逻辑回归简单案例分析--鸢尾花数据集
文章目录
- 1. IRIS数据集介绍
- 2. 具体步骤
- 2.1 手动将数据转化为numpy矩阵
- 2.1.1 从csv文件数据构建Numpy数据
- 2.1.2 模型的搭建与训练
- 2.1.3 分类器评估
- 2.1.4 分类器的分类报告总结
- 2.1.5 用交叉验证(Cross Validation)来验证分类器性能
- 2.1.6 完整代码:
- 2.2 使用sklearn内置的iris数据集(多分类)
- 2.2.1 导入数据集
- 2.2.2 划分训练集和测试集
- 2.2.3 定义逻辑回归模型并训练
- 2.2.5 用训练好的模型在训练集和测试集上做预测
- 2.2.6 对预测结果进行可视化
1. IRIS数据集介绍
Iris也称鸢尾花卉数据集,是常用的分类实验数据集,由R.A. Fisher于1936年收集整理的。其中包含3种植物种类,分别是山鸢尾(setosa)变色鸢尾(versicolor)和维吉尼亚鸢尾(virginica),每类50个样本,共150个样本。
该数据集包含4个特征变量,1个类别变量。iris每个样本都包含了4个特征:花萼长度,花萼宽度,花瓣长度,花瓣宽度,以及1个类别变量(label)。我们需要建立一个分类器,分类器可以通过这4个特征来预测鸢尾花卉种类是属于山鸢尾,变色鸢尾还是维吉尼亚鸢尾。其中有一个类别是线性可分的,其余两个类别线性不可分,这在最后的分类结果绘制图中可观察到。
| 变量名 | 变量解释 | 数据类型 |
|---|---|---|
| sepal_length | 花萼长度(单位cm) | numeric |
| sepal_width | 花萼宽度(单位cm) | numeric |
| petal_length | 花瓣长度(单位cm) | numeric |
| petal_width | 花瓣长度(单位cm) | categorical |
2. 具体步骤
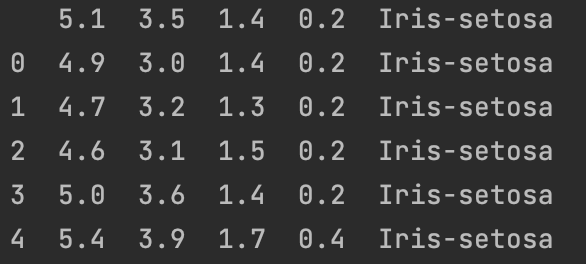
Step1:数据集预览
df=pd.read_csv('./data/iris.data.csv',header=0)
print(df.head())
2.1 手动将数据转化为numpy矩阵
2.1.1 从csv文件数据构建Numpy数据
Step 1:构造映射函数iris_type。因为实际数据中,label并不都是便于学习分类的数字型,而是string类型。
Step 2:对于文本类的label, 将label列的所有内容都转变成映射函数的输出,存成新的dataframe
Step 3:将Step2的结果转换成numpy矩阵
Step 4:划分训练集与测试集
def iris_type(s):class_label={'Iris-setosa':0,'Iris-versicolor':1,'Iris-virginica':2}return class_label[s]
df=pd.read_csv('./data/iris.data.csv',header=0)
#2.将第4列内容映射至iris_type函数定义的内容
df['Species']=df['Species'].apply(iris_type)
print(df.head())
#3.将df解析到numpy_arrat
data=np.array(df)
# print(data[:2])#4.将原始数据集分为测试集合和验证集合
# 用np.split按列(axis=1)进行分割
# (4,):分割位置,前4列作为x的数据,第4列之后都是y的数据
x,y=np.split(data,(4,),axis=1)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.7,random_state=0)
2.1.2 模型的搭建与训练
-
Pipeline(steps)
利用sklearn提供的管道机制
Pipeline
来实现对全部步骤的流式化封装与管理。
- 第一个环节:可以先进行 数据标准化 StandardScaler()
- 中间环节:可以加上 PCA降维处理 取2个重要特征
- 最终环节:逻辑回归分类器
pip_LR=Pipeline([('sc',StandardScaler()),('pca',PCA(n_components=2)),('clf_lr',LogisticRegression(random_state=1))])#开始训练
pip_LR.fit(x_train,y_train.ravel())#显示当前管道的配置和参数设置,它并没有直接运行或产生实际的影响,只展示了机器学习管道的配置
Pipeline(memory=None,steps=[('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('pca', PCA(copy=True, iterated_power='auto', n_components=2, random_state=None,svd_solver='auto', tol=0.0, whiten=False)), ('clf_lr', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,penalty='l2', random_state=1, solver='liblinear', tol=0.0001,verbose=0, warm_start=False))])
2.1.3 分类器评估
print("训练准确率:%0.2f"%pip_LR.score(x_train,y_train))print("测试准确率:%0.2f"%pip_LR.score(x_test,y_test))y_hat=pip_LR.predict(x_test)
accuracy=metrics.accuracy_score(y_test,y_hat)
print("逻辑回归分类器的准确率:%0.2f" % accuracy)
2.1.4 分类器的分类报告总结
