2020年认证杯SPSSPRO杯数学建模D题(第一阶段)让电脑桌面飞起来全过程文档及程序
2020年认证杯SPSSPRO杯数学建模
D题 让电脑桌面飞起来
原题再现:
对于一些必须每天使用电脑工作的白领来说,电脑桌面有着非常特殊的意义,通常一些频繁使用或者比较重要的图标会一直保留在桌面上,但是随着时间的推移,桌面上的图标会越来越多,有的时候想找到一个马上要用的图标是非常困难的,就比如下图所示的桌面。各种各样的图标会让你眼花缭乱,甚至有的时候反复找好几遍都找不到你想要的图标。其实只要把图标进行有效的分类就可以解决这个问题,但是手工分类往往非常浪费时间,有的时候使用者也会陷入分类决定困难,不知该如何选择。

第一阶段问题: 请你的团队建立合理的数学模型,设计一种快速、有效地桌面图标分类的算法,使得能够根据图标的名字进行自动分类,让电脑桌面真正飞起来!这里需要注意的是,应用程序的图标文件不能通过扩展名来区分其功能,只能通过在已有的数据库或者互联网上查询文件名来判断其功能。当然也可以通过机器学习的方式来学习人的分类经验来形成一个分类模式。
整体求解过程概述(摘要)
随着电脑办公的普及,对于桌面图标的分类整理已成为让很多电脑使用者极为头疼的一件事,无论是专业的计算机开发者还是日常办公人员,进行有效的桌面图标整理工作,对于办公效率提升其价值是不言而喻的,对于桌面图标的有效分类以及桌面区域的划分是解决该问题的有效途径。
针对图标分类而言,我们获取桌面图标有关的 logo 图像、描述文本、以及近期访问量等三大特征。对于图像特征利用 CNN 进行图像特征提取匹配 logo 相似程度,根据图标名称寻找对应详细的文本介绍借助自然语言处理中的 LDA 主题提取算法,通过计算图标之间有关用途、来源等文本主题进行文本聚类,形成以主题为依据的图标存放单元。针对桌面图标点击量进行排序单独划分访问区域,根据图标 logo 特征提取后的结果结合图标的点击率调整图标的透明度和大小。最后得到五大主题图标区域与两块文件分类区域,在桌面上添加图标搜索栏,以完成对于文档类型图标的快速查找。
最后利用 ROC 曲线通过新增图标数量判别分类器准确度为 87.8%,通过实际测试得到该模型对于桌面图标查找速度提升为 65%。
问题分析:
(一)问题一的分析
对于桌面图标而言,人们往往凭借记忆和直观视觉完成对于所需图标范围的定位与查找,这往往耗费使用者大量时间。因此查找桌面图标时间的长短是衡量桌面图标分类效果的重要标准,与此同时优化图标对于用户的视觉舒适度。首先对于桌面图标需要合理设置若干个基本存放单元[1],将桌面区域进行划分,缩小用户对于所需图标的查找范围,对于新产生的图标可通过分类器判决进入对应的基本存放单元。
桌面图标包括三个维度的信息:1、所属文件的类型与自然文本 2、图标图像信息 3、近期桌面图标浏览量。首先,利用 CNN 对于图像论文进行特性提取,在输出层外接 LGAM快速训练模型,判决图标之间的相近程度。接着通过图标的名称向 Web 服务器发出请求查找对应名称内容的相应数据库,根据 LDA 主题模型进行主题聚类[2],将同一类型产品进行规律,最终根据用户的使用频率与图标颜色近似程度来改变的图标的透明度,最后留出一块基本存放单元体现桌面图标访问状况。通过桌面图标的访问评论调整图标的大小,并且对于使用频率低于一周一次的图标向用户申请删除命令。于此同时,针对大量同类型图标文件例如 Excel 与 Word 报表,在桌面增添搜索区域增加对于相近文件的区分度。
模型假设:
1.假设用户对于桌面图标重命名合理(符合图标内容属性);
2.假设用户图标类型较为常见,不存在大量图标名称极为近似
3.假设图标的透明度与大小能进行调整
4.假设图标名称与所关联的文本内容是一致的
5.假设申请删除某桌面图标的标准为访问周期小于一周
论文缩略图:

