文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models
- 文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models
- 1. 文章简介
- 2. 具体方法介绍
- 1. SoRA具体结构
- 2. 阈值选取考察
- 3. 实验 & 结论
- 1. 基础实验
- 1. 实验设置
- 2. 结果分析
- 2. 细节讨论
- 1. 稀疏度分析
- 2. rank分析
- 3. 参数位置分析
- 4. 效率考察
- 1. 基础实验
- 4. 总结 & 思考
- 文献链接:https://arxiv.org/abs/2311.11696
- GitHub链接:https://github.com/TsinghuaC3I/SoRA
1. 文章简介
这篇文章是清华大学在23年11月发表的一篇针对LLM的高效finetune方面的工作。
众所周知,LLM虽然效果很好,但是由于其极其巨大的参数量,对LLM的finetune一直是一个老大难问题,因此最近针对这方面的研究也是层出不穷,其中最为知名的可能就是微软提出的LoRA算法了,我自己之前也整理了一篇水文来介绍过这篇工作(文献阅读:LoRA: Low-Rank Adaptation of Large Language Models)。
整体上来说,LoRA的核心思路就是用一个额外的Adapter网络来模拟模型finetune之后的参数微扰,使得原始模型的输出加上Adapter模型的输出近似于finetune之后的模型输出。此时,我们只需要train一个很小的adapter就可以来模拟模型的finetune了,既不用改动原始大模型的结构,也不需要增加很多额外的参数。
但是,LoRA有一个比较大的问题就是它默认了微扰对于各个层的影响都是一样的,且都是比较小的,因此LoRA对所有层都共享一个超参,就是adapter中间层的维度。而这个假设事实上是有点强的,因此后续也有一些工作尝试对这个点进行优化,文中提到的一个典型工作就是AdaLoRA,它通过奇异值分解的方式来动态调整不同层所需的Adapter中间层的维度,但是因为他引入了奇异值分解,因此需要挺多的额外计算量,且需要引入一些额外的正交假设。
基于此,文中提出了一个新的他们命名为SoRA的方法,本质上来说,它和AdaLoRA一样,也是希望动态调整不同层中Adapter中间层的维度,但是相较于AdaLoRA,更加简单直接,无需引入额外的假设,且不会增加多少额外的计算量。
下面,我们来具体看一下文中提出的SoRA方法的具体实现和对应的实验以及实验结果。
2. 具体方法介绍
1. SoRA具体结构
下面,我们首先来看一下SoRA的整体结构。