- 精确度(Precision):指的是在所有模型预测为某一类别的样本中,真正属于该类别的比例。计算方式为该类别的 True Positives / (True Positives + False Positives)。
- 召回率(Recall):指的是在所有实际属于某一类别的样本中,被模型正确预测为该类别的比例。计算方式为该类别的 True Positives / (True Positives + False Negatives)
- F1 Score:是精确度和召回率的调和平均数,综合考虑了两者的性能。计算方式为 2 ∗ P r e c s i o n ∗ R e c a l l P r e c i s i o n + R e c a l l 2*\frac{Precsion*Recall}{Precision+Recall} 2∗Precision+RecallPrecsion∗Recall
- support:指的是属于该类别的样本数。
- accuracy(准确度):指的是模型在所有类别上正确预测的比例。计算方式为 Sum of True PositivesTotal SamplesTotal SamplesSum of True Positives。
- macro avg(宏平均):对所有类别的指标取平均,不考虑类别样本数量的差异。
- weighted avg(加权平均):对所有类别的指标取加权平均,考虑类别样本数量的差异。
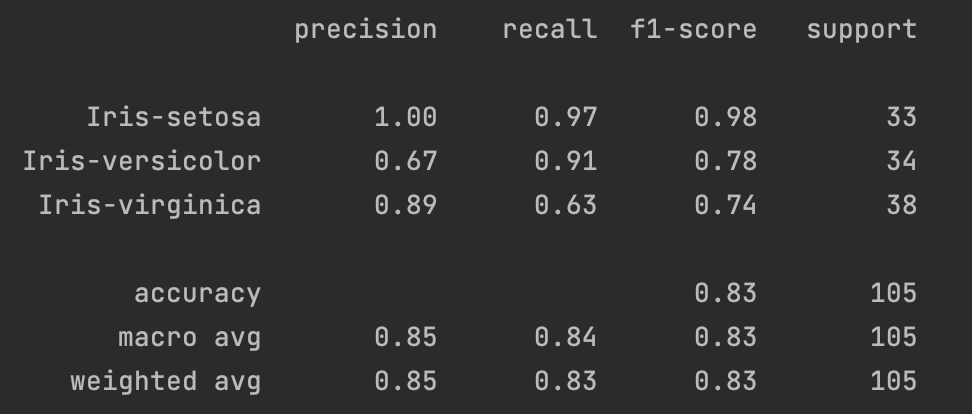
#描述分类器的精确度,召回率,F1Score
target_names=['Iris-setosa','Iris-versicolor','Iris-virginica']
print(metrics.classification_report(y_test,y_hat,target_names=target_names))
2.1.5 用交叉验证(Cross Validation)来验证分类器性能
交叉验证常用于防止模型过于复杂而造成过拟合,同时也称为循环估计。基本思想是将原始数据分成K组(一般是平均分组),每个子集数据分别做一次验证集或测试集,其余的K-1个子集作为训练集。这样就会得到K个模型,取这K个模型的分类准确率的平均数作为分类器的性能指标更具说服力。
比如说在这里我们使用的是5折交叉验证(5-fold cross validation),即数据集被分成了5份,轮流将其中4份作为训练数据集,剩余1份作为测试集,进行试验。每次试验都会得出相应的正确率,将5次试验得出的相应正确率的平均值作为分类器的准确率的估计。同样的,K也可以取10,20等。
iris_data=x
iris_target=y
scores=cross_val_score(pip_LR,iris_data,iris_target.ravel(),cv=5,scoring='f1_macro')
print("5折交叉验证:\n逻辑回归分类器的准确率:%.2f 误差范围:(+/- %.2f)"%(scores.mean(), scores.std()*2))
X_trainval, X_test, y_trainval, y_test = train_test_split(iris_data, iris_target, random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, random_state=1)
print("训练集大小:{} 验证集大小:{} 测试集大小:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0]))2.1.6 完整代码:
#将原始数据文件转为机器学习可用的numpy数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import plotly.express as px
import chart_studio.grid_objs as go
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn import metrics
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import GridSearchCVdef iris_type(s):class_label={'Iris-setosa':0,'Iris-versicolor':1,'Iris-virginica':2}return class_label[s]
df=pd.read_csv('./data/iris.data.csv',header=0)
#2.将第4列内容映射至iris_type函数定义的内容
df['Species']=df['Species'].apply(iris_type)
print(df.head())
#3.将df解析到numpy_arrat
data=np.array(df)
# print(data[:2])#4.将原始数据集分为测试集合和验证集合
# 用np.split按列(axis=1)进行分割
# (4,):分割位置,前4列作为x的数据,第4列之后都是y的数据
x,y=np.split(data,(4,),axis=1)
# X = x[:,0:2] # 取前两列特征
# 用train_test_split将数据按照7:3的比例分割训练集与测试集,
# 随机种子设为1(每次得到一样的随机数),设为0或不设(每次随机数都不同)
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.7,random_state=0)
pip_LR=Pipeline([('sc',StandardScaler()),('pca',PCA(n_components=2)),('clf_lr',LogisticRegression(random_state=1))])#开始训练
pip_LR.fit(x_train,y_train.ravel())#显示当前管道的配置和参数设置,它并没有直接运行或产生实际的影响,只展示了机器学习管道的配置
