经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理
经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理
之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。
经典目标检测YOLO系列(一)YOLOV1的复现(1)总体架构
经典目标检测YOLO系列(一)复现YOLOV1(2)反解边界框及后处理
经典目标检测YOLO系列(一)复现YOLOV1(3)正样本的匹配及损失函数的实现
我们今天讲解下数据集的读取、数据集的预处理以及数据增强。
1、利用VOCDataset类读取数据集
对于目标检测任务而言,常用的数据集包括较小的PASCAL VOC以及较大的MS COCO。我们目前只需要了解并掌握使用较小的PASCAL VOC数据集即可,虽然COCO数据集是当下最主流的数据集之一,但其较大的数据量自然增加了训练成本。
VOC2007及2012数据集的下载(百度网盘)和介绍可以参考:
经典目标检测YOLO系列(1)YOLO-V1算法及其在VOC2007数据集上的应用
当然,作者在项目代码中,dataset/script文件中提供了用于下载VOC数据集的脚本。
1.1 VOCDataset类的实现
我们自定义VOCDataset类,继承pytorch提供的torch.utils.data.Dataset类,主要实现__getitem__函数。再利用pytorch提供的Dataloader,就可以通过调用__getitem__函数来批量读取VOC数据集图片和标签了。
VOCDataset类的初始化部分,如下方的代码所示:
# RT-ODLab\dataset\voc.pyclass VOCDataset(data.Dataset):def __init__(self, img_size :int = 640,data_dir :str = None,# image_sets = [('2007', 'trainval'), ('2012', 'trainval')],image_sets = [('2007', 'trainval')],trans_config = None,transform = None,is_train :bool = False,load_cache :bool = False,):# ----------- Basic parameters -----------self.img_size = img_sizeself.image_set = image_setsself.is_train = is_trainself.target_transform = VOCAnnotationTransform()# ----------- Path parameters -----------self.root = data_dirself._annopath = osp.join('%s', 'Annotations', '%s.xml')self._imgpath = osp.join('%s', 'JPEGImages', '%s.jpg')# ----------- Data parameters -----------self.ids = list()for (year, name) in image_sets:rootpath = osp.join(self.root, 'VOC' + year)for line in open(osp.join(rootpath, 'ImageSets', 'Main', name + '.txt')):self.ids.append((rootpath, line.strip()))self.dataset_size = len(self.ids)# ----------- Transform parameters -----------self.transform = transformself.mosaic_prob = trans_config['mosaic_prob'] if trans_config else 0.0self.mixup_prob = trans_config['mixup_prob'] if trans_config else 0.0self.trans_config = trans_configprint('==============================')print('use Mosaic Augmentation: {}'.format(self.mosaic_prob))print('use Mixup Augmentation: {}'.format(self.mixup_prob))print('==============================')# ----------- Cached data -----------self.load_cache = load_cacheself.cached_datas = Noneif self.load_cache:self.cached_datas = self._load_cache()
VOCDataset类包含读取图片和标签的功能,对此,我们实现了相关的功能,如下方代码所示:
- 通过调用pull_image和pull_anno两个函数来分别去读取图片和以XML格式保存的标签文件,load_image_target 函数最终会输出一张图片image,以及保存了该图片中的所有目标的边界框和类别信息的target。
- 需要注意的是,当self.cached_datas不是None时,我们会从缓存了数据集所有数据的self.cached_datas中直接索引图片和对应的标签数据,而不用再从本地去读取了。
# RT-ODLab\dataset\voc.py# ------------ Load data function ------------def load_image_target(self, index):# 读取图片和标签的功能# == 从缓存中进行加载 ==if self.cached_datas is not None:# load a datadata_item = self.cached_datas[index]image = data_item["image"]target = data_item["target"]# ==从磁盘中进行加载 ==else: # load an image# 1、利用open-cv加载一张图像image, _ = self.pull_image(index)height, width, channels = image.shape# laod an annotation# 2、利用ET读取一张图片的标签信息(bbox以及类别信息)anno, _ = self.pull_anno(index)# guard against no boxes via resizinganno = np.array(anno).reshape(-1, 5)target = {"boxes": anno[:, :4], # 一张图片中GT所有的bbox信息"labels": anno[:, 4], # 一张图片中物体信息"orig_size": [height, width] # 原始图片的大小}# 返回一张图像及其标签信息return image, targetdef pull_image(self, index):# 利用opencv读取一张图片img_id = self.ids[index]# D:\\VOCdevkit\\VOC2007\\JPEGImages\\000001.jpgimage = cv2.imread(self._imgpath % img_id, cv2.IMREAD_COLOR)return image, img_iddef pull_anno(self, index):# 利用ET读取一张图片的标签信息(bbox以及类别信息)img_id = self.ids[index]# 'D:\\VOCdevkit\\VOC2007\\Annotations\\000001.xml'anno = ET.parse(self._annopath % img_id).getroot()# 解析xml文件,返回[[xmin,ymin,xmax,ymax,标签id],...]anno = self.target_transform(anno)return anno, img_id
这里作者为了实现了从缓冲中读取,实现了下面代码:
- 代码中,将所有的图片和标签都保存在data_items变量中,注意,对于读取的每一张图片,我们都预先对其做resize操作,这是因为在后续的数据预处理环节中,我们会对原始图片先做一步resize操作,然后再去做其他的预处理操作,为了节省内存空间,这里我们就直接做好了。
- 不过,就学习而言,我们是默认不采用这种cache方式,因为这对于设备的内存要求会很高。
# RT-ODLab\dataset\voc.pydef _load_cache(self):data_items = []for idx in range(self.dataset_size):if idx % 2000 == 0:print("Caching images and targets : {} / {} ...".format(idx, self.dataset_size))# load a dataimage, target = self.load_image_target(idx)orig_h, orig_w, _ = image.shape# resize imager = self.img_size / max(orig_h, orig_w)if r != 1: interp = cv2.INTER_LINEARnew_size = (int(orig_w * r), int(orig_h * r))image = cv2.resize(image, new_size, interpolation=interp)img_h, img_w = image.shape[:2]# rescale bboxboxes = target["boxes"].copy()boxes[:, [0, 2]] = boxes[:, [0, 2]] / orig_w * img_wboxes[:, [1, 3]] = boxes[:, [1, 3]] / orig_h * img_htarget["boxes"] = boxesdict_item = {}dict_item["image"] = imagedict_item["target"] = targetdata_items.append(dict_item)return data_items
在实现了load_image_target函数后,我们再实现一个pull_item函数,在该函数中,我们会对读取进来的数据做预处理操作(先忽略预处理):
- 代码中,我们会根据random.random()< self.mosaic_prob条件来决定是否读取马赛克图像,即将多张图像拼接在一起,使得拼接后的图像能拥有更丰富的目标信息。