可以看到,本质上来说,SoRA依然走的还是LoRA的降维投影的模式,不过,SoRA的思路是先给一个较大的中间维度,然后通过 L 1 L_1 L1正则来获取参数的稀疏性,然后通过要给阈值来对维度进行剪裁,使得最终使用的中间矩阵 W u W_u Wu与 W d W_d Wd是两个较小维度的矩阵。
具体来说的话,我们先给出一个具有较大中间维度的系数投影矩阵 W u W_u Wu与 W d W_d Wd,这部分的定义是和LoRA完全一样的,然后我们给出一个门向量来对中间维度进行稀疏化剪裁,使得 W u W_u Wu与 W d W_d Wd当中用不到的部分直接置零被抹去。
具体的扰动量输出结果就是:
z = W u ( g ⊙ ( W d ⋅ x ) ) z = W_u(g \odot (W_d \cdot x)) z=Wu(g⊙(Wd⋅x))
然后,关于这个门向量 g g g的训练方式的话,就是通过如下的方式:
g t + 1 = Γ η t ⋅ λ ( g t − η t ∇ L 0 ( △ t ) ) g_{t+1} = \Gamma_{\eta_t \cdot \lambda} (g_t - \eta_t \nabla L_{0}(\triangle_t)) gt+1=Γηt⋅λ(gt−ηt∇L0(△t))
其中,阈值函数的定义为:
Γ ξ ( x ) = { x − ξ , x > ξ 0 , − ξ < x ≤ ξ x + ξ , x ≤ − ξ \Gamma_{\xi}(x) = \left\{ \begin{aligned} &x - \xi, && x > \xi \\ &0, && -\xi < x \leq \xi \\ &x + \xi, && x \leq -\xi \\ \end{aligned} \right. Γξ(x)=⎩ ⎨ ⎧x−ξ,0,x+ξ,x>ξ−ξ<x≤ξx≤−ξ
这个实现的本质事实上就是 L 1 L_1 L1正则,换用另一个等价形式可以写为:
g t + 1 = a r g m i n g η t ⋅ λ ∥ g ∥ 1 + 1 2 ∥ g − ( g t − η t ∇ L 0 ( g t ) ) ∥ 2 2 g_{t+1} = \mathop{argmin}\limits_{g} \eta_t \cdot \lambda \| g \|_1 + \frac{1}{2} \| g - (g_t - \eta_t \nabla L_0(g_t)) \|_2^2 gt+1=gargminηt⋅λ∥g∥1+21∥g−(gt−ηt∇L0(gt))∥22
而这个恰好就是 L 1 L_1 L1正则项:
L ( △ ) = L 0 ( △ ) + λ ∑ k = 1 K ∥ g ( k ) ∥ 1 L(\triangle) = L_0(\triangle) + \lambda \sum\limits_{k=1}^{K} \| g^{(k)} \|_1 L(△)=L0(△)+λk=1∑K∥g(k)∥1
因此,我们可知 g g g会趋向于稀疏,而由此,我们就可以对参数矩阵 W u W_u Wu与 W d W_d Wd进行降维剪裁。
可以看到,上述实现和AdaLoRA基本上是有异曲同工之妙的,本质上都是先设置一个较大的中间维度之后进行剪裁,不过,相较于AdaLoRA,用文中的话来说,SoRA并没有引入额外的正交限制,且只使用 L 1 L_1 L1正则来动态控制每一层中间层的剪裁力度,因此多少显得更加直接以及优雅一些。
2. 阈值选取考察
最后,文中还讨论了一下上述实现中的阈值参数 ξ \xi ξ的选择,通过控制 ξ \xi ξ,我们就可以有效地控制最终的输出向量 g g g的稀疏性,因此,关于 ξ \xi ξ的选择,事实上是需要注意一下的,显然太稀疏的话会影响模型的效果,而太稠密的话那么稀疏化的意义也就没有了,耗费的计算量也大。
因此,文中给出了一个 ξ \xi ξ的schedule算法如下:

通过上述算法,文中得到了一系列不同稀疏度的模型,然后对其进行分析就可以获得一些关于 ξ \xi ξ的直观认知了。
3. 实验 & 结论
下面,我们来看一下文中给出的具体实验内容。
1. 基础实验
1. 实验设置
首先,关于SoRA的具体实验设计方面,文中使用的baseline模型主要包括以下一些:
- Adapter
- BitFit
- LoRA
- AdaLoRA
其次,文中使用的实验数据集为GLUE数据集。
最后,关于文中实验所使用的模型,文中主要是使用DeBERTaV3-base和RoBERTa-large模型进行考察,不过主要还是前者为主。
2. 结果分析
下面,我们给出文中得到的基础实验的结果如下:

可以看到:
- SoRA与AdaLoRA的效果相近,均基本都能够干掉LoRA。
为了更好地比较SoRA与LoRA,文中还控制两者在拥有相同的中间维度进行了一下比较,得到结果如下:

可以看到:
- SoRA的参数量均少于LoRA,但是效果基本都能够优于LoRA模型。
2. 细节讨论
然后,我们来看一下文中关于SoRA的细节讨论分析。
1. 稀疏度分析
首先,我们来看一下稀疏度对SoRA效果的影响,文中给出结果示意图如下:

可以看到:
- 整体来说,只需要很小的参数量,SoRA的效果就能控制和完整的参数量差不多。
2. rank分析
其次,文中还对不同任务下SoRA在各个层当中保留的中间层的维度进行了分析讨论,得到结果如下:

可以看到:
- 不同任务下,SoRA保留的中间层的维度是不相同的,QQP的保留维度明显就要高于QNLI任务;
- 同一任务当中网络的不同部分所需要保留的中间维度也不尽相同,多数情况下FFW层所需的中间维度是要高于其他部分的。
3. 参数位置分析
此外,文中还对attention层当中QKV矩阵进行了更细致的讨论,看看SoRA分别作用于这几部分时的影响,得到结果如下:

可以看到:
- 整体上还是所有部分都使用了SoRA之后能获得最优的效果。
4. 效率考察
最后,文中还对比了SoRA与AdaLoRA的训练效率,得到结果如下:

可以看到:
- 相较于AdaLoRA,SoRA在训练上成本更低,耗时更少。
4. 总结 & 思考
综上,文中提出了一个LoRA的优化算法SoRA,目的是动态调整LoRA的中间维度,使得模型可以在保留tuning效果的前提下进一步压缩extra模型的参数量。
当然,考虑到我们当前的工作事实上来LoRA都用不到,根本不涉及LLM的tuning,因此这部分暂时应该也没有机会去上手实操看看了,不过整体上感觉还是非常有价值的一个工作,后面有机会的话还是想试试……
啊啊啊啊啊,我想train模型啊,天天调prompt,真的是烦死了!!!!!
相关文章:
文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models
文献阅读:Sparse Low-rank Adaptation of Pre-trained Language Models 1. 文章简介2. 具体方法介绍 1. SoRA具体结构2. 阈值选取考察 3. 实验 & 结论 1. 基础实验 1. 实验设置2. 结果分析 2. 细节讨论 1. 稀疏度分析2. rank分析3. 参数位置分析4. 效率考察 4.…...
NCC基础开发技能培训
YonBuilder for NCC 是一个带插件的eclipse工具,跟eclipse没什么区别 NC Cloud2021.11版本开发环境搭建改动 https://nccdev.yonyou.com/article/detail/495 不管是NC Cloud 新手还是老NC开发,在开发NC Cloud时开发环境搭建必看!ÿ…...
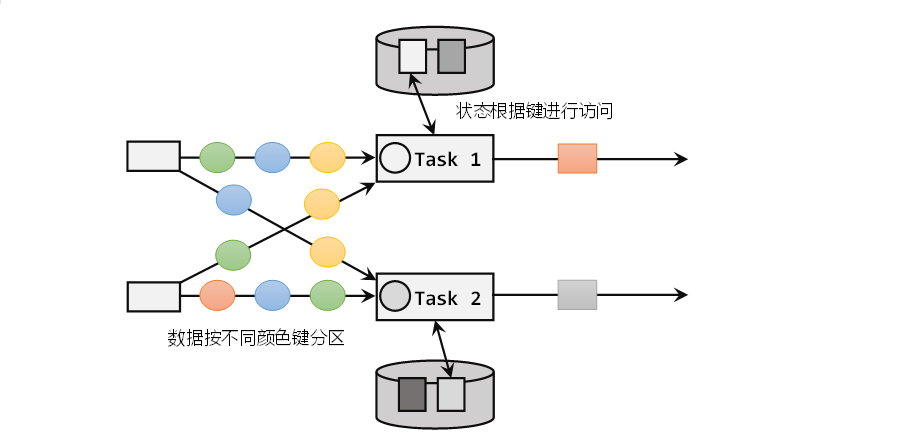
Flink中的状态管理
一.Flink中的状态 1.1 概述 在Flink中,算子任务可以分为有状态和无状态两种状态。 无状态的算子任务只需要观察每个独立事件,根据当前输入的数据直接转换输出结果。例如Map、Filter、FlatMap都是属于无状态算子。 而有状态的算子任务,就…...

【linux】线程互斥
线程互斥 1.线程互斥2.可重入VS线程安全3.常见锁的概念 喜欢的点赞,收藏,关注一下把! 1.线程互斥 到目前为止我们学了线程概念,线程控制接下来我们进行下一个话题,线程互斥。 有没有考虑过这样的一个问题,…...

机器学习原理到Python代码实现之LinearRegression
Linear Regression 线性回归模型 该文章作为机器学习的第一篇文章,主要介绍线性回归模型的原理和实现方法。 更多相关工作请参考:Github 算法介绍 线性回归模型是一种常见的机器学习模型,用于预测一个连续的目标变量(也称为响应变…...

Hive SQL / SQL
1. 建表 & 拉取表2. 插入数据 insert select3. 查询3.1 查询语句语法/顺序3.2 关系操作符3.3 聚合函数3.4 where3.5 分组聚合3.6 having 筛选分组后结果3.7 显式类型转换 & select产生指定值的列 4. join 横向拼接4.1 等值连接 & 不等值连接4.2 两表连接4.2.1 内连…...

程序媛的mac修炼手册--MacOS系统更新升级史
啊,我这个口罩三年从未感染过新冠的天选免疫王,却被支原体击倒😷大意了,前几天去医院体检,刚检查完出医院就摘口罩了🤦大伙儿还是要注意戴口罩,保重身体啊!身体欠恙,就闲…...

