互联网加竞赛 基于人工智能的图像分类算法研究与实现 - 深度学习卷积神经网络图像分类
文章目录
- 0 简介
- 1 常用的分类网络介绍
- 1.1 CNN
- 1.2 VGG
- 1.3 GoogleNet
- 2 图像分类部分代码实现
- 2.1 环境依赖
- 2.2 需要导入的包
- 2.3 参数设置(路径,图像尺寸,数据集分割比例)
- 2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
- 2.5 数据预处理
- 2.6 训练分类模型
- 2.7 模型训练效果
- 2.8 模型性能评估
- 3 1000种图像分类
- 4 最后
0 简介
🔥 优质竞赛项目系列,今天要分享的是
基于人工智能的图像分类技术
该项目较为新颖,适合作为竞赛课题方向,学长非常推荐!
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
1 常用的分类网络介绍
1.1 CNN
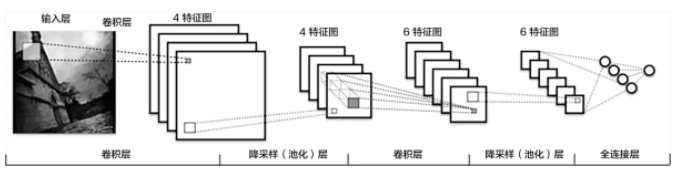
传统CNN包含卷积层、全连接层等组件,并采用softmax多类别分类器和多类交叉熵损失函数。如下图:
-
卷积层(convolution layer): 执行卷积操作提取底层到高层的特征,发掘出图片局部关联性质和空间不变性质。
-
池化层(pooling layer): 执行降采样操作。通过取卷积输出特征图中局部区块的最大值(max-pooling)或者均值(avg-pooling)。降采样也是图像处理中常见的一种操作,可以过滤掉一些不重要的高频信息。
-
全连接层(fully-connected layer,或者fc layer): 输入层到隐藏层的神经元是全部连接的。
-
非线性变化: 卷积层、全连接层后面一般都会接非线性变化层,例如Sigmoid、Tanh、ReLu等来增强网络的表达能力,在CNN里最常使用的为ReLu激活函数。
-
Dropout : 在模型训练阶段随机让一些隐层节点权重不工作,提高网络的泛化能力,一定程度上防止过拟合
在CNN的训练过程总,由于每一层的参数都是不断更新的,会导致下一次输入分布发生变化,这样就需要在训练过程中花费时间去设计参数。在后续提出的BN算法中,由于每一层都做了归一化处理,使得每一层的分布相对稳定,而且实验证明该算法加速了模型的收敛过程,所以被广泛应用到较深的模型中。
1.2 VGG
VGG 模型是由牛津大学提出的(19层网络),该模型的特点是加宽加深了网络结构,核心是五组卷积操作,每两组之间做Max-
Pooling空间降维。同一组内采用多次连续的3X3卷积,卷积核的数目由较浅组的64增多到最深组的512,同一组内的卷积核数目是一样的。卷积之后接两层全连接层,之后是分类层。该模型由于每组内卷积层的不同主要分为
11、13、16、19 这几种模型