- 另外,我们也会根据random.random()< self.mixup_prob条件来决定是要加载混合图像,即使用混合增强(Mixup augmentation)技术随机将两张图片以加权求和的方式融合在一起。
- 就目前的学习目标而言,我们暂时还不会使用到这两个过于强大的数据增强,因此mosaic_prob及mixup_prob默认为0。
- 最后,外部的Dataloader就可以通过调用
__getitem__函数来读取VOC数据集图片和标签了。
# RT-ODLab\dataset\voc.pydef pull_item(self, index):# 实现一个pull_item函数,在该函数中,我们会对读取进来的数据做预处理操作if random.random() < self.mosaic_prob:# load a mosaic imagemosaic = Trueimage, target = self.load_mosaic(index)else:mosaic = False# load an image and targetimage, target = self.load_image_target(index)# MixUpif random.random() < self.mixup_prob:image, target = self.load_mixup(image, target)# augmentimage, target, deltas = self.transform(image, target, mosaic)return image, target, deltas# ------------ Basic dataset function ------------def __getitem__(self, index):image, target, deltas = self.pull_item(index)return image, target, deltasdef __len__(self):return self.dataset_size
1.2 读取VOC数据集
1.2.1 build_dataset函数
这里,将读取VOC数据集封装为build_dataset函数,如下:
build_dataset函数:
# RT-ODLab\dataset\build.py# ------------------------------ Dataset ------------------------------
def build_dataset(args, data_cfg, trans_config, transform, is_train=True):# ------------------------- Basic parameters -------------------------data_dir = os.path.join(args.root, data_cfg['data_name'])num_classes = data_cfg['num_classes']class_names = data_cfg['class_names']class_indexs = data_cfg['class_indexs']dataset_info = {'num_classes': num_classes,'class_names': class_names,'class_indexs': class_indexs}# ------------------------- Build dataset -------------------------## VOC datasetif args.dataset == 'voc':image_sets = [('2007', 'trainval')] if is_train else [('2007', 'test')]dataset = VOCDataset(img_size = args.img_size,data_dir = data_dir,image_sets = image_sets,transform = transform,trans_config = trans_config,is_train = is_train,load_cache = args.load_cache)## COCO datasetelif args.dataset == 'coco':image_set = 'train2017' if is_train else 'val2017'dataset = COCODataset(img_size = args.img_size,data_dir = data_dir,image_set = image_set,transform = transform,trans_config = trans_config,is_train = is_train,load_cache = args.load_cache)## CrowdHuman datasetelif args.dataset == 'crowdhuman':image_set = 'train' if is_train else 'val'dataset = CrowdHumanDataset(img_size = args.img_size,data_dir = data_dir,image_set = image_set,transform = transform,trans_config = trans_config,is_train = is_train,)## Custom datasetelif args.dataset == 'ourdataset':image_set = 'train' if is_train else 'val'dataset = OurDataset(data_dir = data_dir,img_size = args.img_size,image_set = image_set,transform = transform,trans_config = trans_config,s_train = is_train,oad_cache = args.load_cache)return dataset, dataset_info
1.2.2 build_dataloader函数
- 在实现了Dataset以及数据预处理操作后,我们接下来就需要为训练中要用到的Dataloader做一些准备。
- Dataloader的作用就是利用多线程来快速地为当前的训练迭代准备好一批数据,以便我们去做推理、标签分配和损失函数,这其中就要用到collate_fn方法,该方法的主要目的就是去将多个线程读取进来的数据处理成我们所需要的格式。
- 默认情况下,Dataloader自带的该方法是直接将所有数据组成个更大的torch.Tensor,但这不适合于我们的数据,因为我们的标签数据是Dict,无法拼接成Tensor,因此,我们需要自己实现一个Collate函数,如下方的代码所示。
- 这段代码的逻辑十分简单,就是从Dataloader利用多线程读取进来的一批数据batch, 分别去取出图片和标签,然后将图片组成一批数据,即torch.Tensor类型,其shape是[B, C, H, W],再将所有图片的target存放在一个List中,最后输出即可。
# RT-ODLab\utils\misc.py## collate_fn for dataloader
class CollateFunc(object):def __call__(self, batch):targets = []images = []for sample in batch:image = sample[0]target = sample[1]images.append(image)targets.append(target)images = torch.stack(images, 0) # [B, C, H, W]return images, targets
# batch为2的时候,值为下面所示:
[(tensor([[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]],[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]],[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]]]), {'boxes': tensor([[114., 295., 119., 312.],[ 29., 230., 148., 321.]]), 'labels': tensor([14., 18.]), 'orig_size': [281, 500]}, None), (tensor([[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]],[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]],[[0., 0., 0., ..., 0., 0., 0.],...,[0., 0., 0., ..., 0., 0., 0.]]]), {'boxes': tensor([[ 0., 79., 416., 362.]]), 'labels': tensor([1.]), 'orig_size': [375, 500]}, None)
]# 经过CollateFunc函数后转变为:
# images.shape:
torch.Size([2, 3, 416, 416])
# targets为:
[{'boxes': tensor([[114., 295., 119., 312.],[ 29., 230., 148., 321.]]), 'labels': tensor([14., 18.]), 'orig_size': [281, 500]}, {'boxes': tensor([[ 0., 79., 416., 362.]]), 'labels': tensor([1.]), 'orig_size': [375, 500]}
]
在写完了Collate函数后,我们就可以利用PyTorch框架提供的Dataloader来实现这部分的操作:
- 当args.distributed=True时,我们会开启分布式训练,即所谓的“DDP”,此时我们就要构建DDP模块下的sampler,否则的话我们就构建单卡环境下的RandomSampler即可。
- 然后构建读取一批数据的BatchSampler,其中,我们将drop_last设置为True,即当数dataloader读取到最后,发现剩下的数据数量少于我们设定的batch size,那么就丢掉这一批数据。
- 由于每次dataloader读取完所有的数据后,即完成一次训练的epoch,内部数据会被重新打乱一次,因此这种丢弃方法不会造成负面影响。
build_dataloader函数:
# RT-ODLab\utils\misc.py# ---------------------------- For Dataset ----------------------------
## build dataloader
def build_dataloader(args, dataset, batch_size, collate_fn=None):# distributedif args.distributed:sampler = DistributedSampler(dataset)else:sampler = torch.utils.data.RandomSampler(dataset)batch_sampler_train = torch.utils.data.BatchSampler(sampler, batch_size, drop_last=True)# 读取VOC数据集dataloader = DataLoader(dataset, batch_sampler=batch_sampler_train,collate_fn=collate_fn, num_workers=args.num_workers, pin_memory=True)return dataloader
2、数据预处理
2.1 SSD风格的预处理
我们在构造VOCDataset类时候,需要传入transform,这就是数据的预处理。下面是构造transform的函数:
-
在YOLOV1中,我们使用ssd风格数据预处理及数据增强策略,即trans_config[‘aug_type’]的值为ssd
-
训练过程中,我们使用SSDAugmentation,即只采用SSD工作所用到的数据增强操作,包括
随机裁剪、随机翻转、随机色彩空间变换、随机图像色彩变换等等。 -
前向推理过程中,我们使用SSDBaseTransform,即前向推理过程中,只对图像做预处理操作。
-
在YOLOV1中,我们关闭马赛克增强以及混合增强。
-
我们可以运行dataset/voc.py文件,将数据增强后的图片可视化出来,增强的效果即可一目了然。读者可以参考下方的运行命令来查看。具体数据增强的代码实现,还请参考源码。
python dataset/voc.py --root /data/VOCdevkit --aug_type ssd --is_train
# RT-ODLab\dataset\build.py# ------------------------------ Transform ------------------------------
def build_transform(args, trans_config, max_stride=32, is_train=False):# Modify trans_configif is_train:## mosaic prob.if args.mosaic is not None:trans_config['mosaic_prob']=args.mosaic if is_train else 0.0else:trans_config['mosaic_prob']=trans_config['mosaic_prob'] if is_train else 0.0## mixup prob.if args.mixup is not None:trans_config['mixup_prob']=args.mixup if is_train else 0.0else:trans_config['mixup_prob']=trans_config['mixup_prob'] if is_train else 0.0# Transformif trans_config['aug_type'] == 'ssd':if is_train:transform = SSDAugmentation(img_size=args.img_size,)else:transform = SSDBaseTransform(img_size=args.img_size,)trans_config['mosaic_prob'] = 0.0trans_config['mixup_prob'] = 0.0elif trans_config['aug_type'] == 'yolov5':if is_train:transform = YOLOv5Augmentation(img_size=args.img_size,trans_config=trans_config,use_ablu=trans_config['use_ablu'])else:transform = YOLOv5BaseTransform(img_size=args.img_size,max_stride=max_stride)return transform, trans_config
1.1.1 训练过程中的SSDAugmentation
- 数据集固定,其所携带的各种信息便也就固定了下来,因此也就限定了模型的学习能力。为了扩充数据集的数量以及样本的丰富性、提高模型的鲁棒性和泛化能力,我们往往会在
训练阶段对数据集已有的数据做随机的预处理操作,比如随机水平翻转、随机剪裁、色彩扰动、空间尺寸缩放等,这就是数据增强。 - 对于我们现在所要实现的YOLOv1,我们只采用SSD工作所用到的数据增强操作,包括
随机裁剪、随机翻转、随机色彩空间变换、随机图像色彩变换等等。 - 我们暂时不会用到更强大的马赛克增强、混合增强等手段。在我们实现的YOLOv1的配置文件中,我们可以看到’trans_type’: ‘ssd’ 字样,这就表明我们使用SSD风格的数据增强。
# RT-ODLab\dataset\data_augment\ssd_augment.py
# ----------------------- Main Functions -----------------------
## SSD-style Augmentation
class SSDAugmentation(object):def __init__(self, img_size=640):self.img_size = img_sizeself.augment = Compose([ConvertFromInts(), # 将int类型转换为float32类型PhotometricDistort(), # 图像颜色增强Expand(), # 扩充增强RandomSampleCrop(), # 随机剪裁RandomHorizontalFlip(), # 随机水平翻转Resize(self.img_size) # resize操作])def __call__(self, image, target, mosaic=False):boxes = target['boxes'].copy()labels = target['labels'].copy()deltas = None# augmentimage, boxes, labels = self.augment(image, boxes, labels)# to tensorimg_tensor = torch.from_numpy(image).permute(2, 0, 1).contiguous().float()target['boxes'] = torch.from_numpy(boxes).float()target['labels'] = torch.from_numpy(labels).float()return img_tensor, target, deltas
1.1.2 前向推理过程中的SSDBaseTransform
-
前向推理过程中,只对图像做预处理操作。
-
首先,对于给定的一张图片image,我们调用opencv提供的cv2.resize函数将其空间尺寸变换到指定的图像尺寸,比如416x416。
- 注意,经过这么一次操作,原始图像的长宽比通常会被改变,使得图片发生一定的畸变。大多数时候这一问题并不严重,但对于某些场景来说,这种畸变可能会破坏模型对真实世界的认识。
- 因此,在后来的YOLO工作里,采用了保留长宽比的Resize操作。
-
需要注意的是,
我们没有在这里对图像做归一化操作,这一操作我们后在训练部分的代码中再做。 -
在完成了对图像的Resize操作后,
我们也需要对相应的边界框坐标也做必要的调整,因为边界框坐标是相对于图片的,既然图片的尺寸都改变了,边界框坐标也必须做相应的比例变换。最后,我们将标签数据全部转换为torch.Tensor类型,以便后续的处理。
# RT-ODLab\dataset\data_augment\ssd_augment.py## SSD-style valTransform
class SSDBaseTransform(object):def __init__(self, img_size):self.img_size = img_sizedef __call__(self, image, target=None, mosaic=False):deltas = None# resizeorig_h, orig_w = image.shape[:2]image = cv2.resize(image, (self.img_size, self.img_size)).astype(np.float32)# scale targetsif target is not None:boxes = target['boxes'].copy()labels = target['labels'].copy()img_h, img_w = image.shape[:2]boxes[..., [0, 2]] = boxes[..., [0, 2]] / orig_w * img_wboxes[..., [1, 3]] = boxes[..., [1, 3]] / orig_h * img_htarget['boxes'] = boxes# to tensorimg_tensor = torch.from_numpy(image).permute(2, 0, 1).contiguous().float()if target is not None:target['boxes'] = torch.from_numpy(boxes).float()target['labels'] = torch.from_numpy(labels).float()return img_tensor, target, deltas
至此,我们讲完了数据预处理操作,接下来,我们就可以在开始训练我们实现的YOLOv1模型。
相关文章:
复现YOLOV1(4)VOC2007数据集的读取及预处理)
经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理
经典目标检测YOLO系列(一)复现YOLOV1(4)VOC2007数据集的读取及预处理 之前,我们依据《YOLO目标检测》(ISBN:9787115627094)一书,提出了新的YOLOV1架构,并解决前向推理过程中的两个问题,继续按照此书进行YOLOV1的复现。 经典目标检…...
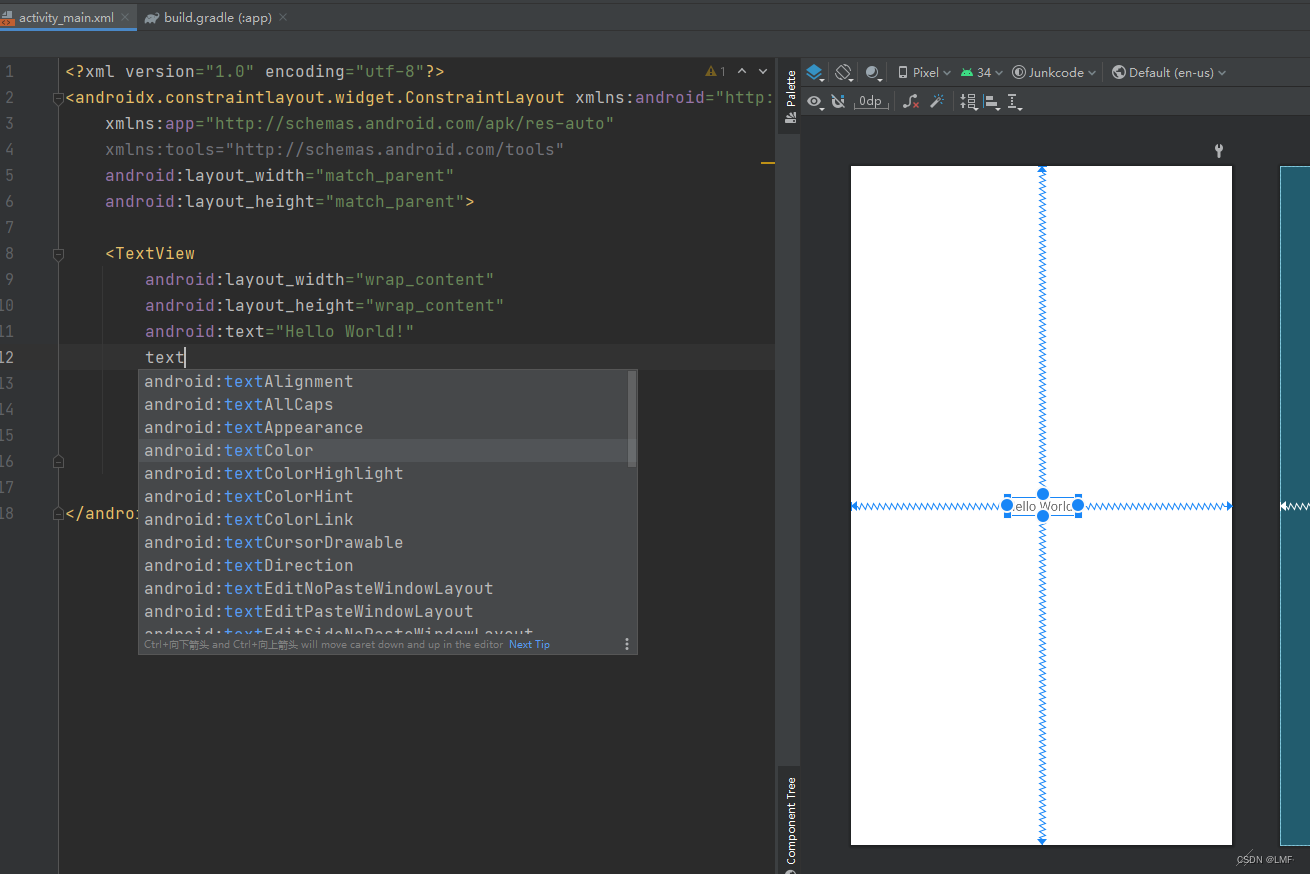
Android Studio xml布局代码补全功能失效问题
这里写目录标题 前言:问题描述原因分析:解决方案:1.更新 Android Studio 版本2.原版本解决XML补全失效 小结 前言: 在开发过程中,你可能遇到很多奇奇怪怪的问题。Android Studio 编译器出现问题也是常有的事情&#x…...