Pipeline(memory=None,steps=[('sc', StandardScaler(copy=True, with_mean=True, with_std=True)), ('pca', PCA(copy=True, iterated_power='auto', n_components=2, random_state=None,svd_solver='auto', tol=0.0, whiten=False)), ('clf_lr', LogisticRegression(C=1.0, class_weight=None, dual=False, fit_intercept=True,intercept_scaling=1, max_iter=100, multi_class='ovr', n_jobs=1,penalty='l2', random_state=1, solver='liblinear', tol=0.0001,verbose=0, warm_start=False))])
print("训练准确率:%0.2f"%pip_LR.score(x_train,y_train))
print("测试准确率:%0.2f"%pip_LR.score(x_test,y_test))
y_hat=pip_LR.predict(x_test)
accuracy=metrics.accuracy_score(y_test,y_hat)
print("逻辑回归分类器的准确率:%0.2f" % accuracy)#描述分类器的精确度,召回率,F1Score
target_names=['Iris-setosa','Iris-versicolor','Iris-virginica']
print(metrics.classification_report(y_test,y_hat,target_names=target_names))#交叉验证(Cross Validation)来验证分类器的性能
iris_data=x
iris_target=y
scores=cross_val_score(pip_LR,iris_data,iris_target.ravel(),cv=5,scoring='f1_macro')
print("5折交叉验证:\n逻辑回归分类器的准确率:%.2f 误差范围:(+/- %.2f)"%(scores.mean(), scores.std()*2))
X_trainval, X_test, y_trainval, y_test = train_test_split(iris_data, iris_target, random_state=0)
X_train, X_val, y_train, y_val = train_test_split(X_trainval, y_trainval, random_state=1)
print("训练集大小:{} 验证集大小:{} 测试集大小:{}".format(X_train.shape[0],X_val.shape[0],X_test.shape[0]))网格搜索验证见:用逻辑回归实现鸢尾花数据集分类(2) - Heywhale.com
2.2 使用sklearn内置的iris数据集(多分类)
2.2.1 导入数据集
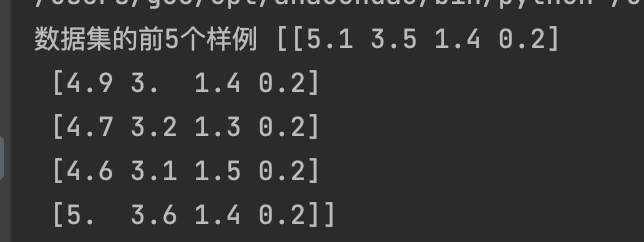
#导入内置数据集,已经处理空置,无需进行预处理
iris = load_iris()print('数据集的前5个样例', iris.data[0:5])
2.2.2 划分训练集和测试集
y = iris.target
X = iris.data
X_train, X_test, Y_train, Y_test = train_test_split(X, y, train_size=0.8, random_state=2020)
2.2.3 定义逻辑回归模型并训练
logistic = LogisticRegression(random_state=0,solver='lbfgs')
logistic.fit(X_train, Y_train)
print('the weight of Logistic Regression:\n',logistic.coef_)
print('the intercept(w0) of Logistic Regression:\n',logistic.intercept_)
y_train_predict=logistic.predict(X_train)
y_test_predict = logistic.predict(X_test)
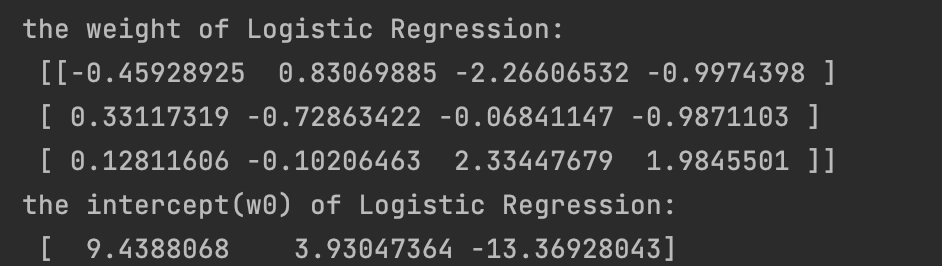
可以看到此处打印出了三组参数,这是因为这里我们是三分类问题。
2.2.5 用训练好的模型在训练集和测试集上做预测
#由于逻辑回归模型是概率预测模型,所有我们可以利用 predict_proba 函数预测其概率
train_predict_proba = logistic.predict_proba(X_train)
test_predict_proba = logistic.predict_proba(X_test)
print('The test predict Probability of each class:\n',test_predict_proba)# 利用accuracy(准确度)【预测正确的样本数目占总预测样本数目的比例】评估模型效果
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(Y_train,y_train_predict))
print('The accuracy of the Logistic Regression is:',metrics.accuracy_score(Y_test,y_test_predict))confusion_matrix_result = metrics.confusion_matrix(y_test_predict,Y_test)
print('The confusion matrix result:\n',confusion_matrix_result)