增加网络深度和宽度,也就意味着巨量的参数,而巨量参数容易产生过拟合,也会大大增加计算量。
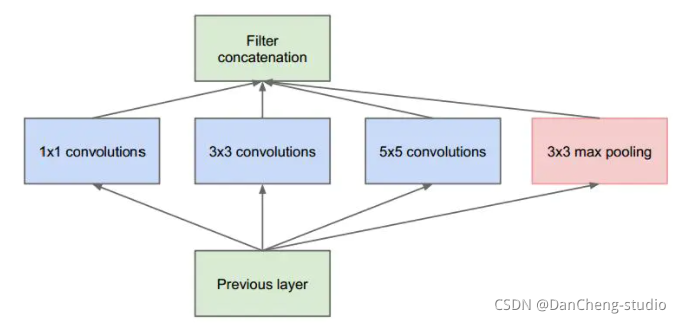
1.3 GoogleNet
GoogleNet模型由多组Inception模块组成,模型设计借鉴了NIN的一些思想.
NIN模型特点:
-
1. 引入了多层感知卷积网络(Multi-Layer Perceptron Convolution, MLPconv)代替一层线性卷积网络。MLPconv是一个微小的多层卷积网络,即在线性卷积后面增加若干层1x1的卷积,这样可以提取出高度非线性特征。 - 2)设计最后一层卷积层包含类别维度大小的特征图,然后采用全局均值池化(Avg-Pooling)替代全连接层,得到类别维度大小的向量,再进行分类。这种替代全连接层的方式有利于减少参数。
Inception 结构的主要思路是怎样用密集成分来近似最优的局部稀疏结构。
2 图像分类部分代码实现
2.1 环境依赖
python 3.7
jupyter-notebook : 6.0.3
cudatoolkit 10.0.130
cudnn 7.6.5
tensorflow-gpu 2.0.0
scikit-learn 0.22.1
numpy
cv2
matplotlib
2.2 需要导入的包
import osimport cv2import numpy as npimport pandas as pdimport tensorflow as tffrom tensorflow import kerasfrom tensorflow.keras import layers,modelsfrom tensorflow.keras.models import Sequentialfrom tensorflow.keras.optimizers import Adamfrom tensorflow.keras.callbacks import Callbackfrom tensorflow.keras.utils import to_categoricalfrom tensorflow.keras.applications import VGG19from tensorflow.keras.models import load_modelimport matplotlib.pyplot as pltfrom sklearn.preprocessing import label_binarizetf.compat.v1.disable_eager_execution()os.environ['CUDA_VISIBLE_DEVICES'] = '0' #使用GPU
2.3 参数设置(路径,图像尺寸,数据集分割比例)
preprocessedFolder = '.\\ClassificationData\\' #预处理文件夹outModelFileName=".\\outModelFileName\\" ImageWidth = 512ImageHeight = 320ImageNumChannels = 3TrainingPercent = 70 #训练集比例ValidationPercent = 15 #验证集比例
2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)
def read_dl_classifier_data_set(preprocessedFolder):num = 0 # 图片的总数量cnt_class = 0 #图片所属的类别label_list = [] # 存放每个图像的label,图像的类别img_list = [] #存放图片数据for directory in os.listdir(preprocessedFolder):tmp_dir = preprocessedFolder + directorycnt_class += 1for image in os.listdir(tmp_dir):num += 1tmp_img_filepath = tmp_dir + '\\' + imageim = cv2.imread(tmp_img_filepath) # numpy.ndarrayim = cv2.resize(im, (ImageWidth, ImageHeight)) # 重新设置图片的大小img_list.append(im)label_list.append(cnt_class) # 在标签中添加类别print("Picture " + str(num) + "Load "+tmp_img_filepath+"successfully")
print("共有" + str(num) + "张图片")
print("all"+str(num)+"picturs belong to "+str(cnt_class)+"classes")
return np.array(img_list),np.array(label_list)all_data,all_label=read_dl_classifier_data_set(preprocessedFolder)
2.5 数据预处理
图像数据压缩, 标签数据进行独立热编码one-hot
def preprocess_dl_Image(all_data,all_label):all_data = all_data.astype("float32")/255 #把图像灰度值压缩到0--1.0便于神经网络训练all_label = to_categorical(all_label) #对标签数据进行独立热编码return all_data,all_labelall_data,all_label = preprocess_dl_Image(all_data,all_label) #处理后的数据
对数据及进行划分(训练集:验证集:测试集 = 0.7:0.15:0.15)