全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
import logging
import logging.config
import ConfigParser
import numpy as np
import random
import codecs
import os
from collections import OrderedDict
#获取当前路径
path = os.getcwd()
#导入日志配置文件
logging.config.fileConfig("logging.conf")
#创建日志对象
logger = logging.getLogger()
# loggerInfo = logging.getLogger("TimeInfoLogger")
# Consolelogger = logging.getLogger("ConsoleLogger")
#导入配置文件
conf = ConfigParser.ConfigParser()
conf.read("setting.conf")
#文件路径
trainfile = os.path.join(path,os.path.normpath(conf.get("filepath", "trainfile")))
wordidmapfile = os.path.join(path,os.path.normpath(conf.get("filepath","wordidmapfile")))
thetafile = os.path.join(path,os.path.normpath(conf.get("filepath","thetafile")))
phifile = os.path.join(path,os.path.normpath(conf.get("filepath","phifile")))
paramfile = os.path.join(path,os.path.normpath(conf.get("filepath","paramfile")))
topNfile = os.path.join(path,os.path.normpath(conf.get("filepath","topNfile")))
tassginfile = os.path.join(path,os.path.normpath(conf.get("filepath","tassginfile")))
#模型初始参数
K = int(conf.get("model_args","K"))
alpha = float(conf.get("model_args","alpha"))
beta = float(conf.get("model_args","beta"))
iter_times = int(conf.get("model_args","iter_times"))
top_words_num = int(conf.get("model_args","top_words_num"))
class Document(object):
def __init__(self):
self.words = []
self.length = 0
#把整个文档及真的单词构成 vocabulary(不允许重复)
class DataPreProcessing(object):
def __init__(self):
self.docs_count = 0
self.words_count = 0
#保存每个文档 d 的信息(单词序列,以及 length)
self.docs = []
#建立 vocabulary 表,照片文档的单词
self.word2id = OrderedDict()
def cachewordidmap(self):
with codecs.open(wordidmapfile, 'w','utf-8') as f:
for word,id in self.word2id.items():
f.write(word +"\t"+str(id)+"\n")
class LDAModel(object):
def __init__(self,dpre):
self.dpre = dpre #获取预处理参数
#
#模型参数
#聚类个数 K,迭代次数 iter_times,每个类特征词个数 top_words_num,超参数α(alpha) β(beta)
#
self.K = K
self.beta = beta
self.alpha = alpha
self.iter_times = iter_times
self.top_words_num = top_words_num
#
#文件变量
#分好词的文件 trainfile
#词对应 id 文件 wordidmapfile
#文章-主题分布文件 thetafile
#词-主题分布文件 phifile
#每个主题 topN 词文件 topNfile
#最后分派结果文件 tassginfile
#模型训练选择的参数文件 paramfile
#
self.wordidmapfile = wordidmapfile
self.trainfile = trainfile
self.thetafile = thetafile
self.phifile = phifile
self.topNfile = topNfile
self.tassginfile = tassginfile
self.paramfile = paramfile
# p,概率向量 double 类型,存储采样的临时变量
# nw,词 word 在主题 topic 上的分布
# nwsum,每各 topic 的词的总数
# nd,每个 doc 中各个 topic 的词的总数
# ndsum,每各 doc 中词的总数
self.p = np.zeros(self.K)
# nw,词 word 在主题 topic 上的分布
self.nw = np.zeros((self.dpre.words_count,self.K),dtype="int")
# nwsum,每各 topic 的词的总数
self.nwsum = np.zeros(self.K,dtype="int")
# nd,每个 doc 中各个 topic 的词的总数
self.nd = np.zeros((self.dpre.docs_count,self.K),dtype="int")
# ndsum,每各 doc 中词的总数
self.ndsum = np.zeros(dpre.docs_count,dtype="int")
self.Z = np.array([ [0 for y in xrange(dpre.docs[x].length)] for x in xrange(dpre.docs_count)])
# M*doc.size(),文档中词的主题分布
#随机先分配类型,为每个文档中的各个单词分配主题
for x in xrange(len(self.Z)):
self.ndsum[x] = self.dpre.docs[x].length
for y in xrange(self.dpre.docs[x].length):
topic = random.randint(0,self.K-1)#随机取一个主题
self.Z[x][y] = topic#文档中词的主题分布
self.nw[self.dpre.docs[x].words[y]][topic] += 1
self.nd[x][topic] += 1
self.nwsum[topic] += 1
self.theta = np.array([ [0.0 for y in xrange(self.K)] for x in xrange(self.dpre.docs_count) ])
self.phi = np.array([ [ 0.0 for y in xrange(self.dpre.words_count) ] for x in xrange(self.K)])
def sampling(self,i,j):
#换主题
topic = self.Z[i][j]
#只是单词的编号,都是从 0 开始 word 就是等于 j
word = self.dpre.docs[i].words[j]
#if word==j:
# print 'true'
self.nw[word][topic] -= 1
self.nd[i][topic] -= 1
self.nwsum[topic] -= 1
self.ndsum[i] -= 1
Vbeta = self.dpre.words_count * self.beta
Kalpha = self.K * self.alpha
self.p = (self.nw[word] + self.beta)/(self.nwsum + Vbeta) * \
(self.nd[i] + self.alpha) / (self.ndsum[i] + Kalpha)
#随机更新主题的吗
# for k in xrange(1,self.K):
# self.p[k] += self.p[k-1]
# u = random.uniform(0,self.p[self.K-1])
# for topic in xrange(self.K):
# if self.p[topic]>u:
# break
#按这个更新主题更好理解,这个效果还不错
p = np.squeeze(np.asarray(self.p/np.sum(self.p)))
topic = np.argmax(np.random.multinomial(1, p))
self.nw[word][topic] +=1
self.nwsum[topic] +=1
self.nd[i][topic] +=1
self.ndsum[i] +=1
return topic
def est(self):
# Consolelogger.info(u"迭代次数为%s 次" % self.iter_times)
for x in xrange(self.iter_times):
for i in xrange(self.dpre.docs_count):
for j in xrange(self.dpre.docs[i].length):
topic = self.sampling(i,j)
self.Z[i][j] = topic
logger.info(u"迭代完成。")
logger.debug(u"计算文章-主题分布")
self._theta()
logger.debug(u"计算词-主题分布")
self._phi()
logger.debug(u"保存模型")
self.save()
def _theta(self):
for i in xrange(self.dpre.docs_count):#遍历文档的个数词
self.theta[i] = (self.nd[i]+self.alpha)/(self.ndsum[i]+self.K * self.alpha)
def _phi(self):
for i in xrange(self.K):
self.phi[i] = (self.nw.T[i] + self.beta)/(self.nwsum[i]+self.dpre.words_count * self.beta)
def save(self):
# 保存 theta 文章-主题分布
logger.info(u"文章-主题分布已保存到%s" % self.thetafile)
with codecs.open(self.thetafile,'w') as f:
for x in xrange(self.dpre.docs_count): for y in xrange(self.K):
f.write(str(self.theta[x][y]) + '\t')
f.write('\n')
# 保存 phi 词-主题分布
logger.info(u"词-主题分布已保存到%s" % self.phifile)
with codecs.open(self.phifile,'w') as f:
for x in xrange(self.K):
for y in xrange(self.dpre.words_count):
f.write(str(self.phi[x][y]) + '\t')
f.write('\n')
# 保存参数设置
logger.info(u"参数设置已保存到%s" % self.paramfile)
with codecs.open(self.paramfile,'w','utf-8') as f:
f.write('K=' + str(self.K) + '\n')
f.write('alpha=' + str(self.alpha) + '\n')
f.write('beta=' + str(self.beta) + '\n')
f.write(u'迭代次数 iter_times=' + str(self.iter_times) + '\n')
f.write(u'每个类的高频词显示个数 top_words_num=' + str(self.top_words_num) + '\n')
# 保存每个主题 topic 的词
logger.info(u"主题 topN 词已保存到%s" % self.topNfile)
lda = LDAModel(dpre)
lda.est()
if __name__ == '__main__':
run()
全部论文及程序请见下方“ 只会建模 QQ名片” 点击QQ名片即可
相关文章:
2020年认证杯SPSSPRO杯数学建模D题(第一阶段)让电脑桌面飞起来全过程文档及程序
2020年认证杯SPSSPRO杯数学建模 D题 让电脑桌面飞起来 原题再现: 对于一些必须每天使用电脑工作的白领来说,电脑桌面有着非常特殊的意义,通常一些频繁使用或者比较重要的图标会一直保留在桌面上,但是随着时间的推移,…...

