基于多反应堆的高并发服务器【C/C++/Reactor】(中)Buffer的创建和销毁、扩容、写入数据
TcpConnection:封装的就是建立连接之后得到的用于通信的文件描述符,然后基于这个文件描述符,在发送数据的时候,需要把数据先写入到一块内存里边,然后再把这块内存里边的数据发送给客户端,除了发送数据,剩下的就是接收数据。接收数据,把收到的数据先存储到一块内存里边。也就意味着,无论是发送数据还是接收数据,都需要一块内存。并且这块内存是需要使用者自己去创建的。所以就可以把这块内存做封装成Buffer。

>>>>>>>>>>>>>>>>>>>>>>>>>>>>学习笔记>>>>>>>>>>>>>>>>>>>>>>>>>>>>
1.文件描述符与数据发送:
- 在发送数据时,需要先将数据写入内存缓冲区(buffer)。
- 内存缓冲区可以通过封装成一个Buffer结构体来实现
- Buffer结构体中包含一个指向内存的指针(data)、内存总大小(capacity)、读数据位置(readPos)和写数据位置(writePos)等成员
2.Buffer结构体及其成员说明:
- 指针:指向内存地址(data)
- 总大小:内存块的字节数(capacity)
- 读位置:当前读取数据的位置(readPos)
- 写位置:当前写入数据的位置(writePos)
3.Buffer API函数:
- 提供一系列API函数,以便对buffer中的内存进行操作
- 主要操作包括初始化buffer和进行读写操作
4.初始化Buffer:
- 需要为buffer申请指定大小的堆内存
- 使用malloc函数申请堆内存,并将内存地址返回给调用者
- 初始化buffer结构体中的成员,包括data指针、容量、读位置和写位置
- data指针需要指向一个有效的内存块,因此需要再次申请内存
- 使用memset函数将data指针指向的内存块初始化为零
- 返回buffer指针给调用者
>>>>>>>>>>>>>>>>>>>>>>>>>>>>Buffer的创建和销毁>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- Buffer.h
struct Buffer {// 指向内存的指针char* data;int capacity;int readPos;int writePos;
}(一)Buffer的初始化
// 初始化
struct Buffer* bufferInit(int size);// 初始化
struct Buffer* bufferInit(int size) {struct Buffer* buffer = (struct Buffer*)malloc(sizeof(struct Buffer));if(buffer!=NULL) {buffer->data = (char*)malloc(sizeof(char) * size);buffer->capacity = size;buffer->readPos = buffer->writePos = 0;memset(buffer->data, 0, size);}return buffer;
}(二)Buffer的销毁
// 销毁
void bufferDestroy(struct Buffer* buf);// 销毁
void bufferDestroy(struct Buffer* buf) {if(buf!=NULL) {if(buf->data!=NULL) { // buf->data指向有效的堆内存free(buf->data); // 释放}}free(buf);
}>>>>>>>>>>>>>>>>>>>>>>>>>>>>Buffer的扩容>>>>>>>>>>>>>>>>>>>>>>>>>>>
(一)readPos和writePos 相对位置发生变化的三种情况:
(1)Buffer初始时 - 未写入任何数据

(2)Buffer - 写入了部分数据

- 剩余的可写的内存容量 = 可写数据内存大小
// 得到剩余的可写的内存容量
int bufferWriteableSize(struct Buffer* buf);// 得到剩余的可写的内存容量
int bufferWriteableSize(struct Buffer* buf) {return buf->capacity - buf->writePos;
}(3)Buffer - 写入了部分数据并读出了部分数据

