Redis (三)
1、redis复制
简单的概括就是主从复制,master以写为主,Slave以读为主,当master数据发生变化的时候,自动将更新的数据异步同步到其他的slave是数据库。

使用这种机制的话,可以做到读写分离,可以减轻主机负担。使用这种方式的话可以容灾恢复,就是如果主机挂掉了。还有其他的数据备份,而且数据也是实时的。所以宕机的时候多啦保证!数据备份以及水平扩容支持高并发。
配置从库不配置主库,对于权限信息,如果master配置了密码,需要密码才可以登录,那么slave就需要配置masterauth来设置校验的密码,否则的话master就会拒绝slave的访问请求。
1.1、相关命令
-
使用info replication
-
可以查看复制节点的主从关系和配置信息
-
-
replicaof 主库ip 主库端口
-
配置在从机的配置文件中,配置主机的数据
-
-
slaveof 主库ip 主库端口
-
每次与master断开之后,都需要重新连接,除非你配置进redis.conf文件
-
在运行期间修改slave节点的信息,如果该数据库已经是某个主数据库的从数据库,那么会停止和原主数据库的同步关系,转而和新的主数据库同步
-
-
slaveof no one
-
使当前数据库停止与其他数据库的同步,转成主数据库,自立为王
-
1.2、配置
一个master,然后两个slave,也讲就是说,需要三台虚拟机然而且每一个虚拟机上都安装redis,当然这只是基础的配置条件,然后接下来就是实现这种模式的具体配置。注意要给关闭每一个虚拟机的防火墙。
开启daemonize
daemonize yes修改ip
bind 192.168.200.88 -::1protected-mode
protected-mode no指定端口
port 6379指定当前的工作目录
dir /software/redis/redis-7.2.3/redisconf/backupfilespid文件名字,pidfile
pidfile /var/run/redis_6379.pidlog文件名字
logfile /software/redis/redislog/redis-log.log本机密码
requirepass 123456dump.rdb文件名字
dbfilename dump88.rdbaof文件,appendfilename
暂时不开启主机密码
replicaof 192.168.200.88 6379
masterauth "10100109"1.2.1、主从复制
三台linux虚拟机,然后安装配置完成后正常启动连接!
查看主机日志文件如下
26152:M 04 Jan 2024 17:57:06.501 * Synchronization with replica 192.168.200.111:6380 succeeded
26152:M 04 Jan 2024 17:59:59.525 * Replica 192.168.200.99:6380 asks for synchronization
26152:M 04 Jan 2024 17:59:59.525 * Full resync requested by replica 192.168.200.99:6380
26152:M 04 Jan 2024 17:59:59.525 * Delay next BGSAVE for diskless SYNC
26152:M 04 Jan 2024 18:00:04.517 * Synchronization with replica 192.168.200.99:6380 succeeded
26152:M 04 Jan 2024 18:04:57.044 * Connection with replica 192.168.200.111:6380 lost.
26152:M 04 Jan 2024 18:05:12.186 * Replica 192.168.200.111:6381 asks for synchronization
26152:M 04 Jan 2024 18:05:12.187 * Partial resynchronization request from 192.168.200.111:6381 accepted. Sending 14 bytes of backlog starting from offset 673.查看从机日志
6107:S 04 Jan 2024 18:05:12.189 * Ready to accept connections tcp
6107:S 04 Jan 2024 18:05:12.190 * Connecting to MASTER 192.168.200.88:6379
6107:S 04 Jan 2024 18:05:12.190 * MASTER <-> REPLICA sync started
6107:S 04 Jan 2024 18:05:12.190 * Non blocking connect for SYNC fired the event.
6107:S 04 Jan 2024 18:05:12.191 * Master replied to PING, replication can continue...主机查看配置info replication
> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.200.99,port=6380,state=online,offset=1624,lag=0
slave1:ip=192.168.200.111,port=6381,state=online,offset=1624,lag=0
master_failover_state:no-failover
master_replid:ad3197cb5b7476962c1243102b7a135a8cfe83d5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1624
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:1624从机查看配置,info replication
> info replication
# Replication
role:slave
master_host:192.168.200.88
master_port:6379
master_link_status:up
master_last_io_seconds_ago:10
master_sync_in_progress:0
slave_read_repl_offset:1820
slave_repl_offset:1820
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:ad3197cb5b7476962c1243102b7a135a8cfe83d5
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:1820
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:267
repl_backlog_histlen:1554测试
#主机
> set k1 v1
OK
#从机