2.2.6 对预测结果进行可视化
confusion_matrix_result = metrics.confusion_matrix(y_test_predict,Y_test)
print('The confusion matrix result:\n',confusion_matrix_result)# 利用热力图对于结果进行可视化
plt.figure(figsize=(8, 6))
sns.heatmap(confusion_matrix_result, annot=True, cmap='Blues')
plt.xlabel('Predicted labels')
plt.ylabel('True labels')
plt.show()
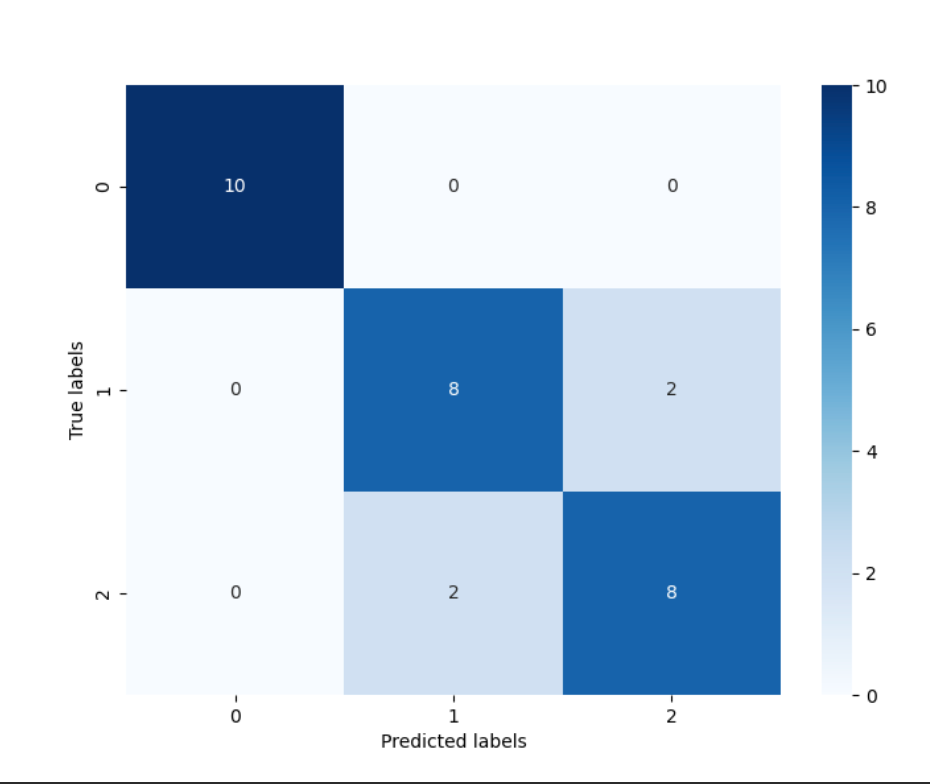
通过结果我们可以发现,其在三分类的结果其在测试集上的准确度为: 86.67% ,这是由于’versicolor’(1)和 ‘virginica’(2)这两个类别的特征,我们从可视化的时候也可以发现,其特征的边界具有一定的模糊性(边界类别混杂,没有明显区分边界),所有在这两类的预测上出现了一定的错误。
从混淆矩阵中可以看出:标签值y=0的10个样本都被正确分类;标签值y=1的10个样本中,有8个被正确分类,其中有两个被误分类为y=2;标签值y=2的10个样本中,有8个被正确分类,其中有两个被误分类为y=1。
相关文章:
逻辑回归简单案例分析--鸢尾花数据集
文章目录 1. IRIS数据集介绍2. 具体步骤2.1 手动将数据转化为numpy矩阵2.1.1 从csv文件数据构建Numpy数据2.1.2 模型的搭建与训练2.1.3 分类器评估2.1.4 分类器的分类报告总结2.1.5 用交叉验证(Cross Validation)来验证分类器性能2.1.6 完整代码…...