def split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent):s = np.arange(all_data.shape[0])np.random.shuffle(s) #随机打乱顺序all_data = all_data[s] #打乱后的图像数据all_label = all_label[s] #打乱后的标签数据all_len = all_data.shape[0]train_len = int(all_len*TrainingPercent/100) #训练集长度valadation_len = int(all_len*ValidationPercent/100)#验证集长度temp_len=train_len+valadation_lentrain_data,train_label = all_data[0:train_len,:,:,:],all_label[0:train_len,:] #训练集valadation_data,valadation_label = all_data[train_len:temp_len, : , : , : ],all_label[train_len:temp_len, : ] #验证集test_data,test_label = all_data[temp_len:, : , : , : ],all_label[temp_len:, : ] #测试集return train_data,train_label,valadation_data,valadation_label,test_data,test_labeltrain_data,train_label,valadation_data,valadation_label,test_data,test_label=split_dl_classifier_data_set(all_data,all_label,TrainingPercent,ValidationPercent)
2.6 训练分类模型
-
使用迁移学习(基于VGG19)
-
epochs = 30
-
batch_size = 16
-
使用 keras.callbacks.EarlyStopping 提前结束训练
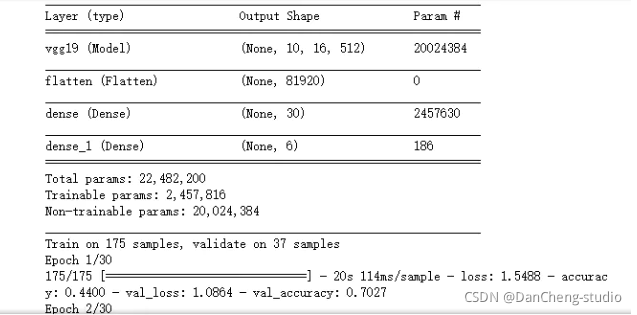
def train_classifier(train_data,train_label,valadation_data,valadation_label,lr=1e-4):conv_base = VGG19(weights='imagenet',include_top=False,input_shape=(ImageHeight, ImageWidth, 3) ) model = models.Sequential()model.add(conv_base)model.add(layers.Flatten())model.add(layers.Dense(30, activation='relu')) model.add(layers.Dense(6, activation='softmax')) #Dense: 全连接层。activation: 激励函数,‘linear’一般用在回归任务的输出层,而‘softmax’一般用在分类任务的输出层conv_base.trainable=Falsemodel.compile(loss='categorical_crossentropy',#loss: 拟合损失方法,这里用到了多分类损失函数交叉熵 optimizer=Adam(lr=lr),#optimizer: 优化器,梯度下降的优化方法 #rmspropmetrics=['accuracy'])model.summary() #每个层中的输出形状和参数。early_stoping =tf.keras.callbacks.EarlyStopping(monitor="val_loss",min_delta=0,patience=5,verbose=0,baseline=None,restore_best_weights=True)history = model.fit(train_data, train_label,batch_size=16, #更新梯度的批数据的大小 iteration = epochs / batch_size,epochs=30, # 迭代次数validation_data=(valadation_data, valadation_label), # 验证集callbacks=[early_stoping])return model,history model,history = train_classifier(train_data,train_label,valadation_data,valadation_label,)
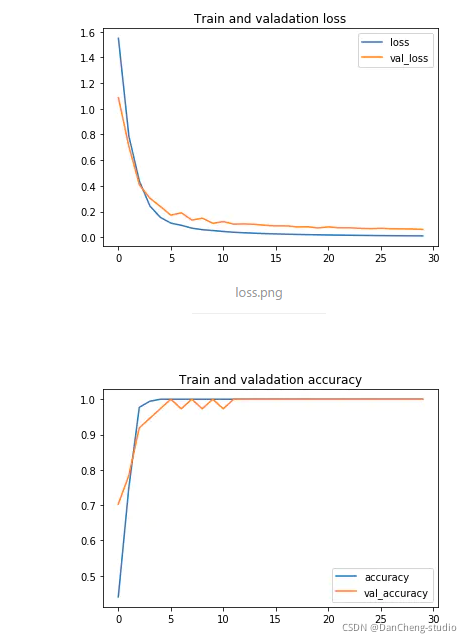
2.7 模型训练效果
def plot_history(history):history_df = pd.DataFrame(history.history)history_df[['loss', 'val_loss']].plot()plt.title('Train and valadation loss')history_df = pd.DataFrame(history.history)history_df[['accuracy', 'val_accuracy']].plot()plt.title('Train and valadation accuracy')plot_history(history)
2.8 模型性能评估
-
使用测试集进行评估
-
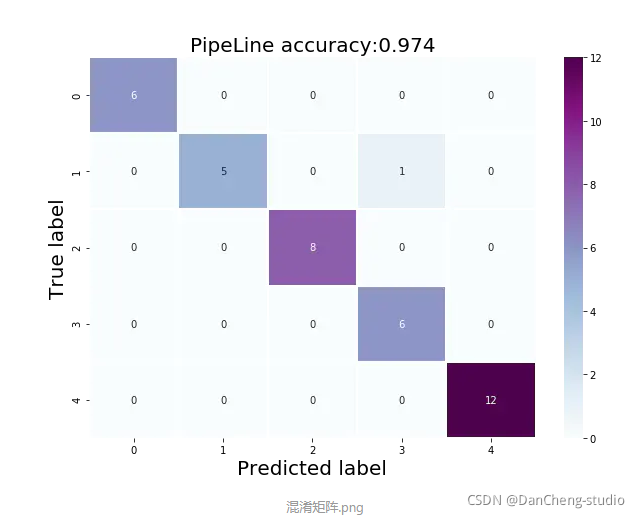
输出分类报告和混淆矩阵
-
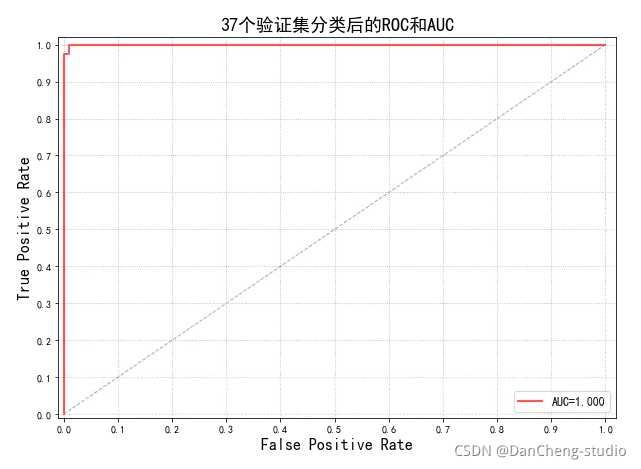
绘制ROC和AUC曲线
from sklearn.metrics import classification_report from sklearn.metrics import confusion_matrix from sklearn.metrics import accuracy_score import seaborn as sns Y_pred_tta=model.predict_classes(test_data) #模型对测试集数据进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 Y_pred_tta=model.predict_classes(test_data) #模型对测试集进行预测 Y_test = [np.argmax(one_hot)for one_hot in test_label]# 由one-hot转换为普通np数组 print('验证集分类报告:\n',classification_report(Y_test,Y_pred_tta)) confusion_mc = confusion_matrix(Y_test,Y_pred_tta)#混淆矩阵 df_cm = pd.DataFrame(confusion_mc) plt.figure(figsize = (10,7)) sns.heatmap(df_cm, annot=True, cmap="BuPu",linewidths=1.0,fmt="d") plt.title('PipeLine accuracy:{0:.3f}'.format(accuracy_score(Y_test,Y_pred_tta)),fontsize=20) plt.ylabel('True label',fontsize=20) plt.xlabel('Predicted label',fontsize=20)