【数据库原理】(9)SQL简介
一.SQL 的发展历史 起源:SQL 起源于 1970 年代,由 IBM 的研究员 Edgar F. Codd 提出的关系模型概念演化而来。初期:Boyce 和 Chamberlin 在 IBM 开发了 SQUARE 语言的原型,后发展成为 SQL。这是为了更好地利用和管理关系数据库。…...

第二百五十二回
文章目录 概念介绍实现方法示例代码 我们在上一章回中介绍了如何在页面中添加图片相关的内容,本章回中将介绍如何给组件添加阴影.闲话休提,让我们一起Talk Flutter吧。 概念介绍 我们在本章回中介绍的阴影类似影子,只是它不像影子那么明显&a…...
)
Leetcode 3701 · Find Nearest Right Node in Binary Tree (遍历和BFS好题)
3701 Find Nearest Right Node in Binary TreePRE Algorithms This topic is a pre-release topic. If you encounter any problems, please contact us via “Problem Correction”, and we will upgrade your account to VIP as a thank you. Description Given a binary t…...

网站被攻击了,接入CDN对比直接使用高防服务器有哪些优势
网站是互联网行业中经常被攻击的目标之一。攻击是许多站长最害怕遇到的情况。当用户访问一个网站,页面半天打不开,响应缓慢,或者直接打不开,多半是会直接走开,而不是等待继续等待相应。针对网站攻击的防护,…...

location常用属性和方法
目录 Location 对象 Location 对象属性 Location 对象方法 location.assign() location.replace() location.reload() Location 对象 Location 对象包含有关当前 URL 的信息。Location 对象是 Window 对象的一个部分,可通过 window.location 属性来访问。 L…...

二分图
目录 二分图 染色法判定二分图 匈牙利算法 二分图 二分图,又叫二部图,将所有点分成两个集合,使得所有边只出现在集合之间的点之间,而集合内部的点之间没有边。二分图当且仅当图中没有奇数环。只要图中环的边数没奇数个数的&am…...
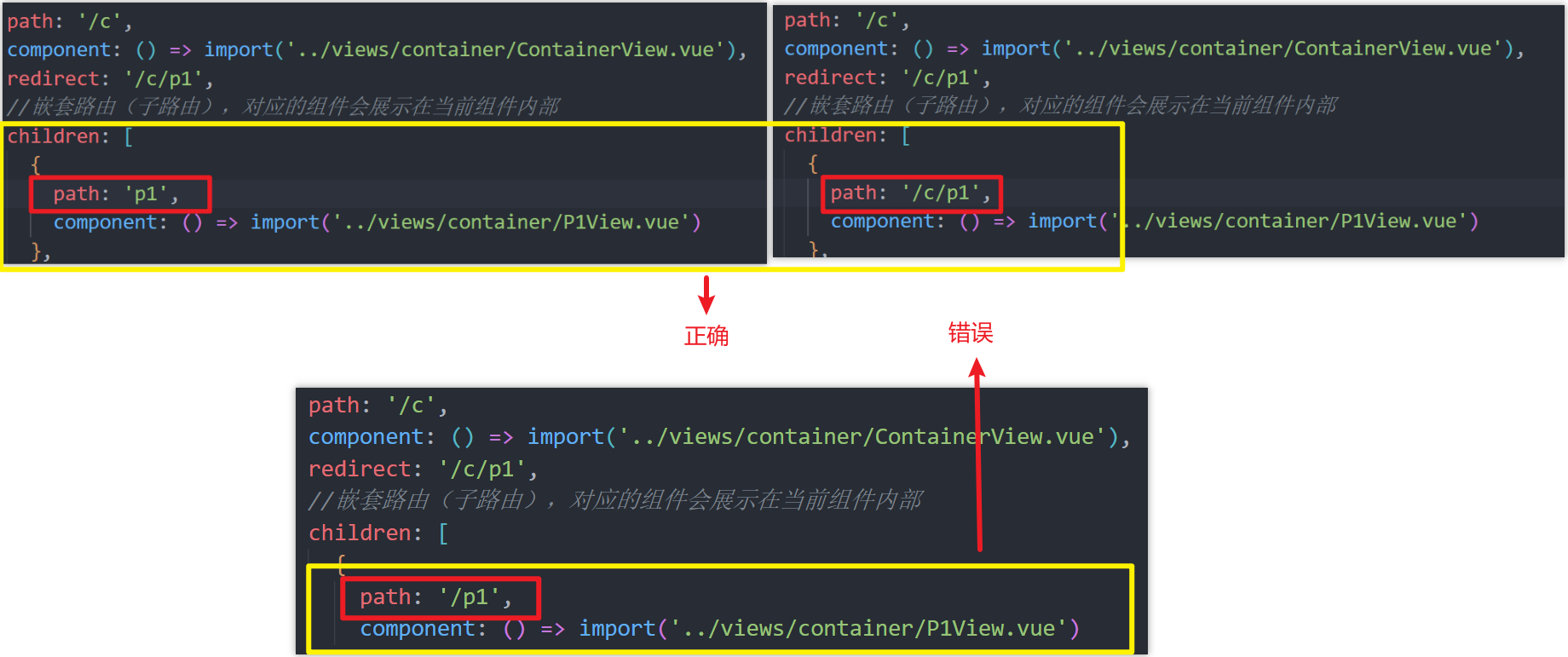
[VUE]3-路由
目录 路由 Vue-Router1、Vue-Router 介绍2、路由配置3、嵌套路由3.1、简介3.2、实现步骤3.3、⭐注意事项 4、⭐router-view标签详解 🍃作者介绍:双非本科大三网络工程专业在读,阿里云专家博主,专注于Java领域学习,擅…...