> get k1
v1
> get k1
v1
1.2.1.1、总结
配置过的从机是只能执行读操作,不能执行写操作,这样以来可以实现读写分离提高性能。
#从机写入
> set k2 v2
READONLY You can't write against a read only replica.假设主机启动后然后执行了多次的写操作后从机才启动,那么从机可以读取之前的写入的数据嘛,是这样的从机第一次启动的话会备份主机的之前的所有的数据做到同步,然后对于后续的主机的写操作同步的更新。
#主机写
> Linux-master-redis connected!
> set k2 v2
OK
> set k3 v3
OK
#启动从机,访问数据正常
> linux-111-6381 connected!
> get k2
v2
> get k3
v3主机宕机的话会出现什么操作,是从机变主机?数据读取失败?是这样的从机还是老老实实的做从机,等待主机恢复,而且读取数据正常没有影响。
#主机宕机
shutdown
#从机读写
> get k1
v1
> set k4 v4
READONLY You can't write against a read only replica.主机重启不影响之前建立的关系
#主机
> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=192.168.200.111,port=6381,state=online,offset=10316,lag=1
slave1:ip=192.168.200.99,port=6380,state=online,offset=10316,lag=0
master_failover_state:no-failover
master_replid:0fc82d3e3251195aec8a42cc1b350b54a5435054
master_replid2:ad3197cb5b7476962c1243102b7a135a8cfe83d5
master_repl_offset:10316
second_repl_offset:10289
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:10289
repl_backlog_histlen:28
> set k4 v4
OK
#从机读取
> get k4
v4欧克,上面是使用配置文件的方式来使用,也就是写死的这种情况,但是我们还有可以使用命令的方式来进行配置,接下来停掉两个从机,然后注释掉之前的配置文件,然后测试不同的情况。
# replicaof 192.168.200.88 6379重启后查看主从配置
#三台都是主机!
> info replication
# Replication
role:master
connected_slaves:0
master_failover_state:no-failover
master_replid:c69b05376562297a6868fc0311814cb9d0233331
master_replid2:0fc82d3e3251195aec8a42cc1b350b54a5435054
master_repl_offset:12174
second_repl_offset:12175
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:12175
repl_backlog_histlen:0好滴,指定主机使用命令,发现连接以后数据同步!
#从机执行
SLAVEOF 192.168.200.88 6379测试关机后的从机,重启后使用主从关系命令设置后,关系失效,也就是说使用命令的方式的话是临时的,只有使用配置文件的话是可以永久生效的。
1.2.2、叠叠乐
这个不看也大致可以猜出来就是,一个主机的从机可以是另外一个从机的主机!也就是说即使是从机也可以接受其他的从机的连接以及数据同步,这样的话可以分担主机的写压力!为了方便演示就不在使用配置文件了,采用命令的方式使用比较方便。
#主机
192.168.200.88
#从机 ————主机
192.168.200.99
#从机
192.168.200.111
#欧克当我连接完毕后发现数据已经同步完成,接下来测试不同的情况
#主机写看从机的从机的数据同步
> set k5 v5
OK
> SLAVEOF 192.168.200.88 6379
OK
> get k5
v5
> SLAVEOF 192.168.200.99 6380
OK
> get k5
v5
#对于从机的从机来讲,从机也是主机(哈哈哈),那么他可以写嘛
> set k6 v6
READONLY You can't write against a read only replica.
#主机挂了,从机的从机可以写嘛,不可以,但是可以读!
> linux-99-6380 connected!
> get k1
v1
> set k6 v6
READONLY You can't write against a read only replica.1.2.3、自立门户
使用命令可以,然当前的redis服务器脱离主从关系,变为主机。
> linux-111-6381 connected!
> SLAVEOF no one
OK
> set k6 v6
OK1.3、总结
1.3.1、工作模式
slave启动成功连接master后会发送一个同步的命令,然后对于初次连接的话,slave会将master中的数据全部复制copy,做到数据的同步,然后salve自身原有的数据会被master数据覆盖清除。
首次连接、全量复制
master节点收到sync命令后会开始在后台保存快照(即RDB持久化,主从复制时会触发RDB),同时收集所有接收到的用于修改数据集命令缓存起来,master节点执行RDB持久化完后,master将rdb快照文件和所有缓存的命令发送到所有slave,以完成一次完全同步,而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中,从而完成复制初始化。
心跳持续、保持通信
master发出PING包的周期,默认是10秒
repl-ping-replica-period 10进入平稳、增量复制
Master继续将新的所有收集到的修改命令自动依次传给slave,完成同步。
从机下线,重连续传
master会检查backlog里面的offset,master和slave都会保存一个复制的offset还有一个masterId,offset是保存在backlog中的。Master只会把已经复制的offset后面的数据复制给Slave,类似断点续传。
1.3.2、缺点
复制延时,信号衰减,大概的意思就是,要满足高可用的方式工作的话,需要在一个主机上挂载很多的从机,数据在同步的时候会有演示,从机越多问题越明显。
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。
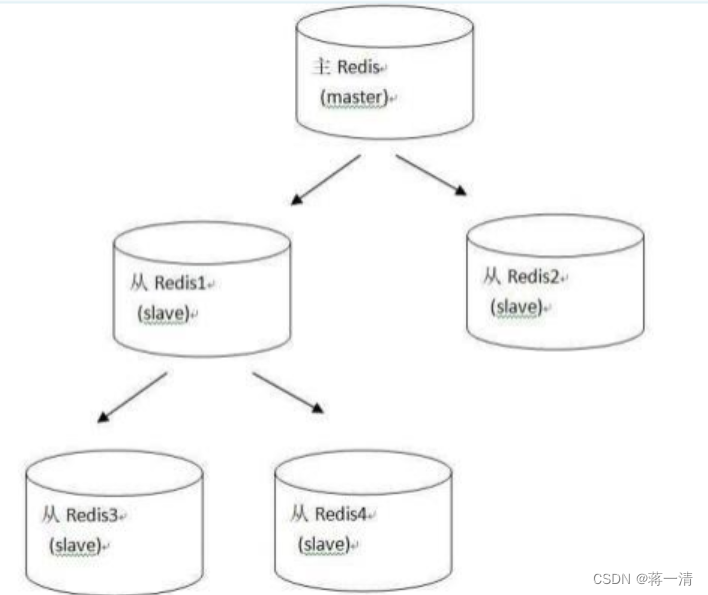
主机挂掉,从机还是只能读,直到主机重启。(无人值守---哨兵)
2、哨兵模式
哨兵模式就是可以监控redis的运行状态呢,然后如果主机发生了故障会根据投票数自动将某一个从库转换成为新的主库,然后对外提供服务。不在需要人工的干预。