算法每日一题:队列中可以看到的人数 | 单调栈
大家好,我是星恒 今天是一道困难题,他的题解比较好理解,但是不好想出来,接下来就让我带大家来捋一捋这道题的思路,以及他有什么特征 题目:leetcode 1944有 n 个人排成一个队列,从左到右 编号为 …...

报表控件Stimulsoft 2023回顾:都做了哪些产品的改变?
在2023年过去一年中,报表控件Stimulsoft 针各类控件都做了重大改变,其中新增了某些产品、同时加强了很多产品的性能和UI设计,更加符合开发者需求,下面就跟随小编一起来回顾,具体都有哪些↓↓↓ Stimulsoft Ultimate &…...
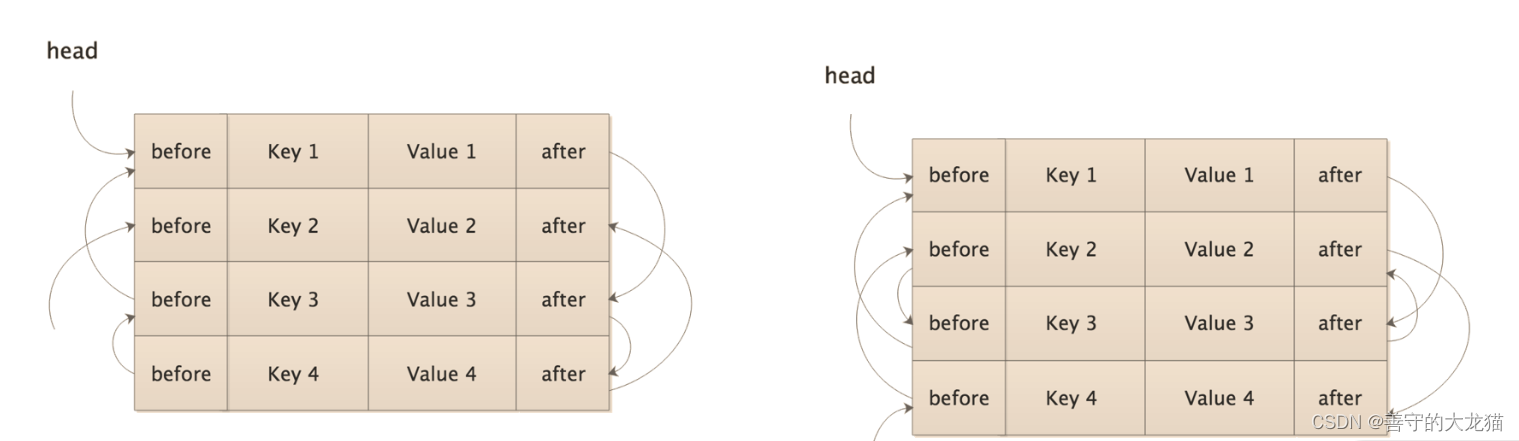
Mybatis缓存实现方式
文章目录 装饰器模式Cache 接口及核心实现Cache 接口装饰器1. BlockingCache2. FifoCache3. LruCache4. SoftCache5. WeakCache 小结 缓存是优化数据库性能的常用手段之一,我们在实践中经常使用的是 Memcached、Redis 等外部缓存组件,很多持久化框架提供…...
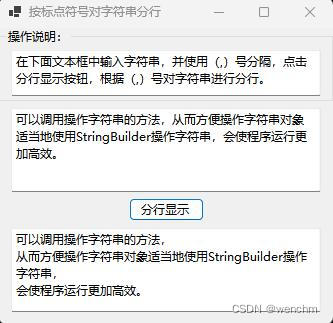
C#用StringBuilder高效处理字符串
目录 一、背景 二、使用StringBuilder便捷、高效地操作字符串 三、实例 1.源码 2.生成效果 四、实例中知识点 1.StringBuilder 构造函数 (1)定义 (2)重载 (3)StringBuilder() (4&…...
答案(4.2))
python开发案例教程-清华大学出版社(张基温)答案(4.2)
目录 练习 4.2 1. 代码分析题 2. 程序设计题 练习 4.2 1. 代码分析题 阅读下面的代码,给出输出结果。 (1) class A:def __init__(self,a,b,c):self.xabca A(3,5,7);b getattr(a,x);setattr(a,x,b3);print(a.x)18 (2&…...
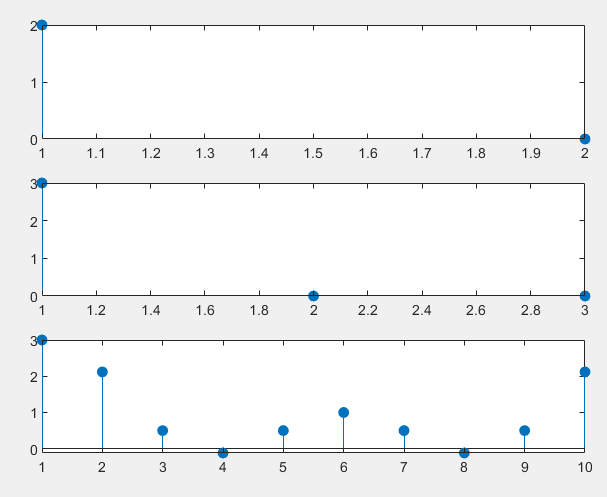
【MATLAB】【数字信号处理】线性卷积和抽样定理
已知有限长序列:xk1,2,1,1,0,-3, hk[1,-1,1] , 计算离散卷积和ykxk*h(k) 。 程序如下: function [t,x] My_conv(x1,x2,t1,t2,dt) %文件名与函数名对应 %自写的卷积函数 x conv(x1,x2)*dt; t0 t1(1) t2(1); L length(x1) length(x2)-2; t t0:dt…...