谷歌推出创新SynCLR技术:借助AI生成的数据实现高效图像建模,开启自我训练新纪元!
谷歌推出了一种创新性的合成图像框架,这一框架独特之处在于它完全不依赖真实数据。这个框架首先从合成的图像标题开始,然后基于这些标题生成相应的图像。接下来,通过对比学习的技术进行深度学习,从而训练出能够精准识别和理解这些…...
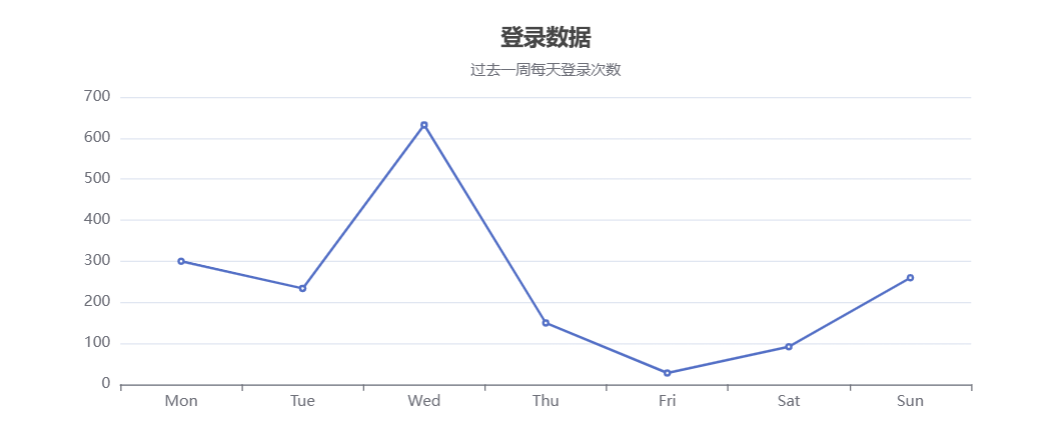
Vue2中使用echarts,并从后端获取数据同步
一、安装echarts npm install echarts -S 二、导入echarts 在script中导入,比如: import * as echarts from "echarts"; 三、查找要用的示例 比如柱状图 四、初始化并挂载 <template><div id"total-orders-chart" s…...