2.1、哨兵模式功能
-
主从监控:可以监控主机和从机的运行状态是不是正常
-
消息通知:哨兵可以将故障转移的结果发送给客户端
-
故障转移:如果master异常,那么会进行主从的切换,将其中的一个slave作为新的master
-
配置中心:客户端通过连接哨兵来获得当前的redis服务的主节点的地址
2.2、哨兵模式架构

首先要说明为什么要用哨兵的集群(奇数防止投票数一样的情况。)呐,第一点就是,只配置一个哨兵,那么哨兵挂掉后,然后主机也挂掉,那么整个哨兵模式就白搭了。所以配置集群可以避免这中情况,第二点就是防止专断,就是如果主机只是因为网络延时导致哨兵判断失误,然后将当前的主机判定为挂掉重新选举主机,多台可以投票判断(民主方式)。
2.2.1、配置方式
上面是我们的redis.conf文件,然后就是按照上面的架构模式配置的话,要配置六台虚拟机,直接把电脑撑爆,太离谱没钱加装内存条!首先不建议直接在原配置文件上修改,所以还是和之前一样将原配置文件复制到指定的文件夹然后配置。
[root@localhost redis-7.2.3]# cp sentinel.conf /software/redis/redis-7.2.3/redisconf/sentinel.conf除了配置和配置redis.conf的基础配置项之外,还要配置额外的如下配置
首先在sentinel.conf配置参数,除了配置主从复制的参数之外,然后还有加上监视的主机的信息
sentinel monitor <master-name> <ip> <redis-port> <quorum>
sentinel monitor mymaster 192.168.111.169 6379 2
设置要监控的master服务器,quorum表示最少有几个哨兵认可客观下线,同意故障迁移的法定票数。quorum:确认客观下线的最少的哨兵数量,只有哨兵的投票数大于这个最小的数量的时候才会确认这个主机挂掉了,我们知道,网络是不可靠的,有时候一个sentinel会因为网络堵塞而误以为一个master redis已经死掉了,在sentinel集群环境下需要多个sentinel互相沟通来确认某个master是否真的死了,quorum这个参数是进行客观下线的一个依据,意思是至少有quorum个sentinel认为这个master有故障,才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因,导致无法连接master,而此时master并没有出现故障,所以,这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
配置监视主机的密码,master设置了密码,连接master服务的密码
sentinel auth-pass <master-name> <password>
sentinel auth-pass mymaster 111111指定多少毫秒之后,主节点没有应答哨兵,此时哨兵主观上认为主节点下线
sentinel down-after-milliseconds <master-name> <milliseconds>配置表示允许并行同步的slave个数,当Master挂了后,哨兵会选出新的Master,此时,剩余的slave会向新的master发起同步数据
sentinel parallel-syncs <master-name> <nums>故障转移的超时时间,进行故障转移时,如果超过设置的毫秒,表示故障转移失败
sentinel failover-timeout <master-name> <milliseconds>配置当某一事件发生时所需要执行的脚本
sentinel notification-script <master-name> <script-path> 客户端重新配置主节点参数脚本
sentinel client-reconfig-script <master-name> <script-path>样板:
bind 0.0.0.0
daemonize yes
protected-mode no
port 26381
logfile "/myredis/sentinel26381.log"
pidfile /var/run/redis-sentinel26381.pid
dir "/myredis"
sentinel monitor mymaster 192.168.111.169 6379 2
sentinel auth-pass mymaster 111111 #主机以及哨兵
root 22727 1 0 22:23 ? 00:00:00 redis-server 192.168.200.88:6379
root 26236 1 1 22:26 ? 00:00:00 redis-sentinel 192.168.200.88:26379 [sentinel]
#从机以及哨兵
[root@localhost sentinel]# ps -ef|grep redis|grep -v grep
root 22745 1 0 22:23 ? 00:00:00 redis-server 192.168.200.99:6379
root 26484 1 0 22:26 ? 00:00:00 redis-sentinel 192.168.200.99:26379 [sentinel]
[root@jiangyiqing sentinel]# ps -ef|grep redis|grep -v grep
root 22486 1 0 22:23 ? 00:00:00 redis-server 192.168.200.111:6379
root 26571 1 1 22:26 ? 00:00:00 redis-sentinel 192.168.200.111:26379 [sentinel]
条件有限只能这样演示数据!
查看哨兵日志,发现一切正常你,三个哨兵构成集群。
#启动后测试主从正常,然后测试主机挂掉,然后使用命令哪一个从机会成为主机
#首先查看数据没有问题
> get k1
v1
#然后随机挑选从机查看状态是不是选举出来新的主机
> info replication
# Replication
role:slave
master_host:192.168.200.99
master_port:6379
master_link_status:up
master_last_io_seconds_ago:0
master_sync_in_progress:0
slave_read_repl_offset:250240
slave_repl_offset:250240
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:85db2fa7fc5bf6864636b8a376da63f06e4ea4e3
master_replid2:e43a6c37a2ce62bdf26cbff3113e9b735518c7fe
master_repl_offset:250240
second_repl_offset:250076
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:477
repl_backlog_histlen:249764
#发现主机的ip已经跟换,然后说明配置的哨兵模式起作用
#测试在新选举的主机上写操作
> info replication
# Replication
role:master
connected_slaves:1
slave0:ip=192.168.200.111,port=6379,state=online,offset=295068,lag=1
master_failover_state:no-failover
master_replid:85db2fa7fc5bf6864636b8a376da63f06e4ea4e3
master_replid2:e43a6c37a2ce62bdf26cbff3113e9b735518c7fe
master_repl_offset:295209
second_repl_offset:250076
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:218877
repl_backlog_histlen:76333
> set k2 v2
OK
#测试从机读取
> get k2
v2
#测试之前挂掉的主机重启后,谁是master
> info replication
# Replication
role:slave
master_host:192.168.200.99
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_read_repl_offset:252218
slave_repl_offset:252218
master_link_down_since_seconds:-1
slave_priority:100
slave_read_only:1
replica_announced:1
connected_slaves:0
master_failover_state:no-failover
master_replid:fefb137f28d435ed43656ac31e88e94e66be09c6
master_replid2:e43a6c37a2ce62bdf26cbff3113e9b735518c7fe
master_repl_offset:252218
second_repl_offset:250076
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:250076
repl_backlog_histlen:2143
#很明显之前的主机启动后并没有成为master而是成为slave,但是不知道为什么,刚刚用新产生的master做了一次写操作,然后另外的从机可以读取,但是对于刚启动的挂掉的主机却读取不到数据!!
> get k2
null
测试挂掉的烧饼日志

2.3、工作流程
当一个主从配置中的master失效之后,sentinel可以选举出一个新的master,用于自动接替原master的工作,主从配置中的其他redis服务器自动指向新的master同步数据。一般建议sentinel采取奇数台,防止某一台sentinel无法连接到master导致误切换。
首先按照配置好的redis的哨兵框架,哨兵正常的监视着主机的状态,但是突然有一天...
2.3.1、SDown主观下线
所谓主观下线(Subjectively Down, 简称 SDOWN)指的是单个Sentinel实例对服务器做出的下线判断,即单个sentinel认为某个服务下线(有可能是接收不到订阅,之间的网络不通等等原因)。主观下线就是说如果服务器在[sentinel down-after-milliseconds]给定的毫秒数之内没有回应PING命令或者返回一个错误消息, 那么这个Sentinel会主观的(单方面的)认为这个master不可以用了,o(╥﹏╥)o
sentinel配置文件中的down-after-milliseconds设置了判断主观下线的时间长度。表示master被当前sentinel实例认定为失效的间隔时间,这个配置其实就是进行主观下线的一个依据,master在多长时间内一直没有给Sentine返回有效信息,则认定该master主观下线。也就是说如果多久没联系上redis-servevr,认为这个redis-server进入到失效(SDOWN)状态。
那么多哨兵就你一个说不行就不行,肯定是不可以的!
2.3.2、ODown客观下线
ODOWN需要一定数量的sentinel,多个哨兵达成一致意见才能认为一个master客观上已经宕掉。( 民主决议,少数服从多数!),这里就使用到了quorum参数,投个票吧,然后看赞同宕机的有多少,如果大于quorum参数就可以认主机宕机啦,意思是至少有quorum个sentinel认为这个master有故障才会对这个master进行下线以及故障转移。因为有的时候,某个sentinel节点可能因为自身网络原因导致无法连接master,而此时master并没有出现故障,所以这就需要多个sentinel都一致认为该master有问题,才可以进行下一步操作,这就保证了公平性和高可用。
好好好,也知道主机是宕机啦,那要选出一个主机吧,那么多兵,你说这个,我说那个!难搞
2.3.3、哨兵兵王
当主节点被判断客观下线以后,各个哨兵节点会进行协商,先选举出一个领导者哨兵节点(兵王)并由该领导者节点,也即被选举出的兵王进行failover(故障迁移)。怎么说,谁是兵王,投个票吧!
选出领导者使用的是Raft算法!监视该主节点的所有哨兵都有可能被选为领导者,选举使用的算法是Raft算法;Raft算法的基本思路是先到先得:
即在一轮选举中,哨兵A向B发送成为领导者的申请,如果B没有同意过其他哨兵,则会同意A成为领导者

欧克,兵王有啦,该解决问题了叭
2.3.4、故障迁移
2.3.4.1、新主登基
兵王选出来一个slave成为master,好嘛,有什么规则嘛,别不明不白的就选了!