什么是 MVVM ?
课堂笔记 什么是 MVVM ? MVVM 是一种架构模式,它最初是由微软的两位工程师在 2005 年的时候所提出的。 Model:Model代表的是你的数据View:视图,直接和用户打交道的ViewModel:ViewModel 是 View 和 Model…...
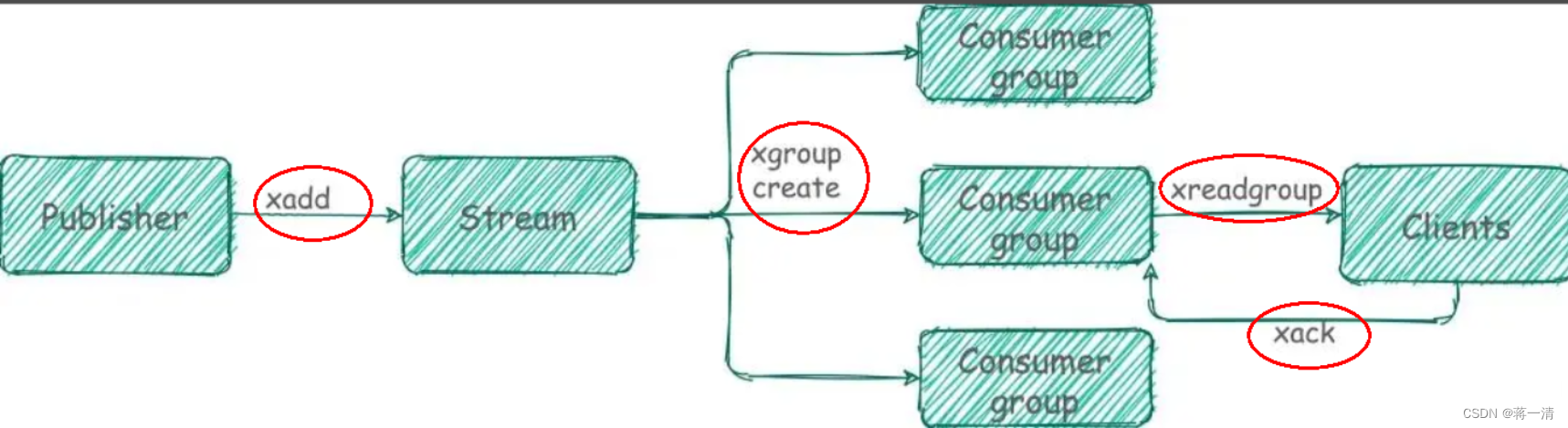
Redis(一)
1、redis Redis是一个完全开源免费的高性能(NOSQL)的key-value数据库。它遵守BSD协议,使用ANSI C语言编写,并支持网络和持久化。Redis拥有极高的性能,每秒可以进行11万次的读取操作和8.1万次的写入操作。它支持丰富的数…...
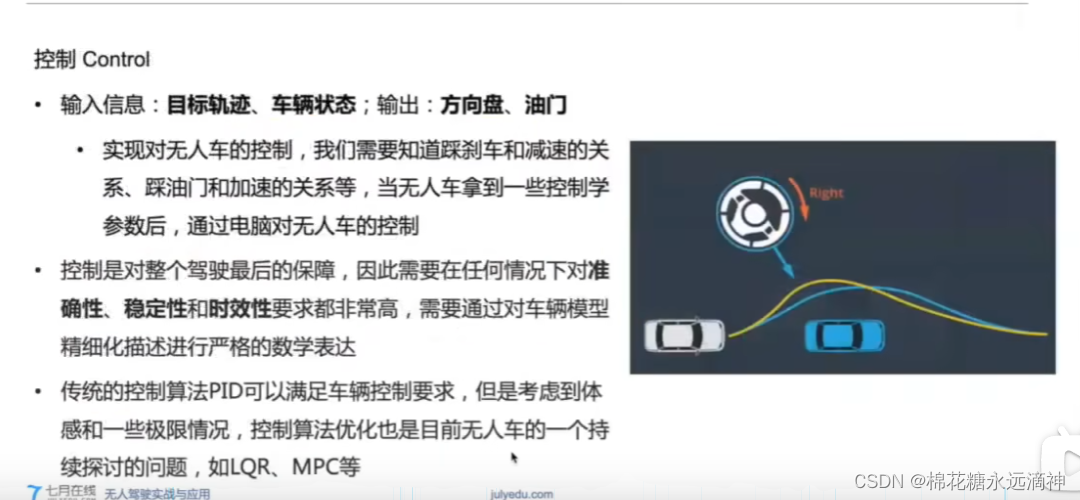
自动驾驶预测-决策-规划-控制学习(1):自动驾驶框架、硬件、软件概述
文章目录 前言:无人驾驶分级一、不同level的无人驾驶实例分析1.L2级别2.L3级别3.L4级别①如何在减少成本的情况下,实现类似全方位高精度的感知呢?②路侧终归是辅助,主车的智能才是重中之重:融合深度学习 二、无人驾驶的…...
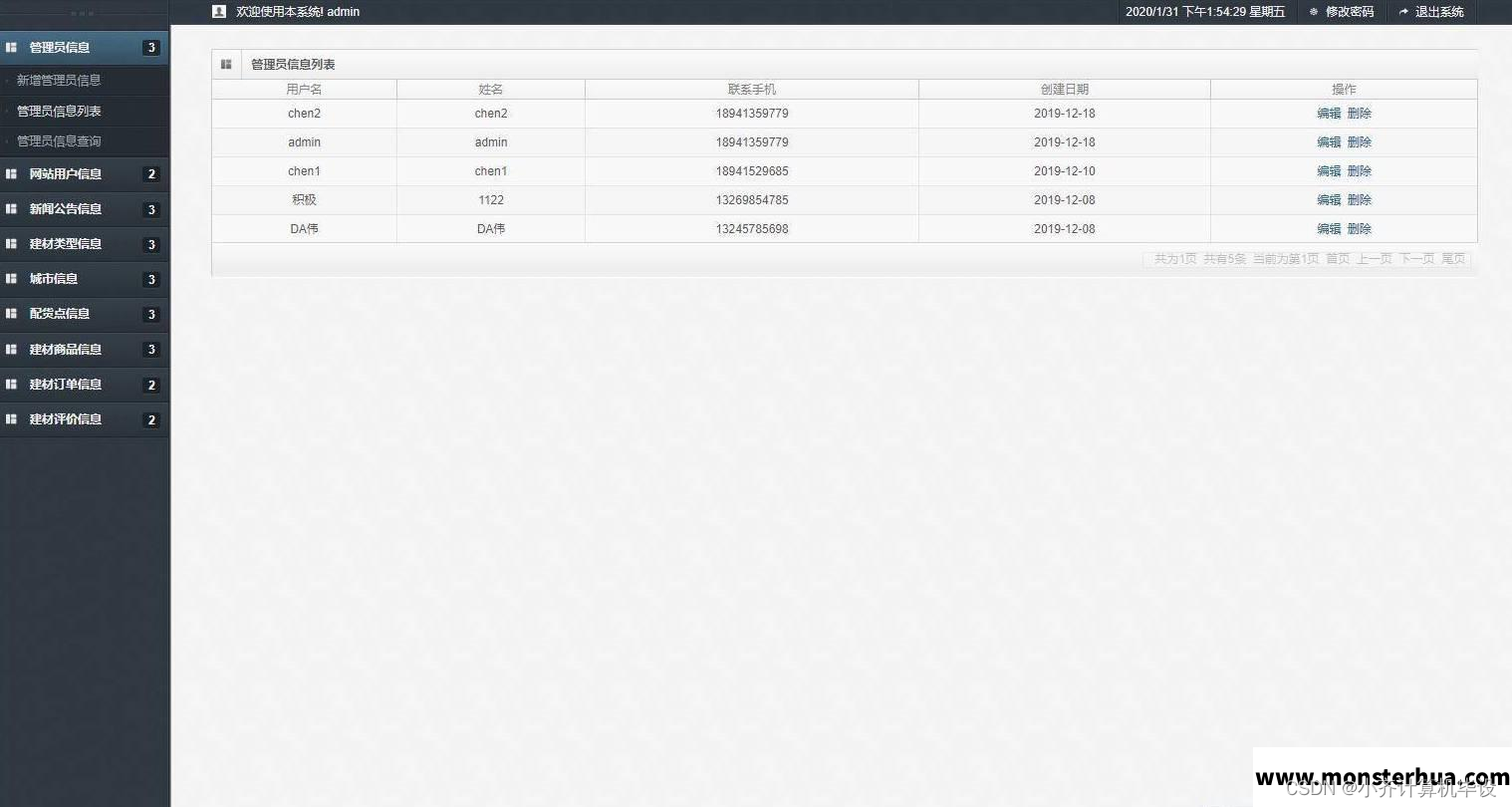
SSM建材商城网站----计算机毕业设计
项目介绍 本项目分为前后台,前台为普通用户登录,后台为管理员登录; 管理员角色包含以下功能: 管理员登录,管理员管理,注册用户管理,新闻公告管理,建材类型管理,配货点管理,建材商品管理,建材订单管理,建材评价管理等功能。 用…...