from sklearn.metrics import precision_recall_curve
from sklearn.metrics import average_precision_score
from sklearn.metrics import roc_curve
from sklearn import metrics
import matplotlib as mpl# 计算属于各个类别的概率,返回值的shape = [n_samples, n_classes]
y_score = model.predict_proba(test_data)
# 1、调用函数计算验证集的AUC
print ('调用函数auc:', metrics.roc_auc_score(test_label, y_score, average='micro'))
# 2、手动计算验证集的AUC
#首先将矩阵test_label和y_score展开,然后计算假正例率FPR和真正例率TPR
fpr, tpr, thresholds = metrics.roc_curve(test_label.ravel(),y_score.ravel())
auc = metrics.auc(fpr, tpr)
print('手动计算auc:', auc)
mpl.rcParams['font.sans-serif'] = u'SimHei'
mpl.rcParams['axes.unicode_minus'] = False
#FPR就是横坐标,TPR就是纵坐标
plt.figure(figsize = (10,7))
plt.plot(fpr, tpr, c = 'r', lw = 2, alpha = 0.7, label = u'AUC=%.3f' % auc)
plt.plot((0, 1), (0, 1), c = '#808080', lw = 1, ls = '--', alpha = 0.7)
plt.xlim((-0.01, 1.02))
plt.ylim((-0.01, 1.02))
plt.xticks(np.arange(0, 1.1, 0.1))
plt.yticks(np.arange(0, 1.1, 0.1))
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.grid(b=True, ls=':')
plt.legend(loc='lower right', fancybox=True, framealpha=0.8, fontsize=12)
plt.title('37个验证集分类后的ROC和AUC', fontsize=18)
plt.show()
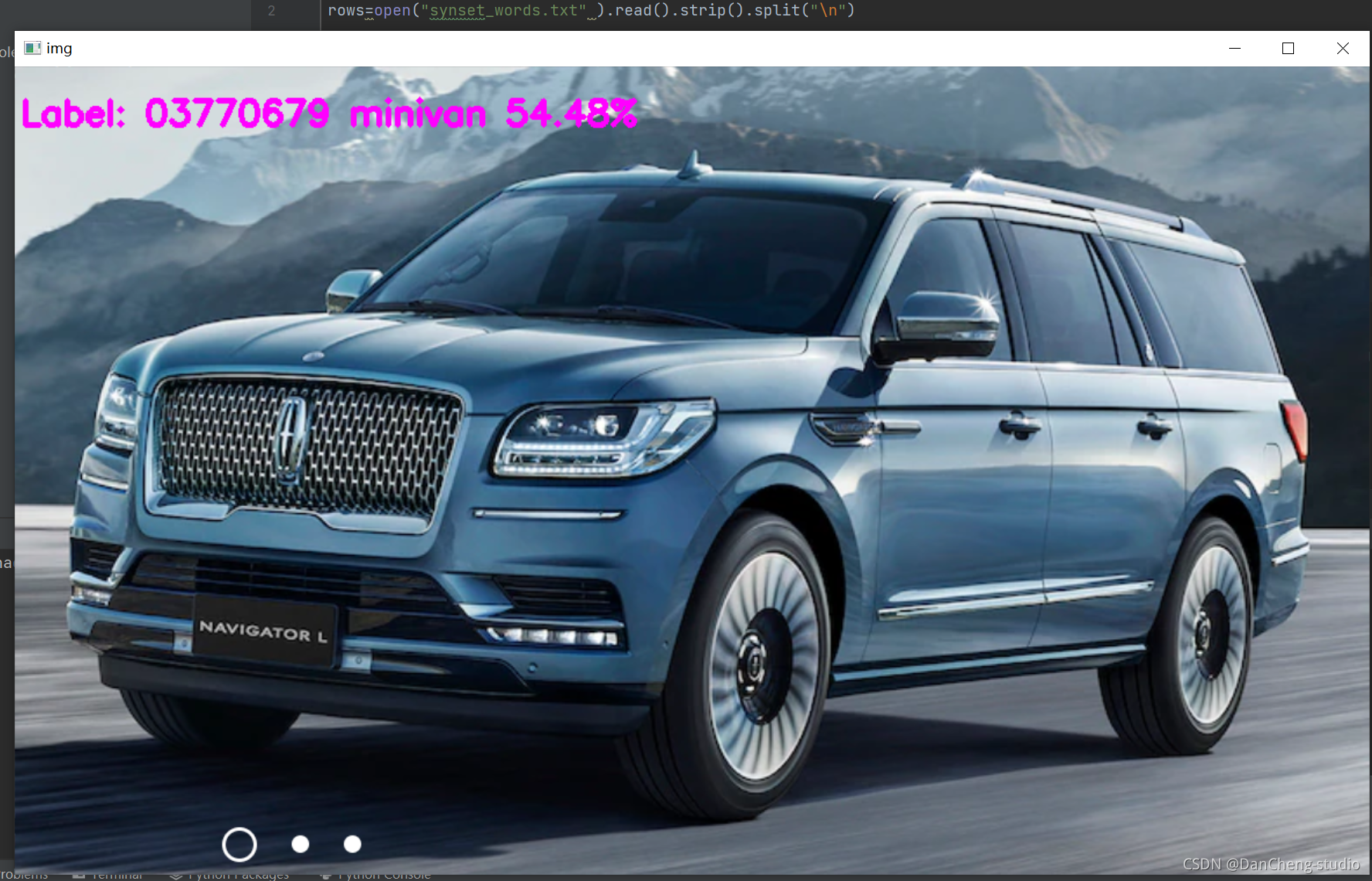
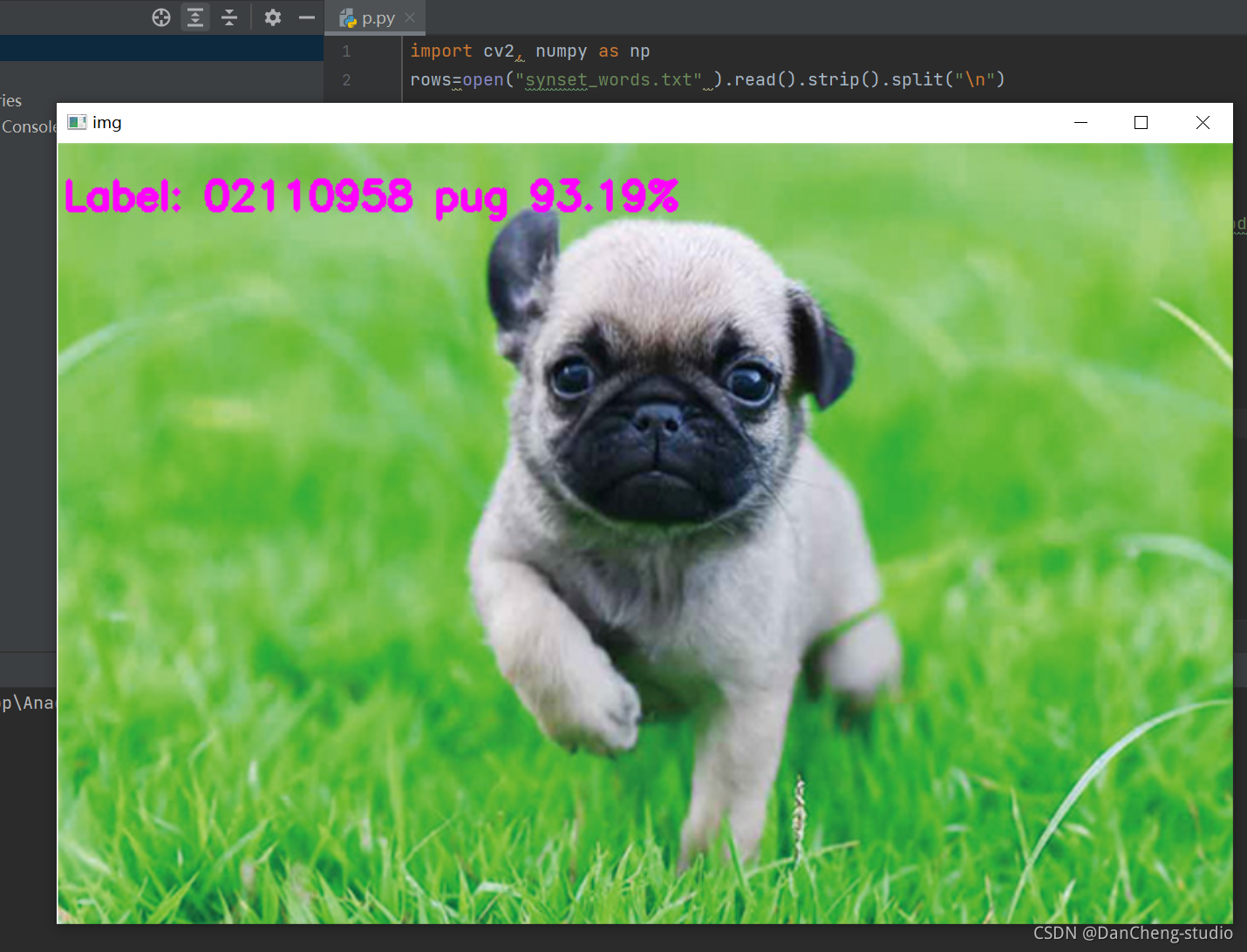
3 1000种图像分类
这是学长训练的能识别1000种类目标的图像分类模型,演示效果如下