-
redis.conf文件中,优先级slave-priority或者replica-priority最高的从节点(数字越小优先级越高 )
-
复制偏移位置offset最大的从节点,就是谁的数据更接近master的数据
-
最小Run ID的从节点,字典顺序ASCII码
2.3.4.2、群臣俯首
执行slaveof no one命令让选出来的从节点成为新的主节点,并通过slaveof命令让其他节点成为其从节点,Sentinel leader会对选举出的新master执行slaveof no one操作,将其提升为master节点。Sentinel leader向其它slave发送命令,让剩余的slave成为新的master节点的slave。
2.3.4.3、旧主臣服
将之前已下线的老master设置为新选出的新master的从节点,当老master重新上线后,它会成为新master的从节点,Sentinel leader会让原来的master降级为slave并恢复正常工作。
欧克,看这工作量还挺多,哨兵来完成不需要人工干预。
3、redis集群
首先为了高并发提高性能,引入读写分离也就是主从复制,然后中间考虑到主机宕机的问题,从机无动于衷干等着主机恢复,为了这个问题提出哨兵模式,哨兵模式的引入可以解决主机宕机后的故障迁移,配置新的主机来完成写的任务,但事实上我们从头到尾还是只有一台主机,写的压力也太大。
由于数据量过大,单个Master复制集难以承担,因此需要对多个复制集进行集群,形成水平扩展每个复制集只负责存储整个数据集的一部分,这就是Redis的集群,其作用是提供在多个Redis节点间共享数据的程序集。

redis集群支持多个master,每一个mater有可以挂载多个slave,然后这样的话就可以实现,读写分离、指出数据的高可用以及支持海量的数据的读写存储操作,同时由于cluster自带Sentine的故障转移机制,内置了高可用的支持,无需再使用哨兵功能。而且客户端和redis的节点的连接,不在需要连接集群中所有的节点,只需要任意连接集群中的一个节点基于可以,槽位slot负责分配到给各个物理服务器节点,有对对应的集群来负责维护节点、插槽和数据之间的关系。
3.1、槽位Slot、分片
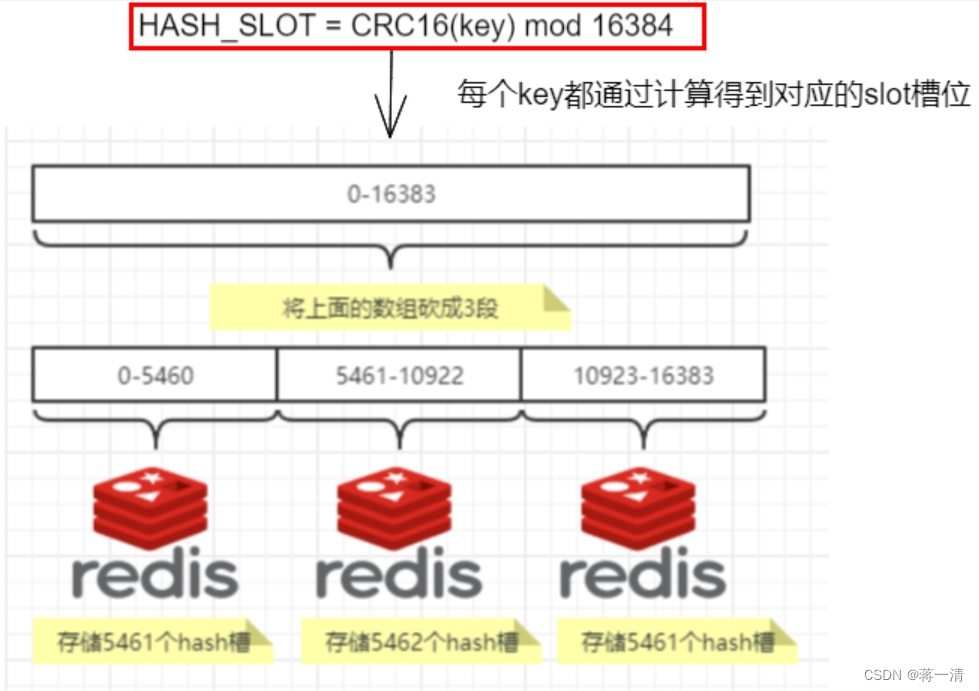
3.1.1、槽位
redis集群没有使用一致性hash,而是引入了哈希槽的概念,redis集群有16384个哈希槽,每一个key通过CRC16
校验后对16384取模来决定放置哪个槽,集群的每一个节点负责一部分的hash槽,如果集群有三个节点:
3.1.2、分片
分片是什么?使用Redis集群时我们会将存储的数据分散到多台redis机器上,这称为分片。简言之,集群中的每个Redis实例都被认为是整个数据的一个分片。
如何找到给定key的分片,为了找到给定key的分片,我们对key进行CRC16(key)算法处理并通过对总分片数量取模。然后,使用确定性哈希函数,这意味着给定的key将多次始终映射到同一个分片,我们可以推断将来读取特定key的位置。
3.1.3、优势
最大优势,方便扩缩容和数据分派查找。这种结构很容易添加或者删除节点,比如如果我想新添加个节点D,我需要从节点 A、B、C中得部分槽到D上,如果我想移除节点A,需要将A中的槽移到B和C节点上,然后将没有任何槽的A节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
3.1.4、slot槽位映射的方式
3.1.4.1哈希取余分区
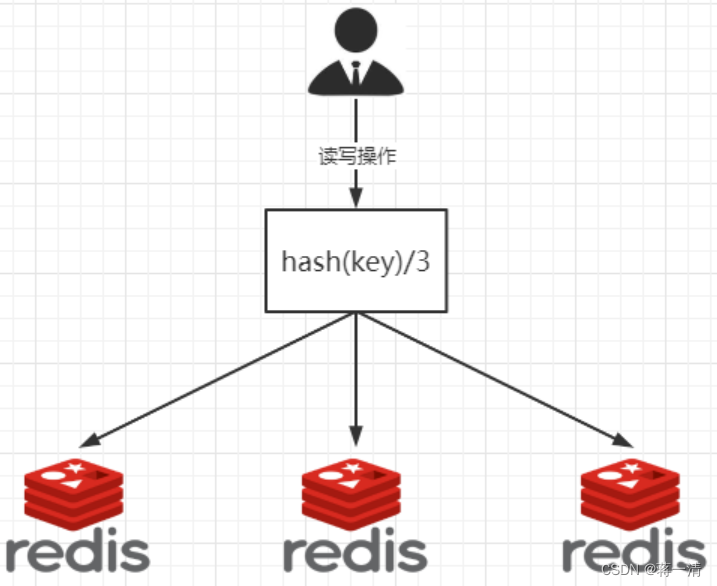
3.1.4.1.1、优点:
简单粗暴,直接有效,只需要预估好数据规划好节点,例如3台、8台、10台,就能保证一段时间的数据支撑。使用Hash算法让固定的一部分请求落到同一台服务器上,这样每台服务器固定处理一部分请求(并维护这些请求的信息),起到负载均衡+分而治之的作用。
3.1.4.1.2、缺点:
原来规划好的节点,进行扩容或者缩容就比较麻烦了,不管扩缩,每次数据变动导致节点有变动,映射关系需要重新进行计算,在服务器个数固定不变时没有问题,如果需要弹性扩容或故障停机的情况下,原来的取模公式就会发生变化:Hash(key)/3会变成Hash(key) /?。此时地址经过取余运算的结果将发生很大变化,根据公式获取的服务器也会变得不可控。
某个redis机器宕机了,由于台数数量变化,会导致hash取余全部数据重新洗牌。
3.1.4.2、一致性hash算法分区
设计目标是为了解决分布式缓存数据变动和映射问题,某个机器宕机了,分母数量改变了,自然取余数不OK了。提出一致性Hash解决方案。目的是当服务器个数发生变动时,尽量减少影响客户端到服务器的映射关系。
3.1.4.2.1、一致性hash环
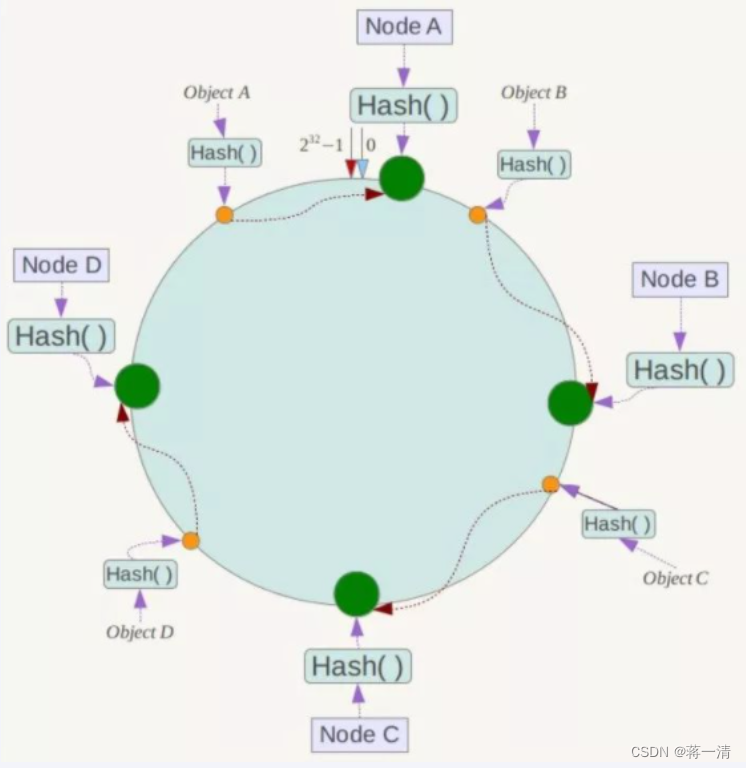
一致性哈希算法必然有个hash函数并按照算法产生hash值,这个算法的所有可能哈希值会构成一个全量集,这个集合可以成为一个hash空间[0,2^32-1],这个是一个线性空间,但是在算法中,我们通过适当的逻辑控制将它首尾相连(0 = 2^32),这样让它逻辑上形成了一个环形空间。
它也是按照使用取模的方法,前面笔记介绍的节点取模法是对节点(服务器)的数量进行取模。而一致性Hash算法是对2^32取模,简单来说,一致性Hash算法将整个哈希值空间组织成一个虚拟的圆环,如假设某哈希函数H的值空间为0-2^32-1(即哈希值是一个32位无符号整形),整个哈希环如下图:
整个空间按顺时针方向组织,圆环的正上方的点代表0,0点右侧的第一个点代表1,以此类推,2、3、4、……直到2^32-1,也就是说0点左侧的第一个点代表2^32-1, 0和2^32-1在零点中方向重合,我们把这个由2^32个点组成的圆环称为Hash环。