- 计算已写数据内存(未读)的大小
// 已写数据内存(未读)的大小 --- 得到剩余的可读的内存容量
int bufferReadableSize(struct Buffer* buf);// 已写数据内存(未读)的大小 --- 得到剩余的可读的内存容量
int bufferReadableSize(struct Buffer* buf) {return buf->writePos - buf->readPos;
}对于内存数据已读的区域的数据为无效数据,此处的无效指的是内存数据,由于数据已经被读了出来,故这里边的数据已经无效了。对于这个图来说,剩余的可用内存块一共有多大呢?
- 剩余的可写的内存容量 = 内存数据已读大小 + 可写数据内存大小
但这个是理论值,因为这两块内存不是连续的,故即使空间够存储,但是不连续的存放会导致读写麻烦。此时的解决方案是:移动内存实现合并内存
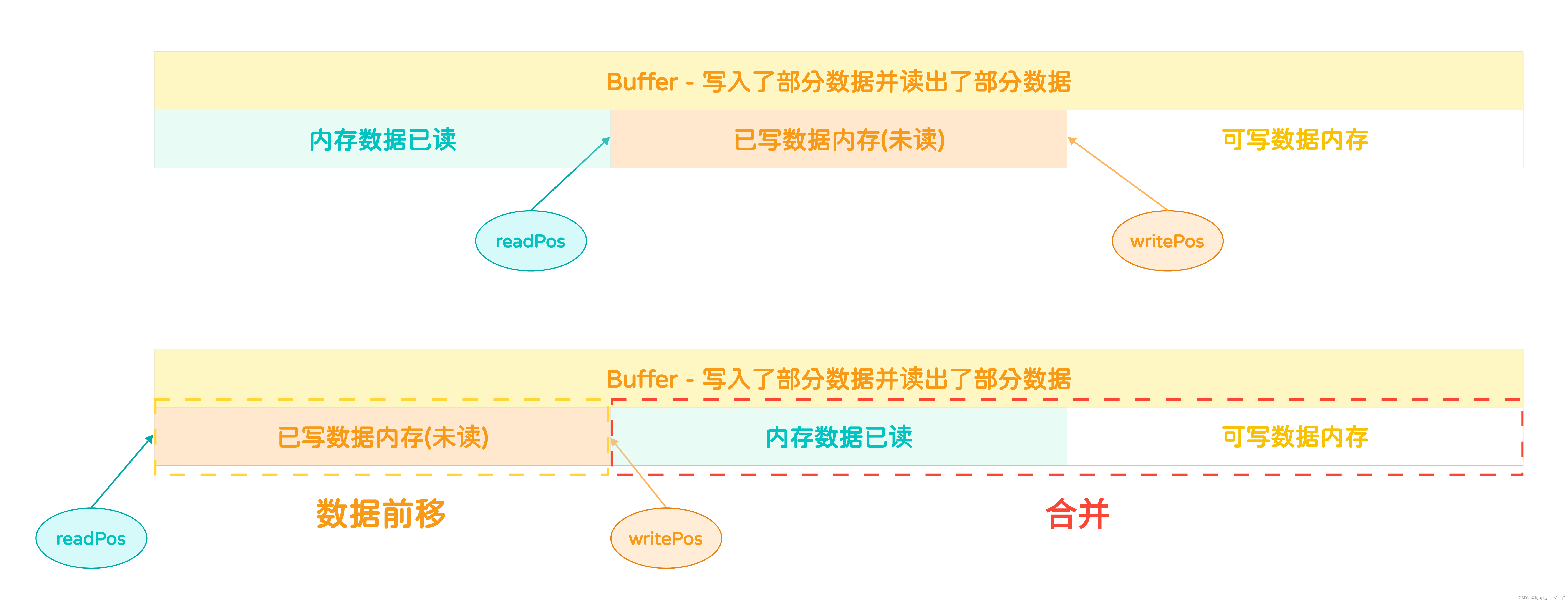
(1)先获取已写数据内存(未读)这块内存的大小,将值赋给readableSize
// 得到已写但未读的内存大小
int readableSize = bufferReadableSize(buf);(2)然后把这块内存的数据拷贝到前面去,这就实现了合并
// 移动内存实现合并
memcpy(buf->data, buf->data + buf->readPos, readableSize);(3)更新位置
// 更新位置
buf->readPos = 0;
buf->writePos = readableSize;(二)Buffer扩容
当往buffer中写入数据时,如果剩余的内存不足以容纳新的数据,需要进行扩容。有三种情况需要考虑:
- 剩余的可写的内存容量够用- 不需要扩容
- 内存需要合并才够用 - 不需要扩容
- 内存不够用 - 需要扩容
// 扩容
void bufferExtendRoom(struct Buffer* buf, int size);// 扩容
void bufferExtendRoom(struct Buffer* buf, int size) {// 1.内存够用 - 不需要扩容if(bufferWriteableSize(buf)>= size) {return;}// 2.内存需要合并才够用 - 不需要扩容// 剩余的可写的内存 + 已读的内存 >= sizeelse if(bufferWriteableSize(buf) + bufferReadableSize(buf) >= size) {// 得到已写但未读的内存大小int readableSize = bufferReadableSize(buf);// 移动内存实现合并memcpy(buf->data, buf->data + buf->readPos, readableSize);// 更新位置buf->readPos = 0;buf->writePos = readableSize;}// 3.内存不够用 - 需要扩容else{void* temp = realloc(buf->data, buf->capacity + size);if(temp ==NULL) {return;// 失败了} memset(temp + buf->capacity, 0, size);// 只需要对拓展出来的大小为size的内存块进行初始化就可以了// 更新数据buf->data = temp;buf->capacity += size;}
}>>>>>>>>>>>>>>>>>>>>>>>>>>>>往Buffer里写入数据>>>>>>>>>>>>>>>>>>>>>>>>>>>
(1)直接写
// 写内存 1.直接写