Python print 高阶玩法
Python print 高阶玩法 当涉及到在Python中使用print函数时,有许多方式可以玩转文本样式、字体和颜色。在此将深入探讨这些主题,并介绍一些print函数的高级用法。 1. 基本的文本样式与颜色设置 使用ANSI转义码 ANSI转义码是一种用于在终端࿰…...
Wpf 使用 Prism 实战开发Day09
设置模块设计 1.效果图 一.系统设置模块,主要有个性化(用于更改主题颜色),系统设置,关于更多,3个功能点。 个性化的颜色内容样式,主要是从 Material Design Themes UI简称md、提供的demo里复制代码过来使用的。 1.设置…...
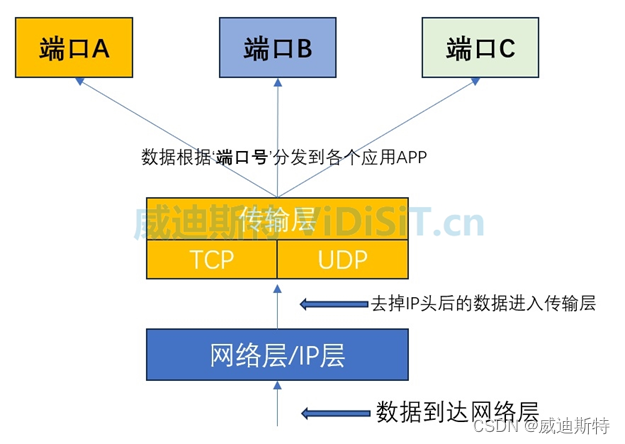
网络端口(包括TCP端口和UDP端口)的作用、定义、分类,以及在视频监控和流媒体通信中的定义
目 录 一、什么地方会用到网络端口? 二、端口的定义和作用 (一)TCP协议和UDP协议 (二)端口的定义 (三)在TCP/IP体系中,端口(TCP和UDP)的作用 (…...