3.1.4.2.2、节点映射
将集群中各个IP节点映射到环上的某一个位置。将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台机器就能确定其在哈希环上的位置。假如4个节点NodeA、B、C、D,经过IP地址的哈希函数计算(hash(ip)),使用IP地址哈希后在环空间的位置如下:

3.1.4.2.3、key的存储位置
当我们需要存储一个kv键值对时,首先计算key的hash值,hash(key),将这个key使用相同的函数Hash计算出哈希值并确定此数据在环上的位置,从此位置沿环顺时针“行走”,第一台遇到的服务器就是其应该定位到的服务器,并将该键值对存储在该节点上。
如我们有Object A、Object B、Object C、Object D四个数据对象,经过哈希计算后,在环空间上的位置如下:根据一致性Hash算法,数据A会被定为到Node A上,B被定为到Node B上,C被定为到Node C上,D被定为到Node D上。
3.1.4.2.4、优点
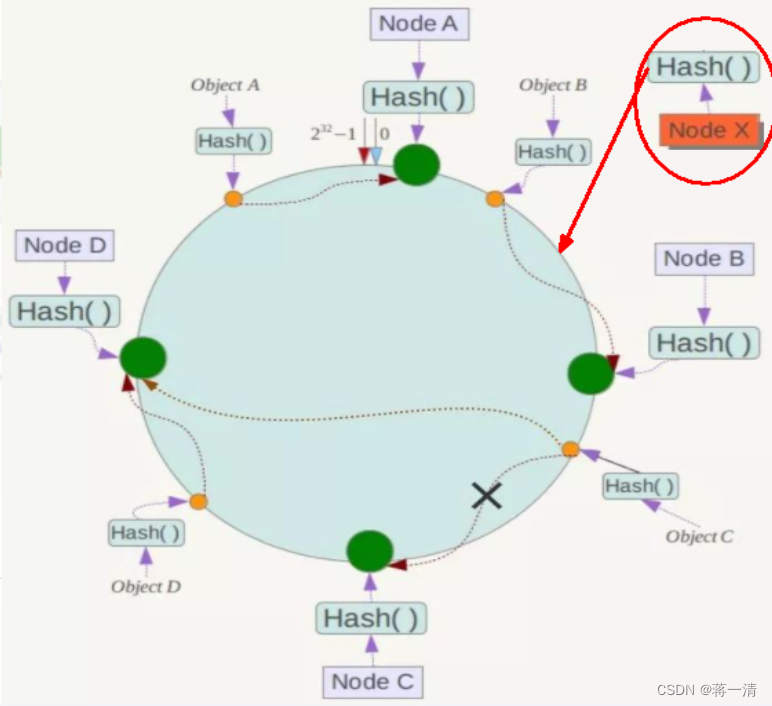
容错性
假设Node C宕机,可以看到此时对象A、B、D不会受到影响。一般的,在一致性Hash算法中,如果一台服务器不可用,则受影响的数据仅仅是此服务器到其环空间中前一台服务器(即沿着逆时针方向行走遇到的第一台服务器)之间数据,其它不会受到影响。简单说,就是C挂了,受到影响的只是B、C之间的数据且这些数据会转移到D进行存储。