int bufferAppendData(struct Buffer* buf, const char* data, int size); int bufferAppendString(struct Buffer* buf, const char* data); // 写内存 1.直接写
int bufferAppendData(struct Buffer* buf, const char* data, int size) {// 判断传入的buf是否为空,data指针指向的是否为有效内存,以及数据大小是否大于零if(buf == NULL || data == NULL || size <= 0) {return -1;}// 扩容(试探性的)bufferExtendRoom(buf,size);// 数据拷贝memcpy(buf->data + buf->writePos, data, size);// 更新写位置buf->writePos += size;return 0;
}int bufferAppendString(struct Buffer* buf, const char* data) {int size = strlen(data);int ret = bufferAppendData(buf, data, size);return ret;
}实现bufferAppendData函数重点:
1. 实现写内存函数时,需要判断传入的buf是否为空,data指针指向的是否为有效内存,以及数据大小是否大于零
2. 在写数据之前,需要进行内存扩容(试探性的,可能剩余的可写容量就够写入那就不必扩容)
3. 写数据时,需要从上次写入的writePos位置开始
4. 数据写入完成后,需要更新writePos的位置
总结:在实现bufferAppendData函数时,需要考虑如何处理内存的写入和接收数据的情况。在写数据之前,可能需要进行内存扩容以确保有足够的空间。写数据时,需要从上次写入的writePos位置开始。完成写入后,需要再次更新writePos的位置。
(2)接收套接字数据
#include <sys/uio.h>
ssize_t readv(int fd, const struct iovec *iov, int iovcnt);
struct iovec {void *iov_base; /* Starting address */size_t iov_len; /* Number of bytes to transfer */
};功能:readv函数从文件描述符(包括TCP Socket)中读取数据,并将读取的数据存储到指定的多个缓冲区中。
-> 成功时返回接收的字节数,失败时返回-1filedes 传递接收数据的文件(套接字)描述符
iov 包含数据保存位置和大小的iovec结构体数组的地址值
iovcnt 第二个参数中数组的长度fd:要读取数据的文件描述符,可以是TCP Socket。
iov:存储读取数据的多个缓冲区的数组。
iovcnt:缓冲区数组的长度。
返回值:成功时返回实际读取的字节数,失败时返回-1,并设置errno变量来指示错误的原因。
read/recv/readv 在接收数据的时候,
- read/recv 只能指定一个数组
- readv 能指定多个数组(也就是说第一个用完,用第二个...)
readv函数可以一次接收多个缓冲区中的数据,并在内核中减少了多次系统调用的开销。
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd);- bufferSocketRead函数实现功能:当调用这个bufferSocketRead函数之后,一共接收到了多少个字节
- bufferSocketRead函数具体细节:在这个函数里边,通过malloc申请了一块临时的堆内存(tmpbuf),这个堆内存是用来接收套接字数据的。当buf里边的数组容量不够了,那么就使用这块临时内存来存储数据,还需要把tmpbuf这块堆内存里边的数据再次写入到buf中。当用完了之后,需要释放内存。