【Redux】自己动手实现redux-thunk
1. 前言 在原始的redux里面,action必须是plain object,且必须是同步。而我们经常使用到定时器,网络请求等异步操作,而redux-thunk就是为了解决异步动作的问题而出现的。 2. redux-thunk中间件实现源码 function createThunkMidd…...
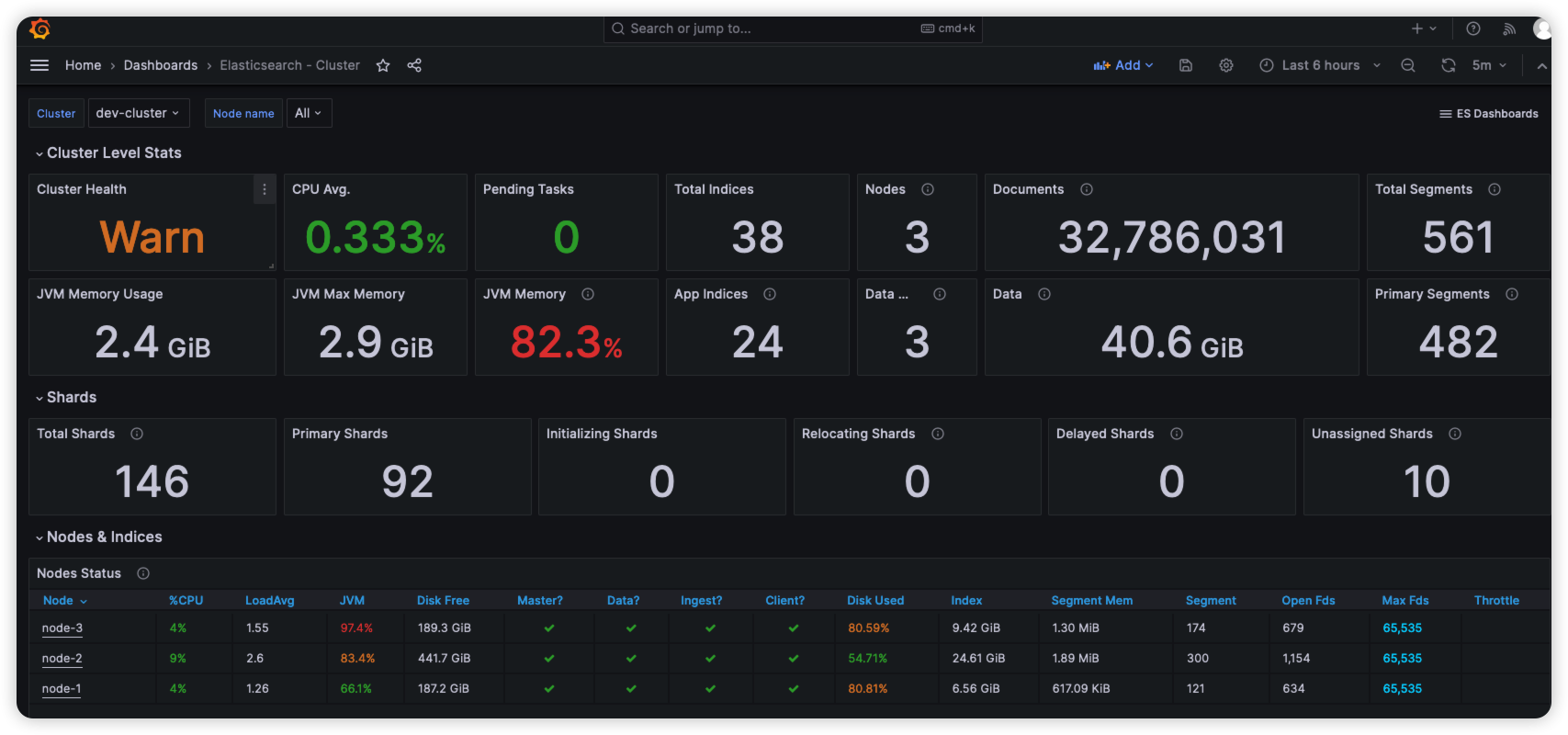
ElasticSearch使用Grafana监控服务状态-Docker版
文章目录 版本信息构建docker-compose.yml参数说明 创建Prometheus配置文件启动验证配置Grafana导入监控模板模板说明 参考资料 版本信息 ElasticSearch:7.14.2 elasticsearch_exporter:1.7.0(latest) 下载地址:http…...
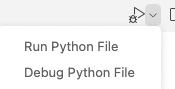
VS Code 如何调试Python文件
VS Code中有1,2,3处跟Run and Debug相关的按钮, 1 处:调试和运行就不多说了,Open Configurations就是打开workspace/.vscode下的lauch.json文件,而Add Configuration就是在lauch.json文件中添加当前运行Python文件的Configuratio…...
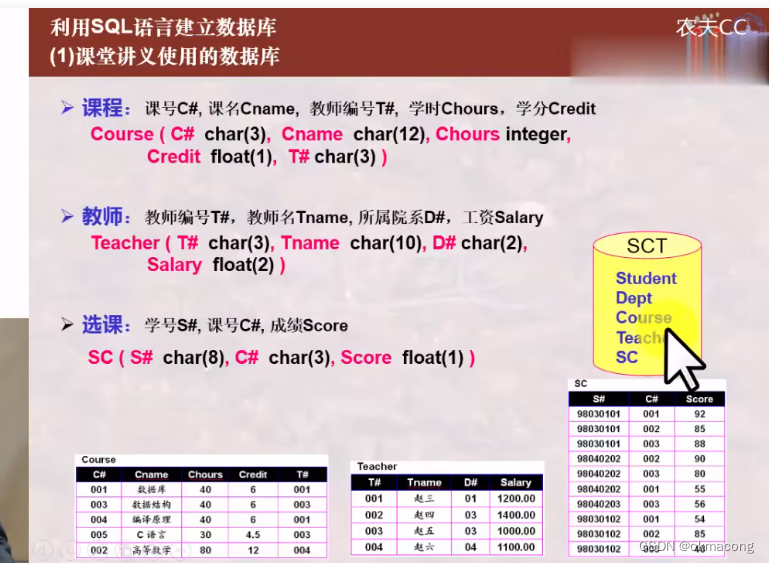
day06、SQL语言之概述
SQl 语言之概述 6.1 SQL语言概述6.2 SQL语言之DDL定义数据库6.3 SQL语言之DML操纵数据库 6.1 SQL语言概述 6.2 SQL语言之DDL定义数据库 6.3 SQL语言之DML操纵数据库...