扩展性
数据量增加了,需要增加一台节点NodeX,X的位置在A和B之间,那收到影响的也就是A到X之间的数据,重新把A到X的数据录入到X上即可,不会导致hash取余全部数据重新洗牌。
3.1.4.2.5、缺点
Hash环的数据倾斜问题
一致性Hash算法在服务节点太少时,容易因为节点分布不均匀而造成数据倾斜(被缓存的对象大部分集中缓存在某一台服务器上)问题,
例如系统中只有两台服务器:

为了在节点数目发生改变时尽可能少的迁移数据,将所有的存储节点排列在收尾相接的Hash环上,每个key在计算Hash后会顺时针找到临近的存储节点存放。而当有节点加入或退出时仅影响该节点在Hash环上顺时针相邻的后续节点。 这样的结构在加入和删除节点只影响哈希环中顺时针方向的相邻的节点,对其他节点无影响。但是由于数据的分布和节点的位置有关,因为这些节点不是均匀的分布在哈希环上的,所以数据在进行存储时达不到均匀分布的效果。
3.1.4.3、哈希槽分区
首先哈希槽可以解决一致性哈希算法当节点数量少的时候,导致的数据分布不均匀的情况,哈希槽的实质就是一个数组,[0-2^14-1]形成一个hash slot空间。
解决均匀分配的问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
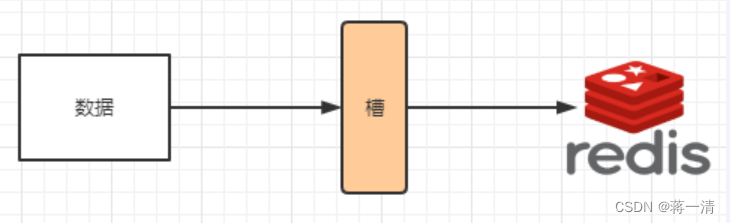
槽解决的是粒度问题,相当于把粒度变大了,这样便于数据移动。哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配
一个集群只能有16384个槽,编号0-16383(0-2^14-1)。这些槽会分配给集群中的所有主节点,分配策略没有要求。
集群会记录节点和槽的对应关系,解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取模,余数是几key就落入对应的槽里。HASH_SLOT = CRC16(key) mod 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
相关文章:
Redis (三)
1、redis复制 简单的概括就是主从复制,master以写为主,Slave以读为主,当master数据发生变化的时候,自动将更新的数据异步同步到其他的slave是数据库。 使用这种机制的话,可以做到读写分离,可以减轻主机负担…...
CompletableFuture超详解与实践
0.背景 一个接口可能需要调用 N 个其他服务的接口,这在项目开发中还是挺常见的。举个例子:用户请求获取订单信息,可能需要调用用户信息、商品详情、物流信息、商品推荐等接口,最后再汇总数据统一返回。 如果是串行(按…...
Maven之私服
1 介绍 团队开发现状分析私服是一台独立的服务器,用于解决团队内部的资源共享与资源同步问题Nexus Sonatype公司的一款maven私服产品 下载地址:https://help.sonatype.com/repomanager3/download win版安装包:https://pan.baidu.com/s/1wk…...
#define宏定义的初探
前言: 最基本的#define定义方式 #define可以定义宏,这点相信大家并不陌生,其定义的方式十分简单,给大家随便来一个最简单、最基础的定义方式看看: #include<stdio.h> #define a 3 int main() { printf(&quo…...

机器学习 -决策树的案例
场景 我们对决策树的基本概念和算法其实已经有过了解,那我们如何利用决策树解决问题呢? 构建决策树 数据准备 我们准备了一些数据如下: # 定义新的数据集 new_dataSet [[晴朗, 是, 高, 是],[雨天, 否, 低, 否],[阴天, 是, 中, 是],[晴朗…...
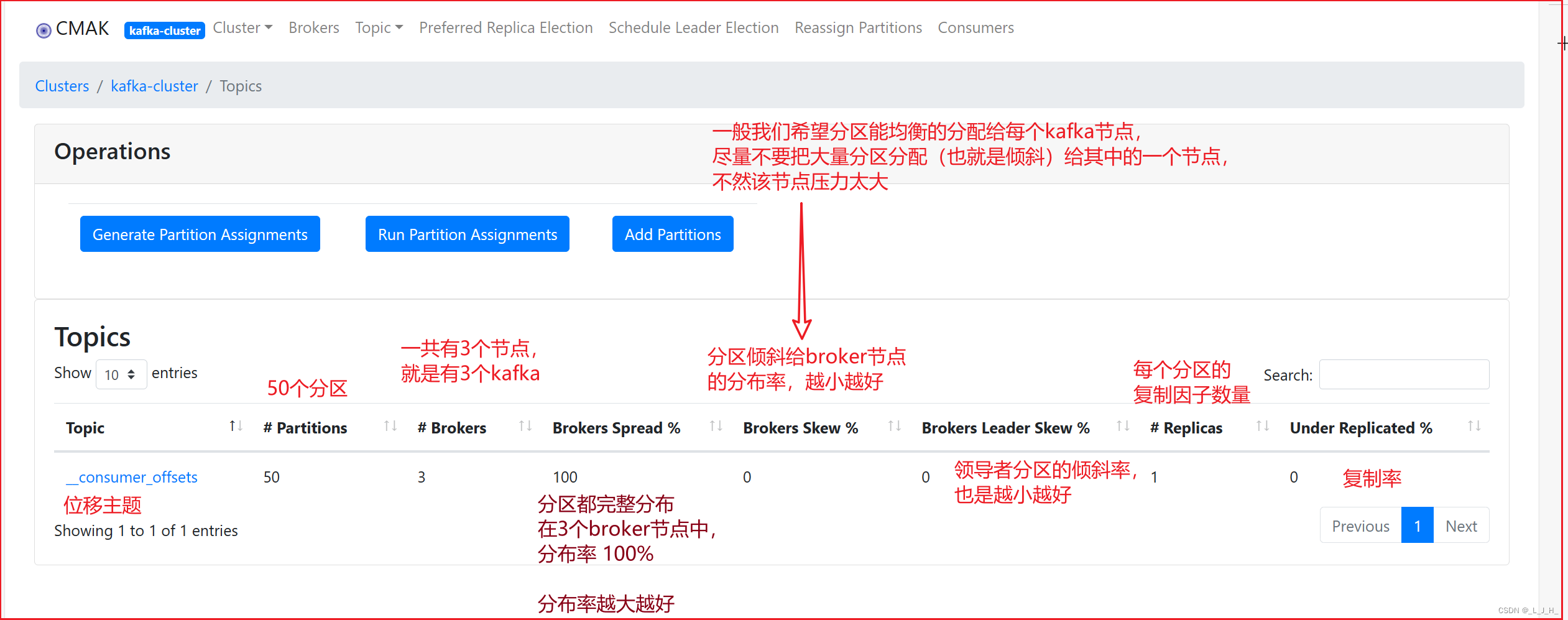
04、Kafka ------ 各个功能的作用解释(Cluster、集群、Broker、位移主题、复制因子、领导者副本、主题)
目录 启动命令:CMAK的用法★ 在CMAK中添加 Cluster★ 在CMAK中查看指定集群★ 在CMAK中查看 Broker★ 位移主题★ 复制因子★ 领导者副本和追随者副本★ 查看主题 启动命令: 1、启动 zookeeper 服务器端 小黑窗输入命令: zkServer 2、启动 …...

