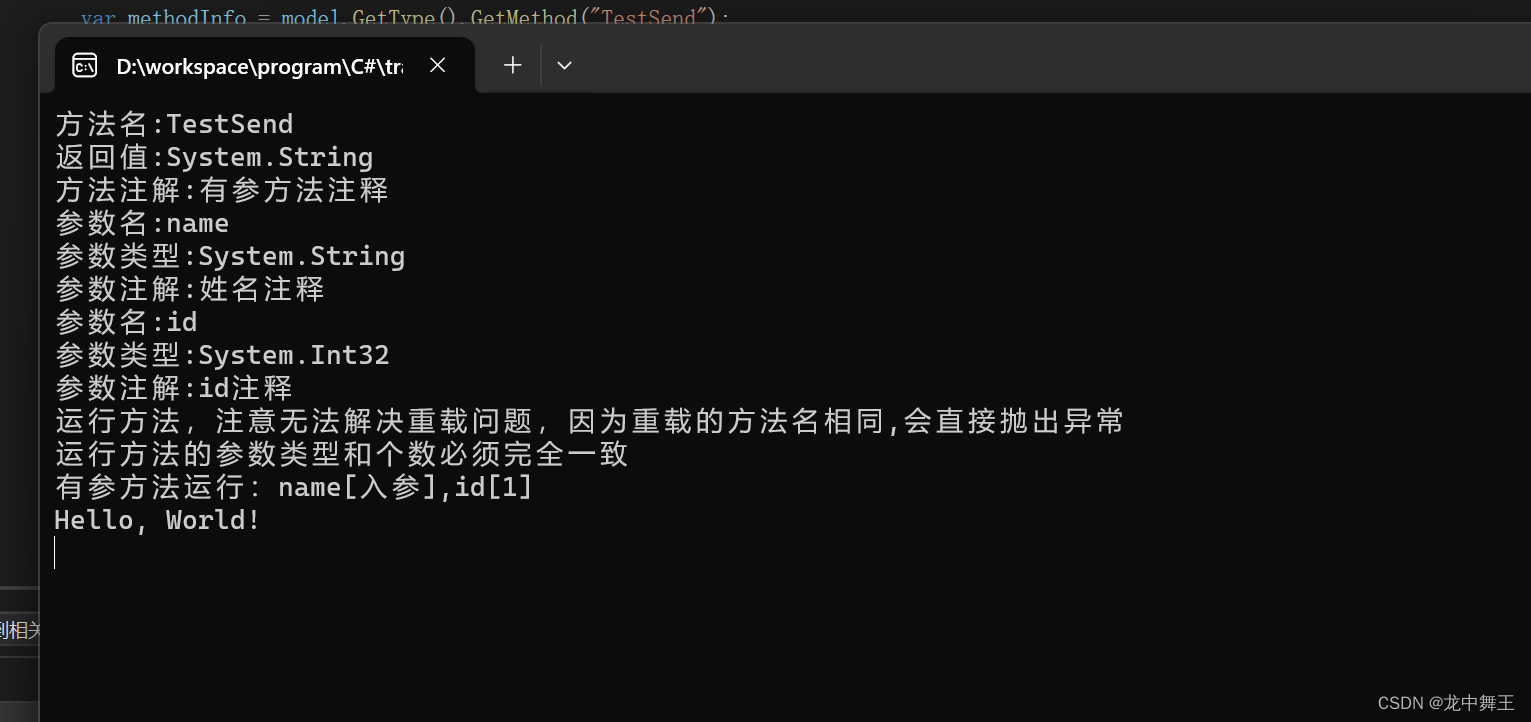
C# 反射的终点:Type,MethodInfo,PropertyInfo,ParameterInfo,Summry
文章目录 前言反射是什么?常用类型操作SummryPropertyInfoMethodInfo无参函数运行 有参函数运行,获取paramterInfo 总结 前言 我之前写了一篇Attribute特性的介绍,成功拿到了Attribute的属性,但是如果把Attribute玩的溜,那就要彻…...

2020年认证杯SPSSPRO杯数学建模D题(第一阶段)让电脑桌面飞起来全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 D题 让电脑桌面飞起来 原题再现: 对于一些必须每天使用电脑工作的白领来说,电脑桌面有着非常特殊的意义,通常一些频繁使用或者比较重要的图标会一直保留在桌面上,但是随着时间的推移,…...