3D目标检测(教程+代码)
随着计算机视觉技术的不断发展,3D目标检测成为了一个备受关注的研究领域。与传统的2D目标检测相比,3D目标检测可以在三维空间中对物体进行定位和识别,具有更高的准确性和适用性。本文将介绍3D目标检测的相关概念、方法和代码实现。 一、3D目…...

让设备更聪明 |启英泰伦离线自然说,开启智能语音交互新体验!
语音交互按部署方式可以分为两种:离线语音交互和在线语音交互。 在线语音交互是将数据储存在云端,其具备足够大的存储空间和算力,可以实现海量的语音数据处理。 离线语音交互是以语音芯片为载体,语音数据的采集、计算、决策均在…...

React Hooks之useState、useRef
文章目录 React Hooks之useStateReact HooksuseStatedemo:在函数式组件中使用 useState Hook 管理计数器demo:ant-design-pro 中EditableProTable组件使用 useRef React Hooks之useState React Hooks 在 React 16.8 版本中引入了 Hooks,它是…...

提供电商Api接口-100种接口,淘宝,1688,抖音商品详情数据安全,稳定,支持高并发
Java是一种高级编程语言,由Sun Microsystems公司于1995年推出,现在属于Oracle公司开发和维护。Java以平台无关性、面向对象、安全性、可移植性和高性能著称,广泛用于桌面应用程序、嵌入式系统、企业级服务、Android移动应用程序等。 接口是Ja…...

git的使用 笔记1
GIT git的使用 使用git提交的两步 第一步:是使用 git add 把文件添加进去,实际上就是把文件添加到暂存区。第二步:使用git commit提交更改,实际上就是把暂存区的所有内容提交到当前分支上。 .git 跟踪管理版本的目录 创建版本库…...

基于SpringBoot的医疗挂号管理系统
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot的医疗挂号管理系统,java…...
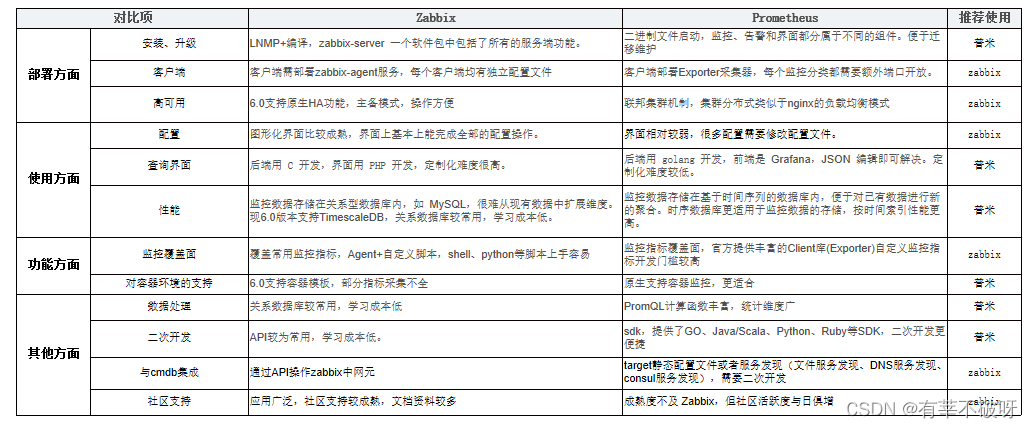
prometheus与zabbix监控的对比介绍
一、普米与zabbix基本介绍 1、prometheus介绍 Prometheus的基本原理是Prometheus Server通过HTTP周期性抓取被监控组件的监控数据,任意组件只要提供对应的HTTP接口并且符合Prometheus定义的数据格式,就可以接入Prometheus监控。 工作流程大致分为收集数…...
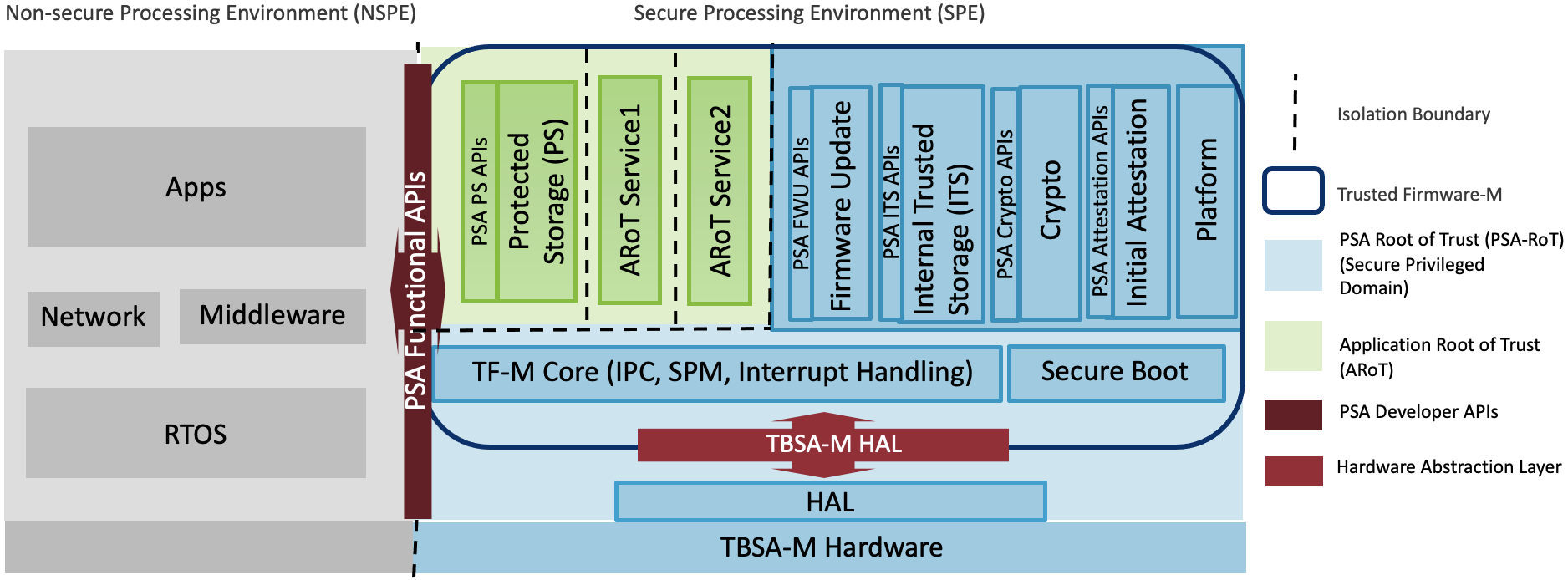
详解全志R128 RTOS安全方案功能
介绍 R128 下安全方案的功能。安全完整的方案基于标准方案扩展,覆盖硬件安全、硬件加解密引擎、安全启动、安全系统、安全存储等方面。 配置文件相关 本文涉及到一些配置文件,在此进行说明。 env*.cfg配置文件路径: board/<chip>/&…...