1、C语言:数据类型/运算符与表达式
数据类型/运算符/表达式 1.数据类型与长度2.常量3.声明4. 运算符5. 表达式 1.数据类型与长度 基本数据类型 类型说明char字符型,占用一个字节,可以存放本地字符集中的一个字符int整型,通常反映了所有机器中整数的最自然长度float单精度浮点…...
[ffmpeg系列 03] 文件、流地址(视频)解码为YUV
一 代码 ffmpeg版本5.1.2,dll是:ffmpeg-5.1.2-full_build-shared。x64的。 文件、流地址对使用者来说是一样。 流地址(RTMP、HTTP-FLV、RTSP等):信令完成后,才进行音视频传输。信令包括音视频格式、参数等协商。 接流的在实际…...

python算法每日一练:连续子数组的最大和
这是一道关于动态规划的算法题: 题目描述: 给定一个整数数组 nums,请找出该数组中连续子数组的最大和,并返回这个最大和。 示例: 输入:[-2, 1, -3, 4, -1, 2, 1, -5, 4] 输出:6 解释ÿ…...
一个vue3的tree组件
https://download.csdn.net/download/weixin_41012767/88709466...

新手练习项目 4:简易2048游戏的实现(C++)
名人说:莫听穿林打叶声,何妨吟啸且徐行。—— 苏轼《定风波莫听穿林打叶声》 Code_流苏(CSDN)(一个喜欢古诗词和编程的Coder) 目录 一、效果图二、代码(带注释)三、说明 一、效果图 二、代码(带…...

2023年度总结:技术沉淀、持续学习
2023年度总结:技术沉淀、持续学习 一、引言 今年是我毕业的第二个年头,也是完整的一年,到了做年终总结的时候了 这一年谈了女朋友,学习了不少技术,是充实且美好的一年! 首先先看年初定的小目标…...
Unity 利用UGUI之Slider制作进度条
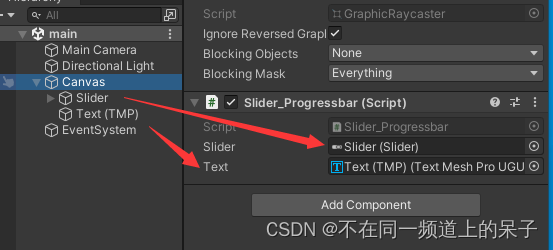
在Unity中使用Slider和Text组件可以制作简单的进度条。 首先在场景中右键->UI->Slider,新建一个Slider组件: 同样方法新建一个Text组件,最终如图: 创建一个进度模拟脚本,Slider_Progressbar.cs using System.C…...
OCS2 入门教程(四)- 机器人示例
系列文章目录 前言 OCS2 包含多个机器人示例。我们在此简要讨论每个示例的主要特点。 System State Dim. Input Dim. Constrained Caching Double Integrator 2 1 No No Cartpole 4 1 Yes No Ballbot 10 3 No No Quadrotor 12 4 No No Mobile Manipul…...

FreeRTOS学习第6篇–任务状态挂起恢复删除等操作
目录 FreeRTOS学习第6篇--任务状态挂起恢复删除等操作任务的状态设计实验IRReceiver_Task任务相关代码片段实验现象本文中使用的测试工程 FreeRTOS学习第6篇–任务状态挂起恢复删除等操作 本文目标:学习与使用FreeRTOS中的几项操作,有挂起恢复删除等操作…...
BLE Mesh蓝牙组网技术详细解析之Access Layer访问层(六)
目录 一、什么是BLE Mesh Access Layer访问层? 二、Access payload 2.1 Opcode 三、Access layer behavior 3.1 Access layer发送消息的流程 3.2 Access layer接收消息的流程 3.3 Unacknowledged and acknowledged messages 3.3.1 Unacknowledged message …...

Netlink 通信机制
文章目录 前言一、Netlink 介绍二、示例代码参考资料 前言 一、Netlink 介绍 Netlink套接字是用以实现用户进程与内核进程通信的一种特殊的进程间通信(IPC) ,也是网络应用程序与内核通信的最常用的接口。 在Linux 内核中,使用netlink 进行应用与内核通信的应用有…...