js逆向第9例:猿人学第2题-js混淆-动态cookie1
题目2:提取全部5页发布日热度的值,计算所有值的加和,并提交答案 (感谢蔡老板为本题提供混淆方案) 既然题目已经给出了cookie问题,那就从cookie入手,控制台找到数据请求地址 可以看到如下加密字符串m类似md5,后面跟着时间戳 m=45cc41dcdb15159ebb50564635f8e362|1704301…...
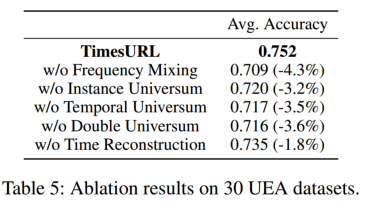
[论文分享]TimesURL:通用时间序列表示学习的自监督对比学习
论文题目:TimesURL: Self-supervised Contrastive Learning for Universal Time Series Representation Learning 论文地址:https://arxiv.org/abs/2312.15709 代码地址:暂无 摘要 学习适用于各种下游任务的通用时间序列表示具有挑战性&…...
解决sublime中文符号乱码问题
效果图 原来 后来 问题不是出自encode文件编码,而是win10的字体问题。 解决方法 配置: { "font_face":"Microsoft Yahei", "dpi_scale": 1.0 } 参考自 Sublime 输入中文显示方框问号乱码_sublime中文问号-CSDN博…...