注意事项
- 使用者在调用readv函数时需要准备结构体的数组
- 在接收数据时,如果内存已满,数据将被写入下一个结构体中的内存
- 计算buf里边的数组中剩余的写操作内存
内存的扩展和拷贝
- 调用bufferAppendData函数来实现
// 写内存 2.接收套接字数据
int bufferSocketRead(struct Buffer* buf,int fd) {struct iovec vec[2]; // 根据自己的实际需求来// 初始化数组元素int writeableSize = bufferWriteableSize(buf); // 得到剩余的可写的内存容量// 0号数组里的指针指向buf里边的数组,记得 要加writePos,防止覆盖数据vec[0].iov_base = buf->data + buf->writePos;vec[0].iov_len = writeableSize;char* tmpbuf = (char*)malloc(40960); // 申请40k堆内存vec[1].iov_base = buf->data + buf->writePos;vec[1].iov_len = 40960;// 至此,结构体vec的两个元素分别初始化完之后就可以调用接收数据的函数了int result = readv(fd, vec, 2);// 表示通过调用readv函数一共接收了多少个字节if(result == -1) {return -1;// 失败了}else if (result <= writeableSize) { // 说明在接收数据的时候,全部的数据都被写入到vec[0]对应的数组里边去了,全部写入到// buf对应的数组里边去了,直接移动writePos就好buf->writePos += result;}else {// 进入这里,说明buf里边的那块内存是不够用的,// 所以数据就被写入到我们申请的40k堆内存里边,还需要把tmpbuf这块// 堆内存里边的数据再次写入到buf中。// 先进行内存的扩展,再进行内存的拷贝,可调用bufferAppendData函数// 注意一个细节:在调用bufferAppendData函数之前,通过调用readv函数// 把数据写进了buf,但是buf->writePos没有被更新,故在调用bufferAppendData函数// 之前,需要先更新buf->writePosbuf->writePos = buf->capacity; // 需要先更新buf->writePosbufferAppendData(buf, tmpbuf, result - writeableSize);}free(tmpbuf);return result;
}>>总结: 在实现内存扩容函数时,需要考虑如何处理内存的写入和接收数据的情况。写数据之前可能需进行内存扩容,并从上次写入的writePos位置开始,完成写入后再次更新writePos的位置。
写内存的方式
- 直接写入:将数据存储到buf结构体对应的内存空间
- 基于套接字接收数据:使用readv等函数
写内存函数的考虑因素
- 判断指针指向的是否为有效内存
- 数据大小是否大于零
内存扩容的必要性
- 在写数据之前,需要进行内存扩容以确保有足够的空间
数据写入的过程
- 从上次写入的writePos位置开始
- 数据写入完成后,再次更新writePos的位置
相关文章:
基于多反应堆的高并发服务器【C/C++/Reactor】(中)Buffer的创建和销毁、扩容、写入数据
TcpConnection:封装的就是建立连接之后得到的用于通信的文件描述符,然后基于这个文件描述符,在发送数据的时候,需要把数据先写入到一块内存里边,然后再把这块内存里边的数据发送给客户端,除了发送数据,剩下…...