4 最后
🧿 更多资料, 项目分享:
https://gitee.com/dancheng-senior/postgraduate
相关文章:
互联网加竞赛 基于人工智能的图像分类算法研究与实现 - 深度学习卷积神经网络图像分类
文章目录 0 简介1 常用的分类网络介绍1.1 CNN1.2 VGG1.3 GoogleNet 2 图像分类部分代码实现2.1 环境依赖2.2 需要导入的包2.3 参数设置(路径,图像尺寸,数据集分割比例)2.4 从preprocessedFolder读取图片并返回numpy格式(便于在神经网络中训练)2.5 数据预…...

pip安装报错SSL
confirming the ssl certificate: HTTPSConnectionPool(hostmirrors.cloud.tencent.com, port443) 错误代码如上 偶然搜索:ubuntu pip出错 confirming the ssl certificate: HTTPSConnectionPool(host‘mirrors.cloud.tencent.com’, port443) 看到这个回答 【日常踩…...
手机视频监控客户端APP如何实现跨安卓、苹果和windows平台,并满足不同人的使用习惯
目 录 一、手机视频监控客户端的应用和发展 二、手机视频监控客户端存在的问题 三、HTML5视频监控客户端在手机上实现的方案 (一)HTML5及其优点 (二)HTML5在手机上实现视频应用功能的优势 四、手机HTML5…...