Kafka(六)消费者
目录 Kafka消费者1 配置消费者bootstrap.serversgroup.idkey.deserializervalue.deserializergroup.instance.idfetch.min.bytes1fetch.max.wait.msfetch.max.bytes57671680 (55 mebibytes)max.poll.record500max.partition.fetch.bytessession.timeout.ms45000 (45 seconds)he…...

RK3399平台入门到精通系列讲解(实验篇)共享工作队列的使用
🚀返回总目录 文章目录 一、工作队列相关接口函数1.1、初始化函数1.2、调度/取消调度工作队列函数二、信号驱动 IO 实验源码2.1、Makefile2.2、驱动部分代码工作队列是实现中断下半部分的机制之一,是一种用于管理任务的数据结构或机制。它通常用于多线程,多进程或分布式系统…...

STM32 基于 MPU6050 的飞行器姿态控制设计与实现
基于STM32的MPU6050姿态控制设计是无人机、飞行器等飞行器件开发中的核心技术之一。在本文中,我们将介绍如何利用STM32和MPU6050实现飞行器的姿态控制,并提供相应的代码示例。 1. 硬件连接及库配置 首先,我们需要将MPU6050连接到STM32微控制…...
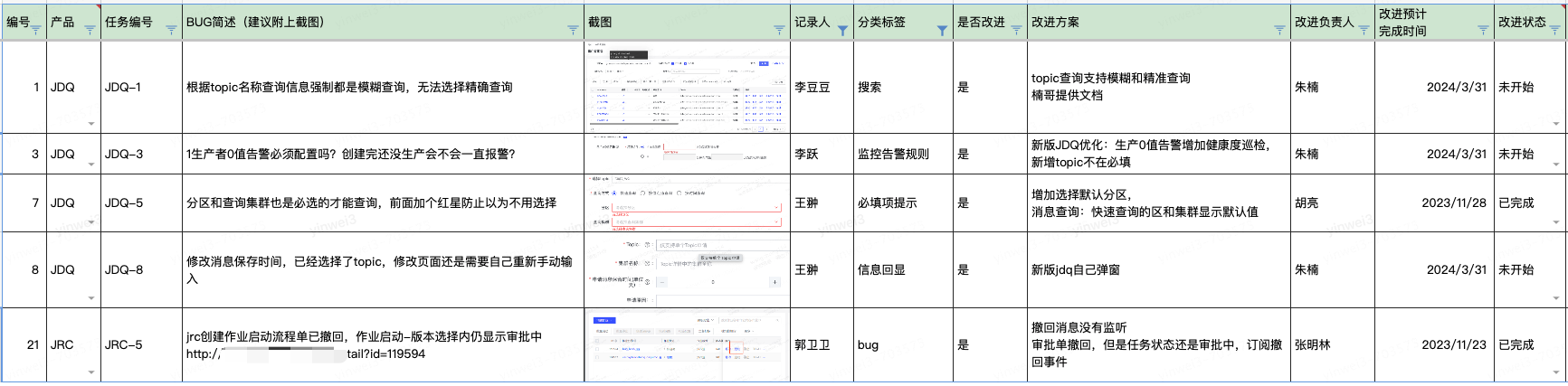
大数据平台Bug Bash大扫除最佳实践
一、背景 随着越来越多的"新人"在日常工作以及大促备战中担当大任,我们发现仅了解自身系统业务已不能满足日常系统开发运维需求。为此,大数据平台部门组织了一次Bug Bash活动,既能提升自己对兄弟产品的理解和使用,又能…...