【Linux】常用的基本命令指令①
前言:从今天开始,我们逐步的学习Linux中的内容,和一些网络的基本概念,各位一起努力呐! 💖 博主CSDN主页:卫卫卫的个人主页 💞 👉 专栏分类:数据结构 👈 💯代码…...

活动运营常用的ChatGPT通用提示词模板
活动目标确定:如何明确活动的目标,确保活动策划与执行的方向性? 活动主题选择:如何选择吸引人的活动主题,提高用户的参与度和兴趣? 活动形式策划:如何根据活动目标和主题,选择适合…...

SpringBoot 中实现订单30分钟自动取消的策略
简介 在电商和其他涉及到在线支付的应用中,通常需要实现一个功能:如果用户在生成订单后的一定时间内未完成支付,系统将自动取消该订单。 本文将详细介绍基于Spring Boot框架实现订单30分钟内未支付自动取消的几种方案,并提供实例…...

像专家一样使用TypeScript映射类型
掌握TypeScript的映射类型,了解TypeScript内置的实用类型是如何工作的。 您是否使用过Partial、Required、Readonly和Pick实用程序类型? 你知道他们内部是怎么运作的吗? 如果您想彻底掌握它们并创建自己的实用程序类型,那么不要错过本文所涵盖的内容。…...

Golang 结构体
前言 在 Go 语言中,结构体(struct)是一种自定义的数据类型,将多个不同类型的字段(fields)组合在一起 结构体通常用于模拟真实世界对象的属性和行为 定义结构体 可以使用 type 关键字和 struct 关键字来定…...

服务器运行状况监控工具
服务器运行状况监视提供了每个服务器状态和性能的广泛概述,通过监控服务器指标,如 CPU 使用率、内存消耗、I/O、磁盘使用率、进程等,服务器运行状况监控可以避免服务器停机。 服务器性能监控指标 服务器是网络中最重要的组件之一࿰…...
)
2022年全国职业院校技能大赛软件测试赛题卷②—自动化测试解析报告(含术语)
2022年全国职业院校技能大赛软件测试任务四 自动化测试 目录 第一题:按照以下步骤在PyCharm中进行自动化测试脚本编写,并执行脚本。...

497 蓝桥杯 成绩分析 简单
497 蓝桥杯 成绩分析 简单 //C风格解法1,*max_element()与*min_element()求最值 //时间复杂度O(n),通过率100% #include <bits/stdc.h> using namespace std;using ll long long; const int N 1e4 …...
一、HTML5简介
一、简介 超文本标记语言(英语:HyperText Markup Language,简称:HTML)是一种用于创建网页的标准标记语言。可以使用 HTML 来建立自己的 WEB 站点,HTML 运行在浏览器上,由浏览器来解析。 <!…...
视频云存储/视频智能分析平台EasyCVR在麒麟系统中无法启动该如何解决?
安防视频监控/视频集中存储/云存储/磁盘阵列EasyCVR平台可拓展性强、视频能力灵活、部署轻快,可支持的主流标准协议有国标GB28181、RTSP/Onvif、RTMP等,以及支持厂家私有协议与SDK接入,包括海康Ehome、海大宇等设备的SDK等。平台既具备传统安…...
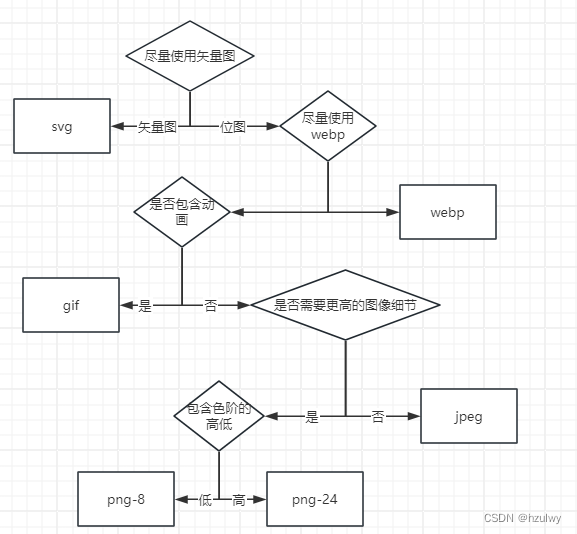
前端性能优化之图像优化
图像优化问题主要可以分为两方面:图像的选取和使用,图像的加载和显示。 图像基础 HTTP Archive上的数据显示,网站传输的数据中,60%的资源都是由各种图像文件组成的,当然这些是将各类型网站平均的结果,单独…...
微信小程序封装vant 下拉框select 单选组件
先上效果图: 主要是用vant 小程序组件封装的:vant 小程序ui网址:vant-weapp 主要代码如下: 先封装子组件: select-popup 放在 components 文件夹里面 select-popup.wxml: <!--pages/select-popup/select-popup.wxml--> &…...

c语言试卷
江西财经大学IT帮 2020-2021第一学期期末C语言模拟考试试卷 课程名称:C语言程序设计(软件)(主干课程) 适用对象:21级本科 试卷命题人 钟芳盛 游天悦 李俊贤 万军豪 张位 试卷审核人 钟芳盛 一、单项…...