flink如何写入es
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档 文章目录 前言一、写入到Elasticsearch5二、写入到Elasticsearch7总结 前言 Flink sink 流数据写入到es5和es7的简单示例。 一、写入到Elasticsearch5 pom maven依赖 <d…...

Java、Python、C++和C#的界面开发框架和工具的重新介绍
好的,以下是Java、Python、C和C#的界面开发框架和工具的重新介绍: Java界面开发: Swing: 是Java提供的一个基于组件的GUI工具包,可以创建跨平台的图形用户界面。它提供了丰富的组件和布局管理器,使得界面开发相对简单。…...

Java二叉树的遍历以及最大深度问题
Java学习面试指南:https://javaxiaobear.cn 1、树的相关概念 1、树的基本定义 树是我们计算机中非常重要的一种数据结构,同时使用树这种数据结构,可以描述现实生活中的很多事物,例如家谱、单位的组织架构、等等。 树是由n&#…...
Apollo 9.0搭建问题记录
虚拟机安装 可以看这个:https://blog.csdn.net/qq_45138078/article/details/129815408 写的很详细 内存 为了学习 Apollo ,所以只是使用了虚拟机,内存得大一点(128G),第一次,就是因为分配内…...

【心得】PHP文件包含高级利用攻击面个人笔记
目录 一、nginx日志文件包含 二、临时文件包含 三、php的session文件包含 四、pear文件包含 五 、远程文件包含 文件包含 include "/var/www/html/flag.php"; 一 文件名可控 $file$_GET[file]; include $file.".php"; //用php伪协议 ࿰…...

[scala] 列表常见用法
文章目录 不可变列表 List可变列表 ListBuffer 不可变列表 List 在 Scala 中,列表是一种不可变的数据结构,用于存储一系列元素。列表使用 List 类来表示,它提供了许多方法来操作和处理列表。 下面是一些常见的使用列表的示例: 创…...