JavaScript 中的数组过滤
在构建动态和交互式程序时,您可能需要添加一些交互式功能。例如,用户单击按钮以筛选一长串项目。 您可能还需要处理大量数据,以仅返回与指定条件匹配的项目。 在本文中,您将学习如何使用两种主要方法在 JavaScript 中过滤数组。…...
)
随机森林(Random Forest)
随机森林(Random Forest)是一种集成学习方法,通过组合多个决策树来提高模型的性能和鲁棒性。随机森林在每个决策树的训练过程中引入了随机性,包括对样本和特征的随机选择,以提高模型的泛化能力。以下是随机森林的基本原…...

synchronized 学习
学习源: https://www.bilibili.com/video/BV1aJ411V763?spm_id_from333.788.videopod.episodes&vd_source32e1c41a9370911ab06d12fbc36c4ebc 1.应用场景 不超卖,也要考虑性能问题(场景) 2.常见面试问题: sync出…...

CVPR 2025 MIMO: 支持视觉指代和像素grounding 的医学视觉语言模型
CVPR 2025 | MIMO:支持视觉指代和像素对齐的医学视觉语言模型 论文信息 标题:MIMO: A medical vision language model with visual referring multimodal input and pixel grounding multimodal output作者:Yanyuan Chen, Dexuan Xu, Yu Hu…...

【OSG学习笔记】Day 18: 碰撞检测与物理交互
物理引擎(Physics Engine) 物理引擎 是一种通过计算机模拟物理规律(如力学、碰撞、重力、流体动力学等)的软件工具或库。 它的核心目标是在虚拟环境中逼真地模拟物体的运动和交互,广泛应用于 游戏开发、动画制作、虚…...

React hook之useRef
React useRef 详解 useRef 是 React 提供的一个 Hook,用于在函数组件中创建可变的引用对象。它在 React 开发中有多种重要用途,下面我将全面详细地介绍它的特性和用法。 基本概念 1. 创建 ref const refContainer useRef(initialValue);initialValu…...

MongoDB学习和应用(高效的非关系型数据库)
一丶 MongoDB简介 对于社交类软件的功能,我们需要对它的功能特点进行分析: 数据量会随着用户数增大而增大读多写少价值较低非好友看不到其动态信息地理位置的查询… 针对以上特点进行分析各大存储工具: mysql:关系型数据库&am…...

MVC 数据库
MVC 数据库 引言 在软件开发领域,Model-View-Controller(MVC)是一种流行的软件架构模式,它将应用程序分为三个核心组件:模型(Model)、视图(View)和控制器(Controller)。这种模式有助于提高代码的可维护性和可扩展性。本文将深入探讨MVC架构与数据库之间的关系,以…...

vue3 字体颜色设置的多种方式
在Vue 3中设置字体颜色可以通过多种方式实现,这取决于你是想在组件内部直接设置,还是在CSS/SCSS/LESS等样式文件中定义。以下是几种常见的方法: 1. 内联样式 你可以直接在模板中使用style绑定来设置字体颜色。 <template><div :s…...

2021-03-15 iview一些问题
1.iview 在使用tree组件时,发现没有set类的方法,只有get,那么要改变tree值,只能遍历treeData,递归修改treeData的checked,发现无法更改,原因在于check模式下,子元素的勾选状态跟父节…...

Cinnamon修改面板小工具图标
Cinnamon开始菜单-CSDN博客 设置模块都是做好的,比GNOME简单得多! 在 applet.js 里增加 const Settings imports.ui.settings;this.settings new Settings.AppletSettings(this, HTYMenusonichy, instance_id); this.settings.bind(menu-icon, menu…...

vue3+vite项目中使用.env文件环境变量方法
vue3vite项目中使用.env文件环境变量方法 .env文件作用命名规则常用的配置项示例使用方法注意事项在vite.config.js文件中读取环境变量方法 .env文件作用 .env 文件用于定义环境变量,这些变量可以在项目中通过 import.meta.env 进行访问。Vite 会自动加载这些环境变…...