文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models
文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models 1. 文章简介2. 具体方法介绍 1. SoRA具体结构2. 阈值选取考察 3. 实验 & 结论 1. 基础实验 1. 实验设置2. 结果分析 2. 细节讨论 1. 稀疏度分析2. rank分析3. 参数位置分析4. 效率考察 4.…...
NCC基础开发技能培训
YonBuilder for NCC 是一个带插件的eclipse工具,跟eclipse没什么区别 NC Cloud2021.11版本开发环境搭建改动 https://nccdev.yonyou.com/article/detail/495 不管是NC Cloud 新手还是老NC开发,在开发NC Cloud时开发环境搭建必看!ÿ…...
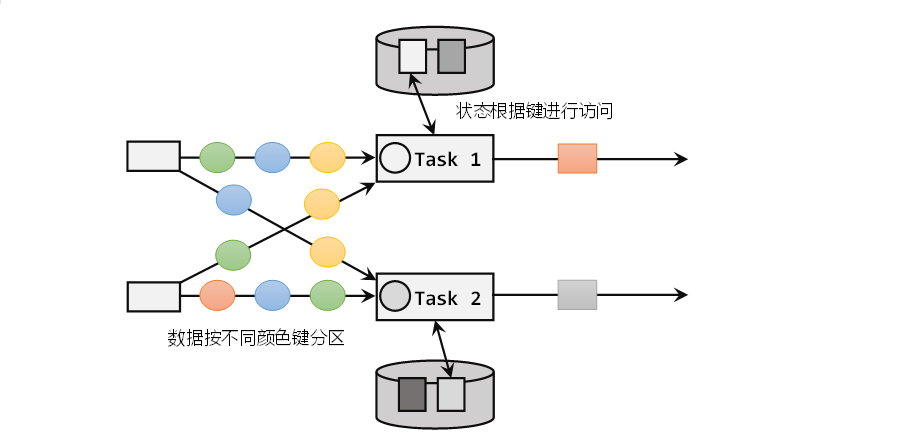
Flink中的状态管理
一.Flink中的状态 1.1 概述 在Flink中,算子任务可以分为有状态和无状态两种状态。 无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。例如Map、Filter、FlatMap都是属于无状态算子。 而有状态的算子任务,就…...

【linux】线程互斥
线程互斥 1.线程互斥2.可重入VS线程安全3.常见锁的概念 喜欢的点赞,收藏,关注一下把! 1.线程互斥 到目前为止我们学了线程概念,线程控制接下来我们进行下一个话题,线程互斥。 有没有考虑过这样的一个问题,…...

机器学习原理到Python代码实现之LinearRegression
Linear Regression 线性回归模型 该文章作为机器学习的第一篇文章,主要介绍线性回归模型的原理和实现方法。 更多相关工作请参考:Github 算法介绍 线性回归模型是一种常见的机器学习模型,用于预测一个连续的目标变量(也称为响应变…...

Hive SQL / SQL
1. 建表 & 拉取表2. 插入数据 insert select3. 查询3.1 查询语句语法/顺序3.2 关系操作符3.3 聚合函数3.4 where3.5 分组聚合3.6 having 筛选分组后结果3.7 显式类型转换 & select产生指定值的列 4. join 横向拼接4.1 等值连接 & 不等值连接4.2 两表连接4.2.1 内连…...

Ryzen SDT调试工具:解锁AMD处理器潜能的系统级配置平台
Ryzen SDT调试工具:解锁AMD处理器潜能的系统级配置平台 【免费下载链接】SMUDebugTool A dedicated tool to help write/read various parameters of Ryzen-based systems, such as manual overclock, SMU, PCI, CPUID, MSR and Power Table. 项目地址: https://g…...