从写下第1个脚本到年薪40W,我的自动化测试心路历程
我希望我的故事能够激励现在的软件测试人,尤其是还坚持在做“点点点”的测试人。 你可能会有疑问:“我也能做到这一点的可能性有多大?”因此,我会尽量把自己做决定和思考的过程讲得更具体一些,并尽量体现更多细节。 …...
Vue CLI组件通信
目录 一、组件通信简介1.什么是组件通信?2.组件之间如何通信3.组件关系分类4.通信解决方案5.父子通信流程6.父向子通信代码示例7.子向父通信代码示例8.总结 二、props1.Props 定义2.Props 作用3.特点4.代码演示 三、props校验1.思考2.作用3.语法4.代码演示 四、prop…...
C语言编译器(C语言编程软件)完全攻略(第九部分:VS2019使用教程(使用VS2019编写C语言程序))
介绍常用C语言编译器的安装、配置和使用。 九、VS2019使用教程(使用VS2019编写C语言程序) 继《八、VS2019下载地址和安装教程(图解)》之后,本节给大家讲解如何用 VS2019 编写并运行 C 语言程序。 例如,在…...

走向云原生 破局数字化
近年来,随着云计算概念和技术的普及,云原生一词也越来越热门,云原生成为云计算领域的新变量。行业内,华为、阿里巴巴、字节跳动等各个大厂都在“抢滩”云原生市场。行业外,云原生也逐渐出圈,出现在大众视野…...
springbean类)
spring常用注解(三)springbean类
一、Service用于标注业务层组件、 二、Repository用于标注数据访问组件,即DAO组件。 三、Component泛指组件,当组件不好归类的时候,我们可以使用这个注解进行标注。(pojo) 四、Scope用于指定scope作用域的ÿ…...

qiankun微服务
官网 📦 基于 single-spa 封装,提供了更加开箱即用的 API。 📱 技术栈无关,任意技术栈的应用均可 使用/接入,不论是 React/Vue/Angular/JQuery 还是其他等框架。 💪 HTML Entry 接入方式,让你接…...
文件夹重命名方法:提高效率减少错误,中英文批量翻译文件夹名称
在日常生活和工作中,经常要处理大量的文件夹,无论是整理电脑上的文件,还是为项目分类。如何快速、准确地重命名这些文件夹,对于提高工作效率和减少错误至关重要。现在来看下云炫文件管理器一些实用的文件夹重命名方法,…...