python 使用urllib3发起post请求,携带json参数
当通过python脚本,发起http post请求,网络上大多是通过fields传递数据,然而这样,服务器收到的请求,但无法解析json数据。类似这些链接: Python urllib3库使用指南 软件测试|Python urllib3库使用指南 p…...
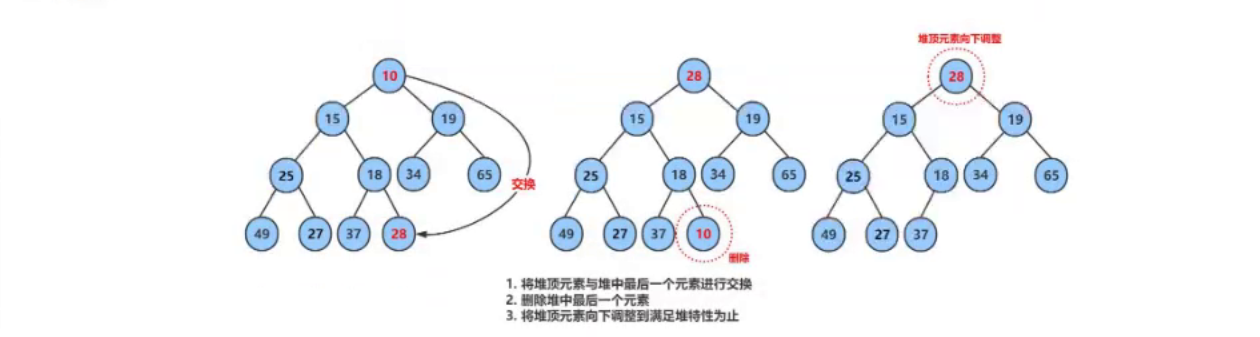
深入理解堆(Heap):一个强大的数据结构
. 个人主页:晓风飞 专栏:数据结构|Linux|C语言 路漫漫其修远兮,吾将上下而求索 文章目录 前言堆的实现基本操作结构体定义初始化堆(HeapInit)销毁堆(HeapDestroy) 重要函数交换函数(…...
抖音在线查权重系统源码,附带查询接口
抖音权重在线查询只需输入抖音主页链接,即可查询作品情况。 搭建教程 上传源码并解压 修改数据库“bygoukai.sql” 修改“config.php” 如需修改水印请修改第40行 如需修改限制次数,请修改第156行 访问域名user.php即可查看访问用户,停…...

Spring Framework和SpringBoot的区别
目录 一、前言 二、什么是Spring 三、什么是Spring Framework 四、什么是SpringBoot 五、使用Spring Framework构建工程 六、使用SpringBoot构建工程 七、总结 一、前言 作为Java程序员,我们都听说过Spring,也都使用过Spring的相关产品࿰…...
2024--Django平台开发-Django知识点(三)
day03 django知识点 项目相关路由相关 urls.py视图相关 views.py模版相关 templates资源相关 static/media 1.项目相关 新项目 开发时,可能遇到使用其他的版本。虚拟环境 老项目 打开项目虚拟环境 1.1 关于新项目 1.系统解释器命令行【学习】 C:/python38- p…...

Github 2024-01-08开源项目周报 Top14
根据Github Trendings的统计,本周(2024-01-08统计)共有14个项目上榜。根据开发语言中项目的数量,汇总情况如下: 开发语言项目数量Python项目5TypeScript项目3C项目2Dart项目1QML项目1Go项目1Shell项目1Rust项目1JavaScript项目1C#项目1 免费…...

vue3 的内置组件汇总
官方给出的说明: Fragment: Vue 3 组件不再要求有一个唯一的根节点,清除了很多无用的占位 div。Teleport: 允许组件渲染在别的元素内,主要开发弹窗组件的时候特别有用。Suspense: 异步组件,更方便开发有异步请求的组件。 一、fr…...
ARM工控机Node-red使用教程
嵌入式ARM工控机Node-red安装教程 从前车马很慢书信很远,而现在人们不停探索“科技改变生活”。 智能终端的出现改变了我们的生活方式,钡铼技术嵌入式工控机协助您灵活布建能源管理、大楼自动化、工业自动化、电动车充电站等各种多元性IoT应用ÿ…...
Visual Studio 发布程序自动更新 ClickOnce和AutoUpdater测试
文章目录 前言运行环境ClickOnce(Visual Studio 程序发布)IIS新建文件夹C# 控制台测试安装测试更新测试卸载 AutoUpdaterDotNET实现原理简单使用新建一个WPF项目 代码封装自动更新代码封装简单使用 总结 前言 虽然写的大部分都是不联网项目,…...
Codeforces Round 761 (Div. 2) E. Christmas Chocolates(思维题 树的直径 二进制性质 lca)
题目 n(n<2e5)个值,第i个值ai(0<ai<1e9),所有ai两两不同 初始时,选择两个位置x,y(x≠y),代表需要对这两个位置进行操作,要把其中一个值变成另一个 你可以执行若干次操作,每一次,你可…...