谷歌推出创新SynCLR技术:借助AI生成的数据实现高效图像建模,开启自我训练新纪元!
谷歌推出了一种创新性的合成图像框架,这一框架独特之处在于它完全不依赖真实数据。这个框架首先从合成的图像标题开始,然后基于这些标题生成相应的图像。接下来,通过对比学习的技术进行深度学习,从而训练出能够精准识别和理解这些…...
Vue2中使用echarts,并从后端获取数据同步
一、安装echarts npm install echarts -S 二、导入echarts 在script中导入,比如: import * as echarts from "echarts"; 三、查找要用的示例 比如柱状图 四、初始化并挂载 <template><div id"total-orders-chart" s…...

【Redux】自己动手实现redux-thunk
1. 前言 在原始的redux里面,action必须是plain object,且必须是同步。而我们经常使用到定时器,网络请求等异步操作,而redux-thunk就是为了解决异步动作的问题而出现的。 2. redux-thunk中间件实现源码 function createThunkMidd…...
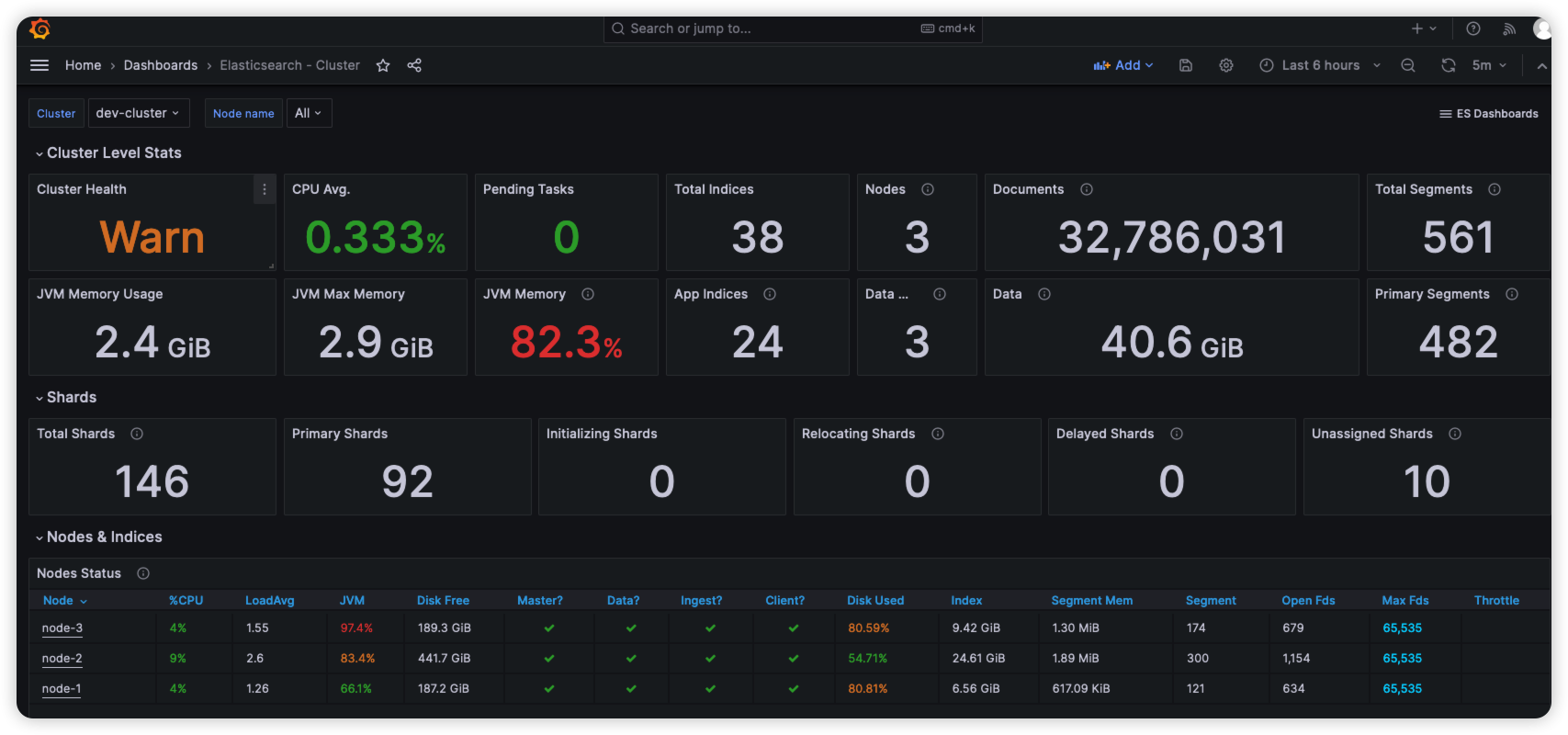
ElasticSearch使用Grafana监控服务状态-Docker版
文章目录 版本信息构建docker-compose.yml参数说明 创建Prometheus配置文件启动验证配置Grafana导入监控模板模板说明 参考资料 版本信息 ElasticSearch:7.14.2 elasticsearch_exporter:1.7.0(latest) 下载地址:http…...
VS Code 如何调试Python文件
VS Code中有1,2,3处跟Run and Debug相关的按钮, 1 处:调试和运行就不多说了,Open Configurations就是打开workspace/.vscode下的lauch.json文件,而Add Configuration就是在lauch.json文件中添加当前运行Python文件的Configuratio…...
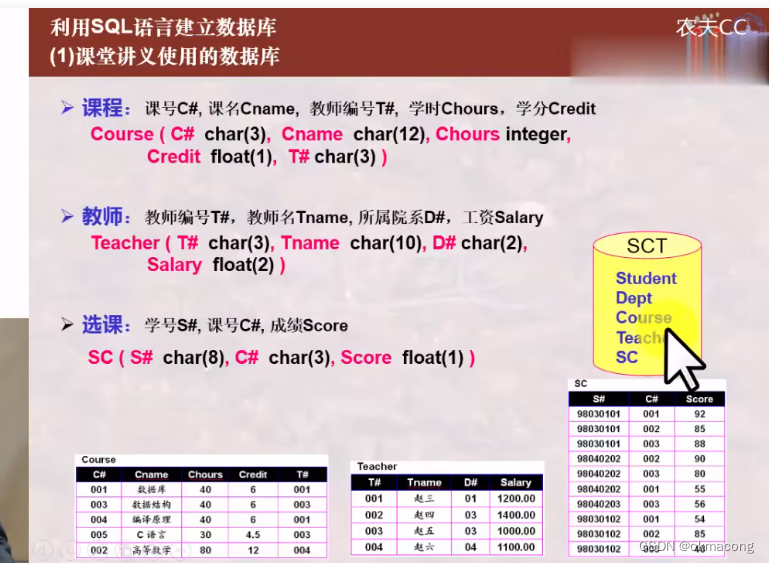
day06、SQL语言之概述
SQl 语言之概述 6.1 SQL语言概述6.2 SQL语言之DDL定义数据库6.3 SQL语言之DML操纵数据库 6.1 SQL语言概述 6.2 SQL语言之DDL定义数据库 6.3 SQL语言之DML操纵数据库...