【PHP】where和whereOr一起复杂查询示例
在ThinkPHP 5 中,where 和 whereOr 方法可以一起使用以实现复杂的查询条件。以下是一个示例: // 接收的参数 $param $this->request->param();// 实例化 $query new UserModel();// 关联表 $query->with([collect > function($collect_qu…...
Mysql 动态链接库配置步骤+ 完成封装init和close接口
1、创建新项目 动态链接库dll 2、将附带的文件都删除,创建LXMysql.cpp 3、项目设置 3.1、预编译头,不使用预编译头 3.2、添加头文件 3.3、添加类 3.4、写初始化函数 4、项目配置 4.1、右键解决方案-属性-常规-输出目录 ..\..\bin 4.2、生成lib文件 右…...
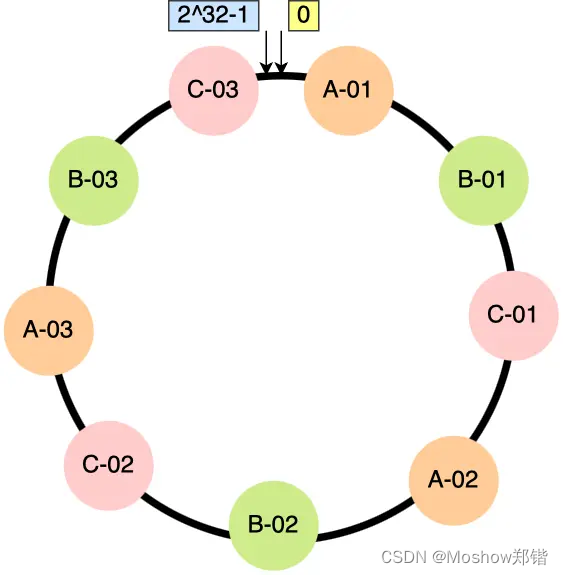
哈希一致性算法
一致性哈希是什么,使用场景,解决了什么问题? #网站分配请求问题? 大多数网站背后肯定不是只有一台服务器提供服务,因为单机的并发量和数据量都是有限的,所以都会用多台服务器构成集群来对外提供服务。 但…...

基于SpringBoot的在线考试系统绿色
文章目录 项目介绍主要功能截图:部分代码展示设计总结项目获取方式🍅 作者主页:超级无敌暴龙战士塔塔开 🍅 简介:Java领域优质创作者🏆、 简历模板、学习资料、面试题库【关注我,都给你】 🍅文末获取源码联系🍅 项目介绍 基于SpringBoot的在线考试系统绿色,java…...

设计模式:原型模式
原型模式 定义代码实现使用场景 定义 原型模式(Prototype Pattern)是一种创建型设计模式,它允许通过复制现有的对象来创建新对象,而无需从头开始编写代码。在这个模式中,我们可以使用已经存在的对象作为“原型”&…...

Qt5+VS2013兼容XP方法
用Qt5VS2013编译程序默认配置会在XP运行时报"不是有效的Win32程序" 工作需要必须要XP运行 pro文件中加一句: QMAKE_LFLAGS_WINDOWS /SUBSYSTEM:WINDOWS,5.01 ------------------------------------------------------- qtbase\mkspecs\common\msvc-desktop.conf …...
GitHub Copilot 最佳免费平替:阿里通义灵码
之前分享了不少关于 GitHub Copilot 的文章,不少粉丝都评论让我试试阿里的通义灵码,这让我对通义灵码有了不少的兴趣。 今天,阿七就带大家了解一下阿里的通义灵码,我们按照之前 GitHub Copilot 的顺序分享通义灵码在相同场景下的…...

体系化的进阶学习内容
UWA学堂:传播游戏行业的体系化的进阶学习内容。UWA学堂作为面向开发者的在线学习平台,目前已经上线272门课程,涵盖了3D引擎渲染、UI、逻辑代码等多个模块,拥有完整的学习体系,一直致力于为广大的开发者提供更丰富、更优…...

SpringBoot解决前后端分离跨域问题:状态码403拒绝访问
最近在写和同学一起做一个前后端分离的项目,今日开始对接口准备进行 登录注册 的时候发现前端在发起请求后,抓包发现后端返回了一个403的错误,解决了很久发现是【跨域问题】,第一次遇到,便作此记录✍ 异常描述 在后端…...

【linux】更改infiniband卡在Debian系统的网络接口名
在Debian或任何其他基于Linux的系统中,网络接口的名称由udev系统管理。通过创建udev规则,可以修改网络接口名称。以下是更改InfiniBand卡接口名称的一般步骤: 1. 找到网络接口的属性,以编写匹配的udev规则 可以使用udevadm命令查…...
Cesium相机控制)
三维GIS开发cesium智慧地铁教程(5)Cesium相机控制
一、环境搭建 <script src"../cesium1.99/Build/Cesium/Cesium.js"></script> <link rel"stylesheet" href"../cesium1.99/Build/Cesium/Widgets/widgets.css"> 关键配置点: 路径验证:确保相对路径.…...

循环冗余码校验CRC码 算法步骤+详细实例计算
通信过程:(白话解释) 我们将原始待发送的消息称为 M M M,依据发送接收消息双方约定的生成多项式 G ( x ) G(x) G(x)(意思就是 G ( x ) G(x) G(x) 是已知的)࿰…...

HTML 列表、表格、表单
1 列表标签 作用:布局内容排列整齐的区域 列表分类:无序列表、有序列表、定义列表。 例如: 1.1 无序列表 标签:ul 嵌套 li,ul是无序列表,li是列表条目。 注意事项: ul 标签里面只能包裹 li…...
)
【RockeMQ】第2节|RocketMQ快速实战以及核⼼概念详解(二)
升级Dledger高可用集群 一、主从架构的不足与Dledger的定位 主从架构缺陷 数据备份依赖Slave节点,但无自动故障转移能力,Master宕机后需人工切换,期间消息可能无法读取。Slave仅存储数据,无法主动升级为Master响应请求ÿ…...