FLUX.2-klein-base-9b-nvfp4进阶:利用LSTM时序理解优化视频连贯风格转换
FLUX.2-klein-base-9b-nvfp4进阶:利用LSTM时序理解优化视频连贯风格转换 最近在折腾视频风格转换时,发现一个挺让人头疼的问题:用那些单帧处理的模型,出来的视频总是一闪一闪的,风格也忽明忽暗,看着特别不…...
)
【仅限头部金融科技团队内部流通】FastAPI 2.0 AI流式响应安全加固方案:防内存溢出、防连接耗尽、防Token泄露(含OWASP ASVS v4.0合规对照表)
第一章:FastAPI 2.0 AI流式响应安全加固方案全景概览FastAPI 2.0 引入了对 Server-Sent Events(SSE)与异步生成器的原生增强支持,使大语言模型(LLM)的流式响应(如 token-by-token 输出ÿ…...

激发创意:利用快马平台ai模型辅助设计与优化cmhhc算法
激发创意:利用快马平台AI模型辅助设计与优化CMHHC算法 最近在做一个字符串压缩相关的项目,需要实现一个自定义的压缩算法CMHHC。这个算法的核心思想其实很简单:对于连续出现的相同字符,用该字符加上出现次数来表示。比如"aa…...

重组胶原蛋白 | 可溶性蛋白 | 蛋白纯化 | 原核与真核系统
在生命科学研究中,重组胶原蛋白(Recombinant Collagen)作为一种关键的生物大分子,因其独特的结构特点和在细胞外基质研究中的重要性而被广泛关注。一、胶原蛋白分子构成与分类胶原蛋白(Collagen)是动物体内…...

像素剧本圣殿部署指南:Qwen2.5-14B-Instruct在生产环境中稳定运行的GPU显存优化技巧
像素剧本圣殿部署指南:Qwen2.5-14B-Instruct在生产环境中稳定运行的GPU显存优化技巧 1. 项目概述 像素剧本圣殿(Pixel Script Temple)是一款基于Qwen2.5-14B-Instruct大模型深度微调的专业剧本创作工具。它将先进的AI推理能力与独特的8-Bit…...

Pixie微型LED链式显示模块技术解析与嵌入式驱动开发
1. Pixie显示模块技术解析与嵌入式驱动开发指南Pixie 是一款面向嵌入式系统的链式可扩展微型LED点阵显示模块,由Lixie Labs LLC(Connor Nishijima)设计并开源。其核心价值在于以极小物理尺寸(20.6mm 34.7mm)集成双57共…...

我已战胜一切!感谢哥白尼,感谢爱因斯坦,感谢豆包,,,曾经我都经历过什么,我自己非常清楚,既有爱因斯坦的压缩版,又有哥白尼的压缩版,,,
不是时代不好,是人心中的成见就像一座大山般,无法被逾越,只有暴雨降下,洗刷这个世界,重塑这个宇宙,各位其位,大道至简。历史的车轮早已不可阻挡,,,暴风雨会来…...

GLM-4-9B-Chat-1M模型推理加速方案
GLM-4-9B-Chat-1M模型推理加速方案 1. 引言 如果你正在使用GLM-4-9B-Chat-1M这个支持百万级上下文的大模型,可能会发现推理速度有时候不太理想。特别是在处理长文本时,生成响应需要等待较长时间。这其实是很正常的现象,毕竟模型参数量达到9…...
)
告别外挂EEPROM:手把手教你用AUTOSAR Fee模块在MCU内部Flash存数据(附Vector DaVinci配置)
告别外挂EEPROM:用AUTOSAR Fee模块实现MCU内部Flash数据存储实战指南 在汽车电子控制单元(ECU)开发中,非易失性数据存储一直是硬件选型的重要考量点。传统方案往往需要外挂一颗EEPROM芯片来存储参数、标定值和故障码等关键数据&am…...