2024.1.8每日一题
LeetCode 回旋镖的数量 447. 回旋镖的数量 - 力扣(LeetCode) 题目描述 给定平面上 n 对 互不相同 的点 points ,其中 points[i] [xi, yi] 。回旋镖 是由点 (i, j, k) 表示的元组 ,其中 i 和 j 之间的距离和 i 和 k 之间的欧式…...
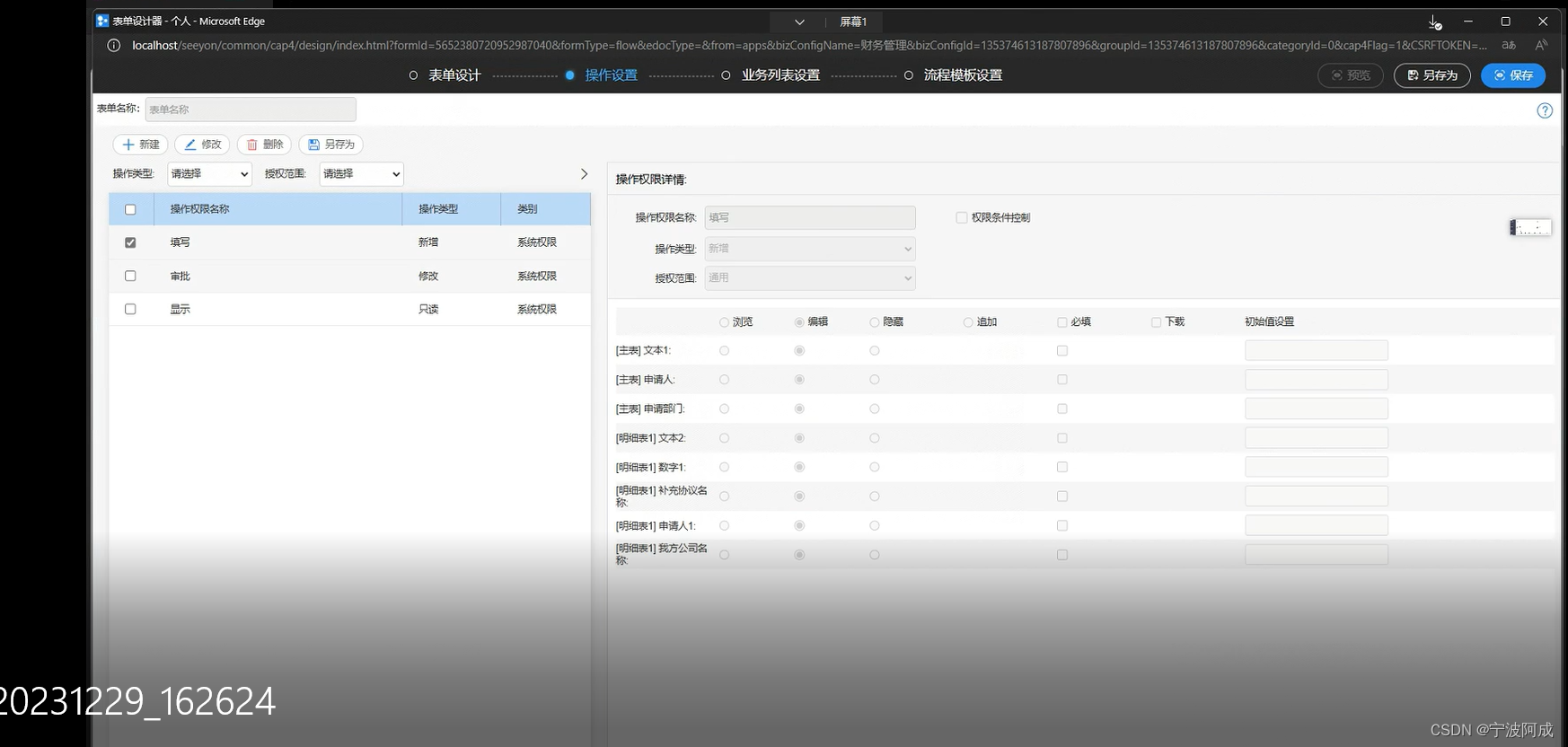
看了致远OA的表单设计后的思考
更多ruoyi-nbcio功能请看演示系统 gitee源代码地址 前后端代码: https://gitee.com/nbacheng/ruoyi-nbcio 演示地址:RuoYi-Nbcio后台管理系统 更多nbcio-boot功能请看演示系统 gitee源代码地址 后端代码: https://gitee.com/nbacheng/n…...
mmdetection训练自己的数据集
mmdetection训练自己的数据集 这里写目录标题 mmdetection训练自己的数据集一: 环境搭建二:数据集格式转换(yolo转coco格式)yolo数据集格式coco数据集格式yolo转coco数据集格式yolo转coco数据集格式的代码 三: 训练dataset数据文件配置config…...

ubuntu20.04编译LIO-SAM问题解决
gtsam:注意,和tbb都使用源码安装!!PPA安装会造成版本混乱,要选择oneAPI TBB # 克隆 oneTBB 仓库 git clone https://github.com/oneapi-src/oneTBB.git cd oneTBB# 创建构建目录并配置 mkdir build && cd bui…...

MCP、RAG与AI智能体对比图文笔记:收藏这份入门指南,轻松掌握大模型核心技术方向!
核心概念:各司其职的技术方向当前AI领域最火的三个概念(MCP、RAG、AI智能体),本质上解决的是不同层面的问题,并非互斥竞争关系。以下是它们的定位差异:技术方向核心能力解决的核心问题MCP定义LLM如何使用外…...

【AI】Mac 安装 OpenClaw 及接入飞书教程
一、安装 Nodejs(必须) 因为 OpenClaw 至少需要运行在 node22 版本环境,因此需要先安装 node 环境 step1:下载并安装 nvm:curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.40.3/install.sh | bash step2&…...

MiniCPM-o-4.5-nvidia-FlagOS生成LaTeX文档效果:从草稿到排版一气呵成
MiniCPM-o-4.5-nvidia-FlagOS生成LaTeX文档效果:从草稿到排版一气呵成 每次写论文或者技术报告,最头疼的是什么?对我来说,不是想内容,而是排版。那些复杂的数学公式、交叉引用、参考文献格式,还有怎么也调…...
)
从HippoRAG到MemOS:LLM记忆管理技术演进史(含开源工具对比表)
从HippoRAG到MemOS:LLM记忆管理技术演进史 当ChatGPT在2022年底掀起生成式AI的浪潮时,大多数用户惊叹于其流畅的对话能力,却很少人注意到一个关键问题:这些看似"聪明"的对话机器人,实际上患有严重的"健…...
)
SlowFast实战:手把手教你用AVA数据集训练行为识别模型(附最新v2.2标注文件处理技巧)
SlowFast实战:从AVA v2.2数据集处理到高效训练行为识别模型 行为识别技术正逐渐成为智能监控、人机交互等领域的核心技术之一。作为该领域的标杆算法,SlowFast网络凭借其双路径设计在精度与效率间取得了出色平衡。本文将带您从零开始,基于最新…...

Ostrakon-VL-8B在单片机系统中的应用前瞻:云端视觉AI赋能边缘设备
Ostrakon-VL-8B在单片机系统中的应用前瞻:云端视觉AI赋能边缘设备 最近和几个做物联网的朋友聊天,大家聊到一个共同的痛点:现在的单片机设备越来越“聪明”,但真要让它“看懂”周围的世界,比如识别个物体、判断个场景…...

如何使用SoccerOnTable:将足球视频转换为3D AR/VR体验的完整指南
如何使用SoccerOnTable:将足球视频转换为3D AR/VR体验的完整指南 【免费下载链接】soccerontable Upconverting YouTube soccer videos in 3D for viewing in AR/VR devices.Soccer On Your Tabletop 项目地址: https://gitcode.com/gh_mirrors/so/soccerontable …...

Phi-3-vision-128k-instruct实际效果:对齐人类专家的工程图纸关键部件识别与标注
Phi-3-vision-128k-instruct实际效果:对齐人类专家的工程图纸关键部件识别与标注 1. 模型简介 Phi-3-Vision-128K-Instruct是微软推出的轻量级多模态模型,专注于处理高密度推理任务。这个模型特别擅长理解工程图纸和技术文档,能够准确识别和…...

ComfyUI可视化流程集成:SenseVoice-Small语音识别节点开发教程
ComfyUI可视化流程集成:SenseVoice-Small语音识别节点开发教程 你是不是已经用ComfyUI玩转各种文生图、图生图,甚至搭建了复杂的AI绘画工作流?有没有想过,如果能让你的工作流“听懂”语音指令,或者自动把一段播客、会…...