【MySQL】WITH AS 用法以及 ROW_NUMBER 函数 和 自增ID 的巧用
力扣题 1、题目地址 601. 体育馆的人流量 2、模拟表 表:Stadium Column NameTypeidintvisit_datedatepeopleint visit_date 是该表中具有唯一值的列。每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)每天只有…...
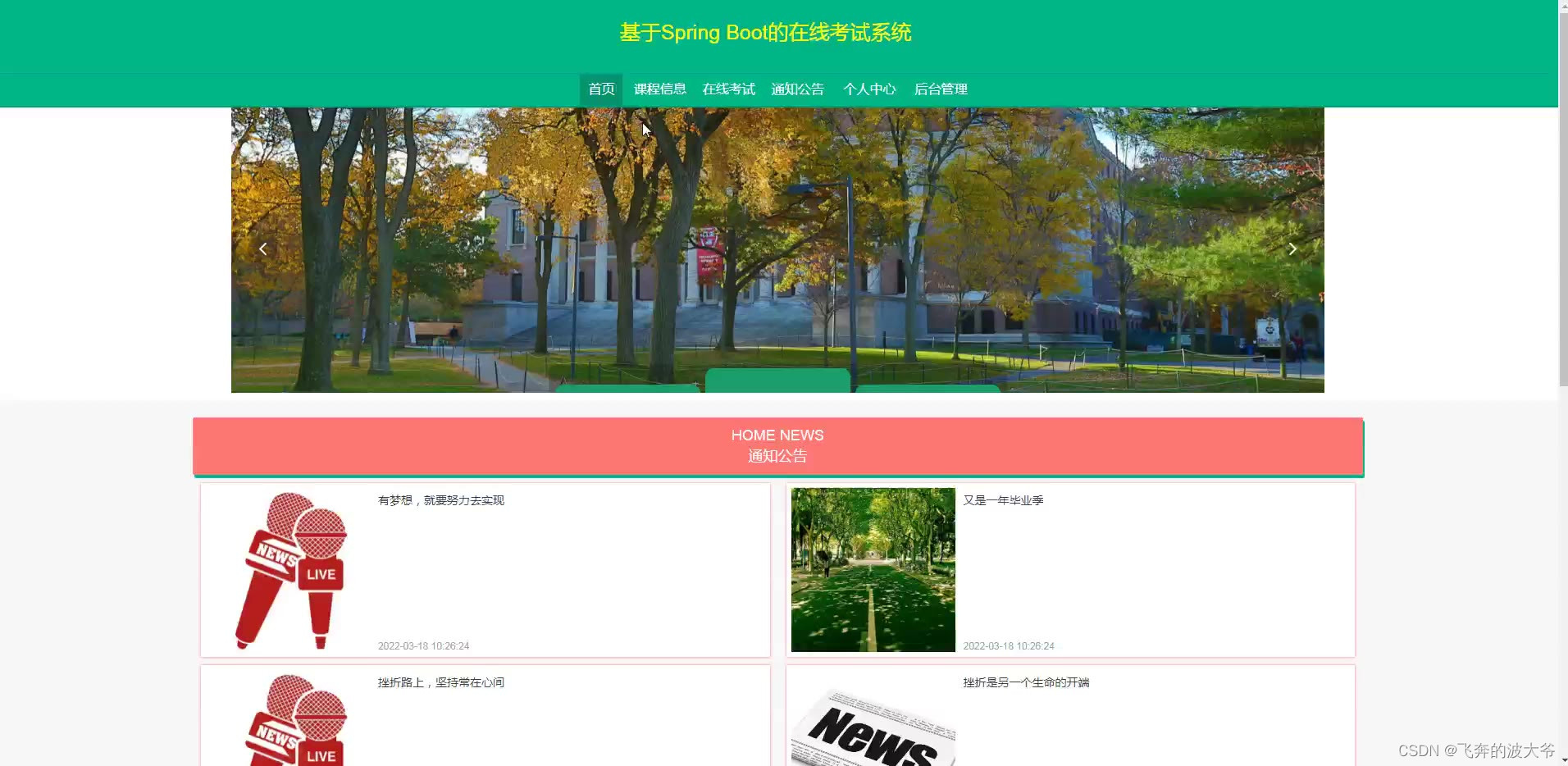
基于SpringBoot的在线考试系统源码和论文
网络的广泛应用给生活带来了十分的便利。所以把在线考试管理与现在网络相结合,利用java技术建设在线考试系统,实现在线考试的信息化管理。则对于进一步提高在线考试管理发展,丰富在线考试管理经验能起到不少的促进作用。 在线考试系统能够通…...