卡证检测矫正模型Java面试题精讲:核心算法与系统设计
卡证检测矫正模型Java面试题精讲:核心算法与系统设计 最近在面试一些Java后端和算法工程师时,我发现很多同学对“卡证检测矫正”这个在金融、政务、安防等领域非常常见的需求,理解还停留在调用API的层面。一旦被问到背后的原理、如何设计一个…...

基于Gamma校正与LAB空间的图片亮度和色度统一化实践
1. 为什么我们需要处理图片亮度和色度 你有没有遇到过这样的问题?同一批照片里,有的看起来特别暗,有的又亮得刺眼,还有的颜色发绿或者发蓝。这种情况在批量处理图片时特别常见,尤其是用不同相机或者在不同光线条件下拍…...

DynamicLake:为Mac带来灵动岛交互体验,支持应用与通知 | ProductHunt 今日热榜 - 03月16日
今日榜单登顶产品 DynamicLake 以 343 票登顶今日热榜!这是一款为Mac移植灵动岛交互体验的工具,整合通知、快捷转换等多种功能,让桌面交互更直观高效。 本期亮点产品介绍 本期Product Hunt热榜AI相关产品占比超一半,围绕OpenCla…...

气功点穴精粹
整理老书发再的,不敢私藏特分享给大家 链接1: https://pan.baidu.com/s/124M0S76gTc6FGAZSr4jBmg?pwd3mu3 链接2:https://pan.quark.cn/s/8f2c95a3d5bb...

OSPF4种网络类型分析-Broadcast/NBMA/P2MP/P2P
一、四种OSPF网络类型分析1. Broadcast(广播模式) 网络特点:支持广播通信,所有设备共享同一广播域(如以太网、VLAN)。 邻居建立:路由协议通过多播Hello包自动发现邻居,并选举DR&…...
——矢量数据集合和影像集合的连接join,给矢量集合添加到两景影像作为矢量集合的属性)
Google Earth Engine(GEE)——矢量数据集合和影像集合的连接join,给矢量集合添加到两景影像作为矢量集合的属性
本次教程主要是加载一个矢量集合,然后通过设定指定的时间条件和地理条件,和指定的时间窗口进行筛选应用于Landsat8 影像,最后将筛选出的影像加载到矢量集合中。 矢量数据集合: Feature Index Dy (Long) Hr (Long) Location N (String) Mo (Long) Year (Long) system:index…...

终极ShareX源码结构解析:核心模块与依赖关系全指南
终极ShareX源码结构解析:核心模块与依赖关系全指南 【免费下载链接】ShareX ShareX is a free and open source program that lets you capture or record any area of your screen and share it with a single press of a key. It also allows uploading images, t…...

Phi-4-reasoning-vision-15B多场景落地:从办公文档处理到工业质检界面分析
Phi-4-reasoning-vision-15B多场景落地:从办公文档处理到工业质检界面分析 1. 引言:当AI学会“看图说话”与“看图思考” 想象一下,你手头有一份复杂的财务报表PDF,里面全是密密麻麻的数字和图表,你需要快速提取关键…...

ClawdBot真实案例:用户上传餐厅菜单图片→OCR识别→翻译成德语结果
ClawdBot真实案例:用户上传餐厅菜单图片→OCR识别→翻译成德语结果 1. 引言:当AI助手遇上跨国点餐难题 想象一下这个场景:你走进一家异国餐厅,菜单上密密麻麻的外文让你一头雾水。服务员忙得不可开交,你也不好意思一…...

通达OA header伪造漏洞实战:从原理到未授权访问
1. 通达OA身份认证绕过漏洞初探 第一次听说通达OA这个漏洞时,我正在给客户做安全审计。当时发现一个奇怪的现象:明明没有登录,却能直接访问后台管理页面。后来深入研究才发现,原来是header伪造导致的身份认证绕过问题。这个漏洞影…...