3D目标检测(教程+代码)
随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。 一、3D目…...

让设备更聪明 |启英泰伦离线自然说,开启智能语音交互新体验!
语音交互按部署方式可以分为两种:离线语音交互和在线语音交互。 在线语音交互是将数据储存在云端,其具备足够大的存储空间和算力,可以实现海量的语音数据处理。 离线语音交互是以语音芯片为载体,语音数据的采集、计算、决策均在…...

React Hooks之useState、useRef
文章目录 React Hooks之useStateReact HooksuseStatedemo:在函数式组件中使用 useState Hook 管理计数器demo:ant-design-pro 中EditableProTable组件使用 useRef React Hooks之useState React Hooks 在 React 16.8 版本中引入了 Hooks,它是…...

Spring Boot面试题精选汇总
🤟致敬读者 🟩感谢阅读🟦笑口常开🟪生日快乐⬛早点睡觉 📘博主相关 🟧博主信息🟨博客首页🟫专栏推荐🟥活动信息 文章目录 Spring Boot面试题精选汇总⚙️ **一、核心概…...

Spring Boot+Neo4j知识图谱实战:3步搭建智能关系网络!
一、引言 在数据驱动的背景下,知识图谱凭借其高效的信息组织能力,正逐步成为各行业应用的关键技术。本文聚焦 Spring Boot与Neo4j图数据库的技术结合,探讨知识图谱开发的实现细节,帮助读者掌握该技术栈在实际项目中的落地方法。 …...

爬虫基础学习day2
# 爬虫设计领域 工商:企查查、天眼查短视频:抖音、快手、西瓜 ---> 飞瓜电商:京东、淘宝、聚美优品、亚马逊 ---> 分析店铺经营决策标题、排名航空:抓取所有航空公司价格 ---> 去哪儿自媒体:采集自媒体数据进…...

PAN/FPN
import torch import torch.nn as nn import torch.nn.functional as F import mathclass LowResQueryHighResKVAttention(nn.Module):"""方案 1: 低分辨率特征 (Query) 查询高分辨率特征 (Key, Value).输出分辨率与低分辨率输入相同。"""def __…...