基于Spring Boot的美妆分享系统:打造个性化推荐、互动社区与智能决策
基于Spring Boot的美妆分享系统:打造个性化推荐、互动社区与智能决策 1. 项目介绍2. 管理员功能2.1 美妆管理2.2 页面管理2.3 链接管理2.4 评论管理2.5 用户管理2.6 公告管理 3. 用户功能3.1 登录注册3.2 分享商品3.3 问答3.4 我的分享3.5 我的收藏夹 4. 创新点4.1 …...
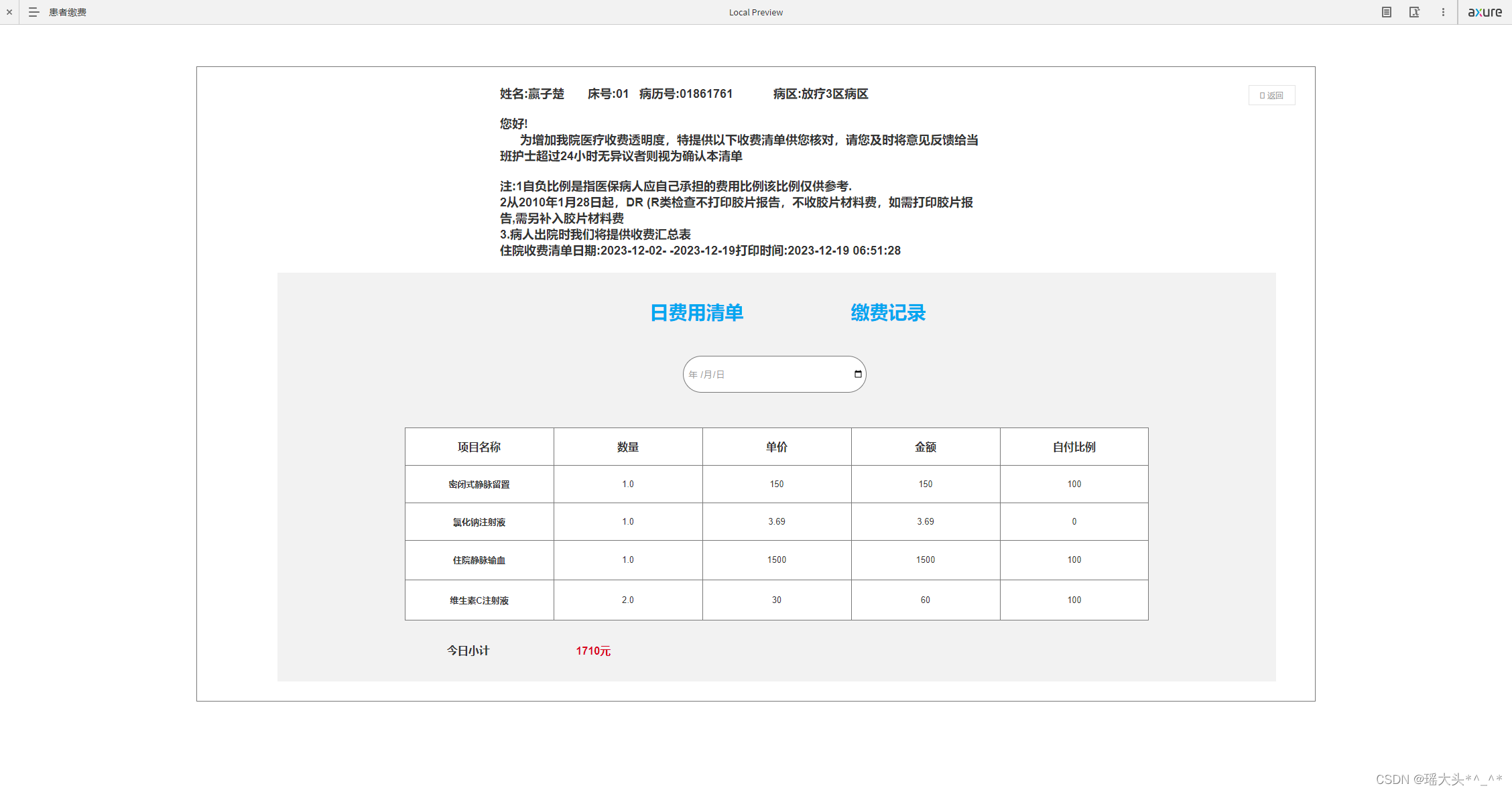
Axure医疗-住院板块,住院患者原型预览,新增医护人员原型预览,新增病房原型预览,选择床位原型预览,主治医生原型预览,主治医生医嘱原型预览
目录 一.医疗项目原型图-----住院板块 1.1 住院板块原型预览 1.2 新增住院患者原型预览 1.3 新增医护人员原型预览 1.4 新增病房原型预览 1.5 选择床位原型预览 1.6 主治医生原型预览 1.7 主治医生医嘱原型预览 1.8 主治医生查看患者报告原型预览 1.9 护士原型预…...