厚积薄发11年,鸿蒙究竟有多可怕
12月20日中国工程院等权威单位发布《2023年全球十大工程成就》。本次发布的2023全球十大工程成就包括“鸿蒙操作系统”在内。入围的“全球十大工程成就”,主要指过去五年由世界各国工程科技工作者合作或单独完成且实践验证有效的,并且已经产生全球影响…...
 pyDAL查询操作)
pyDAL一个python的ORM(4) pyDAL查询操作
1 、简单查询 rows db(db.person.dept marketing).select(db.person.id, db.person.name, db.person.dept) rows db(db.person.dept marketing).select() rows db(db.person.dept marketing).select(db.person.ALL) rows db().select(db.person.ALL) / db(db.person).se…...

如何通过Python将各种数据写入到Excel工作表
在数据处理和报告生成等工作中,Excel表格是一种常见且广泛使用的工具。然而,手动将大量数据输入到Excel表格中既费时又容易出错。为了提高效率并减少错误,使用Python编程语言来自动化数据写入Excel表格是一个明智的选择。Python作为一种简单易…...
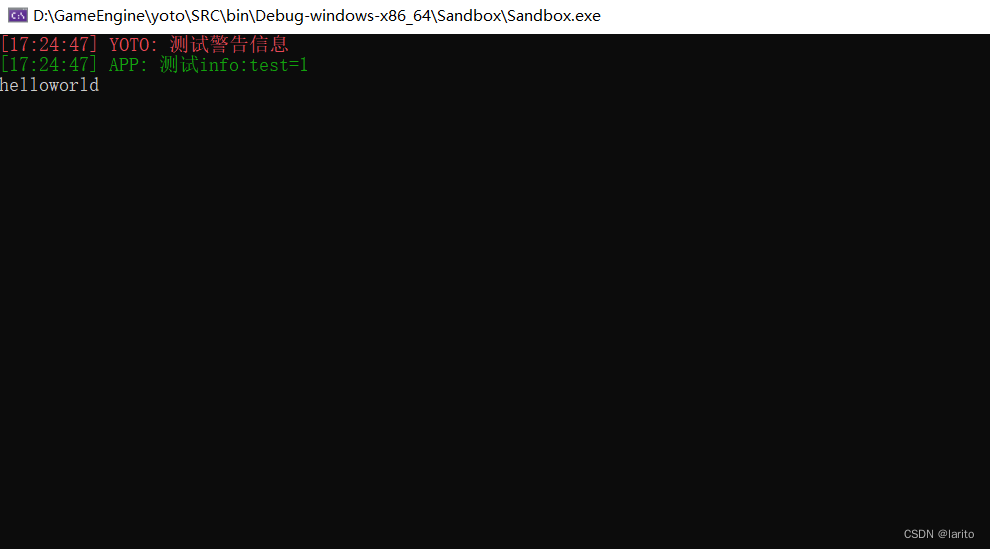
跟着cherno手搓游戏引擎【2】:日志系统spdlog和premake的使用
配置: 日志库文件github: GitHub - gabime/spdlog: Fast C logging library. 新建vendor文件夹 将下载好的spdlog放入 配置YOTOEngine的附加包含目录: 配置Sandbox的附加包含目录: 包装spdlog: 在YOTO文件夹下创建…...
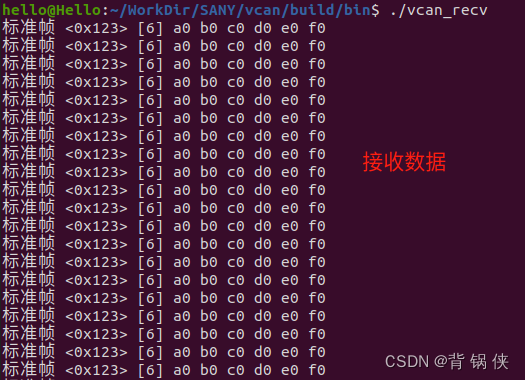
Ubuntu20.04 上启用 VCAN 用作本地调试
目录 一、启用本机的 VCAN 编辑 1.1 加载本机的 vcan 1.2 添加本机的 vcan0 1.3 查看添加的 vcan0 1.4 开启本机的 vcan0 1.5 关闭本机的 vcan0 1.6 删除本机的 vcan0 二、测试本机的 VCAN 2.1 CAN 发送数据 代码 2.2 CAN 接收数据 代码 2.3 CMakeLists.…...