[大语言模型]在个人电脑上部署ollama 并进行管理,最后配置AI程序开发助手.
ollama官网: 下载 https://ollama.com/ 安装 查看可以使用的模型 https://ollama.com/search 例如 https://ollama.com/library/deepseek-r1/tags # deepseek-r1:7bollama pull deepseek-r1:7b改token数量为409622 16384 ollama命令说明 ollama serve #:…...

MacOS下Homebrew国内镜像加速指南(2025最新国内镜像加速)
macos brew国内镜像加速方法 brew install 加速formula.jws.json下载慢加速 🍺 最新版brew安装慢到怀疑人生?别怕,教你轻松起飞! 最近Homebrew更新至最新版,每次执行 brew 命令时都会自动从官方地址 https://formulae.…...

前端高频面试题2:浏览器/计算机网络
本专栏相关链接 前端高频面试题1:HTML/CSS 前端高频面试题2:浏览器/计算机网络 前端高频面试题3:JavaScript 1.什么是强缓存、协商缓存? 强缓存: 当浏览器请求资源时,首先检查本地缓存是否命中。如果命…...

【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅!
【把数组变成一棵树】有序数组秒变平衡BST,原来可以这么优雅! 🌱 前言:一棵树的浪漫,从数组开始说起 程序员的世界里,数组是最常见的基本结构之一,几乎每种语言、每种算法都少不了它。可你有没有想过,一组看似“线性排列”的有序数组,竟然可以**“长”成一棵平衡的二…...
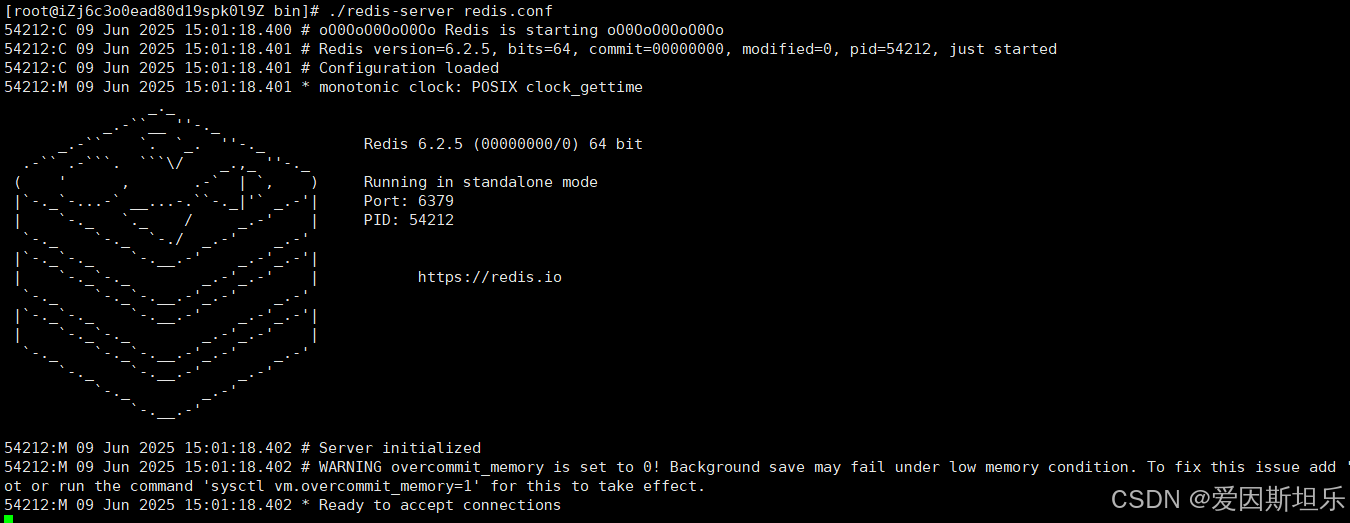
【若依】框架项目部署笔记
参考【SpringBoot】【Vue】项目部署_no main manifest attribute, in springboot-0.0.1-sn-CSDN博客 多一个redis安装 准备工作: 压缩包下载:http://download.redis.io/releases 1. 上传压缩包,并进入压缩包所在目录,解压到目标…...

【java面试】微服务篇
【java面试】微服务篇 一、总体框架二、Springcloud(一)Springcloud五大组件(二)服务注册和发现1、Eureka2、Nacos (三)负载均衡1、Ribbon负载均衡流程2、Ribbon负载均衡策略3、自定义负载均衡策略4、总结 …...