前端实战第一期:悬浮动画
悬浮动画 像这样的悬浮动画该怎么做,让我们按照以下步骤完成 步骤: 先把HTML内容做起来,用button属性创建一个按钮,按钮内写上悬浮效果 <button classbtn>悬浮动画</button>在style标签内设置样式,先设置盒子大小&…...

未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?
编辑:陈萍萍的公主一点人工一点智能 未来机器人的大脑:如何用神经网络模拟器实现更智能的决策?RWM通过双自回归机制有效解决了复合误差、部分可观测性和随机动力学等关键挑战,在不依赖领域特定归纳偏见的条件下实现了卓越的预测准…...

PHP和Node.js哪个更爽?
先说结论,rust完胜。 php:laravel,swoole,webman,最开始在苏宁的时候写了几年php,当时觉得php真的是世界上最好的语言,因为当初活在舒适圈里,不愿意跳出来,就好比当初活在…...

以下是对华为 HarmonyOS NETX 5属性动画(ArkTS)文档的结构化整理,通过层级标题、表格和代码块提升可读性:
一、属性动画概述NETX 作用:实现组件通用属性的渐变过渡效果,提升用户体验。支持属性:width、height、backgroundColor、opacity、scale、rotate、translate等。注意事项: 布局类属性(如宽高)变化时&#…...

MMaDA: Multimodal Large Diffusion Language Models
CODE : https://github.com/Gen-Verse/MMaDA Abstract 我们介绍了一种新型的多模态扩散基础模型MMaDA,它被设计用于在文本推理、多模态理解和文本到图像生成等不同领域实现卓越的性能。该方法的特点是三个关键创新:(i) MMaDA采用统一的扩散架构…...

Nginx server_name 配置说明
Nginx 是一个高性能的反向代理和负载均衡服务器,其核心配置之一是 server 块中的 server_name 指令。server_name 决定了 Nginx 如何根据客户端请求的 Host 头匹配对应的虚拟主机(Virtual Host)。 1. 简介 Nginx 使用 server_name 指令来确定…...
详解:相对定位 绝对定位 固定定位)
css的定位(position)详解:相对定位 绝对定位 固定定位
在 CSS 中,元素的定位通过 position 属性控制,共有 5 种定位模式:static(静态定位)、relative(相对定位)、absolute(绝对定位)、fixed(固定定位)和…...

土地利用/土地覆盖遥感解译与基于CLUE模型未来变化情景预测;从基础到高级,涵盖ArcGIS数据处理、ENVI遥感解译与CLUE模型情景模拟等
🔍 土地利用/土地覆盖数据是生态、环境和气象等诸多领域模型的关键输入参数。通过遥感影像解译技术,可以精准获取历史或当前任何一个区域的土地利用/土地覆盖情况。这些数据不仅能够用于评估区域生态环境的变化趋势,还能有效评价重大生态工程…...

蓝桥杯3498 01串的熵
问题描述 对于一个长度为 23333333的 01 串, 如果其信息熵为 11625907.5798, 且 0 出现次数比 1 少, 那么这个 01 串中 0 出现了多少次? #include<iostream> #include<cmath> using namespace std;int n 23333333;int main() {//枚举 0 出现的次数//因…...

安宝特方案丨船舶智造的“AR+AI+作业标准化管理解决方案”(装配)
船舶制造装配管理现状:装配工作依赖人工经验,装配工人凭借长期实践积累的操作技巧完成零部件组装。企业通常制定了装配作业指导书,但在实际执行中,工人对指导书的理解和遵循程度参差不齐。 船舶装配过程中的挑战与需求 挑战 (1…...
uniapp 小程序 学习(一)
利用Hbuilder 创建项目 运行到内置浏览器看效果 下载微信小程序 安装到Hbuilder 下载地址 :开发者工具默认安装 设置服务端口号 在Hbuilder中设置微信小程序 配置 找到运行设置,将微信开发者工具放入到Hbuilder中, 打开后出现 如下 bug 解…...