内存分配函数malloc kmalloc vmalloc
内存分配函数malloc kmalloc vmalloc malloc实现步骤: 1)请求大小调整:首先,malloc 需要调整用户请求的大小,以适应内部数据结构(例如,可能需要存储额外的元数据)。通常,这包括对齐调整,确保分配的内存地址满足特定硬件要求(如对齐到8字节或16字节边界)。 2)空闲…...

家政维修平台实战20:权限设计
目录 1 获取工人信息2 搭建工人入口3 权限判断总结 目前我们已经搭建好了基础的用户体系,主要是分成几个表,用户表我们是记录用户的基础信息,包括手机、昵称、头像。而工人和员工各有各的表。那么就有一个问题,不同的角色…...

python如何将word的doc另存为docx
将 DOCX 文件另存为 DOCX 格式(Python 实现) 在 Python 中,你可以使用 python-docx 库来操作 Word 文档。不过需要注意的是,.doc 是旧的 Word 格式,而 .docx 是新的基于 XML 的格式。python-docx 只能处理 .docx 格式…...

【Web 进阶篇】优雅的接口设计:统一响应、全局异常处理与参数校验
系列回顾: 在上一篇中,我们成功地为应用集成了数据库,并使用 Spring Data JPA 实现了基本的 CRUD API。我们的应用现在能“记忆”数据了!但是,如果你仔细审视那些 API,会发现它们还很“粗糙”:有…...

Unity | AmplifyShaderEditor插件基础(第七集:平面波动shader)
目录 一、👋🏻前言 二、😈sinx波动的基本原理 三、😈波动起来 1.sinx节点介绍 2.vertexPosition 3.集成Vector3 a.节点Append b.连起来 4.波动起来 a.波动的原理 b.时间节点 c.sinx的处理 四、🌊波动优化…...

USB Over IP专用硬件的5个特点
USB over IP技术通过将USB协议数据封装在标准TCP/IP网络数据包中,从根本上改变了USB连接。这允许客户端通过局域网或广域网远程访问和控制物理连接到服务器的USB设备(如专用硬件设备),从而消除了直接物理连接的需要。USB over IP的…...

华为OD机考-机房布局
import java.util.*;public class DemoTest5 {public static void main(String[] args) {Scanner in new Scanner(System.in);// 注意 hasNext 和 hasNextLine 的区别while (in.hasNextLine()) { // 注意 while 处理多个 caseSystem.out.println(solve(in.nextLine()));}}priv…...

git: early EOF
macOS报错: Initialized empty Git repository in /usr/local/Homebrew/Library/Taps/homebrew/homebrew-core/.git/ remote: Enumerating objects: 2691797, done. remote: Counting objects: 100% (1760/1760), done. remote: Compressing objects: 100% (636/636…...
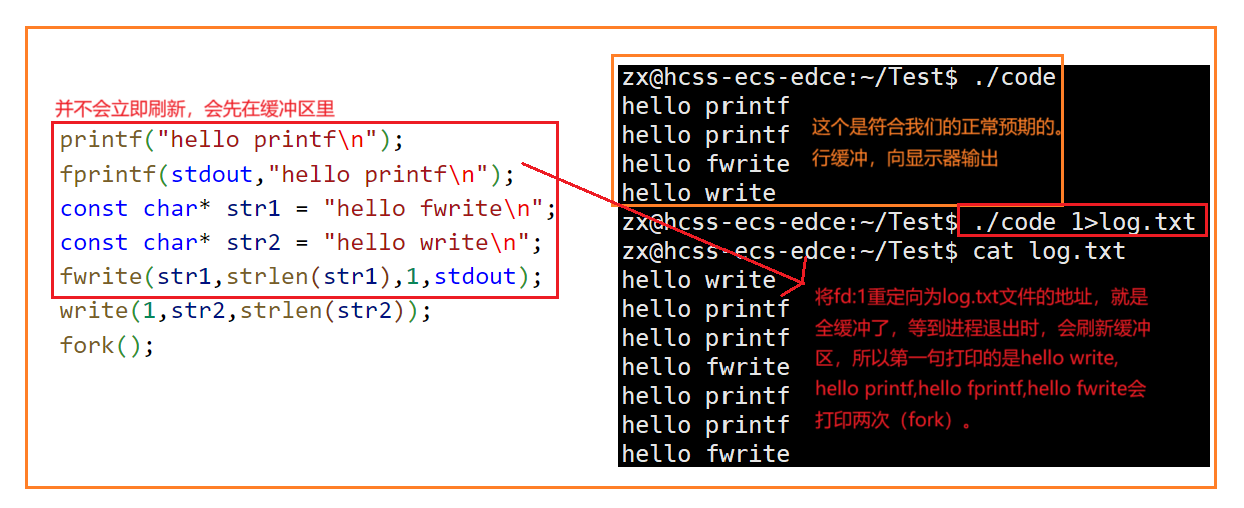
Linux中《基础IO》详细介绍
目录 理解"文件"狭义理解广义理解文件操作的归类认知系统角度文件类别 回顾C文件接口打开文件写文件读文件稍作修改,实现简单cat命令 输出信息到显示器,你有哪些方法stdin & stdout & stderr打开文件的方式 系统⽂件I/O⼀种传递标志位…...

[特殊字符] 手撸 Redis 互斥锁那些坑
📖 手撸 Redis 互斥锁那些坑 最近搞业务遇到高并发下同一个 key 的互斥操作,想实现分布式环境下的互斥锁。于是私下顺手手撸了个基于 Redis 的简单互斥锁,也顺便跟 Redisson 的 RLock 机制对比了下,记录一波,别踩我踩过…...