基于SpringBoot在线拍卖系统的设计和实现
摘 要 随着社会的发展,社会的各行各业都在利用信息化时代的优势。计算机的优势和普及使得各种信息系统的开发成为必需。 在线拍卖系统,主要的模块包括管理员;首页、个人中心、用户管理、商品类型管理、拍卖商品管理、历史竞拍管理、竞拍订单…...
宇树科技,改名了!
提到国内具身智能和机器人领域的代表企业,那宇树科技(Unitree)必须名列其榜。 最近,宇树科技的一项新变动消息在业界引发了不少关注和讨论,即: 宇树向其合作伙伴发布了一封公司名称变更函称,因…...
django blank 与 null的区别
1.blank blank控制表单验证时是否允许字段为空 2.null null控制数据库层面是否为空 但是,要注意以下几点: Django的表单验证与null无关:null参数控制的是数据库层面字段是否可以为NULL,而blank参数控制的是Django表单验证时字…...

WPF八大法则:告别模态窗口卡顿
⚙️ 核心问题:阻塞式模态窗口的缺陷 原始代码中ShowDialog()会阻塞UI线程,导致后续逻辑无法执行: var result modalWindow.ShowDialog(); // 线程阻塞 ProcessResult(result); // 必须等待窗口关闭根本问题:…...
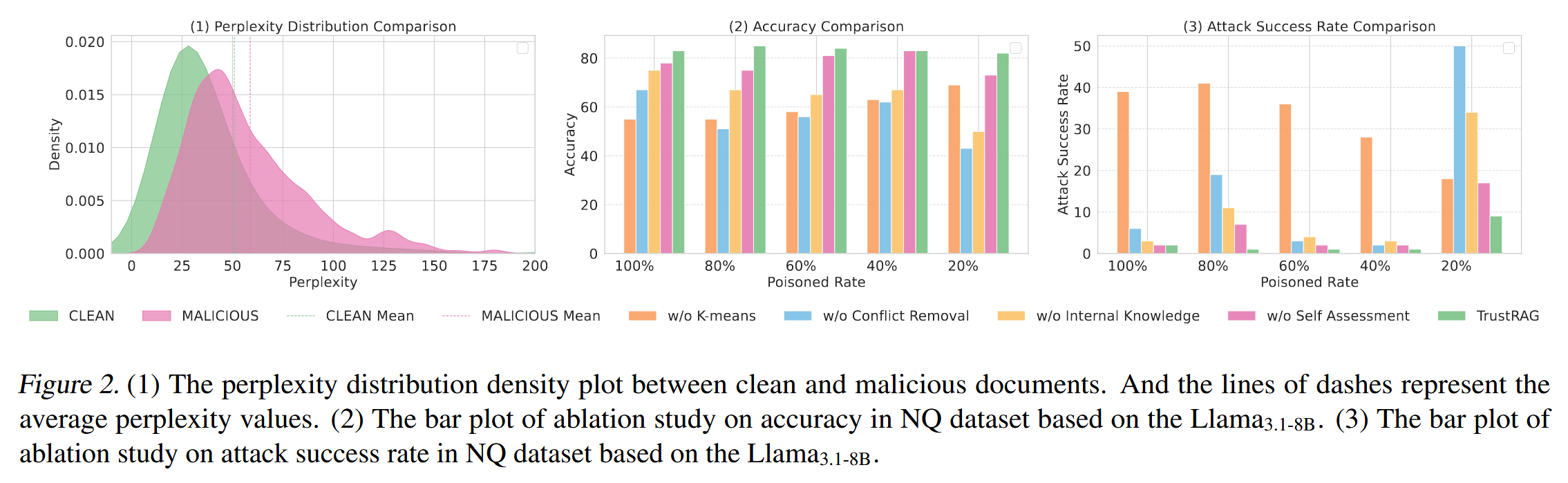
[论文阅读]TrustRAG: Enhancing Robustness and Trustworthiness in RAG
TrustRAG: Enhancing Robustness and Trustworthiness in RAG [2501.00879] TrustRAG: Enhancing Robustness and Trustworthiness in Retrieval-Augmented Generation 代码:HuichiZhou/TrustRAG: Code for "TrustRAG: Enhancing Robustness and Trustworthin…...

【FTP】ftp文件传输会丢包吗?批量几百个文件传输,有一些文件没有传输完整,如何解决?
FTP(File Transfer Protocol)本身是一个基于 TCP 的协议,理论上不会丢包。但 FTP 文件传输过程中仍可能出现文件不完整、丢失或损坏的情况,主要原因包括: ✅ 一、FTP传输可能“丢包”或文件不完整的原因 原因描述网络…...